

支付宝的架构
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
自 2008 年双 11 以来在每年双 11 超大规模流量的冲击上蚂蚁金服都会不断突破现有技术的极限。2010 年双 11 的支付峰值为 2 万笔/分钟到 2017 年双 11 时这个数字变为了 25.6 万笔/秒。
2018 年双 11 的支付峰值为 48 万笔/秒2019 年双 11 支付峰值为 54.4 万笔/秒创下新纪录是 2009 年第一次双 11 的 1360 倍。
在如此之大的支付 TPS 背后除了削峰等锦上添花的应用级优化最解渴最实质的招数当数基于分库分表的单元化了蚂蚁技术称之为 LDC逻辑数据中心。
本文不打算讨论具体到代码级的分析而是尝试用最简单的描述来说明其中最大快人心的原理。
我想关心分布式系统设计的人都曾被下面这些问题所困扰过
支付宝海量支付背后最解渴的设计是啥换句话说实现支付宝高 TPS 的最关键的设计是啥
LDC 是啥LDC 怎么实现异地多活和异地灾备的
CAP 魔咒到底是啥P 到底怎么理解
什么是脑裂跟 CAP 又是啥关系
什么是 PAXOS它解决了啥问题
PAXOS 和 CAP 啥关系PAXOS 可以逃脱 CAP 魔咒么
Oceanbase 能逃脱 CAP 魔咒么
如果你对这些感兴趣不妨看一场赤裸裸的论述拒绝使用晦涩难懂的词汇直面最本质的逻辑。

LDC 和单元化
LDClogic data center是相对于传统的Internet Data Center-IDC提出的逻辑数据中心所表达的中心思想是无论物理结构如何的分布整个数据中心在逻辑上是协同和统一的。
这句话暗含的是强大的体系设计分布式系统的挑战就在于整体协同工作可用性分区容忍性和统一一致性。
单元化是大型互联网系统的必然选择趋势举个最最通俗的例子来说明单元化。
我们总是说 TPS 很难提升确实任何一家互联网公司比如淘宝、携程、新浪它的交易 TPS 顶多以十万计量平均水平很难往上串了。
因为数据库存储层瓶颈的存在再多水平扩展的服务器都无法绕开而从整个互联网的视角看全世界电商的交易 TPS 可以轻松上亿。
这个例子带给我们一些思考为啥几家互联网公司的 TPS 之和可以那么大服务的用户数规模也极为吓人而单个互联网公司的 TPS 却很难提升
究其本质每家互联网公司都是一个独立的大型单元他们各自服务自己的用户互不干扰
这就是单元化的基本特性任何一家互联网公司其想要成倍的扩大自己系统的服务能力都必然会走向单元化之路。
它的本质是分治我们把广大的用户分为若干部分同时把系统复制多份每一份都独立部署每一份系统都服务特定的一群用户。
以淘宝举例这样之后就会有很多个淘宝系统分别为不同的用户服务每个淘宝系统都做到十万 TPS 的话N 个这样的系统就可以轻松做到 N*十万的 TPS 了。
LDC 实现的关键就在于单元化系统架构设计所以在蚂蚁内部LDC 和单元化是不分家的这也是很多同学比较困扰的地方看似没啥关系实则是单元化体系设计成就了 LDC。
小结分库分表解决的最大痛点是数据库单点瓶颈这个瓶颈的产生是由现代二进制数据存储体系决定的即 I/O 速度。
单元化只是分库分表后系统部署的一种方式这种部署模式在灾备方面也发挥了极大的优势。

系统架构演化史
几乎任何规模的互联网公司都有自己的系统架构迭代和更新大致的演化路径都大同小异。
最早一般为了业务快速上线所有功能都会放到一个应用里系统架构如下图所示
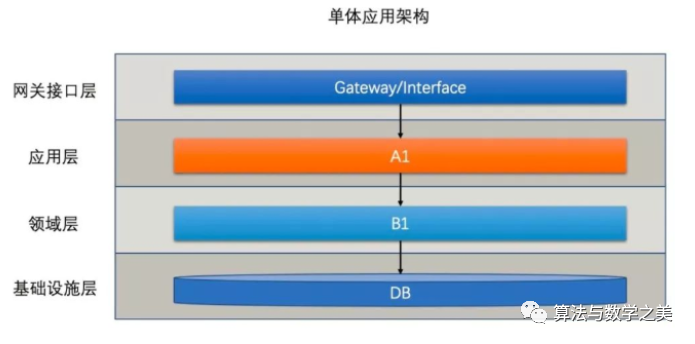
这样的架构显然是有问题的单机有着明显的单点效应单机的容量和性能都是很局限的而使用中小型机会带来大量的浪费。
随着业务发展这个矛盾逐渐转变为主要矛盾因此工程师们采用了以下架构
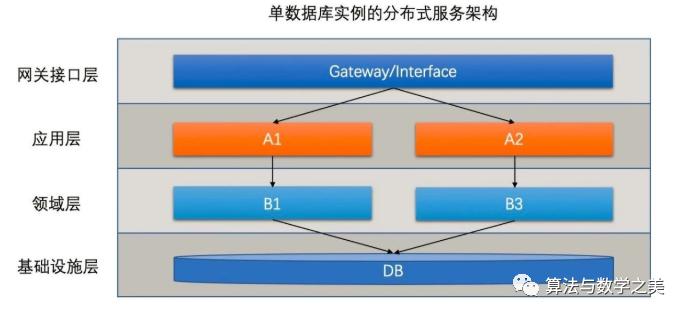
这是整个公司第一次触碰到分布式也就是对某个应用进行了水平扩容它将多个微机的计算能力团结了起来可以完胜同等价格的中小型机器。
慢慢的大家发现应用服务器 CPU 都很正常了但是还是有很多慢请求究其原因是因为单点数据库带来了性能瓶颈。
于是程序员们决定使用主从结构的数据库集群如下图所示
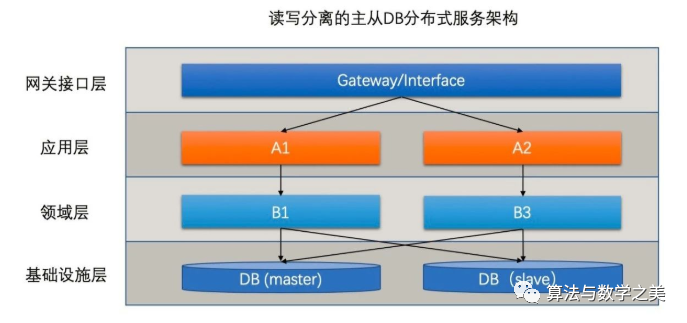
其中大部分读操作可以直接访问从库从而减轻主库的压力。然而这种方式还是无法解决写瓶颈写依旧需要主库来处理当业务量量级再次增高时写已经变成刻不容缓的待处理瓶
这时候分库分表方案出现了
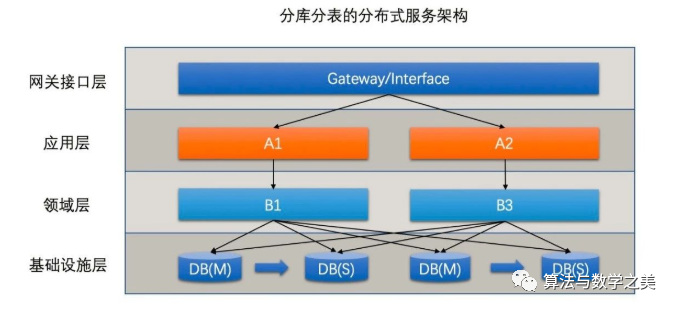
分库分表不仅可以对相同的库进行拆分还可以对相同的表进行拆分对表进行拆分的方式叫做水平拆分。
不同功能的表放到不同的库里一般对应的是垂直拆分按照业务功能进行拆分此时一般还对应了微服务化。
这种方法做到极致基本能支撑 TPS 在万级甚至更高的访问量了。然而随着相同应用扩展的越多每个数据库的链接数也巨量增长这让数据库本身的资源成为了瓶颈。
这个问题产生的本质是全量数据无差别的分享了所有的应用资源比如 A 用户的请求在负载均衡的分配下可能分配到任意一个应用服务器上因而所有应用全部都要链接 A 用户所在的分库数据库连接数就变成笛卡尔乘积了。
在本质点说这种模式的资源隔离性还不够彻底。要解决这个问题就需要把识别用户分库的逻辑往上层移动从数据库层移动到路由网关层。
这样一来从应用服务器 a 进来的来自 A 客户的所有请求必然落库到 DB-A因此 a 也不用链接其他的数据库实例了这样一个单元化的雏形就诞生了。
思考一下应用间其实也存在交互比如 A 转账给 B也就意味着应用不需要链接其他的数据库了但是还需要链接其他应用。
如果是常见的 RPC 框架如 Dubbo 等使用的是 TCP/IP 协议那么等同于把之前与数据库建立的链接换成与其他应用之间的链接了。
为啥这样就消除瓶颈了呢首先由于合理的设计应用间的数据交互并不巨量其次应用间的交互可以共享 TCP 链接比如 A->B 之间的 Socket 链接可以被 A 中的多个线程复用。
而一般的数据库如 MySQL 则不行所以 MySQL 才需要数据库链接池。
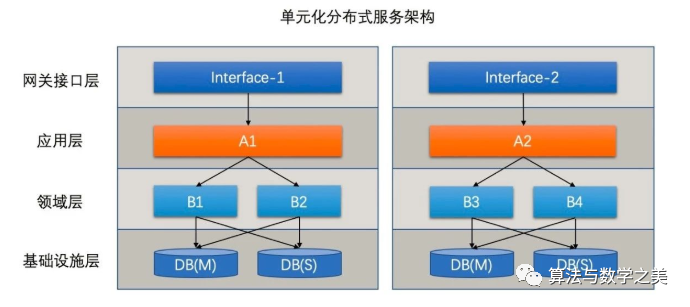
如上图所示但我们把整套系统打包为单元化时每一类的数据从进单元开始就注定在这个单元被消化由于这种彻底的隔离性整个单元可以轻松的部署到任意机房而依然能保证逻辑上的统一。
下图为一个三地五机房的部署方式


蚂蚁单元化架构实践
蚂蚁支付宝应该是国内最大的支付工具其在双 11 等活动日当日的支付 TPS 可达几十万级未来这个数字可能会更大这决定了蚂蚁单元化架构从容量要求上看必然从单机房走向多机房。
另一方面异地灾备也决定了这些 IDC 机房必须是异地部署的。整体上支付宝也采用了三地五中心IDC 机房来保障系统的可用性。
跟上文中描述的有所不同的是支付宝将单元分成了三类也称 CRG 架构
RZoneRegion Zone直译可能有点反而不好理解。实际上就是所有可以分库分表的业务系统整体部署的最小单元。每个 RZone 连上数据库就可以撑起一片天空把业务跑的溜溜的。
GZoneGlobal Zone全局单元意味着全局只有一份。部署了不可拆分的数据和服务比如系统配置等。
实际情况下GZone 异地也会部署不过仅是用于灾备同一时刻只有一地 GZone 进行全局服务。GZone 一般被 RZone 依赖提供的大部分是读取服务。
CZoneCity Zone顾名思义这是以城市为单位部署的单元。同样部署了不可拆分的数据和服务比如用户账号服务客户信息服务等。理论上 CZone 会被 RZone 以比访问 GZone 高很多的频率进行访问。
CZone 是基于特定的 GZone 场景进行优化的一种单元它把 GZone 中有些有着”写读时间差现象”的数据和服务进行了的单独部署这样 RZone 只需要访问本地的 CZone 即可而不是访问异地的 GZone。
“写读时间差现象”是蚂蚁架构师们根据实践统计总结的他们发现大部分情况下一个数据被写入后都会过足够长的时间后才会被访问。
生活中这种例子很常见我们办完银行卡后可能很久才会存第一笔钱我们创建微博账号后可能想半天才会发微博我们下载创建淘宝账号后可能得浏览好几分钟才会下单买东西。
当然了这些例子中的时间差远远超过了系统同步时间。一般来说异地的延时在 100ms 以内所以只要满足某地 CZone 写入数据后 100ms 以后才用这个数据这样的数据和服务就适合放到 CZone 中。
相信大家看到这都会问为啥分这三种单元其实其背后对应的是不同性质的数据而服务不过是对数据的操作集。
下面我们来根据数据性质的不同来解释支付宝的 CRG 架构。当下几乎所有互联网公司的分库分表规则都是根据用户 ID 来制定的。
而围绕用户来看整个系统的数据可以分为以下两类
用户流水型数据典型的有用户的订单、用户发的评论、用户的行为记录等。
这些数据都是用户行为产生的流水型数据具备天然的用户隔离性比如 A 用户的 App 上绝对看不到 B 用户的订单列表。所以此类数据非常适合分库分表后独立部署服务。
用户间共享型数据这种类型的数据又分两类。一类共享型数据是像账号、个人博客等可能会被所有用户请求访问的用户数据。
比如 A 向 B 转账A 给 B 发消息这时候需要确认 B 账号是否存在又比如 A 想看 B 的个人博客之类的。
另外一类是用户无关型数据像商品、系统配置汇率、优惠政策、财务统计等这些非用户纬度的数据很难说跟具体的某一类用户挂钩可能涉及到所有用户。
比如商品假设按商品所在地来存放商品数据这需要双维度分库分表那么上海的用户仍然需要访问杭州的商品。
这就又构成跨地跨 Zone 访问了还是达不到单元化的理想状态而且双维度分库分表会给整个 LDC 运维带来复杂度提升。
注网上和支付宝内部有另外一些分法比如流水型和状态性有时候还会分为三类流水型、状态型和配置型。
个人觉得这些分法虽然尝试去更高层次的抽象数据分类但实际上边界很模糊适得其反。
直观的类比我们可以很轻易的将上述两类数据对应的服务划分为 RZone 和 GZoneRZone 包含的就是分库分表后负责固定客户群体的服务GZone 则包含了用户间共享的公共数据对应的服务。
到这里为止一切都很完美这也是主流的单元化话题了。对比支付宝的 CRG 架构我们一眼就发现少了 CCity ZoneCZone 确实是蚂蚁在单元化实践领域的一个创新点。
再来分析下 GZoneGZone 之所以只能单地部署是因为其数据要求被所有用户共享无法分库分表而多地部署会带来由异地延时引起的不一致。
比如实时风控系统如果多地部署某个 RZone 直接读取本地的话很容易读取到旧的风控状态这是很危险的。
这时蚂蚁架构师们问了自己一个问题——难道所有数据受不了延时么这个问题像是打开了新世界的大门通过对 RZone 已有业务的分析架构师们发现 80% 甚至更高的场景下数据更新后都不要求立马被读取到。
也就是上文提到的”写读时间差现象”那么这就好办了对于这类数据我们允许每个地区的 RZone 服务直接访问本地为了给这些 RZone 提供这些数据的本地访问能力蚂蚁架构师设计出了 CZone。
在 CZone 的场景下写请求一般从 GZone 写入公共数据所在库然后同步到整个 OB 集群然后由 CZone 提供读取服务。比如支付宝的会员服务就是如此。
即便架构师们设计了完美的 CRG但即便在蚂蚁的实际应用中各个系统仍然存在不合理的 CRG 分类尤其是 CG 不分的现象很常见。

支付宝单元化的异地多活和灾备
流量挑拨技术探秘简介
单元化后异地多活只是多地部署而已。比如上海的两个单元为 ID 范围为 [00~19][40~59] 的用户服务。
而杭州的两个单元为 ID 为 [20~39]和[60,79]的用户服务这样上海和杭州就是异地双活的。
支付宝对单元化的基本要求是每个单元都具备服务所有用户的能力即——具体的那个单元服务哪些用户是可以动态配置的。所以异地双活的这些单元还充当了彼此的备份。
发现工作中冷备热备已经被用的很乱了。最早冷备是指数据库在备份数据时需要关闭后进行备份也叫离线备份防止数据备份过程中又修改了不需要关闭即在运行过程中进行数据备份的方式叫做热备也叫在线备份。
也不知道从哪一天开始冷备在主备系统里代表了这台备用机器是关闭状态的只有主服务器挂了之后备服务器才会被启动。
而相同的热备变成了备服务器也是启动的只是没有流量而已一旦主服务器挂了之后流量自动打到备服务器上。本文不打算用第二种理解因为感觉有点野。
为了做到每个单元访问哪些用户变成可配置支付宝要求单元化管理系统具备流量到单元的可配置以及单元到 DB 的可配置能力。
如下图所示
其中 Spanner 是蚂蚁基于 Nginx 自研的反向代理网关也很好理解有些请求我们希望在反向代理层就被转发至其他 IDC 的 Spanner 而无需进入后端服务如图箭头 2 所示。
那么对于应该在本 IDC 处理的请求就直接映射到对应的 RZ 即可如图箭头 1。
进入后端服务后理论上如果请求只是读取用户流水型数据那么一般不会再进行路由了。
然而对于有些场景来说A 用户的一个请求可能关联了对 B 用户数据的访问比如 A 转账给 BA 扣完钱后要调用账务系统去增加 B 的余额。
这时候就涉及到再次的路由同样有两个结果跳转到其他 IDC如图箭头 3或是跳转到本 IDC 的其他 RZone如图箭头 4。
RZone 到 DB 数据分区的访问这是事先配置好的上图中 RZ 和 DB 数据分区的关系为
RZ0* --> a
RZ1* --> b
RZ2* --> c
RZ3* --> d
下面我们举个例子来说明整个流量挑拨的过程假设 C 用户所属的数据分区是 c而 C 用户在杭州访问了 cashier.alipay.com随便编的。
①目前支付宝默认会按照地域来路由流量具体的实现承载者是自研的 GLSBGlobal Server Load Balancing
https://developer.alipay.com/article/1889
它会根据请求者的 IP自动将 cashier.alipay.com 解析为杭州 IDC 的 IP 地址或者跳转到 IDC 所在的域名。
大家自己搞过网站的化应该知道大部分 DNS 服务商的地址都是靠人去配置的GLSB 属于动态配置域名的系统网上也有比较火的类似产品比如花生壳之类建过私站的同学应该很熟悉的。
②好了到此为止用户的请求来到了 IDC-1 的 Spanner 集群服务器上Spanner 从内存中读取到了路由配置知道了这个请求的主体用户 C 所属的 RZ3* 不再本 IDC于是直接转到了 IDC-2 进行处理。
③进入 IDC-2 之后根据流量配比规则该请求被分配到了 RZ3B 进行处理。
④RZ3B 得到请求后对数据分区 c 进行访问。
⑤处理完毕后原路返回。
大家应该发现问题所在了如果再来一个这样的请求岂不是每次都要跨地域进行调用和返回体传递
确实是存在这样的问题的对于这种问题支付宝架构师们决定继续把决策逻辑往用户终端推移。
比如每个 IDC 机房都会有自己的域名真实情况可能不是这样命名的:
IDC-1 对应 cashieridc-1.alipay.com
IDC-2 对应 cashieridc-2.alipay.com
那么请求从 IDC-1 涮过一遍返回时会将前端请求跳转到 cashieridc-2.alipay.com 去如果是 App只需要替换 rest 调用的接口域名后面所有用户的行为都会在这个域名上发生就避免了走一遍 IDC-1 带来的延时。
支付宝灾备机制
流量挑拨是灾备切换的基础和前提条件发生灾难后的通用方法就是把陷入灾难的单元的流量重新打到正常的单元上去这个流量切换的过程俗称切流。
支付宝 LDC 架构下的灾备有三个层次
同机房单元间灾备
同城机房间灾备
异地机房间灾备
同机房单元间灾备灾难发生可能性相对最高但其实也很小。对 LDC 来说最小的灾难就是某个单元由于一些原因局部插座断开、线路老化、人为操作失误宕机了。
从上节里的图中可以看到每组 RZ 都有 AB 两个单元这就是用来做同机房灾备的并且 AB 之间也是双活双备的。
正常情况下 AB 两个单元共同分担所有的请求一旦 A 单元挂了B 单元将自动承担 A 单元的流量份额。这个灾备方案是默认的。
同城机房间灾备灾难发生可能性相对更小。这种灾难发生的原因一般是机房电线网线被挖断或者机房维护人员操作失误导致的。
在这种情况下就需要人工的制定流量挑拨切流方案了。下面我们举例说明这个过程如下图所示为上海的两个 IDC 机房。
整个切流配置过程分两步首先需要将陷入灾难的机房中 RZone 对应的数据分区的访问权配置进行修改。
假设我们的方案是由 IDC-2 机房的 RZ2 和 RZ3 分别接管 IDC-1 中的 RZ0 和 RZ1。
那么首先要做的是把数据分区 ab 对应的访问权从 RZ0 和 RZ1 收回分配给 RZ2 和 RZ3。
即将如上图所示为初始映射
RZ0* --> a
RZ1* --> b
RZ2* --> c
RZ3* --> d
变为
RZ0* --> /
RZ1* --> /
RZ2* --> a
RZ2* --> c
RZ3* --> b
RZ3* --> d
然后再修改用户 ID 和 RZ 之间的映射配置。假设之前为
[00-24] --> RZ0A(50%),RZOB(50%)
[25-49] --> RZ1A(50%),RZ1B(50%)
[50-74] --> RZ2A(50%),RZ2B(50%)
[75-99] --> RZ3A(50%),RZ3B(50%)
那么按照灾备方案的要求这个映射配置将变为
[00-24] --> RZ2A(50%),RZ2B(50%)
[25-49] --> RZ3A(50%),RZ3B(50%)
[50-74] --> RZ2A(50%),RZ2B(50%)
[75-99] --> RZ3A(50%),RZ3B(50%)
这样之后所有流量将会被打到 IDC-2 中期间部分已经向 IDC-1 发起请求的用户会收到失败并重试的提示。
实际情况中整个过程并不是灾难发生后再去做的整个切换的流程会以预案配置的形式事先准备好推送给每个流量挑拨客户端集成到了所有的服务和 Spanner 中。
这里可以思考下为何先切数据库映射再切流量呢这是因为如果先切流量意味着大量注定失败的请求会被打到新的正常单元上去从而影响系统的稳定性数据库还没准备好。
异地机房间灾备这个基本上跟同城机房间灾备一致这也是单元化的优点不再赘述。

蚂蚁单元化架构的 CAP 分析
回顾 CAP
①CAP 的定义
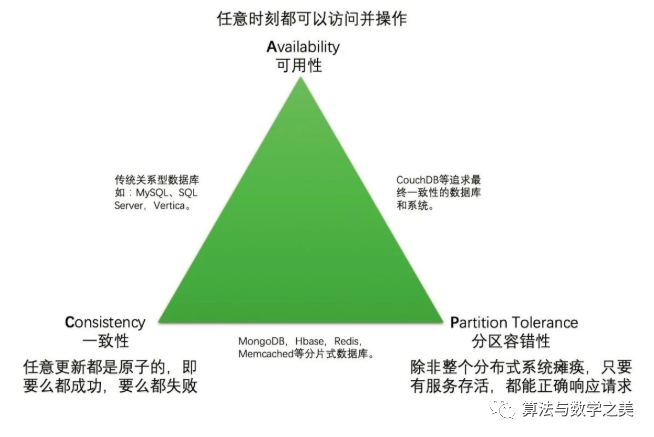
CAP 原则是指任意一个分布式系统同时最多只能满足其中的两项而无法同时满足三项。
所谓的分布式系统说白了就是一件事一个人做的现在分给好几个人一起干。
我们先简单回顾下 CAP 各个维度的含义
Consistency一致性这个理解起来很简单就是每时每刻每个节点上的同一份数据都是一致的。
这就要求任何更新都是原子的即要么全部成功要么全部失败。想象一下使用分布式事务来保证所有系统的原子性是多么低效的一个操作。
Availability可用性这个可用性看起来很容易理解但真正说清楚的不多。我更愿意把可用性解释为任意时刻系统都可以提供读写服务。
举个例子当我们用事务将所有节点锁住来进行某种写操作时如果某个节点发生不可用的情况会让整个系统不可用。
对于分片式的 NoSQL 中间件集群RedisMemcached来说一旦一个分片歇菜了整个系统的数据也就不完整了读取宕机分片的数据就会没响应也就是不可用了。
需要说明一点哪些选择 CP 的分布式系统并不是代表可用性就完全没有了只是可用性没有保障了。
为了增加可用性保障这类中间件往往都提供了”分片集群+复制集”的方案。
Partition tolerance分区容忍性这个可能也是很多文章都没说清楚的。P 并不是像 CA 一样是一个独立的性质它依托于 CA 来进行讨论。
参考文献中的解释”除非整个网络瘫痪否则任何时刻系统都能正常工作”言下之意是小范围的网络瘫痪节点宕机都不会影响整个系统的 CA。
我感觉这个解释听着还是有点懵逼所以个人更愿意解释为当节点之间网络不通时出现网络分区可用性和一致性仍然能得到保障。
从个人角度理解分区容忍性又分为“可用性分区容忍性”和“一致性分区容忍性”。
出现分区时会不会影响可用性的关键在于需不需要所有节点互相沟通协作来完成一次事务不需要的话是铁定不影响可用性的。
庆幸的是应该不太会有分布式系统会被设计成完成一次事务需要所有节点联动一定要举个例子的话全同步复制技术下的 MySQL 是一个典型案例。
出现分区时会不会影响一致性的关键则在于出现脑裂时有没有保证一致性的方案这对主从同步型数据库MySQL、SQL Server是致命的。
一旦网络出现分区产生脑裂系统会出现一份数据两个值的状态谁都不觉得自己是错的。
需要说明的是正常来说同一局域网内网络分区的概率非常低这也是为啥我们最熟悉的数据库MySQL、SQL Server 等也是不考虑 P 的原因。
下图为 CAP 之间的经典关系图
还有个需要说明的地方其实分布式系统很难满足 CAP 的前提条件是这个系统一定是有读有写的如果只考虑读那么 CAP 很容易都满足。
比如一个计算器服务接受表达式请求返回计算结果搞成水平扩展的分布式显然这样的系统没有一致性问题网络分区也不怕可用性也是很稳的所以可以满足 CAP。
②CAP 分析方法
先说下 CA 和 P 的关系如果不考虑 P 的话系统是可以轻松实现 CA 的。
而 P 并不是一个单独的性质它代表的是目标分布式系统有没有对网络分区的情况做容错处理。
如果做了处理就一定是带有 P 的接下来再考虑分区情况下到底选择了 A 还是 C。所以分析 CAP建议先确定有没有对分区情况做容错处理。
以下是个人总结的分析一个分布式系统 CAP 满足情况的一般方法
if( 不存在分区的可能性 || 分区后不影响可用性或一致性 || 有影响但考虑了分区情况-P){
if(可用性分区容忍性-A under P)
return "AP";
else if(一致性分区容忍性-C under P
return "CP";
}
else{ //分区有影响但没考虑分区情况下的容错
if(具备可用性-A && 具备一致性-C{
return AC;
}
}
这里说明下如果考虑了分区容忍性就不需要考虑不分区情况下的可用性和一致性了大多是满足的。
水平扩展应用+单数据库实例的 CAP 分析
让我们再来回顾下分布式应用系统的来由早年每个应用都是单体的跑在一个服务器上服务器一挂服务就不可用了。
另外一方面单体应用由于业务功能复杂对机器的要求也逐渐变高普通的微机无法满足这种性能和容量的要求。
所以要拆还在 IBM 大卖小型商用机的年代阿里巴巴就提出要以分布式微机替代小型机。
所以我们发现分布式系统解决的最大的痛点就是单体单机系统的可用性问题。
要想高可用必须分布式。一家互联网公司的发展之路上第一次与分布式相遇应该都是在单体应用的水平扩展上。
也就是同一个应用启动了多个实例连接着相同的数据库为了简化问题先不考虑数据库是否单点如下图所示

这样的系统天然具有的就是 AP可用性和分区容忍性
一方面解决了单点导致的低可用性问题。
另一方面无论这些水平扩展的机器间网络是否出现分区这些服务器都可以各自提供服务因为他们之间不需要进行沟通。
然而这样的系统是没有一致性可言的想象一下每个实例都可以往数据库 insert 和 update注意这里还没讨论到事务那还不乱了套。
于是我们转向了让 DB 去做这个事这时候”数据库事务”就被用上了。用大部分公司会选择的 MySQL 来举例用了事务之后会发现数据库又变成了单点和瓶颈。
单点就像单机一样(本例子中不考虑从库模式)理论上就不叫分布式了如果一定要分析其 CAP 的话根据上面的步骤分析过程应该是这样的
分区容忍性先看有没有考虑分区容忍性或者分区后是否会有影响。单台 MySQL 无法构成分区要么整个系统挂了要么就活着。
可用性分区容忍性分区情况下假设恰好是该节点挂了系统也就不可用了所以可用性分区容忍性不满足。
一致性分区容忍性分区情况下只要可用单点单机的最大好处就是一致性可以得到保障。
因此这样的一个系统个人认为只是满足了 CP。A 有但不出色从这点可以看出CAP 并不是非黑即白的。
包括常说的 BASE 最终一致性方案其实只是 C 不出色但最终也是达到一致性的BASE 在一致性上选择了退让。
关于分布式应用+单点数据库的模式算不算纯正的分布式系统这个可能每个人看法有点差异上述只是我个人的一种理解是不是分布式系统不重要重要的是分析过程。
其实我们讨论分布式就是希望系统的可用性是多个系统多活的一个挂了另外的也能顶上显然单机单点的系统不具备这样的高可用特性。
所以在我看来广义的说 CAP 也适用于单点单机系统单机系统是 CP 的。
说到这里大家似乎也发现了水平扩展的服务应用+数据库这样的系统的 CAP 魔咒主要发生在数据库层。
因为大部分这样的服务应用都只是承担了计算的任务像计算器那样本身不需要互相协作所有写请求带来的数据的一致性问题下沉到了数据库层去解决。
想象一下如果没有数据库层而是应用自己来保障数据一致性那么这样的应用之间就涉及到状态的同步和交互了ZooKeeper 就是这么一个典型的例子。
水平扩展应用+主从数据库集群的CAP分析
上一节我们讨论了多应用实例+单数据库实例的模式这种模式是分布式系统也好不是分布式系统也罢整体是偏 CP 的。
现实中技术人员们也会很快发现这种架构的不合理性——可用性太低了。
于是如下图所示的模式成为了当下大部分中小公司所使用的架构
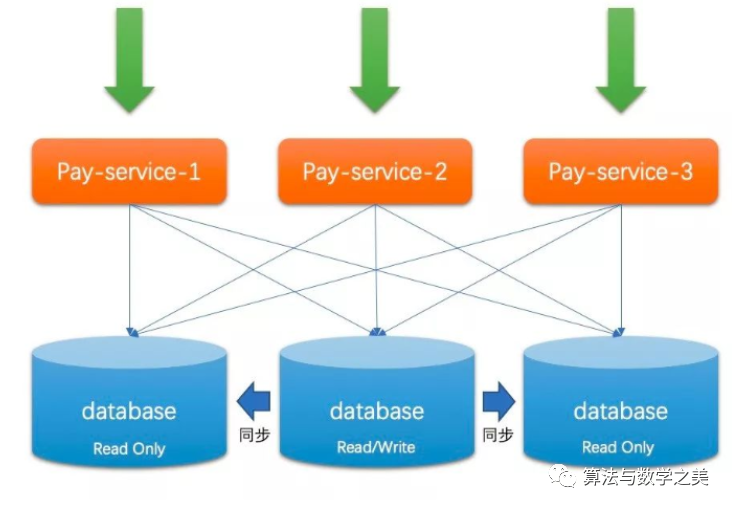
从上图我可以看到三个数据库实例中只有一个是主库其他是从库。
一定程度上这种架构极大的缓解了”读可用性”问题而这样的架构一般会做读写分离来达到更高的”读可用性”幸运的是大部分互联网场景中读都占了 80% 以上所以这样的架构能得到较长时间的广泛应用。
写可用性可以通过 Keepalived 这种 HA高可用框架来保证主库是活着的但仔细一想就可以明白这种方式并没有带来性能上的可用性提升。还好至少系统不会因为某个实例挂了就都不可用了。
可用性勉强达标了这时候的 CAP 分析如下
分区容忍性依旧先看分区容忍性主从结构的数据库存在节点之间的通信他们之间需要通过心跳来保证只有一个 Master。
然而一旦发生分区每个分区会自己选取一个新的 Master这样就出现了脑裂常见的主从数据库MySQLOracle 等并没有自带解决脑裂的方案。所以分区容忍性是没考虑的。
一致性不考虑分区由于任意时刻只有一个主库所以一致性是满足的。
可用性不考虑分区HA 机制的存在可以保证可用性所以可用性显然也是满足的。
所以这样的一个系统我们认为它是 AC 的。我们再深入研究下如果发生脑裂产生数据不一致后有一种方式可以仲裁一致性问题是不是就可以满足 P 了呢。
还真有尝试通过预先设置规则来解决这种多主库带来的一致性问题的系统比如 CouchDB它通过版本管理来支持多库写入在其仲裁阶段会通过 DBA 配置的仲裁规则也就是合并规则比如谁的时间戳最晚谁的生效进行自动仲裁自动合并从而保障最终一致性BASE自动规则无法合并的情况则只能依赖人工决策了。
蚂蚁单元化 LDC 架构 CAP 分析
①战胜分区容忍性
在讨论蚂蚁 LDC 架构的 CAP 之前我们再来想想分区容忍性有啥值得一提的为啥很多大名鼎鼎的 BASE最终一致性体系系统都选择损失实时一致性而不是丢弃分区容忍性呢
分区的产生一般有两种情况
某台机器宕机了过一会儿又重启了看起来就像失联了一段时间像是网络不可达一样。
异地部署情况下异地多活意味着每一地都可能会产生数据写入而异地之间偶尔的网络延时尖刺网络延时曲线图陡增、网络故障都会导致小范围的网络分区产生。
前文也提到过如果一个分布式系统是部署在一个局域网内的一个物理机房内那么个人认为分区的概率极低即便有复杂的拓扑也很少会有在同一个机房里出现网络分区的情况。
而异地这个概率会大大增高所以蚂蚁的三地五中心必须需要思考这样的问题分区容忍不能丢
同样的情况还会发生在不同 ISP 的机房之间想象一下你和朋友组队玩 DOTA他在电信你在联通。
为了应对某一时刻某个机房突发的网络延时尖刺活着间歇性失联一个好的分布式系统一定能处理好这种情况下的一致性问题。
那么蚂蚁是怎么解决这个问题的呢我们在上文讨论过其实 LDC 机房的各个单元都由两部分组成负责业务逻辑计算的应用服务器和负责数据持久化的数据库。
大部分应用服务器就像一个个计算器自身是不对写一致性负责的这个任务被下沉到了数据库。所以蚂蚁解决分布式一致性问题的关键就在于数据库
想必蚂蚁的读者大概猜到下面的讨论重点了——OceanBase下文简称OB中国第一款自主研发的分布式数据库一时间也确实获得了很多光环。
在讨论 OB 前我们先来想想 Why not MySQL
首先就像 CAP 三角图中指出的MySQL 是一款满足 AC 但不满足 P 的分布式系统。
试想一下一个 MySQL 主从结构的数据库集群当出现分区时问题分区内的 Slave 会认为主已经挂了所以自己成为本分区的 Master脑裂。
等分区问题恢复后会产生 2 个主库的数据而无法确定谁是正确的也就是分区导致了一致性被破坏。这样的结果是严重的这也是蚂蚁宁愿自研 OceanBase 的原动力之一。
那么如何才能让分布式系统具备分区容忍性呢按照老惯例我们从”可用性分区容忍”和”一致性分区容忍”两个方面来讨论
可用性分区容忍性保障机制可用性分区容忍的关键在于别让一个事务一来所有节点来完成这个很简单别要求所有节点共同同时参与某个事务即可。
一致性分区容忍性保障机制老实说都产生分区了哪还可能获得实时一致性。
但要保证最终一致性也不简单一旦产生分区如何保证同一时刻只会产生一份提议呢
换句话说如何保障仍然只有一个脑呢下面我们来看下 PAXOS 算法是如何解决脑裂问题的。
这里可以发散下所谓的“脑”其实就是具备写能力的系统“非脑”就是只具备读能力的系统对应了 MySQL 集群中的从库。
下面是一段摘自维基百科的 PAXOS 定义
Paxos is a family of protocols for solving consensus in a network of unreliable processors (that is, processors that may fail).
大致意思就是说PAXOS 是在一群不是特别可靠的节点组成的集群中的一种共识机制。
Paxos 要求任何一个提议至少有 (N/2)+1 的系统节点认可才被认为是可信的这背后的一个基础理论是少数服从多数。
想象一下如果多数节点认可后整个系统宕机了重启后仍然可以通过一次投票知道哪个值是合法的多数节点保留的那个值。
这样的设定也巧妙的解决了分区情况下的共识问题因为一旦产生分区势必最多只有一个分区内的节点数量会大于等于 (N/2)+1。
通过这样的设计就可以巧妙的避开脑裂当然 MySQL 集群的脑裂问题也是可以通过其他方法来解决的比如同时 Ping 一个公共的 IP成功者继续为脑显然这就又制造了另外一个单点。
如果你了解过比特币或者区块链你就知道区块链的基础理论也是 PAXOS。区块链借助 PAXOS 对最终一致性的贡献来抵御恶意篡改。
而本文涉及的分布式应用系统则是通过 PAXOS 来解决分区容忍性。再说本质一点一个是抵御部分节点变坏一个是防范部分节点失联。
大家一定听说过这样的描述PAXOS 是唯一能解决分布式一致性问题的解法。
这句话越是理解越发觉得诡异这会让人以为 PAXOS 逃离于 CAP 约束了所以个人更愿意理解为PAXOS 是唯一一种保障分布式系统最终一致性的共识算法所谓共识算法就是大家都按照这个算法来操作大家最后的结果一定相同。
PAXOS 并没有逃离 CAP 魔咒毕竟达成共识是 (N/2)+1 的节点之间的事剩下的 (N/2)-1 的节点上的数据还是旧的这时候仍然是不一致的。
所以 PAXOS 对一致性的贡献在于经过一次事务后这个集群里已经有部分节点保有了本次事务正确的结果共识的结果这个结果随后会被异步的同步到其他节点上从而保证最终一致性。
以下摘自维基百科
Paxos is a family of protocols for solving consensus in a network of unreliable processors (that is, processors that may fail).Quorums express the safety (or consistency) properties of Paxos by ensuring at least some surviving processor retains knowledge of the results.
另外 PAXOS 不要求对所有节点做实时同步实质上是考虑到了分区情况下的可用性通过减少完成一次事务需要的参与者个数来保障系统的可用性。
②OceanBase 的 CAP 分析
上文提到过单元化架构中的成千山万的应用就像是计算器本身无 CAP 限制其 CAP 限制下沉到了其数据库层也就是蚂蚁自研的分布式数据库 OceanBase本节简称 OB。
在 OB 体系中每个数据库实例都具备读写能力具体是读是写可以动态配置参考第二部分。
实际情况下大部分时候对于某一类数据固定用户号段的数据任意时刻只有一个单元会负责写入某个节点其他节点要么是实时库间同步要么是异步数据同步。
OB 也采用了 PAXOS 共识协议。实时库间同步的节点包含自己个数至少需要 (N/2)+1 个这样就可以解决分区容忍性问题。
下面我们举个马老师改英文名的例子来说明 OB 设计的精妙之处
假设数据库按照用户 ID 分库分表马老师的用户 ID 对应的数据段在 [0-9]开始由单元 A 负责数据写入。
假如马老师用户 ID 假设为 000正在用支付宝 App 修改自己的英文名马老师一开始打错了打成了 Jason MaA 单元收到了这个请求。
这时候发生了分区比如 A 网络断开了我们将单元 A 对数据段 [0,9] 的写入权限转交给单元 B更改映射马老师这次写对了为 Jack Ma。
而在网络断开前请求已经进入了 A写权限转交给单元 B 生效后A 和 B 同时对 [0,9] 数据段进行写入马老师的英文名。
假如这时候都允许写入的话就会出现不一致A 单元说我看到马老师设置了 Jason MaB 单元说我看到马老师设置了 Jack Ma。
然而这种情况不会发生的A 提议说我建议把马老师的英文名设置为 Jason Ma 时发现没人回应它。
因为出现了分区其他节点对它来说都是不可达的所以这个提议被自动丢弃A 心里也明白是自己分区了会有主分区替自己完成写入任务的。
同样的B 提出了将马老师的英文名改成 Jack Ma 后大部分节点都响应了所以 B 成功将 Jack Ma 写入了马老师的账号记录。
假如在写权限转交给单元 B 后 A 突然恢复了也没关系两笔写请求同时要求获得 (N/2)+1 个节点的事务锁通过 no-wait 设计在 B 获得了锁之后其他争抢该锁的事务都会因为失败而回滚。
下面我们分析下 OB 的 CAP
分区容忍性OB 节点之间是有互相通信的需要相互同步数据所以存在分区问题OB 通过仅同步到部分节点来保证可用性。这一点就说明 OB 做了分区容错。
可用性分区容忍性OB 事务只需要同步到 N/2)+1 个节点允许其余的一小半节点分区宕机、断网等只要 (N/2)+1 个节点活着就是可用的。
极端情况下比如 5 个节点分成 3 份2:2:1那就确实不可用了只是这种情况概率比较低。
一致性分区容忍性分区情况下意味着部分节点失联了一致性显然是不满足的。但通过共识算法可以保证当下只有一个值是合法的并且最终会通过节点间的同步达到最终一致性。
所以 OB 仍然没有逃脱 CAP 魔咒产生分区的时候它变成 AP+最终一致性C。整体来说它是 AP 的即高可用和分区容忍。

结语
个人感觉本文涉及到的知识面确实不少每个点单独展开都可以讨论半天。回到我们紧扣的主旨来看双十一海量支付背后技术上大快人心的设计到底是啥
我想无非是以下几点
基于用户分库分表的 RZone 设计。每个用户群独占一个单元给整个系统的容量带来了爆发式增长。
RZone 在网络分区或灾备切换时 OB 的防脑裂设计PAXOS。我们知道 RZone 是单脑的读写都在一个单元对应的库而网络分区或者灾备时热切换过程中可能会产生多个脑OB 解决了脑裂情况下的共识问题PAXOS 算法。
基于 CZone 的本地读设计。这一点保证了很大一部分有着“写读时间差”现象的公共数据能被高速本地访问。
剩下的那一丢丢不能本地访问只能实时访问 GZone 的公共配置数据也兴不起什么风作不了什么浪。
比如用户创建这种 TPS不会高到哪里去。再比如对于实时库存数据可以通过“页面展示查询走应用层缓存”+“实际下单时再校验”的方式减少其 GZone 调用量。
而这就是蚂蚁 LDC 的 CRG 架构相信 54.4 万笔/秒还远没到 LDC 的上限这个数字可以做到更高。
当然双 11 海量支付的成功不单单是这么一套设计所决定的还有预热削峰等运营+技术的手段以及成百上千的兄弟姐妹共同奋战特此在这向各位双 11 留守同学致敬。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |