

神经网络--基于mnist数据集取得最高的识别准确率
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

前言Hello大家好我是Dream。 今天来学习一下如何基于mnist数据集取得最高的识别准确率本文是从零开始的如有需要可自行跳至所需内容~
本文目录
说明在此试验下我们使用的是使用tf2.x版本在jupyter环境下完成
在本文中我们将主要完成以下这个任务
- 基于mnist数据集尽量取得更好的识别准确率。注意要使用非训练集内容通过evaluate方法得出准确率
1.调用库函数
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Conv2D,MaxPooling2D,BatchNormalization,Flatten,Dense
指定当前程序使用的 GPU
# 指定当前程序使用的 GPU
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
2.调用数据集
# 调用数据集
(train_X, train_y),(test_X, test_y) = tf.keras.datasets.mnist.load_data()
train_X, test_X = train_X / 255.0, test_X / 255.0
train_X = train_X.reshape(-1, 28, 28, 1)
train_y = tf.keras.utils.to_categorical(train_y)
X_train, X_test, y_train, y_test = train_test_split(train_X, train_y, test_size=0.1, random_state=0)
3.选择模型构建网络
在此我们使用的是CNN网络以此搭建Conv2D层、MaxPooling2D层网络
# 选择模型构建网络
model = tf.keras.Sequential()
model.add(Conv2D(64, (3, 3), activation='relu', input_shape=(28, 28, 1))), #添加Conv2D层
model.add(Conv2D(64, (3, 3), activation='relu')), #添加Conv2D层
model.add(MaxPooling2D((2, 2), strides=2)), #添加MaxPooling2D层
model.add(BatchNormalization()),
model.add(Conv2D(128, (3, 3), activation='relu')), #添加Conv2D层
model.add(Conv2D(128, (3, 3), activation='relu')), #添加Conv2D层
model.add(MaxPooling2D((2, 2), strides=2)), #添加MaxPooling2D层
model.add(BatchNormalization()),
model.add(Conv2D(256, (3, 3), activation='relu')), #添加Conv2D层
model.add(MaxPooling2D((2, 2), strides=2)), #添加MaxPooling2D层
model.add(BatchNormalization()),
model.add(Flatten()), #展平
model.add(Dense(512, activation='relu')),
model.add(Dense(10, activation='softmax'))
4.编译
使用交叉熵作为loss函数指定优化器、损失函数和验证过程中的评估指标
# 编译使用交叉熵作为loss函数
model.compile(optimizer='adam', #指定优化器
loss="categorical_crossentropy", #指定损失函数
metrics=['accuracy']) #指定验证过程中的评估指标
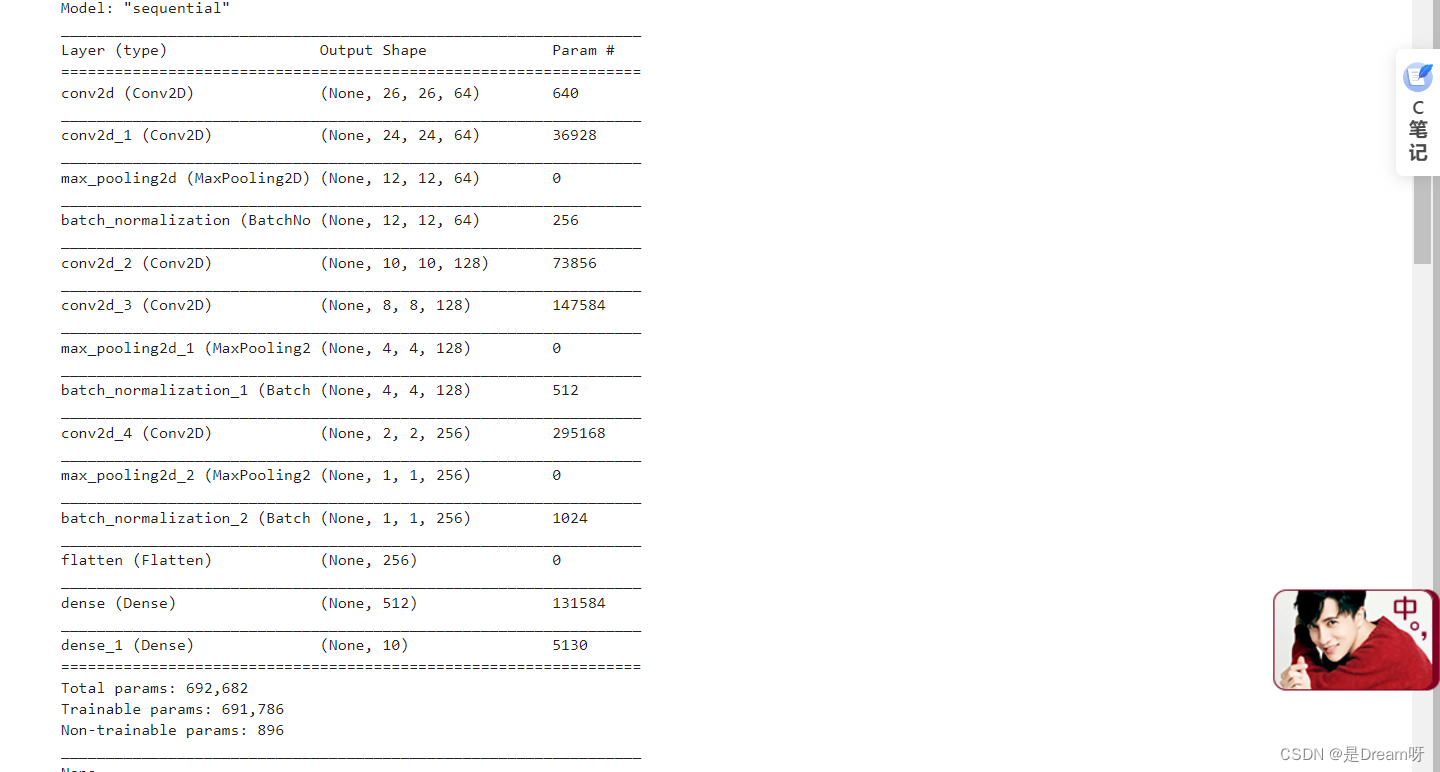
# 展示训练的过程
display(model.summary())
这里是输出的结果
5.数据增强
在这里我们使用数据增强方法更好的提高准确率
# 数据增强
datagen = ImageDataGenerator(
rotation_range=15,
zoom_range = 0.01,
width_shift_range=0.1,
height_shift_range=0.1)
train_gen = datagen.flow(X_train, y_train, batch_size=128)
test_gen = datagen.flow(X_test, y_test, batch_size=128)
6.训练
首先我们批量输入的样本个数然后经过我们测试分析此模型训练到30轮之前变化趋于静止我们可以只进行30个epoch。
# 批量输入的样本个数
batch_size = 128
train_steps = X_train.shape[0] // batch_size
valid_steps = X_test.shape[0] // batch_size
# 经过我们测试分析此模型训练到30轮之前变化趋于静止我们可以只进行30个epoch
es = tf.keras.callbacks.EarlyStopping(
monitor="val_accuracy",
patience=10,
verbose=1,
mode="max",
restore_best_weights=True)
rp = tf.keras.callbacks.ReduceLROnPlateau(
monitor="val_accuracy",
factor=0.2,
patience=5,
verbose=1,
mode="max",
min_lr=0.00001)
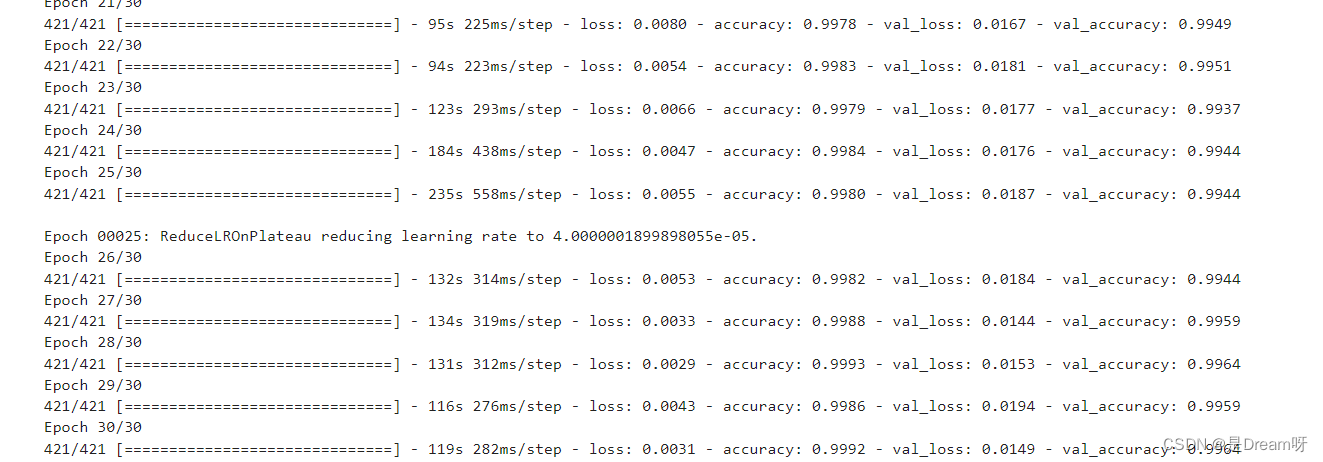
# 训练训练30个epoch
history = model.fit(train_gen,
epochs = 30,
steps_per_epoch = train_steps,
validation_data = test_gen,
validation_steps = valid_steps,
callbacks=[es, rp])
这里是输出的结果
7.画出图像
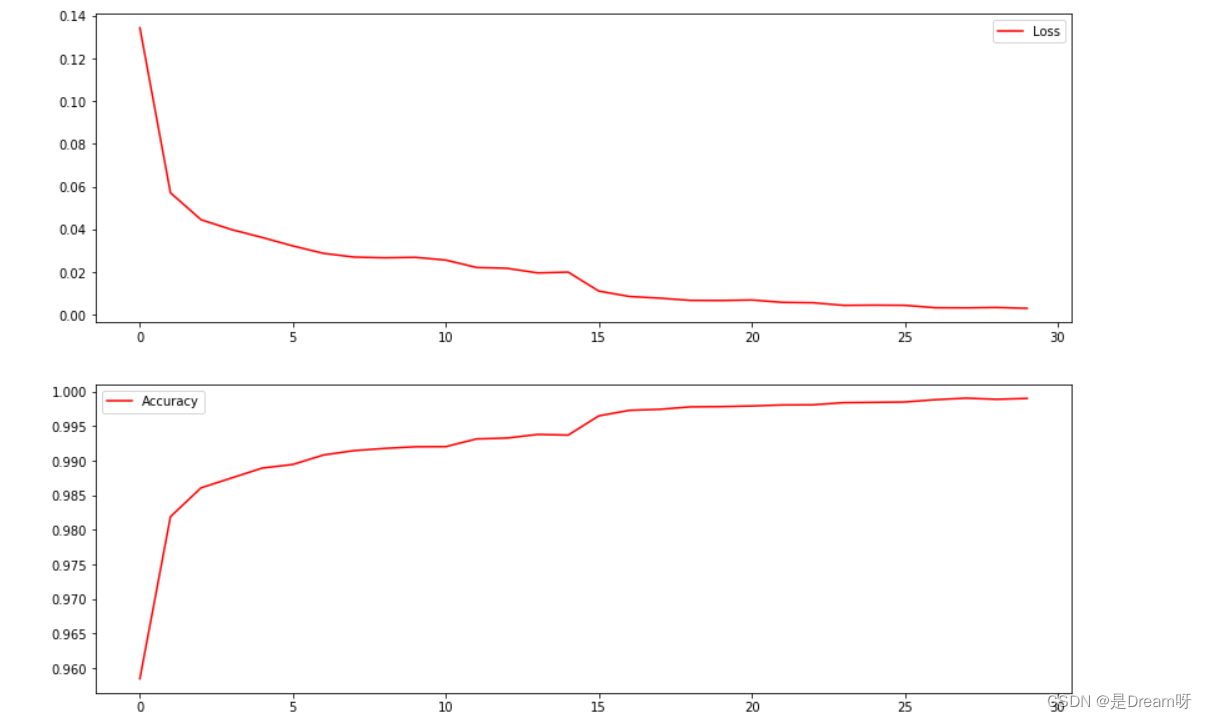
使用plt模块进行数据可视化处理
# 画出图像
fig, ax = plt.subplots(2,1, figsize=(14, 10))
ax[0].plot(history.history['loss'], color='red', label="Loss")
ax[0].legend(loc='best', shadow=False)
ax[1].plot(history.history['accuracy'], color='red', label="Accuracy")
ax[1].legend(loc='best', shadow=False)
plt.show()
这里是输出的结果
8.输出
最后在测试集上进行模型评估输出测试集上的预测准确率
score = model.evaluate(X_test, y_test) # 在测试集上进行模型评估
print('测试集预测准确率:', score[1]) # 打印测试集上的预测准确率
这里是输出的结果

9.结果
最后的结果mnist数据集最终的准确率是: 0.996833
源码获取
关注此公众号人生苦短我用Pythons回复 神经网络实验获取源码快点击我吧
🌲🌲🌲 好啦这就是今天要分享给大家的全部内容了我们下期再见
❤️❤️❤️如果你喜欢的话就不要吝惜你的一键三连了~

