

小知识·编码格式和转换方法
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
什么是编码格式
从一个小问题引入
我们在学习C语言的时候有一道必做的题目是将大写字母转换成小写相信有点基础的同学都能不加思索的写出下面的代码
chartoLower(char upper){
if (upper >= 'A' && upper <= 'Z'){
return upper + 32;
}else{
return upper;
}
} 要问为什么是这段代码我们往往也能说得出因为大小写字母在ASCII码上正好相差32(字符'a'为97 字符'A'为65)。
我们在进行字符初始化的时候往往会将字符初始化为'\0'。因为'\0'在ASCII码中对应的数值是0。
我们理所应当地知道char型字符对应的范围是0~127因为ASCII码的范围就是0~127。
但是有没有想过为什么是ASCII码
所谓的ASCII码又到底是什么
编码格式介绍
要说起ASCII码不得不说起编码格式。
我们知道对于计算机来说我们在屏幕上看到的千姿百态的文字、图片、甚至视频是不能直接识别的而是要通过某种方式转换为0和1组成的二进制的机器码最终被计算机识别0为低电平1为高电平。
对于数字来说有一套非常成熟的转换方案就是将十进制的数字转换为二进制就能直接被计算机识别如5转换为二进制是 0000 0101。但是对于像ABCD这样的英文字母还有!@#$这样的特殊符号计算机是不能直接识别的所以就需要有一套通用的标准来进行规范。
这套规范就是ASCII码。
ASCII码使用127个字符表示A~Z等26个大小写字母包含数字0~9所有标点符号以及特殊字符甚至还有不能在屏幕上直接看到的比如回车、换行、ESC等。

按照这套SACII的编码标准就很容易的知道'\0'代表的是0 'A'代表的是65而'a'代表的是97'A'和'a'之间正好相差了32。
ASCII码虽然只有127位但基本实现了对所有英文的支持。所以为什么说char类型只占1个字节因为char型最大的数字是127转成二进制也不过是0111 1111,只需要1个字节就能表示所有的char型字符因此char只占1个字节。
但是随着计算机的普及计算机不但要处理英文还有汉字、甚至希腊文字、韩文、日文等诸多文字这时127个字符肯定不够了这时就引入了Unicode的概念。
Unicode是一个编码字符集它基本涵盖了世界上绝大多数的文字只有极少数没有包含在Unicode中文对照表中可以查看一些汉字的Unicode字符集。
比如汉字”七“在Unicode表示为十六进制0x4e03表示成二进制位0100 1110 0000 0011占了15位至少需要两个字节才能放得下有些更复杂的生僻字可能占用的字节数甚至不止两位。
这就面临着一个问题当一个中英文夹杂的字符串输入到电脑的时候计算机是如何知道它到底是什么的
就像上面的0100 1110 0000 0011它到底是表示的是0100 1110和0000 0011两个ASCII字符还是汉字”七“计算机并不知道。所以就需要一套规则来告诉计算机到底该按照什么来解析。这些规则就是字符编码格式。
其中就包括以下几种。
ASCII
UTF-8
GBK
GB2312
GB18030
BIG5
ISO8859
编码格式分类
ASCII
ASCII 编码前面已经介绍过此处就不再多说了。它使用0~127这128位数字代表了所有的英文字母以及数字、标点、特殊符号和键盘上有但屏幕上看不见的特殊按键。
它的优点是仅用128个数字就实现了对英文的完美支持但是缺点也同样明显不支持中文等除英文以外的其他语言文字。
因此ASCII码基本可以看做是其他字符编码格式的一个子集其他字符编码都是在ASCII码的基础上实现了一定的扩展但毫无意外地都实现了对ASCII码的兼容。
UTF-8
在汉字环境下UTF-8可以说是最常见的编码。它是Windows系统默认的文本编码格式。
UTF-8是一种变长的编码方式最大可以支持到6位。这就意味着他可以有效地节省空间在后面介绍GBK的时候会讲GBK是固定长度的编码方式。
那么UTF8是如何知道当前所要表达的字符是几个字节呢
在UTF8中它以首字节的高位作为标识用来区别当前字节的长度。其规则大致如下
1字节 0xxxxxxx 范围0x00-0x7F
2字节 110xxxxx 10xxxxxx (范围0x80-0x7ff)
3字节 1110xxxx 10xxxxxx 10xxxxxx (范围0x800-0xffff)
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (范围0x10000-0x10ffff)
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
如上面的汉字”七“的unicode码是0x4e03在0x800-0xffff区间所以是3字节用UTF-8表示就是11100100 10111000 10000011(十六进制表示为0xe4b883)。
"七"的Unicode码是0100 1110 0000 0011可为什么是这个数呢
根据3字节的填充规则从右往左依次填充x的位置
0100 111000 000011
+
1110xxxx 10xxxxxx 10xxxxxx
=
11100100 10111000 10000011
事实上utf-8编码下汉字都为3字节。
实际上UTF家族除了UTF-8外还有UTF-16、UTF-32等由于不太常用此处也就不展开讨论了。
GBK/GB2312/GB18030
GB就是”国标“的拼音开头顾名思义以GB开头的编码都是中国人专门为支持汉语而设计的编码格式。但这三者又有区别最早出现的是GB2312它收录了6763个汉字基本满足了计算机对汉字的处理需要。
GB2312使用双字节表示一个汉字。对汉字进行分区处理。每个区含有94个汉字或符号这种表示方式称之为区位码。
01-09 区为特殊符号。
16-55 区为一级汉字按拼音排序。
56-87 区为二级汉字按部首/笔画排序。
10-15 区及 88-94 区则未有编码。
GB2312编码范围A1A1-FEFE其中汉字编码范围B0A1-F7FE。表示汉字时第一字节0xB0-0xF7对应区号16-87第二个字节0xA1-0xFE对应位号01-94。
GBK是在GB2312基础上的扩展。GBK的K就是扩展的”扩“的拼音首字母。因此GBK向下兼容GB2312。
GBK也使用双字节表示汉字其中首字节范围0x81-0xfe第二个字节范围0x40-0xfe剔除0x7F一条线。因此GBK所能表示的汉字比GB2312要多得多能表示21886个汉字。
GB18030是最新的内码字集可以表示70244个汉字。它与UTF-8类似采用多字节编码每个汉字由1、2、4个字节组成。
单字节其值从 0 到 0x7F与 ASCII 编码兼容。
双字节第一个字节的值从 0x81 到 0xFE第二个字节的值从 0x40 到 0xFE不包括0x7F与 GBK 标准兼容。
四字节第一个字节的值从 0x81 到 0xFE第二个字节的值从 0x30 到 0x39第三个字节从0x81 到 0xFE第四个字节从 0x30 到 0x39。
如果你看到这个地方已经觉得很乱了不要紧。我们只需要知道在GB打头的编码格式下我们能够用键盘敲出来的你在电脑上所看见的所有汉字都是双字节的四字节的汉字极少只有一些极少数不常用的生僻字用到。
BIG5
BIG5从字面翻译来看叫做”大五码“它主要用来表示中文繁体字。
它也是用双字节表示一个汉字其中高位字节使用了0x81-0xFE低位字节使用了0x40-0x7E及0xA1-0xFE。。
这种编码格式用的比较少此处就不展开说了。
汉字编码
上面介绍的几种编码格式UTF-8、GBK等都支持汉字但是标准不同因此在实际进行开发的过程中对汉字的处理也不尽相同。
如何判断汉字编码
无论是UTF-8、GBK还是GB18030或者BIG5它都是向下兼容ASCII的为了区分ASCII码和汉字在汉字的高位补1。
这也就是说如果我们以int的形式取出单个字符的值汉字都是小于0的。
因此判断是否是汉字也就变得简单了
enumboolean{true, false};
typedefint boolean;
boolean isChinese(char ch){
return (ch < 0) ? true : false;
}
写一段代码验证一下
voidtest01(){
char str[20];
memset(str, 0, sizeof(str));
strcpy(str, "hello汉字");
for (int i = 0; i < strlen(str); i++){
if (isChinese(str[i]) == true){
printf("str[%d]: Chinese\n", i);
}else{
printf("str[%d]: English\n", i);
}
}
}我们在main函数里调用test01函数得到如下结果
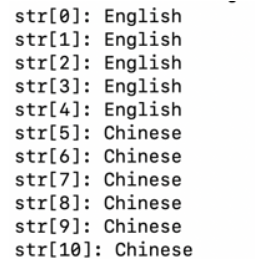
因为在utf-8下一个汉字占3字节所以后面从5~10这6个字节正好代表着2个汉字。
如果我们把编码改成GB2312运行可以得到如下结果

可以看到只有最后4个字节是汉字充分说明了GB2312编码格式下一个汉字占2个字节。
如何处理汉字截断问题
如果我们把上面的字符串按字符打印出来得到下面的结果
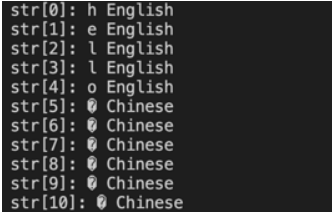
可以看到所有的汉字都乱码了原因就在于UTF-8编码下每个汉字占3个字节一个字节不足以表示完整的汉字所以打印出来都是乱码的。
在实际开发中比较常见的需要处理的问题是截取一定长度的字符串但是如果截取的位置正好是个汉字难免会遇到汉字被截断的问题。
那么这类问题如何处理呢
根据汉字的编码规则我们知道UTF-8和GBK对汉字的处理是不一样的。
UFT-8一个汉字是3字节且规则如下
1110xxxx 10xxxxxx 10xxxxxx
所以我们很容易知道汉字的首字节范围为11100000~11101111,转成十六进制为0xe0~0xef第二、三字节的范围为10000000~10111111转成十六进制范围为0x80~0xbf。
所以UTF-8的汉字截断问题处理可以如下
void HalfChinese_UTF8(constchar*input, size_tinput_len, char*output, size_t*output_len)
{
char current = *(input + input_len);
if (isChinese(current) == false)
{
*output_len = input_len;
strncpy(output, input, *output_len);
return;
}
//汉字
*output_len = input_len;
//1110xxxx 10xxxxxx 10xxxxxx//第二位和第三位的范围是10000000~10ffffff转成十六进制是0x80~0xbf在这个范围内都说明是汉字被截断while ((current&0xff) < 0xc0 && (current&0xff) >= 0x80)
{
(*output_len)++;
current = *(input + *output_len);
}
strncpy(output, input, *output_len);
}该函数有四个参数其中input和input_len作为原始输入input_len代表需要截取的位置output和output_len作为输出output为截断处理后的字符串output_len为截断处理后的长度。
我们使用下面的代码进行测试
voidtest02()
{
charin[20], out[20];
memset(in, 0, sizeof(in));
memset(out, 0, sizeof(out));
strcpy(in, "hello汉字");
size_t out_len = 0;
for (int i = 1; i <= strlen(in); i++)
{
HalfChinese_UTF8(in, i, out, &out_len);
printf("out: %s\n", out);
}
}运行后结果如下
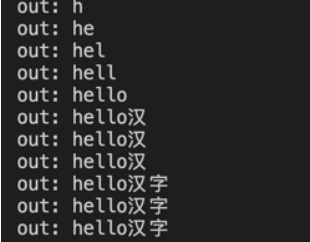
如果是GBK编码要稍微麻烦一点。因为我们知道GBK是双字节表示汉字且第一个字节的值从 0x81 到 0xFE第二个字节的值从 0x40 到 0xFE不包括0x7F单从字符的值无法判断到底是汉字的首字节还是后一个字节因为二者的值有重复部分。
如果字符串纯为汉字倒还好办我们已经知道汉字占2个字节直接根据长度的奇偶来判断就可以但如果是中英文夹杂就不能采用这种方式了。
在这里我使用的是先对字符串进行一道过滤处理判断字符串中除掉英文字符后纯汉字的长度如果为奇数代表汉字被截断加1就能取其完整的汉字如果是偶数说明正好是一个完整的汉字无需处理直接返回即可。
代码实现如下
void HalfChinese_GBK(constchar*input, size_tinput_len, char*output, size_t*output_len){
char current = *(input + input_len);
if (isChinese(current) == false)
{
*output_len = input_len;
strncpy(output, input, *output_len);
return;
}
*output_len = input_len;
if (MoveEnglish(input, input_len) %2 != 0){
(*output_len)++;
}
strncpy(output, input, *output_len);
}
intMoveEnglish(constchar*input, size_tinput_len){
int out_len = input_len;
for (int i = 0; i < input_len; i++)
{
if (isChinese(input[i]) == false){
out_len++;
}
}
return (out_len > 0) ? out_len : 0;
}同样使用上面的测试代码进行测试得到如下结果

如何实现编码之间互相转换
既然编码格式这么多那么怎么进行编码之间的转换呢
在C语言下主要是利用系统的iconv函数完成。
iconv函数包含在头文件iconv.h中其函数原型如下所示
size_t iconv (iconv_t __cd, char **__restrict__inbuf,
size_t *__restrict__inbytesleft,
char **__restrict__outbuf,
size_t *__restrict__outbytesleft);第一个参数是转换的一个句柄由iconv_open函数创建第二个参数是输入的字符串第三个参数是输入字符串的长度第四个参数是转换后的输出字符串第五个参数是输出字符串的长度。在编码转换完成之后需要调用iconv_close函数关闭句柄。所以完整的调用顺序为
iconv_open打开iconv句柄
调用iconv进行编码转换
iconv_close关闭句柄
还有一点需要注意的是__inbytesleft和__outbytesleft的长度因为不同编码对于汉字的处理字节数不同比如从UTF-8转换为GBK同样都是两个汉字转换前长度为6转换后长度为4。也就是说在编码转换过程中字符串可能会变长或缩短如果长度不正确很容易造成越界从而导致错误。
完整的编码转换功能封装如下
booleanconvert_encoding(char *in, size_t in_len, char *out, size_t out_len, constchar *from, constchar *to){
if (strcasecmp(from, to) == 0){
size_t len = (in_len < out_len) ? in_len : out_len;
memcpy(out, in, len);
returntrue;
}
iconv_t cd = iconv_open(from, to);
if (cd == (iconv_t)-1){
printf("iconvopen err\n");
returnfalse;
}
size_t inbytesleft = in_len;
size_t outbytesleft = out_len;
char *src = in;
char *dst = out;
size_t nconv;
nconv = iconv(cd, &src, &inbytesleft, &dst, &outbytesleft);
if (nconv == (size_t)-1){
if (errno == EINVAL){
printf("EINVAL\n");
} else {
printf("error:%d\n", errno);
}
}
iconv_close(cd);
returntrue;
}注意由于使用到了libiconv编译时需要加-liconv进行链接。
测试代码如下
voidtest04()
{
charin[20], out[20];
memset(in, 0, sizeof(in));
memset(out, 0, sizeof(out));
strcpy(in, "hello汉字world");
if (false == convert_encoding(in, strlen(in), out, 20, "utf-8", "gbk")){
printf("failed\n");
return;
}
printf("in: %s\nout:%s\n", in, out);
}以上代码运行结果如下所示

将GBK转换为UTF-8也是同样的操作此处就不做演示了。