

【机器学习】异常检测
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
前言
异常检测实际案例网络安全中的攻击检测金融交易欺诈检测疾病侦测和噪声数据过滤等。时间序列的异常又分为点异常和模式异常。

对于一个新观测值进行判断
- 离群点检测: 训练数据包含离群点,即远离其它内围点。离群点检测估计器会尝试拟合出训练数据中内围点聚集的区域, 会忽略有偏离的观测值。
- 新奇点检测: 训练数据未被离群点污染我们对新观测值是否为离群点感兴趣。在这个语境下离群点被认为是新奇点。
离群点检测 也被称之为 无监督异常检测; 而 新奇点检测 被称之为 半监督异常检测。 在离群点检测的语境下, 离群点/异常点 不能够形成一个稠密的聚类簇因为可用的估计器都假定了 离群点/异常点 位于低密度区域。相反的在新奇点检测的语境下新奇点/异常点 是可以形成 稠密聚类簇的只要它们在训练数据的一个低密度区域这被认为是正常的。
I. 传统机器学习
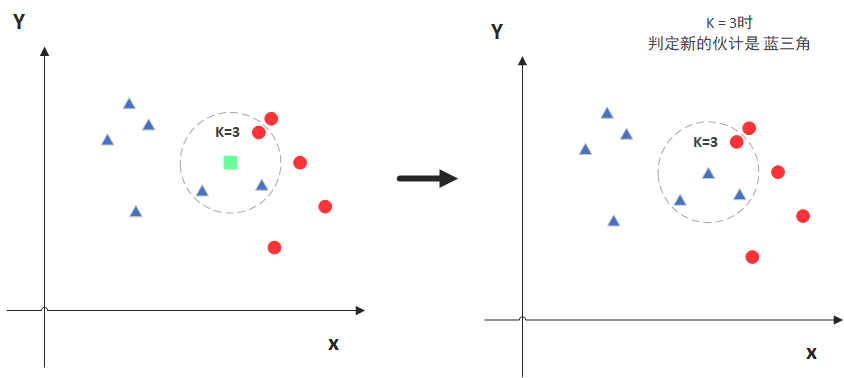
1. KNN算法
def KNeighborsClassifier(n_neighbors = 5,
weights='uniform',
algorithm = '',
leaf_size = '30',
p = 2,
metric = 'minkowski',
metric_params = None,
n_jobs = None
)
from sklearn.neighbors import KNeighborsClassifier2. LOF算法Local Outlier Factor
LOF算法计算出反映观测异常程度的得分称为局部离群因子。 它测量给定数据点相对于其邻近点的局部密度偏差。 算法思想是检测出具有比其邻近点明显更低密度的样本。
LOF 算法的优点是考虑到数据集的局部和全局属性即使在具有不同潜在密度的离群点数据集中它也能够表现得很好。 问题不在于样本是如何被分离的而是样本与周围近邻的分离程度有多大。
from sklearn.neighbors import LocalOutlierFactor
lof= LocalOutlierFactor(n_neighbors=2)
lof.fit_predict()
## 计算每个样本相反的异常值得分,越接近-1,LOF得分越高
outfactor = lof.negative_outlier_factor_
## 将得分标准化
radius = (outfactor.max() - outfactor) / (outfactor.max() - outfactor.min())
iris.plot(kind = "scatter",x= "SepalWidthCm",y = "PetalWidthCm",
c = "r",figsize = (10,6),label = "data")
plt.scatter(iris["SepalWidthCm"], iris["PetalWidthCm"], s =800 * radius,
edgecolors="k",facecolors="none", label="LOF得分")
3. COF 连通性离群因子
COF是LOF的变种相比于LOFCOF可以处理低密度下的异常值COF的局部密度是基于平均链式距离计算得到。
from pyod.models.cof import COF
cof = COF(contamination = 0.06, ## 异常值所占的比例
n_neighbors = 20, ## 近邻数量
)
cof_label = cof.fit_predict(iris.values)4. SOS算法 stochastic outlier selection algorithm
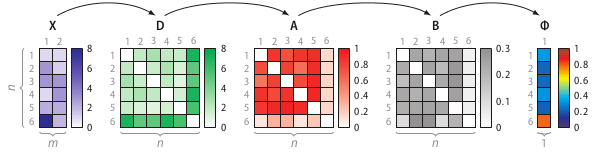
SOS算法是一种无监督的异常检测算法其将和其它所有点的关联度affinity很小的筛选出来
输入特征矩阵(feature martrix)或者相异度矩阵dissimilarity matrix
输出一个异常概率值向量每个点对应一个

SOS算法的整个流程
- 计算相异度矩阵D
- 计算关联度矩阵A
- 计算关联概率矩阵B
- 算出异常概率向量
pip install scikit-sos
>>> import pandas as pd
>>> from sksos import SOS
>>> iris = pd.read_csv("http://bit.ly/iris-csv")
>>> X = iris.drop("Name", axis=1).values
>>> detector = SOS()
>>> iris["score"] = detector.predict(X)
>>> iris.sort_values("score", ascending=False).head(10)
SepalLength SepalWidth PetalLength PetalWidth Name score
41 4.5 2.3 1.3 0.3 Iris-setosa 0.981898
106 4.9 2.5 4.5 1.7 Iris-virginica 0.964381
22 4.6 3.6 1.0 0.2 Iris-setosa 0.957945
134 6.1 2.6 5.6 1.4 Iris-virginica 0.897970
24 4.8 3.4 1.9 0.2 Iris-setosa 0.871733
114 5.8 2.8 5.1 2.4 Iris-virginica 0.831610
62 6.0 2.2 4.0 1.0 Iris-versicolor 0.821141
108 6.7 2.5 5.8 1.8 Iris-virginica 0.819842
44 5.1 3.8 1.9 0.4 Iris-setosa 0.773301
100 6.3 3.3 6.0 2.5 Iris-virginica 0.765657 https://github.com/jeroenjanssens/scikit-sos
https://github.com/jeroenjanssens/scikit-sos5. DBSCAN密度聚类
1eps DBSCAN算法参数即我们的ϵ-邻域的距离阈值和样本距离超过ϵ的样本点不在ϵ-邻域内。默认值是0.5.一般需要通过在多组值里面选择一个合适的阈值。eps过大则更多的点会落在核心对象的ϵ-邻域此时我们的类别数可能会减少 本来不应该是一类的样本也会被划为一类。反之则类别数可能会增大本来是一类的样本却被划分开。
2min_samples DBSCAN算法参数即样本点要成为核心对象所需要的ϵ-邻域的样本数阈值。默认值是5. 一般需要通过在多组值里面选择一个合适的阈值。通常和eps一起调参。在eps一定的情况下min_samples过大则核心对象会过少此时簇内部分本来是一类的样本可能会被标为噪音点类别数也会变多。反之min_samples过小的话则会产生大量的核心对象可能会导致类别数过少。
from sklearn.cluster import DBSCAN
y_pred = DBSCAN(eps=0.1, min_samples = 10).fit_predict(X)6. 孤立森林Isolation Forest
孤立森林是无监督异常检测算法。
孤立森林的基本原理异常样本相较普通样本可以通过较少次数的随机特征分割被孤立出来。
算法步骤每次取随机超平面对一个数据空间进行切割切一次可以生成两个子空间再继续随机选取超平面来切割第一步得到的两个子空间以此循环下去直到每子空间里面只包含一个数据点为止。


孤立森林的创新点包括以下四个
- Partial models在训练过程中每棵孤立树都是随机选取部分样本
- No distance or density measures不同于 KMeans、DBSCAN 等算法孤立森林不需要计算有关距离、密度的指标可大幅度提升速度减小系统开销
- Linear time complexity因为基于 ensemble所以有线性时间复杂度。通常树的数量越多算法越稳定
- Handle extremely large data size由于每棵树都是独立生成的因此可部署在大规模分布式系统上来加速运算。
from sklearn.ensemble import IsolationForest
df = pd.DataFrame({'salary':[4,1,4,5,3,6,2,5,6,2,5,7,1,8,12,33,4,7,6,7,8,55]})
model = IsolationForest(n_estimators=100,
max_samples='auto',
contamination=float(0.1),
max_features=1.0)
model.fit(df[['salary']])
# 预测 decision_function 可以得出 异常评分
df['scores'] = model.decision_function(df[['salary']])
# predict() 函数 可以得到模型是否异常的判断-1为异常1为正常
df['anomaly'] = model.predict(df[['salary']])
7. 基于核的一类One Class分类
7.1 OCSVM (One Class SVM)
ocsvm是半监督异常检测算法。
ocsvm基本原理如下其输入的数据只需要有正常数据及其标签即可在训练过程中ocsvm会学习正常观测值的决策边界svm中划分正负样本的超平面同时考虑一些离群值如果奇异值模型未见过的新数据点落在决策边界内则模型将其认为是正常的反之认为其是异常的。
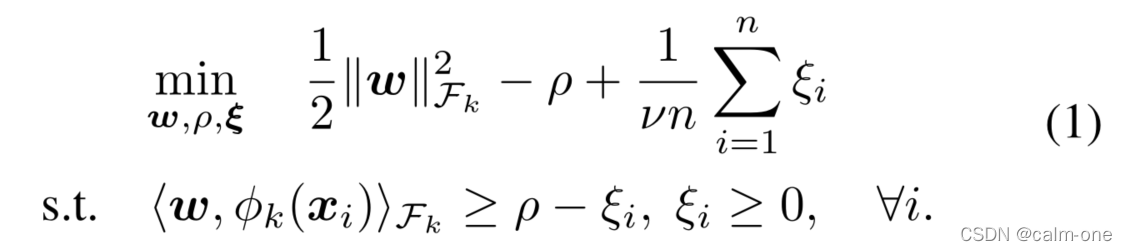
OC-SVM公式描述其中第一项是正则项第二项是超平面距离原点的距离(ρ)第三项中
是松弛变量允许部分错误数据
是学习到的超平面
是超参数以平衡学习到的目标限制条件是超平面
在希尔伯特空间中的点积大于平面到原点距离(减去一个松弛变量)
即异常数据
7.2 SVDD (support vector data description)
SVDD的基本思想是建立一个最小的超球体利用这个超球体去尽可能地包含所有的数据当要测试一个新的数据时我们只需要判断数据是在超球体内还是超球体外就可以实现分类了

SVDD原始问题描述这里第一项直接理解为最小化超球体体积即可第二项同样是使用到松弛变量用于平衡目标支持向量描述器(SVDD)是与OC-SVM相关的技术其使用的是超球体划分数据而不是超平面SVDD的目标是寻找最小的超球体(中心c半径R)包含大多数的数据。
即被认为是异常数据。
OC-SVM和SVDD是非常接近的两个问题都可以通过他们的对偶问题来解决即二次规划问题有很多方法比如序列最小化。在使用高斯核时这两类问题时等价的以及渐近一致的密度水平集估计问题。形成带有 ν \nu ν 的原始问题 ν \nu ν 一方面时离群点占比的上界一方面是支持向量占比的下界。这个结果被称为 ν \nu ν 属性它允许人们将关于训练数据中存在的异常值分数的先验信息纳入模型即允许训练数据存在异常。
除了实现显式特征工程上述方法的另一个缺点是由于内核的构造和操作它们的计算伸缩性较差除非使用某种近似技术否则基于内核的方法在样本数量上至少以二次方为单位。此外使用核方法进行预测需要存储支持向量这可能需要大量内存。
8. 自编码器Auto-Encoder
自编码器是一种无监督式学习模型。其将数据压缩后还原判断与原本相似程度。
- 优点泛化性强无监督不需要数据标注
- 缺点针对异常识别场景训练数据需要为正常数据。
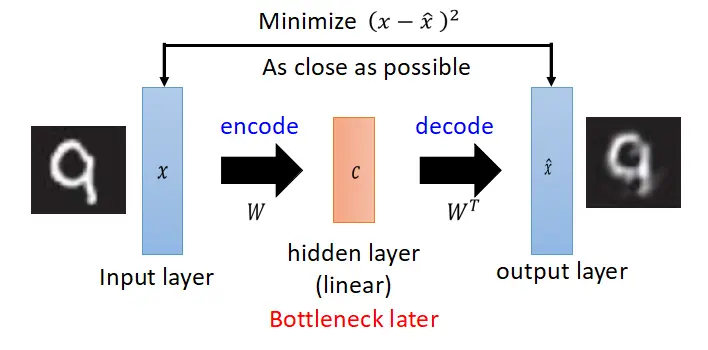
自编码器AutoEncoder解决异常检测问题_码猿小菜鸡的博客-CSDN博客_autoencoder异常检测
9. PCAprincipal components analysis
PCA 应用于异常检测大体上有两种套路1将原始数据映射到低维特征空间然后在低维空间里查看每一个点跟其他数据点的偏离程度2将原始数据映射到低维特征空间然后由低维特征空间重新映射回原空间尝试用低维特征重构原始数据看重构误差的大小。
10. DAGMM
DAGMM将AE自编码器和GMM高斯混合模型结合在一起的无监督异常检测模型
DAGMM基于这俩的套路自编码器中间隐藏层特征和最后的重构误差对于识别异常都是有用的。
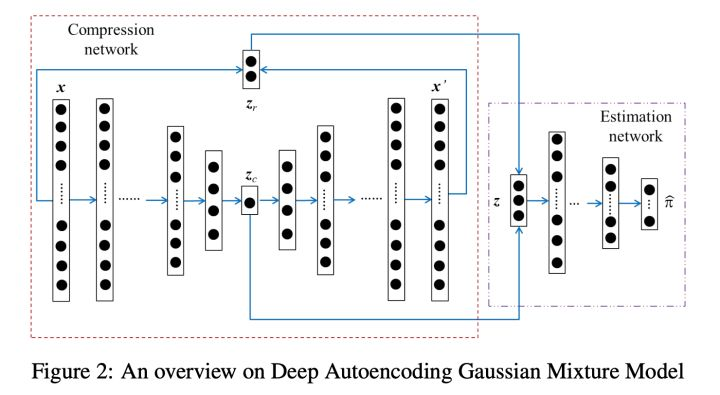
DAGMM构成
- Compression Network压缩网络: 学习高维输入的降维表示同时充分考虑到重建损失(reconstruction error)目的是为了防止降维造成的信息损失。关于重构误差文章中建议了两种方式来计算欧式距离和余弦相似度。
- Estimation Network估计网络: 结构上只是常规的多层神经网络但其实是 GMM高斯混合模型的“替代品”用于模拟 GMM 的结果。具体的假设 GMM 中 gaussian component 的个数为 k则估计网络的输出 p 经过 softmax 层可以得到样本分别归属 k 个 component 的概率。得到 N 个样本分别归属不同 component 的概率之后我们可以用来估计 GMM 的几个重要参数均值、方差、协方差矩阵。更新 GMM 的参数计算得到似然函数E(z)优化目标函数
- 在测试过程中可以通过模型计算E(z)的值我们希望值越小越好似然函数前添加了负号值越大越有可能异常我们可以根据训练集中的数据获得先验阈值来判断预测样本是否发生异常。
GitHub - tnakae/DAGMM: DAGMM Tensorflow implementation![]() https://github.com/tnakae/DAGMM
https://github.com/tnakae/DAGMM
import tensorflow as tf
from dagmm import DAGMM
# Initialize
model = DAGMM(
comp_hiddens=[32,16,2], comp_activation=tf.nn.tanh,
est_hiddens=[16.8], est_activation=tf.nn.tanh,
est_dropout_ratio=0.25
)
# Fit the training data to model
model.fit(x_train)
# Evaluate energies
# (the more the energy is, the more it is anomary)
energy = model.predict(x_test)
# Save fitted model to the directory
model.save("./fitted_model")
# Restore saved model from dicrectory
model.restore("./fitted_model")II. 时间序列异常检测

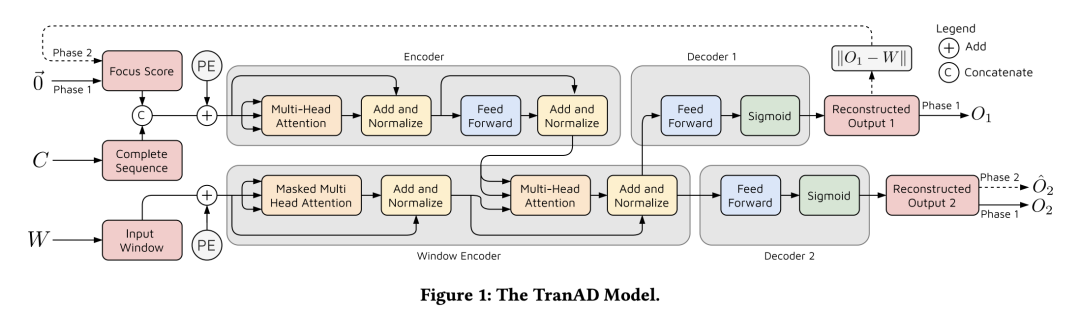
TranAD: tranformer+GAN2022
GitHub - imperial-qore/TranAD: [VLDB'22] Anomaly Detection using Transformers, self-conditioning and adversarial training. https://github.com/imperial-qore/tranad
https://github.com/imperial-qore/tranad
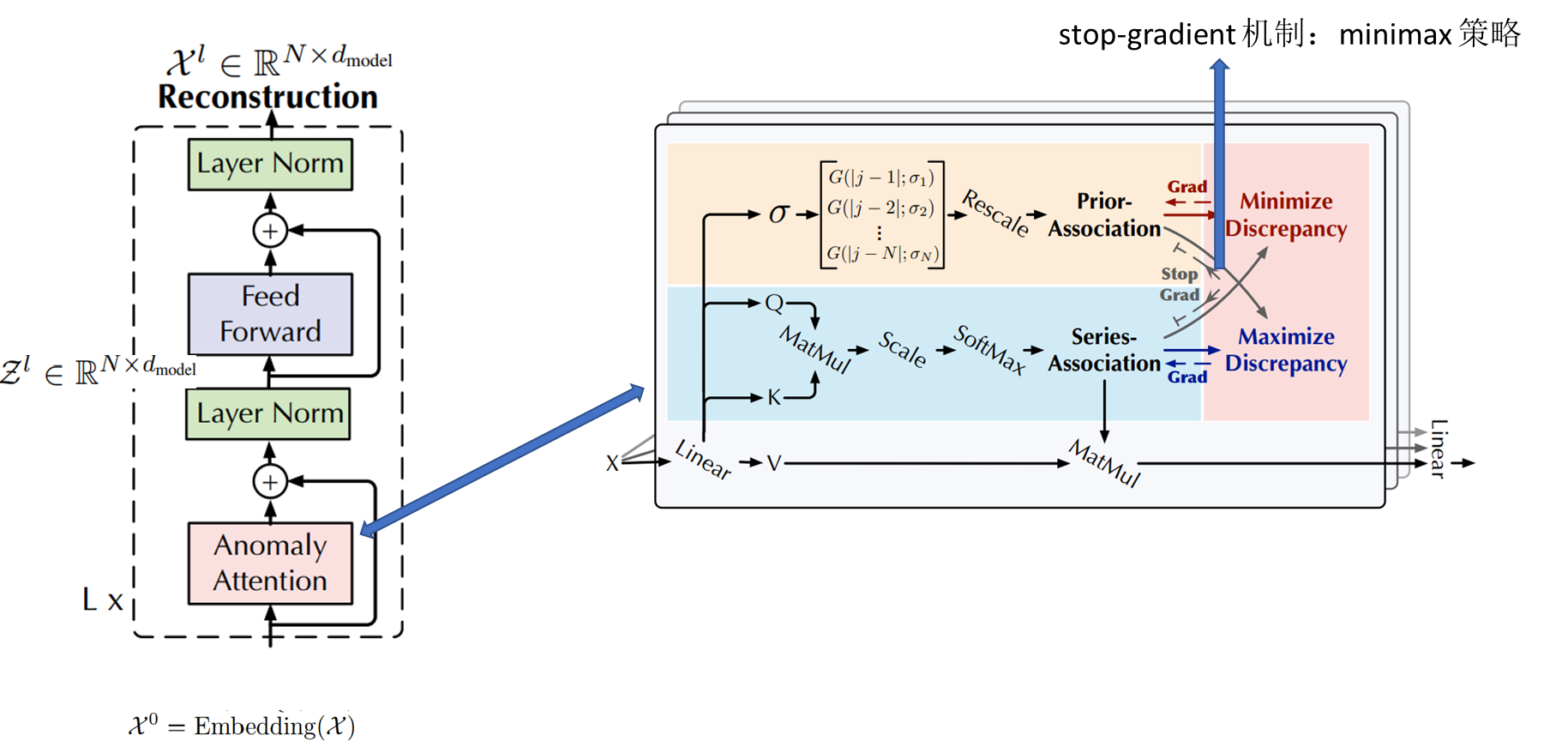
Anomaly-Transformer2022
提出动机
- 数据标注困难因此专注于无监督设置下的时间序列异常检测
- RNN重建或预测误差是逐点计算的不能提供对时间上下文的全面描述
- 向量自回归模型和状态空间模型很难学习信息表示和建模细粒度的关联。
- GNN局限于单个时间点对于复杂的时间模式来说不够
模型特点
- 先验关联prior-association邻接归纳的偏差可学习的高斯核来计算相对时间距离
- 序列关联 series-association序列之间的偏差关系
- 极大极小策略放大关联差异Association Discrepancy的 normal-abnormal 可分性
- 特殊设计的停止梯度机制(灰色箭头)以约束先验关联和序列关联获得更可区分的关联差异。
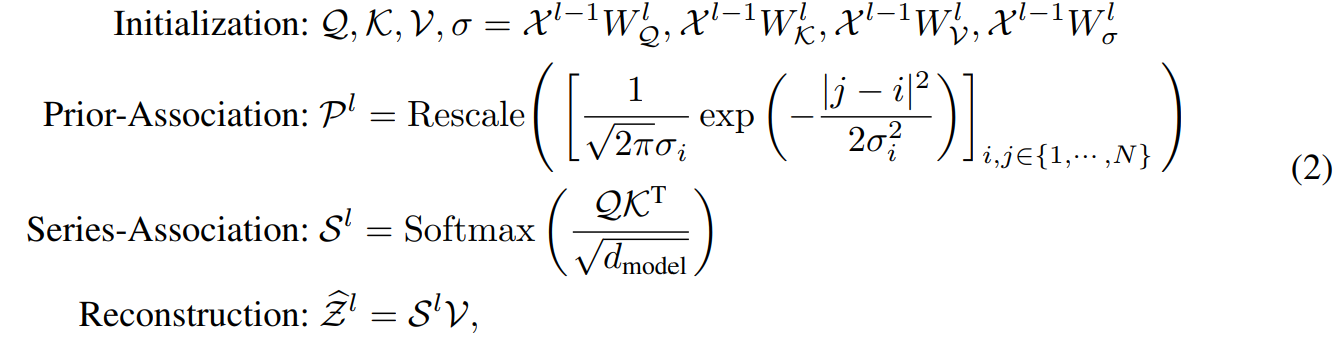
III. 图像异常检测
2021综述


2022综述
Deep Learning for Unsupervised Anomaly Localization in Industrial Images: A Survey
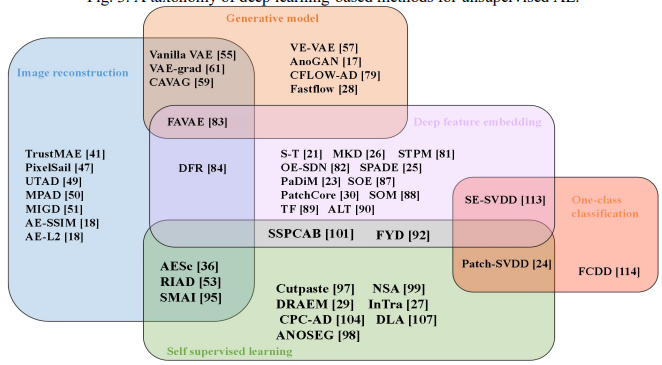
DSVDDDeep SVDD
One Class 一类分类器
主要思想基于核支持向量描述器与最小化体积寻找包含数据的最小超球体。
通过卷积神经网络学习从输入空间到输出空间的映射其中输出空间包含所有的一类样本数据目标就是在输出空间寻找最小的超球体包含所有的一类样本数据其中包含两个部分一个是网络参数的学习一个是超球体参数学习因此论文中提到联合学习(因为无法同时优化这两类参数)。
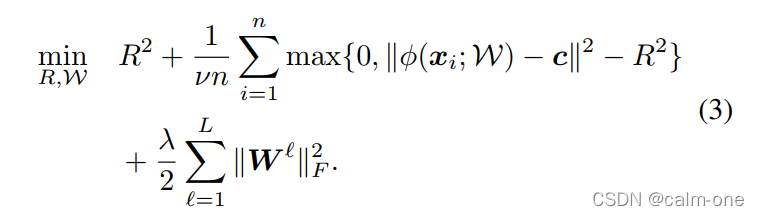
上式便是DSVDD的优化问题第一项是超球体体积表示第二项是样本到超球体中心的距离大于半径程度的衡量简单理解若样本在超球体外使得这一距离最小若样本在超球体内直接为0第三项是正则项防止参数学习过于复杂而造成过拟合。
DSVDD优化方案采用交替最小化/块坐标下降法交替优化网络参数和半径即训练k轮得到网络参数 W 时固定 R 在第k轮时使用最新的参数 W 计算半径。 R 可以通过简单的线性搜索得到解决。
【论文精读】一类分类器一—DSVDD_calm-one的博客-CSDN博客_一类分类器
Deep-SVDD论文研读 - 知乎 (zhihu.com)
代码
GitHub - nuclearboy95/Anomaly-Detection-Deep-SVDD-Tensorflow: Tensorflow Implementation of Deep SVDD
OC-GAN2019
PaDiM2020
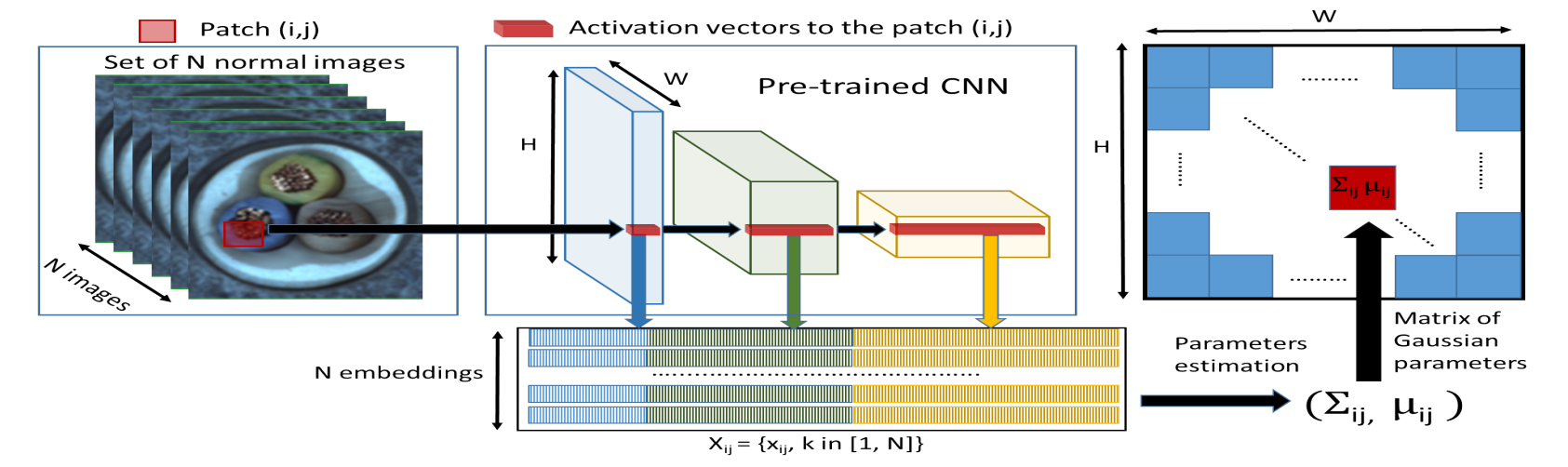
A Patch Distribution Modeling Framework for Anomaly Detection and Localization
PaDiM 通过特征提取搞出每张图的特征块再利用所有图的所有特征块为每个像素形成一个多维 高斯分布马氏距离作为评价分数。模型不需训练只使用训练好的网络提取特征。过程
- Embedding extraction补丁嵌入向量patch embedding vectors所谓补丁指的是像素所谓嵌入指的是将网络提取的不同特征组合到一块。都是封装的名词罢了。
由于生成的嵌入向量可能携带冗余信息使用随机选择来降低维数。作者使用PCA效果不好 - Learning of the normality图像的这些像素先验假设是多维的高斯分布所以网络要将这个分布搞出来通过求所有batch的每个像素均值和协方差实现。处理完成后每个像素位置上都有了一个多维的高斯分布。
这里的协方差公式除了是正宗的协方差外还在对角线上加了小操作添加一个正则项 0.01*单位矩阵使协方差矩阵能够满秩且可逆。协方差还使得不同维度的特征关联起来实验证明这种关联的信息有助于检测效果。 - Inference测试图与正常图分布的每个像素位置处计算马氏距离需要正常图形成的协方差矩阵的逆均值和异常特征图所有位置中得分最高的视为检测分数。
PatchCore2021
Towards Total Recall in Industrial Anomaly Detection 面向全召回的工业异常检测
PatchCore对SPADE,PaDiM等一系列基于图像Patch的无监督异常检测算法工作进行了扩展主要解决了SPADE测试速度太慢的问题并且在特征提取部分做了一些探索。
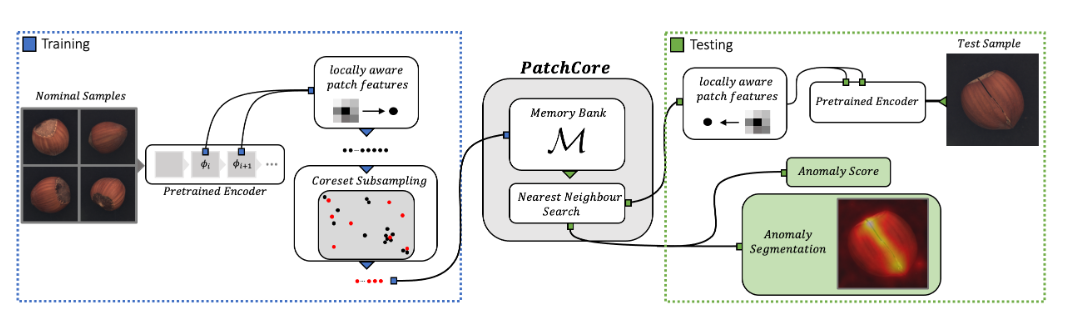
相比SPADE,PaDiMPatchCore 仅使用stage2、stage3的特征图进行建模通过增加窗口大小为3、步长为1、padding为1的平均池化AvgPool2d增大感受野后拼接使用KNN Greedy CoreSet 采样选取最具代表性的特征点选择与其他特征点最远的点以实现尽可能平衡的采样效果类似泊松圆盘,构建特征向量记忆池只保留1%~10%的特征数进而实现高效的特征筛选并用于异常检测。并提出采用了re-weighting策略计算Image-Level的异常得分代替此前的最大值异常得分。
- Locally aware patch features
- Coreset-reduced patch-feature memory bank
- Anomaly Detection with PatchCore
CFLOW-AD2021
Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows
CFLOW-AD基于条件归一化流框架由一个辨别性的预训练编码器和一个多尺度生成编码器组成。这种类型的AD任务也被叫做具有AD目标的分布外检测OOD任务。 CFLOW-AD不需要得知特征图的空间维度类似CNN选取特征维度低维信息可以使用K近邻和更先进的聚类方法完成。
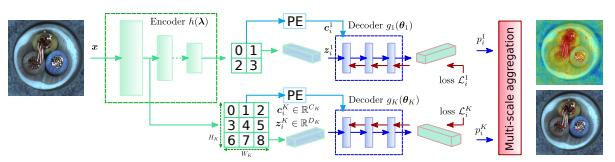
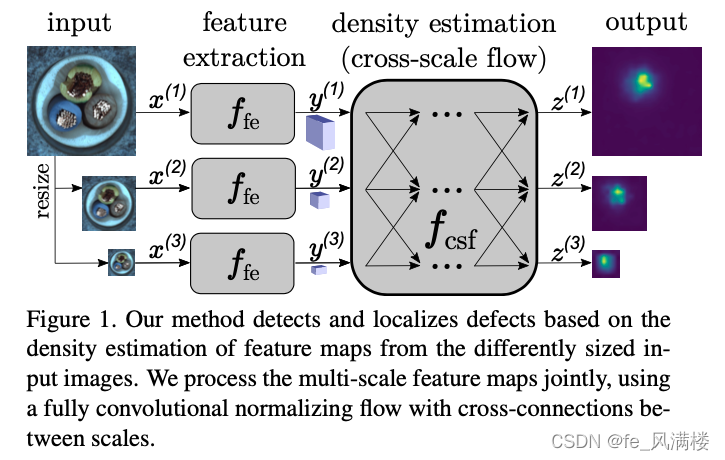
CS-Flow2021
fully convolutional cross-scale normalizing flow (CS-Flow) 模型是基于real-NVP的流模型
CS-Flow能同时处理不同尺度的特征图处理时将多种尺度的特征图并行传入流模型并且让它们之间相互作用。
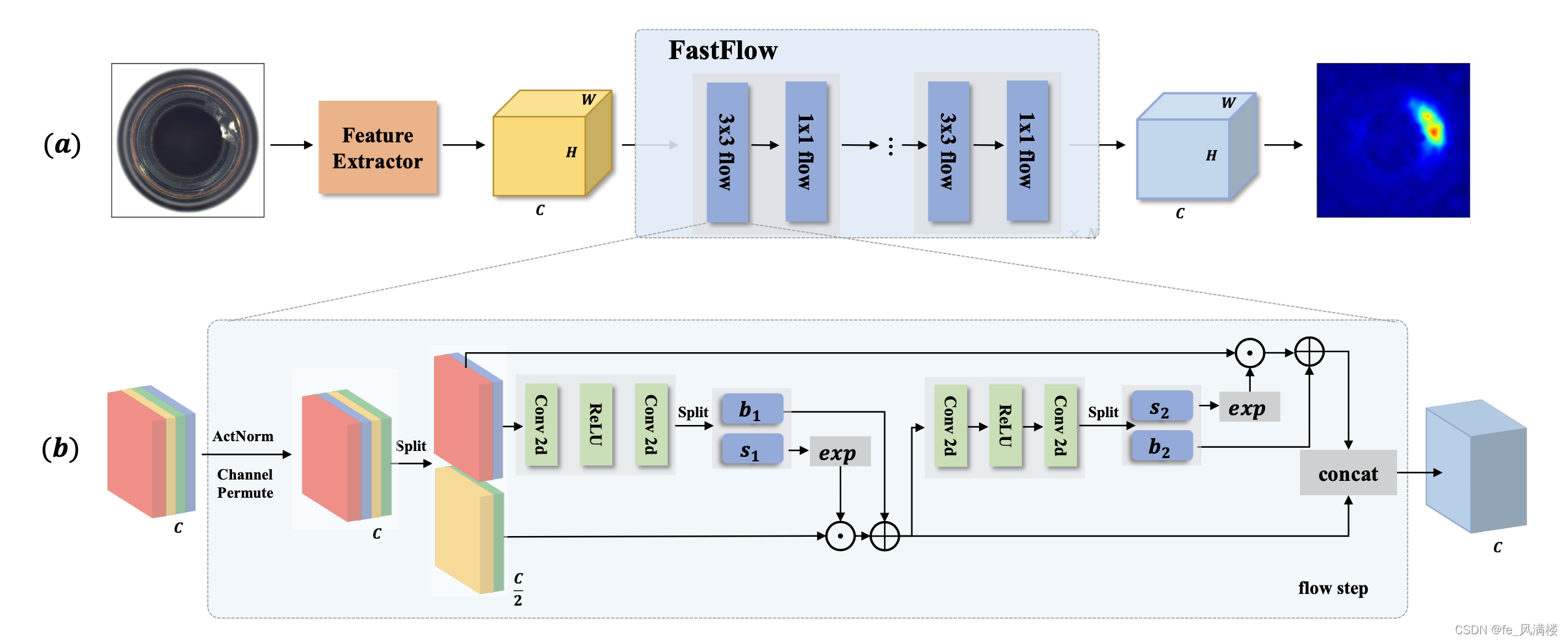
FastFlow2021
Unsupervised Anomaly Detection and Localization via 2D Normalizing Flows
Contributions
其他模型
- 当前的异常检测模型不能有效的将图像特征映射到一个明确的分布
- 当前模型忽略了局部特征和全局特征间的关系
- 传统flow模型需将2D特征压缩成1D进行概率估计损伤了内部的空间关系信息限制的flow的能力
- 传统flow模型使用sliding window method需在大量patch逐个检测异常复杂度高、推理速度受限
FastFlow模型
- 训练阶段学习将输入的特征映射到特定的分布
- 推理阶段利用似然去识别异常
- 2D的flow维持了原特征的空间位置关系提升了检测效率
- 端到端的推理整个图片直接输出异常检测和定位结果推理效率高
IV. 图数据异常检测
图模型可以对复杂的拓扑关系进行建模。因为其强大的表达能力图模型最近被广泛用于推荐系统生物制药等领域并在很多领域上都有对应的开源工具库推荐系统GNN-RecSys生物制药DGL-LifeSci。
作为数据挖掘中的经典问题异常检测技术在图数据上的应用也逐渐受到关注。其主要应用方向有虚假信息检测、金融欺诈检测系统安全监测等
PyGOD库
GitHub - pygod-team/pygod: A Python Library for Graph Outlier Detection (Anomaly Detection)![]() https://github.com/pygod-team/pygod图数据上的异常检测工具库集成了超过10个重要的图数据异常检测模型。
https://github.com/pygod-team/pygod图数据上的异常检测工具库集成了超过10个重要的图数据异常检测模型。
补充统计方法
绝对中位差Median Absolute Deviation, MAD
MAD是一种采用计算各观测值与平均值的距离总和的检测离群值的方法。

绝对中位差是一种统计离差的测量。而且MAD是一种鲁棒统计量比标准差更能适应数据集中的异常值。对于标准差使用的是数据到均值的距离平方所以大的偏差权重更大异常值对结果也会产生重要影响。对于MAD少量的异常值不会影响最终的结果。
由于MAD是一个比样本方差或者标准差更鲁棒的度量它对于不存在均值或者方差的分布效果更好比如柯西分布。
def c_except(x,thresh=3.5):
'''
使用绝对中位差消除异常
:return:
'''
if len(x)<=1:
return
me=np.median(x)
abs=np.absolute(x-me)
abs_me=np.median(abs)
score=norm.ppf(0.75)*abs/abs_me
return score<thresh
Pyod包
from pyod.models.mad import MAD
model = MAD().fit(data)
score = model.decision_function(data)Python集成库
Anomalib库

工业异常检测

支持模型包括
- PatchcoreSegmentation25M trainable params
- PadimSegmentation
- DFKDEClassification11.2M trainable params
- DFMClassification
- CFlowSegmentation265M
- GanomalyClassification188M trainable params
- STFPMSegmentation
- FastFlowSegmentation5.6M trainable params
- DREAM
- Reverse Distillation
链接🔗
Anomaly Detection | Papers With Code