

Spark简介
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Spark是什么
Spark 是 UC Berkeley AMP Lab 开源的通用分布式并行计算框架。
Spark基于map reduce算法实现的分布式计算拥有Hadoop MapReduce所具有的优点但不同于MapReduce的是Job中间输出和结果可以保存在内存中从而不再需要读写HDFS因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
spark是基于内存计算框架计算速度非常之快但是它仅仅只是涉及到计算并没有涉及到数据的存储后期需要使用spark对接外部的数据源比如hdfs。
Spark的四大特性
Simple易用性
Spark 提供了丰富的高级运算操作支持丰富的算子并支持 Java、Python、Scala、R、SQL 等语言的 API使用户可以快速构建不同的应用。
开发人员只需调用 Spark 封装好的 API 来实现即可无需关注 Spark 的底层架构。
Fast(速度快)
Spark 将处理的每个任务都构造成一个DAGDirected Acyclic Graph, 有向无环图来执行实现原理是基于RDDResilient Distributed Dataset, 弹性分布式数据集在内存中对数据进行迭代计算以实现批量和流式数据的高性能快速计算处理。
Spark比MR速度快的原因
- 基于内存
mapreduce任务后期再计算的时候每一个job的输出结果会落地到磁盘后续有其他的job需要依赖于前面job的输出结果这个时候就需要进行大量的磁盘io操作。性能就比较低。
spark任务后期再计算的时候job的输出结果可以保存在内存中后续有其他的job需要依赖于前面job的输出结果这个时候就直接从内存中获取得到避免了磁盘io操作性能比较高
对于spark程序和mapreduce程序都会产生shuffle阶段在shuffle阶段中它们产生的数据都会落地到磁盘。- 进程与线程
mapreduce任务以进程的方式运行在yarn集群中比如程序中有100个MapTask一个task就需要一个进程这些task要运行就需要开启100个进程。
spark任务以线程的方式运行在进程中比如程序中有100个MapTask后期一个task就对应一个线程这里就不再是进程这些task需要运行这里可以极端一点只需要开启1个进程在这个进程中启动100个线程就可以了。
进程中可以启动很多个线程而开启一个进程与开启一个线程需要的时间和调度代价是不一样。 开启一个进程需要的时间远远大于开启一个线程。## Scalable可融合性
Unified通用性
大数据处理的传统方案需要维护多个平台比如离线任务是放在 Hadoop MapRedue 上运行实时流计算任务是放在 Storm 上运行。
而Spark 提供了一站式的统一解决方案可用于批处理、交互式查询Spark SQL、实时流处理Spark Streaming、机器学习Spark MLlib和图计算GraphX等。这些不同类型的处理都可以在同一个应用中无缝组合使用。
Scalable(兼容性)
Spark 可以非常方便地与其他的开源产品进行融合。比如Spark 可以使用 Hadoop 的 YARN 和 Apache Mesos 作为它的资源管理和调度器可以处理所有 Hadoop 支持的数据包括 HDFS、HBase 和 Cassandra 等。
Spark运行原理
Spark运行模式
| 运行模式 | 运行类型 | 说明 |
|---|---|---|
| Local | 本地模式 | 常用于本地开发分为Local单线程和Local-Cluster多线程模式 |
| Standalone | 集群模式 | 独立模式在Spark自己的资源调度管理框架上运行该框架采用master/salve结构 |
| ON YARN | 集群模式 | 用于生产环境在YARN资源管理器框架上运行由YARN负责资源管理Spark负责任务调度和计算 |
| ON Mesos | 集群模式 | 用于生产环境在Mesos资源管理器框架上运行由Mesos责资源管理Spark负责任务调度和计算 |
| ON Cloud | 集群模式 | 运行在AWS、阿里云等环境 |
Spark集群架构
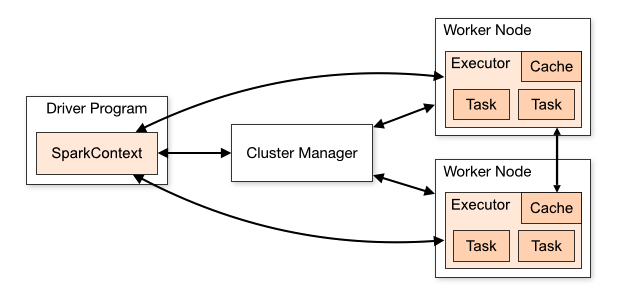
- Cluster Manager
Cluster Manager 是 Spark 的集群资源管理器存在于 Master 进程中主要用于对整个集群资源进行管理和分配根据其部署模式的不同可以分为 Local、Standalone、YARN、Mesos、Cloud 等模式。 - Driver:
执行客户端写好的main方法它会构建一个名叫SparkContext对象该对象是所有spark程序的执行入口 - Worker:
Spark的工作节点用于执行提交的任务其主要的工作职责有以下几点:
- Worker 节点通过注册机向 Cluster Manager 汇报自身的 CPU、内存等资源使用信息。
- Worker 节点在 Spark Master 的指示下创建并启用 Executor真正的计算单元。
- Spark Master 将资源和 Task 分配给 Worker 节点上的 Executor 并执行运用。
- Worker 节点同步 Executor 状态和资源信息给 Cluster Manager。
- Executor:
它是一个进程它会在worker节点启动该进程计算资源一个worker节点可以有多个Executor进程 - Task:
spark任务是以task线程的方式运行在worker节点对应的executor进程中 - Application:
Application 是基于 Spark API 编写的应用程序包括实现 Driver 功能的代码和在集群中各个 Executor 上要执行的代码。
一个 Application 由多个 Jobs 组成。
其中 Application 的入口为用户所定义的 main() 方法。
Spark Core
Spark 基础配置
- SparkConf 用于定义 Spark Application 的配置信息。
- SparkContext Spark Application 所有功能的主要入口点 其隐藏了网络通信、消息通信分布式部署、存储体系、计算存储等底层逻辑开发人员只需使用其提供的 API 即可完成 Application 的提交与执行。核心作用是初始化 Spark Application 所需要的组件同时还负责向 Master 进程进行注册等。
- SparkRPC 基于 Netty 实现的 Spark RPC 框架用于 Spark 组件之间的网络通信分为异步和同步两种方式。
- SparkEnv Spark 的执行环境其内部封装了很多 Spark 运行所需要的基础环境组件。
- ListenerBus 事件总线主要用于 SparkContext 内部各组件之间的事件交互属于监听者模式采用异步调用。
- MetricsSystem 度量系统用于整个 Spark 集群中各个组件状态的运行监控。
Spark 存储系统
Spark 存储系统用于管理 Spark 运行中依赖的数据的存储方式和存储位置。存储系统会优先考虑在各节点的内存中存储数据内存不足时将数据写入磁盘中这也是 Spark 计算性能高的重要原因。
数据存储在内存和磁盘之间的边界可以灵活控制同时可以通过远程网络调用将结果输出到远程存储中比如 HDFS、HBase 等。
Spark调度系统
Spark 调度系统主要由 DAGScheduler 和 TaskScheduler 组成。
- DAGScheduler负责创建 Job把一个 Job 根据 RDD 间的依赖关系划分到不同 Stage 中并将划分后的每个 Stage 都抽象为一个或多个 Task 组成的 TaskSet批量提交给 TaskScheduler 来进行进一步的任务调度。
- TaskScheduler负责按照调度算法对每个具体的 Task 进行批量调度执行协调物理资源跟踪并获取状态结果。
主要的调度算法有 FIFO、FAIR。
- FIFO 调度先进先出Spark 默认的调度模式。
- FAIR 调度支持将作业分组到池中并为每个池设置不同的调度权重任务可以按照权重来决定执行顺序。
Spark 计算引擎
Spark 计算引擎主要由内存管理器、TaskSet 管理器、Task 管理器、Shuffle 管理器等组成。
核心组件
Spark 基于 Spark Core 扩展了四个核心组件分别用于满足不同领域的计算需求。
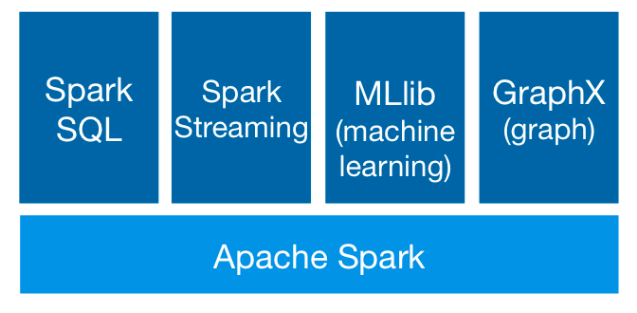
Spark SQL
Spark SQL 主要用于结构化数据的处理。其具有以下特点
- 能够将 SQL 查询与 Spark 程序无缝混合允许您使用 SQL 或 DataFrame API 对结构化数据进行查询
- 支持多种数据源包括 HiveAvroParquetORCJSON 和 JDBC
- 支持 HiveQL 语法以及用户自定义函数 (UDF)允许你访问现有的 Hive 仓库
- 支持标准的 JDBC 和 ODBC 连接
- 支持优化器列式存储和代码生成等特性以提高查询效率。
Spark Streaming

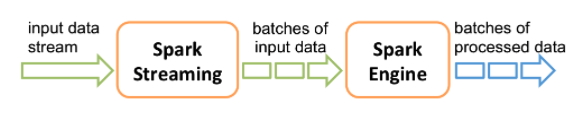
Spark Streaming 主要用于快速构建可扩展高吞吐量高容错的流处理程序。支持从 HDFSFlumeKafkaTwitter 和 ZeroMQ 读取数据并进行处理。
Spark Streaming 的本质是微批处理它将数据流进行极小粒度的拆分拆分为多个批处理从而达到接近于流处理的效果。
MLlib
MLlib 是 Spark 的机器学习库。其设计目标是使得机器学习变得简单且可扩展。它提供了以下工具
- ML Algorithms: 如分类回归聚类和协同过滤
- Featurization: 特征提取转换降维和选择
- Pipelines: 用于构建评估和调整 ML 管道的工具
- Persistence: 保存和加载算法模型管道数据
- Utilities: 线性代数统计数据处理等。
Graphx
GraphX 是 Spark 中用于图形计算和图形并行计算的新组件。在高层次上GraphX 通过引入一个新的图形抽象来扩展 RDD(一种具有附加到每个顶点和边缘的属性的定向多重图形)。为了支持图计算GraphX 提供了一组基本运算符如 subgraphjoinVertices 和 aggregateMessages以及优化后的 Pregel API。此外GraphX 还包括越来越多的图形算法和构建器以简化图形分析任务。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |