

迁移学习(ADDA)《Adversarial Discriminative Domain Adaptation》【已复现迁移】
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
论文信息
论文标题:Adversarial Discriminative Domain Adaptation
论文作者:Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell
论文来源:CVPR 2017
论文地址:download
论文代码:download
引用次数:3257
1 简介
本文主要探讨的是:源域和目标域特征提取器共享参数的必要性。
源域和目标域特征提取器共享参数的代表——DANN。
2 对抗域适应
标准监督损失训练源数据:
$\underset{M_{s}, C}{\text{min}} \quad \mathcal{L}_{\mathrm{cls}}\left(\mathbf{X}_{s}, Y_{t}\right)= \mathbb{E}_{\left(\mathbf{x}_{s}, y_{s}\right) \sim\left(\mathbf{X}_{s}, Y_{t}\right)}-\sum\limits _{k=1}^{K} \mathbb{1}_{\left[k=y_{s}\right]} \log C\left(M_{s}\left(\mathbf{x}_{s}\right)\right)\quad\quad(1)$
域对抗:首先使得域鉴别器分类准确,即最小化交叉熵损失 $\mathcal{L}_{\operatorname{adv}_{D}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, M_{s}, M_{t}\right)$:
$\begin{array}{l}\mathcal{L}_{\text {adv }_{D}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, M_{s}, M_{t}\right)= -\mathbb{E}_{\mathbf{x}_{s} \sim \mathbf{X}_{s}}\left[\log D\left(M_{s}\left(\mathbf{x}_{s}\right)\right)\right] -\mathbb{E}_{\mathbf{x}_{t} \sim \mathbf{X}_{t}}\left[\log \left(1-D\left(M_{t}\left(\mathbf{x}_{t}\right)\right)\right)\right]\end{array} \quad\quad(2)$
其次,源映射和目标映射根据一个受约束的对抗性目标进行优化(使得域鉴别器损失最大)。
域对抗技术的通用公式如下:
$\begin{array}{l}\underset{D}{\text{min}} & \mathcal{L}_{\mathrm{adv}_{D}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, M_{s}, M_{t}\right) \\\underset{M_{s}, M_{t}}{\text{min}} & \mathcal{L}_{\mathrm{adv}_{M}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, D\right) \\\text { s.t. } & \psi\left(M_{s}, M_{t}\right)\end{array}\quad\quad(3)$
2.1 源域和目标域映射
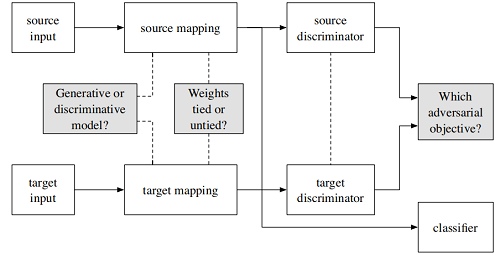
归结为三个问题:
-
- 选择生成式模型还是判别式模型?
- 针对源域与目标域的映射是否共享参数?
- 损失函数如何定义?
2.2 Adversarial losses
回顾DANN 的训练方式:DANN 的梯度反转层优化映射,使鉴别器损失最大化
$\mathcal{L}_{\text {adv }_{M}}=-\mathcal{L}_{\mathrm{adv}_{D}}\quad\quad(6)$
当训练 GANs 时,而不是直接使用 minimax,通常是用带有倒置标签[10]的标准损失函数来训
回顾 GAN :GAN将优化分为两个独立的目标,一个用于生成器,另一个用于鉴别器。训练生成器的时候,其中 $\mathcal{L}_{\mathrm{adv}_{D}}$ 保持不变,但 $\mathcal{L}_{\mathrm{adv}_{M}}$ 变成:
Note:$\mathbf{x}_{t}$ 代表噪声数据,这里是使得噪声数据尽可能迷惑鉴别器。


adversarial_loss = torch.nn.BCELoss() # 损失函数(二分类交叉熵损失)
generator = Generator() #生成器
discriminator = Discriminator() #鉴别器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) # 生成器优化器
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) # 鉴别器优化器
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False) #torch.Size([64, 1])
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False) #torch.Size([64, 1])
real_imgs = Variable(imgs.type(Tensor)) #torch.Size([64, 1, 28, 28]) 真实数据
# ----------------------> 训练生成器 [生成器使用噪声数据,使得其尽可能为真,迷惑鉴别器]
optimizer_G.zero_grad()
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))) #torch.Size([64, 100])
gen_imgs = generator(z) #torch.Size([64, 1, 28, 28])
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ----------------------> 训练鉴别器 [ 尽可能将真实数据和噪声数据区分开]
optimizer_D.zero_grad()
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
本文采用的方法类似于 GAN 。
3 对抗性域适应
与之前方法不同:

本文方法:
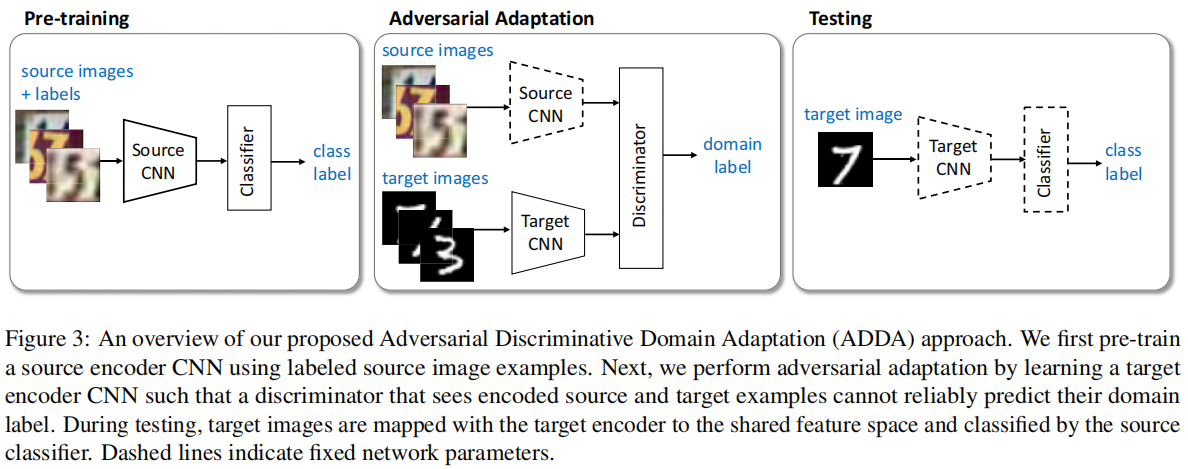
首先:Pretrain ,使用源域训练一个分类器;[ 公式 9 第一个子公式]
其次:Adversarial Adaption
-
- 使用源域和目标域数据,训练一个域鉴别器 Discriminator ,是的鉴别器尽可能区分源域和目标域数据 ;[ 公式 9 第二个子公式]
- 使用目标域数据,训练目标域特征提取器,尽可能使得域鉴别器区分不出目标域样本;[ 公式 9 第三个子公式]
最后:Testing,在目标域上做 Eval;
ADDA对应于以下无约束优化:
$\begin{array}{l}\underset{M_{s}, C}{\text{min}} \quad \mathcal{L}_{\mathrm{cls}}\left(\mathbf{X}_{s}, Y_{s}\right) &=&-\mathbb{E}_{\left(\mathbf{x}_{s}, y_{s}\right) \sim\left(\mathbf{X}_{s}, Y_{s}\right)} \sum_{k=1}^{K} \mathbb{1}_{\left[k=y_{s}\right]} \log C\left(M_{s}\left(\mathbf{x}_{s}\right)\right) \\\underset{D}{\text{min}} \quad\mathcal{L}_{\text {adv }_{D}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, M_{s}, M_{t}\right)&=& -\mathbb{E}_{\mathbf{x}_{s} \sim \mathbf{X}_{s}}\left[\log D\left(M_{s}\left(\mathbf{x}_{s}\right)\right)\right] \text { - } \mathbb{E}_{\mathbf{x}_{t} \sim \mathbf{X}_{t}}\left[\log \left(1-D\left(M_{t}\left(\mathbf{x}_{t}\right)\right)\right)\right] \\\underset{M_{t}}{\text{min}} \quad \mathcal{L}_{\operatorname{adv}_{M}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, D\right)&=& -\mathbb{E}_{\mathbf{x}_{t} \sim \mathbf{X}_{t}}\left[\log D\left(M_{t}\left(\mathbf{x}_{t}\right)\right)\right] \\\end{array} \quad\quad(9)$
tgt_encoder.train() discriminator.train() # setup criterion and optimizer criterion = nn.CrossEntropyLoss() optimizer_tgt = optim.Adam(tgt_encoder.parameters(),lr=params.c_learning_rate,betas=(params.beta1, params.beta2)) optimizer_discriminator = optim.Adam(discriminator.parameters(),lr=params.d_learning_rate,betas=(params.beta1, params.beta2)) len_data_loader = min(len(src_data_loader), len(tgt_data_loader)) #149 for epoch in range(params.num_epochs): # zip source and target data pair data_zip = enumerate(zip(src_data_loader, tgt_data_loader)) for step, ((images_src, _), (images_tgt, _)) in data_zip: # 2.1 训练域鉴别器,使得域鉴别器尽可能的准确 images_src = make_variable(images_src) images_tgt = make_variable(images_tgt) discriminator.zero_grad() feat_src,feat_tgt = src_encoder(images_src) ,tgt_encoder(images_tgt) # 源域特征提取 # 目标域特征提取 feat_concat = torch.cat((feat_src, feat_tgt), 0) pred_concat = discriminator(feat_concat.detach()) # 域分类结果 label_src = make_variable(torch.ones(feat_src.size(0)).long()) #假设源域的标签为 1 label_tgt = make_variable(torch.zeros(feat_tgt.size(0)).long()) #假设目标域域的标签为 0 label_concat = torch.cat((label_src, label_tgt), 0) loss_critic = criterion(pred_concat, label_concat) loss_critic.backward() optimizer_discriminator.step() # 域鉴别器优化 pred_cls = torch.squeeze(pred_concat.max(1)[1]) acc = (pred_cls == label_concat).float().mean() # 2.2 train target encoder # 使得目标域特征生成器,尽可能使得域鉴别器区分不出源域和目标域样本 optimizer_discriminator.zero_grad() optimizer_tgt.zero_grad() feat_tgt = tgt_encoder(images_tgt) pred_tgt = discriminator(feat_tgt) label_tgt = make_variable(torch.ones(feat_tgt.size(0)).long()) #假设目标域域的标签为 1(错误标签),使得域鉴别器鉴别错误 loss_tgt = criterion(pred_tgt, label_tgt) loss_tgt.backward() optimizer_tgt.step() # 目标域 encoder 优化
因上求缘,果上努力~~~~ 作者:加微信X466550探讨,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17020378.html
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |