

生成式预训练模型(Generative Pre-trained Models)概述
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
生成式预训练模型(Generative Pre-trained Models)
生成式预训练模型(Generative Pre-trained Models)是一种革命性的技术,通过预训练模型在大规模无标签文本数据上进行自监督学习,实现了强大的自然语言处理能力。这些模型的核心思想是通过学习大量文本数据的统计模式,获得对语言的深层理解和生成能力。
预训练过程
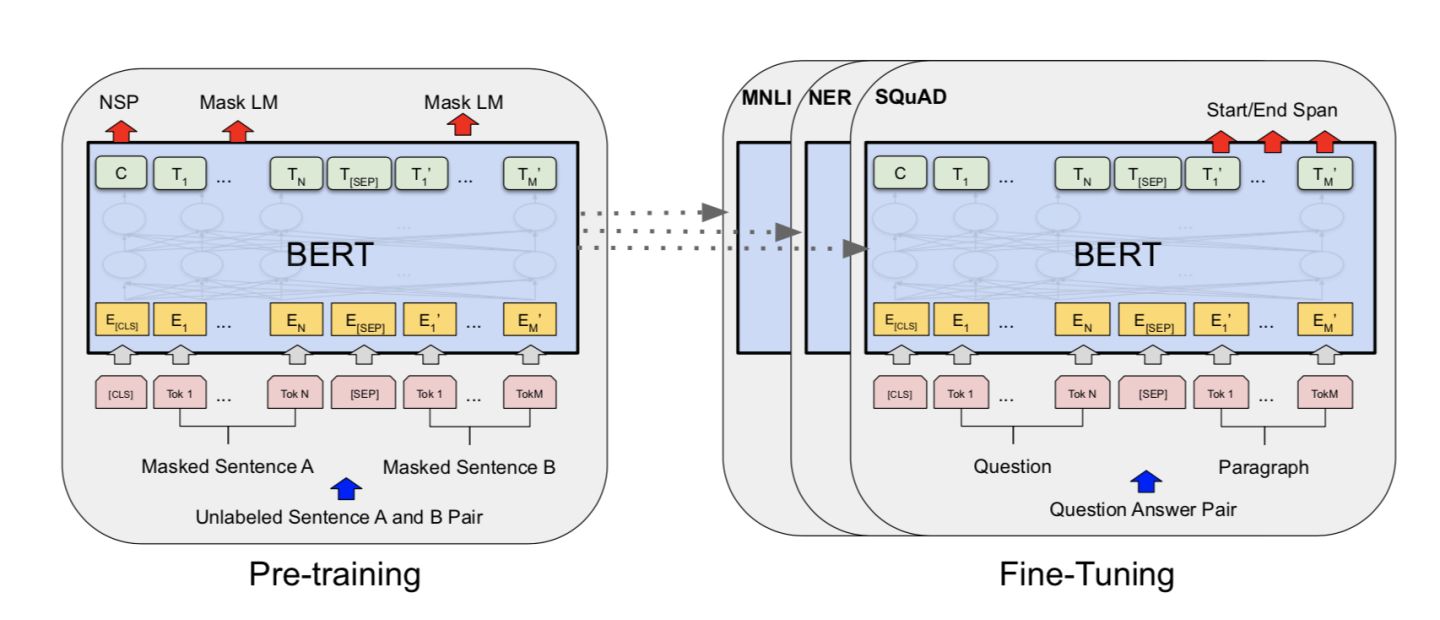
生成式预训练模型的预训练阶段通常采用了Transformer架构,如BERT(Bidirectional Encoder Representations from Transformers)或GPT(Generative Pre-trained Transformer)。这些模型通过自编码任务进行预训练,如掩码语言建模(Masked Language Modeling)或下一个句子预测(Next Sentence Prediction)。
在掩码语言建模任务中,模型需要预测句子中被随机遮盖的部分。通过这种方式,模型被迫学习上下文中的语义和语法规则,从而捕捉到单词之间的关联性。在下一个句子预测任务中,模型需要判断两个句子是否连续,从而促使模型学习到句子级别的语义关系。
预训练模型通常使用大规模的互联网文本数据进行训练,例如维基百科、新闻文章和网页内容。预训练过程中的优化算法通常采用变种的随机梯度下降(Stochastic Gradient Descent)和自适应优化器(如Adam)。
微调过程
在预训练阶段完成后,生成式预训练模型需要在特定任务上进行微调,以将通用语言表示转化为特定任务的表示。微调阶段使用有标签的任务特定数据集,如情感分类、命名实体识别或机器翻译数据集。
微调过程的目标是通过进一步训练模型参数,使其适应具体任务的需求。通常,微调采用更小的学习率和较少的训练轮次,以避免破坏预训练模型中学到的知识。在微调期间,模型的参数根据任务特定的损失函数进行优化,以提高在特定任务上的性能。
技术细节和底层论文
生成式预训练模型的发展离不开一系列的技术细节和重要论文。以下是一些与生成式预训练模型相关的经典论文:
-
BERT:《Pre-training of Deep Bidirectional Transformers for Language Understanding》(Devlin et al., 2018)是一篇开创性的论文,引入了BERT模型,通过双向Transformer编码器的预训练来捕捉单词和句子的上下文信息。BERT通过多层自注意力机制(self-attention)和全连接层构建了深度的表示学习网络,为自然语言处理任务带来了显著的性能提升。
-
GPT:《Improving Language Understanding by Generative Pre-training》(Radford et al., 2018)是GPT模型的原始论文,采用了单向Transformer解码器进行预训练,并在各种下游任务上展现出优秀的表现。
-
GPT-2:《Language Models are Unsupervised Multitask Learners》(Radford et al., 2019)介绍了GPT-2模型,该模型在预训练阶段引入了更大规模的数据集和模型参数,并且通过多任务学习取得了更好的性能。
-
T5:《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》(Raffel et al., 2019)提出了T5模型,它通过将多种自然语言处理任务统一为文本到文本转换任务,并进行大规模预训练和微调,取得了优秀的泛化能力。
-
GPT-3:《Language Models are Few-Shot Learners》(Brown et al., 2020)描述了GPT-3模型,它引入了更大规模的模型和更广泛的任务集合,通过少量示例进行快速学习和推理。
这些论文对生成式预训练模型的发展和突破起到了重要的推动作用。通过不断改进和扩展这些技术,研究者们取得了令人瞩目的成果,使得生成式预训练模型在自然语言处理任务中取得了突破性的进展。
总结起来,生成式预训练模型通过在大规模无标签数据上进行预训练,通过自编码任务捕捉语言的统计模式和语义关系,并通过微调阶段将通用语言表示转化为特定任务的表示。这种技术的发展离不开Transformer架构和一系列重要的底层论文的贡献。通过生成式预训练模型,我们能够更好地理解和生成自然语言,推动自然语言处理技术的发展。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |