大数据-Hadoop的介绍、配置和集群的使用
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
HDFS分布式文件系统
分布式将多台服务器集中在一起每台服务器都实现总体中的不同业务做不同的事情
单机模式
厨房里只有一个人这个人既要买菜又要切菜还要炒菜效率低。
分布式模式
厨房里有三个人一个人买菜一个切菜一个炒菜效率提高了。
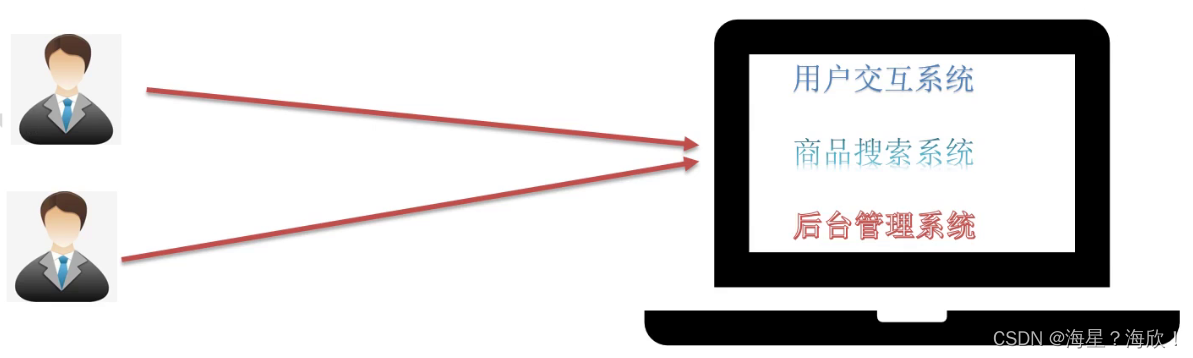
问题
1用户交互系统的压力大都要访问它
2单点故障问题
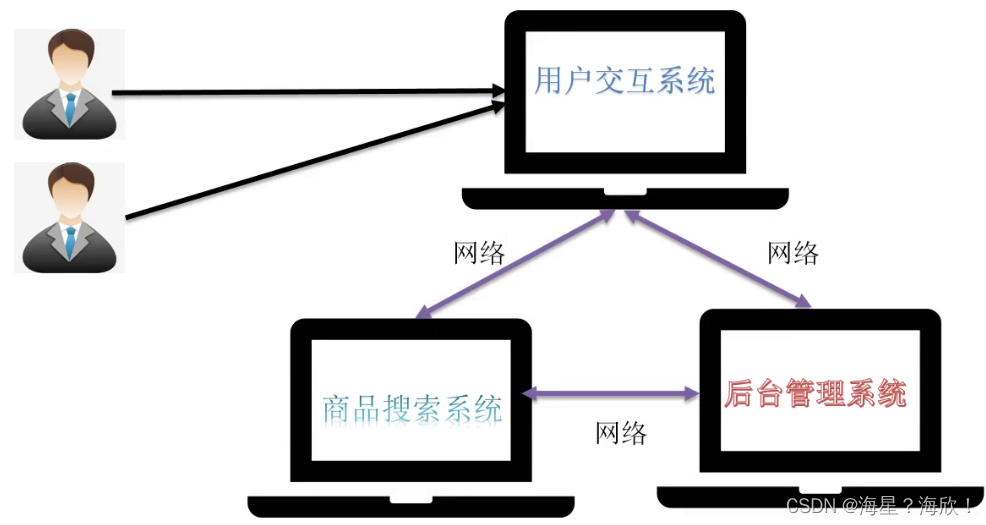
集群
解决上面分布式的问题引入集群概念
集群一组独立的计算机系统构成的一多处理器系统它们之间通过网络实现进程间的通信让若干个计算机联合起来工作可以并行也可以是备份的
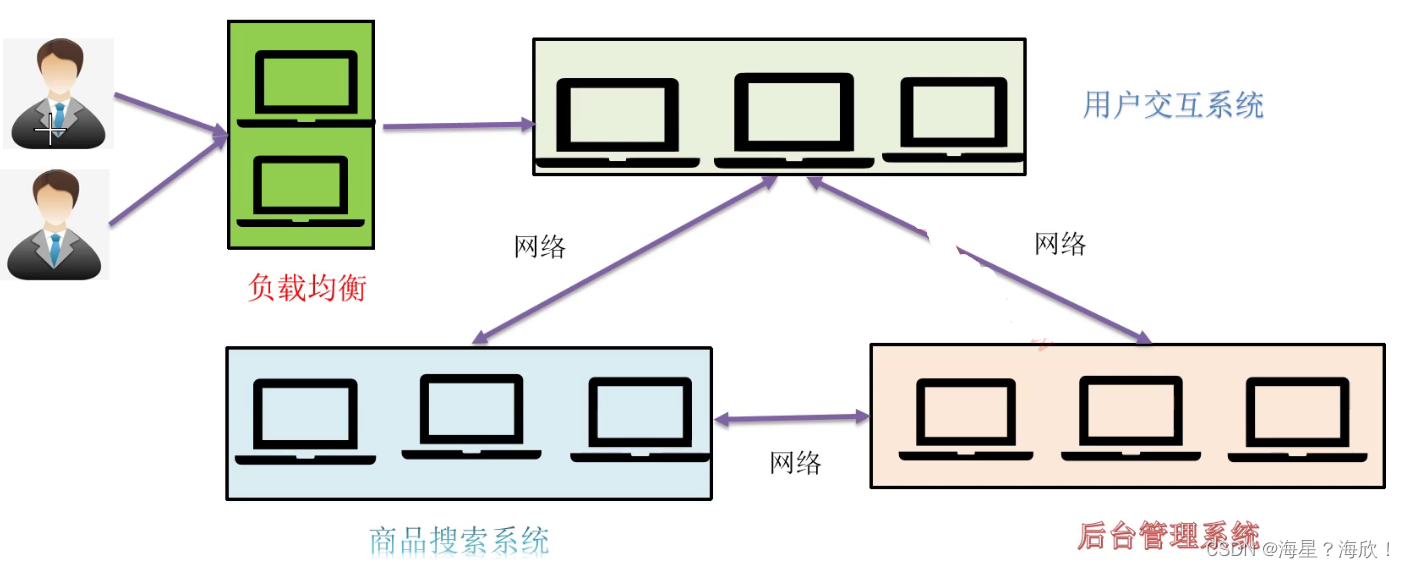
集群相比于分布式方法备份多台服务器
分布式和集群的区别
分布式分布式的主要工作是分解任务将职能拆解多个人在一起做不同的事
集群集群主要是将同一个业务部署在多个服务器多个人在一起做同样的事
Hadoop框架介绍
Hadoop是用Java语言实现的开源软件框架是一个储存和计算的大规模数据的软件平台
Hadoop的核心组件
- HDFS交叉式文件系统解决海量数据存储
- MAPREDUCE分布式运算编程框架解决海量数据计算
- YARN作业调度和集群资源管理框架解决资源任务调度
广义的HadoopHadoop生态圈包括LInux、zookeeper、hive、spark等等
版本
2.x版本开源社区版
Hadoop1.x与Hadoop2.x的区别
- 1.x中mapreduce数据计算、资源管理、hdfs数据存储问题自动备份
- 2.x中mapreduce数据计算、yarn资源管理、hdfs数据存储问题自动备份因为mapreduce压力减轻了从而更稳定
内部结构
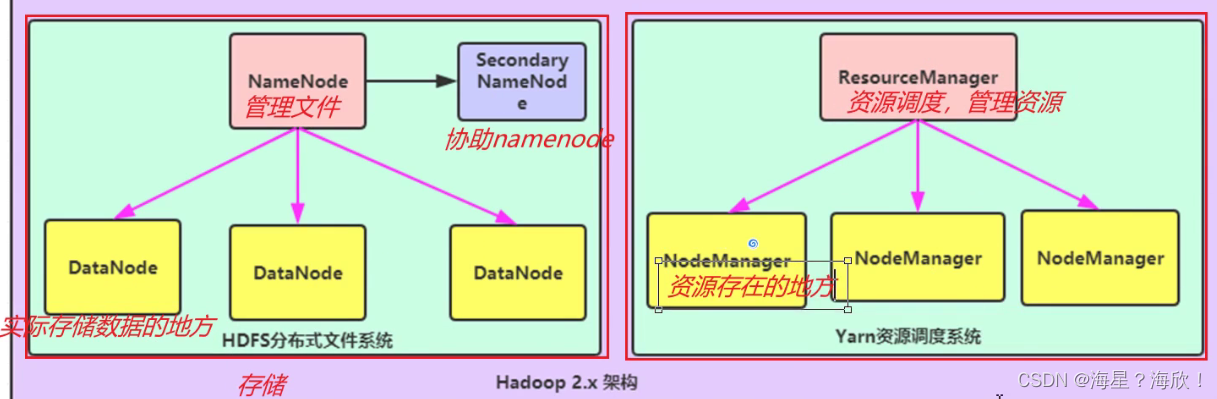
Hadoop集群包括两个集群HDFS集群和YARN集群两者逻辑上分离一个存储一个管理但物理上常在一起指在同一个服务器上
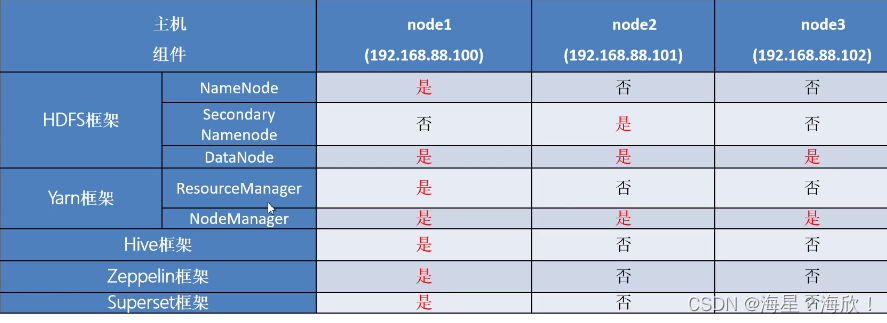
HDFS模块
- NameNode集群中的主节点用于管理集群中的各种数据。存储元数据
- SecondaryNameNode用于Hadoop当中元数据描述数据的数据信息的辅助管理。移动硬盘备份元数据
- DataNode集群中的从节点存储集群中的各种数据
YARN模块
- ResourceManager接收用户的计算请求任务并负责集群的资源分配
- NodeManager负责执行主节点分配的任务实际执行任务
mapreduce模块
mapreduce计算需要的数据和产生的结果需要HDFS来进行存储。—mapreduce慢的主要原因读磁盘慢
mapreduce的运行需要yarn集群来提供资源调度
mapreduce是一个计算框架。map(先分布式计算)、reduce将分布式计算的结果合并
单机模式
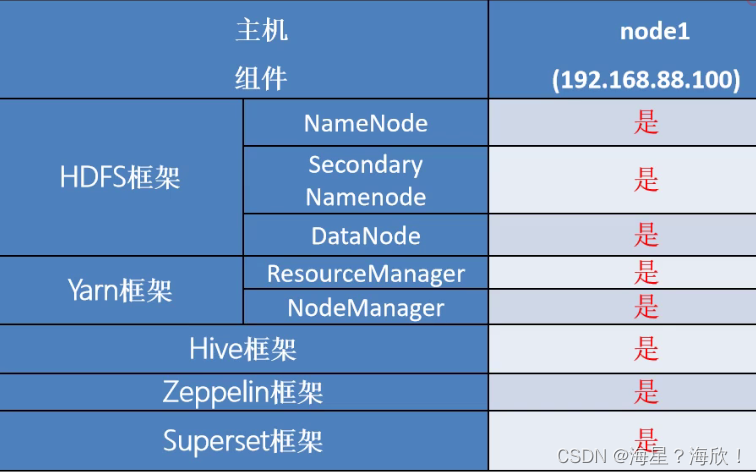
集群模式角色分配