

chatGPT讲师AIGC讲师叶梓:大模型这么火,我们在使用时应该关注些什么?-5-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
以下为叶老师讲义分享
P25-P28
提示工程的模式
- 9、翻译是一种转化。 由于人类对语言理解的巨大需求翻译涉及 ChatGPT 翻译和转换不同的语言或术语。
- 10、推理模式下可以让 ChatGPT 观察和推断未知的事实或逻辑关系。 它的价值在于提供更全面的解决方案和灵感。
- 11、感应模式下ChatGPT 可以从具体的例子或事实中归纳出一般规则或结论看到一些事物的本质。
- 12、模拟 模式下可以让 ChatGPT 模拟一个过程或现象
- 13、演员 模式下可以让你与其进行更专注、更专业的对话提高获取信息的效率。
微调大模型的意义
- 节省计算资源
- 在微调过程中不需要重新训练整个模型因此可以节省计算资源。
- 提高特定任务上的性能
- 通过微调模型可以适应特定任务的语言特征和模式从而提高模型的性能。
- 保留模型的通用性
- 预训练模型具有较高的通用性能微调可以帮助模型适应特定任务的语言特征和模式从而提高模型的通用性。
- 减少数据需求
- 预训练模型已经过大量训练因此在微调过程中可以使用较少的数据。
微调大模型的方法Adapter-Tuning
- 微调时冻结预训练模型的主体由Adapter模块学习特定下游任务的知识。
- Adapter调优的参数量大约为LM参数的3.6%。

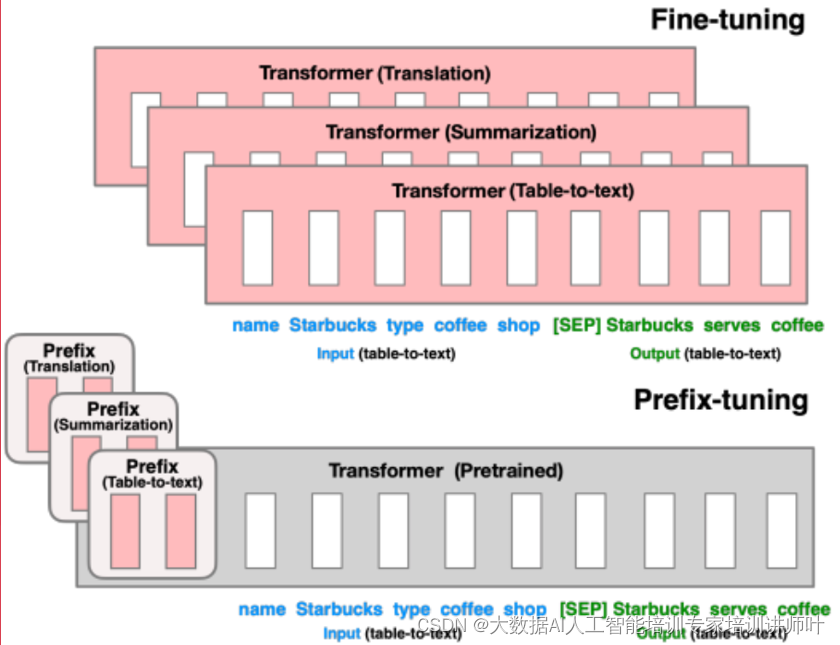
- Prefix Tuning只是在每个任务前有少量的prefix的参数
- 比如翻译任务可以在每句话的前面加上“翻译”来引导模型进行翻译功能。
- Prefix Tuning参数规模约为LM模型整体规模的0.1%。
未完下一章继续……