【MPP数据库】TiDB表分区探索与实践
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
方案背景——为什么要进行分区?
一是老板通Tidb集群每天涉及50+张表、2亿多条数据回流合理使用Hash可以把写入压力打散到不同的TiKV;
二是对于大集团数据做聚合利用分区裁剪原理查询时可以充当前置索引预先过滤出部分数据加速查询效率。
分区方案
由于TiDB不支持对多列进行分区(例如group_id + report_date因此我们目前的解决办法是将 需要分区的字段组合成一个值由数仓计算出放在 partition_id 这个字段中建表时通过partition_id分区。
通过不断探索目前得到相对最优的公式partition_id = (group_id * 100000000 + report_date) % 29
为什么要对29取余?
因为group_id本身不离散因此需要把它离散掉。通过测试发现如果对质数(素数取余相对比较离散而如果对非素数(10,20,128…取余离散性较差。
参考如下
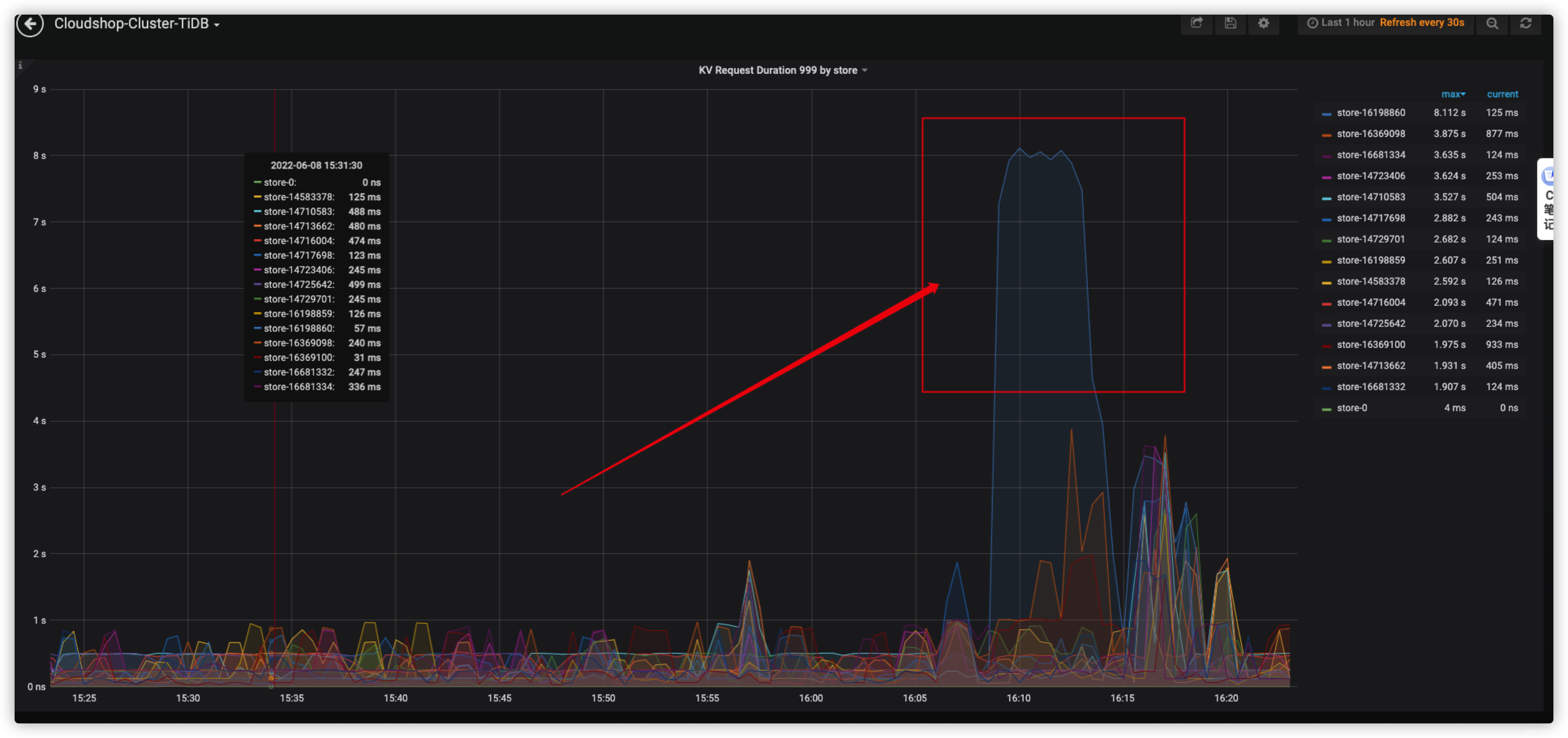
图1是对10取余进行分区数据回流时tidb kv999可以看到存在热点kv数据不离散。
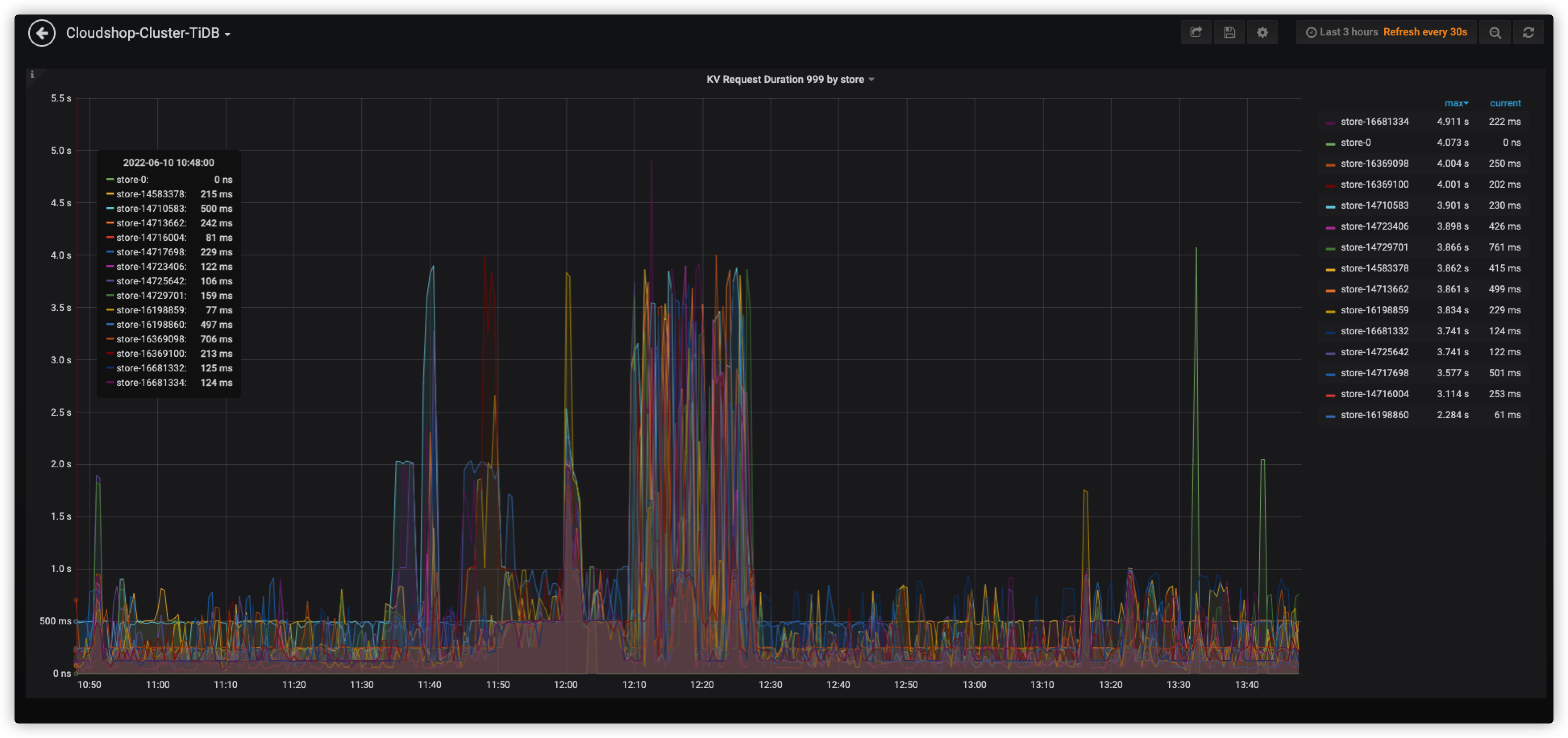
图2是对29进行取余分区数据回流时tidb kv999可以看到无热点kv相对均衡。
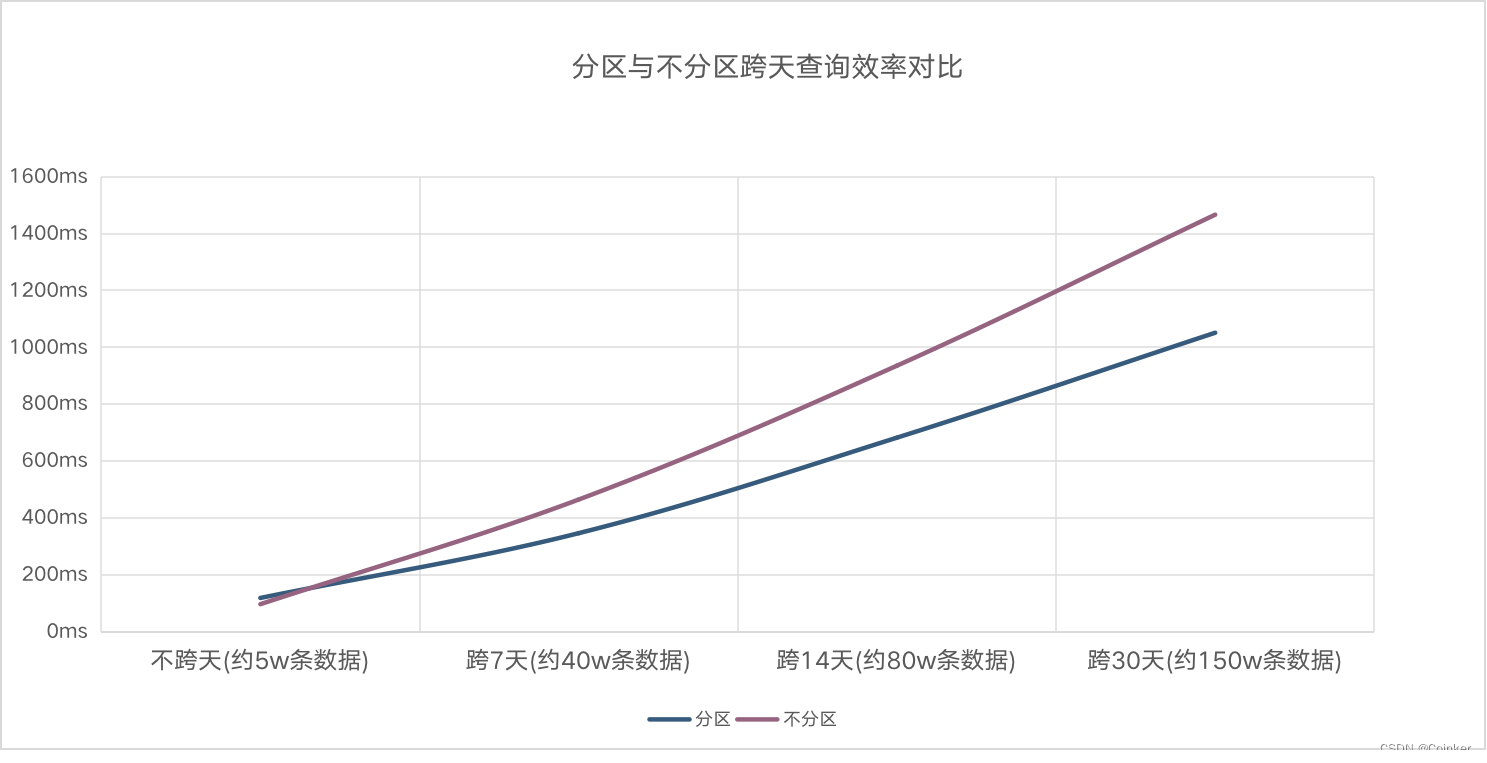
分区与不分区查询测试对比
总得来说随着查询记录数的增多分区表比不分区表查询效率高出30%。