

AI算法工程师 | 09机器学习-概率图模型(二)朴素贝叶斯算法与文本分类(1)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
机器学习 - 概率图模型 之 朴素贝叶斯算法
一、贝叶斯与朴素贝叶斯算法
1、相关概念
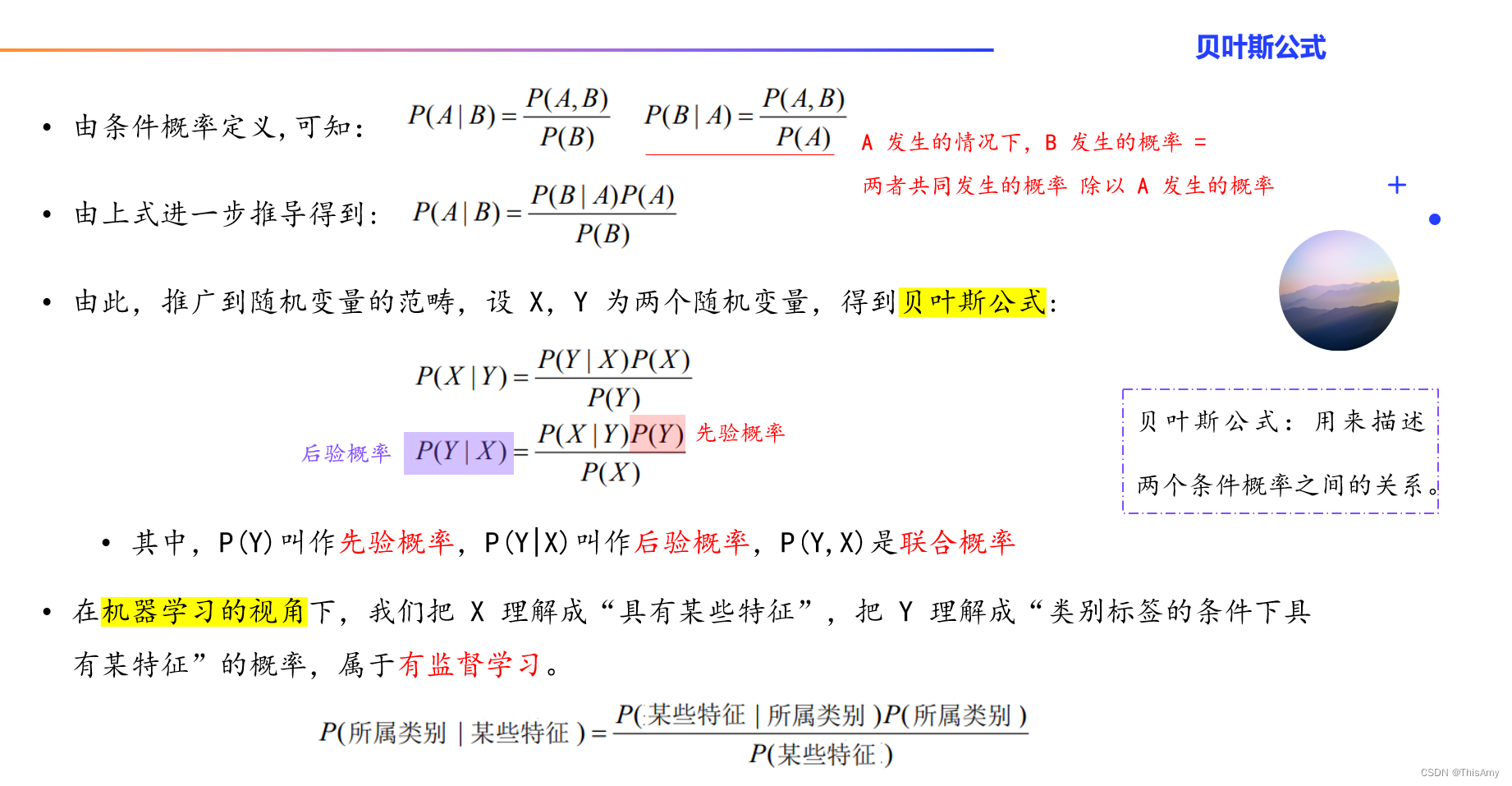
贝叶斯公式
贝叶斯公式最早是由英国神学家贝叶斯提出来的用来描述两个条件概率之间的关系。
朴素贝叶斯算法
用示例理解朴素贝叶斯
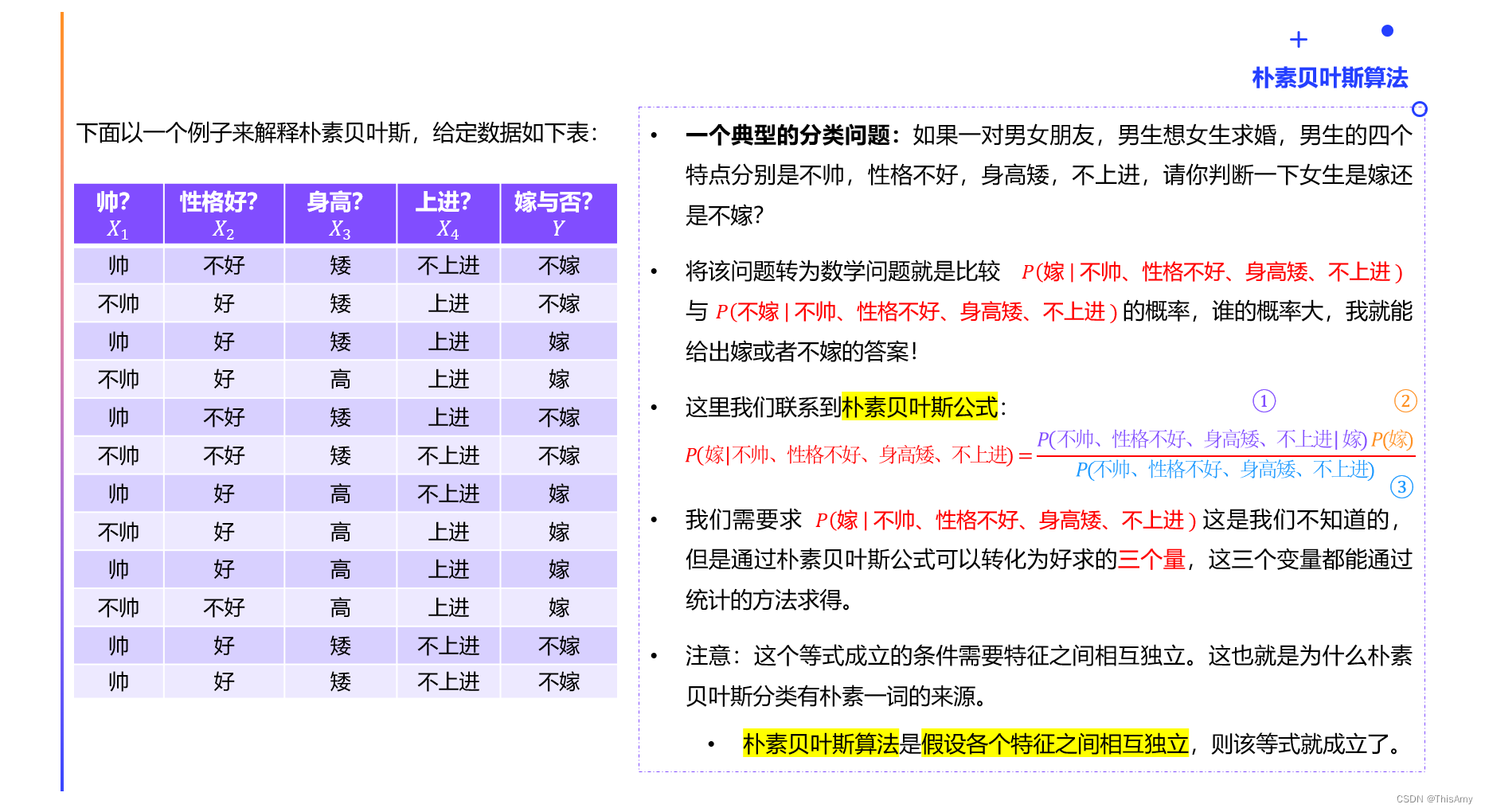
朴素贝叶斯的各特征间相互独立假设
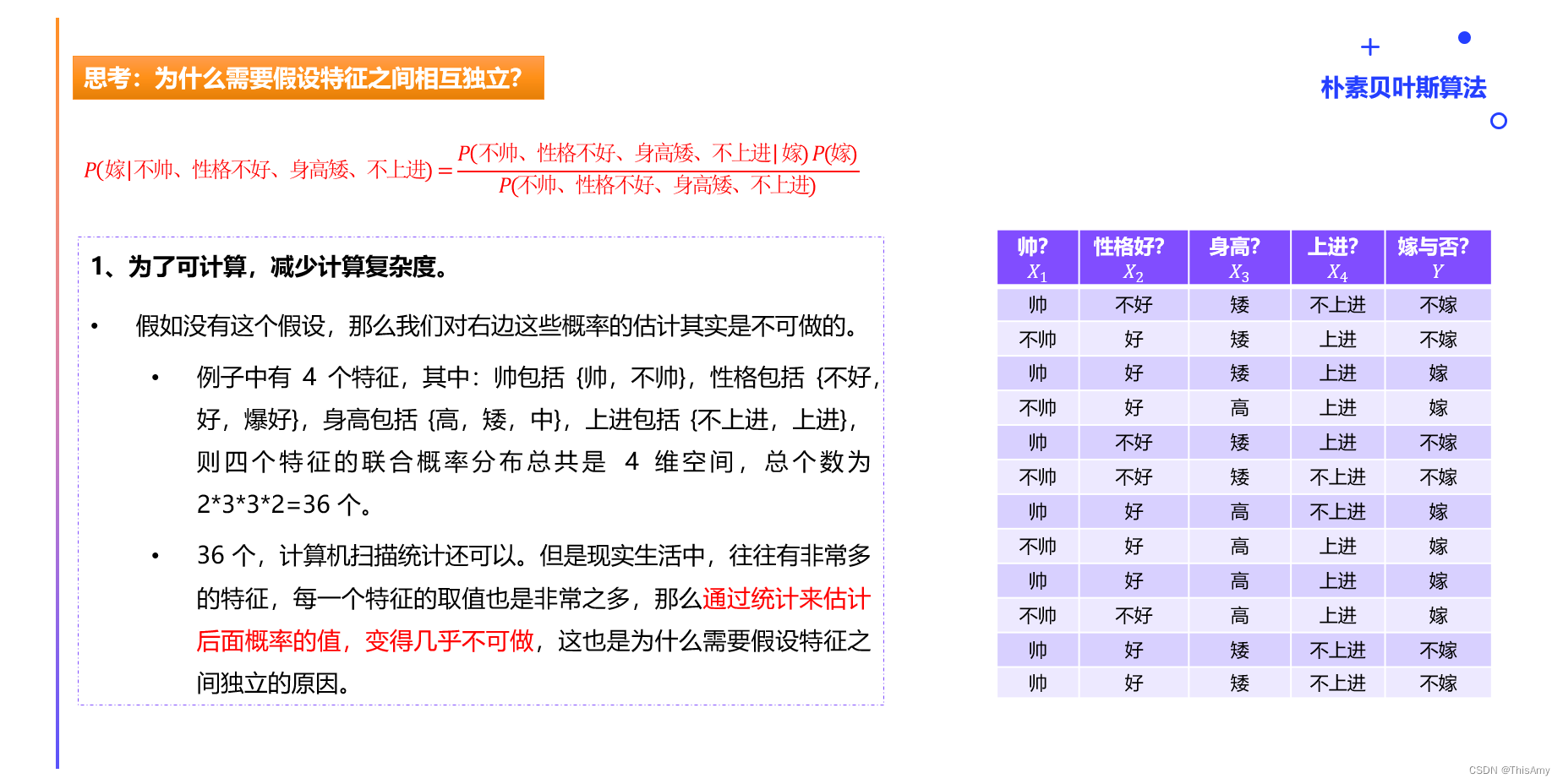
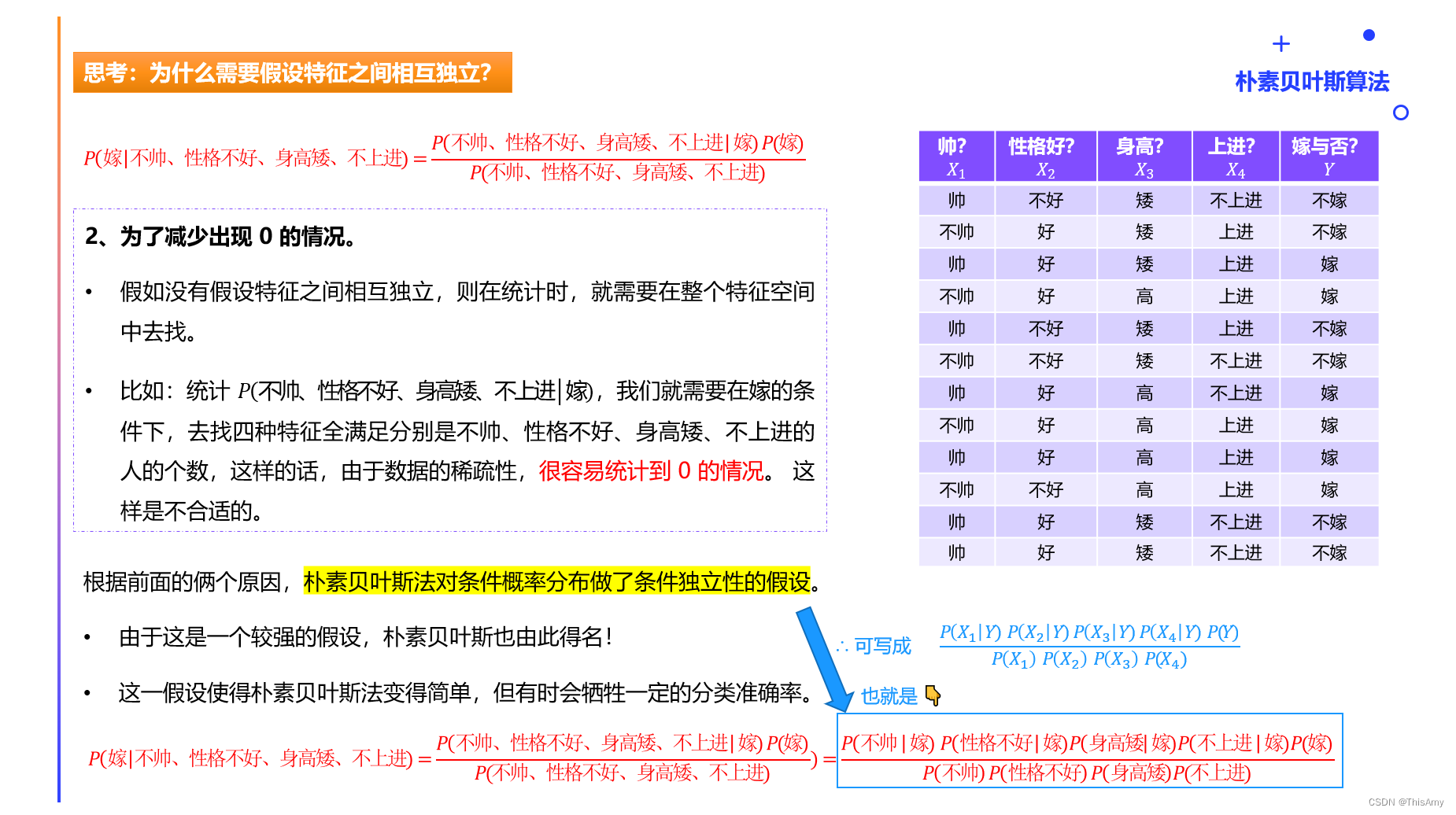
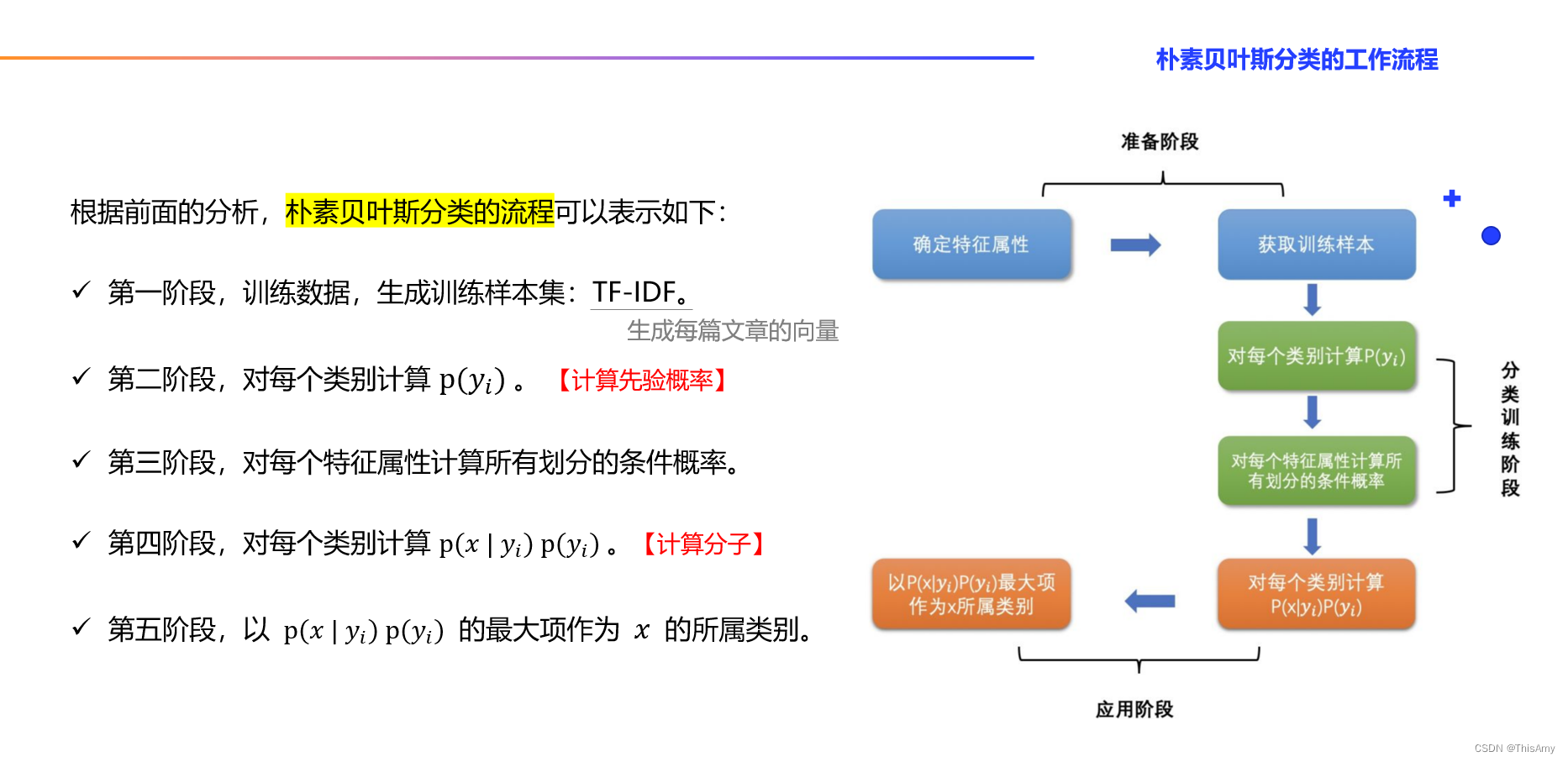
2、朴素贝叶斯分类的工作流程

3、朴素贝叶斯的优缺点
朴素贝叶斯优点
- 算法逻辑简单易于实现算法思路很简单只要使用贝叶斯公式转化即可
- 分类过程中时空开销小假设特征相互独立只会涉及到二维存储
朴素贝叶斯缺点
- 理论上朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此。
- 这是因为朴素贝叶斯模型假设属性之间相互独立这个假设在实际应用中往往是不成立的在属性个数比较多或者属性之间相关性较大时分类效果不好改善可先做数据的预处理如 PCA以减小相关性。
问既然相互独立假设在实际应用中往往不成立为何还需要朴素贝叶斯模型
答
-
朴素贝叶斯模型Naive Bayesian Model简称 NB 的朴素Naive的含义是“很简单很天真” 地假设样本特征彼此独立。
-
这个假设现实中基本上不存在但特征相关性很小的实际情况还是很多的所以这个模型仍然能够工作得很好。
二、文本分类
在处理文本分类之前引入两个概念one-hot 编码、TF-IDF
1、one-hot 编码

one-hot 表达
- 说明one-hot 表达是一种稀疏的表达方式。
- 特点相互独立地表示语料中的每个词。
- 词与词在句子中的相关性被忽略了这正符合朴素贝叶斯对文本的假设。
关于 one-hot 编码推荐参考的文章有
2、TF-IDF 词频-逆文档频率
概念的引入one-hot 编码存在一定的不足下面对其进行改进


TF-IDF 权重策略

TF-IDF

3、代码基于朴素贝叶斯实现文本分类使用 Python 手动实现
回顾
- 在进行算法实现前先来回顾一下朴素贝叶斯分类的工作流程
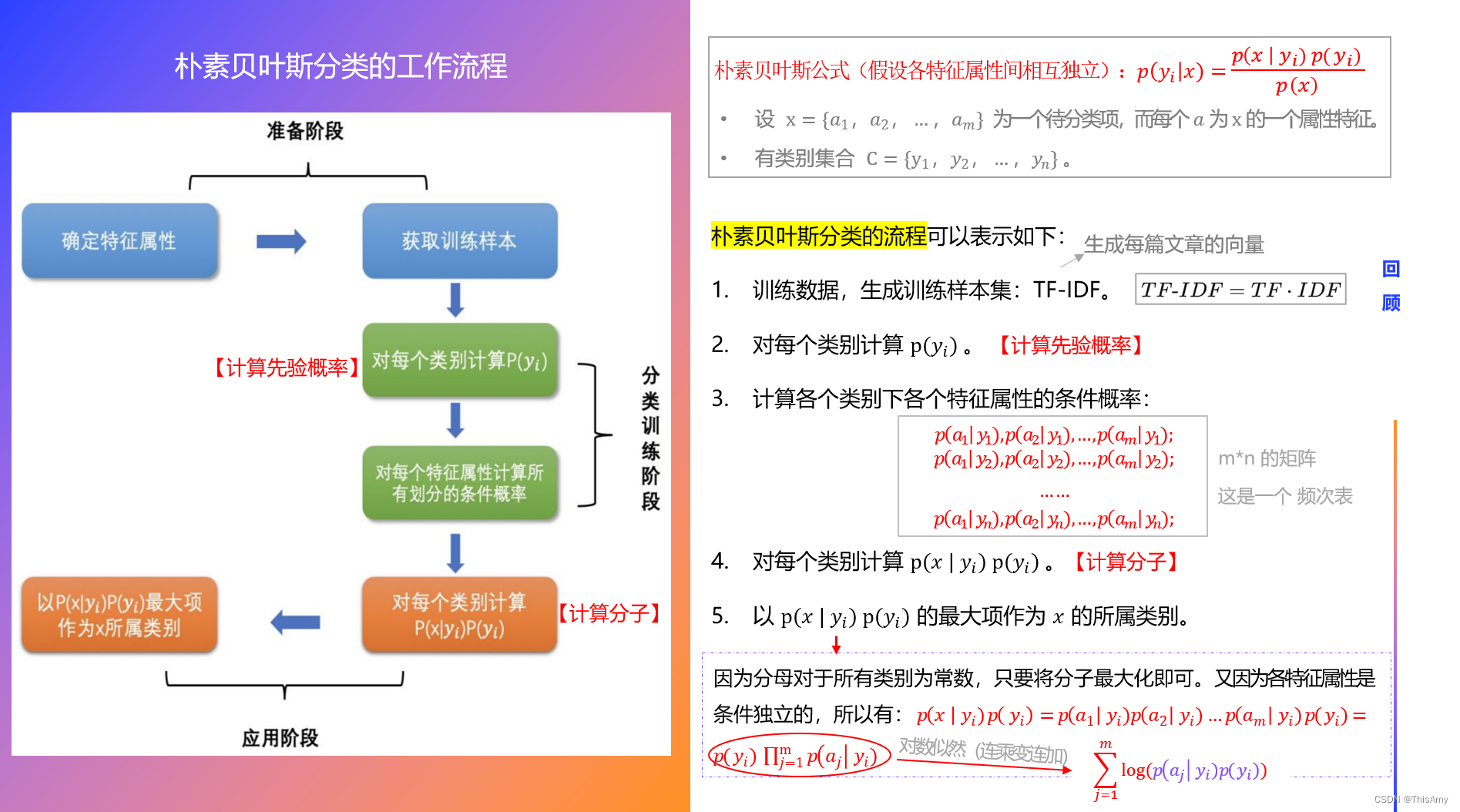
- 代码实现思路
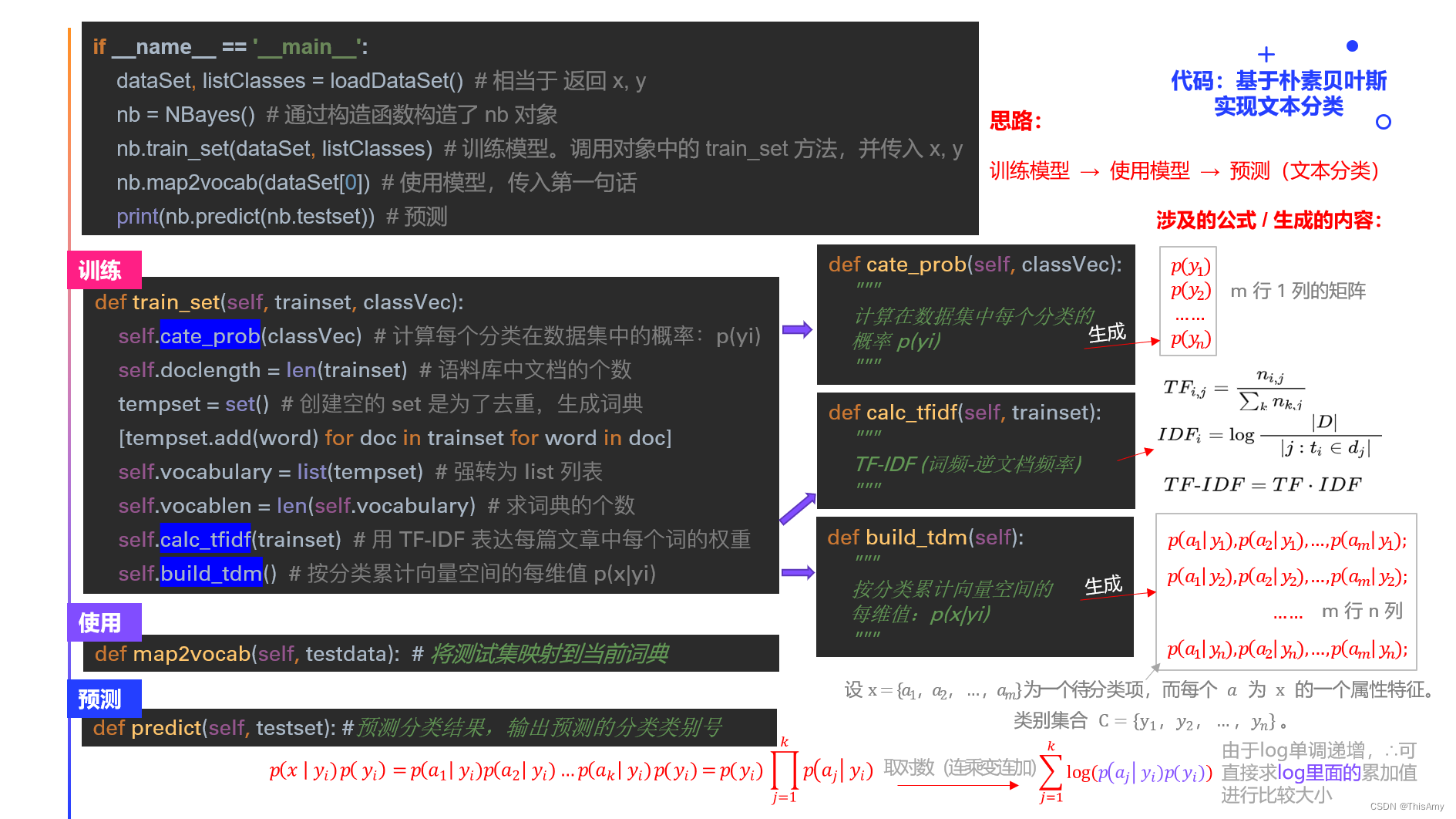
代码 工具PyCharm基于python3
import numpy as np
"""
对 朴素贝叶斯模型Naive Bayesian Model简称 NB 的实现并做文本分类
⭐ 学习时间2023.1.4再次梳理2023.1.25
"""
def loadDataSet():
"""
一个给定的数据集此处未使用文本分词而是直接给出了每句话分好词后的内容
· postingList:一个二维数组x每一个列表每行代表一句话分完词后的情况
· classVec:一维数组y代表某文章是否是'stupid'1该篇文章是0否
"""
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmatian', 'is', 'so', 'cute', 'I', 'love', 'him', 'my'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1] # 1表示该文章属于辱骂性的'stupid'0不是
return postingList, classVec # 相当于 返回 x, y
# 定义了一个类朴素贝叶斯模型Naive Bayesian Model简称 NB
class NBayes(object):
def __init__(self): # 构造函数
self.vocabulary = [] # 词典
self.idf = []
self.tf = []
self.tdm = 0 # p(x|yi)
self.Pcates = {} # p(yi)是一个类别词典
self.labels = [] # 存放类别号
self.doclength = 0 # 文档个数文档长度
self.vocablen = 0 # 词典个数词典长度
self.testset = 0 # 测试集
def cate_prob(self, classVec):
"""
计算在数据集中每个分类的概率 p(yi)
"""
self.labels = classVec
labeltemps = set(self.labels) # 去重
for labeltemp in labeltemps: # 分别对每一种类别分类求概率并赋值给 Pcates
# p(yi) = 某类别的个数/类别总个数。其中统计列表中重复的分类 self.labels.count(labeltemp) —— 这是 python 原生的一个方法
self.Pcates[labeltemp] = float(self.labels.count(labeltemp)) / float(len(self.labels))
def calc_wordfreq(self, trainset):
"""
生成普通的词频向量用的整型计数方式未进行归一化不是概率分布形式
"""
self.tf = np.zeros([self.doclength, self.vocablen])
self.idf = np.zeros([1, self.vocablen])
for index in range(self.doclength):
for word in trainset[index]:
self.tf[index, self.vocabulary.index(word)] += 1
for signleword in set(trainset[index]):
self.idf[0, self.vocabulary.index(signleword)] += 1
def calc_tfidf(self, trainset):
"""
TF-IDF (词频-逆文档频率)【目的生成每篇文章的向量】
"""
self.tf = np.zeros([self.doclength, self.vocablen]) # 定义 TF文章行*词典列初始化所有全为0有多少篇文章就有多少行列数为词典长度。
self.idf = np.zeros([1, self.vocablen]) # 定义 IDF1行*词典列1 行词典多长就有多少列。
for index in range(self.doclength): # 遍历每篇文章取到每篇文章的索引号
for word in trainset[index]: # 取到每篇文章所对应的词的列表遍历每篇文章的每个词
# 统计每篇文章中每个词所对应的在一篇文章中出现的次数。其中self.vocabulary.index(word) 得到每个词所在词典中的索引号
self.tf[index, self.vocabulary.index(word)] += 1
# 消除不同句子长度导致的偏差。【求 TF 词频一篇文章对应的向量某词在文章中的出现次数 ÷ 一篇文章的长度 = 某一个给定的词语某词在该文章中出现的频率】
self.tf[index] = self.tf[index] / float(len(trainset[index]))
for singleword in set(trainset[index]): # 把一篇文章内容拿出来后做去重得到一篇文章中不同的词
# 统计整个语料库中每个词在几篇文章文档中出现
self.idf[0, self.vocabulary.index(singleword)] += 1 # 对一篇文章中出现不同的词进行累加加到 idf 中
self.idf = np.log(float(self.doclength) / self.idf) # IDF逆文档频率。分子语料库中文章的总数分母包含给定词语某一个词的文章数目; 之后取 log
self.tf = np.multiply(self.tf, self.idf) # 求的是 TF-IDF= TF × IDF词频-逆文档频率。
def build_tdm(self):
"""
按分类类别累计向量空间的每维值p(x|yi)
"""
self.tdm = np.zeros([len(self.Pcates), self.vocablen]) # 初始化构建一个 类别行*词典列 的矩阵
sumlist = np.zeros([len(self.Pcates), 1]) # 类别行有多少类就有多少行*1列
for index in range(self.doclength): # 遍历每篇文章
# 将同一个类别的词向量空间值加和相当于加权求和
self.tdm[self.labels[index]] += self.tf[index] # labels[index]某篇文章的类别tf[index]某篇文章的TF-IDF向量包含每个词对应的权重
# 统计每个分类的总值是一个标量
sumlist[self.labels[index]] = np.sum(self.tdm[self.labels[index]])
self.tdm = self.tdm / sumlist # 生成 p(x|yi)
def train_set(self, trainset, classVec):
self.cate_prob(classVec) # 计算每个分类在数据集中的概率p(yi)
self.doclength = len(trainset) # 语料库中文档的个数
tempset = set() # 创建空的 set 是为了去重生成词典
# 生成词典
# 下面是 python 列表生成式其含义为
# ·双重for循环先遍历 trainset 中的每篇文章doc再遍历 每篇doc 得到里面的词word最后将每个word 加入 tempset 中。
# · 添加完后set 集合tempset中会有所有词取值完后的结果。由于生成完后列表本身是不需要的所以未用变量去接它。
[tempset.add(word) for doc in trainset for word in doc]
self.vocabulary = list(tempset) # 强转为 list 列表列表带有顺序我们可根据索引号去查询到列表中具体某个元素的值
self.vocablen = len(self.vocabulary) # 求词典的个数
# 计算词频数据集
# self.calc_wordfreq(trainset) # 可用词频表达
self.calc_tfidf(trainset) # 也可用 TF-IDF 表达每篇文章中每个词的权重
# 按分类累计向量空间的每维值 p(x|yi)
self.build_tdm()
def map2vocab(self, testdata):
"""
将测试集映射到当前词典 【说明此处是简化的方式由于我们的测试集中只有一条样本所以只计算了 count 值词出现的次数】
待改进之处训练集中计算得是 TF-IDF测试集中也应该计算 TF-IDF
"""
self.testset = np.zeros([1, self.vocablen])
for word in testdata: # 遍历文本中每个词进行索引化赋值累加得到词在文本中出现的次数
self.testset[0, self.vocabulary.index(word)] += 1 # self.vocabulary.index(word)找到某词在词典中的索引号
def predict(self, testset):
"""
预测分类结果输出预测的分类类别号
"""
if np.shape(testset)[1] != self.vocablen:
# 如果向量化的测试集长度与词典不相等退出程序
print('输入错误')
exit(0)
predvalue = 0
preclass = '' # 类别号
for tdm_vect, keyclass in zip(self.tdm, self.Pcates): # 相当于遍历字典
# 遍历每个类别
# P(x|yi) P(yi)
print(testset, testset.shape)
print(tdm_vect, len(tdm_vect))
print(self.Pcates[keyclass])
# temp 是对应位置的某个类别的一些概率乘积【P(x|yi)*P(yi)】的累加值此处可看成对数似然——原公式的连乘可变成添加log后的连加 又∵log是单调递增 ∴ 可不用管log直接求累加值
temp = np.sum(testset * tdm_vect * self.Pcates[keyclass])
# 计算最大分类值
if temp > predvalue:
predvalue = temp
preclass = keyclass
return preclass, temp
if __name__ == '__main__':
dataSet, listClasses = loadDataSet() # 加载数据相当于 返回 x, y
nb = NBayes() # 通过构造函数构造了 nb 对象
nb.train_set(dataSet, listClasses) # 训练模型。调用对象中的 train_set 方法并传入 x, y
nb.map2vocab(dataSet[0]) # 使用模型传入第一句话
print(nb.predict(nb.testset)) # 预测
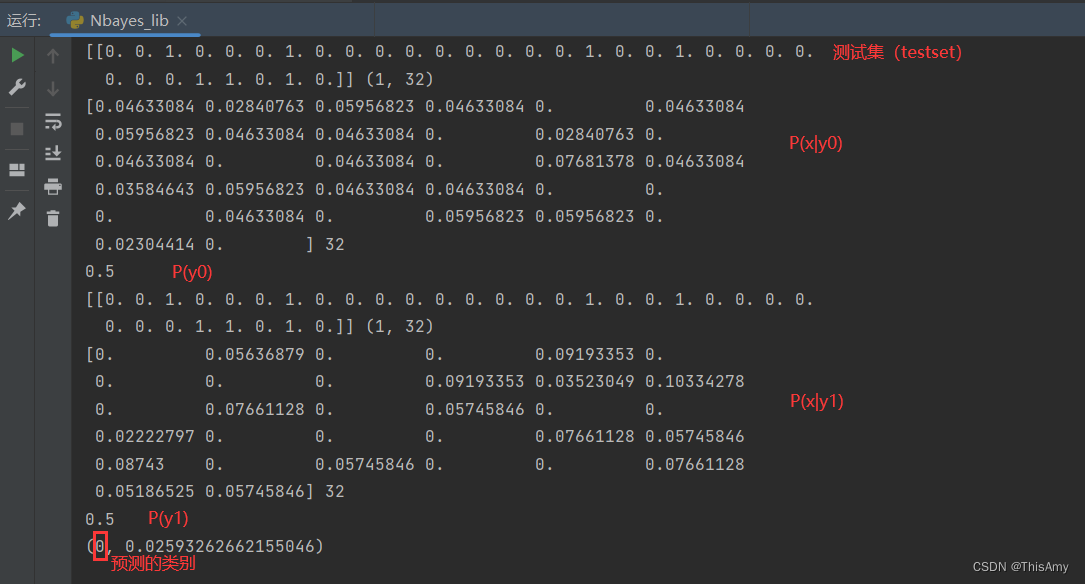
运行结果
补充下面是上述代码中涉及的部分 python 知识点梳理
-
在 NBayes 类里 train_set 函数中
[tempset.add(word) for doc in trainset for word in doc]属于 python 的列表生成式- 含义
# 列表生成式: #双重for循环先遍历 trainset 中的每篇文章doc再遍历 每篇doc 得到里面的词word; # 最后将每个word 加入 tempset创建的set 集合中。 [tempset.add(word) for doc in trainset for word in doc] - 示例列表生成式
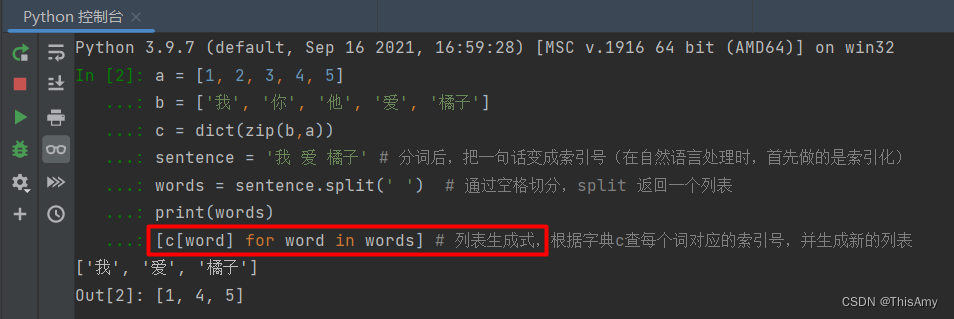
- 含义
-
在 NBayes 类里 cate_prob 函数中统计列表中重复的分类
self.labels.count(labeltemp)涉及 python 的一个原生方法 count()- 含义
self.labels.count(labeltemp) # 统计列表self.labels中 labeltemp 类别 的个数 - 示例 count() 用于统计某个元素在列表中出现的次数
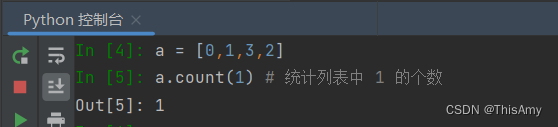
- 含义
—— 说明本文写于 2023.1.3、2023.1.24~1.25文中内容基于 python3使用工具 PyCharm 编写的代码