

OpenPCDet安装、使用方式及自定义数据集训练
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
OpenPCDet安装、使用方式及自定义数据集训练
OpenPCDet安装
# 先根据自己的cuda版本安装对应的spconv
pip install spconv-cu113
# 下载OpenPCDet并安装
git clone https://github.com/open-mmlab/OpenPCDet.git
cd OpenPCDet
pip install -r requirements.txt
python setup.py develop
# 安装open3d可视化工具推荐
pip install open3d
# 可选安装mayavi可视化工具
pip install vtk
pip install mayavi
pip install PyQt5
安装完就可以运行demo.py测试一下。需要准备好模型和数据文件
python demo.py --cfg_file cfgs/kitti_models/pv_rcnn.yaml --ckpt pv_rcnn_8369.pth --data_path ../data/kitti/testing/velodyne/000001.bin
如果出现SharedArray相关的错误的话可以适当的降低其版本。例如pip install -U SharedArray==3.1
注意demo.py运行成功需要在具有显示设备的条件下如果只有终端的话是无法运行成功的。
KITTI数据集训练
首先需要准备KITTI数据集为了快速训练演示选取100个数据进行训练。将数据集按照以下目录格式存放。
OpenPCDet
├── data
│ ├── kitti
│ │ │── ImageSets
│ │ │── training
│ │ │ ├──calib & velodyne & label_2 & image_2 & (optional: planes) & (optional: depth_2)
│ │ │── testing
│ │ │ ├──calib & velodyne & image_2
├── pcdet
├── tools
ImageSets中存在train.txt val.txt test.txt文本其内容为训练、验证和测试使用的数据。
运行下面的代码以生成infos生成的文件可在data/kitti找到。
python -m pcdet.datasets.kitti.kitti_dataset create_kitti_infos tools/cfgs/dataset_configs/kitti_dataset.yaml
openPCDet的可训练网络配置KITTI数据集存放在cfgs/kitti_models目录下。以pv_rcnn训练为例由于本次没有使用planes数据将pv_rcnn.yaml中的USE_ROAD_PLANE改成False。之后在tools目录下运行下面代码即可进行训练。
python train.py --cfg_file cfgs/kitti_models/pv_rcnn.yaml --batch_size 1 --workers 1 --epochs 10
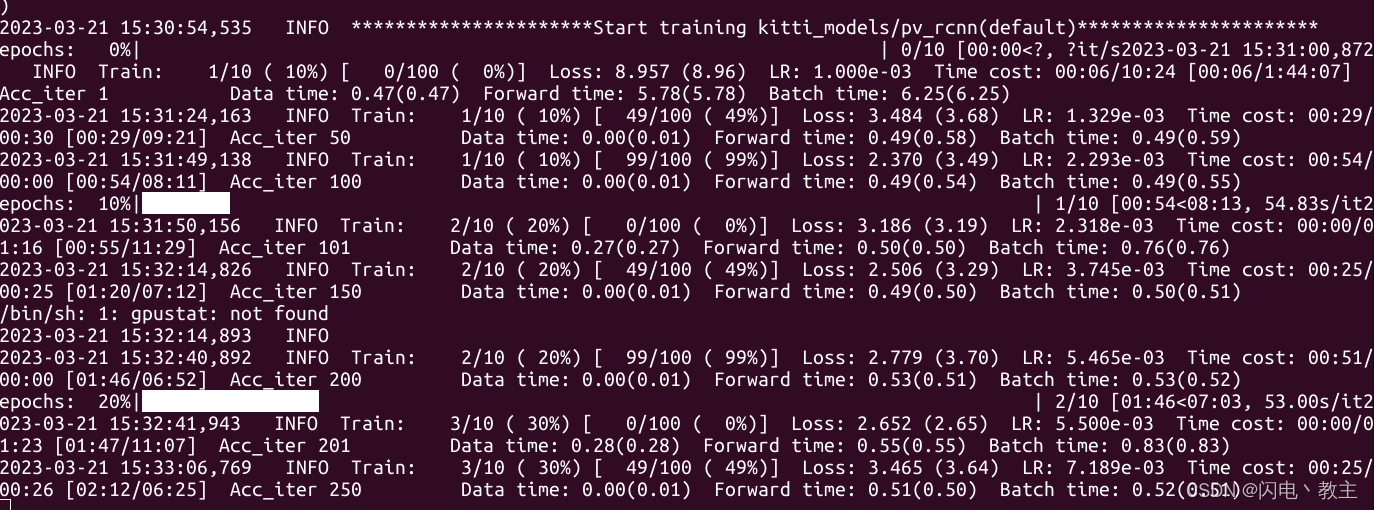
训练结束后可以在output/kitti_models目录中找到模型文件。
训练注意事项—train.py以KITTI数据集为例
-
如果不指定具体的ckpttrain.py中会默认加载最新的ckpt。换句话说如果上一次训练pv_rcnn网络的epochs为5得到了5个ckpt下一次训练pv_rcnn的时候没有指定ckpt且epochs值小于等于5那么就不会进入训练而是直接进入eval。如果本次epochs为大于5的值则会接着epochs=5的ckpt训练。
# trian.py中的相关代码 # 如果ckpt不为None的话就加载该ckpt并从指定ckpt的epoch开始训练 if args.ckpt is not None: it, start_epoch = model.load_params_with_optimizer(args.ckpt, to_cpu=dist_train, optimizer=optimizer, logger=logger) last_epoch = start_epoch + 1 else: # 如果为None的话会默认加载最新的ckpt ckpt_list = glob.glob(str(ckpt_dir / '*.pth')) if len(ckpt_list) > 0: # 按时间进行排序 ckpt_list.sort(key=os.path.getmtime) while len(ckpt_list) > 0: try: it, start_epoch = model.load_params_with_optimizer( ckpt_list[-1], to_cpu=dist_train, optimizer=optimizer, logger=logger ) last_epoch = start_epoch + 1 break except: ckpt_list = ckpt_list[:-1] -
max_ckpt_save_num参数代表最大保存ckpt的数量。如果当前ckpt的数量多于最大保存ckpt数量那么会删除几个时间最早的ckpt。默认为30.
# train_utils.py中的相关代码 ckpt_list = glob.glob(str(ckpt_save_dir / 'checkpoint_epoch_*.pth')) ckpt_list.sort(key=os.path.getmtime) # 如果当前ckpt的数量多于最大保存ckpt数量那么会删除几个时间最早的ckpt if ckpt_list.__len__() >= max_ckpt_save_num: for cur_file_idx in range(0, len(ckpt_list) - max_ckpt_save_num + 1): os.remove(ckpt_list[cur_file_idx]) -
ckpt_save_time_interval参数代表每隔{ckpt_save_time_interval}秒保存一次ckpt。默认为300
-
train.py中的eval使用的数据集是kitti_dataset.yaml中的test值。默认配置下kitti_dataset.yaml中test值为val如下面代码所示
# kitti_dataset.yaml """ 总得来说在训练的时候'train'和'test'分别对应训练集和验证集在测试的时候'test'对应测试集。 所以需要根据训练和测试任务更换test的配置。 """ # 需要加载的文件名称默认为train.txt val.txt DATA_SPLIT: { 'train': train, 'test': val } # 需要加载的pkl文件 可以设置多个 INFO_PATH: { 'train': [kitti_infos_train.pkl], 'test': [kitti_infos_val.pkl], }
如果想要修改val数据集就需要修改DATA_SPLIT和INFO_PATH中的test值。
-
num_epochs_to_eval参数代表只评估最后{num_epochs_to_eval}个epoch。比如当num_epochs_to_eval为1的时候总epochs为5那么只会评估后面4个epoch。默认为0也就是每个epoch都评估。
-
build_dataloader函数中
# 使用变量 dataset_cfg.DATASET 中指定的数据集类型创建一个数据集对象 dataset # 如果dataset_cfg.DATASET为KittiDataset那么返回的dataset为kitti_dataset.py中的KittiDataset类型 dataset = __all__[dataset_cfg.DATASET]( dataset_cfg=dataset_cfg, class_names=class_names, root_path=root_path, training=training, logger=logger, ) -
cfg_from_yaml_file函数将网络yaml和数据集yaml合并在一起如果存在相同的key则用网络yaml相应的val替换。因此如果网络yaml和数据集yaml中存在相同类型的配置比如数据增强那么最终训练使用的配置是网络yaml中的配置。实现这部分的相关代码可以在config.py中找到。
测试注意事项—test.py以KITTI数据集为例
-
运行test.py使用的测试数据集可以在kitti_dataset.yaml中的DATA_SPLIT和INFO_PATH找到相关配置。其中它加载的测试数据集是INFO_PATH中的test值这个值是一个列表里面可以填多个.pkl文件这部分的加载代码可以在kitti_dataset.py的include_kitti_data函数中找到DATA_SPLIT中的test值默认为val表示加载val.txt。
所以说如果想要修改测试数据集就需要修改DATA_SPLIT和INFO_PATH中的test值。
# kitti_dataset.yaml """ 总得来说在训练的时候'train'和'test'分别对应训练集和验证集在测试的时候'test'对应测试集。 所以需要根据训练和测试任务更换test的配置。 """ # 需要加载的文件名称默认为train.txt val.txt DATA_SPLIT: { 'train': train, 'test': val } # 需要加载的pkl文件 可以设置多个 INFO_PATH: { 'train': [kitti_infos_train.pkl], 'test': [kitti_infos_val.pkl], }
demo.py和open3d_vis_utils.py分析以KITTI数据集为例
-
使用Demo.py时如果传入数据集参数时文件夹则会获取文件夹所有符合后缀条件.bin/.npy的文件。
-
模型预测结果pred_dicts是一个列表列表元素为字典字典包含’pred_boxes’, ‘pred_scores’, 'pred_labels’三个键。
-
在open3d_vis_utils.py开头加入下面代码目的是方式警告。不知道是什么原因使用的时候一直会报颜色设置错误的警告。
# 关闭警告 open3d.utility.set_verbosity_level(open3d.utility.VerbosityLevel.Error) -
在draw_box函数中可以得到box3d它是OrientedBoundingBox类型所以可以通过get_box_points、get_center等函数获得相应的点坐标。
-
可以在draw_box函数中加入下面代码功能是给方框标记中心点中心点的颜色与方框相同。
# 给方框标记中心点 if center: sphere_center = open3d.geometry.TriangleMesh.create_sphere(radius=0.1) sphere_center.paint_uniform_color(box_colormap[ref_labels[i]]) sphere_center.translate(box3d.get_center()) vis.add_geometry(sphere_center) -
可以在open3d_vis_utils.py中添加下面的代码用于绘制POINT_CLOUD_RANGE。如图所示红色框为点云边界框。
# 根据最大边界点和最小边界点画出方框---在这里是用于画POINT_CLOUD_RANGE的该参数配置于voxset.yaml min_bound = [0, -39.68, -3] max_bound = [69.12, 39.68, 1] bbox = open3d.geometry.AxisAlignedBoundingBox(min_bound, max_bound) bbox_lines = open3d.geometry.LineSet.create_from_axis_aligned_bounding_box(bbox) bbox_lines.paint_uniform_color([1, 0, 0]) vis.add_geometry(bbox_lines)
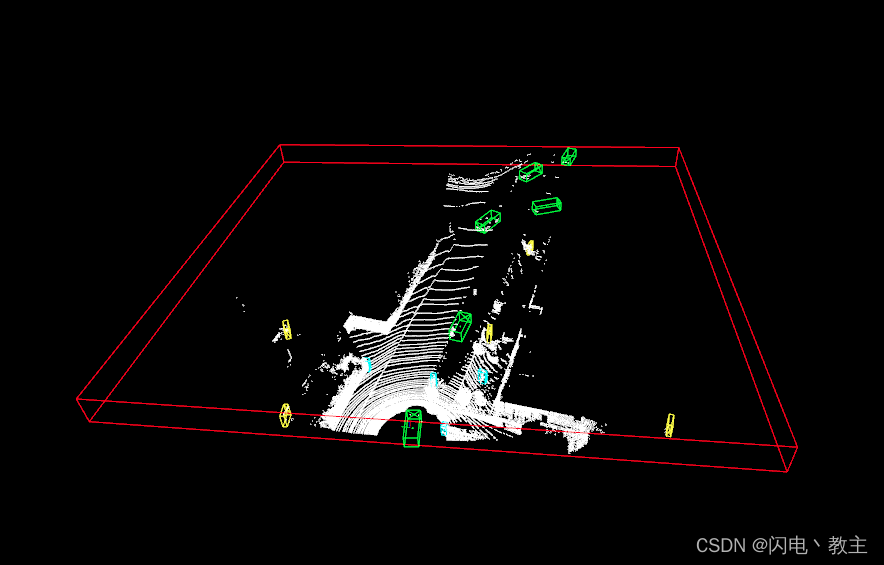
使用自定义数据集进行训练
准备数据集
首先需要按照官方教程创建文件目录如下所示。
OpenPCDet
├── data
│ ├── custom
│ │ │── ImageSets
│ │ │ │── train.txt
│ │ │ │── val.txt
│ │ │── points
│ │ │ │── 000000.npy
│ │ │ │── 999999.npy
│ │ │── labels
│ │ │ │── 000000.txt
│ │ │ │── 999999.txt
├── pcdet
├── tools
使用SUSTechPOINTS标注完后会得到json格式的标签文件我们需要提取有用的内容再保存成txt格式。
OpenPCDet支持的自定义label文件格式如下所示
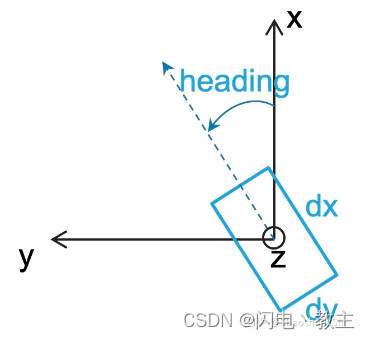
# format: [x y z dx dy dz heading_angle category_name]
1.50 1.46 0.10 5.12 1.85 4.13 1.56 Vehicle
5.54 0.57 0.41 1.08 0.74 1.95 1.57 Pedestrian
其中最后一个heading_angle就是json标签文件中的rotation的z值。不过这个地方需要确保自己点云坐标系激光雷达坐标系与OpenPCDet中规定的坐标系是一致的不然还需要转换成OpenPCDet坐标系。
可以使用下面这个函数实现将json格式的标签文件转换成符合OpenPCDet训练的标签文件。
def json_to_txt(json_path, txt_path):
"""
将json文件转化成符合OpenPCDet训练的标签文件
json_path: json文件所在目录
txt_path 生成txt文件目录
"""
json_list = os.listdir(json_path)
for json_name in json_list:
json_file = os.path.join(json_path, json_name)
with open(json_file, 'r') as f:
data = json.load(f)
label_list = []
for obj_dict in data:
label_name = obj_dict["obj_type"]
pos_xyz = obj_dict["psr"]["position"]
rot_xyz = obj_dict["psr"]["rotation"]
scale_xyz = obj_dict["psr"]["scale"]
temp = ""
for xyz_dict in [pos_xyz, scale_xyz]:
for key in ["x", "y", "z"]:
temp += str(xyz_dict[key])
temp += " "
temp += str(rot_xyz["z"]) + " " + str(label_name) + "\n"
label_list.append(temp)
txt_name = json_name.split(".")[0] + ".txt"
with open(os.path.join(txt_path, txt_name), "w") as f:
for label in label_list:
f.write(label)
除了需要转换标签文件还需要将pcd格式的点云转换成npy格式。可以使用下面的函数实现。
def pcd_to_npy(pcd_path, npy_path):
"""
将pcd文件转换成npy文件
pcd_path: pcd格式点云目录
npy_path: npy格式点云输出目录
"""
pcd_list = os.listdir(pcd_path)
for pcd_name in pcd_list:
pcd_file = os.path.join(pcd_path, pcd_name)
lidar = []
pcd = o3d.io.read_point_cloud(pcd_file)
points = np.array(pcd.points)
for linestr in points:
if len(linestr) == 3: # only x,y,z
linestr_convert = list(map(float, linestr))
linestr_convert.append(0)
lidar.append(linestr_convert)
if len(linestr) == 4: # x,y,z,i
linestr_convert = list(map(float, linestr))
lidar = np.array(lidar).astype(np.float32)
np.save(os.path.join(npy_path, pcd_name[:-4]+".npy"), lidar)
可以使用下面的函数快速生成train.txt和val.txt
def get_train_val_txt(src_path, dst_path, num_of_train):
"""
src_path: 标签文件目录
dst_path: 输出文件目录
num_of_train: 训练集样本数量
"""
src_list = os.listdir(src_path)
random.shuffle(src_list)
with open(os.path.join(dst_path, "train.txt"), 'w') as f:
for index in range(num_of_train):
f.write(src_list[index].split(".")[0])
f.write('\n')
with open(os.path.join(dst_path, "val.txt"), 'w') as f:
for index in range(num_of_train, len(src_list)):
f.write(src_list[index].split(".")[0])
f.write('\n')
将npy点云、txt标签、train.txt和val.txt放到指定目录下。修改custom_dataset.py需要根据自己数据集修改分类类别。
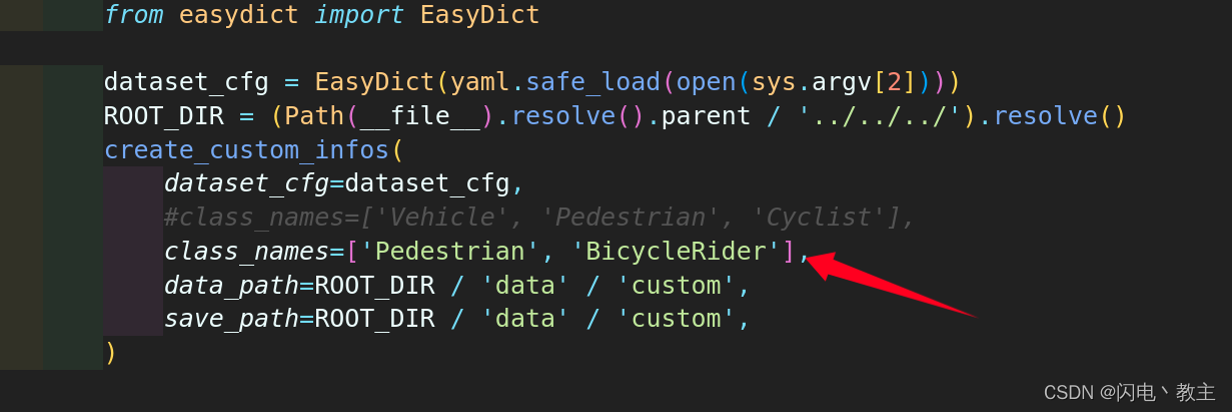
修改custom_dataset.yaml。主要关注以下内容
# 与KITTI数据集映射 左边是自己数据集 右边是KITTI数据集
# 这个地方只会在eval阶段会用到所以如果自己不需要eval的话可以不加
MAP_CLASS_TO_KITTI: {
# 'Vehicle': 'Car'
'Pedestrian': 'Pedestrian',
'BicycleRider': 'Cyclist',
}
# 需要与自己的点云数据格式对应一般不需要改
POINT_FEATURE_ENCODING: {
encoding_type: absolute_coordinates_encoding,
used_feature_list: ['x', 'y', 'z', 'intensity'],
src_feature_list: ['x', 'y', 'z', 'intensity'],
}
DATA_AUGMENTOR:
DISABLE_AUG_LIST: ['placeholder']
AUG_CONFIG_LIST:
- NAME: gt_sampling
USE_ROAD_PLANE: False
DB_INFO_PATH:
- custom_dbinfos_train.pkl
PREPARE: {
# 需要改成自己的数据集类别
filter_by_min_points: ['Pedestrian:5', 'BicycleRider:5'],
# filter_by_difficulty: [-1], # 这个地方如果不注释的话训练可能会报错可以自己尝试一下
}
# 需要改成自己的数据集类别
SAMPLE_GROUPS: [Pedestrian:15', 'BicycleRider:15']
NUM_POINT_FEATURES: 4
DATABASE_WITH_FAKELIDAR: False
REMOVE_EXTRA_WIDTH: [0.0, 0.0, 0.0]
LIMIT_WHOLE_SCENE: True
最后在命令行运行下面命令。如果不报错的话就可以得到训练数据集了。
python -m pcdet.datasets.custom.custom_dataset create_custom_infos tools/cfgs/dataset_configs/custom_dataset.yaml
修改网络yaml配置文件
# 要改成自己的类别
CLASS_NAMES: ['Pedestrian', 'BicycleRider']
# 需要修改成custom_dataset.yaml
_BASE_CONFIG_: cfgs/dataset_configs/custom_dataset.yaml
# 点云范围 [x_min, y_min, z_min, x_max, y_max, z_max]
# 需要和VOXEL_SIZE满足倍数关系。X和Y轴与体素需要满足16倍的关系。详细配置可以看官方教程。
POINT_CLOUD_RANGE: [0, -15.36, -2, 15.36, 15.36, 2]
# 按照自己数据集修改
DATA_AUGMENTOR:
DISABLE_AUG_LIST: ['placeholder']
AUG_CONFIG_LIST:
- NAME: gt_sampling
# 该数据增强方法起源于SECOND网络作者将其他帧ground truth矩形框内的点云抽取出来放在当前帧的空余位置
# 以此来形成“新”一帧的训练数据达到数据增强的目的。
USE_ROAD_PLANE: False
DB_INFO_PATH:
- custom_dbinfos_train.pkl
PREPARE: {
# 保留至少5个点的车辆、行人和骑行者
filter_by_min_points: ['Pedestrian:5', 'BicycleRider:5'],
# filter_by_difficulty: [-1],
}
# 指定需要采样的物体类别和数量
SAMPLE_GROUPS: ['Pedestrian:15', 'BicycleRider:15']
NUM_POINT_FEATURES: 4
DATABASE_WITH_FAKELIDAR: False
REMOVE_EXTRA_WIDTH: [0.0, 0.0, 0.0]
LIMIT_WHOLE_SCENE: False
# anchor配置需要适配自己的数据集
ANCHOR_GENERATOR_CONFIG: [
{
'class_name': 'Pedestrian',
# 尺寸 长宽高 单位为米
'anchor_sizes': [[0.75, 0.66, 1.73]],
'anchor_rotations': [0, 1.57], # 旋转角度 0°和90°(弧度π/2=1.57表示anchor可以沿水平和垂直方向旋转
'anchor_bottom_heights': [-0.6], # 底部高度离地面的高度
'align_center': False, # 居中对齐
'feature_map_stride': 1, # 特征图步幅
'matched_threshold': 0.5, # 匹配阈值 高于这个阈值的被认为是正样本
'unmatched_threshold': 0.35 # 不匹配阈值 低于这个阈值的被认为是负样本
},
{
'class_name': 'BicycleRider',
'anchor_sizes': [[1.83, 0.74, 1.64]],
'anchor_rotations': [0, 1.57],
'anchor_bottom_heights': [-0.6],
'align_center': False,
'feature_map_stride': 1,
'matched_threshold': 0.5,
'unmatched_threshold': 0.35
}
]
可以使用下面的代码获取自己类别的平均anchor
# 获取每个类别的评价lwh以此来设置anchor
import os
if __name__ == "__main__":
label_path = "data/custom/labels"
label_list = os.listdir(label_path)
# l w h
P_counts = 0
Pedestrian = [0.0, 0.0, 0.0]
B_counts = 0
BicycleRider = [0.0, 0.0, 0.0]
for label_name in label_list:
label_file = os.path.join(label_path, label_name)
with open(label_file, 'r') as f:
data = f.readlines()
for line in data:
temp_list = line.split(" ")
cls_name = temp_list[-1][:-1]
if cls_name == "Pedestrian":
Pedestrian[0] += float(temp_list[3])
Pedestrian[1] += float(temp_list[4])
Pedestrian[2] += float(temp_list[5])
P_counts += 1
else:
BicycleRider[0] += float(temp_list[3])
BicycleRider[1] += float(temp_list[4])
BicycleRider[2] += float(temp_list[5])
B_counts += 1
print(f"P l{Pedestrian[0]/P_counts} w{Pedestrian[1]/P_counts} h{Pedestrian[2]/P_counts}")
print(f"B l{BicycleRider[0]/B_counts} w{BicycleRider[1]/B_counts} h{BicycleRider[2]/B_counts}")
按照上述要求修改完就可以训练了。
最后分享一下我自己拍摄标注的数据集点我下载
这个数据集是以树为目标的已经处理成自定义数据集的格式了可以直接使用。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |