

区块链共识协议
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
区块链相关的共识种类多且杂,参考多个综述、期刊、博客形成一个总体框架,干货满满,现分享出来,希望能给想把共识机制研究透彻的小伙伴一点帮助。
1.What
a distributed rule set for the creation of new blocks and verifying the chain hash.
译:用于创建新块和验证链哈希的分布式规则集。
共识算法可以让机群协同工作,并且可以容忍部分成员主机的故障。通常我们提到主机的故障会区分两种情况对待:拜占庭故障和非拜占庭故障。
比特币是第一个解决了拜占庭故障的去中心化系统,它的方法是使用工作量证明共识(POW)。在一个存在拜占庭故障的系统中,不仅会发生主机崩溃的问题,而且某些成员可能会存在恶意行为去影响整个系统的决策过程。
如果一个分布式系统可以处理拜占庭故障,那么它就可以容忍任何类型的错误发生。常见的支持拜占庭故障的共识算法包括PoW、PoS、PBFT和RBFT。
Raft只能处理非拜占庭故障,也就是说Raft共识可以容忍系统崩溃、网络中断/延迟/包丢失等故障。常见的支持非拜占庭故障的共识算法或系统包括:Raft、Kafka、Paxos和Zookeeper。
那么,Hyperledger Fabric为什么不使用可以容忍拜占庭故障的共识机制呢?那样不是更安全吗?
一个原因在于系统的复杂性与安全性的设计折中。假设一个系统中可能同时有n个节点发生拜占庭故障,那么拜占庭容错要求系统至少有3n+1个节点存在。例如,为了应对100个潜在的恶意节点,你至少需要部署301个节点。这就让系统更复杂。Raft则只需要2n+1个节点来应对潜在的n个节点的非拜占庭故障,显然复杂性和成本要低一些。因此有些分布式系统还是更倾向于Raft,尤其是考虑到像Hyperledger Fabric这种许可制的联盟链环境中,通常会使用数字证书等安全机制来增强安全性,因此存在恶意节点的可能性很小。
2.Why
区块链系统是一个典型的分布式系统,其中每个节点维护一份本地区块链数据备份.在区块链系统中,区块链共识协议制定了一组每个节点必须遵守的规则,最终保证分布式系统中各节点区块链数据备份的一致性。
3.How
3.1基础
两个主要步骤:出块节点选举、主链共识。
- 出块节点选举
某个节点(或多个节 点)成为出块节点,提出新区块。
- 主链共识
所有节点对新区块及其构成的主链达成一致,避免分布式网络中可能存在的恶意节点及分叉块的影响。
出块节点选举机制和主链共识共同保证了区块链数据的正确性和一致性,从而为分布式环境中的不可信主 体间建立信任关系提供技术支撑.
4分类
4.1PoX类
以PoW为代表的基于奖惩机制驱动的新型共识协议,还有PoS、PoST等改进协议。基本特点在于设计证明依据,使诚实节点可证明其合法性,从而实现拜占庭容错。
4.1.1PoW
工作量证明proof of work,比特币首次使用该机制进行出块节点选举。 工作量证明的概念最早由 Jakobsson 等人在 1999 年提出,用于实现可验证的计算任务。
工作量证明包括证明者和验证者两个角色,证明者向验证者出示证据,表明自己在某时间段内完成了一定数量的计算任务。由于产生证据需消耗一定量计算资源,工作量证明可用于缓解垃圾邮件和其他拒绝服务攻击问题。

补充:
PoW 并非在区块链中被首次使用,PoW 于1992 年由 Dwork等人提出,并将其应用于处理垃圾邮件,Back则于1997年独立提出了 PoW ,并将其应用于 hashcash系统。 hashcash与前者的不同在于其使用了更高效的哈希算法而不是弱签名算法,hashcash对比特币产生有重大影响。
在比特币系统中,各个节点共同求解一个验证简单但求解复 杂的数学难题以争夺记账权,这一过程也被通俗地称为“挖矿”。该数学难题可简要描述为在某个难度值下,节点寻找一个随机数 使得区块头的两次 sha256 结果不大于目标值,难度值动态调整以 使得区块产生的速率约为10min。 通过付出大量的算力,达到了“ 一 CPU一票”的目的。
由于一定时间内可能存在多个节点都寻找到了合法的随机数 并广播到了网络,网络上的节点可能会分为多个集合即系统存在多条链,这一现象也被称为分叉。 比特币系统中定义了最长链原则,即矿工始终选择最长的链进行挖矿,如果两条链长度一样,则选择最先收到的那一条链。 因此,比特币中的确认是概率性的确认,一旦存在一条更长的链,系统就会切换到该链上去。 如果系统的算力不够庞大或者过于集中,则更有可能遭遇 51%攻击。 所谓 51%攻击,指的是恶意节点通过控制超过一半算力并试图制造更长的链以进行双花等行为的一种恶意攻击。ASIC等专用芯片所打 造出的矿机也使得算力更容易集中于少部分用户手中,这无疑对 PoW所依赖的去中心化假设构成了一定的挑战,增加了PoW区块链系统遭受51%攻击的风险。 此外,PoW还存在效率低下、性能差、能源浪费严重等缺点。
为解决上述问题,一些新的共识机制应运而生。 其中,一部分共识机制如 PoS 选择从挖矿的机制入手,通过重新定义挖矿的机制来降低无效的能源浪费以及提高区块的生成效率;
一部分共识机制选择缩小参与共识的节点范围,将一定时期的共识限制在一部分节点内,而在共识节点之间选择相对传统的共识机制以避免资源浪费并提高效率,这类共识机制有DPoS 、基于VRF的共识机制等;
一部分共识机制选择改变底层的数据结构如选择DAG作为底层的数据结构以提供更好的并行性、更强的安全性及更高的性能,这类共识机制有Conflux等;一部分共识算法 则将节点分片分区以提高系统的并行能力,这一类共识机制有分片技术 、连弩挖矿等。
4.1.2PoS
最早于2012年在peercion(点点币)上采用。 尽管挖矿行为仍然存在,并且同样是共同求解一个 验证简单但求解复杂的数据难题以争夺记账权,但是针对不同节点计算的难度值不再相同。
在PoS共识机制中,定义币龄为货币数量和时间的乘积,节点所拥有的币龄越大,挖矿所面临的难度值也就越低,生成区块的概率也就越大。 通过这种方式,PoS将PoW中 的算力消耗变成了币龄消耗,整个挖矿过程中消耗的能源大大减少。 以太坊创始人Buterin认为,PoS相较于PoW可以节省超过99%的能源消耗。 相应地,系统中主链则被定义为币龄最高的链。
为了避免“富者愈富”的情况发生,当节点成功生成区块时,币龄会被消耗;同时当货币发生转移时,币龄也会被清空。 通过这样的机制,PoS 希望能够避免财富的过度集中以增强系统的去中心化能力。PoS共识机制的支持者认为,在PoS区块链系统中,算力不再 是系统中的硬通货,因此 ASIC等专用芯片打造的矿机所发挥的作 用也受到了抑制,从这一角度上PoS有助于提高区块链系统的去中心化程度。 而发动51%攻击需要攻击者拥有全网大半的币或者币龄,同时攻击成功往往也意味着承担最大的代价,这不仅难以做到,也不符合理性,从这一角度PoS能更好地防范51%攻击。
但是PoS下系统的安全性还存在较多争议。 在PoS共识机制下,即使节点离线其币龄仍然是累积的,所以节点可能会选择累计 币龄到一定程度后再上线参与区块生成,这就导致了系统可能 乏足够多的线上节点维护系统安全,同时也使得恶意节点可以通过这种方式以较小的成本等待时机发动攻击,这一可能性使得PoS更能抵御51%攻击的观点显得不那么可靠。
PoS共识机制还存在免权益证明(免费午餐)问题。 所谓免费午餐问题,是由于在 PoS系统中矿工并不需要类似于PoW中消耗大量的CPU资源进行挖矿以选择一条最长链进行跟随,所以其有更多的可能性在多条链上同时进行工作以获取更多收益。 因为矿工付出的权益只是与现实世界没有直接关联的区块链系统中的资源,而不是不可撤销的CPU算力。
为了解决PoS下的免费午餐问题,系统设计者往往选取惩罚措施以限制矿工同时下注。 但是这一方面增加了系统的复杂度,另一方面矿工本身就可能放弃自己最初认定的区块并选择被多数人认同的区块。 区分恶意下注并进行惩罚并不容易实施,并且更难证明惩罚带来的损失大于同时下注的收益且确实能改善系统中的免费午餐问题。 此外,PoS共识机制还存在一些可能的攻击方式如远程攻击等。 所谓远程攻击,指的是攻击者可以 购买一个过去拥有大量代币的私钥,并以此自己颁发越来越多的奖励,这些奖励的存在使得其得以生成比现有区块链更高的权益 链并逆转区块,而为了缓解这一问题系统需要设置一些检查点以避免历史区块被重组。 因此,PoS共识机制所存在的这一系列问题导致其安全性尚且不能被普遍认可,并且PoS共识机制往往更加复杂而难以实现。
4.1.3DPoS
不论是PoW还是PoS,共识过程都发生于全网所有节点之间 (只参与发起交易的轻节点除外)。 受限于较多的节点数目、较高的网络延迟等客观现实,出块速度、区块大小等都难以进一步提高,这是导致系统性能受限如系统吞吐率低、交易延迟大等的重要因素。 为了在较多参与节点中选取出块者,不可避免地依赖于挖矿机制或类似机制,这些机制不仅效率低下,同时也只能提供概率性的确认。 为了进一步解决PoW和PoS中存在的上述问题,一些共识机制选择缩小参与共识的节点范围,将一定时期的共识限制在一部分节点内,而在共识节点之间选择相对传统的共识机制以避免资源浪费、提高系统效率等。 这类共识机制典型的有DPoS、基于VRF的共识机制等。
DPoS共识将PoS共识范围从全网节点缩小到了选举产生的部分节点,该机制最早于2014年在Bitshares(比特股)中被首次应用,EOS(enterprise operation system)等继承发展了这一思想。一般地,DPoS可分为以下两个环节:
a)选举出委托人。 这一环节通过某种机制在全网节点之间选举出一定数量的委托人在一段时间内参与区块共识环节。
b)在委托人之间达成共识产生区块。 这一环节在选举出的委托人间运行共识算法以在委托人之间产生区块并达成共识。
由于DPoS中共识环节仅有少数委托人所控制的节点参与,在 这些少数节点中可以采取更为高效的共识算法如经典的BFT算法,从而实现高吞吐率、低延迟、确定性的区块生成等。 以EOS为例,EOS的代币持有者进行投票以在全球选出21个超级节点作为委员会,而委员会将在一年内负责参与EOS主网的区块产生。 由于委员会内部节点确定且数目较少,所以EOS在委员会内部共识 中采用了aBFT共识算法,并可以达到较短的区块产生时间、较高 的TPS(transaction per second,每秒交易数) 。 EOS宣称其能够达到百万计TPS,并且 99.9%的交易确认延迟小于250ms,同时相对于需要等待多个区块确认以进行概率性交易确认的PoW和PoS共识 机制,EOS宣称所有的交易都能在1s内进行不可逆的确认。 遗憾的是,EOS所宣称的这些性能指标并未能够完全实现,截止2018年4月,其最终上线主网的平均TPS约为3000,即使在最好情况下TPS也仅有6000,这与其所宣称的百万TPS相差甚远。 一部分研究者认为,其实际可用TPS不高于500,并且在高压下会出现分叉情况 。 但总的来说,虽然EOS未能达到其宣称的性能,但是相较于PoW和PoS等共识机制,DPoS展现出了更好的性能。
但是DPoS存在的中心化的风险不容忽视。DPoS在共识过程中只有少数节点参与,事实上系统在一段时间内由这些少数节点构成的委员会所控制。 如果选举过程不能做到公平,便难以保证委员会的可靠性和公正性。 此外,委员会也存在被恶意用户直接攻击的风险,这一系列缺点是DPoS相对中心化的机制所导致的。 事实上,在EOS选举超级节点的过程中就暴露了贿选、用户参与度低等缺陷,主网上线时间也因此数次被推迟,同时也引发了对EOS是否是公有链的质疑。 因此,虽然DPoS在吞吐率、延迟等方面获 得了较PoW或PoS等共识机制更好的效果,但是其付出的代价也不容忽视。
4.2BFT类
解决拜占庭容错问题的传统共识协议及其改良协议,包括PBFT、BFT-SMaRt、Tendermint等。
4.2.1PBFT
拜占庭将军问题于1982年由Lamport提出;1999年,Catro等人提出了PBFT算法,将拜占庭算法的复杂度降低到多项式级别, 从而使得拜占庭算法进入实用阶段。 PBFT是BFT类共识算法的 典型代表,其在Hyperledger Fabric 0.6被采用,而其变种Instanbul-BFT算法则在摩根大通的iQuorum中被选为所支持的两种共识机 制之一。PBFT算法的共识流程如图所示。 其可以简要描述如下:
a)客户端向主节点发起一次共识请求;
b)主节点向其他节点广播;
c)其他节点之间广播执行prepare和commit过程;
d)所有节点都将执行结果返回给客户端。
由于系统中存在F个可能的恶意节点,所以客户端接收到F+1个相同的执行结果后认为网络达成共识。

尽管PBFT是目前最为成熟的拜占庭容错算法之一,但是其算法复杂度还是相对较高,正常流程下的算法复杂度为O(n^2) ,leader切换时的算法复杂度更是高达O(n^3),较高的算法复杂度使得PBFT不能在较大规模的网络中使用。
为了更好地适应区块链系统的需求,基于PBFT诞生了一批新的拜占庭算法。 在这些拜占庭 算法中,一些共识算法虽然对PBFT进行了一定的改进,但是继承 了算法的核心流程,并保持了与PBFT的相同复杂度。 这一类算法 典型的有Instanbul-BFT等,这类共识算法可以认为是PBFT的变 种而不需要再进行深入讨论。 接下来所讨论的主要是另一类改进 算法,虽然借鉴了PBFT中的某些思想或流程,但是对其核心流程 进行了大胆的修改乃至变更,并且充分考虑了区块链的链式结构 特点和系统主要使用场景,显著降低了其复杂度的共识算法如Tendermint、HotStuff等。 这两种算法将正常流程下的算法复杂度从PBFT中的O(n^2)降低到了O(n) ,从而得以更好地适应网 络节点的数目增长,充分考虑了区块链系统中leader的切换场景, 并将复杂度从PBFT中的O(n^3)降低至O(n^2)乃至 O(n)。 这一系列改进使得这类算法能够达到更高的性能并支持更大的网络规模,通过将这类算法在许可链系统上的应用也进一步拓展了许可链的应用场景。
4.2.2Tendermint
在Tendermint共识算法中,区块成为了共识的基本单位。 借助区块链的链式特点,共识流程得以被充分简化,算法复杂度也得以 被进一步降低。 其中,正常流程下算法复杂度虽然与PBFT一样保 持为O(n^2) ,但是leader切换时的算法复杂度降低为 O(n^2)。 如果在共识实现上加入门限签名的手段,上述流程的复杂度则均降低为O(n)。 其中,算法正常流程如图所示。 其可以简要描述如下:
a)验证节点发起创建区块提议,这一过程称为propose;
b)其他验证节点验证区块是否正确,如果正确则对该区块进行投票,这 一过程称为pre-vote;
c)如果在上一轮搜集到超过2/3的节点的投票,则对该区块发起precommit过程,否则放弃该区块;
d)如果在上 一轮搜集到超过2/3的节点的头片,则对该区块发起commit过程, 并最终产生新的区块,否则进入下一轮区块生成。
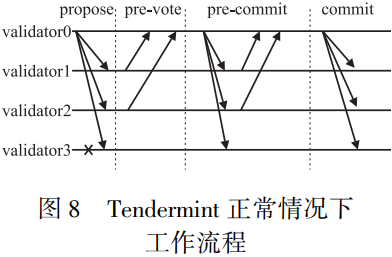
补充: 由于未采用类似工作量证明的身份定价机制,为防止拜占庭节点发动女巫攻击,系统规定节点必须在账户存入保证金才能参与拜占庭容错协议的投票过程,保证金数额与票数成正比。
4.2.3HotStuff
在HotStuff共识算法的设计上也充分考虑了与区块链系统的结合。 基于区块链的链式结构HotStuff得以将共识流程进一步简 化,相对于Tendermint,HotStuff的一个突出贡献是将配置变更与正常流程结合在一起,通过增加消息确认的步骤以及引入门限签名将正常流程和leader切换的复杂度均降低到了O(n),不仅提高了系统的性能,也简化了leader的切换场景;同时,HotStuff将共识的流程流水化,从而使得多个leader同时工作以产生多个区块。 这些特性使得HotStuff可以支持更大的网络规模,也更加适用于区 块链这一相对去中心化的场景。 得益于这些优点,HotStuff被Facebook的Libra所采用,以支持数百个节点构成的区块链系统。
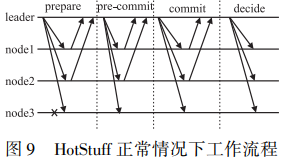
HotStuff共识流程如图所示。 其可以简要描述如下:
a)主节点搜集到足够多新视图变更后开启新视图阶段,发送prepare消息给其 他节点;
b)其他节点对prepare消息进行投票,主节点收集到足够 多投票后发送pre-commit消息;
c)其他节点对pre-commit消息进行投票,主节点收集到足够多投票后发送commit消息;
d)其他节点对commit消息进行投票,主节点搜集到足够多投票后发送decide消 息,其他节点收到decide消息后进行状态迁移并执行新视图变更。
尽管Tendermint及HotStuff等共识算法在许可 链领域取得了一些较为显著的成绩,如两者分别在HyperLedger Burrow及Libra中被作为底层的共识协议所采用,但是这些算法的应用并不仅限于许可链领域。 以Tendermint为例,部分公有链如Cosmos就采用其作为底层的共识机制。HotStuff虽然出现时间 较晚,但是已经有一些公链团队如Cypherium开始尝试将HotStuff作为底层的共识机制。 因此,在共识层面上许可链和公有链 的差异远小于应用场景上的差异,两者的界限在逐渐淡化,以至于出现了一些同时在两个场景下都有着显著应用的共识算法。
4.3CFT类
相较于BFT类共识算法,CFT类共识算法不需要考虑恶意节点可能导致的拜占庭错误,仅需要考虑网络中断、磁盘故障、机器 宕机等意外的场景,包括Raft、Paxos、Kafka协议。
4.3.1Paxos
于1990年由Lamport提出以解决非拜占庭场景下的分布式一致性场景,在其基础上陆续产生了ZAB、Raft等共识算法。 相较于拜占庭将军容错场景下的共识算法,Paxos类共识算法复杂度较低,具备更好的拓展性并拥有更好的性能。
Paxos将系统中的角色分为提议者 (Proposer),决策者 (Acceptor),和最终决策学习者 (Learner):
- Proposer: 提出提案 (Proposal)。Proposal信息包括提案编号 (Proposal ID) 和提议的值 (Value)。
- Acceptor:参与决策,回应Proposers的提案。收到Proposal后可以接受提案,若Proposal获得多数Acceptors的接受,则称该Proposal被批准。
- Learner:不参与决策,从Proposers/Acceptors学习最新达成一致的提案(Value)。
在多副本状态机中,每个副本同时具有Proposer、Acceptor、Learner三种角色。
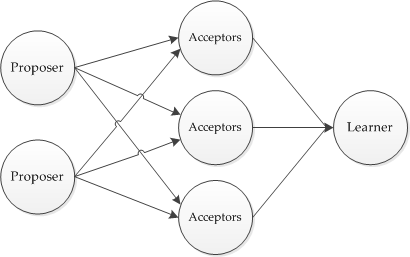
Paxos算法中的角色
Paxos算法通过一个决议分为两个阶段(Learn阶段之前决议已经形成):
- 第一阶段:Prepare阶段。Proposer向Acceptors发出Prepare请求,Acceptors针对收到的Prepare请求进行Promise承诺。
- 第二阶段:Accept阶段。Proposer收到多数Acceptors承诺的Promise后,向Acceptors发出Propose请求,Acceptors针对收到的Propose请求进行Accept处理。
- 第三阶段:Learn阶段。Proposer在收到多数Acceptors的Accept之后,标志着本次Accept成功,决议形成,将形成的决议发送给所有Learners。
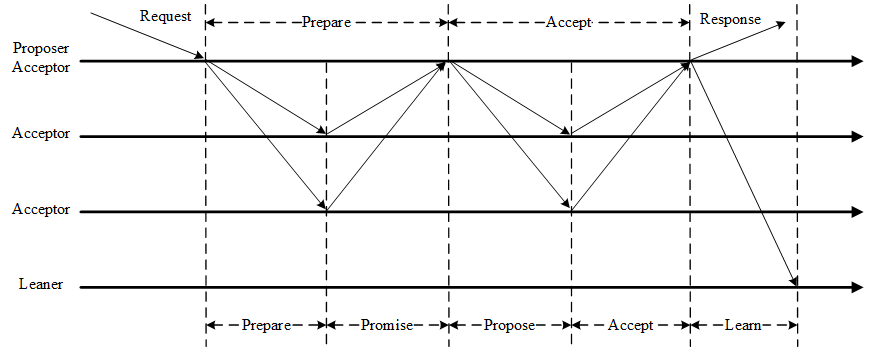
Paxos算法流程
Paxos算法流程中的每条消息描述如下:
- Prepare: Proposer生成全局唯一且递增的Proposal ID (可使用时间戳加Server ID),向所有Acceptors发送Prepare请求,这里无需携带提案内容,只携带Proposal ID即可。
- Promise: Acceptors收到Prepare请求后,做出“两个承诺,一个应答”。
4.3.2Raft
于2014年由Ongaro等人提出, 针对Paxos算法存在 的复杂难懂、实现困难等问题,Raft算法将易于理解放在了核心的 地位。 由于Raft算法相对清晰易懂、易于实现,并且能够提供优异 的性能,自问世以来Raft算法便很快被工业界广泛采用。 作为一 类强 leader共识算法,其核心流程可以分为leader选举和日志同 步。 前者解决的是如何进行 leader的选举问题,后者则解决了日志 如何在leader和follower节点同步的问题。 Raft算法的共识流程可简要描述如下:
a)client向leader发起一次共识请求;b)leader为请求分配一个序号,并向follower节点广播;c)follower将数据安全存储在本地并告知leader;d)leader收到超过一半回复后认定该请求被commit并返回client,commit消息在下一次广播时告知 follower节点。
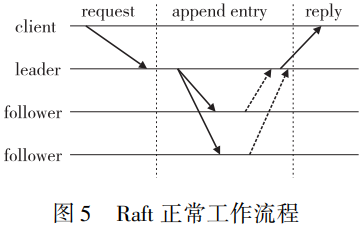
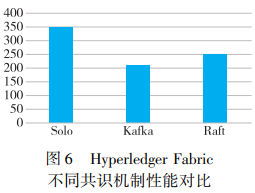
在非拜占庭场景下的许可链使用最多的共识算法就是Raft算法,这得益于Raft算法为数众多的实现。 据统计,Raft算法的各类实现数目近百种,这为构建基于Raft这一共识算法的许可链系统提供了良好的基础。 目前,在许可链的非拜占庭场景中 Raft占 据了统治性的地位,如摩根的Quorum也将Raft作为其所支持的两种共识机制之一。 IBM的 Hyperledger Fabric最初曾使用Kafka以实现分布式共识,在1.4版本实现了基于Raft的分布式共识并在2.0中废弃了Kafka。 Kafka本身是一个开源于2010年的较为成熟的分布式消息系统,支撑其实现分布式共识的是ZAB协议,在工业界有着较为普遍的应用。 但是 Kafka的设计场景是运行得比较紧密的主机集群,往往依赖于统一的组织管理运维,这一点与Hyperledger Fabric的使用场景有所不同, 一定程度上制约了Hyperledger Fabric的发展。 相较于使用Kafka实现分布式共识,Raft更加适用于较大规模的网络,维护及部署难度更低,并且展现了相 对于Kafka更好的性能。 针对Hyperledger Fabric在不同共识机制 下的性能对比如图所示。 选用Hyperledger Caliper中的marbles样例进行测试,其中Fabric版本为1.4.1,通过Docker部署到阿里云ecs.g 5.3xlarge平台。 总的来说,相较于拜占庭场景下的许可链,非拜占庭场景下的许可链参与节点之间信任程度更高,这类系统也往往拥有着更好的性能。
4.3.3Kafka
5对比
选择依据
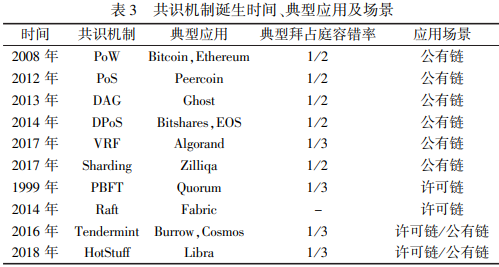
非许可链完全开放,需要抵御严重的拜占庭风险,多用PoX、BFT类协议并配合奖惩机制实现共识。许可链拥有准入控制,网络中节点身份可知,一定程度降低了拜占庭风险,可用BFT、CTF类协议构建。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |