

python机器学习分类模型评估
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
python机器学习分类模型评估
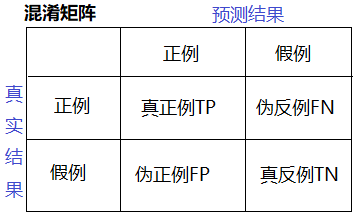
1、混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)
2、准确率、精确率、召回率、F1-score
- 准确率:score = estimator.score(x_test, y_test) #比对预测值与真实值,判断正确的概率;
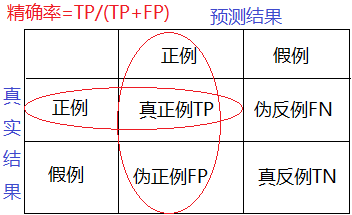
- 精确率 precision:预测结果为正例样本中真实为正例的比例;
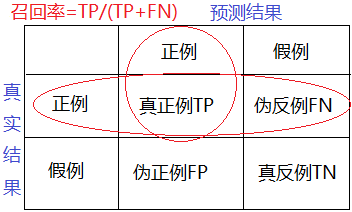
- 召回率recall:真实为正例的样本中预测结果为正例的比例(查得全,对正样本的区分能力);
- F1-score:反应模型的稳健性。F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。F1分数认为召回率和精确率同等重要,F2分数认为召回率的重要程度是精确率的2倍。

3、分类评估报告API
from sklearn.metrics import classification_report
classification_report(y_true,y_pred,labels=[],target_names=None) #返回精确率、召回率、F1-score
- y_true:真实目标值
- y_pred:估计器预测目标值
- labels:指定类别对应的数字
- target_names:目标类别名称
4、ROC曲线和AUC值(二分类评估)
- TPR = TP /(TP+FN) :所有真实类别为1样本中,预测类别为1的比例
- FPR = FP /(FP+TN) :所有真实类别为0样本中,预测类别为1的比例
ROC曲线:
- ROC曲线的横轴就是FPRate,纵轴就是TPRate,当二者相等时,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5
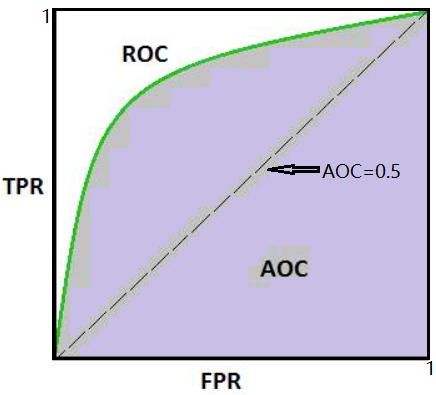
AUC:样本不均匀的情况下衡量模型的好坏
- AUC的概率意义是随机取一对正负样本,正样本得分大于负样本的概率
- AUC的最小值为0.5,最大值为1,取值越高越好
- AUC=1,完美分类器,采用这个预别模型时,不管设定什么阀值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5<AUC<1,优于随机猜测,这个分类器(模型)妥善设定阀值的话,能有预测价值。
- AUC只能用来评价二分类
- AUC非常适合评价样本不平衡中的分类器性能
5、AUC计算API
- from sklearn.metrics import roc_auc_score
- sklearn.metrics.roc_auc_score(y_true,y_predict)
- 计算ROC曲线面积,即AUC值
- y_true:每个样本的真实类别,通常用y_test,必须为0(反例),1(正例)标记
- y_predict:每个样本的预测值,通常y_predict = estimator.predict(x_test)
更多相关内容扫描下方二维码

扫
码
关
注
更多数据分析数据运营
干货在此,随时学习!
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |