

猿创征文|Hadoop大数据技术
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Hadoop大数据技术
昨夜西风凋碧树。独上高楼望尽天涯路。
Hadoop背景
数据已经渗透到当今每一个行业和业务职能领域成为重要的生产因素。人们对于海量数据的挖掘和运用预示着新一波生产率增长和消费者盈余浪潮的到来——麦肯锡

大数据Big Data是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据并不等同于海量数据基本特征如下
- Volume数据体量大存储量大、增量大
- Velocity处理速度快高速数据、高速处理
- Variety数据类型多来源多、类型多
- Value价值密度低
- Veracity数据准确性
当今互联网、云计算、移动与物联网发展迅猛移动设备、RFID、无线传感器每分每秒都在产生数据数以亿计用户的互联网服务时时刻刻在产生巨量的交互。而传统方案集中式存储与计算同时需要考虑设备性能、成本等问题难以满足要求因此架构基于大规模分布式计算MPP的 GFS/HDFS 分布式文件系统、各种 NoSQL分布式 等新方案应运而生。另外在大数据处理上 Hadoop 对于大部分的企业来说基于 Hadoop 已经能够满足绝大部分的数据需求因此才会成为现在的主流选择。

Hadoop生态圈
Hadoop生态圈由 Apache基金会 所开发的分布式系统基础框架用于分布式大数据处理的开源框架允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。
Hadoop生态圈
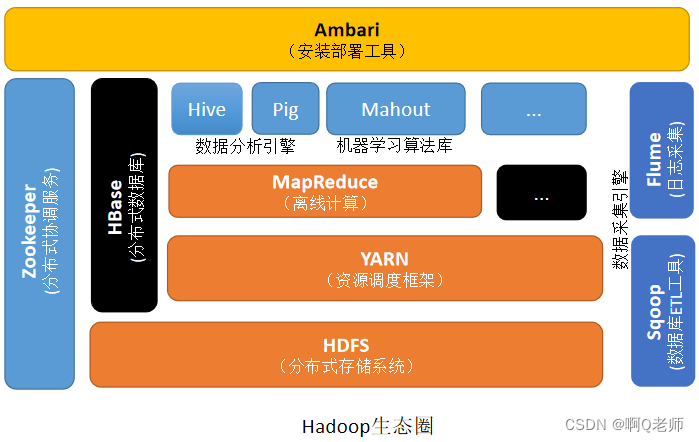
Hadoop生态圈组件说明

Hadoop典型应用架构
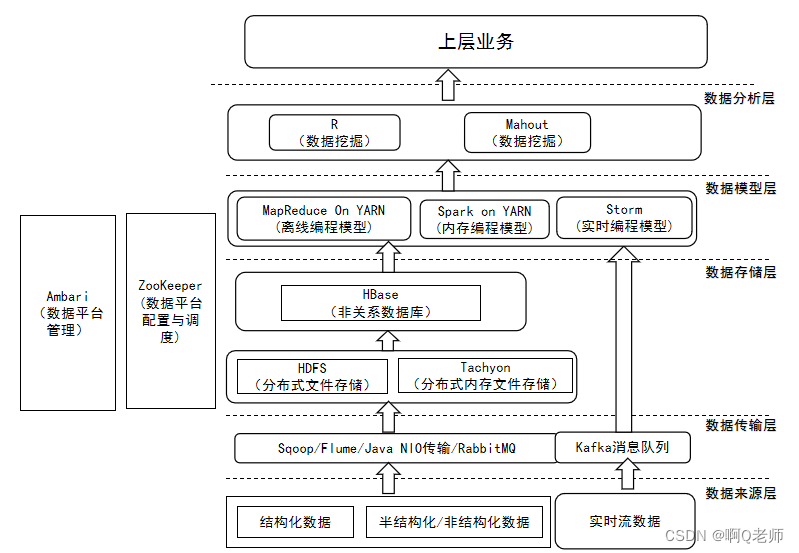
Hadoop模式
- 单机模式Hadoop默认模式在单机上按默认配置以非分布式模式运行的一个独立Java进程没有分布式文件系统HDFS直接在本地操作的文件系统读写一般仅用于本地MapReduce程序的调试。
- 伪分布式模式单机上模拟一个分布式的环境具备Hadoop的主要功能常用于调试程序。
- 完全分布式模式也叫集群模式Hadoop的守护进程运行在由多台主机搭建的集群上是真正的分布式环境是用于实际的生产环境。
HDFS

概述
HDFSHadoop Distributed File SystemHadoop分布式文件系统是 Hadoop 项目的核心子项目是分布式计算中数据存储管理的基础。支持海量数据的存储成百上千的计算机组成存储集群HDFS 可以运行在低成本的硬件之上具有的高容错、高可靠性、高可扩展性、高吞吐率等特征非常适合大规模数据集上的应用。
优点
- 高容错性以数据复制多份并存储在集群的不同节点来实现数据容错。
- 高扩展性Hadoop是在可用的计算机集簇间分配数据并完成计算任务的这些集簇可以方便地扩展到数以千计的节点中。
- 高吞吐率延时较低可存储非常大的文件。
- 低成本可构建在廉价机器上。
- 采用流式的数据访问方式即一次写入多次读取保证数据一致性。
- 适合批处理
- 适合大数据处理
缺点
- 不适合低延迟数据访问Hadoop优化了高数据吞吐量牺牲了获取数据的延迟从而Hadoop不适合低延迟数据访问而HBase更适合低延迟访问需求。
- 不适合大量的小文件存储NameNode将文件系统的元数据存储在内存中因此该文件系统所能存储的文件总数受限于NameNode的内存容量。
- 不适合并发写入、文件随机修改
基本组成
HDFS主要由主节点NameNode、辅助名称节点Secondary NameNode、数据节点DataNode组成。
NameNode
NameNode的职责主要是管理维护 HDFS即管理DataNode上文件Block的均衡维持副本数量接收客户端的请求上传、下载、创建目录等维护 edits 与 fsimage 两个重要的文件。
其中
edits 文件记录操作日志元数据的每一次变更操作都会被记录到edits中。
fsimage 文件HDFS的元信息NameNode节点的元数据运行在内存中为防止宕机数据丢失每隔一段时间会将元数据持久化到磁盘中。
Secondary NameNode
Secondary NameNode主要职责是 定期地创建命名空间的检查点CheckPoint操作——把edits中最新的状态信息合并到 fsimage 文件中防止 edits 过大也可以做冷备即两个服务器一个运行一个不运行做备份对一定范围内数据块做快照性备份。
DataNode
DataNode的主要职责是存储数据块负责客户端对数据块的 io 请求DataNode 定时和 NameNode 进行心跳通信接受 NameNode 的指令。
YARN
YARN Yet Another Resource Negotiator另一种资源协调者一种新的 Hadoop 资源管理器。它是一个通用资源管理系统最初是为了改善MapReduce的实现但也是一种资源调度框架具有通用性可为上层应用提供统一的资源管理和调度可以支持其他的分布式计算模式如Spark。它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
- ResourceManager资源管理器负责整个系统的资源分配和管理是一个全局的资源管理器。它主要由两个组件构成调度器和应用程序管理器。
- 调度器Scheduler根据资源情况为应用程序分配封装在 Container 中的资源。
- 应用程序管理器Application Manager负责管理整个系统中所有应用程序。
- NodeManager节点管理器每个节点上的资源和任务管理器。它会定时向 ResourceManager 汇报本节点上的资源使用情况和各个 Container 的运行状态并接收并处理来自 ApplicationManager 的 Container 启动/停止等请求。
- Container容器YARN中的资源抽象它封装了某个节点上的多维度资源。另外YARN会为每个任务分配一个 Container 。
- ApplicationMaster 主应用用户提交的每一个应用程序均包含一个 ApplicationMaster 。它是一个详细的框架库它结合从 ResourceManager 获得的资源和 NodeManager 协同工作来运行和监控任务。主要功能包括
- 与 ResourceManager 调度器协商以获取抽象资源Container
- 负责应用的监控跟踪应用执行状态重启失败任务等
- 并且与 NodeManager 协同工作完成Task的执行和监控 。
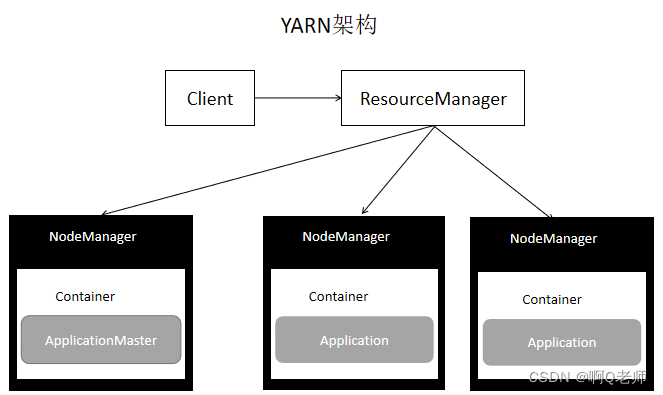
YARN中应用Application运行机制流程
1Client 向 ResourceManager 提交 YARN Application
2 ResourceManager 启动 Container
3 在 NodeManager 的协助下启动 Container首次启动Container 里面包含 Application Master
4 Application Master 计算资源是否足够如果够则自己处理 如果不够Application Master 向 ResourceManager 申请资源
6Application Master 获取到资源后开始启动 Container
7在NodeManager的协助下启动 ContainerApplication 运行 。
YARN中任务进度监控
1任务运行时向自身的 ApplicationMaster 报告进度和状态
2ApplicationMaster 形成一个作业的汇聚视图
3客户端向 ApplicationMaster 获取最新状态 。
YARN调度器Scheduler
YARN调度器Scheduler负责给应用分配资源。但资源的有限需要考虑采用资源利用率最高的策略。
YARN调度器
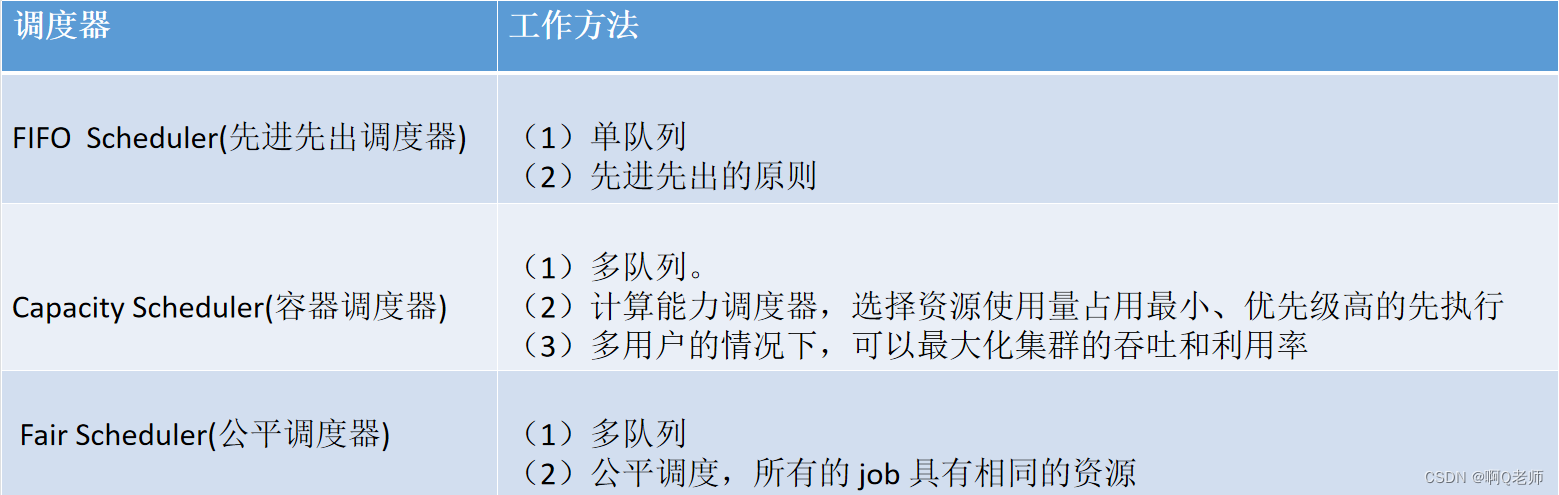
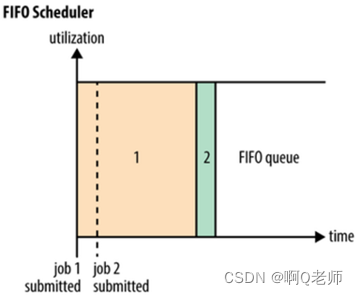
FIFO Scheduler
FIFO Scheduler最简单的调度器所有用户提交应用到仅有一个的队列中按照先进先出的方式处理。可以针对这个队列设置ACL。没有应用优先级可以配置。
如下图
Capacity Schedule
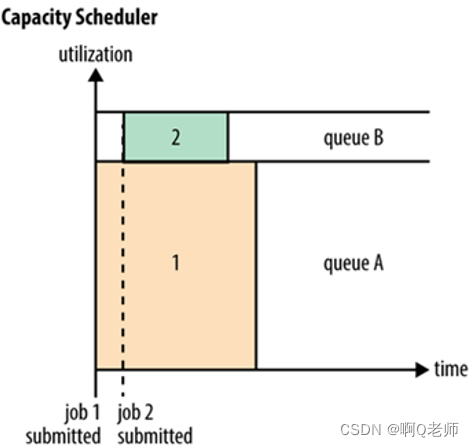
Capacity Schedule可以看作是FIFO Scheduler的多队列版本。每个队列可以限制资源使用量。但队列间的资源分配以使用量作排列依据使得容量小的队列有竞争优势。
注若不限制某队列最大容量则运行过程中它可以占用全部资源。
如下图
Fair Scheduler
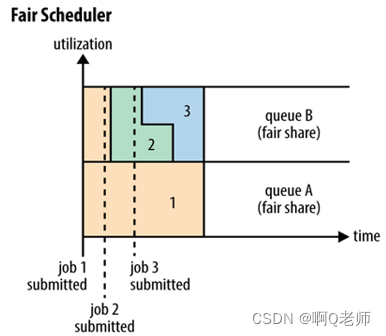
Fair Scheduler多队列多用户共享资源。特有的客户端创建队列的特性使得权限控制不太完美。根据队列设定的最小共享量或权重等参数按比例共享资源。延迟调度机制跟Capacity Schedule的目的类似但是实现方式稍有不同。
资源抢占特性是指调度器能够依据公平资源共享算法计算每个队列应得的资源将超额资源的队列的部分容器释放掉的特性。
如下图
衣带渐宽终不悔为伊消得人憔悴。
MapReduce
MapReduce是一种简化并行计算的编程模型用于进行大数据量的计算。
设计思想
MapReduce采用“分而治之”的思想把对大规模数据集的操作分发给一个主节点管理下的各个子节点共同完成然后整合各个子节点的中间结果得到最终的计算结果。即“分散任务汇总结果”。
编程模型
MapReduce是一种编程模型用于大规模数据集大于1TB的并行运算。概念"Map映射“和"Reduce归约”是它们的主要思想都是从函数式编程语言里借来的还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map映射函数用来把一组键值对映射成一组新的键值对指定并发的Reduce归约函数用来保证所有映射的键值对中的每一个共享相同的键组。
初识MapReduce模型
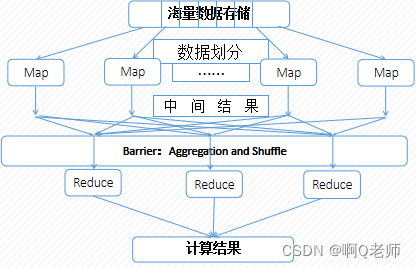
MapReduce模型简单示例
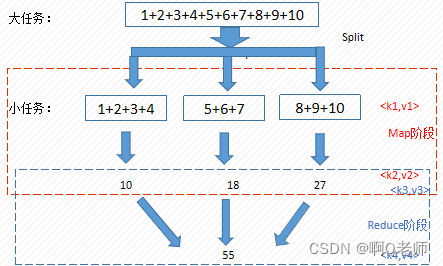
MapReduce编程模型
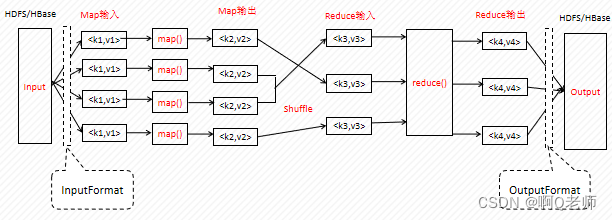
编程模型实例-分析好友关注
创建文本文件friends.txt内容为
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J,K
一、求互粉好友对 数据格式如下
人:关注列表
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
…
上述数据中A-B就是一对互粉好友对 最终结果所有互粉对的集合 X-Y、Y-X
解决思路
map阶段
1、列出所有的关注关系value都为1。如 A:B,C,D => A-B 1,A-C 1,A-D 1。
2、始终把字母顺序小的排在前。如 D-A => A-D F-A => A-F。reduce阶段
3、相同key的value总和大于1的说明两者为互粉。如 A-D的value总和为2说明AD互粉。
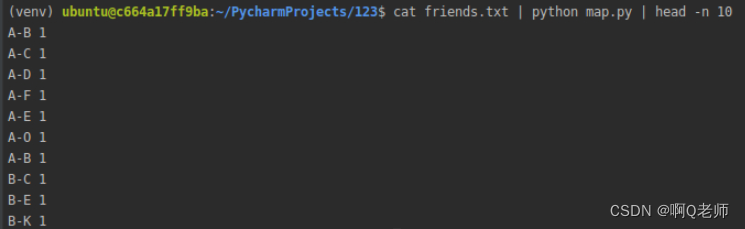
map.py
#导入sys模块与Python解释器进行交互
import sys
#sys.stdin 即Python的标准输入通道通过键盘输入的字符
for line in sys.stdin:
if line[0] != '':
#strip() ——该方法用于删除字符串头尾指定的字符默认空格删除空格符或者换行符split()——该方法为指定分隔符对字符串进行切分默认空格空格切分
Me = line.strip().split(':')[0]
frieds = line.strip().split(':')[1].split(',')
for i in Me:
for fan in frieds:
n = i + fan
m = sorted(n)
s = m[0] + '-' + m[1]
print(s,1)
#本地管道测试
cat friends.txt | python map.py | head -n 10
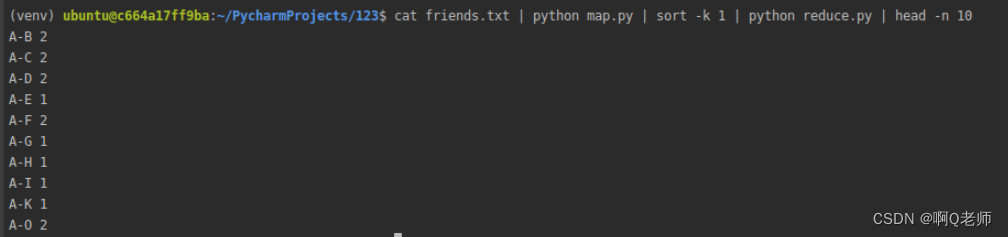
reduce.py
import sys
compare = None
count = 0
for line in sys.stdin:
if line[0] != 0 :
s = line.strip().split()[0]
if compare == None:
compare = s
if compare != s:
print(compare,count)
compare = s
count = 0
count += 1
print(compare,count)
cat friends.txt | python map.py | sort -k 1 | python reduce.py | head -n 10
Hive
Hive 是基于 Hadoop 的一个数据仓库工具可以将结构化的数据文件映射为一张数据库表并提供简单的 SQL 查询功能可以将 SQL 语句转换为 MapReduce 任务来执行。学习成本低可以通过类似 SQL 语句实现快速 MapReduce 统计而不必开发专门的 MapReduce 应用程序。Hive 十分适合对数据仓库进行统计分析。

体系结构
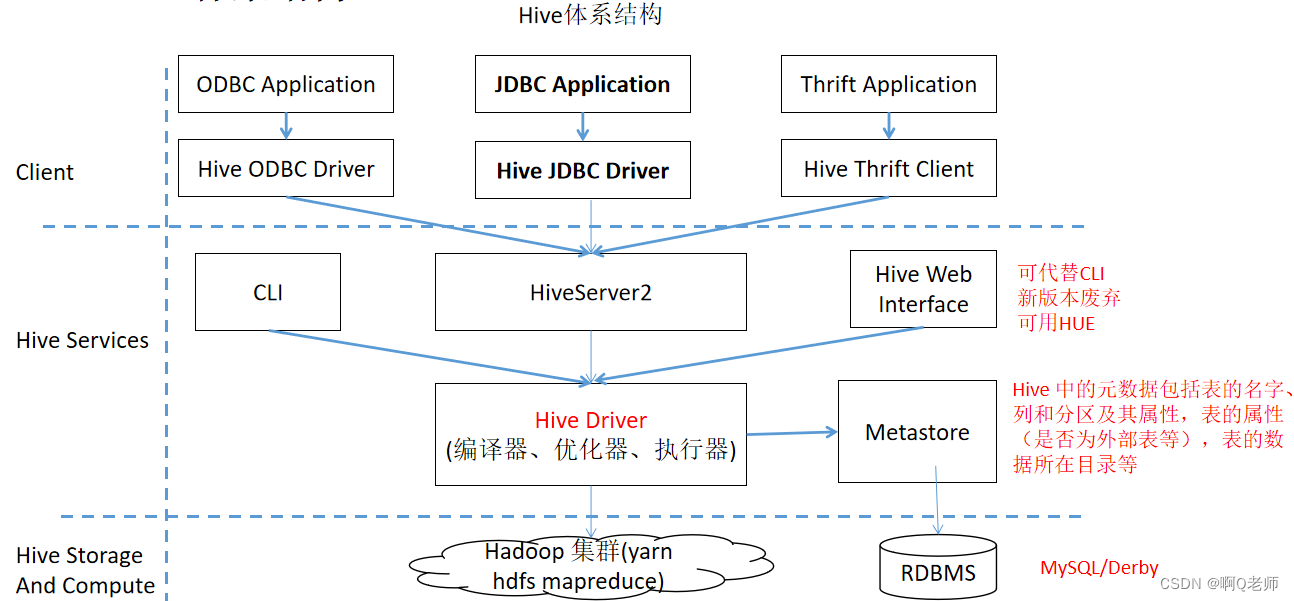
- CLICommand Line Interface命令行界面一种非图形化用户界面即字符用户界面用户通过输入命令与应用程序进行交互。CLI启动的同时会启动一个 Hive 副本。
- ODBCOpen Database Connectivity开放数据库连接帮助任何语言编写的应用程序访问不同类型的数据库。通过 Java 的方式访问 Hive 。
- JDBCJava Database ConnectivityJava数据库连接帮助 Java语言 编写的应用程序访问不同类型的数据库。通过 Java 的方式访问 Hive 。
- HWIHive Web InterfaceHive Web界面通过浏览器访问 Hive 。
- HS2Hive Server2一种能使客户端执行Hive查询并返回结果的服务支持多客户端并发和身份验证。Hive Server 的核心是基于 Thrift Thrift 负责 Hive 的查询服务Thtift 是构建跨平台的 RPC 框架。
- Thrift一种接口描述语言和二进制通讯协议它被用来定义和创建跨语言的服务。它被当作一个远程过程调用 RPC 框架来使用是由 Facebook 为“大规模跨语言服务开发”而开发的。而 ODBC/JDBC 都是通过 Hive Client 与 Hive Server 来保持通讯借助 Thrfit RPC 协议来实现交互。
- Hive Driver是 Hive 的核心组件该组件包括Complier编译器、Optimizer优化器和Executor执行器。其接收查询请求经过对Hive SQL进行解析、编译优化将其转换成一个Hive Job并发送给 Hadoop 集群。
- Metastore访问 Hive 的元数据元数据是描述数据属性的信息即是关于数据的数据。
- RDBMSRelational Database Management System关系数据库管理系统指包括相互联系的逻辑组织与存取这些数据的一套程序数据库管理系统软件。即管理关系数据库并将数据逻辑组织的系统。
工作原理
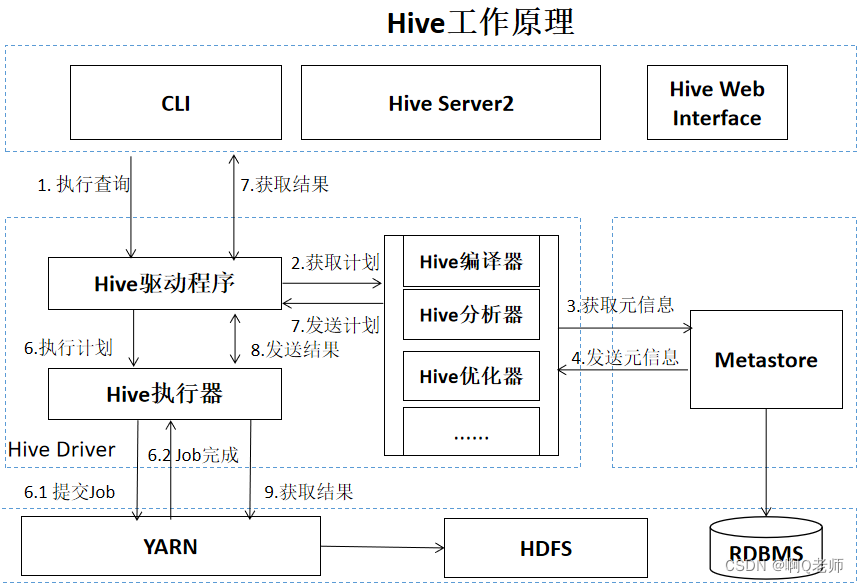
HiveQL
HiveQL 是一种 Hive 定义的类SQL语言提供熟悉SQL的用户方便查询数据。Hive 支持的数据类型有基本数据类型、复杂数据类型与时间类型不区分大小写。
- 基本数据类型
Tinyint / Smallint / Int / Bigint 整数类型
Float / Double浮点数类型
Boolean布尔类型
String字符串类型- 复杂数据类型
Array数组类型由一系列相同数据类型的元素组成
Map集合类型包含<key,value>键值对可以通过key来访问元素
Struct结构类型可以包含不同数据类型的元素。其元素可以通过”点语法”的方式来得到所需要的元素- 时间类型
Date从Hive0.12.0开始支持
Timestamp从Hive0.8.0开始支持
基础语法
HiveQL与SQL语法类似这里简单了解一下
#创建TableName表字段有学号、姓名与所在系
create table TableName(id int, name string, sno string) row format delimited fields terminated by ',';
#TableName表导入本地数据
load data local inpath '数据路径' into table TableName;
#查询
select * from TableName;
#条件查询
select * from TableName where id = 01 ;
#模糊查询
select * from TableName where id like '0%'; 查询id以 ‘0开头’ 的信息
#按所在系分组查询
select * from TableName group by sno;
#按id排序查询
select * from TableName order by id;
内部表
按照表数据的生命周期可将表分为两类内部表与外部表。
内部表管理表在概念上与数据库中的表是类似的。Hive 可以控制该表的生命周期。默认情况下该表的数据都保存在这个目录下/user/hive/warehouse)。 当删除表时Hive也会删除该表中的数据将表文件删除。内部表不适合和其他工具共享数据。
#创表
create table TableName(id int, name string, sno string) row format delimited fields terminated by ',';
#导入数据
load data inpath '数据路径' into table TableName; 导入HDFS的数据
load data local inpath '数据路径' into table TableName; 导入本地Linux的数据
外部表
外部表创建表时会用 external 修饰。Hive 不可以控制该表的生命周期。它与内部表在元数据的组织上是相同的但实际数据的存储则有较大的差异。外部表只有一个过程加载数据和创建表同时完成并不会移动到数据仓库目录中只是与外部数据建立一个链接。当删除外部表时仅删除该链接。外部表的数据可以同时作为多个外部表的数据源共享使用。
#创表
create external table TableName(id int, name string, sno string) row format delimited fields terminated by ',' location '存放目录';
分区表
分区表是将大表的数据分成称为分区的许多小的子集。在 Hive 中表中的一个 Partition 对应于表下的一个目录所有的 Partition 的数据都存储在对应的目录中。
#根据id创建分区
create table TableName(id int, name string, sno string) partitioned by (id int) row format delimited fields terminated by ',';
#往分区表中插入数据指明导入的数据的分区
load data inpath '数据路径' into table TableName partition(id=01);
...
#或者
load data inpath '数据路径' into table DataTable;
insert into table TableName partition(id=01) select id, name, sno from DataTable where id=01; 从DataTable导入数据
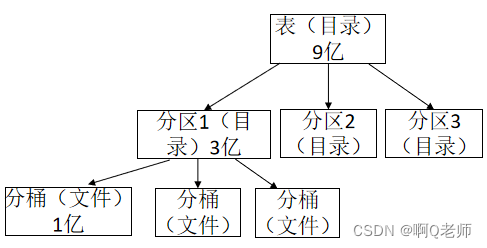
桶表
桶表是对数据进行哈希取值然后放到不同文件中存储。即将数据集分解成更容易管理的若干部分。
#设置环境变量
set hive.enforce.bucketing = true;
#创建一个桶表根据 id 进行分桶
create table TableName(id int, name string, sno string) clustered by (id int) into 3 buckets row format delimited fields terminated by ',';
#通过子查询插入数据
insert into TableName select * from DataTable;
视图
视图是一种虚表是一个逻辑概念即数据库中只存放着视图的定义而不存放视图对应的数据而这些数据仍存放在导出视图的基表中视图建立在已有表的基础上, 视图赖以建立的表称为基表。视图是只读的可以跨越多张表可以简化复杂的查询但不能提高查询的效率。
Hive调优
Hive 最终都会转化为 MapReduce 的 job 来运行Hive 调优实际上就是 MapReduce 的调优。有以下五个方面
1解决数据倾斜问题减少 job 数量
2设置合理的 Map 和 Reduce 个数
3对小文件进行合并
4优化时把握整体单个 task 最优不如整体最优
5按照一定规则分区
Pig简介
Pig 是一个基于 Hadoop 的大规模数据分析平台它提供的 SQL-LIKE 语言叫 Pig Latin该语言的编译器会把 类SQL 的数据分析请求转换为一系列经过优化处理的 MapReduce 运算适用于 Hadoop 平台来查询大型半结构化数据集如日志文件。Pig 为复杂的海量数据并行计算提供了一个简单的操作和编程接口。
Pig 赋予开发人员在大数据集领域更多的灵活性并允许开发简洁的脚本用于转换数据流以便嵌入到较大的应用程序。而 Hive 更适合于数据仓库的任务Hive 主要用于静态的结构以及需要经常分析的工作。

众里寻他千百度蓦然回首那人却在灯火阑珊处。