

机器学习:聚类算法API初步使用
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
学习目标
- 知道聚类算法API的使用
1 api介绍
- sklearn.cluster.KMeans(n_clusters=8)
- 参数:
- n_clusters:开始的聚类中心数量
- 整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数。
- 方法:
- estimator.fit(x)
- estimator.predict(x)
- estimator.fit_predict(x)
- 计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
2 案例
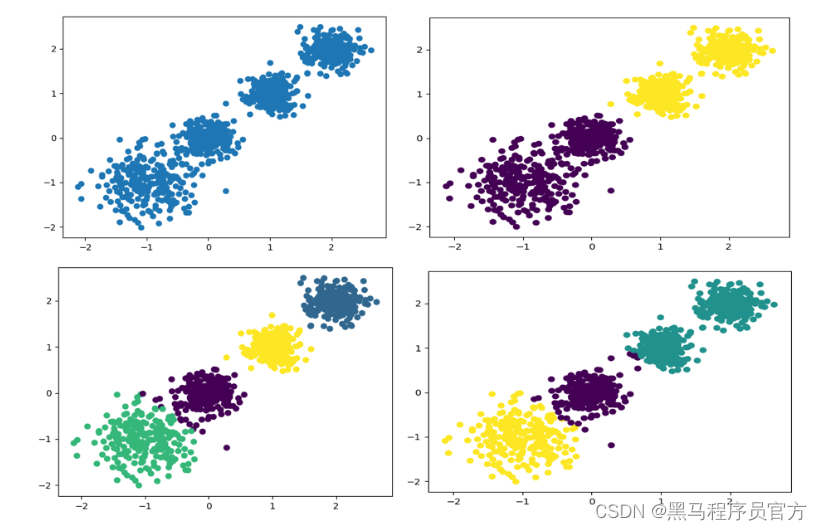
随机创建不同二维数据集作为训练集,并结合k-means算法将其聚类,你可以尝试分别聚类不同数量的簇,并观察聚类效果:
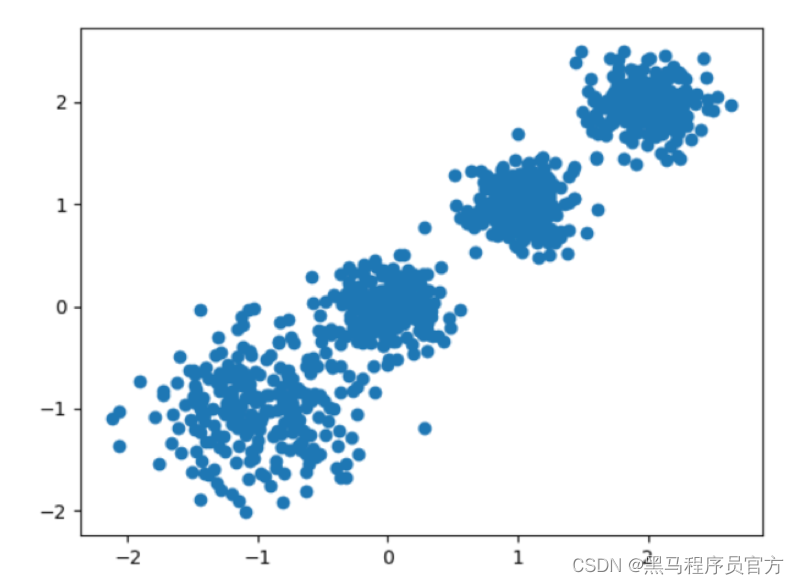
聚类参数n_cluster传值不同,得到的聚类结果不同
2.1流程分析
2.2 代码实现
1.创建数据集
2.使用k-means进行聚类,并使用CH方法评估
3 小结
- api:sklearn.cluster.KMeans(n_clusters=8)【知道】
- 参数:
- n_clusters:开始的聚类中心数量
- 方法:
- estimator.fit_predict(x)
- 计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |