

二、Java框架基础02 XML
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
二、XML
2.1 XML 简介
XML 即可扩展标记语言一种简单的数据存储语言使用一系列简单的标记来描述结构化数据
XML 的特点
- XML 与操作系统编程语言的开发平台无关
- 规范统一实现不同系统之间的数据交互
2.1.1 XML 的文档结构
以下是 XML 代码描述图书的信息
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="bk101">
<title>.NET高级编程</title>
<author>王珊</author>
<description>包含C#框架和网络编程等</description>
</book>
<book id="bk102">
<title>XML基础编程</title>
<author>李明明</author>
<description>包含XML基础概念和基本用法</description>
</book>
</books>
- 通过以上代码来具体了解 XML 文档结构
2.1.2 XML 声明
<?xml version="1.0" encoding="UTF-8"?>表示 XML 声明用于标明这是一个 XML 文件- XML 声明主要有以下部分组成
- version 文档符合 XML 1.0 规范
- encoding 文档字符编码默认为 UTF-8
- 对于任何一个 XML 文档都是固定格式
2.1.3 标签
- XML 中通过用尖括号
<>括起来的各种标签来标记数据 - 标签必须成对使用必须有开始标签
<>和 结束标签</> - 标签之间是标签描述的内容
- 例如
<author>王珊</author>则表示作者信息
2.1.4 元素
-
XML 文档的主要部分是元素
-
元素由开始标签、结束标签和元素内容注册
-
元素内容指开始标签和结束标签之间的内容可以包含子元素字符数据等
-
元素的命名规则如下
- 名称中可以包含字母、数字或其他的字符
- 名称不能以数字或标点符号开始
- 名称不能以字符
xml、XML等开始 - 名称中不能包含空格
- 元素允许是空元素如
<title></title>、<title/>
-
根元素
- 每个 XML 文档必须有且仅有一个根元素如
<books></books> - 根元素是一个完全包括文档中其他所有元素的元素
- 根元素的起始标签要放在所有其他元素的起始标签之前
- 根元素的结束标签要放在所有其他元素的结束标签之后
- 每个 XML 文档必须有且仅有一个根元素如
-
属性
<book id="bk101">标签中使用 id 属性描述图书的编号信息- 属性的定义语法如下
<元素名 属性名="属性值">- 属性值用双引号包裹
- 一个元素可以有多个属性多个属性之间用空格隔开
- 元素中不能直接包含
<、"、& - 属性只能加在元素的起始标签上
-
XML 中的特殊字符的处理
- 在 XML 中有时在元素的文本中会涉及一些特殊字符
<>'"& - 使用这些字符需要用到 XML 中的预定义实体代替
- XML 中的预定义实体和特殊字符的对应关系
特殊字符 实体名称 < < > > & &" "’ ' - 在 XML 中有时在元素的文本中会涉及一些特殊字符
-
CDATA - 未解析字符数据
-
术语 CDATA 是不应该由 XML 解析器解析的文本数据。
-
像
<和&字符在 XML 元素中都是非法的。 -
<会产生错误因为解析器会把该字符解释为新元素的开始。 -
&会产生错误因为解析器会把该字符解释为字符实体的开始。 -
CDATA 部分中的所有内容都会被解析器忽略
-
-
CDATA 语法格式如下
<![CDATA[要显示的字符]]>
2.2 解析 XML 概述
在实际应用当中经常需要对 XML 文档进行各种操作
如在应用程序启动时去读取 XML 配置文件信息
或把数据库中的内容读取出来转为 XML 文档形式
这种情况就要运用到 XML 文档的解析技术
目前常用的 XML 解析技术有 4 种
2.2.1 DOM
- DOM 是基于 XML 的树结构来完成解析的
- DOM 解析 XML 文档时会根据读取的文档构建一个驻留内存的树结构
- 使用 DOM API 可以操作这个树结构
- 支持删除、修改、重新排列等多种功能
- 但 DOM 解析同时也比较消耗资源
2.2.2 SAZ
- SAZ 是基于事件的解析为了解决 DMO 解析的资源消耗而出现的
- SAZ 是通过事件处理器完成对文档的解析
- SAZ 不用事先调入整个文档所以它的优势就是占用资源少内存消耗小
- 在解析数据量较大的 XML 文档时会采用这种方式
2.2.3 JDOM
- JDOM 是针对 Java 的特定文档模型
- 它简化了与 XML 的交互并且币使用 DOM 更快
- JDOM 仅使用具体类而不使用接口在某方面简化了 API
- 但是也限制了灵活性
- API 大量使用了 Java 集合类型对于属性这类的 Java 开发者而简化了使用
2.2.4 DOM4J
- DOM4J 是一个非常优秀的 Java XML API
- 具有性能优异、功能强大、易用的特点
- DOM4J 用于在 Java 平台上使用 Java 集合框架处理 XML、XPath 和 XSLT
- DOM4J 大量使用接口面向接口编程使它币 JDOM 更加灵活
2.3 使用 DOM 读取 XML 数据
2.3.1 DOM 概念
- DOM 即文档对象模型
- DOM 把 XML 文件映射成一课倒挂的 “树”
- 以根元素为根节点每个节点都以对象形式存在
- 通过存取这些对象就能存取 XML 文档的内容
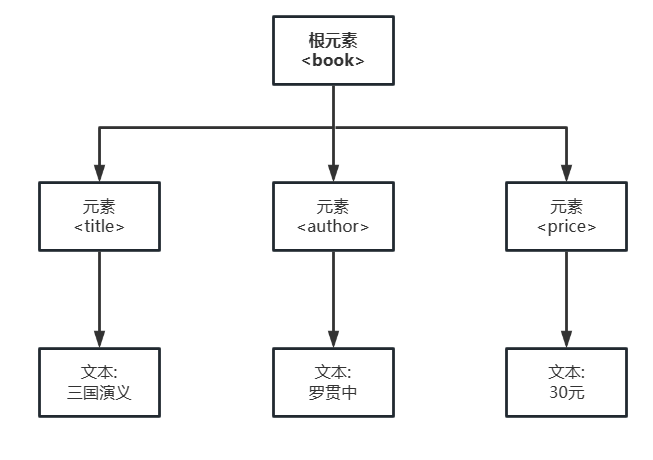
- 例如创建文件 book.xml 并保存book.xml 内容如下
<?xml version="1.0" encoding="UTF-8"?>
<book id="bk101">
<title>三国演义</title>
<author>罗贯中</author>
<price>30元</price>
</book>
- book.xml 对应的 DOM 树结构
2.3.2 使用 DOM 读取手机收藏信息
- 可以使用 JAXP 来解析 XML
- JAXP 包含 3 个包这 3 个包都在 JDK 中
- org.w3c.domW3C 推荐的用于使用 DOM 解析 XML 文档的接口
- org.xml.sax用于使用 SAZ 解析 XML 文档的接口
- javax.xml.parsers解析其工厂工具获得并配置特殊的解析器
- 使用 DOM 解析 XML 时需要导入这些包中相关的类
- JAXP 会把 XML 文档转换成一个 DOM 树
- 使用 DOM 解析 XML 文档的步骤如下
- 创建解析器工厂对象即 DocumentBuilderFactory 对象
- 由解析器工厂对象创建解析器对象即 DocumentBuilder 对象
- 由解析器对象对指定的 XML 文件进行解析构建相应的 DOM 数创建 Document 对象
- 以 Document 对象为起点对DOM 树的节点进行增加、删除、修改、查询等操作
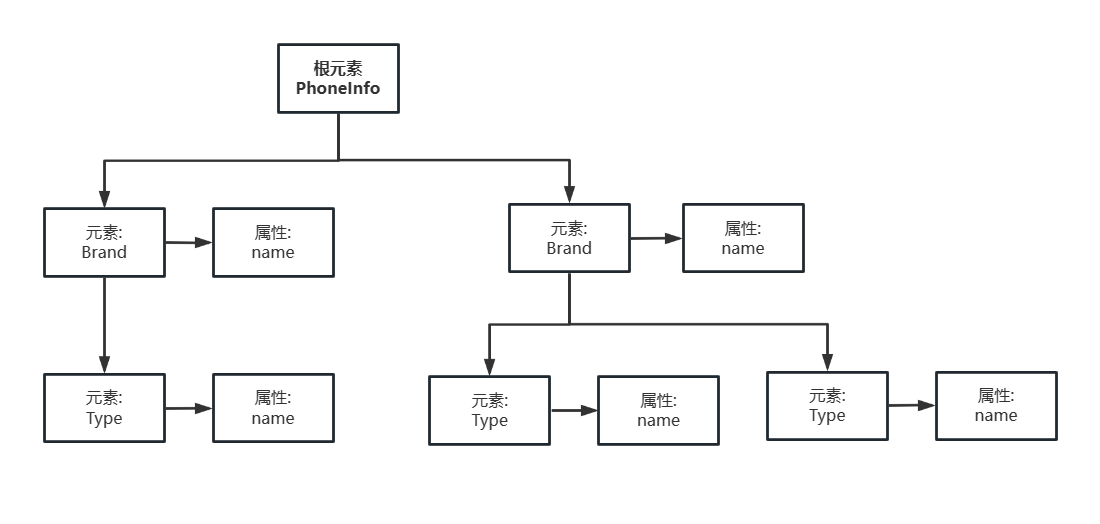
2.3.3 使用 DOM 读取 XML 数据使用 DOM 读取手机收藏信息中的品牌和型号信息 示例
XML 文档代码如下
<?xml version="1.0" encoding="UTF-8"?>
<PhoneInfo>
<Brand name="华为">
<Type name="P90"/>
</Brand>
<Brand>
<Type name="iPhone Z"/>
<Type name="iPhone ZL"/>
</Brand>
</PhoneInfo>
手机收藏信息的 XML 文档对应的 DOM 树主要结构
根据使用 DOM 解析 XML 的文档步骤关键代码如下
package Test01;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.IOException;
public class Test01 {
public static void main(String[] args) throws ParserConfigurationException, IOException, SAXException {
//得到 DOM 解析器的工厂实例
DocumentBuilderFactory dbf=DocumentBuilderFactory.newDefaultInstance();
//从 DOM 工厂获取 DOM 解析器
DocumentBuilder db=dbf.newDocumentBuilder();
//解析 XML 文档等到一个 Document 对象即DOM数
//xml 文件位置从 src包下开始
Document doc= db.parse("src/main/java/Test01/收藏信息.xml");
//等到所有的 Brand 节点列表信息
NodeList brandList=doc.getElementsByTagName("Brand");
//循环 Brand 信息
for (int i=0; i<brandList.getLength();i++){
//获取第 i 个 Brand 元素信息
Node brand=brandList.item(i);
//获取第 i 个 Brand 元素的 name属性
Element element= (Element) brand;
String attrValue=element.getAttribute("name");
//获取第 i 个 Brand 元素的所有子元素的 name 属性值
NodeList types=element.getChildNodes();
for (int j = 0; j <types.getLength() ; j++) {
Node node=types.item(j);
if (node.getNodeType()==Node.ELEMENT_NODE){
Element typeElement= ((Element) types.item(j));
String type=typeElement.getAttribute("name");
System.out.println("手机"+attrValue+type);
}
}
}
}
}
2.3.4 使用 DOM 解析 XML 时主要使用以下对象
Node 对象
- Node 对象是 DOM 结构中的基本对象代表了文档树中的一个抽象节点
- Node 对象的主要方法如下
| 方法名 | 说明 |
|---|---|
| getChildNodes() | 返回包含此节点所有子节点 NodeList |
| getFirstChild() | 如果节点存在子节点则返回第一个子节点 |
| getLastChild() | 如果节点存在子节点则返回最后一个子节点 |
| getNextSibling() | 返回在 DOM 树中这个节点的下一个兄弟节点 |
| getPreviousSibling() | 返回在 DOM 树中这个节点的上一个兄弟节点 |
| getNodeName() | 返回节点的名称 |
| getNodeValue() | 返回节点的值 |
| getNodeType() | 返回节点的类型 |
NodeList 对象
- NodeList 对象是指包含了一个或多个节点 (Node) 列表
- 可以通过方法来获取列表中的元素
- NodeList 对象的常用方法
| 方法名 | 说明 |
|---|---|
| getLength() | 返回列表长度 |
| item(int idnex) | 返回指定位置的 Node 对象 |
Document 对象
- Document 对象代表整个 XML 文档
- 所有其他的 Node 都以一定的顺序包含在 Document 对象之内
- 它是对 XML 文档进行操作的起点先通过解析 XML 源文件获取 Document 对象然后来执行后续的操作
- Document 对象的主要方法
| 方法名 | 说明 |
|---|---|
| getElementsByTagName(String name) | 返回一个 NodeList 对象包含所有给定标签名的标签 |
| getDocumentElement() | 返回一个代表这个 DOM 树的根节点的 Element 对象 |
Element 对象
- Element 对象代表 XML了文档中的 标签元素
- 在标签中可以包含属性因而 Element 对象中也有存取属性的方法
- Element 对象方法如下
| 方法名 | 说明 |
|---|---|
| getAttribute(String attributename) | 返回标签中给定属性名称的属性的值 |
| getElementsByTagName(String name) | 返回具有给定标签名称的所有后代 Elements 的 NodeList |
注意事项
- XML 文档中的空白符也会被作为对象映射在 DOM 树中
- 所以直接调用 Node 对象的 getChildNodes() 方法有时会出现一些问题
- 解决方案如下
- 使用 Element 的 getElementByTagName(String name)返回的 NodeList 对象就是所期待的对象
- 调用 Node 的 getChildNodes() 方法得到 NodeList 对象每次通过 item() 方法提取 Node 对象然后判断
- 判断
node.getNodeType()==Node.ELEMENT_NODE即判断是否为元素节点
2.4 使用 DOM4J 解析 XML
2.4.1 DOM4J API 概述
- 使用 DOM4J 只要了解 XML-DOM 模型就能使用
- DOM4J 主要接口都在 org.dom4j 这个包里定义
| 类 | 说明 |
|---|---|
| Attribute | 定义了 XML 属性 |
| Branch | 为能够包含子节点的节点定义了一个公共行为 |
| CDATA | 定义了 XML CDATA 区域 |
| CharacterData | 是一个标识接口标识基于字符的节点如 CDATA、Comment 和 Text |
| Comment | 定义了 XML 注释的行为 |
| Document | 定义了 XML 文档 |
| DocumentType | 定义 XML DOCTYPE 声明 |
| Element | 定义了 XML 元素 |
| ElementHandler | 定义了 Element 对象的处理器 |
| ElementPath | 被 ElementHandler 使用用于取得当前正在处理的路径层次信息 |
| Entity | 定义 XML 实体 |
| Node | 为 dom4j 中所有的 XML 节点定义了多态行为 |
| NodeFilter | 定义了在 dom4j 节点中产生的一个滤镜或谓词的行为 |
| ProcessingInstruction | 定义 XML 处理指令 |
| Text | 定义了 XML 文本节点 |
| Visitor | 用于实现 Visitor 模式 |
| XPath | 通过分析一个字符串提供一个 XPath 表达式 |
- 使用这些需要提前导入一个 dom4j 的包
<!-- https://mvnrepository.com/artifact/org.dom4j/dom4j -->
<dependency>
<groupId>org.dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>2.1.4</version>
</dependency>
2.4.2 使用 DOM4J 操作 XML 数据
1、Document 对象相关
- 读取 XML 文件获得 Document 对象
SAXReader reader=new SAXReader();
Document document=reader.read(new File("input.xml"));
2、节点相关
- 获得文档的根元素
Element rootElm=document.getRootElement();
- 取得某节点的单个子节点
Element memberElm=rootElm.element("member"); //member 是节点名
- 取得节点的文字
String text=emeberElm.getText();
//或者用下面这种方式
//取得根元素下的 name 子节点的文字
String text=rootElm.elementText("name");
- 在某个节点下添加子节点newMemberElm 是某个已存在的节点
Element ageElm=newMemberElm.addELment("age");
- 设置文字节点
ageElm.setText("29");
- 删除某节点
parentElm.remove(childElm);// childElm 是待删除的节点parentElm是其父节点
3、属性相关
- 取得某节点下的某属性
Element root=document.getRootElement();
Attribute attribute=toor.attribute("size"); //属性名 size
- 取得属性的值
String text=attribute.getText();
//也可以使用
String text2=root.element("name").attributeValue("firstname");
- 为某节点添加属性
newMemberElm.addAttribute("name","learningdom4j");
- 设置属性的值
Attribute attribute=root.attribute("name");
attribute.setText("learningdom4j");
- 删除某属性
Attribute attribute=root.attribute("size"); //属性名saize
root.remove(attribute)
e attribute=toor.attribute(“size”); //属性名 size
- 取得属性的值
~~~java
String text=attribute.getText();
//也可以使用
String text2=root.element("name").attributeValue("firstname");
- 为某节点添加属性
newMemberElm.addAttribute("name","learningdom4j");
- 设置属性的值
Attribute attribute=root.attribute("name");
attribute.setText("learningdom4j");
- 删除某属性
Attribute attribute=root.attribute("size"); //属性名saize
root.remove(attribute)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |