

python数据分析—决策树分类算法及python实现
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
决策树分类算法及python实现
目标值是分类型变量,特征值(属性值/自变量)可以是分类型,也可以是连续型。
1、决策树概括
思想:划分某个特征变量判断类别,接着在该特征变量的条件下继续划分下一个特征变量,一直到特征变量划分完或者确定有好的分类结果后结束划分,最终确定属于哪个分类,也就是if...elif...else...的思想。
问题:众多的特征变量中,先进行哪些特征变量的划分效果/效率会更高呢?需要引入基尼系数、信息熵、信息增益、信息增益比等。
- 基尼系数、信息熵衡量节点(特征变量)的纯度:
- 信息增益、信息增益比—决策树的划分依据
- 决策树的生成:
- 贪婪算法:只能局部最优(具有单一属性分类的节点最佳,到此节点认为分类达到准确)。
- 根据某一属性对数据进行分裂,以达到某一标准的最优值。


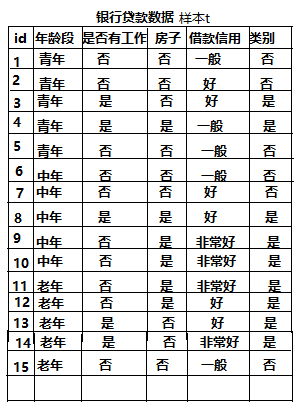

2、3种决策树的原理
- ID3:准则:信息增益最大的准则。
- C4.5:信息增益比最大的准则。
- CART(分类树):基尼系数(GINI)最小的准则。在sklearn中可以选择划分的默认原则,优势是划分更加细致(从后面例子的树显示来理解)。
3、python决策树分类API
语法:sklearn.tree.DecisionTreeClassifier(criterion='gini',max_depth=None,random_state=None)
- tree.DecisionTreeClassifier():决策树分类器
- criterion:默认是'gini'系数,也可以选择信息增益的'entropy'
- max_depth:树的深度大小
- random_state:随机数种子
4、tree可视化
win10安装GraphViz:
- 下载路径:https://www2.graphviz.org/Packages/stable/windows/10/cmake/Release/x64/
- 下载安装包:graphviz-install-2.44.1-win64.exe
- 按照提示安装完成--重要步骤
- 安装完成后,将bin目录加入到系统path环境变量中。
安装graphviz的python库
cmd下conda install python-graphviz(或 pip install graphviz)命令安装即可
安装pydotplus
cmd下pip install pydotplus
生成树文本的API:
- sklearn.tree.export_graphviz(estimator,out_file='tree.dot',feature_names=["","",...]) #该函数能够导出DOT格式
- tree.export_graphviz(模型预估器,导出目录,特征值(变量)名称)
可视化展现API
- 网站:http://webgraphviz.com/,然后粘贴tree.dot,并执行(需要安装和配置环境变量)
- 或者:打开cmd,切换到tree.dot目录下,执行:dot -Tpdf tree.dot -o output.pdf,打开pdf
5、案例
from sklearn import datasets #机器学习数据集库
from sklearn.model_selection import train_test_split #数据集划分
from sklearn.tree import DecisionTreeClassifier #可以按照ginf系数或者信息增益entropy的决策树算法
from sklearn.model_selection import GridSearchCV #网格搜索和交叉验证
from sklearn.tree import export_graphviz #决策树可视化文件生成
'''# 1 获取数据:使用datasets.load_iris的数据'''
#sklearn.datasets.load_*() # *:表示某个数据集的名称,load_:获取小规模数据集
df = datasets.load_iris() #iris:花儿的数据集
# display(df.data) #返回特征值(自变量)数组
# display(df.target) #返回目标值(因变量)数组
# print(df["DESCR"]) #返回描述信息
# display(df["feature_names"]) #返回特征值的字段名称
# display(df.feature_names) #返回特征值的字段名称
# display(df.target_names) #返回目标值数字对应解释
'''# 2 数据清新(略)'''
'''# 3 特征工程(略)'''
'''# 4 数据集划分'''
x_train,x_test,y_train,y_test = train_test_split(df.data,df.target,test_size=0.25,random_state=11)
print(x_train.shape,x_test.shape,y_train.shape,y_test.shape)
'''# 5、tree预估器训练模及型选择'''
#实例化一个转换器类
#estimator = DecisionTreeClassifier(criterion='gint',max_depth=None,random_state=11)
#加入模型选择与调优,网格搜索和交叉验证
#网格搜索和交叉验证
estimator = DecisionTreeClassifier(random_state=11)
#准备参数
param_dict = {"criterion":['entropy','gini']}
estimator = GridSearchCV(estimator,param_grid=param_dict,cv=10) #cv=10是10折交叉验证
#执行预估器
estimator.fit(x_train,y_train)
'''# 6、模型评估选择'''
#方法1:比对真实值和预测值
y_predict = estimator.predict(x_test) #计算预测值
print(y_predict)
#方法2:直接计算准确率
accuracy=estimator.score(x_test,y_test)
print(accuracy)
# 3、查看网格搜索和交叉验证返回结果
# 最佳参数:best_params_
print("最佳参数k:",estimator.best_params_)
# 验证集的最佳结果:best_score_
print("验证集的最佳结果准确率:",estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器",estimator.best_estimator_)
# 交叉验证结果:cv_results_
# print(estimator.cv_results_) #比较长这里就不输出了
'''tree可视化文件.dot的生成'''
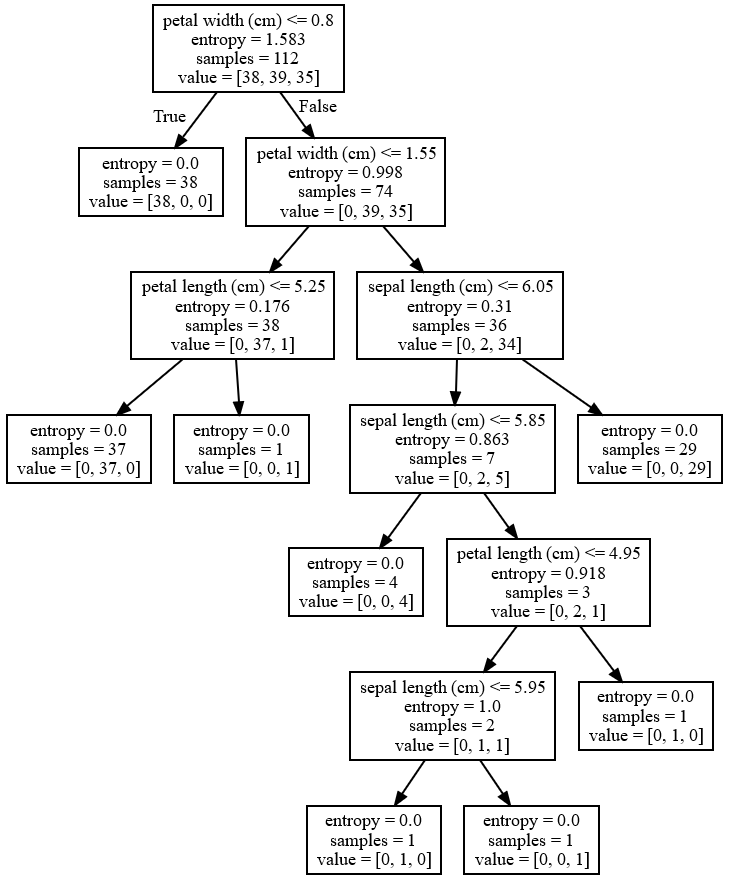
export_graphviz(estimator.best_estimator_,out_file=r'tree.dot',feature_names=df.feature_names)
#estimator.best_estimator_ :使用最终估计器
# 然后打开cmd,执行:dot -Tpdf D:\jupyter代码\python脚本\tree.dot -o D:\jupyter代码\python脚本\output.pdf
更多相关内容扫描下方二维码

扫
码
关
注
更多数据分析数据运营
干货在此,随时学习!
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |