

论文阅读:LOGO-Former: Local-Global Spatio-Temporal Transformer for DFER(ICASSP2023)-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
本篇论文 LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition发表在ICASSP声学顶会代码暂未开源。
摘要
以前的动态面部表情识别DFER方法主要基于卷积神经网络CNN其局部操作忽略了视频中的长程依赖性。基于Transformer的DFER方法可以实现更好的性能但会导致更高的FLOPs和计算成本。为了解决这些问题局部-全局时空TransformerLOGO-Former被提出来捕获每个帧内的区别性特征并在平衡复杂度的同时建模帧之间的上下文关系。基于面部肌肉局部运动和面部表情逐渐变化的先验知识我们首先将空间注意力和时间注意力限制在一个局部窗口内以捕获特征标记之间的局部交互。此外我们执行的全局注意力通过查询一个token的功能从每个局部窗口迭代获得整个视频序列的长距离信息。此外我们提出了紧凑的损失正则化项以进一步鼓励学习的特征具有最小的类内距离和最大的类间距离。在两个野外动态面部表情数据集上的实验即DFEW和FERV 39 K的结果表明我们的方法提供了一种有效的方法来利用空间和时间的依赖性DFER。
动机与贡献
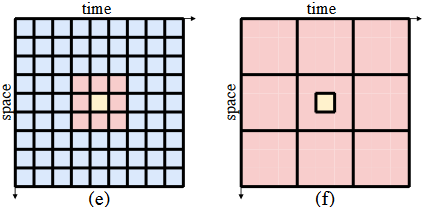
下面是几种不同时空自注意方案
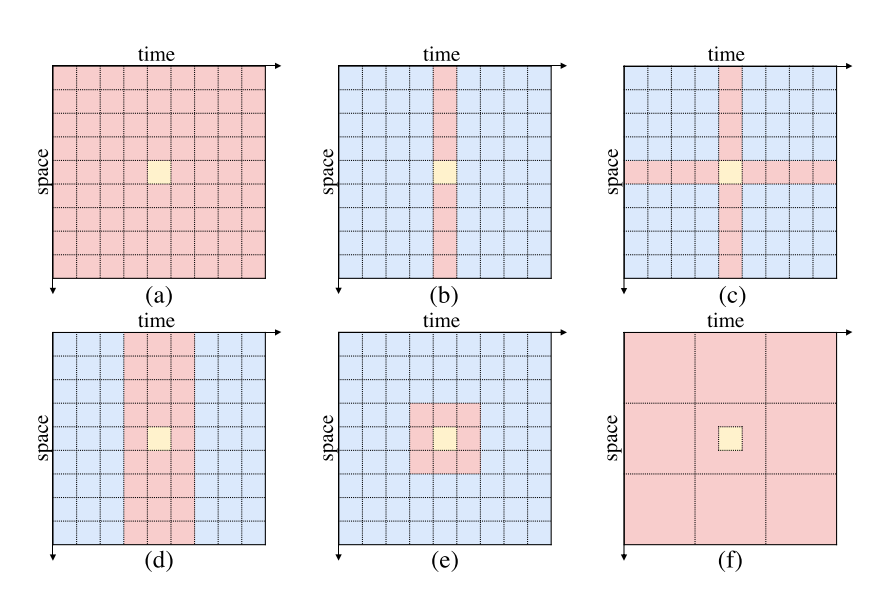
不同时空自我注意方案的可视化。为了更好地说明我们用浅黄色表示query token用玫瑰色表示key token用浅蓝色表示非注意token。
a全局时空注意力
O
T
2
S
2
OT^2S^2
OT2S2
b仅空间注意力
O
T
S
2
OTS^2
OTS2
c时空分割注意力
O
T
S
2
+
T
2
S
OTS^2+T^2S
OTS2+T2S
d时空混合注意力
O
T
S
2
OTS^2
OTS2
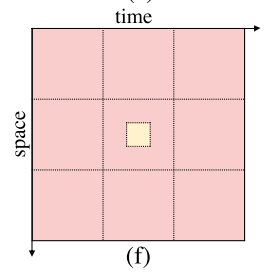
ef本文采用的局部和全局时空的注意力机制
不同的面部肌肉在局部面部区域内运动并且面部表情在视频中的相邻帧内逐渐改变。我们的目标是利用视频中的时空信息同时最大限度地减少tranformer的计算成本以实现高效的动态面部表情识别。
- 为了实现这一点本文提出了局部-全局时空TransformerLOGO-Former用于捕获短期和长期依赖关系同时降低transformer的计算成本。我们计算非重叠窗口内的自我注意力以捕捉token之间的局部交互。
- 这样的局部时空注意力无法捕捉全局信息。因此利用全局时空注意力使query token关注窗口级的 key token如上如f所示
- 为了进一步提高模型的鉴别能力我们提出了紧凑损失正则化项来减少类内距离和增加类间距离。定量结果和可视化结果表明我们的方法在野外动态面部表情识别的有效性。
具体方法
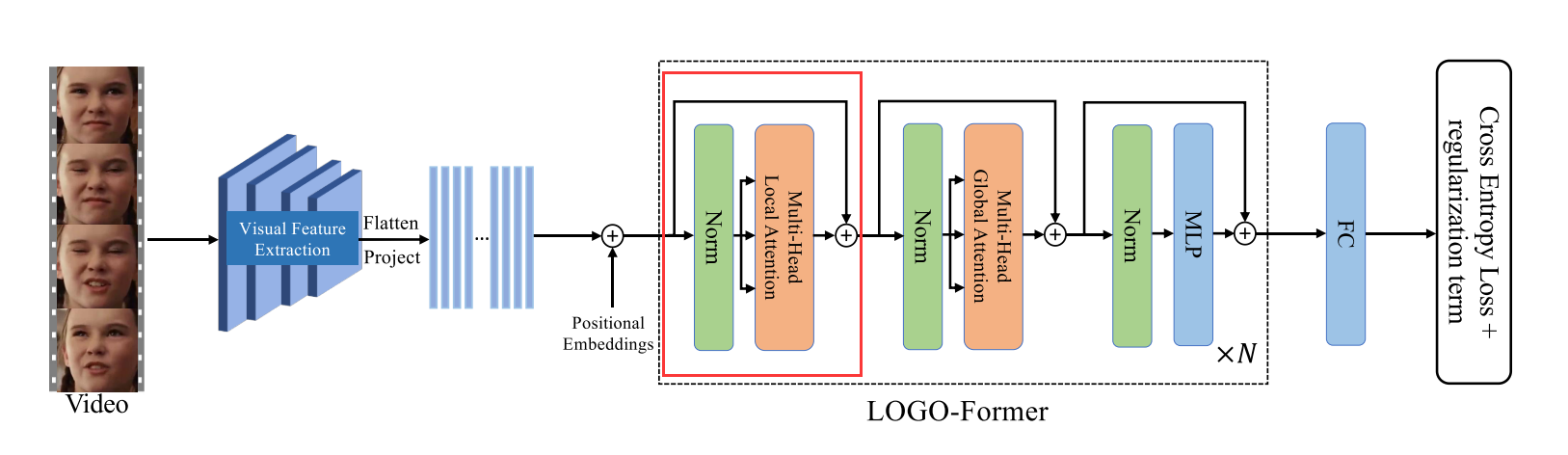
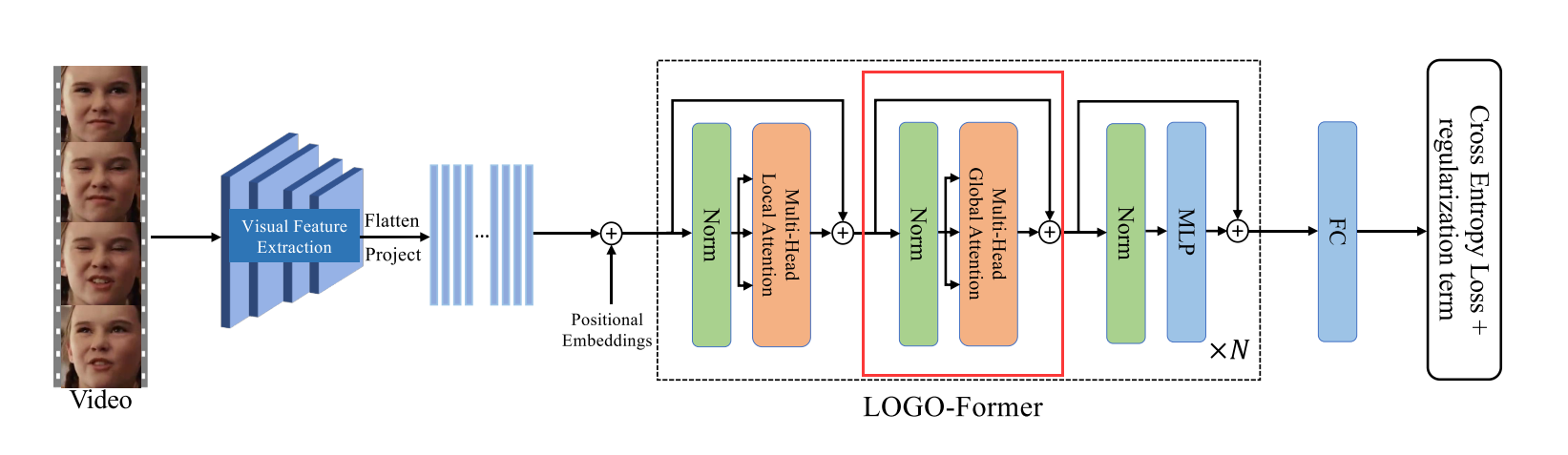
整体架构
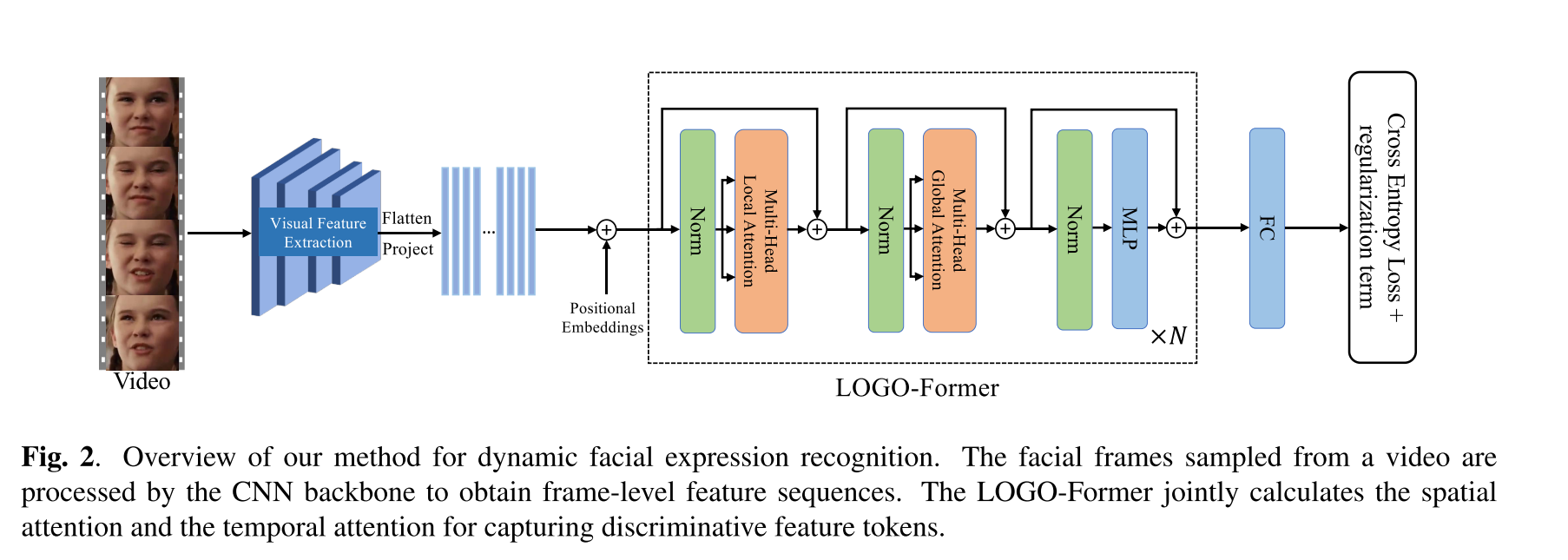
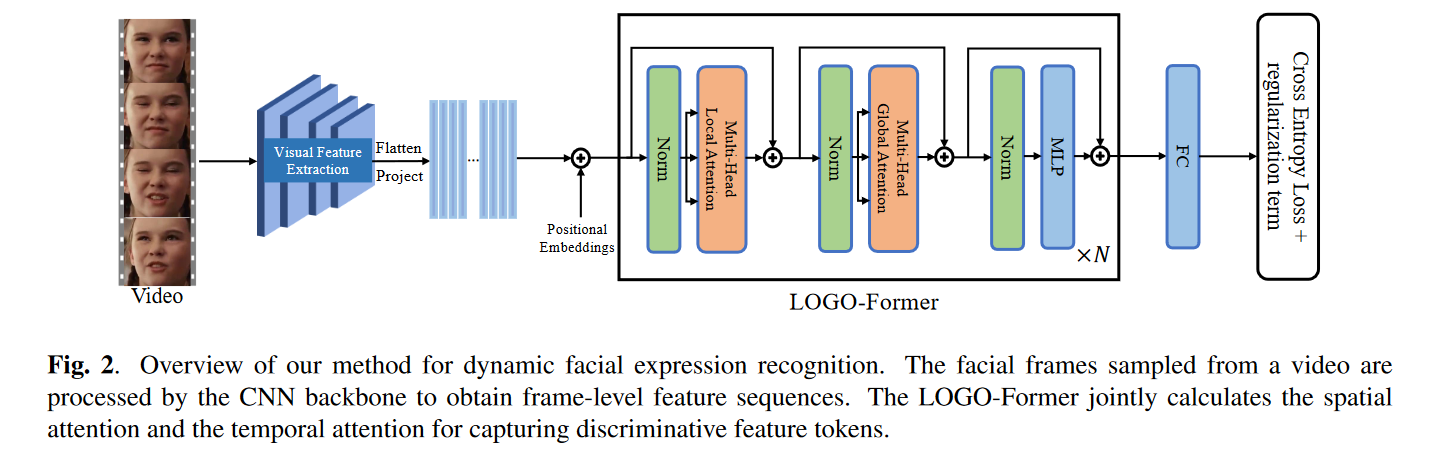
从视频中采样的人脸帧被CNN主干处理以获得帧级别的特征序列。LOGO-FORM通过联合计算空间关注度和时间关注度来获取区分特征标记。
输入嵌入生成
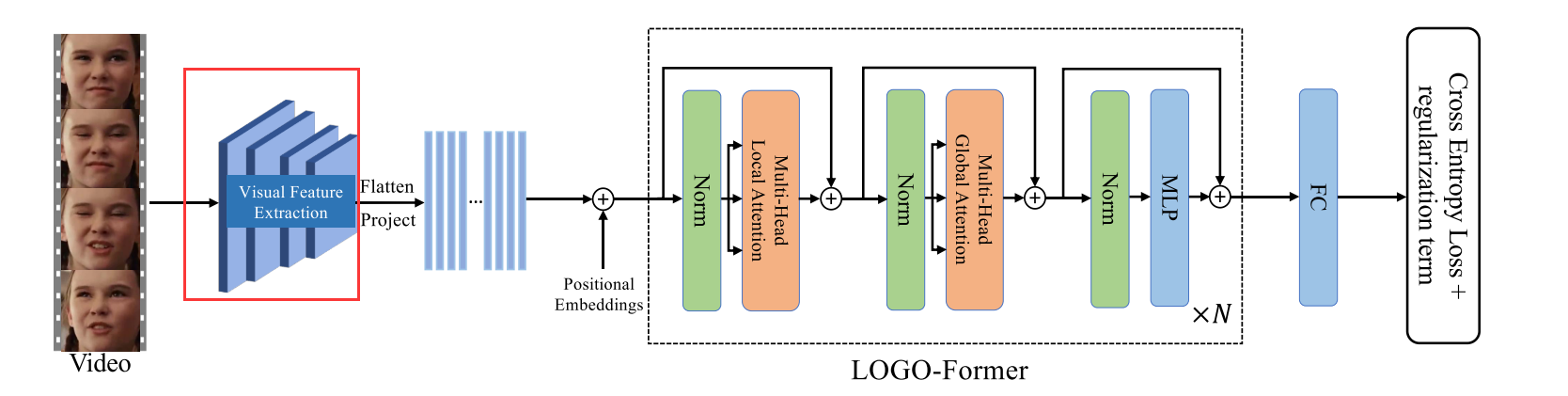
给定一个图像序列 X ∈ R F × H 0 × W 0 × 3 X ∈ R^{F× H _0 × W _0 ×3} X∈RF×H0×W0×3其中 F F F个RGB人脸帧大小为 H 0 × W 0 H _0 × W _0 H0×W0从视频中采样我们利用CNN骨干提取帧级特征。标准CNN主干ResNet 18用于为每帧生成大小为 H × W H ×W H×W的高级特征图。片段特征 f 0 ∈ R F × H × W × C f_0 ∈ R^{F×H×W×C} f0∈RF×H×W×C是通过连接所有帧级特征图来获得的。
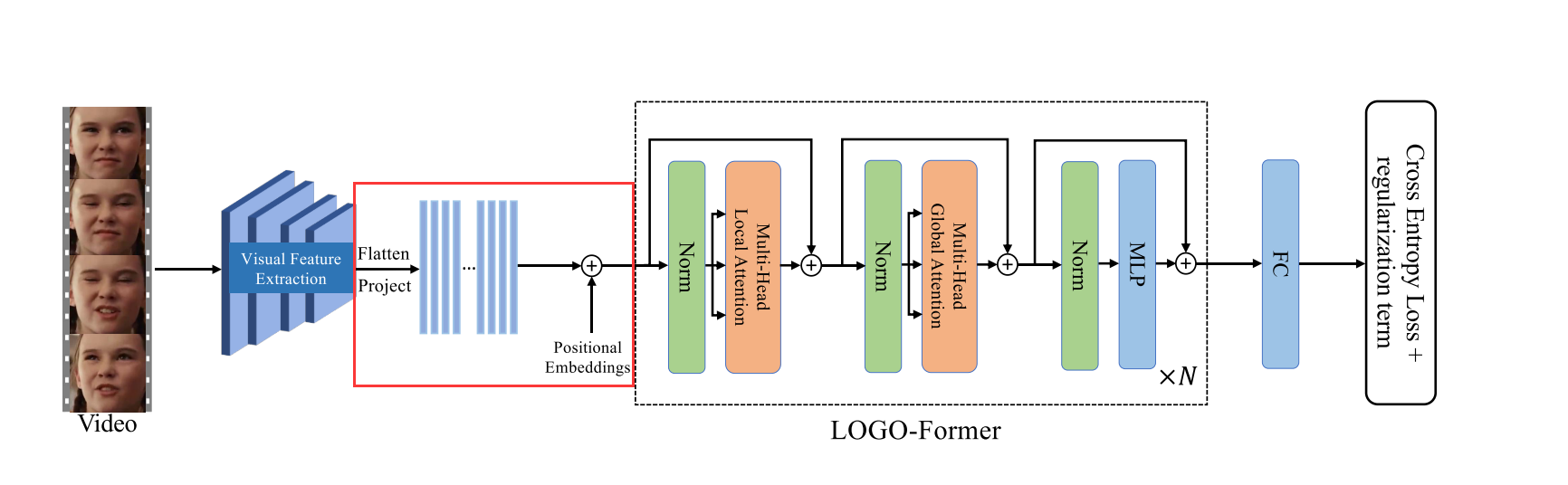
随后我们将片段特征 f 0 f_0 f0的空间维度平坦化并通过1 × 1卷积将它们投影从而产生新的特征序列 f 1 ∈ R F × H × W × d f1 ∈ R^{F×H×W×d} f1∈RF×H×W×d。
注意 f 1 f_1 f1的时间顺序与输入 X X X的时间顺序一致。为了补充特征序列的时空位置信息我们将可学习的位置嵌入与 f 1 f_1 f1结合起来。我们还在时间维度上将分类标记 [ C L S ] [CLS] [CLS]前置到序列中该标记对序列的全局状态进行建模并进一步用于识别。类似地还添加了时间位置嵌入。最后获得时空Transformer的输入嵌入X0。
LOGO-Former
LOGO-Former由 N N N个分块组成每个分块由多头局部注意力和多头全局注意力组成迭代学习上下文和区分性时空特征表示。
多头局部注意力
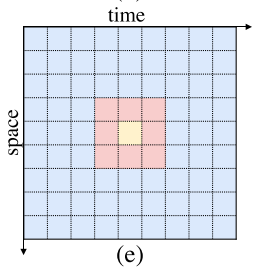
以
F
×
H
×
W
F ×H ×W
F×H×W的输入特征图为了简单起见我们在这里省略了
[
C
L
S
]
[CLS]
[CLS]标记作为输入我们将其均匀地分成几个大小为
f
×
h
w
f × hw
f×hw的窗口从而得到
F
f
×
H
W
h
w
\frac{F}{ f} × \frac{HW} {hw}
fF×hwHW窗口如上图所示。我们在一个窗口
i
j
ij
ij内将这些token平坦化可以表示为
X
i
j
∈
R
f
h
w
×
d
X_{ij} ∈ R^{fhw×d}
Xij∈Rfhw×d。第
k
k
k个块的多头局部注意力公式化为
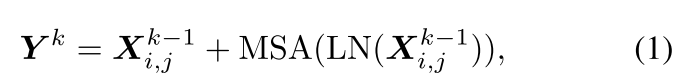
时间复杂度如下
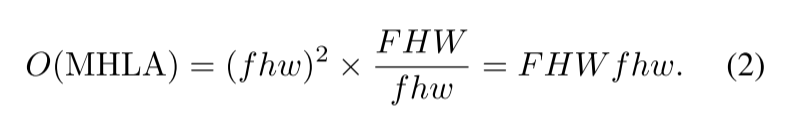
多头全局注意力
我们应用卷积运算来分离和合并特征图划分为非重叠区域其中每个区域是特征图的时空抽象。每个区域用于将全局上下文信息传递给每个查询标记。多头全局注意力被公式化为
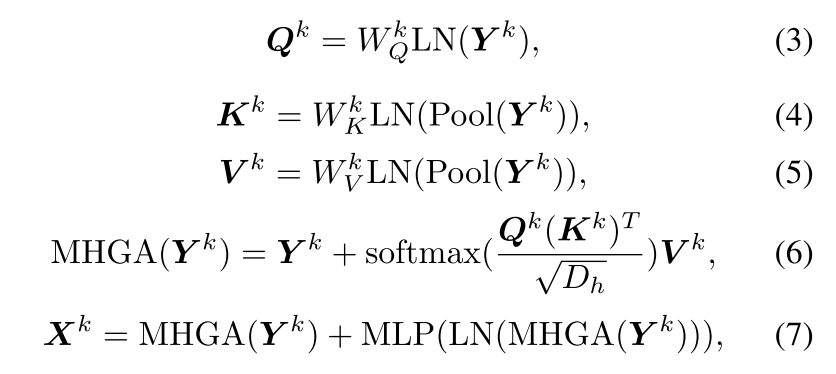
不失一般性假设我们将特征映射
Y
k
Y_k
Yk池化成
F
W
H
f
w
h
\frac{FWH} {fwh}
fwhFWH个token我们的多头全局注意力的复杂度为
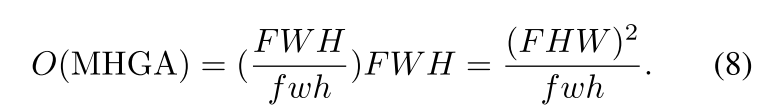
因此我们的LOGOFormer的整个注意力复杂度可以计算为
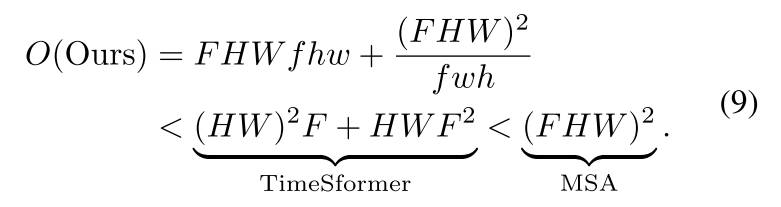
最后我们将单个全连接FC层应用于最后一个块的分类token
X
0
0
N
X^N_{00}
X00N
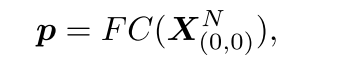
紧凑损失正则化
进阶详解KL散度https://zhuanlan.zhihu.com/p/372835186
学习判别性的时空特征在野外DFER要求损失函数具有最大化不同类别之间的特征距离的能力。为了实现这一点我们建议使用对称Kullback-LeiblerKL散度
D
u
∣
∣
p
+
D
p
∣
∣
u
{Du||p+ Dp|| u}
Du∣∣p+Dp∣∣u来测量分布
u
u
u和
p
p
p之间的差异并对预测分布
p
p
p施加约束其中
u
u
u是
C
−
1
C − 1
C−1上的均匀分布
p
p
p是预测分布但不包括相应目标
y
y
y的概率。
u
由
u由
u由softmax函数计算
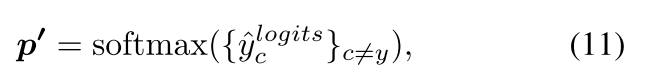
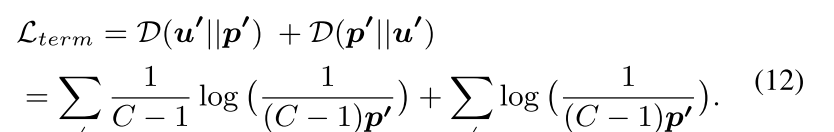
实验
我们使用两个野外DFER数据集即DFEW和FERV 39 K来评估我们提出的方法。对于DFEW和FERV 39 K经处理的面部区域图像被正式检测、对齐并公开提供。我们的模型在DFEW和FERV 39 K上使用两个NVIDIA GTX 1080Ti GPU卡进行了100次训练批量为32。初始学习率为0.001的SGD优化器和锐度感知最小化用于优化我们提出的模型。我们使用MSCeleb-1 M 上预训练的ResNet 18作为CNN骨干。时空Transformer层的数量N和头的数量分别经验地分配为4和8。未加权平均召回率UAR和加权平均召回率WAR作为评价指标。
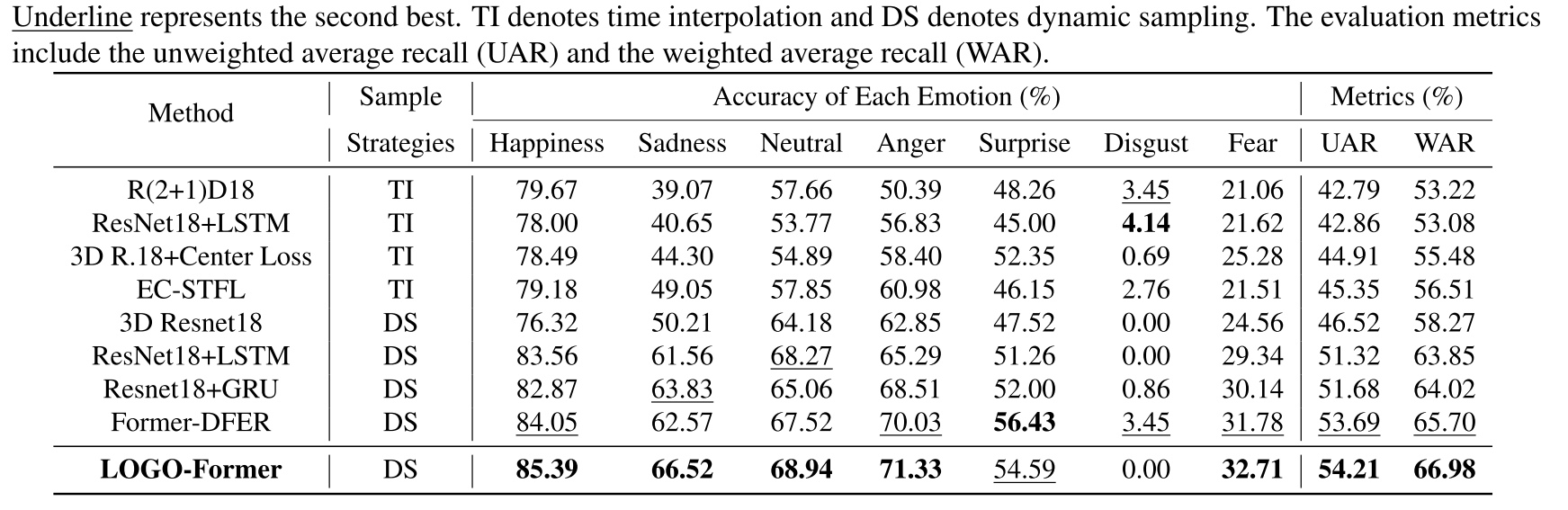
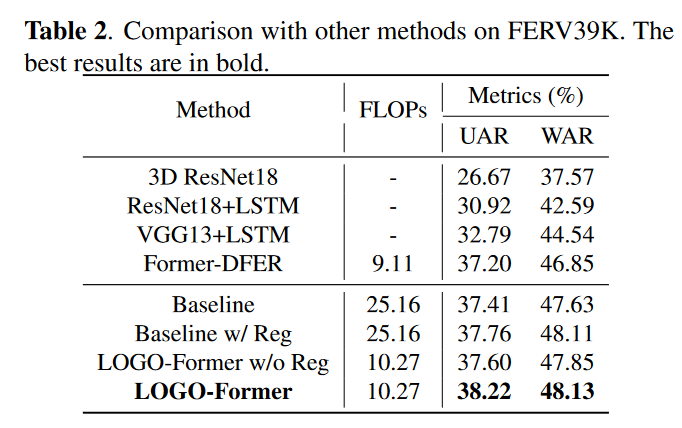
从上表中可以发现加入正则项之后对模型的性能有显著的提升我们提出的新方法在降低计算量的情况下还能有较好的模型性能。

通过可视化也可以发现加入紧凑正则项之后使得学习到的特征具有更好的聚合效果在不同表情之间表现出更清晰的类间边界。
思考
本篇文章设计的思路与MAE-DFER: Efficient Masked Autoencoder for Self-supervised Dynamic Facial Expression Recognition有一定的相似之处。
在MAE-DFER中LGI - Former是组成编码器的核心模块LGI - Former的核心思想是在局部区域引入一组具有代表性的小标记。一方面这些标记负责汇总局部区域的关键信息。另一方面它们允许对不同区域之间的长距离依赖关系进行建模并实现有效的局部-全局信息交换。
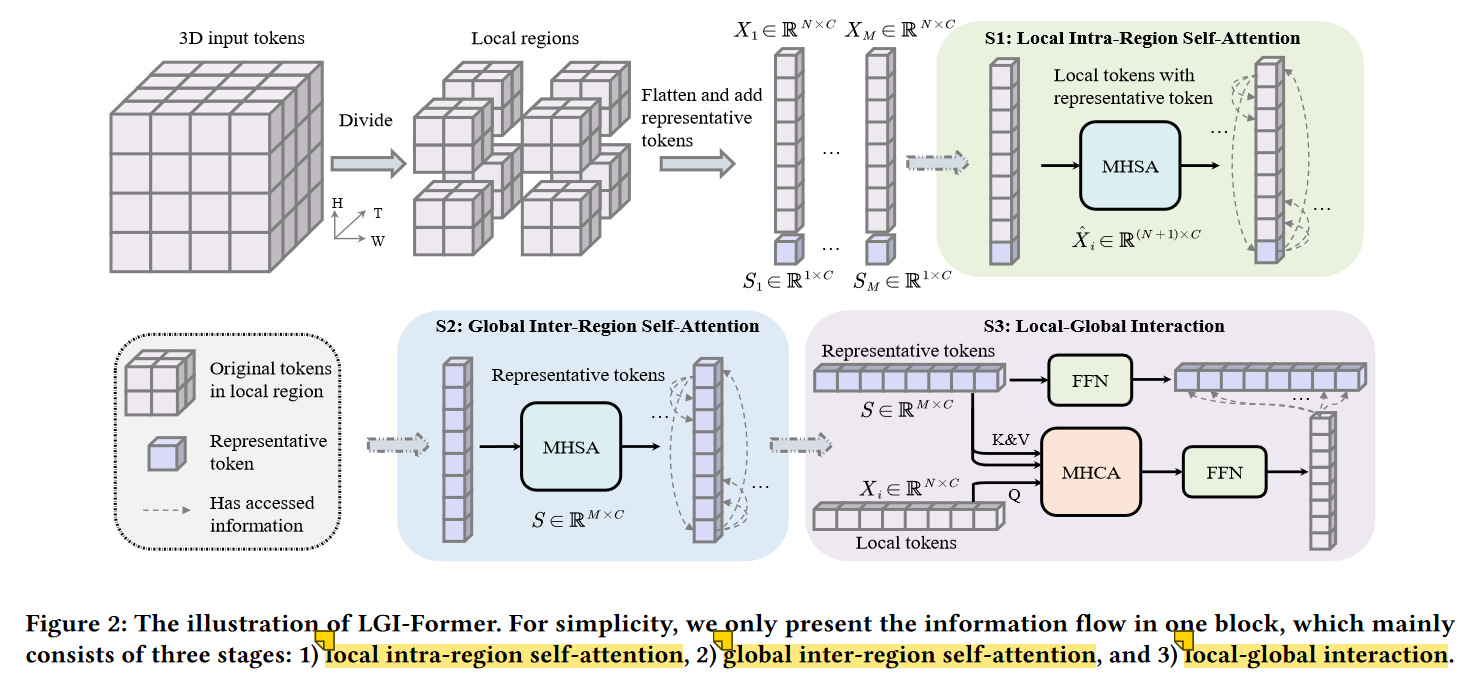
本文设计的 LOGO-Former和上文的LGI - Former有异曲同工之妙 LOGO-Former的多头局部注意力和LGI - Former中的Local Intra-Regin Self-Attention基本完全相同。
LOGO-Former的多头全局注意力模块应用卷积操作来分离和池化特征图每个区域用于向每个query key传递全局上下文信息。这一操作对应着LGI - Former中的global inter-region self-attention和local-global interaction。
总结
在本文中我们提出了一个简单而有效的局部-全局TransformerLOGO-Former和紧凑的损失正则化项在野生动态面部表情识别DFER。我们联合应用每个块内的局部注意力和全局注意力来迭代地学习时空表示。为了进一步提高模型的判别能力我们通过紧凑的损失正则化项对预测分布施加约束以增强类内相关性并增加类间距离。实验结果和可视化结果表明我们的方法学习的歧视性时空特征表示并提高了分类边缘。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |