

Python爬虫之Web自动化测试工具Selenium&&Chrome handless
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

@作者 : SYFStrive
@博客首页 : HomePage
🥧 上一篇续文传送门
📌个人社区欢迎大佬们加入 👉社区链接🔗
📌如果觉得文章对你有帮助可以点点关注 👉专栏连接🔗
💃程序员每天坚持锻炼💪
🔗阅读文章


📋目录
Selenium简介
- Selenium是一个用于Web应用程序测试的工具。
- Selenium 测试直接运行在浏览器中就像真正的用户在操作一样。(真正的用户还不给数据那么网站存在的意义是什么)
- 支持通过各种driverFirfoxDriverIternetExplorerDriverOperaDriverChromeDriver驱动
真实浏览器完成测试。 - selenium也是支持无界面浏览器操作的。
- 缺点有点慢
为什么使用selenium❓
模拟浏览器功能自动执行网页中的js代码实现动态加载
如何安装selenium❓
步骤
- 下载对应浏览器版本驱动
- 查看自己浏览器的版本 如以🛠为例谷歌浏览器右上角‐‐>帮助‐‐>关于
- 以🛠浏览器为例驱动下载点击跳转
- 把下载好的放驱动放在项目的目录下
- 安装语法pip install selenium
- 其他驱动
| 驱动名 | 链接 |
|---|---|
| GG | https://chromedriver.chromium.org/downloads |
| Ee | https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/ |
| 🦊 | https://github.com/mozilla/geckodriver/releases |
| 🍏 | https://webkit.org/blog/6900/webdriver-support-in-safari-10/ |
selenium的使用步骤❓
- 因为随着 selenium版本的升级一些语法也随之发生改变请参考 👇 文档不懂的可以私聊我互相交流
- 官方文档点击跳转至官方
- selenium文档直接跳至selenium文档
- 导入from selenium import webdriver
- 创建谷歌浏览器操作对象
- path = 谷歌浏览器驱动文件路径
- bor= webdriver.Chrome(path)
- 访问网址
- url = 要访问的网址
- bor.get(url) = 自动打开浏览器
- 获取内容
- content = bor.page_source = 获取爬取的源码
selenium获取🔍源码练习
📰代码演示
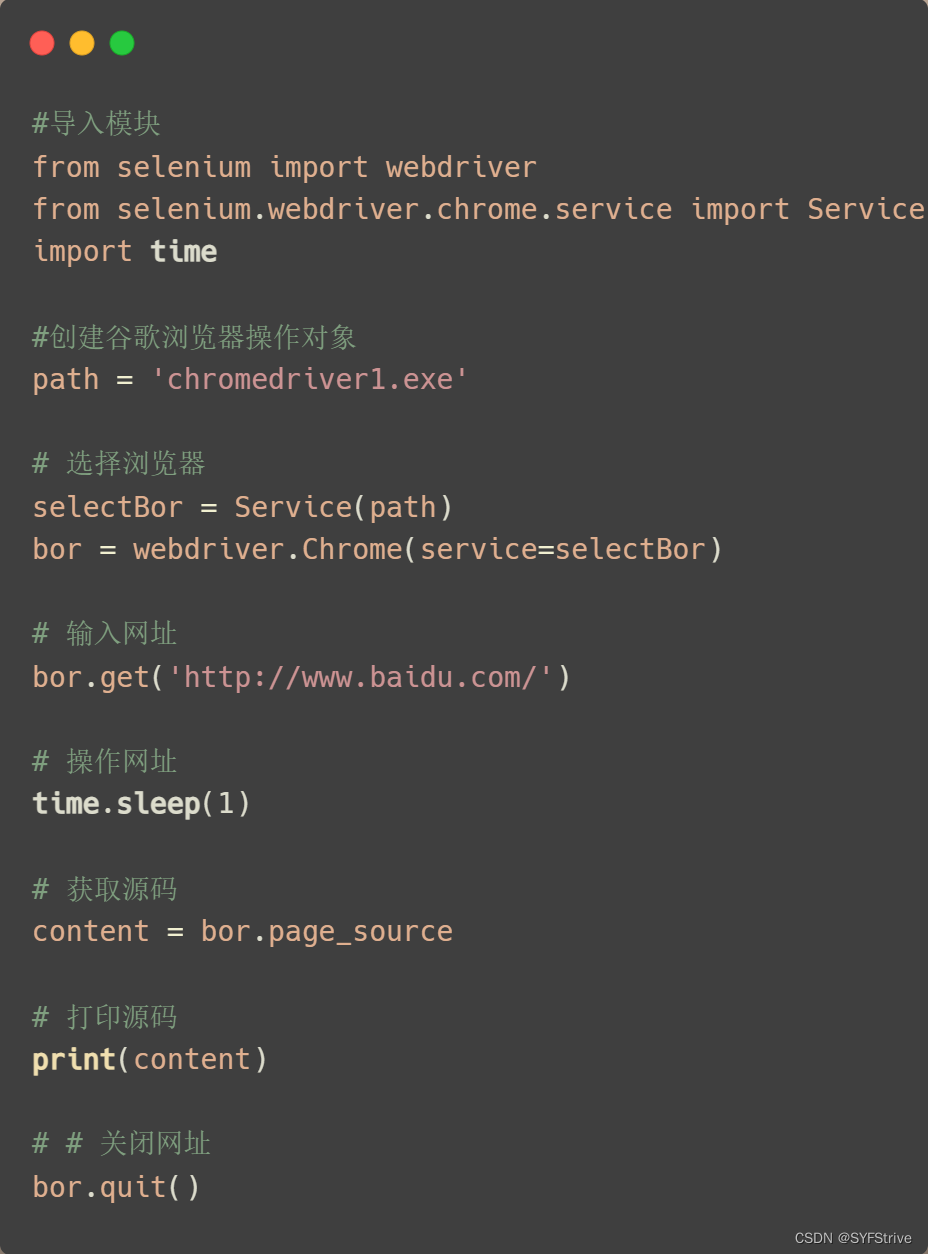
如果出现下面的报错不要慌问题出现在浏览器驱动版本不一致 或者 高于当前浏览器版本下载对应的驱动即可

如下图成功🆗
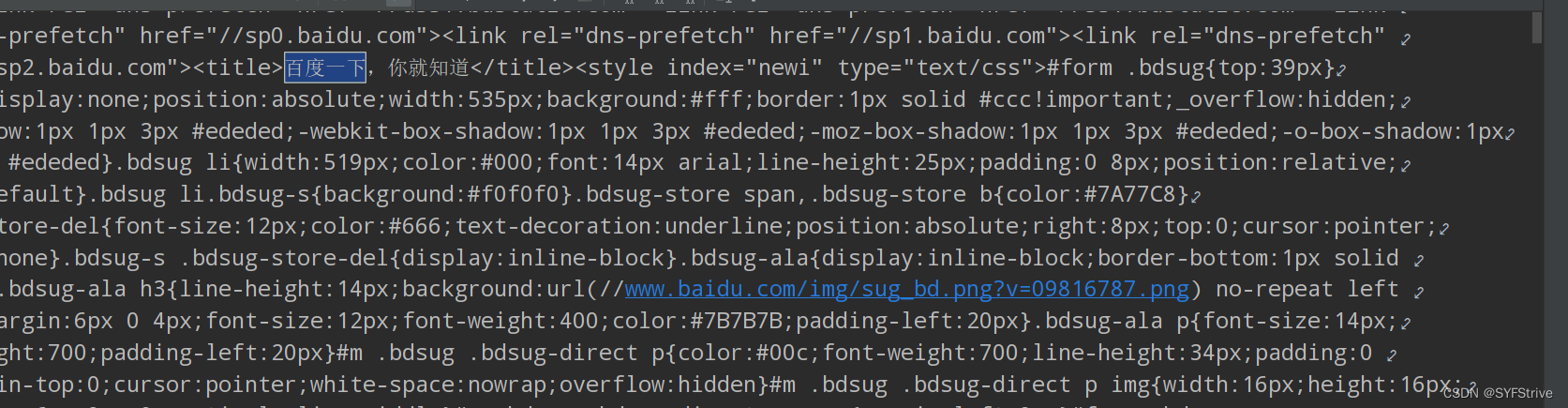

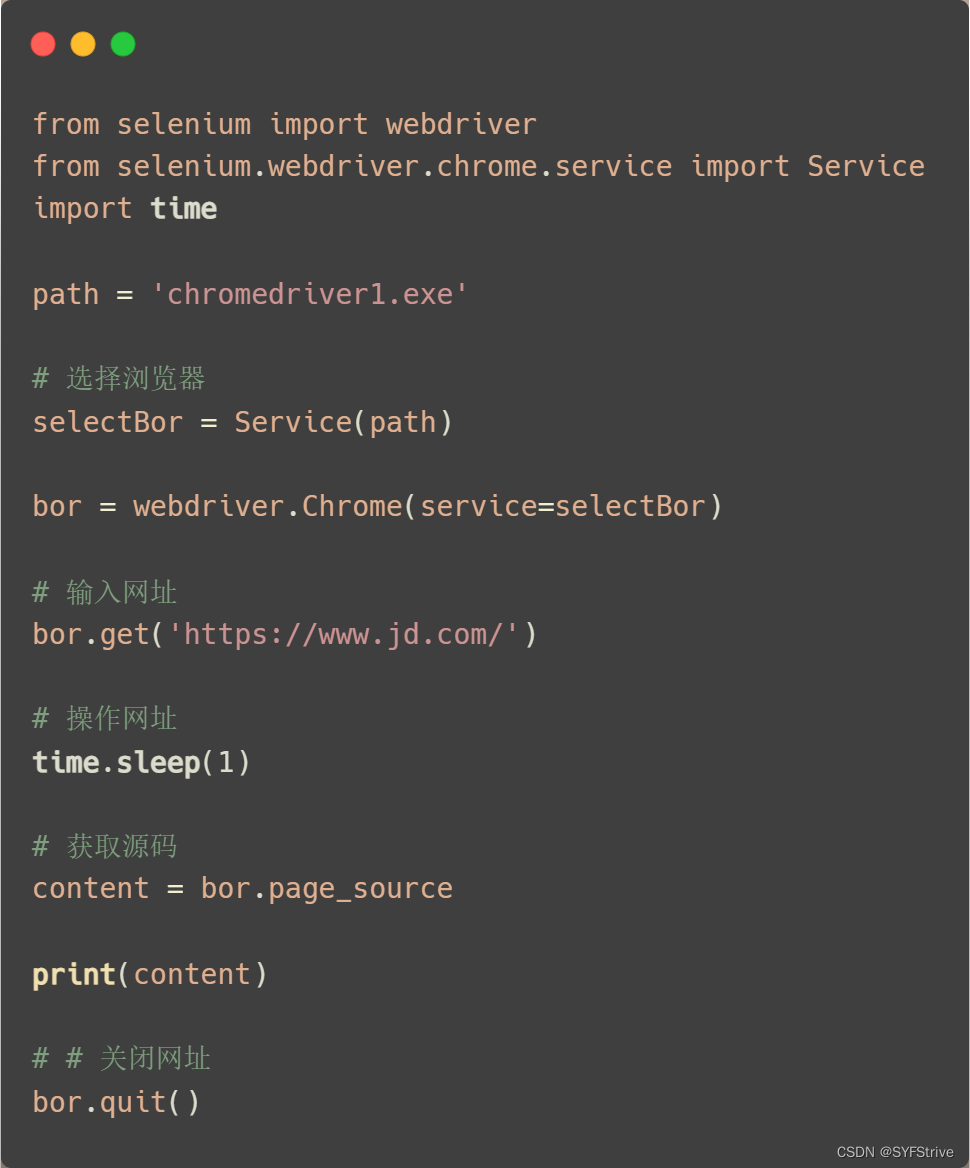
selenium获取🛒源码练习
📰代码演示
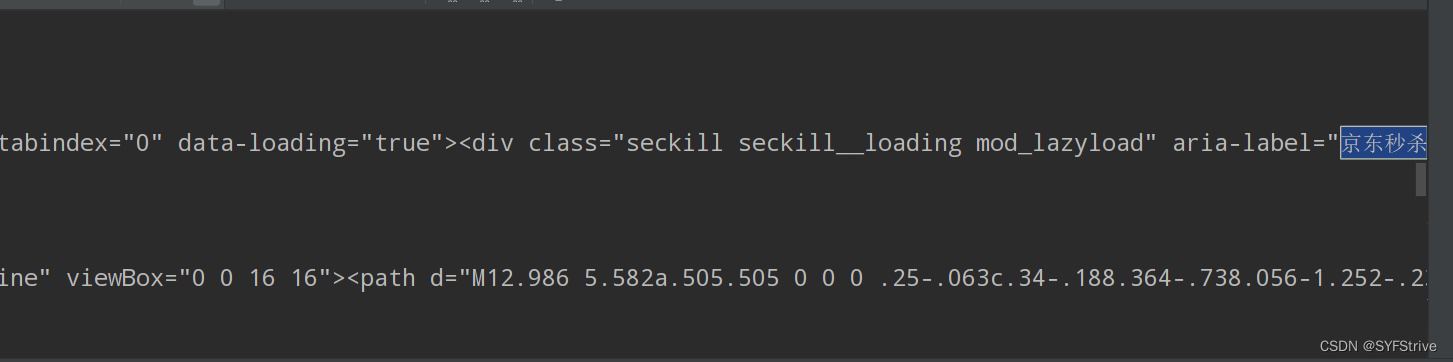
如下图成功🆗

selenium之元素定位❓
说明元素定位自动化要做的就是模拟鼠标和键盘来操作来操作这些元素点击、输入等等。操作这些元素前首先要找到它们WebDriver提供很多定位元素的方法比如自动抢票等😀
方法
🔋表示常用
推荐博客园文章关于元素定位的相关使用👉点击跳转🔗
常用的六种方法方法对应关系 (这是旧版的报错但不影响使用) =>新版使用新版需要导入from selenium.webdriver.common.by import By
| 方法使用 | 举例 |
|---|---|
| find_element_by_id=>find_element(By.ID, “ID”) | eg:button = bor.find_element_by_id(‘id值’) 🔋 |
| find_elements_by_name=>find_element(By.NAME, “NAME”) | eg:name = bor.find_element_by_name(‘input里面的name’) |
| find_element_by_xpath=>find_element(By.XPATH, “XPATH”) | eg:xpath1 = bor.find_element_by_xpath(‘//input[@id=“id值”]’) 返回值 🔋 |
| find_elements_by_tag_name=>find_element(By.NAME, “NAME”) | eg:names = bor.find_elements_by_tag_name(‘标签名’) |
| find_elements_by_css_selector=>find_element(By.CSS_SELECTOR, ‘#J_footer’) | eg:my_input = bor.find_elements_by_css_selector(‘这里简单记使用的是Bs4语法’)[0]🔋 |
| find_elements_by_link_text=>find_element(By.LINK_TEXT, ‘秒杀’) | eg:bor.find_element_by_link_text(“页面中的链接文本”) |
| find_element(By.CLASS_NAME, “CLASS_NAME”) | eg:name = bor.find_elements(By.CLASS_NAME, “秒杀”) |
| 方法对比 |
|---|
| find_element VS find_elements 一个返回的是值一个是列表 |
📰代码演示
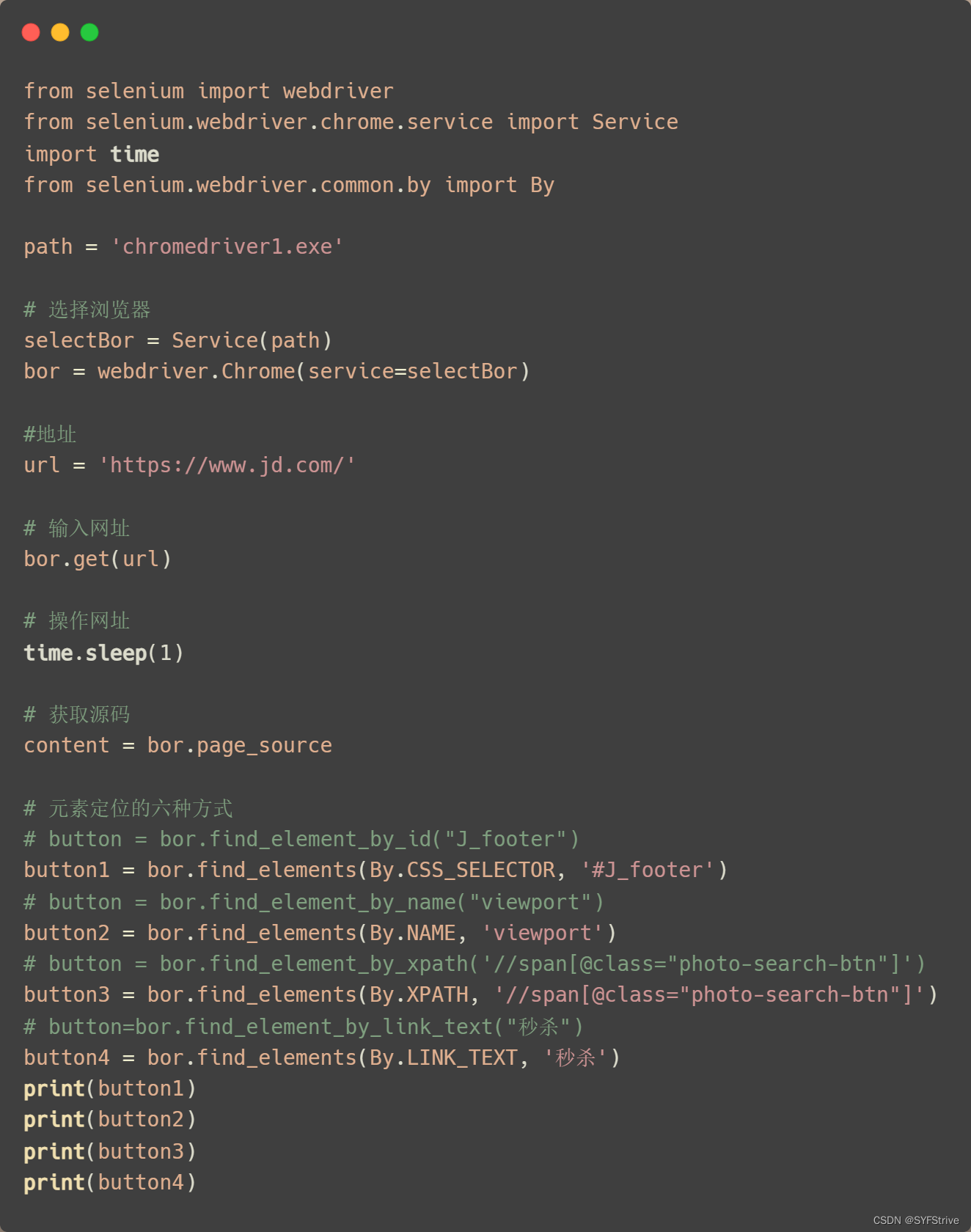
如下图成功🆗

访问的相关使用
说明定位到元数后获取该元素的文本、类Id名等等……
访问元素信息
- 获取元素属性
.get_attribute(‘class’) - 获取元素文本
.text - 获取标签名
.tag_name
📰代码演示
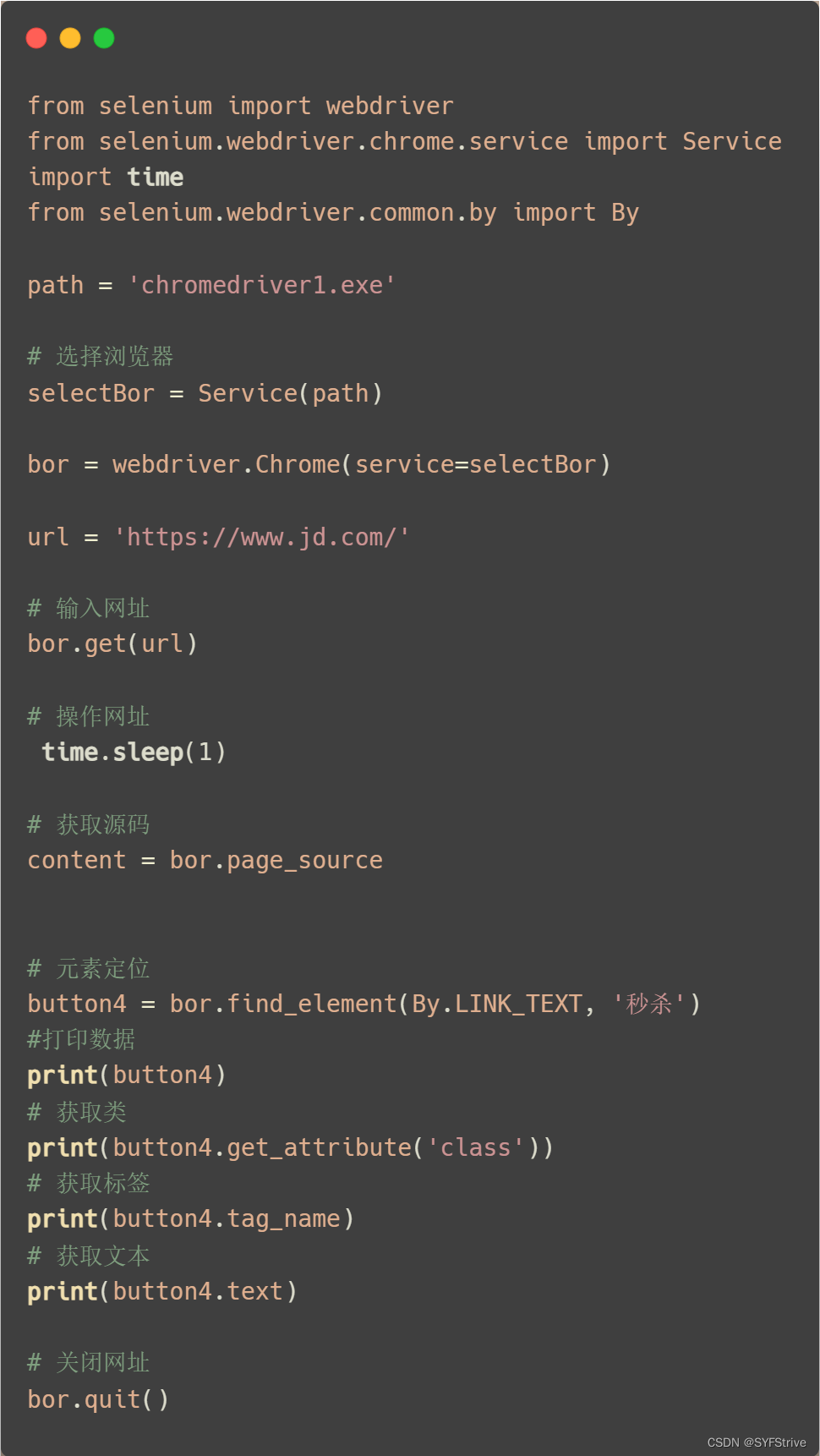
如下图成功🆗

交互的相关使用
说明如自动打开🔍然后输入大司马然后点击他的简介进行查看自动执行刷起来
交互
- 点击:click()
- 输入:send_keys()
- 后退操作:bor.back()
- 前进操作:bor.forword()
- 模拟JS滚动:
- js=‘document.documentElement.scrollTop=100000’
- bor.execute_script(js) 执行js代码
- 退出bor.quit()
📰代码演示
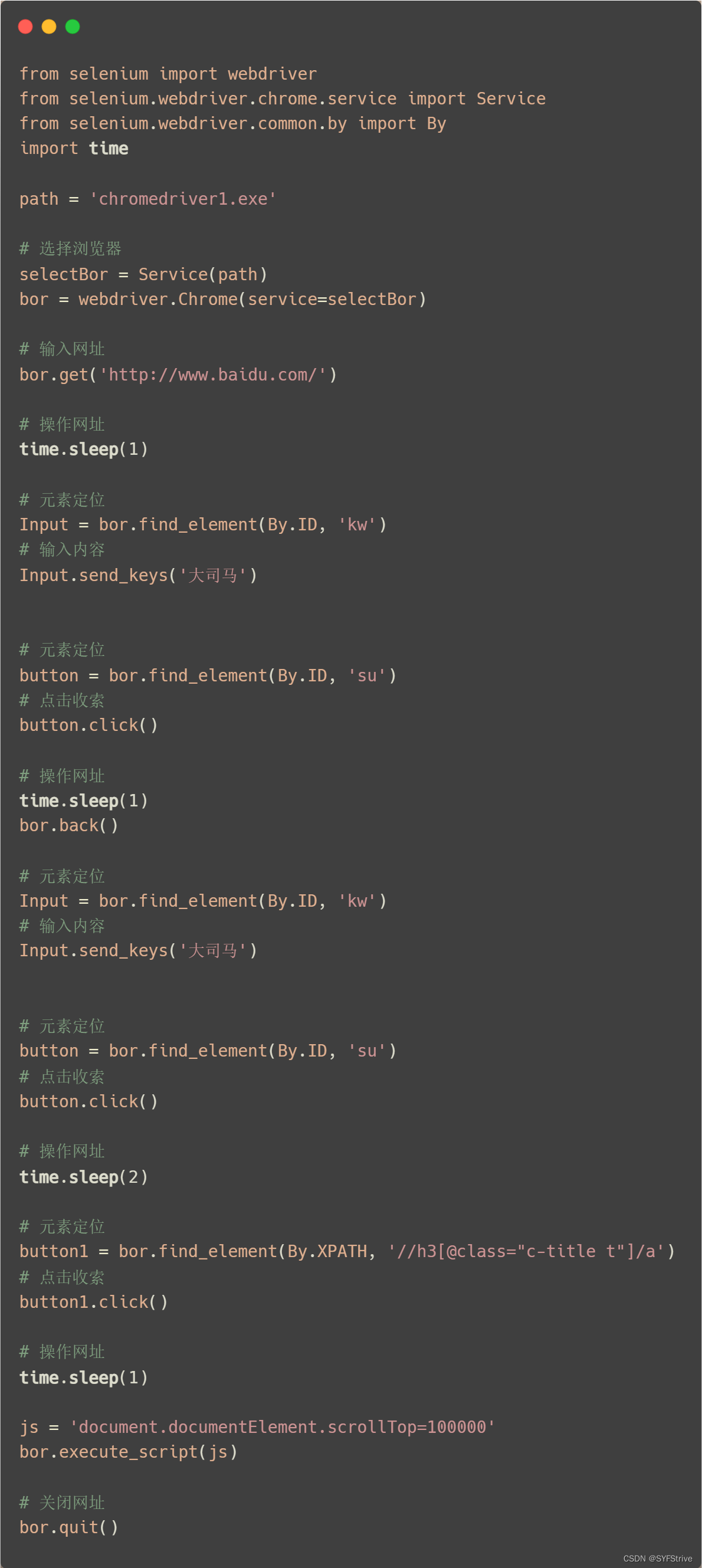
如下图全自动的gif太大传不了可以自己把time设置大一点感受🆗
链接👉 点击查看
{kind=link}
小总结✍
**使用步骤**使用selenium获取源码 👉 定位元素 👉 访问元素 👉 模拟交互
Chrome handless
简介
- Chrome handless 跟 Selenium使用方法差不多使用起来速度比Selenium更快
- Chrome-headless 模式 Google 针对 Chrome 浏览器 59版 新增加的一种模式可以让你不打开UI界面的情况下
- 使用 Chrome 浏览器所以运行效果与 Chrome 保持完美一致。
- 优点快
- 缺点无界面
系统要求
- 系统要求
- Chrome
- Unix\Linux 系统需要 chrome >= 59
- Windows 系统需要 chrome >= 60
- Python3.6
- Selenium==3.4.*
- ChromeDriver==2.31
Chrome handless相关使用
- 配置固定模板
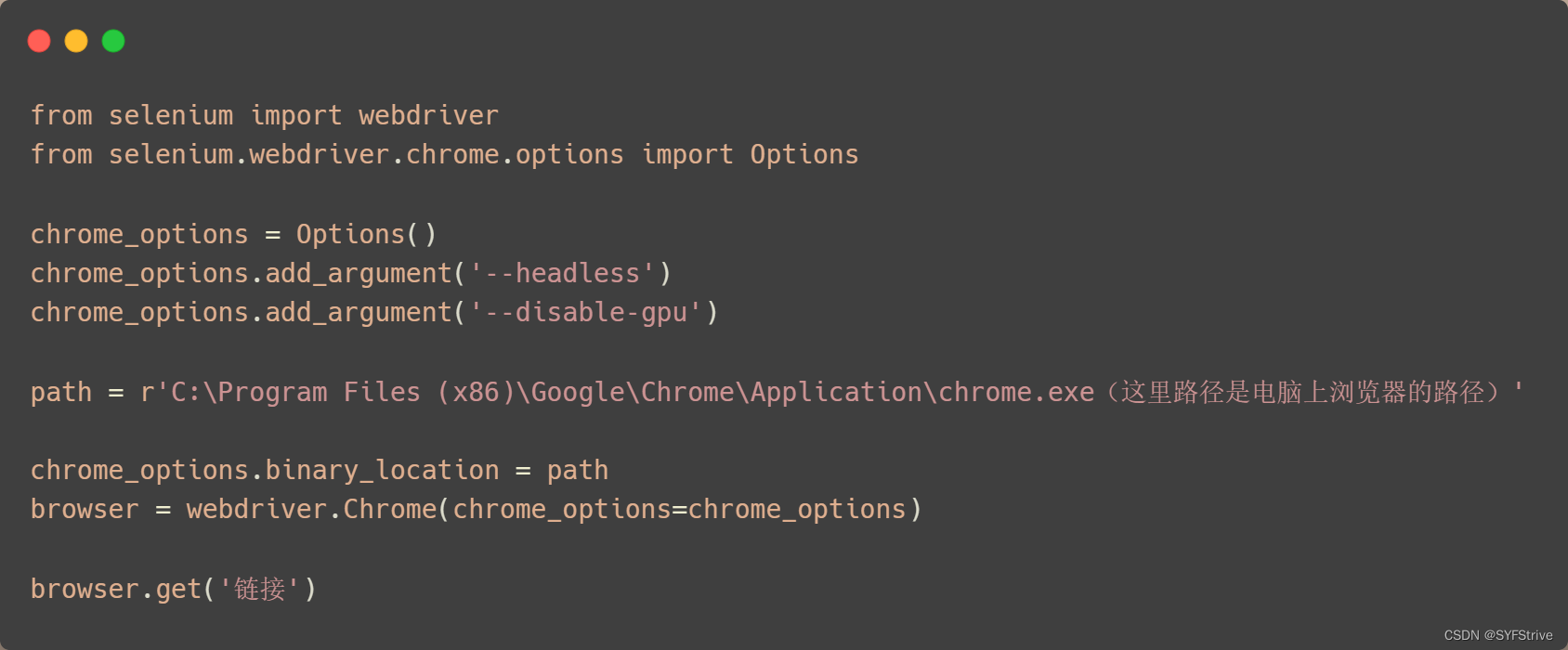
📰代码演示
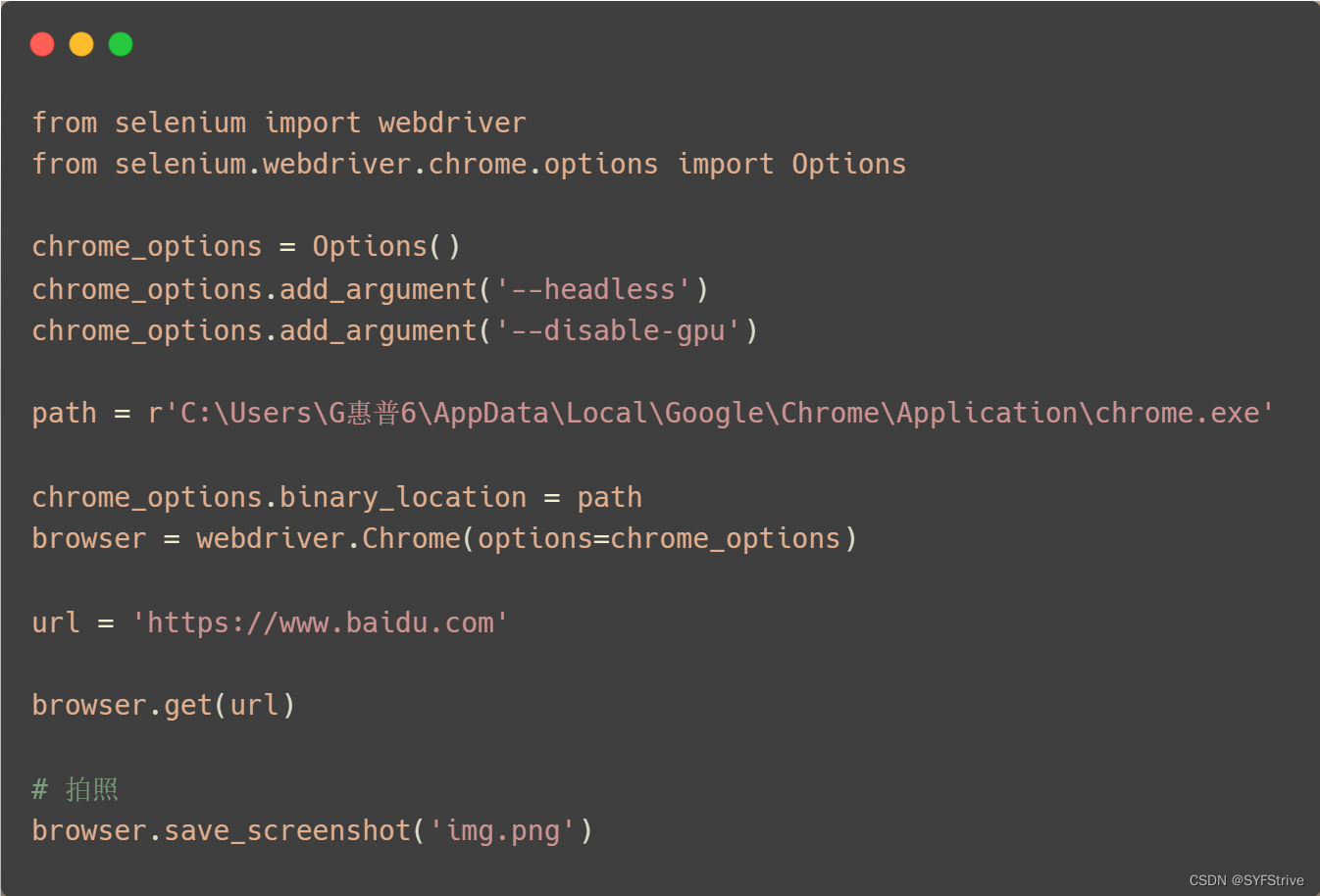
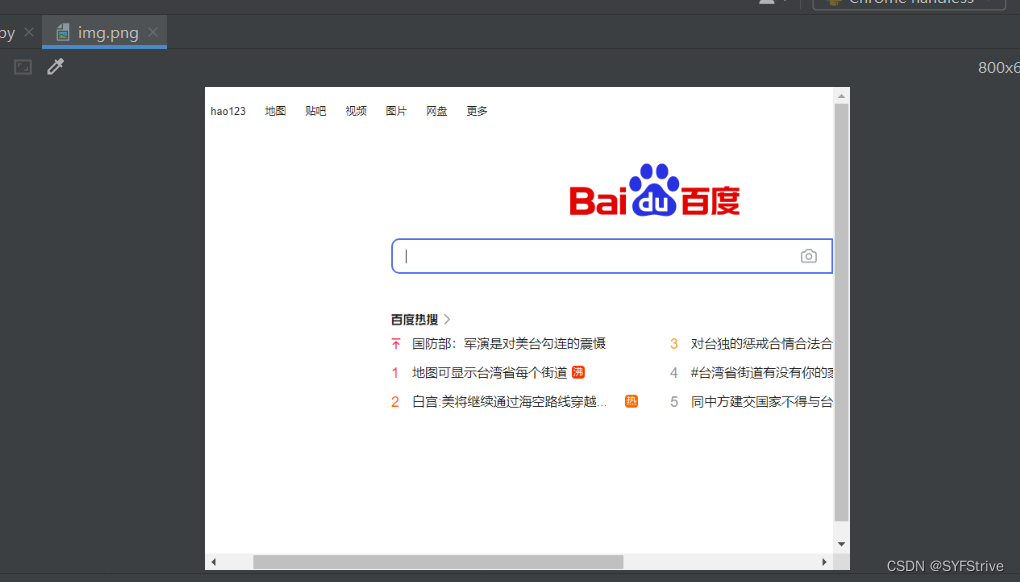
如下图成功🆗
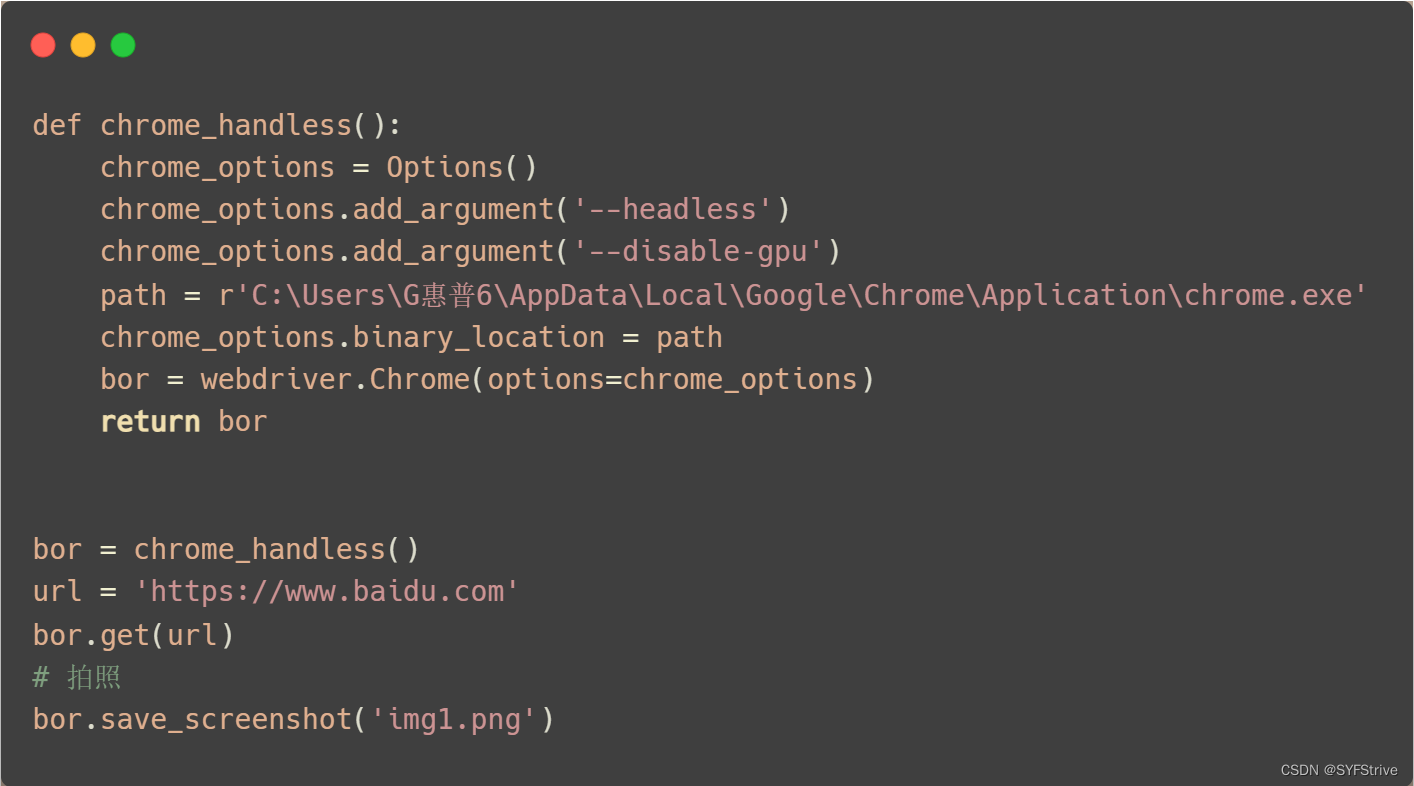
Chrome handless简单封装
最后
本文章到这里就结束了觉得不错的请给我专栏点点订阅你的支持是我们更新的动力感谢大家的支持希望这篇文章能帮到大家

下篇文章再见ヾ( ̄▽ ̄)ByeBye
