Hadoop集群搭建
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
一、运行环境配置(所有节点)
所有集群服务都需要配置
1、基础配置
关闭防火墙关闭防火墙开机自启
systemctl stop firewalld
systemctl disable firewalld
创建lydms用户并修改lydms用户的密码lydms123
useradd lydms
passwd lydms
配置lydms用户具有root权限方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
lydms ALL=(ALL) NOPASSWD:ALL
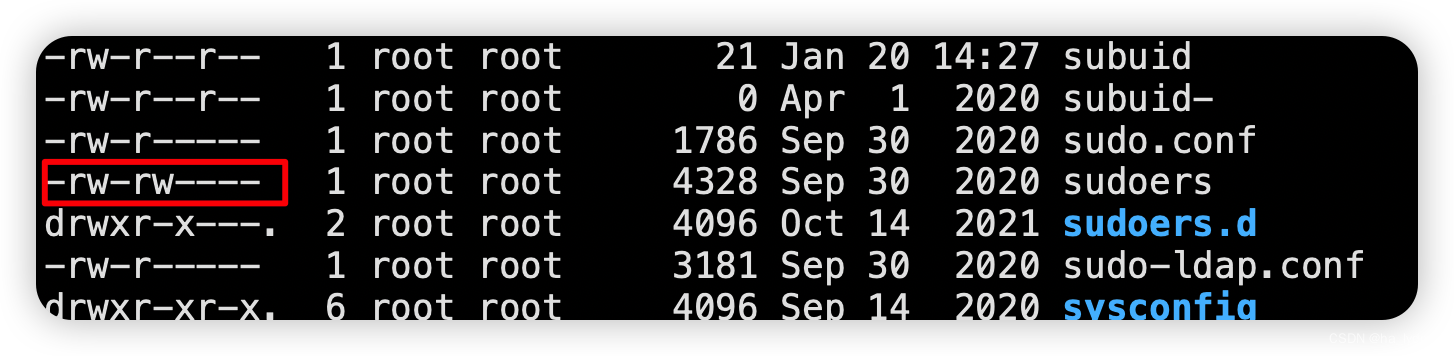
'readonly' option is set (add ! to override) 查看5.1解决。
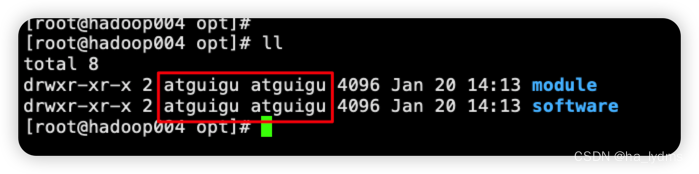
在/opt目录下创建文件夹
mkdir /opt/module
mkdir /opt/software
并修改所属主和所属组
chown lydms:lydms /opt/module
chown lydms:lydms /opt/software
2、配置Host
更新本机名称(参照下表)
vim /etc/hostname
172.27.181.176 hadoop101
172.27.181.177 hadoop102
172.27.181.178 hadoop103
配置Linux克隆机主机名称映射hosts文件
vim /etc/hosts
172.27.181.176 hadoop101
172.27.181.177 hadoop102
172.27.181.178 hadoop103

重启虚拟机
reboot
二、依赖软件安装(101节点)
只有主节点进行配置
1、安装JDK
https://www.oracle.com/java/technologies/downloads/archive/
wget https://gitcode.net/weixin_44624117/software/-/raw/master/software/jdk-8u181-linux-x64.tar.gz?inline=false
解压文件
tar -zxvf jdk-8u341-linux-x64.tar.gz -C /opt/module/
添加环境变量
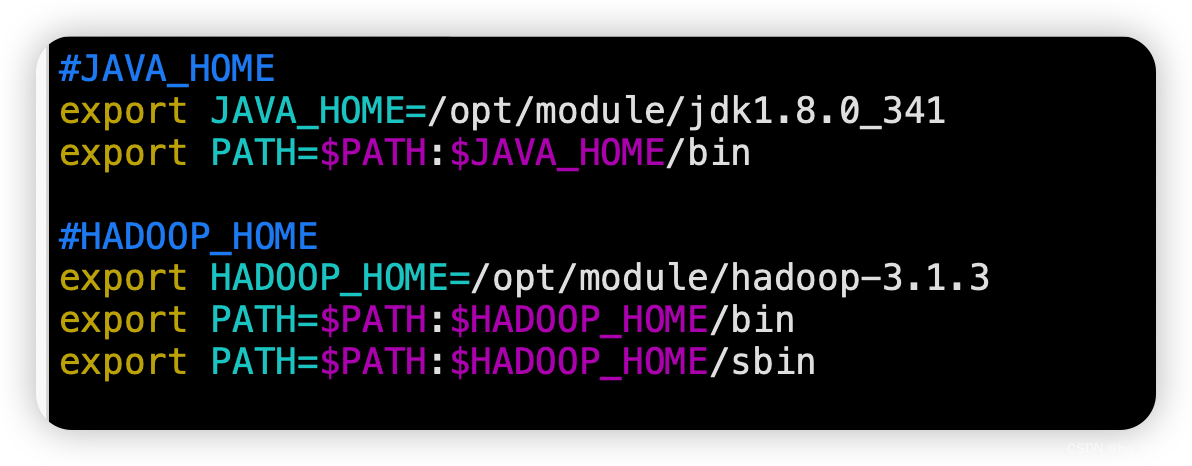
vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_341
export PATH=$PATH:$JAVA_HOME/bin
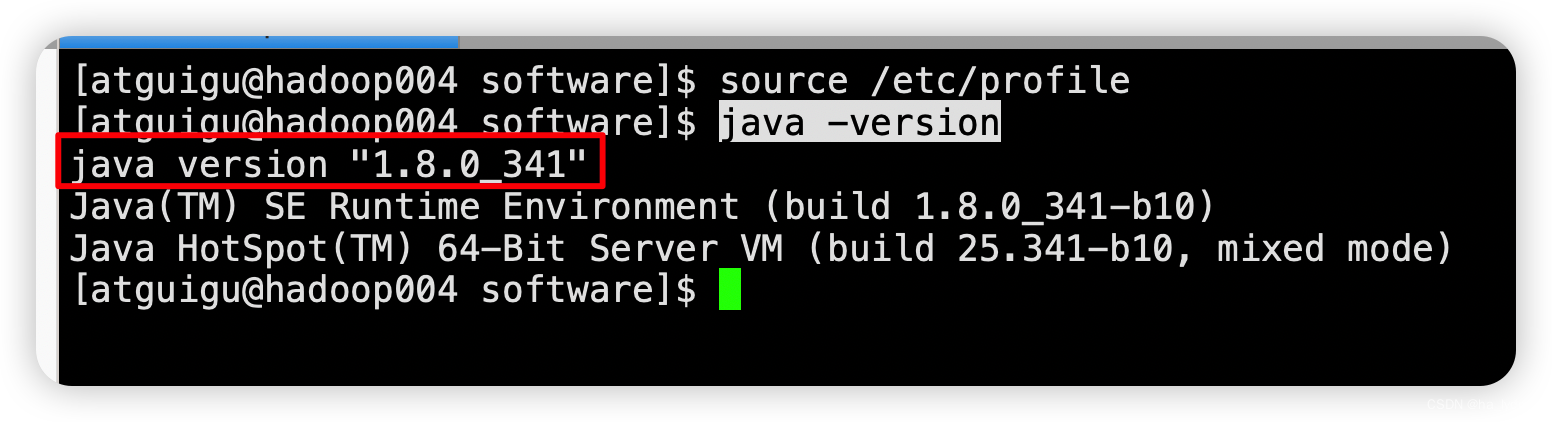
加载环境变量
source /etc/profile
查看是否安装完成
java -version
2、安装Hadoop(root)
https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
解压到/opt/module/目录
tar -zxvf /root/hadoop-3.1.3.tar.gz -C /opt/module/
添加环境变量
vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
加载环境变量
source /etc/profile
查看是否安装完成
hadoop version
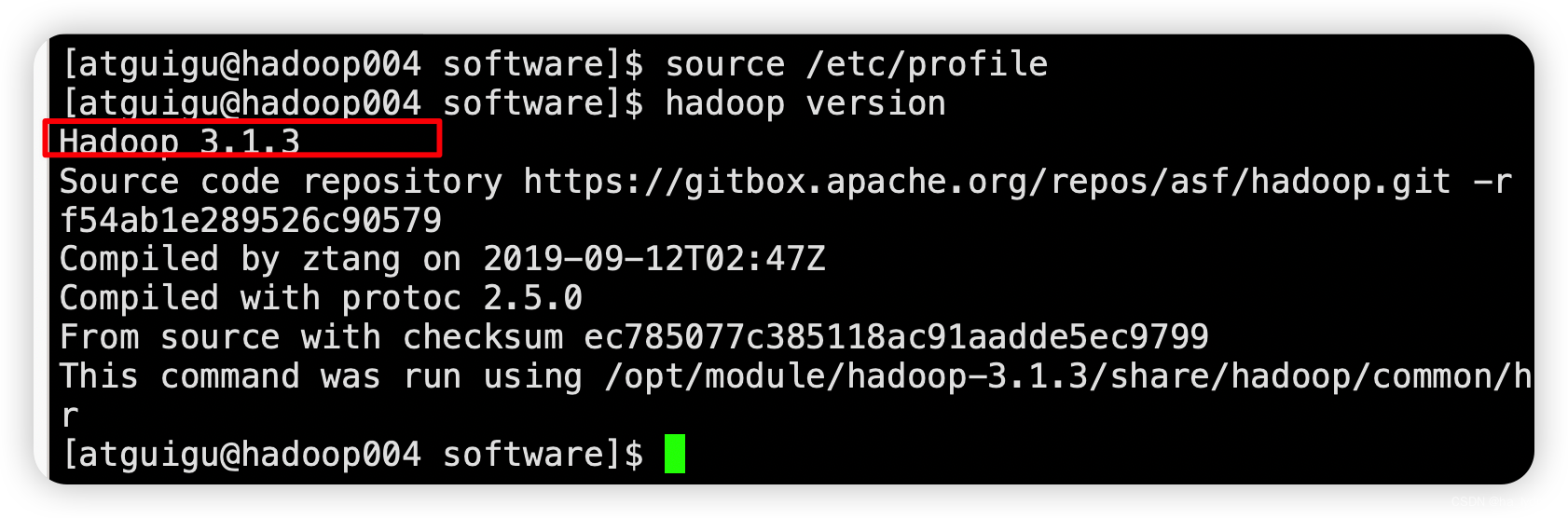
3、Hadoop目录结构
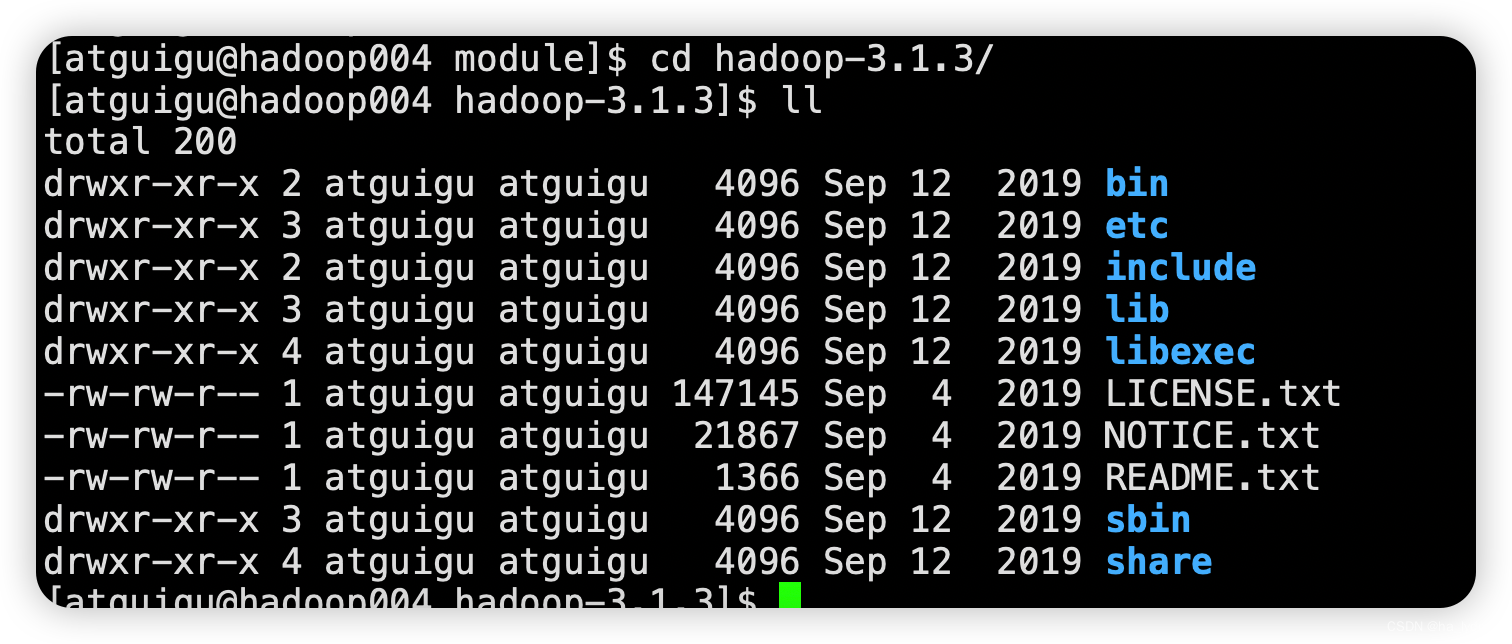
- bin目录存放对Hadoop相关服务hdfsyarnmapred进行操作的脚本。
- etc目录Hadoop的配置文件目录存放Hadoop的配置文件。
- lib目录存放Hadoop的本地库对数据进行压缩解压缩功能。
- sbin目录存放启动或停止Hadoop相关服务的脚本。
- share目录存放Hadoop的依赖jar包、文档、和官方案例。
三、本地运行模式官方WordCount
1、简介
Hadoop官方网站http://hadoop.apache.org/
Hadoop运行模式包括本地模式、伪分布式模式以及完全分布式模式。
- 本地模式单机运行只是用来演示一下官方案例。生产环境不用。
- 伪分布式模式也是单机运行但是具备Hadoop集群的所有功能一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试生产环境不用。
- 完全分布式模式多台服务器组成分布式环境。生产环境使用。
2、本地运行模式官方WordCount
在hadoop-3.1.3文件下面创建一个wcinput文件夹
mkdir /opt/module/hadoop-3.1.3/wcinput
在wcinput文件下创建一个word.txt文件
vim /opt/module/hadoop-3.1.3/wcinput/word.txt
hadoop yarn
hadoop mapreduce
lydms
lydms
运行单机Hadoop
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
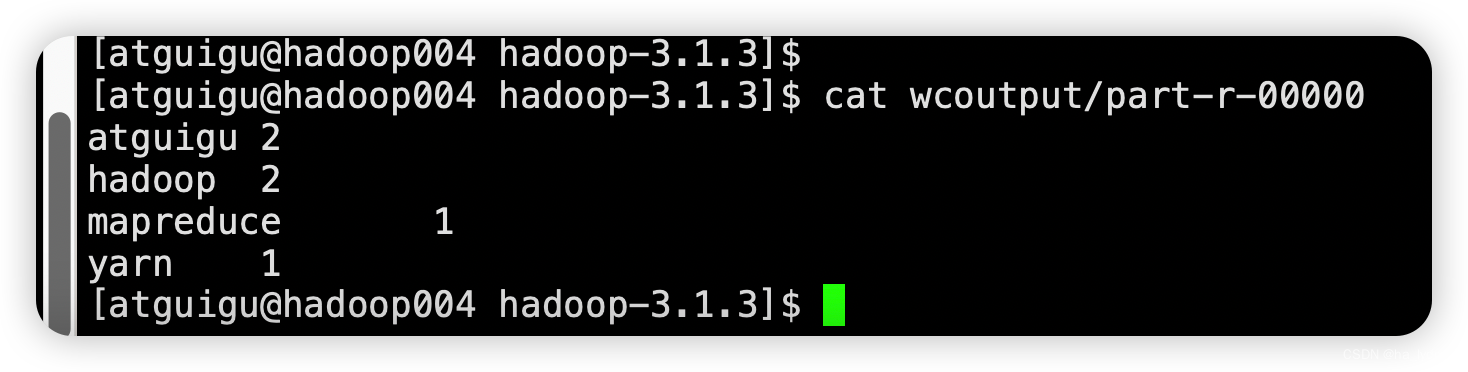
查看运行结果
cat wcoutput/part-r-00000
四、完全分布式运行模式
三台资源列表
172.27.181.176 hadoop101
172.27.181.177 hadoop102
172.27.181.178 hadoop103
1、文件分发脚本(root)
新建文件xsync
vim /bin/xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo "Not Enough Arguement!"
exit
fi
#2. 遍历集群所有机器
for host in hadoop101 hadoop102 hadoop103
do
echo ==================== $host ====================
#3. 遍历所有目录挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
添加执行权限
chmod +x /bin/xsync
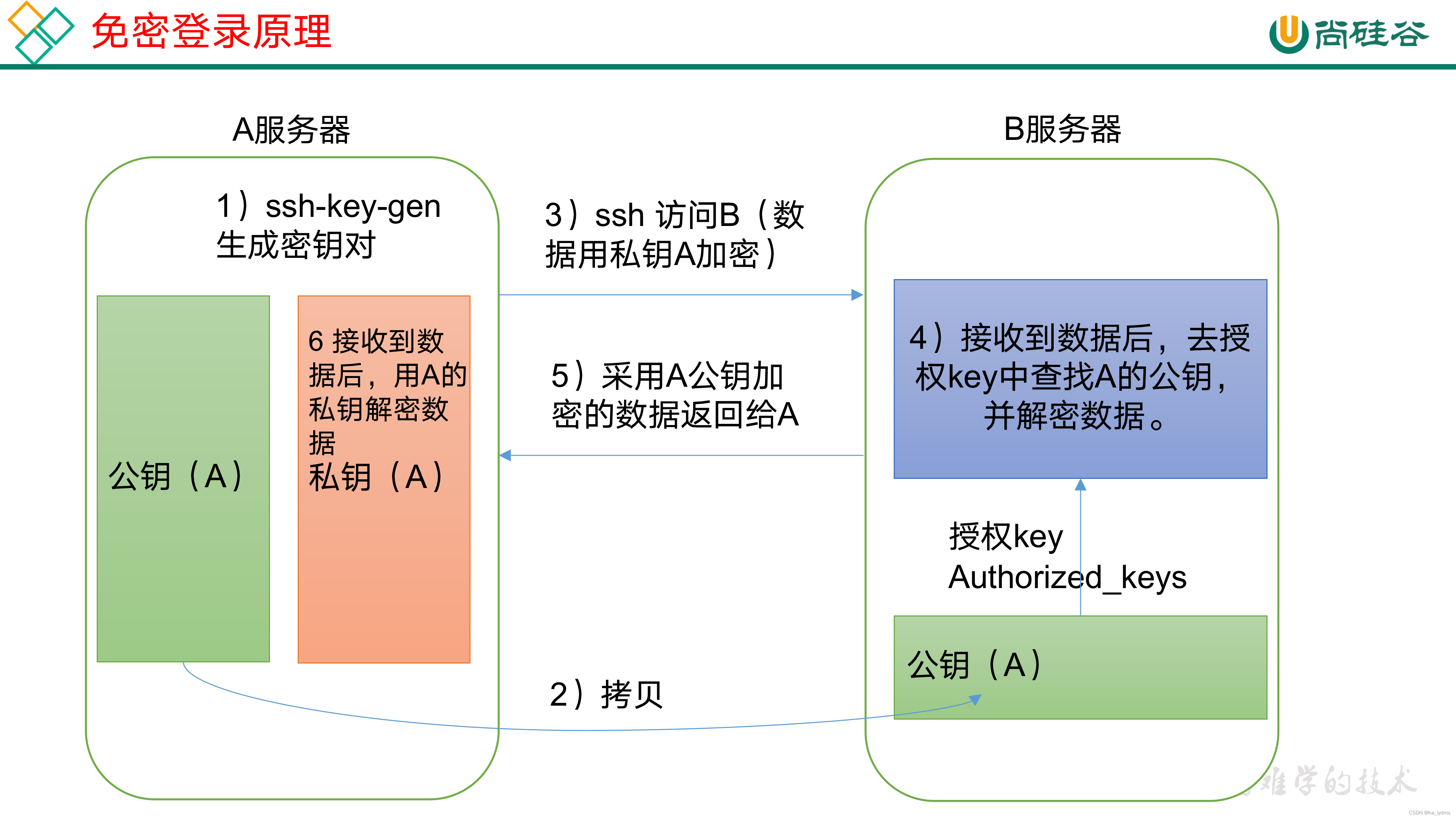
2、SSH免密登录设置
原理
生成公私钥
ssh-keygen -t rsa
查看生成文件
cd /home/lydms/.ssh/
ll
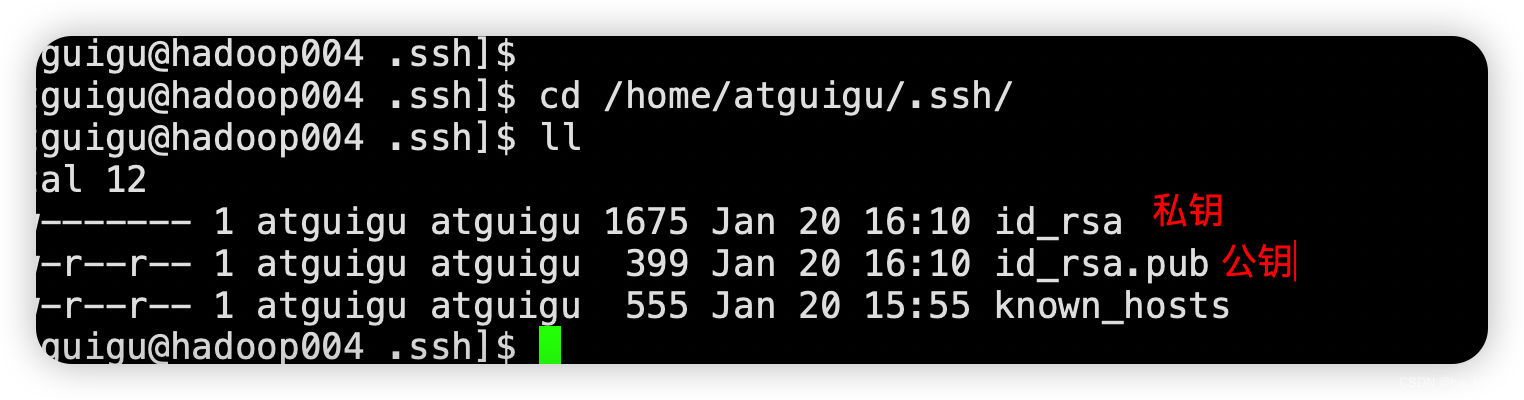
| known_hosts | 记录ssh访问过计算机的公钥public key |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
将公钥拷贝到要免密登录的目标机器上(输入相应密码)
几台服务器之间都要互相配置
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
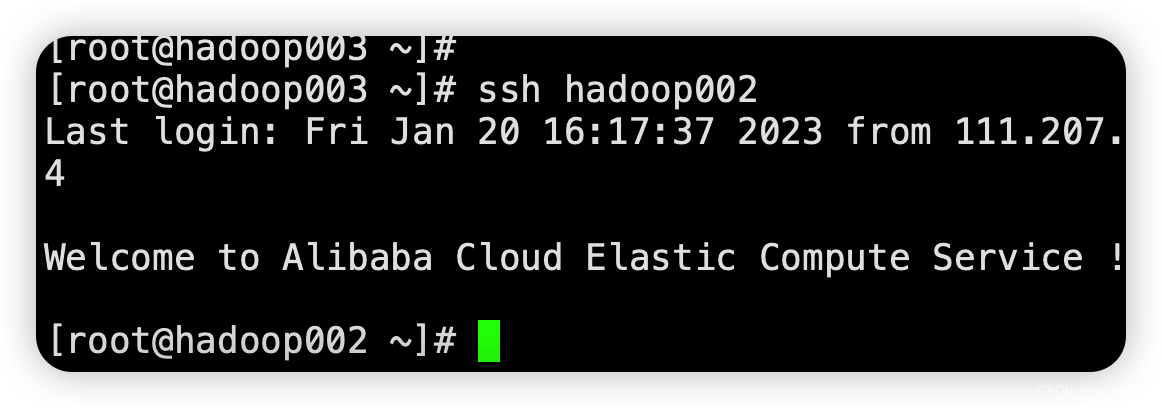
测试
ssh hadoop001
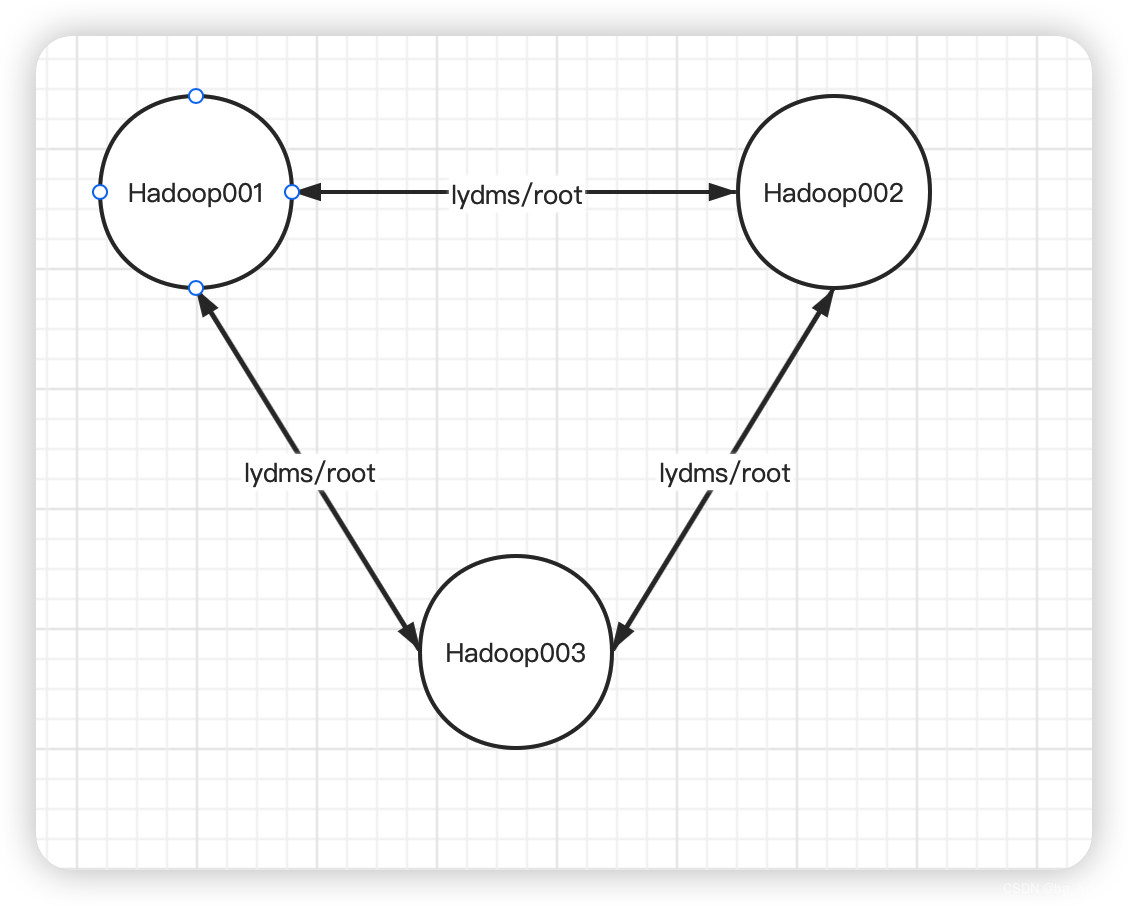
还需要配置(集群各个节点之间免密沟通)
hadoop101上采用root账号配置一下免密登录到hadoop101、hadoop102、hadoop103。hadoop102上采用root账号配置一下免密登录到hadoop101、hadoop102、hadoop103。hadoop103上采用root账号配置一下免密登录到hadoop101、hadoop102、hadoop103
最终效果
3、同步文件
-
同步环境变量
/etc/profile.d/my_env.sh -
同步JDK、Hadoop
/opt/model
同步环境变量
xsync /etc/profile.d/my_env.sh
# 在各个节点服务器中加载环境变量(hadoop001、hadoop002、hadoop003)
source /etc/profile
同步JDK、Hadoop
xsync /opt/module/
4、集群节点资源配置
- NameNode和SecondaryNameNode不要安装在同一台服务器。
- ResourceManager也很消耗内存不要和NameNode、SecondaryNameNode配置在同一台机器上。
| Hadoop001 | Hadoop002 | Hadoop003 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
Hadoop配置文件分两类默认配置文件和自定义配置文件只有用户想修改某一默认配置值时才需要修改自定义配置文件更改相应属性值。
默认配置文件。
| 默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上用户可以根据项目需求重新进行修改配置。
4.1 核心配置文件(core-site.xml)
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml
文件内容
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为lydms -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>lydms</value>
</property>
</configuration>
4.2 HDFS配置文件(hdfs-site.xml)
vim hdfs-site.xml
文件内容
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
</configuration>
4.3 YARN配置文件(yarn-site.xml)
vim yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
4.4 MapReduce配置文件mapred-site.xml
vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.5 分发配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
5、群起集群
5.1 配置workers
新增节点配置文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
hadoop101
hadoop102
hadoop103
同步配置
xsync /opt/module/hadoop-3.1.3/etc
5.2 启动集群
如果集群是第一次启动需要在hadoop001节点格式化NameNode。
注意格式化NameNode会产生新的集群id导致NameNode和DataNode的集群id不一致集群找不到已往数据。如果集群在运行过程中报错需要重新格式化NameNode的话一定要先停止namenode和datanode进程并且要删除所有机器的data和logs目录然后再进行格式化。
hdfs namenode -format
启动HDFS
# 启动
/opt/module/hadoop-3.1.3/sbin/start-dfs.sh
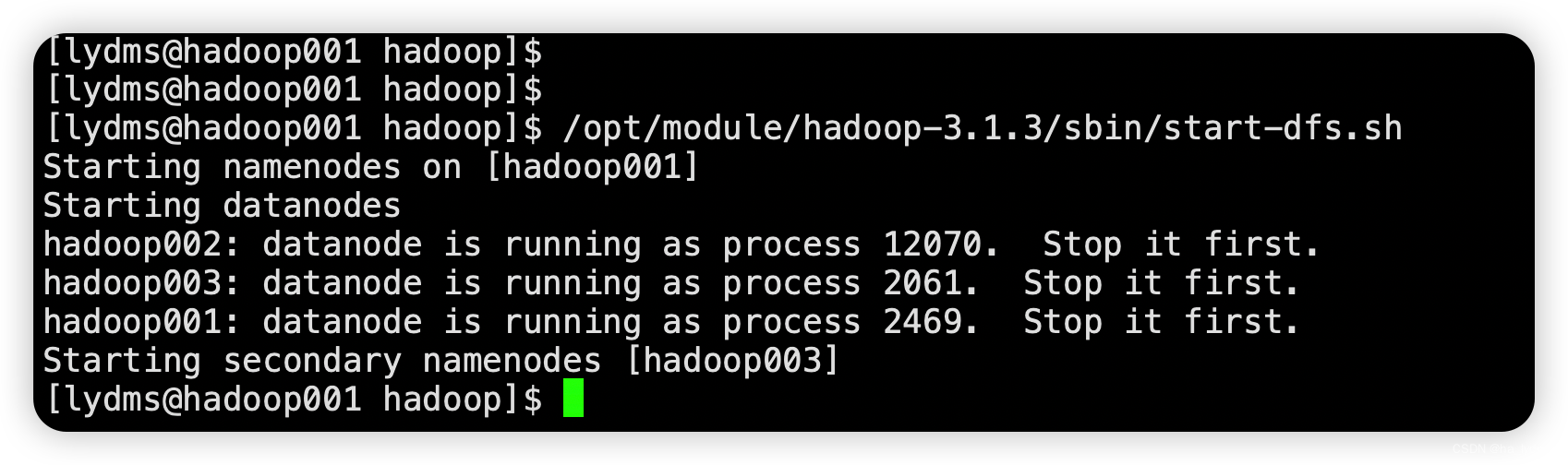
启动YARN配置了ResourceManager的节点hadoop002
# 启动
/opt/module/hadoop-3.1.3/sbin/start-yarn.sh

5.3 其它启动停止方式
启动/停止HDFS
# 整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
# 分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
启动/停止YARN
# 整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
# 分别启动/停止YARN组件
yarn --daemon start/stop resourcemanager/nodemanager
5.4 启动脚本
新建启动/停止集群脚本
cd /home/lydms/bin
vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " ======启动 hadoop集群 ======="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
;;
"stop")
echo " ==========关闭 hadoop集群 ========="
echo " --------------- 关闭 yarn ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
赋予脚本执行权限
chmod +x myhadoop.sh
新建Java进程脚本jpsall
cd /home/lydms/bin
vim jpsall
#!/bin/bash
for host in hadoop101 hadoop102 hadoop103
do
echo =============== $host ===============
ssh $host jps
done
赋予脚本执行权限
chmod +x jpsall
分发/home/atguigu/bin目录保证自定义脚本在三台机器上都可以使用
xsync /home/lydms/bin/
6、查看相关页面
Web端查看HDFS的NameNode
http://hadoop101:9870/
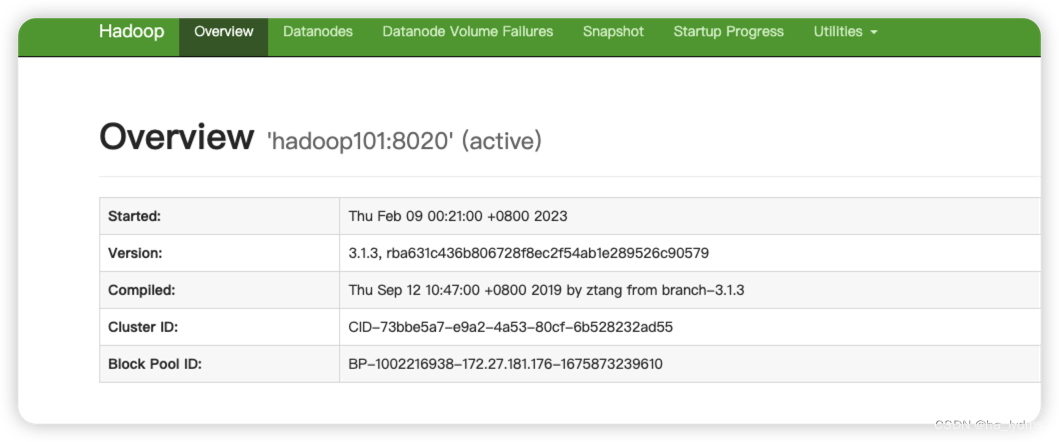
Web端查看YARN的ResourceManager
http://hadoop102:8088
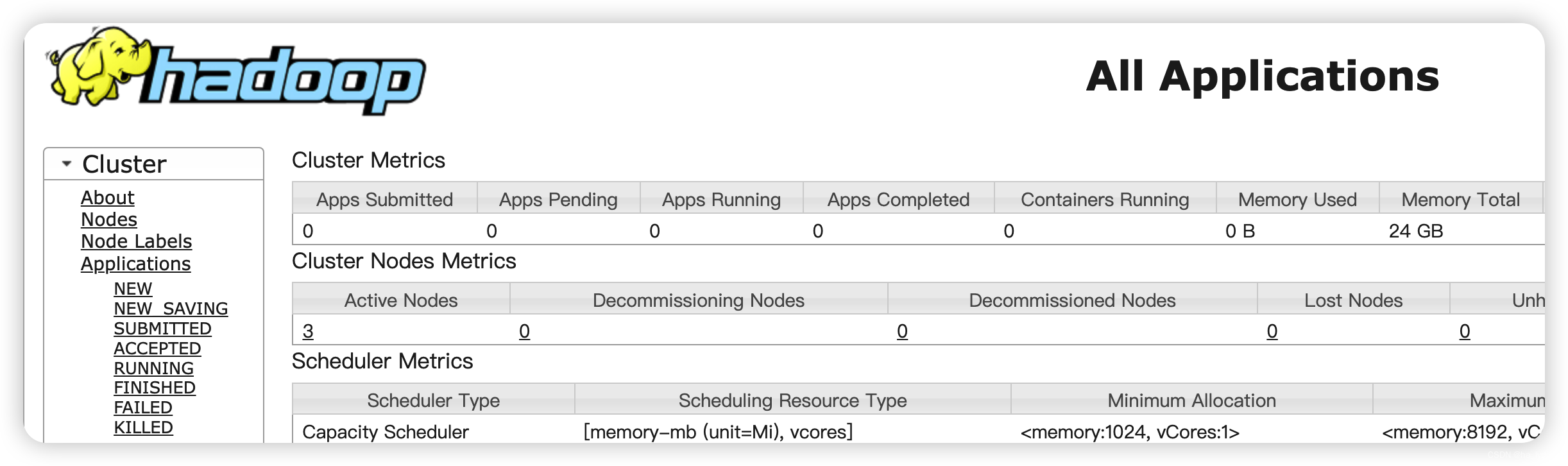
7、配置历史服务器
vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
</configuration>
分发配置
xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
hadoop101启动历史服务器
mapred --daemon start historyserver
查看是否启动
jps

查看页面
http://hadoop101:19888/jobhistory
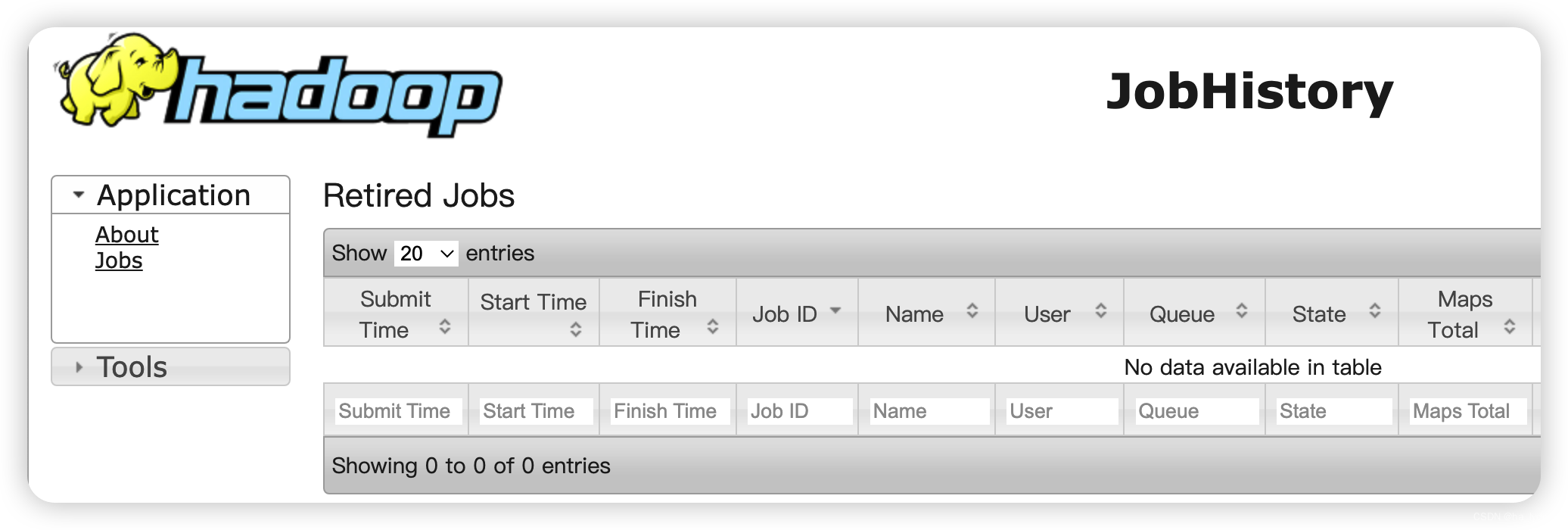
8、配置日志的聚集
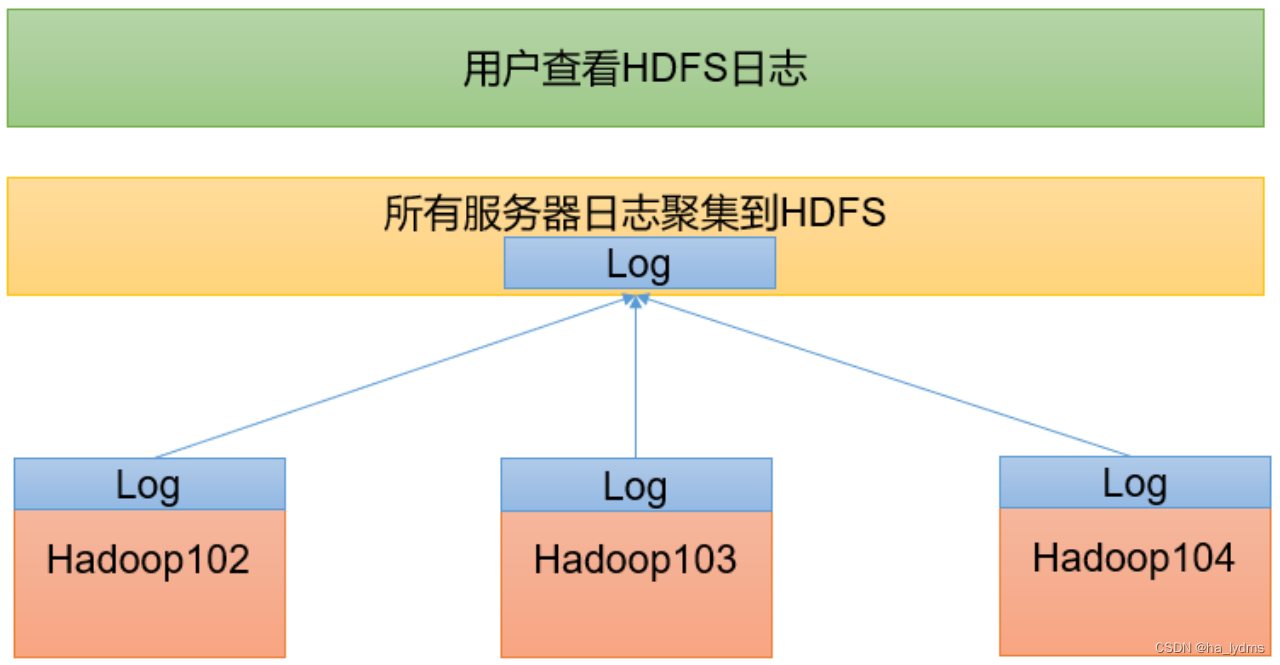
日志聚集概念应用运行完成以后将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处可以方便地查看到程序运行详情方便开发调试。
**注意**开启日志聚集功能需要重新启动NodeManager 、ResourceManager和HistoryServer。
vim yarn-site.xml
新增配置
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
分发配置
xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
删除HDFS上已经存在的输出文件(可以通过页面删除)
hadoop fs -rm -r /output
需要重启Hadoop集群
/home/lydms/bin/myhadoop.sh stop
/home/lydms/bin/myhadoop.sh start
9、其它
9.1 常用端口号
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
9.2 常用页面
Web端查看HDFS的NameNode
http://hadoop101:9870/
YARN的ResourceManager
http://hadoop102:8088
历史服务器
http://hadoop101:19888/jobhistory
五、遇到问题
1、编辑文件无权限(‘readonly’ option is set (add ! to override))
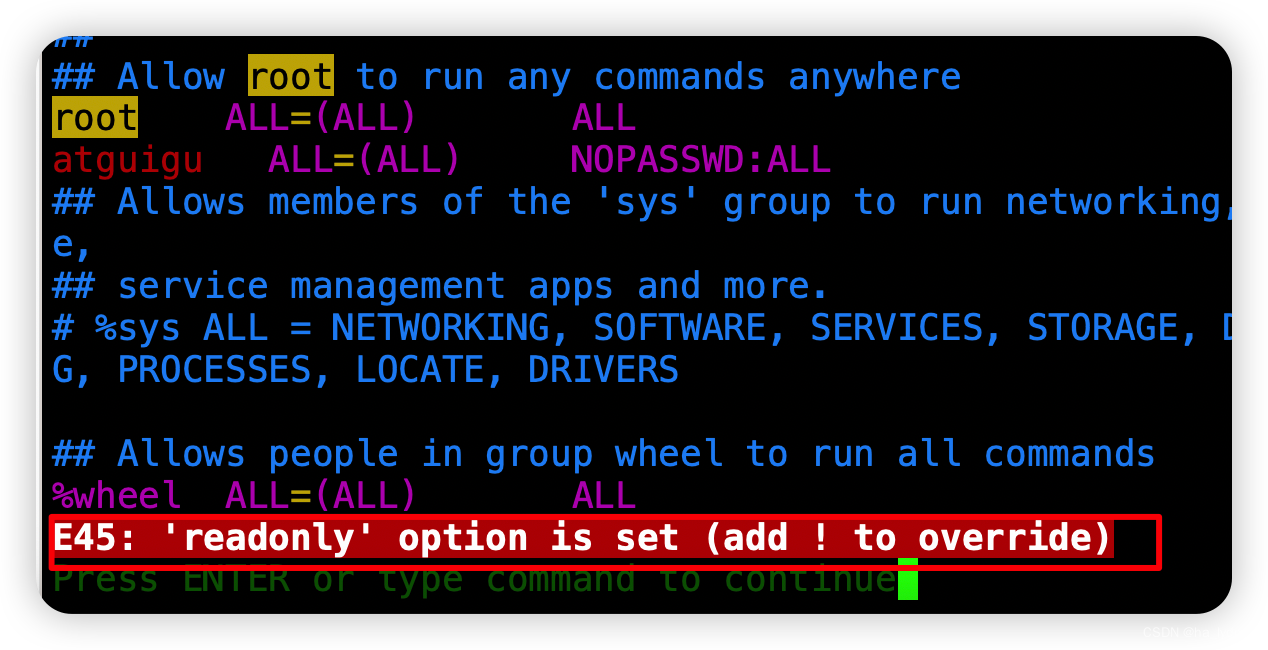
原因
当前文件为不可以编辑权限
解决
chmod 660 /etc/sudoers