

【CCXT】如何获取历史行情,为后面开发策略做准备?_ccxt
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
前言
工欲利其事必先利其器。在量化交易中数据质量的高低直接决定了策略可不可靠。本章主要是为后续开发量化策略打下基础并且给出两个策略代码一个代码可以获取比特币3年内行情数据一个可以获取10年以上的数据。
一、CCXT
CCXT 库可用于世界各地的加密货币/山寨币交易所的连接和交易以及转账支付处理服务。它提供了快速访问市场数据的途径可用于存储数据分析可视化指标开发算法交易策略回测机器人程序网上商店集成及其它相关的软件工程。
这个章节我们主要利用了ccxt中集成好的框架获取各个交易所的币种行情数据保存到本地文件。
1.1 下载ccxt
pip install ccxt
1.2 获取行情数据
这块会有个bug由于数字货币交易所都在国外访问外网需要有一定条件懂的都懂需要在本地项目中设置代理。
# -*- coding: utf-8 -*-
# __file__name:binance-fetch-ohlcv-to-csv.py
import os
import time
import pandas as pd
os.environ["http_proxy"] = "http://127.0.0.1:1001"
os.environ["https_proxy"] = "http://127.0.0.1:1001"
# -----------------------------------------------------------------------------
root = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import ccxt # noqa: E402
# -----------------------------------------------------------------------------
def retry_fetch_ohlcv(exchange, max_retries, symbol, timeframe, since, limit):
num_retries = 0
try:
num_retries += 1
ohlcv = exchange.fetch_ohlcv(symbol, timeframe, since, limit)
# print('Fetched', len(ohlcv), symbol, 'candles from', exchange.iso8601 (ohlcv[0][0]), 'to', exchange.iso8601 (ohlcv[-1][0]))
time.sleep(0.05)
return ohlcv
except Exception:
if num_retries > max_retries:
raise # Exception('Failed to fetch', timeframe, symbol, 'OHLCV in', max_retries, 'attempts')
def scrape_ohlcv(exchange, max_retries, symbol, timeframe, since, limit):
timeframe_duration_in_seconds = exchange.parse_timeframe(timeframe)
timeframe_duration_in_ms = timeframe_duration_in_seconds * 1000
timedelta = limit * timeframe_duration_in_ms
now = exchange.milliseconds()
all_ohlcv = []
fetch_since = since
while fetch_since < now:
try:
ohlcv = retry_fetch_ohlcv(exchange, max_retries, symbol, timeframe, fetch_since, limit)
fetch_since = (ohlcv[-1][0] + 1) if len(ohlcv) else (fetch_since + timedelta)
all_ohlcv = all_ohlcv + ohlcv
if len(all_ohlcv):
print(len(all_ohlcv), 'candles in total from', exchange.iso8601(all_ohlcv[0][0]), 'to',
exchange.iso8601(all_ohlcv[-1][0]))
else:
print(len(all_ohlcv), 'candles in total from', exchange.iso8601(fetch_since))
except Exception as e:
print(e)
return exchange.filter_by_since_limit(all_ohlcv, since, None, key=0)
def write_to_csv(filename, data):
df = pd.DataFrame(data, columns=["时间戳", "开盘价", "最高价", "最低价", "收盘价", "成交量"])
df.to_csv(filename, index=False)
def scrape_candles_to_csv(filename, exchange_id, max_retries, symbol, timeframe, since, limit):
# instantiate the exchange by id
exchange = getattr(ccxt, exchange_id)()
# convert since from string to milliseconds integer if needed
if isinstance(since, str):
since = exchange.parse8601(since)
# preload all markets from the exchange
exchange.load_markets()
# fetch all candles
ohlcv = scrape_ohlcv(exchange, max_retries, symbol, timeframe, since, limit)
# save them to csv file
write_to_csv(filename, ohlcv)
print('Saved', len(ohlcv), 'candles from', exchange.iso8601(ohlcv[0][0]), 'to', exchange.iso8601(ohlcv[-1][0]),
'to', filename)
# -----------------------------------------------------------------------------
if __name__ == '__main__':
# Binance's BTC/USDT candles start on 2017-08-17
path = r'datas\binance.csv'
scrape_candles_to_csv(os.path.join(root, path), 'binance', 3, 'BTC/USDT', '1d', '2017-08-17T00:00:00Z', 1)
代码中需要强调几个地方
-
代理主机

-
函数scrape_candles_to_csv()中
- timeframe获取k线时间周期
- since开始时间UTC格式
- limit1 表示上下两个数据之间间隔1个timeframe
-
由于币安交易所限制最多只能获取近5年的数据而且每分钟最多请求1200个数据平均1秒20个数据
1.3 交易所时间戳转换问题
在真实交易前面临的第一个问题就是时间戳时间戳是一个不可避免的问题。时间戳指的是UNIX时间戳即从UTC时间1970年1月1日0时0分0秒到现在所过去的时间数。
时间戳无论在交易还是数据研究中都具有重要意义。在实际交易中当交易信号产生后应检查本地时间戳与服务器时间戳的差异若两个时间戳差距过大应当停止当前交易等待下一次交易信号产生。在回测数据的研究中CCXT一般返回的都是13位的UNIX时间戳因此也需要将时间戳转换成正常日期后才方便进一步地回测研究。
引用https://blog.csdn.net/c_morning/article/details/120679567
3.1 UNIX时间戳与ISO8601
Unix时间戳根据精度不同大致有10位秒级、13位毫秒级、19位纳秒级。
大多数交易所包括CCXT的接口目前提供的是13位的UNIX时间戳即毫秒级时间戳。本文将针对13位UNIX时间戳与ISO8601时间格式转换进行。
-
Unix毫秒级时间戳 = Unix秒级时间戳 * 1000
-
交易所目前提供的ISO8601格式为 “2021-10-09T10:08:09.999Z”
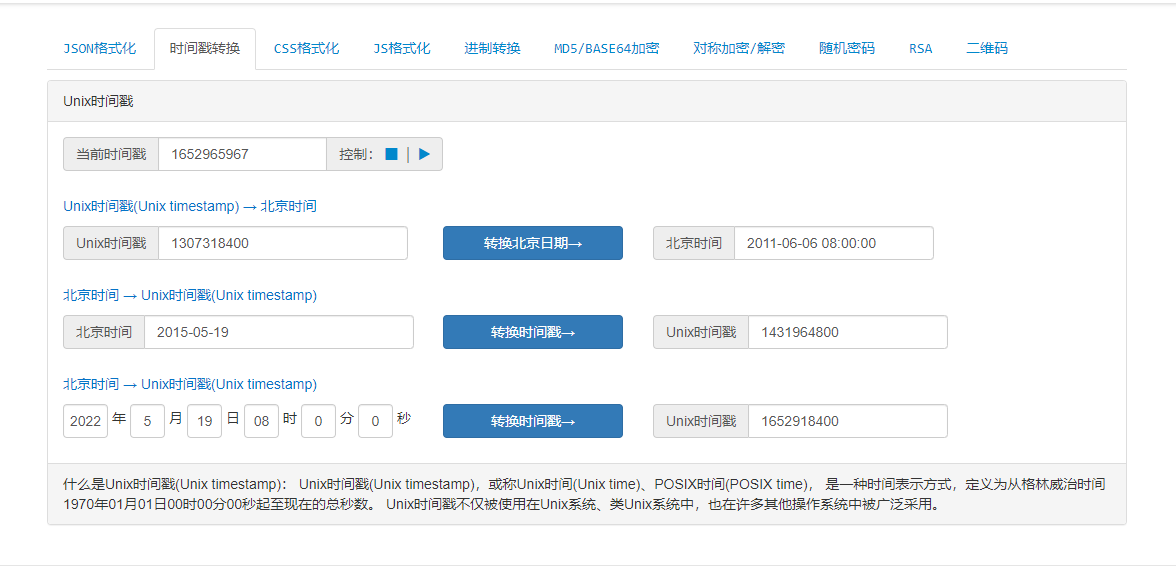
3.2 时间戳在线转化
由于一直通不过审核所以就把链接给下了
二、cryptocompare
可以根据api文档进行开发https://min-api.cryptocompare.com/documentation
2.1 代码获取日线数据
获取其他级别周期的数据可以参考文档开发
import os
import json
import requests
import pandas as pd
# 设置你的代理
os.environ["http_proxy"] = "http://127.0.0.1:1001"
os.environ["https_proxy"] = "http://127.0.0.1:1001"
def fetch_ohlcv(fsym,tsym,limit,toTs,api_key=None):
url = f"https://min-api.cryptocompare.com/data/v2/histoday?fsym={fsym}&tsym={tsym}&limit={limit}&toTs={toTs}&api_key={api_key}"
response = requests.get(url)
json_content = json.loads(response.content)
data = json_content["Data"]["Data"] # 转化为json格式
df = pd.DataFrame(data,columns=["time","high","low","open","close","volumefrom"])
return df
start_time = 1356998400 # 获取行情的起始时间
end_time = 1652918400 # 获取行情的终止时间
frames = []
while start_time<end_time:
df = fetch_ohlcv("BTC","USD","1000",end_time,"your_api_key")
end_time = df['time'].iloc[0]
frames.append(df)
df = pd.concat(frames)
df = df.sort_values(by=["time"])
df = df.sort_values(by=["time"])
df.set_index("time",inplace=True)
df[df.index>=start_time]
df.to_csv("btc.csv") # 保存文件
def fetch_ohlcv(start: datetime, end: datetime = None):
"""
获取数据行情,只能获取到2010/7/16之后的数据
:param start数据获取开始时间
:param end: 数据结束获取时间
:return:
"""
api_key = "your api"
fsym: str = "BTC"
tsym: str = "USD"
limit: int = 2000 # 0-2000
toTs: int = int(end.timestamp())
df: DataFrame = DataFrame()
while True:
url = f"https://min-api.cryptocompare.com/data/v2/histoday?fsym={fsym}&tsym={tsym}&limit={limit}&toTs={toTs}&api_key={api_key}"
response = requests.get(url)
res = json.loads(response.content)
data = res["Data"]["Data"]
tmp = pd.DataFrame(data, columns=["time", "high", "low", "open", "close", "volumefrom"])
toTs = tmp.iloc[0].at["time"]
df = pd.concat([df, tmp])
if toTs <= start.timestamp():
break
df["time"] = df["time"].apply(lambda time: datetime.fromtimestamp(time))
df.dropna(inplace=True)
df.duplicated(subset="time", keep="first")
df = df.set_index("time")
df = df.sort_index()
df = df[df.index > datetime(2010,7,17)]
df.to_csv("your_path.csv")
2.2 pandas
在2.1给出的代码中含有部分对pandas的操作对pandas不熟悉的朋友可以参考官方文档进行学习在这里留一个小坑后续我会出个系列教程教大家如何入门pandas。