

JavaSE与网络面试题
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
大佬的 https://github.com/Snailclimb/JavaGuide
https://osjobs.net/topk/all/
自增自减
要点
-
赋值 = 最后计算
-
= 右边的从左到右加载值一次压入操作数栈
-
实际先算哪个看运算符的优先级
-
自增、自减操作都是直接修改变量的值不经过操作数栈
-
做后赋值之前临时结果也是先储存在数栈中
-
局部变量表 存储局部变量 和 操作数栈 进行运算
-
++ 在前先赋值给局部变量然后在压入操作数栈
-
++ 在后先压入操作数栈在赋值给局部变量





答案
i = 4
j = 1
k = 11
单例模式
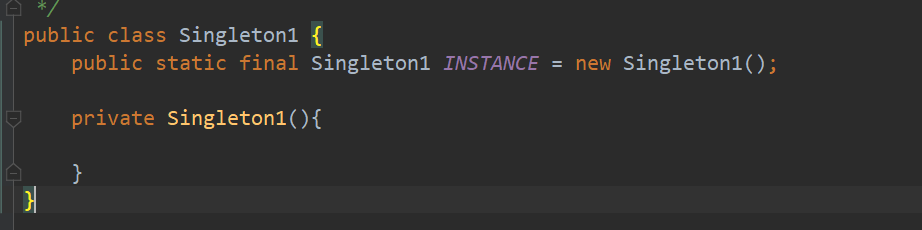
1.饿汉式
-
直接创建对象不存在线程安全问题
-
直接实例化饿汉式(简洁直观)
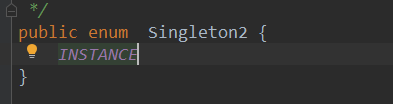
-
枚举式(最简洁)
-
静态代码块饿汉式(适合复杂实例化)
静态代码块饿汉式(适合复杂实例化)
一般用于读取配置文件 的信息
public class Singleton3 {
public static final Singleton3 INSTANCE;
private String info;
static{
try {
Properties pro = new Properties(); pro.load(Singleton3.class.getClassLoader().getResourceAsStream("single.properties"));
INSTANCE = new Singleton3(pro.getProperty("info"));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private Singleton3(String info){
this.info = info;
}
public String getInfo() {
return info;
}
public void setInfo(String info) {
this.info = info;
}
@Override
public String toString() {
return "Singleton3 [info=" + info + "]";
}
}

2.懒汉式
-
线程不安全
线程不安全适用于单线程
只有调用方法才创建对象public class Singleton4 { private static Singleton4 instance; private Singleton4() { } public static Singleton4 getInstance() { if (instance == null) { try { TimeUnit.MICROSECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } instance = new Singleton4(); } return instance; } } -
线程安全
线程安全适用于多线程
利用synchronized 锁住class对象public class Singleton5 { private volatile static Singleton5 instance; private Singleton5() { } public static Singleton5 getInstance() { if (instance == null) { synchronized (Singleton5.class) { if (instance == null) { try { TimeUnit.MICROSECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } instance = new Singleton5(); } } } return instance; } } -
静态内部类形式
静态内部类形式适用于多线程
利用静态内部类实现单例懒汉式在内部类被加载和初始化时 才创建INSTANCE对象
静=态内部类不会随着外部类的加载和初始化而初始化他是要单独去加载和初始化的
因为是在内部类加载和初始化创建的 因此是线程安全的
public class Singleton6 {
private Singleton6() {
}
private static class Inner {
private static final Singleton6 INSTANCE = new Singleton6();
}
public static Singleton6 getInstance() {
return Inner.INSTANCE;
}
}
类初始化和实例初始化
父类的静态变量->父类静态代码块->子类静态变量->子类静态代码块->父类的非静变量->父类非静态构造块->父类构造器->子类的非静变量->子类非静态构造块->子类构造器
其中静态代码块和静态变量看先后顺序
非静态变量和非静态代码块看先后顺序
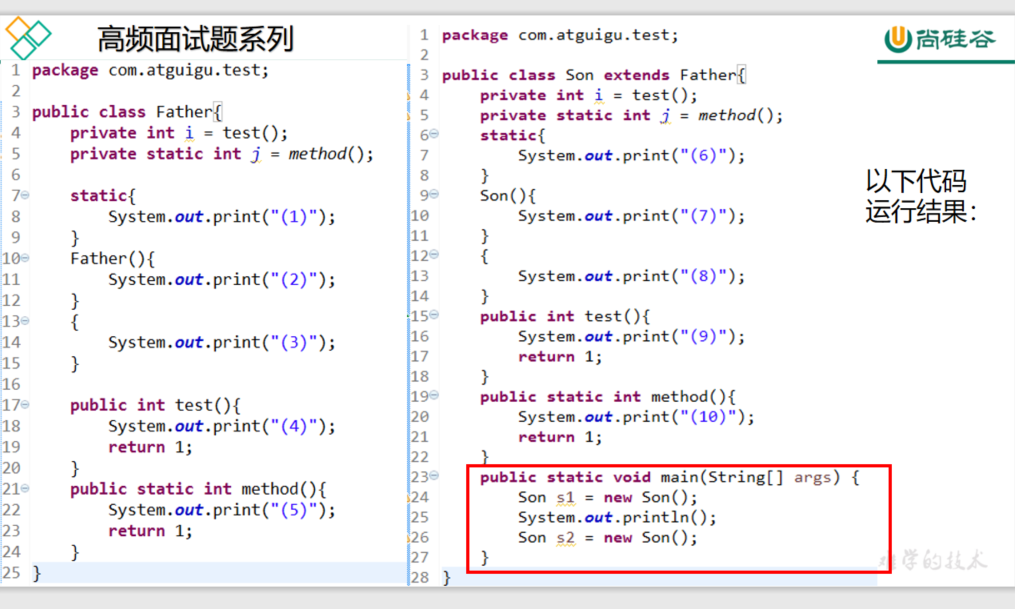
5 1 10 6 9 3 2 9 8 7
9 3 2 9 8 7
答案
(5)(1)(10)(6)(9)(3)(2)(9)(8)(7)
(9)(3)(2)(9)(8)(7)
因为实例初始化 this对象是子类 子类重写了test方法因此会调用子类的test方法
类初始化
-
一个类要创建实例需要先加载并初始化该类main方法所在的类需要先加载和初始化
-
一个子类要初始化需要先初始化父类
-
一个类初始化就是执行()方法(每个类都有 字节码文件中,只有一个)
()方法由静态类变量显示赋值代码和静态代码块组成
类变量显示赋值代码和静态代码块代码从上到下顺序执行
()方法只执行一次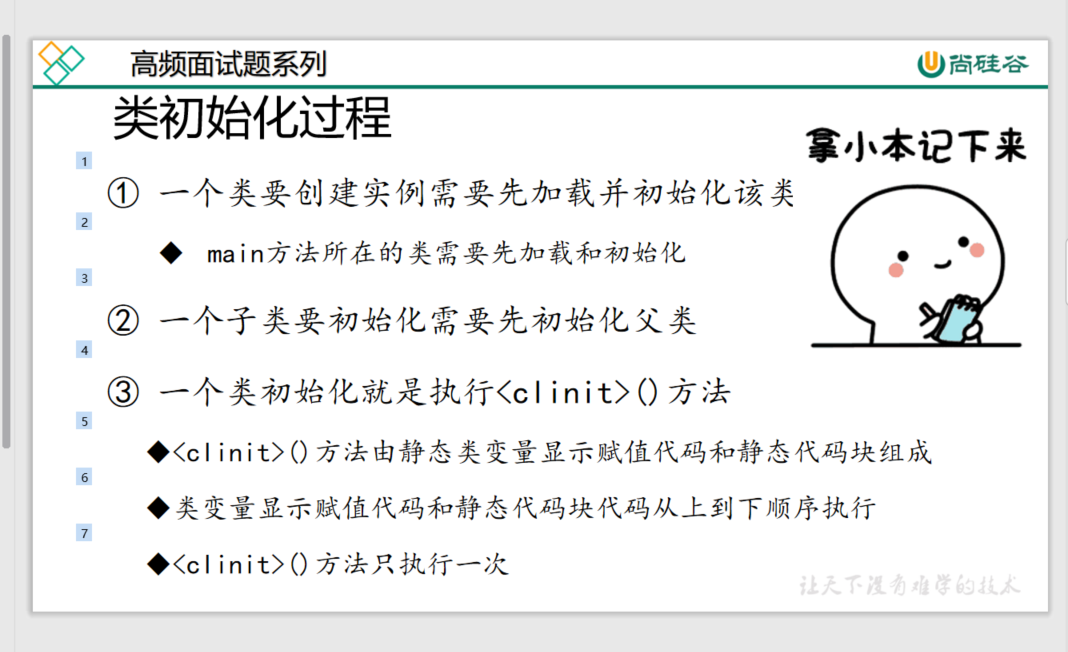
实例初始化
1.实例初始化就是执行()方法(在字节码文件中)
2.()方法可能重载有多个有几个构造器就有几个方法
3.()方法由非静态实例变量显示赋值代码和非静态代码块、对应构造器代码组成
4.非静态实例变量显示赋值代码和非静态代码块代码从上到下顺序执行而对应构造器的代码最后执行
5.每次创建实例对象调用对应构造器执行的就是对应的方法
6.方法的首行是super()或super(实参列表)即对应父类的方法
重写和重载
方法的重写Override
在Java程序中类的继承关系可以产生一个子类子类继承父类它(子类)具备了父类所有的特征继承了父类所有的方法和变量。
子类可以定义新的特征当子类需要修改父类的一些方法进行扩展增大功能程序设计者常常把这样的一种操作方法称为重写也叫称为覆写或覆盖。
重写的优点
-
重写体现了Java优越性重写是建立在继承关系上它使语言结构更加丰富。在Java中的继承中子类既可以隐藏和访问父类的方法也可以覆盖继承父类的方法。
-
重写的好处在于子类可以根据需要定义特定于自己的行为。也就是说子类能够根据需要实现父类的方法。
-
在面向对象原则里重写意味着可以重写任何现有方法。
子类将父类中的方法重写了调用的时候肯定是调用被重写过的方法那么如果现在一定要调用父类中的方法该怎么办呢?
此时通过使用super关键就可以实现这个功能super关键字可以从子类访问父类中的内容如果要访问被重写过的方法使用“super.方法名(参数列表)”的形式调用。
如果要使用super关键字不一定非要在方法重写之后使用也可以明确地表示某个方法是从父类中继承而来的。使用super只是更加明确的说要从父类中查找就不在子类查找了。
注意super 和 this 不能同时使用
哪些方法不可以被重写
- final方法
- 静态方法
- private等子类中不可见方法
对象的多态性
- 子类如果重写了父类的方法通过子类对象调用的一定是子类重写过的代码
- 非静态方法默认的调用对象是this
- this对象在构造器或者说方法中就是正在创建的对象
重写的规则
那看来解决问题的关键还必须从invokevirtual指令本身入手要弄清 楚它是如何确定调用方法版本、如何实现多态查找来着手分析才行。根据《Java虚拟机规范》invokevirtual指令的运行时解析过程[4]大致分为以下几步
1找到操作数栈顶的第一个元素所指向的对象的实际类型记作C。
2如果在类型C中找到与常量中的描述符和简单名称都相符的方法则进行访问权限校验如果 通过则返回这个方法的直接引用查找过程结束不通过则返回java.lang.IllegalAccessError异常。
3否则按照继承关系从下往上依次对C的各个父类进行第二步的搜索和验证过程。
4如果始终没有找到合适的方法则抛出java.lang.AbstractMethodError异常。 正是因为invokevirtual指令执行的第一步就是在运行期确定接收者的实际类型所以两次调用中的
invokevirtual指令并不是把常量池中方法的符号引用解析到直接引用上就结束了还会根据方法接收者
的实际类型来选择方法版本这个过程就是Java语言中方法重写的本质。
把这种在运行期根据实 际类型确定方法执行版本的分派过程称为动态分派。
既然这种多态性的根源在于虚方法调用指令invokevirtual的执行逻辑那自然我们得出的结论就==只 会对方法有效对字段是无效的因为字段不使用这条指令。事实上在Java里面只有虚方法存在 字段永远不可能是虚的换句话说字段永远不参与多态哪个类的方法访问某个名字的字段时该 名字指的就是这个类能看到的那个字段。==当子类声明了与父类同名的字段时虽然在子类的内存中两 个字段都会存在但是子类的字段会遮蔽父类的同名字段。
在重写方法时需要遵循以下的规则两同 两小 一大
(一) 父类方法的参数列表必须完全与被子类重写的方法的参数列表相同否则不能称其为重写而是重载。
(二) 父类的返回类型必须与被子类重写的方法返回类型相同否则不能称其为重写而是重载。
(三) Java中规定被子类重写的方法不能拥有比父类方法更加严格的访问权限。编写过Java程序的人就知道父类中的方法并不是在任何情况下都可以重写的当父类中方法的访问权限修饰符为private时该方法只能被自己的类访问不能被外部的类访问在子类是不能被重写的。如果定义父类的方法为public在子类定义为private程序运行时就会报错。
(四) 由于父类的访问权限修饰符的限制一定要大于被子类重写方法的访问权限修饰符而private权限最小。所以如果某一个方法在父类中的访问权限是private那么就不能在子类中对其进行重写。如果重新定义也只是定义了一个新的方法不会达到重写的效果。
(五) 在继承过程中如果父类当中的方法抛出异常那么在子类中重写父类的该方法时也要抛出异常而且抛出的异常不能多于父类中抛出的异常(可以等于父类中抛出的异常)。换句话说重写方法一定不能抛出新的检查异常或者比被重写方法声明更加宽泛的检查型异常。例如父类的一个方法申明了一个检查异常IOException在重写这个方法时就不能抛出Exception只能抛出IOException的子类异常可以抛出非检查异常。同样的道理如果子类中创建了一个成员变量而该变量和父类中的一个变量名称相同称作变量重写或属性覆盖。但是此概念一般很少有人去研究它因为意义不大。
==============================================================================================================================================================================================
方法重载(Overloading)
方法重载是让类以统一的方式处理不同类型数据的一种手段。调用方法时通过传递给它们的不同个数和类型的参数来决定具体使用哪个方法这就是多态性。
所谓方法重载是指在同一个类中多个方法的方法名相同但是参数列表不同。参数列表不同指的是参数个数、参数类型或者参数的顺序不同。
构造方法也可以重载!!!
方法重载注意事项
当Java调用一个重载方法是参数与调用参数匹配的方法被执行。在使用重载要注意以下的几点:
1.在使用重载时只能通过不同的参数列表必须具有不同的参数列表。
2.不能通过访问权限、返回类型、抛出的异常进行重载。
3.方法的异常类型和数目不会对重载造成影响。
4.可以有不同的返回类型只要参数列表不同就可以了。
5.可以有不同的访问修饰符。
6.可以抛出不同的异常。
7.每个重载的方法或者构造函数都必须有一个独一无二的参数类型列表。
重载的规则
被重载的方法必须改变参数列表
被重载的方法可以改变返回类型
被重载的方法可以改变访问修饰符
被重载的方法可以声明新的或更广的检查异常
方法能够在同一个类中或者在一个子类中被重载。
访问权限修饰符的区别与范围
所有依赖静态类型来决定方法执行版本的分派动作都称为静态分派。静态分派的最典型应用表 现就是方法重载。静态分派发生在编译阶段因此****确定静态分派的动作实际上不是由虚拟机来执行**** *的*这点也是为何一些资料选择把它归入“解析”而不是“分派”的原因。
需要注意==Javac编译器虽然能确定出方法的重载版本但在很多情况下这个重载版本并不是“唯 一”的往往只能确定一个“相对更合适的”版本。==这种模糊的结论在由0和1构成的计算机世界中算是个 比较稀罕的事件产生这种模糊结论的主要原因是字面量天生的模糊性它不需要定义所以字面量 就没有显式的静态类型它的静态类型只能通过语言、语法的规则去理解和推断。
可见变长参数的重载优先级是最低的
编译期间选择静态分派目标的过程这个过程也是Java语言实现方法重载的本 质。
总结
重写与重载之间的区别
方法重载
1、同一个类中
2、方法名相同参数列表不同参数顺序、个数、类型
3、方法返回值、访问修饰符任意
4、与方法的参数名无关
方法重写
1、有继承关系的子类中
2、方法名相同参数列表相同参数顺序、个数、类型方法返回值相同
3、访问修饰符访问范围需要大于等于父类的访问范围
4、与方法的参数名无关
方法的重载和重写都是实现多态的方式区别在于前者实现的是编译时的多态性而后者实现的是运行时的多态性。
发生在同一个类中方法名相同参数列表不同参数类型不同、个数不同、顺序不同与方法返回值和访问修饰符无关即重载的方法不能根据返回类型进行区分
发生在父子类中方法名、参数列表必须相同返回值小于等于父类抛出的异常小于等于父类访问修饰符大于等于父类里氏代换原则如果父类方法访问修饰符为private则子类中就不是重写
两同 方法名、参数列表必须相同
两小 返回值小于等于父类抛出的异常小于等于父类
一大 访问修饰符大于等于父类里氏替换原则
多态多态是同一个行为具有多个不同表现形式或形态的能力。
单分派与多分派
方法的接收者与方法的参数统称为方法的宗量单分派是根据一个宗量对
目标方法进行选择多分派则是根据多于一个宗量对目标方法进行选择。
Java语言是一门静态多分派、动态单分派的语言。
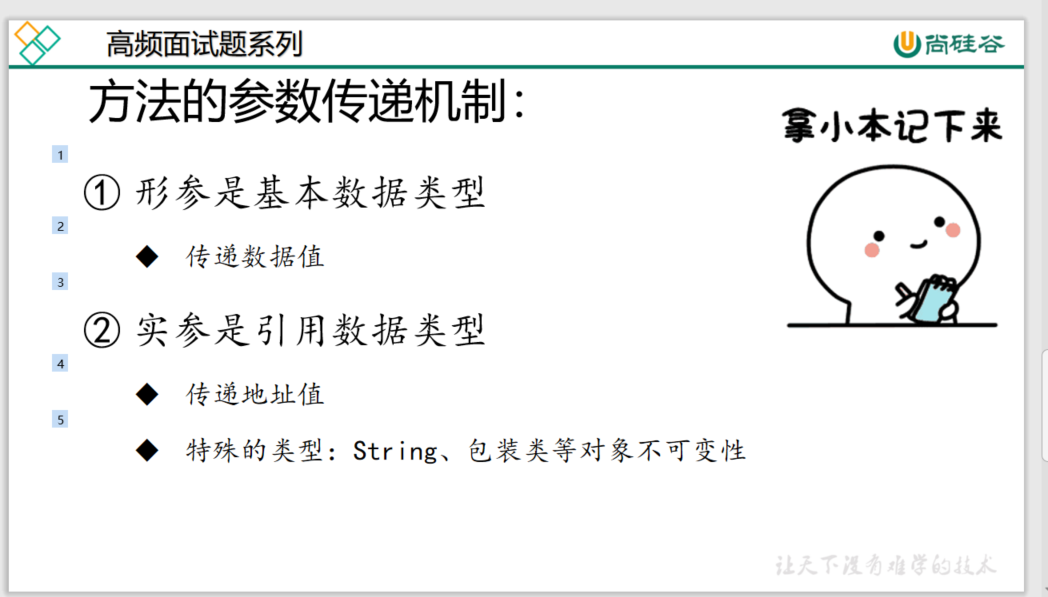
方法参数的传递
方法的参数传递机制
形参是基本数据类型
传递数据值
实参是引用数据类型
传递地址值
特殊的类型String、包装类等对象不可变性
堆和栈的概念和区别
在说堆和栈之前我们先说一下JVM虚拟机内存的划分
高亮的部分是线程所共享的反之不共享
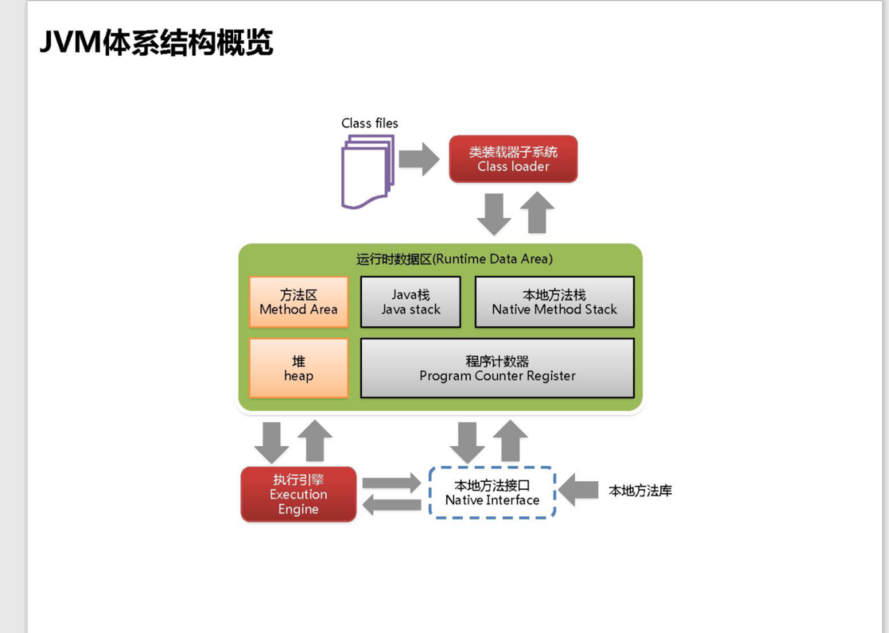
我们重点来说一下堆和栈
栈内存:
栈内存首先是一片内存区域存储的都是局部变量凡是定义在方法中的都是局部变量方法外的是全局变量for循环内部定义的也是局部变量是先加载函数才能进行局部变量的定义所以方法先进栈然后再定义变量变量有自己的作用域一旦离开作用域变量就会被释放。栈内存的更新速度很快因为局部变量的生命周期都很短。
堆内存:
存储的是数组和对象其实数组就是对象凡是new建立的都是在堆中堆中存放的都是实体对象实体用于封装数据而且是封装多个实体的多个属性如果一个数据消失这个实体也没有消失还可以用所以堆是不会随时释放的但是栈不一样栈里存放的都是单个变量变量被释放了那就没有了。堆里的实体虽然不会被释放但是会被当成垃圾Java有垃圾回收机制不定时的收取。
所以堆与栈的区别很明显
-
栈内存存储的是局部变量而堆内存存储的是实体
-
栈内存的更新速度要快于堆内存因为局部变量的生命周期很短
-
栈内存存放的变量生命周期一旦结束就会被释放而堆内存存放的实体会被垃圾回收机制不定时的回收。

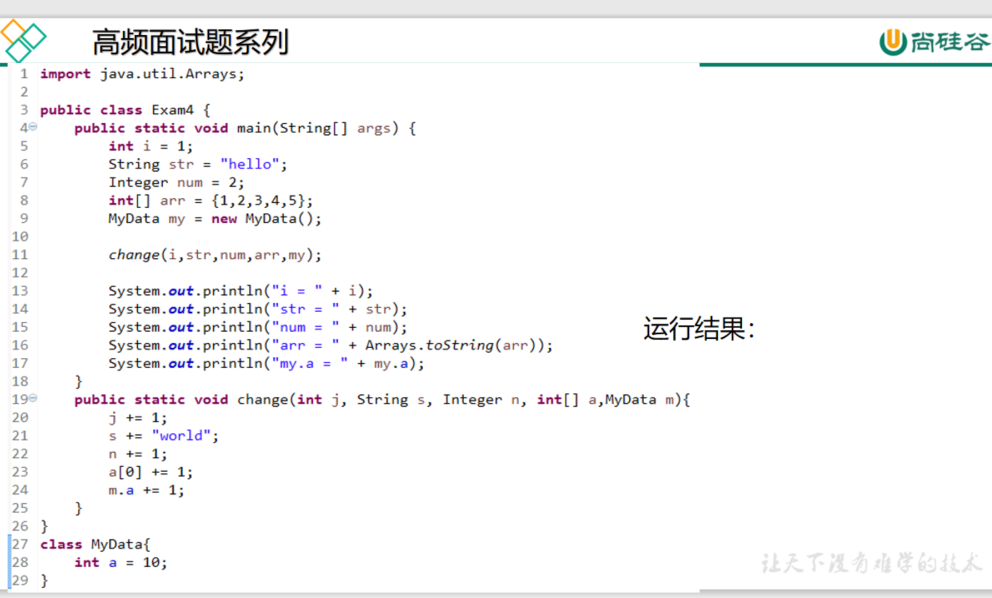
答案
i = 1
str = hello
num = 200
arr = [2, 2, 3, 4, 5]
my.a = 11
当一个对象被当作参数传递到一个方法后此方法可改变这个对象的属性并可返回变化后的结果那么这里到底是值传递还是引用传递
是值传递。Java 语言的方法调用只支持参数的值传递。当一个对象实例作为一个参数被传递到方法中时==参数的值就是对该对象的引用。==对象的属性可以在被调用过程中被改变但对对象引用的改变是不会影响到调用者的
为什么Java中只有值传递
首先回顾一下在程序设计语言中有关将参数传递给方法或函数的一些专业术语。
按值调用(call by value)表示方法接收的是调用者提供的值
而按引用调用call by reference)表示方法接收的是调用者提供的变量地址。
一个方法可以修改传递引用所对应的变量值而不能修改传递值调用所对应的变量值。 它用来描述各种程序设计语言不只是Java)中方法参数传递方式。
Java程序设计语言总是采用按值调用。
也就是说方法得到的是所有参数值的一个拷贝
也就是说方法不能修改传递给它的任何参数变量的内容。
值传递pass by value是指在调用函数时将实际参数复制一份传递到函数中这样在函数中如果对参数进行修改将不会影响到实际参数。
引用传递pass by reference是指在调用函数时将实际参数的地址直接传递到函数中那么在函数中对参数所进行的修改将影响到实际参数。

所以值传递和引用传递的区别并不是传递的内容。而是实参到底有没有被复制一份给形参。
所以说Java中其实还是值传递的只不过对于对象参数值的内容是对象的引用。
无论是值传递还是引用传递其实都是一种求值策略(Evaluation strategy)。在求值策略中还有一种叫做按共享传递(call by sharing)。其实Java中的参数传递严格意义上说应该是按共享传递。
按共享传递是指在调用函数时传递给函数的是实参的地址的拷贝如果实参在栈中则直接拷贝该值。在函数内部对参数进行操作时需要先拷贝的地址寻找到具体的值再进行操作。如果该值在栈中那么因为是直接拷贝的值所以函数内部对参数进行操作不会对外部变量产生影响。如果原来拷贝的是原值在堆中的地址那么需要先根据该地址找到堆中对应的位置再进行操作。因为传递的是地址的拷贝所以函数内对值的操作对外部变量是可见的。
简单点说Java中的传递是值传递而这个值实际上是对象的引用。
递归和迭代


//实现f(n):求n步台阶一共有几种走法
public int f(int n) {
if (n < 1) {
throw new RuntimeException(n + "不能小于1");
}
if (n == 1 || n == 2) {
return n;
}
return f(n - 2) + f(n - 1);
}

public int loop(int n) {
if (n < 1) {
throw new RuntimeException(n + "不能小于1");
}
if (n == 1 || n == 2) {
return n;
}
int one = 2;//初始化为走到第二级台阶的走法
int two = 1;//初始化为走到第一级台阶的走法
int sum = 0;
for (int i = 3; i <= n; i++) {
//最后跨2步 + 最后跨一步的走法
sum = two + one;
two = one;
one = sum;
}
return sum;
}
小结
方法调用自身称为递归利用变量的原值推出新值称为迭代。
递归
优点大问题转化为小问题可以减少代码量同时代码精简可读性好
缺点递归调用浪费了空间而且递归太深容易造成堆栈的溢出。
迭代
优点代码运行效率好因为时间只因循环次数增加而增加而且没有额外的空间开销
缺点代码不如递归简洁可读性好

局部变量与成员变量的区别
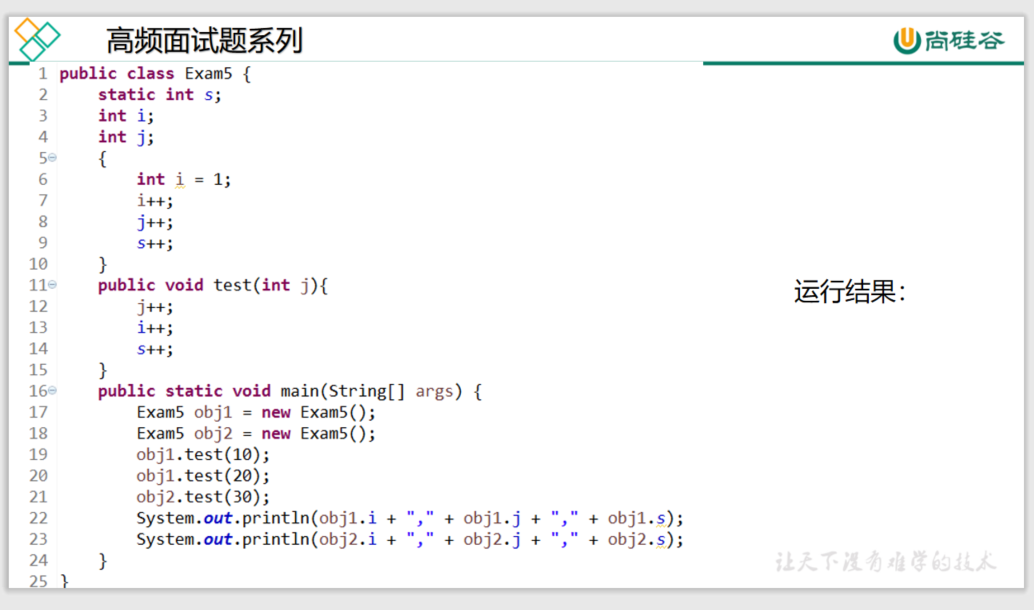
答案
2,1,5
1,1,5
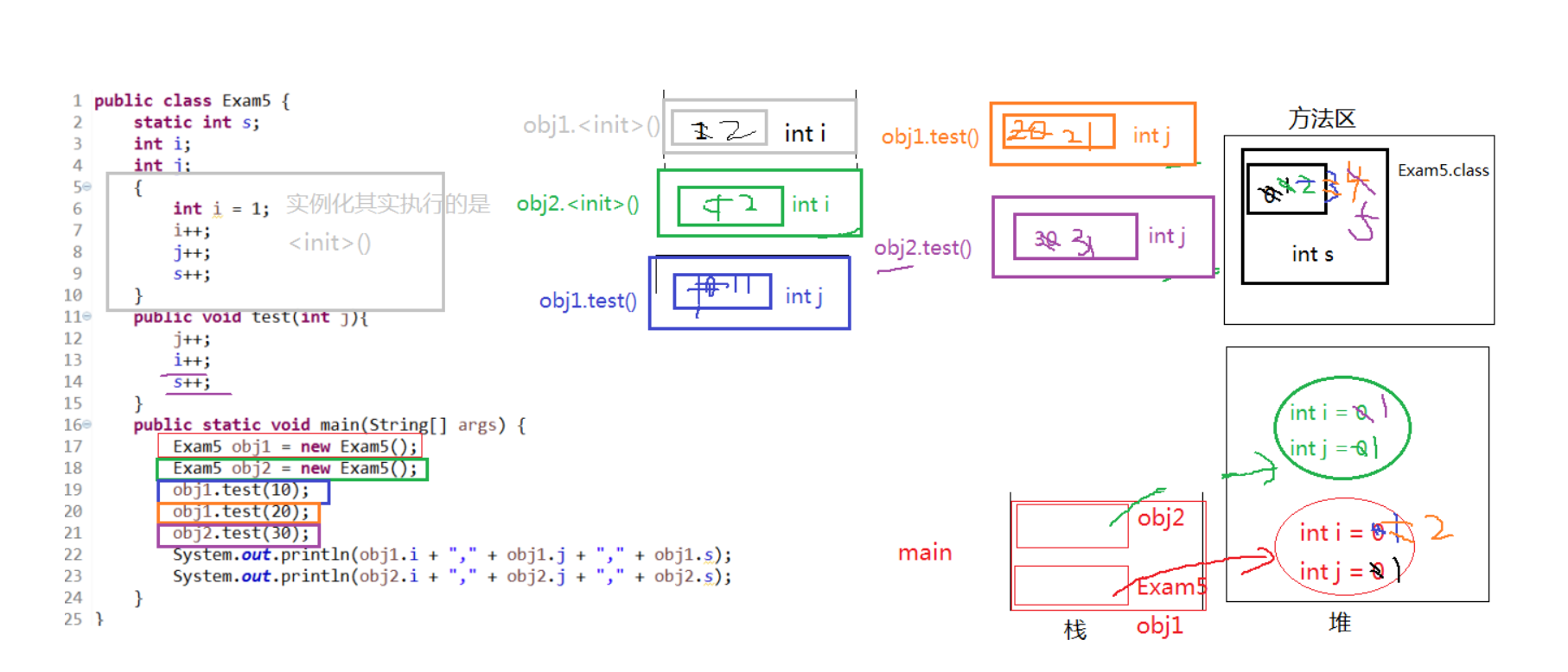
就近原则
变量的就近原则指尽可能在靠近第一次使用变量的位置声明和定义该变量。
变量的分类
成员变量类变量、实例变量
局部变量
非静态代码块的执行
每次创建实例对象都会执行方法的调用规则调用一次执行一次
当没有明确标识变量属于某种变量时通常使用就近原则。

局部变量与成员变量的区别
-
声明的位置
局部变量方法体{}中形参代码块{}中
成员变量类中方法外
类变量有static修饰
实例变量没有static修饰 -
修饰符
局部变量final
成员变量public、protected、private、final、static、volatile、transient -
值存储的位置
局部变量栈
实例变量堆
类变量方法区 -
作用域
局部变量从声明处开始到所属的}结束
实例变量在当前类中“this.”(有时this.可以缺省)在其他类中“对象名.”访问
类变量在当前类中“类名.”(有时类名.可以省略)在其他类中“类名.”或“对象名.”访问 -
生命周期
局部变量每一个线程每一次调用执行都是新的生命周期每一个线程也是独立的
实例变量随着对象的创建而初始化随着对象的被回收而消亡每一个对象的实例变量是独立的
类变量随着类的初始化而初始化随着类的卸载而消亡该类的所有对象的类变量是共享的

重名问题
当局部变量与xx变量重名时如何区分
局部变量与实例变量重名
在实例变量前面加“this.”
局部变量与类变量重名
在类变量前面加“类名.”
注意如果 缺省this和类名 则会采用最近原则策略
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OGuBTUFR-1673796690799)(https://gitee.com/Code_Farming_Liu/image/raw/master/img/20201018185930.png)]
Java 位运算
带符号的移位
即 补码进行操作 之后将补码还原为原码 在求出真值
JDK1.5之后的三大版本
-
Java SE
Java SEJ2SEJava 2 Platform Standard Edition标准版 Java SE 以前称为 J2SE。它允许开发和部署在桌面、服务器、嵌入式环境和实时环境中使用的 Java 应用程序。Java SE 包含了支持 Java Web 服务开发的类并为Java EE和Java ME提供基础。 -
Java EE
Java EE 以前称为 J2EE。企业版本帮助开发和部署可移植、健壮、可伸缩且安全的服务器端Java 应用程序。Java EE 是在 Java SE 的基础上构建的它提供 Web 服务、组件模型、管理和通信 API可以用来实现企业级的面向服务体系结构service-oriented architectureSOA和 Web2.0应用程序。2018年2月Eclipse 宣布正式将 JavaEE 更名为 JakartaEE -
Java ME
Java ME 以前称为 J2ME。Java ME 为在移动设备和嵌入式设备比如手机、PDA、电视机顶盒和打印机上运行的应用程序提供一个健壮且灵活的环境。Java ME 包括灵活的用户界面、健壮的安全模型、许多内置的网络协议以及对可以动态下载的连网和离线应用程序的丰富支持。基于 Java ME 规范的应用程序只需编写一次就可以用于许多设备而且可以利用每个设备的本机功能。JVM、JRE和JDK的关系
https://blog.csdn.net/weixin_30750335/article/details/98007257
-
JVM
Java Virtual Machine是Java虚拟机Java程序需要运行在虚拟机上不同的平台有自己的虚拟机因此Java语言可以实现跨平台。 -
JRE==(如果想要运行一个开发好的Java程序计算机中只需要安装JRE即可。)==
Java Runtime Environment包括Java虚拟机和Java程序所需的核心类库等。核心类库主要是java.lang包包含了运行Java程序必不可少的系统类如基本数据类型、基本数学函数、字符串处理、线程、异常处理类等系统缺省加载这个包 -
JDK
Java Development Kit是提供给Java开发人员使用的其中包含了Java的开发工具也包括了JRE。所以安装了JDK就无需再单独安装JRE了。其中的开发工具编译工具(javac.exe)打包工具(jar.exe)等
-
什么是跨平台性原理是什么?
所谓的跨平台性就是java语言编写的程序一次编译后可以在多个系统的平台运行
实现的原理Java程序是通过java虚拟机在系统平台上运行的只要该系统可以安装相应的java虚拟机该系统就可以运行java程序。
一次编译 到处运行
Java 语言的特点
-
简单易学
-
面向对象
-
封装
-
继承
-
多态
成员变量 静态方法 编译看左 运行看左 其他 编译看左边 运行看右边 -
抽象
-
-
平台无关性
平台是由操作系统和处理器所构成每个平台都会形成自己独特的机器指令与平台无关是指软件的运行不因操作系统、处理器的变化而无法运行或出现运行错误。
-
支持网络编程
-
支持多线程
-
稳定性
-
安全性
什么是字节码采用字节码的最大好处是什么
字节码
Java源代码经过虚拟机编译器编译后产生的文件即扩展为.class的文件它不面向任何特定的处理器只面向虚拟机。
好处
Java中引入了虚拟机的概念即在机器和编译程序之间加入了一层抽象的虚拟机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。编译程序只需要面向虚拟机生成虚拟机能够理解的代码然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在Java中这种供虚拟机理解的代码叫做字节码即扩展为.class的文件它不面向任何特定的处理器只面向虚拟机。每一种平台的解释器是不同的但是实现的虚拟机是相同的。Java源程序经过编译器编译后变成字节码字节码由虚拟机解释执行虚拟机将每一条要执行的字节码送给解释器解释器将其翻译成特定机器上的机器码然后在特定的机器上运行这就是上面提到的Java的特点的编译与解释并存的解释。
Java源代码---->编译器---->jvm可执行的Java字节码(即虚拟指令)---->jvm---->jvm中解释器----->机器可执行的二进制机器码---->程序运行。
Java和 c++的区别
- 都是面向对象的语言都支持封装、继承和多态
- Java不提供指针来直接访问内存程序内存更加安全
- Java的类是单继承的C++支持多重继承虽然Java的类不可以多继承但是接口可以多继承。
- Java有自动内存管理机制不需要程序员手动释放无用内存
Oracle JDK 和 OpenJDK 的对比
- OracleJDK版本将每三年发布一次而OpenJDK版本每三个月发布一次
- OpenJDK 是一个参考模型并且是完全开源的而Oracle JDK是OpenJDK的一个实现并不是完全开源的
- Oracle JDK 比 OpenJDK 更稳定。OpenJDK和Oracle JDK的代码几乎相同但Oracle JDK有更多的类和一些错误修复。因此如果您想开发企业/商业软件我建议您选择Oracle JDK因为它经过了彻底的测试和稳定。某些情况下有些人提到在使用OpenJDK 可能会遇到了许多应用程序崩溃的问题但是只需切换到Oracle JDK就可以解决问题
- 在响应性和JVM性能方面Oracle JDK与OpenJDK相比提供了更好的性能
- Oracle JDK不会为即将发布的版本提供长期支持用户每次都必须通过更新到最新版本获得支持来获取最新版本
- Oracle JDK根据二进制代码许可协议获得许可而OpenJDK根据GPL v2许可获得许可。
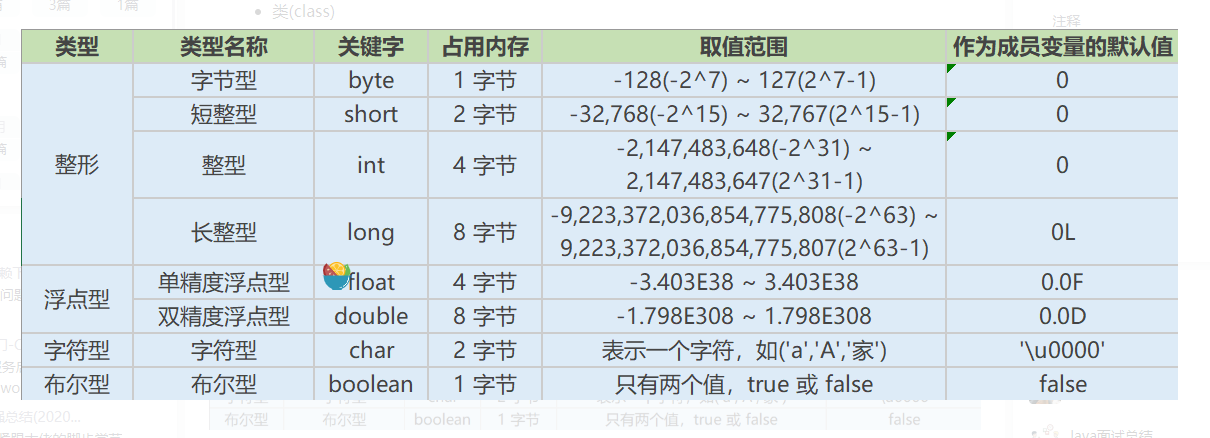
Java数据类型
char 2字节 范围 0~65535 java中的char数据类型一定是无符号的
Java程序开发步骤
- 编写源文件
- 编译源文件
- 运行程序
Java的风格
- Allmans独行代码量较小
- Kernighan行尾代码量较大
标识符和关键字
标识符
- 标识符 由字母 数字 下划线 美元符号组成 长度不受限制
- 数字不能开头
- 标识符不能是关键字
- 标识符不能是 true false null true false null 不是关键字
关键字
具有特殊意思的单词
switch 是否能作用在 byte 上是否能作用在 long 上是否能作用在 String 上
- 在 Java 5 以前switch(expr)中expr 只能是 byte、short、char、int。
- 从 Java5 开始Java 中引入了枚举类型expr 也可以是 enum 类型
- 从 Java 7 开始expr 还可以是字符串String
- 但是长整型long在目前所有的版本中都是不可以的。
Math.round(11.5) 等于多少Math.round(-11.5)等于多少
Math.round(11.5)的返回值是 12
Math.round(-11.5)的返回值是-11。
四舍五入的原理是在参数上加 0.5 然后进行下取整。
Java语言采用何种编码方案有何特点
Java语言采用Unicode编码标准Unicode标准码它为每个字符制订了一个唯一的数值因此在任何的语言平台程序都可以放心的使用。
最多可以识别65536个字符 字符集的前128个字符正好是ASCII 编码
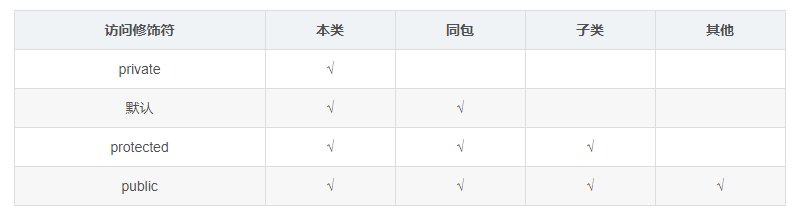
访问修饰符
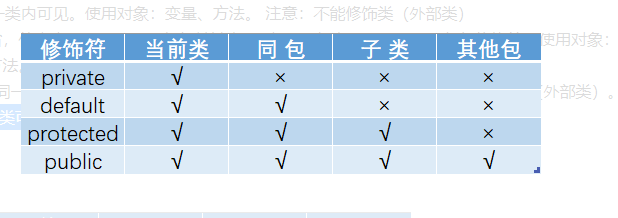
定义
Java中可以使用访问修饰符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
分类
-
private
在同一类内可见。使用对象变量、方法。 注意不能修饰类外部类
-
default
(即缺省友好修饰符什么也不写不使用任何关键字: 在同一包内可见不使用任何修饰符。使用对象类、接口、变量、方法。
-
protected
受保护的修饰符 对同一包内的类和所有子类可见。使用对象变量、方法。 注意不能修饰类外部类。
-
public
public : 对所有类可见。使用对象类、接口、变量、方法
为什么String是不可变得
1字符串池String pool的需求 在Java中当初始化一个字符串变量时如果字符串已经存在就不会创建一个新的字符串变量而是返回存在字符串的引用。 例如 String s1=“abcd”; String s2=“abcd”; 这两行代码在堆中只会创建一个字符串对象。如果字符串是可变的改变另一个字符串变量就会使另一个字符串变量指向错误的值。
2缓存字符串hashcode码的需要 字符串的hashcode是经常被使用的字符串的不变性确保了hashcode的值一直是一样的在需要hashcode时就不需要每次都计算这样会很高效。
3出于安全性考虑 字符串经常作为网络连接、数据库连接等参数不可变就可以保证连接的安全性。
final finally finalize区别
final
-
被final修饰的类不可以被继承
https://blog.csdn.net/Java_I_ove/article/details/76946598?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
-
被final修饰的方法不可以被重写
-
被final修饰的变量不可以被改变被final修饰不可变的是变量的引用而不是引用指向的内容引用指向的内容是可以改变的
-
final可以修饰类、变量、方法修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表
示该变量是一个常量不能被重新赋值。 -
https://blog.csdn.net/qq1028951741/article/details/53418852
finally
finally一般作用在try-catch代码块中在处理异常的时候通常我们将一定要执行的代码方法finally代码块
中表示不管是否出现异常该代码块都会执行一般用来存放一些关闭资源的代码。
finalize
finalize是一个方法属于Object类的一个方法而Object类是所有类的父类该方法一般由垃圾回收器来调
用当我们调用System.gc() 方法的时候由垃圾回收器调用finalize()回收垃圾一个对象是否可回收的
最后判断==这个对象可以趁这个时机挣脱死亡的命运。==
是Object的一个方法设计的目的是保证对象在被垃圾收集前完成特定的资源回收。不推荐使用使用不当会影响系统性能甚至导致死锁。Java平台目前在逐步使用java.lang.ref.Cleaner来替换原有的finalize
自我救赎
对象覆写了finalize()方法这样在被判死后才会调用此方法才有机会做最后的救赎
在finalize()方法中重新引用到"GC Roots"链上如把当前对象的引用this赋值给某对象的类变量/成员变量重新建立可达的引用
this与super的区别
super
它引用当前对象的直接父类中的成员用来访问直接父类中被隐藏的父类中成员数据或函数基类与派生类中有相同成员定义时如super.变量名 super.成员函数据名实参
this
它代表当前对象名在程序中易产生二义性之处应使用this来指明当前对象如果函数的形参与类中的成员数据同名这时需用this来指明成员变量名
super()和this()类似,区别是super()在子类中调用父类的构造方法this()在本类内调用本类的其它构造方法。
super()和this()均需放在构造方法内第一行。
尽管可以用this调用一个构造器但却不能调用两个。
this和super不能同时出现在一个构造函数里面因为this必然会调用其它的构造函数其它的构造函数必然也会有super语句的存在所以在同一个构造函数里面有相同的语句就失去了语句的意义编译器也不会通过。
this()和super()都指的是对象所以均不可以在static环境中使用。包括static变量,static方法static语句块。
从本质上讲this是一个指向本对象的指针, 然而super是一个Java关键字。
面向对象和面向过程的区别
面向过程
优点性能比面向对象高因为类调用时需要实例化开销比较大比较消耗资源;比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发性能是最重要的因素。
缺点没有面向对象易维护、易复用、易扩展
面向对象
优点易维护、易复用、易扩展由于面向对象有封装、继承、多态性的特性可以设计出低耦合的系统使系统更加灵活、更加易于维护
缺点性能比面向过程低
面向过程是具体化的流程化的解决一个问题你需要一步一步的分析一步一步的实现。
面向对象是模型化的你只需抽象出一个类这是一个封闭的盒子在这里你拥有数据也拥有解决问题的方法。需要什么功能直接使用就可以了不必去一步一步的实现至于这个功能是如何实现的管我们什么事我们会用就可以了。
面向对象的底层其实还是面向过程把面向过程抽象成类然后封装方便我们使用的就是面向对象了。
抽象类和接口的对比
https://www.cnblogs.com/dolphin0520/p/3811437.html
抽象类是用来捕捉子类的通用特性的。接口是抽象方法的集合。
从设计层面来说抽象类是对类的抽象是一种模板设计接口是行为的抽象是一种行为的规范。
相同点
- 接口和抽象类都不能实例化
- 都位于继承的顶端用于被其他实现或继承
- 都包含抽象方法其子类都必须覆写这些抽象方法
不同点
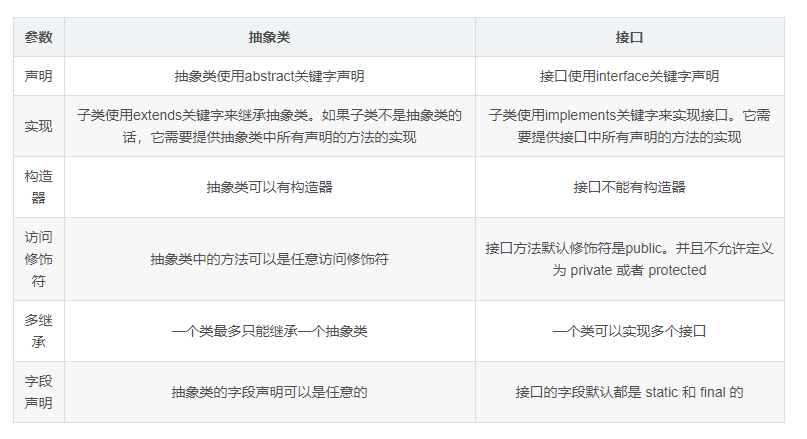
备注Java8中接口中引入默认方法和静态方法以此来减少抽象类和接口之间的差异。
现在我们可以为接口提供默认实现的方法了并且不用强制子类来实现它。
接口和抽象类各有优缺点在接口和抽象类的选择上必须遵守这样一个原则
行为模型应该总是通过接口而不是抽象类定义所以通常是优先选用接口尽量少用抽象类。
选择抽象类的时候通常是如下情况需要定义子类的行为又要为子类提供通用的功能。
局部内部类和匿名内部类访问局部变量的时候为什么变量必须要加上final
是因为生命周期不一致 局部变量直接存储在栈中当方法执行结束后非final的局部变量就被销毁。而局部内部类对局部变量的引用依然存在如果局部内部类要调用局部变量时就会出错。加了final可以确保局部内部类使用的变量与外层的局部变量区分开解决了这个问题。
== 与 equals的区别
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-psZc56Px-1673796690802)(…/…/…/typora/image/image-20210623233710601.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4PmWO95C-1673796690802)(…/…/…/typora/image/image-20210623233724399.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5eUmqsVx-1673796690803)(…/…/…/typora/image/image-20210623233744409.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ElnZNnRX-1673796690804)(…/…/…/typora/image/image-20210623233824170.png)]
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A5cOuJO7-1673796690805)(…/…/…/typora/image/image-20210623234004865.png)]
总结所以说对于==当数据类型是8大基础类型时比较的是栈中数值是否相等当数据类型是引用类型时比较的是对象的引用地址是否相等。这是通过jvm来自动判断的。
总结因为我们在对字符串比较的时候往往关注的就是值一样不一样所以java这样重写也是 很有必要的所以我们一直推荐判断字符串相等用equals方法而不是用==来判断。equals方法具体产生什么样的效果完全看子类是怎么重写的比如Date类重写了equals方法只要两个时间的getTime()时间戳一样那么就相等这也是符合我们的认知的。
hashCode 与 equals (重要)
hashCode()介绍
hashCode() 的作用是获取哈希码也称为散列码它实际上是返回一个int整数。这个**哈希码的作用是确定该对象在哈希表中的索引位置。**hashCode() 定义在JDK的Object.java中这就意味着Java中的任何类都包含有hashCode()函数。
散列表存储的是键值对(key-value)
它的特点是能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码可以快速找到所需要的对象
为什么要有 hashCode
当你把对象加入 HashSet 时HashSet 会先计算对象的 hashcode 值来判断对象加入的位置同时也会与其他已经加入的对象的 hashcode 值作比较如果没有相符的hashcodeHashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同HashSet 就不会让其加入操作成功。如果不同的话就会重新散列到其他位置。摘自我的Java启蒙书《Head first java》第二版。这样我们就大大减少了 equals 的次数相应就大大提高了执行速度。
hashCode()与equals()的相关规定
如果两个对象相等则hashcode一定也是相同的
两个对象相等对两个对象分别调用equals方法都返回true
两个对象有相同的hashcode值它们也不一定是相等的
因此equals 方法被覆盖过则 hashCode 方法也必须被覆盖
hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode()则该 class 的两个对象无论如何都不会相等即使这两个对象指向相同的数据
为什么重写equals需要重写hashcode方法
为了保证当两个对象通过equals()方法比较相等时那么他们的hashCode值也一定要保证相等。
比如hashset将两个equals相同的对象存进去按道理来说equals方法相同这两个对象可以看为同一个对象不可能都存进去但他们的hashCode不同HashSet的add方法实质是将添加的元素作为键存进map集合中map集合再根据hashCode来计算这个元素存在数组的位置但他们hashCode不同所以存的位置不同所以可能都能存进去这就出现问题了
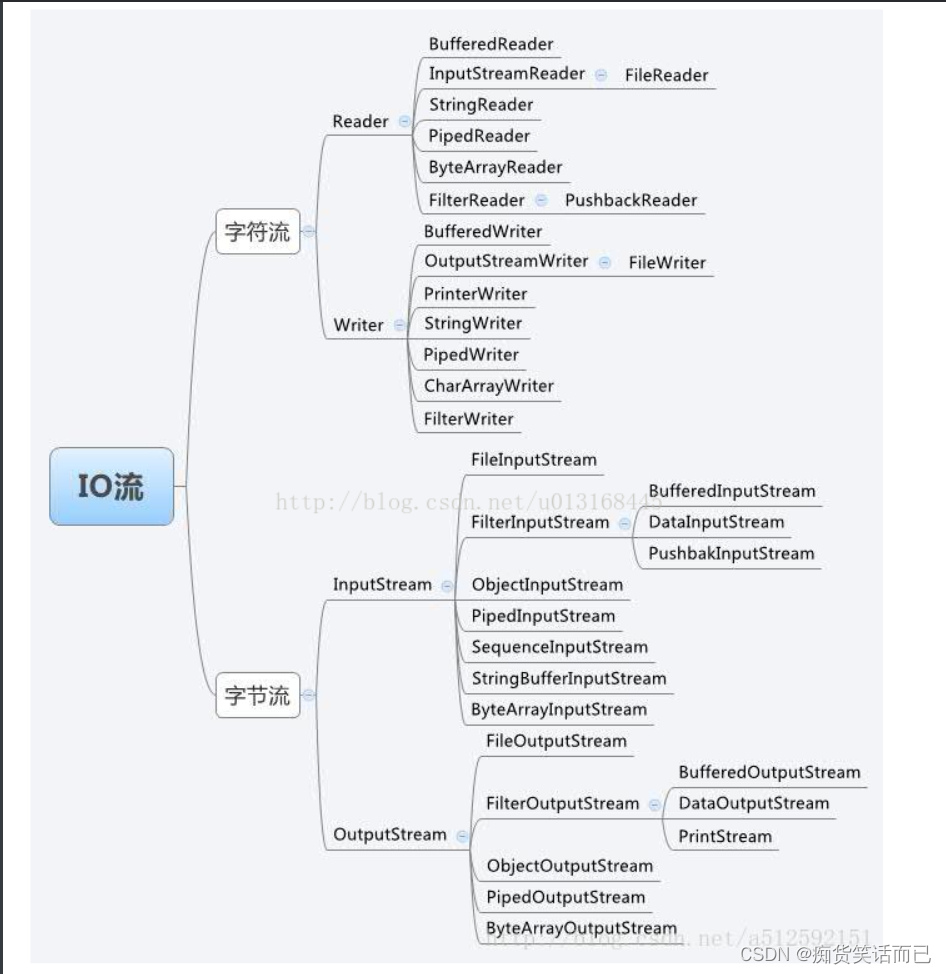
IO流
InputStream/Reader: 所有的输入流的基类前者是字节输入流后者是字符输入流。
OutputStream/Writer: 所有输出流的基类前者是字节输出流后者是字符输出流。
按照流的流向分可以分为输入流和输出流
按照操作单元划分可以划分为字节流和字符流
按照流的角色划分为节点流和处理流。
BIO,NIO,AIO 有什么区别?
BIO
简答
Block IO 同步阻塞式 IO就是我们平常使用的传统 IO它的特点是模式简单使用方便并发处理能力低。
详细
BIO (Blocking I/O): 同步阻塞I/O模式数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高小于单机1000的情况下这种模型是比较不错的可以让每一个连接专注于自己的 I/O 并且编程模型简单也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗可以缓冲一些系统处理不了的连接或请求。但是当面对十万甚至百万级连接的时候传统的 BIO 模型是无能为力的。因此我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO
简答
Non IO 同步非阻塞 IO是传统 IO 的升级客户端和服务器端通过 Channel通道通讯实现了多路复用。
详细
NIO (New I/O): NIO是一种同步非阻塞的I/O模型在Java 1.4 中引入了NIO框架对应 java.nio 包提供了 Channel , SelectorBuffer等抽象。NIO中的N可以理解为Non-blocking不单纯是New。
它支持面向缓冲的基于通道的I/O操作方法。
NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,
两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样比较简单但是性能和可靠性都不好
非阻塞模式正好与之相反。
对于低负载、低并发的应用程序可以使用同步阻塞I/O来提升开发速率和更好的维护性
对于高负载、高并发的网络应用应使用 NIO 的非阻塞模式来开发
简答
Asynchronous IO 是 NIO 的升级也叫 NIO2实现了异步非堵塞 IO 异步 IO 的操作基于事件和回调机制。
详细
AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的也就是应用操作之后会直接返回不会堵塞在那里当后台处理完成操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写虽然 NIO 在网络操作中提供了非阻塞的方法但是 NIO 的 IO 行为还是同步的。对于 NIO 来说我们的业务线程是在 IO 操作准备好时得到通知接着就由这个线程自行进行 IO 操作IO操作本身是同步的。查阅网上相关资料我发现就目前来说 AIO 的应用还不是很广泛Netty 之前也尝试使用过 AIO不过又放弃了。
反射
JAVA反射机制是在运行状态中
-
对于任意一个类都能够知道这个类的所有属性和方法
-
对于任意一个对象都能够调用它的任意一个方法和属性
这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
反射也就是我们可以通过获取它的类从而获取到类里面的成员变量、方法及构造方法并可以使用他们做一些奇奇怪怪的事情。
Activity activity = new Activity();
Class<? extends Activity> activityClass = activity.getClass();
也可以这样
Class<? extends Activity> activityClass = MainActivity.class;
甚至还可以这样
try {
Class activityClass = Class.forName("com.example.mydemo.MainActivity");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
我们一旦获取到他的类之后就可以继续去搞事情了例如我们去他的一个私有成员变量并对它的成员变量进行赋值对于方法及构造函数的获取就不11感觉中文“一一”看起来像破折号下同举例了。
Field[] fields = activityClass.getDeclaredFields();
for (Field field : fields) {
if (field.getName().equals("name")) {
//对私有成员变量赋值必须先执行这个
field.setAccessible(true);
try {
//注意这个activity赋值时第一个参数必须传入的是实例对象
//这个acticity就是上面第一个例子中的acticity
field.set(activity, "dog");
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
}
这样就简单的实现了一个反射的用法我们通过反射不仅可以获取到一个类的私有的东西甚至还可以获取到他的父类的东西同时我们无论获取什么都是一下子全部获取了例如上面这个getDeclaredFields()就获取了这个类里面的全部成员变量这也就人们常说的反射会影响性能的原因。
优点
运行期类型的判断动态加载类提高代码灵活度。
缺点
性能瓶颈反射相当于一系列解释操作通知JVM要做的事情性能比直接的java代码要慢很多。
应用场景
反射是框架设计的灵魂。
在我们平时的项目开发过程中基本上很少会直接使用到反射机制但这不能说明反射机制没有用实际上有很多设计、开发都与反射机制有关例如模块化的开发通过反射去调用对应的字节码动态代理设计模式也采用了反射机制还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
举例①我们在使用JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序②Spring框架也用到很多反射机制最经典的就是xml的配置模式。Spring 通过 XML 配置模式装载 Bean 的过程1) 将程序内所有 XML 或 Properties 配置文件加载入内存中; 2)Java类里面解析xml或properties里面的内容得到对应实体类的字节码字符串以及相关的属性信息; 3)使用反射机制根据这个字符串获得某个类的Class实例; 4)动态配置实例的属性
Java 反射到底慢在哪里
https://www.zhihu.com/question/19826278
获取反射的3种方式
- 通过new对象实现反射机制
- 通过路径实现反射机制
- 通过类名实现反射机制
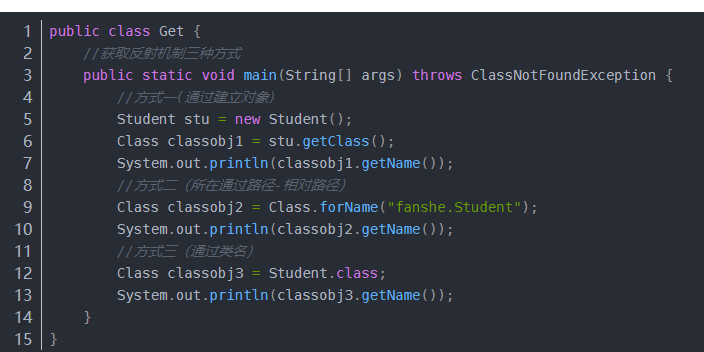
Object类常用的方法
https://blog.51cto.com/12222886/2067876
TCP/IP协议和三次握手 4次挥手
网络协议
在计算机网络要做到有条不紊地交换数据就必须遵守一些事先约定好的规则比如交换数据的格式、是否需要发送一个应答信息。这些规则被称为网络协议。
为进行网络中的数据交换而建立的规则、标椎约定称为网络协议
为什么对网络协议分层
为了使不同体系结构的计算机网络都能互联国际标准化组织 ISO 于1977年提出了一个试图使各种计算机在世界范围内互联成网的标准框架即著名的开放系统互联基本参考模型 OSI/RM简称为OSI。
OSI 的七层协议体系结构的概念清楚理论也较完整但它既复杂又不实用TCP/IP 体系结构则不同但它现在却得到了非常广泛的应用。TCP/IP 是一个四层体系结构它包含应用层运输层网际层和网络接口层用网际层这个名字是强调这一层是为了解决不同网络的互连问题不过从实质上讲TCP/IP 只有最上面的三层因为最下面的网络接口层并没有什么具体内容因此在学习计算机网络的原理时往往采用折中的办法即综合 OSI 和 TCP/IP 的优点采用一种只有五层协议的体系结构这样既简洁又能将概念阐述清楚有时为了方便也可把最底下两层称为网络接口层。
优点
- 各层独立简化问题难度和复杂度。由于各层之间独立我们可以分割大问题为小问题。
- 灵活性好当其中一层的技术变化时只要层间接口关系保持不变其他层不受影响。
- 促进标准化工作。分开后每层功能可以相对简单地被描述。
- 易于实现和维护。
缺点
功能可能出现在多个层里重复出现产生了额外开销。
TCP/IP是一个四层的体系结构
- 应用层
- 运输层
- 网际层
- 网络接口层
五层协议体系结构
-
应用层
应用层( application-layer 的任务是通过应用进程间的交互来完成特定网络应用。
应用层协议定义的是应用进程进程主机中正在运行的程序间的通信和交互的规则。
对于不同的网络应用需要不同的应用层协议。
在互联网中应用层协议很多如域名系统 DNS支持万维网应用的 HTTP 协议支持电子邮件的 SMTP 协议等等。
-
运输层
运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务。
应用进程利用该服务传送应用层报文。
运输层主要使用一下两种协议
- 传输控制协议-TCP提供面向连接的可靠的数据传输服务。
- 用户数据协议-UDP提供无连接的尽最大努力的数据传输服务不保证数据传输的可靠性。
每一个应用层TCP/IP参考模型的最高层协议一般都会使用到两个传输层协议之一
运行在TCP协议上的协议
HTTPHypertext Transfer Protocol超文本传输协议主要用于普通浏览。HTTPSHTTP over SSL安全超文本传输协议,HTTP协议的安全版本。FTPFile Transfer Protocol文件传输协议用于文件传输。POP3Post Office Protocol, version 3邮局协议收邮件用。SMTPSimple Mail Transfer Protocol简单邮件传输协议用来发送电子邮件。TELNETTeletype over the Network网络电传通过一个终端terminal登陆到网络。SSHSecure Shell用于替代安全性差的TELNET用于加密安全登陆用。
运行在==UDP协议==上的协议
BOOTPBoot Protocol启动协议应用于无盘设备。NTPNetwork Time Protocol网络时间协议用于网络同步。DHCPDynamic Host Configuration Protocol动态主机配置协议动态配置IP地址。
运行在**
TCP和UDP**协议上DNSDomain Name Service域名服务用于完成地址查找邮件转发等工作。 -
网络层
网络层的任务就是选择合适的网间路由和交换结点确保计算机通信的数据及时传送。
在发送数据时网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。
在 TCP/IP 体系结构中由于网络层使用 IP 协议因此分组也叫 IP 数据报 简称数据报。
互联网是由大量的异构heterogeneous网络通过路由器router相互连接起来的。
互联网使用的网络层协议是无连接的网际协议Intert Prococol和许多路由选择协议因此互联网的网络层也叫做网际层或 IP 层。
-
数据链路层
数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输总是在一段一段的链路上传送的这就需要使用专门的链路层的协议。
在两个相邻节点之间传送数据时数据链路层将网络层交下来的 IP 数据报组装成帧在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息如同步信息地址信息差错控制等。
在接收数据时控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结束。
一般的web应用的通信传输流是这样的
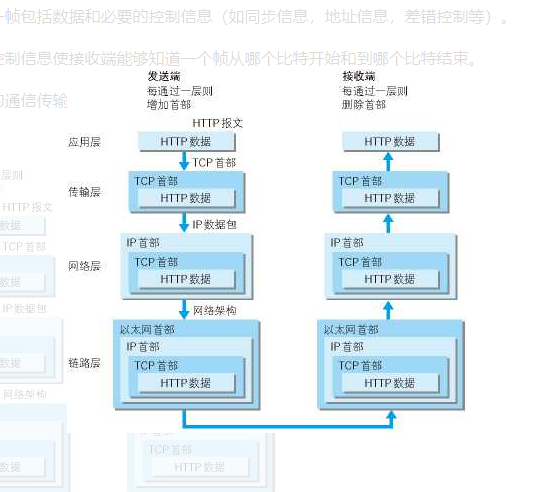
发送端在层与层之间传输数据时每经过一层时会被打上一个该层所属的首部信息。反之接收端在层与层之间传输数据时每经过一层时会把对应的首部信息去除。
-
物理层
在物理层上所传送的数据单位是比特。 **物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送尽可能屏蔽掉具体传输介质和物理设备的差异。**使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化对传送的比特流来说这个电路好像是看不见的。
七层协议体系结构
- 应用层
- 表示层
- 会话层
- 运输层
- 网络层
- 数据链路层
- 物理层
在互联网使用的各种协议中最重要和最著名的就是 TCP/IP 两个协议。
现在人们经常提到的 TCP/IP 并不一定是单指 TCP 和 IP 这两个具体的协议而往往是表示互联网所使用的整个 TCP/IP 协议族。
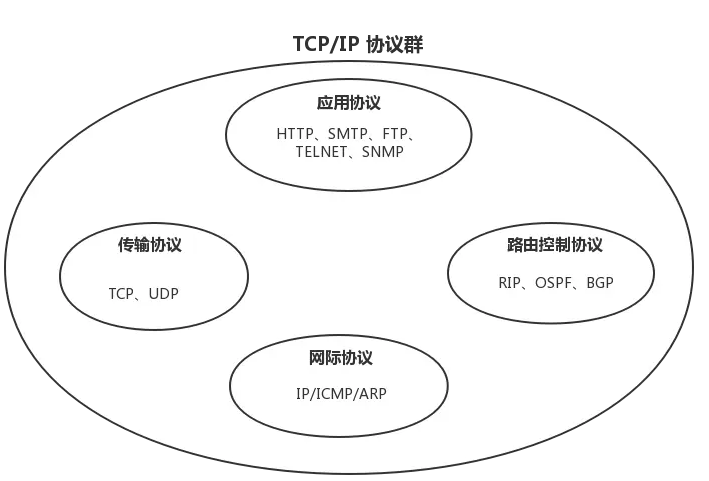
互联网协议套件英语Internet Protocol Suite缩写IPS是一个网络通讯模型以及一整个网络传输协议家族为网际网络的基础通讯架构。它常被通称为TCP/IP协议族英语TCP/IP Protocol Suite或TCP/IP Protocols简称TCP/IP。因为该协定家族的两个核心协定TCP传输控制协议和IP网际协议为该家族中最早通过的标准。
划重点
TCP传输控制协议和IP网际协议 是最先定义的两个核心协议所以才统称为TCP/IP协议族
TCP的三次握手四次挥手
TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议在发送数据前通信双方必须在彼此间建立一条连接。
所谓的“连接”其实是客户端和服务端保存的一份关于对方的信息如ip地址、端口号等。
TCP可以看成是一种字节流它会处理IP层或以下的层的丢包、重复以及错误问题。
在连接的建立过程中双方需要交换一些连接的参数。这些参数可以放在TCP头部。
一个TCP连接由一个4元组构成分别是
- 两个IP地址
- 两个端口号
一个TCP连接通常分为三个阶段
-
连接
-
数据传输
-
退出关闭。
通过三次握手建立一个链接通过四次挥手来关闭一个连接。
当一个连接被建立或被终止时交换的报文段只包含TCP头部而没有数据。
在了解TCP连接之前先来了解一下TCP报文的头部结构。
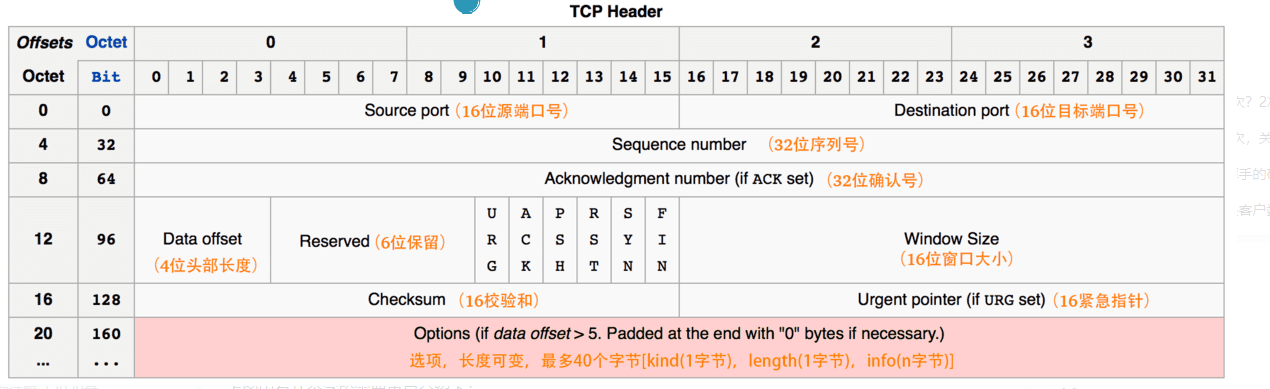
上图中有几个字段需要重点介绍下
1序号seq序号占32位用来标识从TCP源端向目的端发送的字节流发起方发送数据时对此进行标记。
2确认序号ack序号占32位只有ACK标志位为1时确认序号字段才有效ack=seq+1。期望收到对方下一个报文字段的第一个数据字节的序号。
3标志位共6个即URG、ACK、PSH、RST、SYN、FIN等具体含义如下
- ACK确认序号有效。
- FIN释放一个连接。
- PSH接收方应该尽快将这个报文交给应用层。
- RST重置连接。
- SYN发起一个新连接。
- URG紧急指针urgent pointer有效。
需要注意的是
- 不要将确认序号ack与标志位中的ACK搞混了。
- 确认方ack=发起方seq+1两端配对。
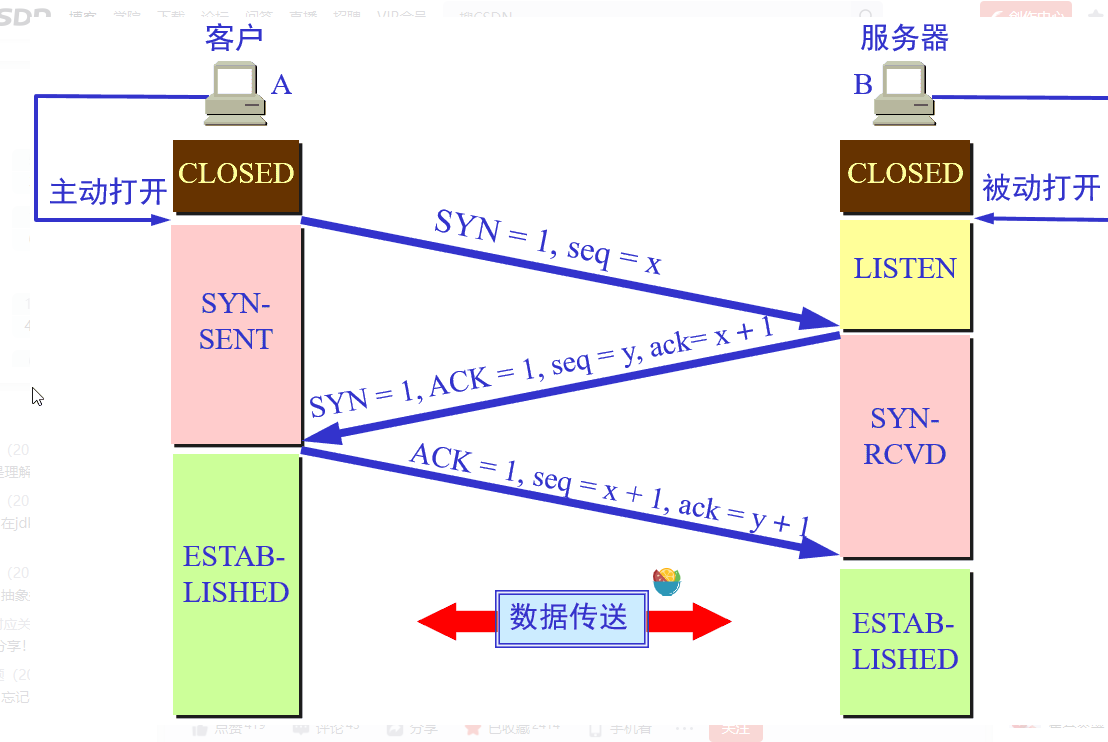
三次握手三报文握手
三次握手的本质是确认通信双方收发数据的能力
首先我让信使运输一份信件给对方对方收到了那么他就知道了我的发件能力和他的收件能力是可以的。
于是他给我回信我若收到了我便知我的发件能力和他的收件能力是可以的并且他的发件能力和我的收件能力是可以。
然而此时他还不知道他的发件能力和我的收件能力到底可不可以于是我最后回馈一次他若收到了他便清楚了他的发件能力和我的收件能力是可以的。
这就是三次握手这样说你理解了吗
为什么TCP需要进行连接
其实正如你所说的tcp也就是为了保证能够可靠的数据流而建立连接的
而所谓的“连接”实际上是逻辑上的一种安全机制这种机制能够保证数据包
的可靠性盒完整性比如tcp"连接"建立的三次握手又比如tcp中的序列号
都是为此设计的。
从物理上来讲tcp&udp一样都是被包装再ip包里面一包一包的发出去的只不过
tcp协议本身已经实现了安全机制从而在逻辑上成为了一种“连接”。
tcp是提供可靠性连接的只有支持端到端的连接才能进行可靠性传输连接的主要功能在于记录两个端口间的通信状态不连接则无法记录两个端口通信的状态则无法知道丢失了哪个数据包重复收到了哪个数据包也无法确保数据包之间的到达顺序还有很多增加可靠性的功能都无法应用。
第一次握手客户端要向服务端发起连接请求首先客户端随机生成一个起始序列号ISN(比如是100)那客户端向服务端发送的报文段包含SYN标志位(也就是SYN=1)序列号seq=100。第二次握手服务端收到客户端发过来的报文后发现SYN=1知道这是一个连接请求于是将客户端的起始序列号100存起来并且随机生成一个服务端的起始序列号(比如是300)。然后给客户端回复一段报文回复报文包含SYN和ACK标志(也就是SYN=1,ACK=1)、序列号seq=300、确认号ack=101(客户端发过来的序列号+1)。第三次握手客户端收到服务端的回复后发现ACK=1并且ack=101,于是知道服务端已经收到了序列号为100的那段报文同时发现SYN=1知道了服务端同意了这次连接于是就将服务端的序列号300给存下来。然后客户端再回复一段报文给服务端报文包含ACK标志位(ACK=1)、ack=301(服务端序列号+1)、seq=101(第一次握手时发送报文是占据一个序列号的所以这次seq就从101开始需要注意的是不携带数据的ACK报文是不占据序列号的所以后面第一次正式发送数据时seq还是101)。当服务端收到报文后发现ACK=1并且ack=301就知道客户端收到序列号为300的报文了就这样客户端和服务端通过TCP建立了连接。
传输控制块TCB 存储着每一个连接的重要信息。
假定TCP客户程序 为A TCP服务程序为B
在开始状态下A、B都处于CLOSED关闭状态
····
第一次握手SYN=1,seq=x
A的客户进程也是创建传输TCP控制块在打算进行TCP连接的时候向B发送连接请求报文段报文段中同步位标志位为1也就是 SYN=1同时选择一个初始序号 seq=x SYN报文段SYN=1的报文段不能携带数据但是要消耗一个序号这时客户进程进入SYN-SENT(同步已发送状态)
第二次握手SYN=1,ACK=1,seq=y,ack=x+1
B收到连接请求报文段后如果同意连接则向A发送确认。在确认报文段中同步位SYN和确认位ACK都设置为1确认号为 ack=x+1之后选择一个初始序号seq=y这个报文段也不能携带数据但是要消耗一个序号这时TCP服务器进入SYN-RCVD同步收到状态
第三次握手ACK=1,seq=x+1,ack=y+1
A客户进程收到B的确认后还要对B给出确认确认的报文段中将ACK设置为1ACK=1确认号 也就是ack=y+1,自己的序号则为x+1seq=x+1ACK报文段可以携带数据但是如果不携带数据则不消耗序号因为携带数据所以将seq=x+1随后A进入ESTABLISHED 已建立连接状态
B收到A的确认后也进入ESTABLISHED状态
为什么A 最后还要发送一次确认呢
这主要是为了防止已失效的连接请求报文段突然又传送到了B。因而产生错误。
已失效的连接请求报文段的产生
正常情况
A 发出连接请求但是因为连接请求丢失而没有收到确认A 重传一次连接请求。后来收到确认建立连接。数据传输完毕之后释放连接A发送两个连接请求其中第一个丢失第二个被B接收因此没有产生 已失效的连接请求报文段
异常情况
也就是A第一个发送的请求报文段没有被丢失而是有可能在网络环境中滞留导致延误到连接释放之后才到达B这本来是已经丢掉的但是B收到这个连接请求报文段就误认为A又一次发送新的连接请求于是向A发送确认报文段同意建立连接。A并没有发送新连接请求因此就不理睬B也不会发送数据但是B却认为是A发送的新的连接请求已经建立并一直等待着A发送数据因此B的资源就被浪费了。
四次挥手
四次挥手的目的是关闭一个连接
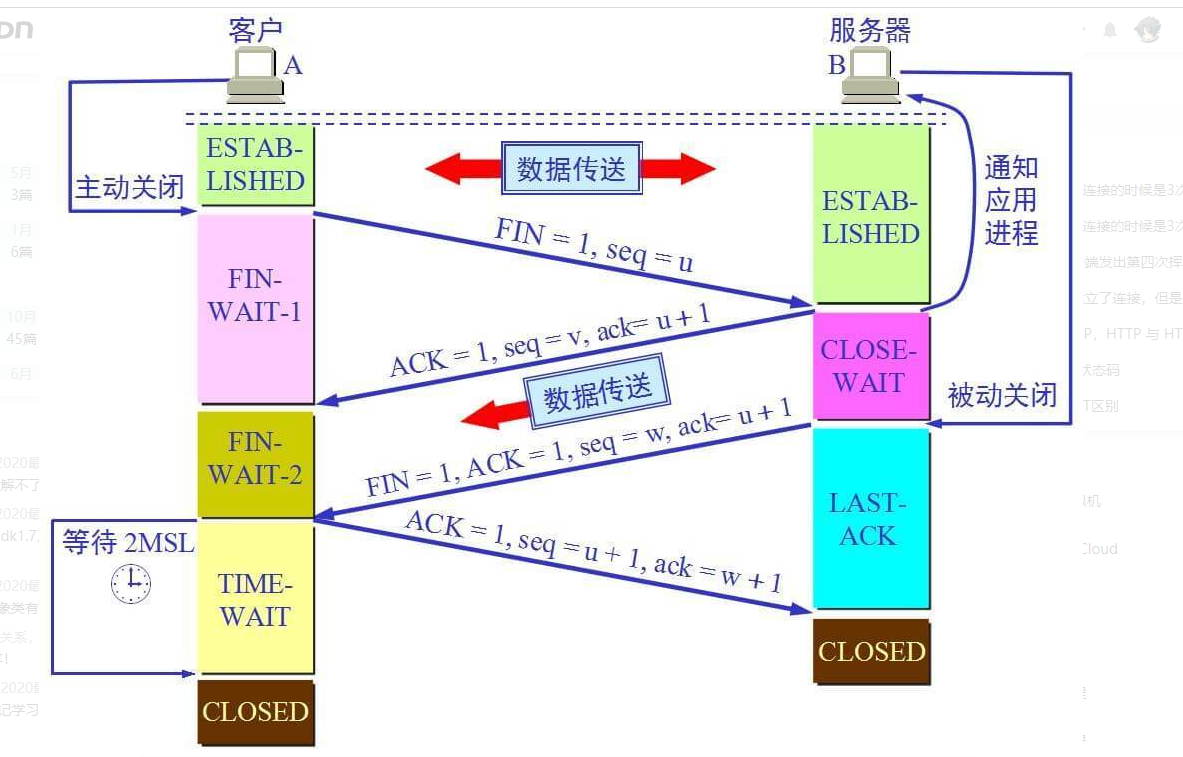
比如客户端初始化的序列号ISA=100服务端初始化的序列号ISA=300。TCP连接成功后客户端总共发送了1000个字节的数据服务端在客户端发FIN报文前总共回复了2000个字节的数据。
第一次挥手当客户端的数据都传输完成后客户端向服务端发出连接释放报文(当然数据没发完时也可以发送连接释放报文并停止发送数据)释放连接报文包含FIN标志位(FIN=1)、序列号seq=1101(100+1+1000其中的1是建立连接时占的一个序列号)。需要注意的是客户端发出FIN报文段后只是不能发数据了但是还可以正常收数据另外FIN报文段即使不携带数据也要占据一个序列号。第二次挥手服务端收到客户端发的FIN报文后给客户端回复确认报文确认报文包含ACK标志位(ACK=1)、确认号ack=1102(客户端FIN报文序列号1101+1)、序列号seq=2300(300+2000)。此时服务端处于关闭等待状态而不是立马给客户端发FIN报文这个状态还要持续一段时间因为服务端可能还有数据没发完。第三次挥手服务端将最后数据(比如50个字节)发送完毕后就向客户端发出连接释放报文报文包含FIN和ACK标志位(FIN=1,ACK=1)、确认号和第二次挥手一样ack=1102、序列号seq=2350(2300+50)。第四次挥手客户端收到服务端发的FIN报文后向服务端发出确认报文确认报文包含ACK标志位(ACK=1)、确认号ack=2351、序列号seq=1102。注意客户端发出确认报文后不是立马释放TCP连接而是要经过2MSL(最长报文段寿命的2倍时长)后才释放TCP连接。而服务端一旦收到客户端发出的确认报文就会立马释放TCP连接所以服务端结束TCP连接的时间要比客户端早一些。
第一次挥手 FIN=1,seq=u
数据传输结束之后双方都可以释放连接现在A和B都处于ESTABLISHED状态。A的进程先向器TCP发出连接释放报文段并停止发送数据主动关闭TCP连接。A 将终止报文段首部终止控制位FIN置1其序号seq=u他等于前面已经传过的数据的最后一个字节序号加1这时A 进入了FIN-WAIT-1终止等待1然后等待B的确认。TCP 规定FIN报文段及时不带数据也将要消耗一个序号。
第二次挥手 ACK=1,ack=u+1,seq=v
B收到连接释放请求后立即确认确认号为ack=u+1ACK=1而这个报文段自己的序号是vseq=v等于B前面所传输的数据的最后一个序号加1然后B进入到CLOSE-WAIT关闭等待状态这时TCP服务进程通知高层应用进程因而A到B的这个方向的连接就释放了这个时候TCP连接处于半关闭状态也就是说 A已经没有数据要发送了 但是B会有可能有数据要发送此时A还要去接收。也就是B到A方向上的连接并没有被关闭这个状态将会维持一段时间。
第三次挥手 FIN=1,ack=u+1,seq=wACK=1
A收到B的确认之后进入FIN-WAIT-2,(终止等待2)状态等待B发送的连接释放报文段。
若B已经没有要向A发送的数据其应用进程应该通知TCP释放连接这时B发出连接释放报文段使FIN=1序号为wseq=w在半关闭的状态下B有可能又发送了一些数据。B还必须要重复上次发送的确认号ack=u+1ACK=1随后B进入LAST-ACK最后确认状态等待A的确认。
第四次挥手 ACK=1,ack= w + 1,seq= u + 1
A在收到B的连接释放报文段之后必须对此做出一个确认在确认报文段中把ACK=1 确认号为w+1ack=w+1而自己的序号为 u+ 1因为A到B释放连接因此不会发送数据 而上一次发送的数据 序号为u 根据TCP的标准规定前面发送的FIN报文段要消耗一个序号然后进入到TIME-WAIT时间等待状态。注意现在TCP还没有被释放掉。必须经过时间等待计时器TIME-WAIT timer设置的时间2MSL后A才能进入到CLOSED状态 时间MSL叫做最长报文段寿命 可以根据不同的实现具体的情况去设置这个MSL值因此从A进入TIME-WAIT状态后要经过2MSL才能进入到CLOSED状态。 B在收到A的确认报文端之后进入CLOSED关闭状态。才能建议下一个新的连接当A撤销相应的传输控制块TCB之后结束这次的TCP连接。而服务端一旦收到客户端发出的确认报文就会立马释放TCP连接所以服务端结束TCP连接的时间要比客户端早一些。
为什么要在TIME-WAIT时间等待状态必须等待2MSL时间呢两个理由
个人理解
-
A发送的最后一个确认报文段丢失然后B进行超时重传如果有2MSL时间 A能收到之后A进行重传确认报文段因此A和B都能达到CLOSED关闭状态如果没有 A直接释放连接就不会收到B重传的连接释放请求因此就不会有A重传确认报文段B就无法正常进入CLOSED状态。
-
经过2MS之后会使该阶段产生的数据全部从网络中消息防止下一个连接中有旧的连接请求报文段
-
为了保证A发送的最后一个ACK报文段能够到达B。
这个ACK报文段有可能丢失因而使处在LAST-ACK状态的B收不到对已发送的FIN + ACK报文段的确认。B会超时重传这个FIN+ ACK报文段而A就能在2MSL时间内收到这个重传的FIN + ACK报文段。接着A重传一次确认重新启动2MSL计时器。最后A和B都正常进入到CLOSED状态。如果A在TIME-WAIT状态不等待-段时间而是在发送完ACK报文段后立即释放连接那么就无法收到B重传的FIN + ACK报文段因而也不会再发送- -次确认报文段。这样B就无法按照正常步骤进入CLOSED状态。
-
第二防止上一节提到的“已失效的连接请求报文段”出现在本连接中。
A在发送完最后一个ACK报文段后再经过时间2MSL就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样就可以使下一个新的连接中不会出现这种旧的连接请求报文段。
B只要收到了A发出的确认就进入CLOSED状态。同样B在撤销相应的传输控制块TCB后就结束了这次的TCP连接。我们注意到B结束TCP连接的时间要比A早一些。
除时间等待计时器外TCP 还设有一个保活计时器(keepalive timer)。 设想有这样的情况客户已主动与服务器建立了TCP连接。但后来客户端的主机突然出故障。显然服务器以后就不能再收到客户发来的数据。因此应当有措施使服务器不要再白白等待下去。这就是使用保活计时器。服务器每收到一次客户的数据就重新设置保活计时器时间的设置通常是两小时。若两小时没有收到客户的数据服务器就发送一个探测报文段以后则每隔75秒钟发送一次。若一连发送10个探测报文段后仍无客户的响应服务器就认为客户端出了故障接着就关闭这个连接。
为什么TCP连接的时候是3次2次不可以吗
因为需要考虑连接时丢包的问题如果只握手2次第二次握手时如果服务端发给客户端的确认报文段丢失此时服务端已经准备好了收发数(可以理解服务端已经连接成功)据而客户端一直没收到服务端的确认报文所以客户端就不知道服务端是否已经准备好了(可以理解为客户端未连接成功)这种情况下客户端不会给服务端发数据也会忽略服务端发过来的数据。
如果是三次握手即便发生丢包也不会有问题比如如果第三次握手客户端发的确认ack报文丢失服务端在一段时间内没有收到确认ack报文的话就会重新进行第二次握手也就是服务端会重发SYN报文段客户端收到重发的报文段后会再次给服务端发送确认ack报文。
为什么TCP连接的时候是3次关闭的时候却是4次
因为采用的是全双工通信只有在客户端和服务端都没有数据要发送的时候才能断开TCP。而客户端发出FIN报文时只能保证客户端没有数据发了服务端还有没有数据发客户端是不知道的。而服务端收到客户端的FIN报文后只能先回复客户端一个确认报文来告诉客户端我服务端已经收到你的FIN报文了但我服务端还有一些数据没发完等这些数据发完了服务端才能给客户端发FIN报文(所以不能一次性将确认报文和FIN报文发给客户端就是这里多出来了一次)。
为什么客户端发出第四次挥手的确认报文后要等2MSL的时间才能释放TCP连接
这里同样是要考虑丢包的问题如果第四次挥手的报文丢失服务端没收到确认ack报文就会重发第三次挥手的报文这样报文一去一回最长时间就是2MSL所以需要等这么长时间来确认服务端确实已经收到了。
如果已经建立了连接但是客户端突然出现故障了怎么办
TCP设有一个保活计时器客户端如果出现故障服务器不能一直等下去白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器时间通常是设置为2小时若两小时还没有收到客户端的任何数据服务器就会发送一个探测报文段以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应服务器就认为客户端出了故障接着就关闭连接。
TCP四元组
唯一能够确定一个连接有4个东西
- 服务器的IP
- 服务器的Port
- 客户端的IP
- 客户端的Port
tcp连接之半连接攻击和全连接攻击总结
https://blog.csdn.net/qq_26105397/article/details/81088188
-
半连接攻击
半连接攻击是一种攻击协议栈的攻击方式坦白说就是攻击主机的一种攻击方式。通过将主机的资源消耗殆尽从而导致应用层的程序无资源可用导致无法运行。
半连接就是通过不断地构造客户端的SYN连接数据包发向服务端等到服务端的半连接队列满的时候后续的正常用户的连接请求将会被丢弃从而无法连接到服务端。此为半连接攻击方式。
如何来解决半连接攻击
可以通过拓展半连接队列的大小来进行补救但缺点是不能无限制的增加这样会耗费过多的服务端资源导致服务端性能地下。这种方式几乎不可取。现主要通syn cookie或者syn中继机制来防范半连接攻部位半连接分配核心内存的方式来防范。
https://netsecurity.51cto.com/art/201009/225615_all.htm
-
全连接攻击
全连接攻击是通过==消费服务端进程数和连接数只连接而不进行发送数据的一种攻击方式。==当客户端连接到服务端仅仅只是连接此时服务端会为每一个连接创建一个进程来处理客户端发送的数据。但是客户端只是连接而不发送数据此时服务端会一直阻塞在recv或者read的状态如此一来多个连接服务端的每个连接都是出于阻塞状态从而导致服务端的崩溃。
如何来解决全连接攻击
可以通过不为全连接分配进程处理的方式来防范全连接攻击具体的情况是当收到数据之后在为其分配一个处理线程。具体的处理方式在accept返回之前是不分配处理线程的。直到接收相关的数据之后才为之提供一个处理过程。
什么是HTTPHTTP 与 HTTPS 的区别
HTTP 是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范 超文本传送协议 面向事务的应用层协议 无状态的 HTTPS S 代表 security
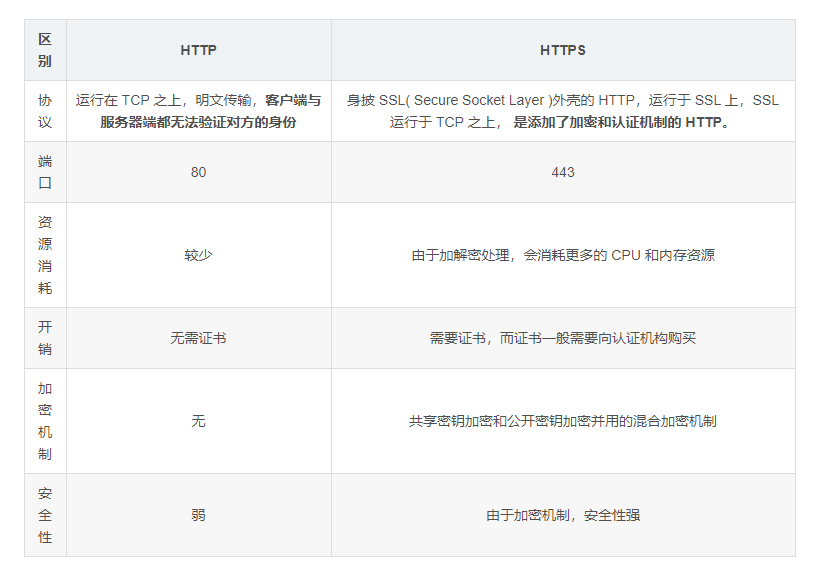
- HTTPS需要带CA申请证书
- HTTP协议运行在TCP之上HTTPS运行在SSL/TLS之上。SSL/TLS运行在TCP之上所以传输内容都是经过加密的。
- HTTP与HTTPS采用完全不同的连接方式端口也不一样HTTP端口是80HTTPS端口是443
- HTTPS可以有效防止运行商劫持解决了防劫持的一个大问题
HTTP是应用层协议TCP是传输层协议
HTTP承载在TCP之上。
打个比喻网络是路TCP是跑在路上的车HTTP是车上的人
Https=Http协议 + ssl
HTTP与HTTPS有什么区别
①、https协议需要到ca申请证书一般免费证书较少因而需要一定费用。
②、http是超文本传输协议信息是明文传输https则是具有安全性的ssl加密传输协议。
③、http默认是80端口后者默认是443端口。
④、http的连接很简单是无状态的HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议
HTTP的请求流程
https://www.cnblogs.com/gzshan/p/11125038.html
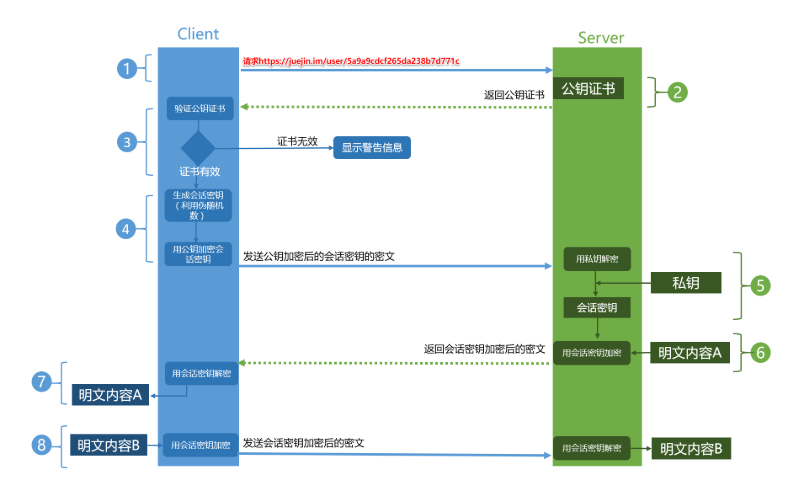
HTTPS的建立连接过程

- 在使用HTTPS是需要保证服务端配置正确了对应的安全证书
- 客户端发送请求到服务端
- 服务端返回公钥和证书到客户端
- 客户端接收后会验证证书的安全性,如果通过则会随机生成一个随机数,用公钥对其加密,发送到服务端
- 服务端接受到这个加密后的随机数后会用私钥对其解密得到真正的随机数,随后用这个随机数当做私钥对需要发送的数据进行对称加密
- 客户端在接收到加密后的数据使用私钥(即生成的随机值)对数据进行解密并且解析数据呈现结果给客户
- SSL加密建立
SSL在传输层与应用层之间对网络连接进行加密。SSL协议工作在应用层与传输层之间。
衍生问题1*HTTPS的加密方式是什么*
HTTPS采用对称加密+非对称加密的方式进行加密具体方式可以参考下图
常用HTTP状态码
HTTP状态码表示客户端HTTP请求的返回结果、标识服务器处理是否正常、表明请求出现的错误等。
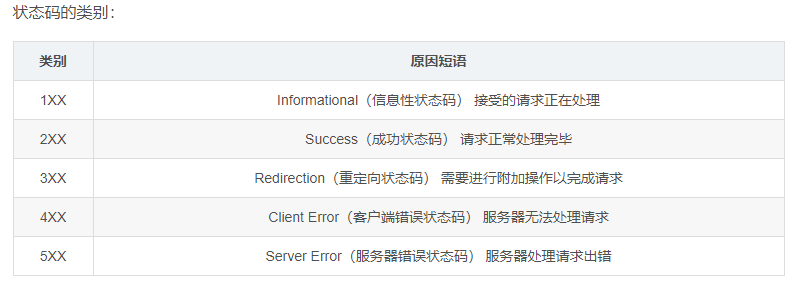


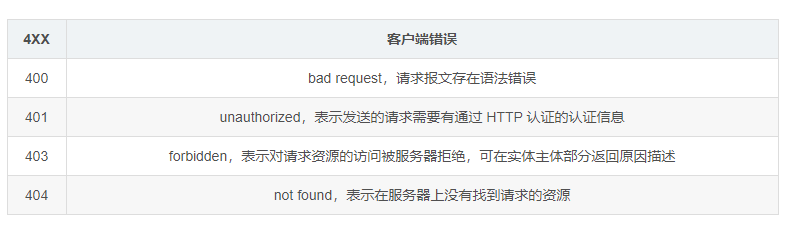
405表示 请求方式的错误
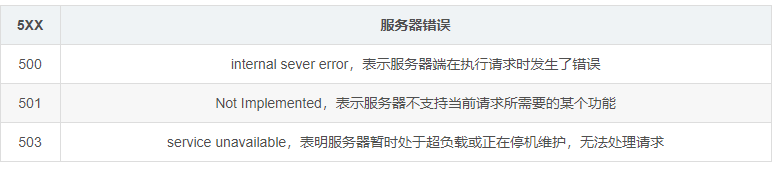
https://blog.csdn.net/huwei2003/article/details/70139062
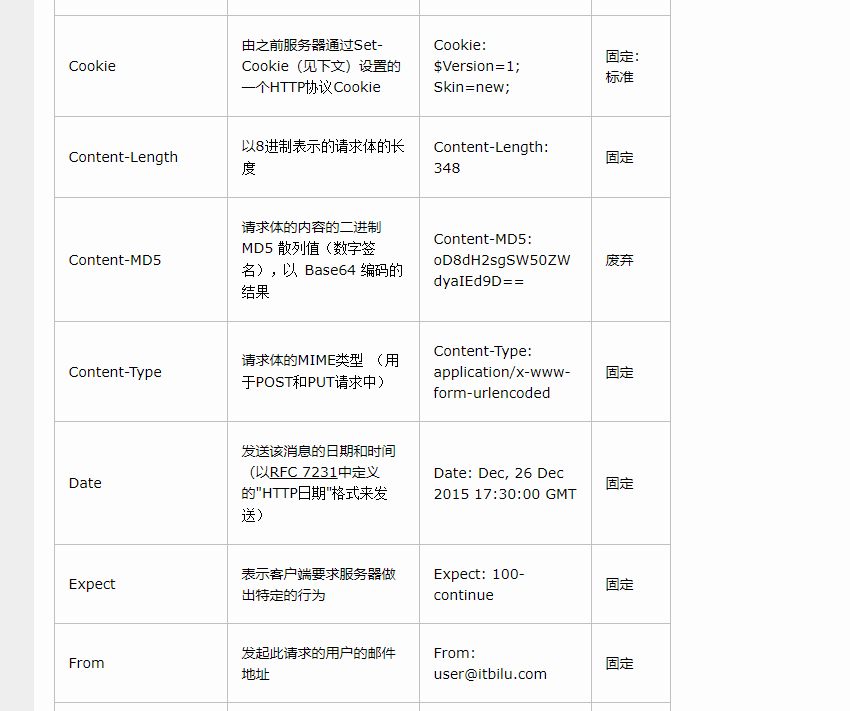
说一说HTTP的首部字段
- Connection浏览器想要优先使用的连接类型
- Cache-control:控制缓存的行为
- Date创建报文的时间
- Accept能正确接收的媒体类型application/json、text/plain
- Accept-charset:用户支持的字符集
- Authorization客户端认证信息一般存token信息
- Cookie发送给服务器的Cookie信息
- Host服务器的域名
- Location重定向到某个URL
- Set-Cookie需要存在客户端的信息
Http的请求头包含什么信息
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-36eqBKjN-1673796690819)(https://gitee.com/Code_Farming_Liu/image/raw/master/img/20201018185950.png)]
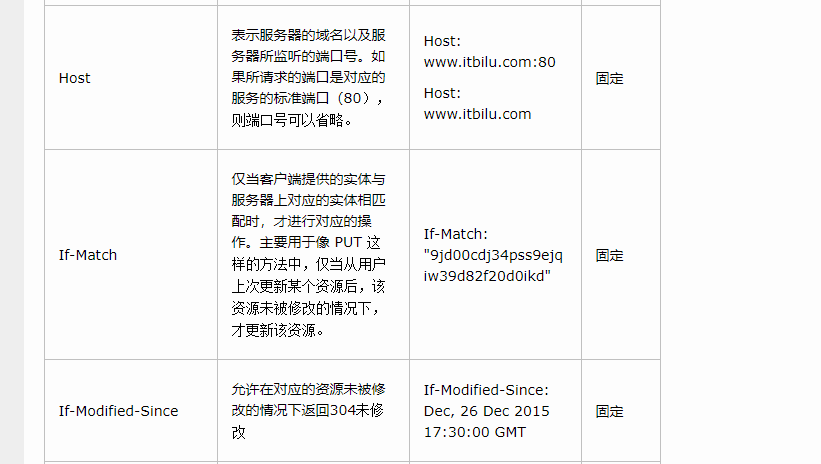
http 请求包含哪几个部分请求行、请求头、请求体
http协议报文
1.请求报文(请求行/请求头/请求数据/空行)
请求行
请求方法字段、URL字段和HTTP协议版本
例如GET /index.html HTTP/1.1
get方法将数据拼接在url后面传递参数受限
请求方法
GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT
请求头(key value形式)
User-Agent产生请求的浏览器类型。
Accept客户端可识别的内容类型列表。
Host主机地址
请求数据
post方法中会把数据以key value形式发送请求
空行
发送回车符和换行符通知服务器以下不再有请求头
2.响应报文(状态行、消息报头、响应正文)
状态行
消息报头
响应正文
GET和POST区别
说到GET和POST就不得不提HTTP协议因为浏览器和服务器的交互是通过HTTP协议执行的而GET和POST也是HTTP协议中的两种方法。
HTTP全称为Hyper Text Transfer Protocol中文翻译为超文本传输协议目的是保证浏览器与服务器之间的通信。HTTP的工作方式是客户端与服务器之间的请求-应答协议。
HTTP协议中定义了浏览器和服务器进行交互的不同方法基本方法有4种分别是GETPOSTPUTDELETE。这四种方法可以理解为对服务器资源的查改增删。
GET和POST区别
-
Get是不安全的因为在传输过程数据被放在请求的URL中Post的所有操作对用户来说都是不可见的。 但是这种做法也不时绝对的大部分人的做法也是按照上面的说法来的但是也可以在get请求加上 request body给 post请求带上 URL 参数。
-
Get请求提交的url中的数据最多只能是2048字节这个限制是浏览器或者服务器给添加的http协议并没有对url长度进行限制目的是为了保证服务器和浏览器能够正常运行防止有人恶意发送请求。Post请求则没有大小限制。
-
Get限制Form表单的数据集的值必须为ASCII字符而Post支持整个ISO10646字符集。
-
Get执行效率却比Post方法好。Get是form提交的默认方法。
-
GET产生一个TCP数据包POST产生两个TCP数据包。
对于GET方式的请求浏览器会把http header和data一并发送出去服务器响应200返回数据
而对于POST浏览器先发送header服务器响应100 continue浏览器再发送data服务器响应200 ok返回数据。
-
get请求传递的参数长度有限制而POST没有
-
post请求比get请求安全因为数据在地址栏不可见。
-
post请求会发出两个TCP数据包
其实这样说是不严谨的
-
get和post传递的参数本身是没有限制的只是get请求是基于浏览器URL传参浏览器会对URL的长度做限制所以才会有get请求传递的参数长度有限制的说法。
-
从传输的角度来说get请求和post请求都是不安全的因为HTTP是明文传输要想安全的传输就采用HTTPS。
-
POST请求会发送两个TCP数据包这个只是某些浏览器和框架的请求方式不是POST请求的必然行为。
-
POST和GET请求最本质的区别就是get具有幂等性。幂等性是指一次或多次请求一个资源应该产生相同的副作用。
-
Get是从服务器上获得数据而Post则是向服务器传递数据的。
-
Get是不安全的很可能你的一些操作会被第三方看到而Post的所有操作多用户来说是不可见的。
-
Get传输的数据量小主要是因为它受约于URL长度的限制而Post可以传输大量的数据所以我们在传文件的时候会用Post。
-
Get只能进行url编码而post支持多种编码方式
-
get比post效率要高
什么是对称加密与非对称加密
对称密钥加密是指加密和解密使用同一个密钥的方式这种方式存在的最大问题就是密钥发送问题即如何安全地将密钥发给对方
公钥的密码体制产生原因 对称密钥的密码体制的密钥分配问题二是对于数字签名的需求
任何加密算法的安全性取决于密钥的长度以及攻破密文的计算量
数字签名的特点
- 报文鉴别
- 报文完整性
- 不可否认
而非对称加密是指使用一对非对称密钥即公钥和私钥公钥可以随意发布但私钥只有自己知道。发送密文的一方使用对方的公钥进行加密处理对方接收到加密信息后使用自己的私钥进行解密。
由于非对称加密的方式不需要发送用来解密的私钥所以可以保证安全性但是和对称加密比起来非常的慢
什么是HTTP2
HTTP2 可以提高了网页的性能。
在 HTTP1 中浏览器限制了同一个域名下的请求数量Chrome 下一般是六个当在请求很多资源的时候由于队头阻塞当浏览器达到最大请求数量时剩余的资源需等待当前的六个请求完成后才能发起请求。
HTTP2 中引入了多路复用的技术这个技术可以只通过一个 TCP 连接就可以传输所有的请求数据。多路复用可以绕过浏览器限制同一个域名下的请求数量的问题进而提高了网页的性能。
**HTTP/1.0:**每次请求都打开一个新的TCP连接收到响应之后立即断开连接。
HTTP/1.1
- 在请求头中新增了range头域允许只请求资源的某一部分
- HTTP/1.1的请求头和响应头必须有HOST头域用来区分同一物理主机的不用虚拟服务器
- 长连接一个TCP连接可以发送多个HTTP请求减少了建立和关闭连接的消耗和延迟
- **缺点**线头堵塞、基于文本协议、请求和响应头信息非常大无法压缩单向请求
HTTP/2.0:
- 采用二进制协议解析
- 压缩头部,减少了需要传输的头部大小并且通讯的双方都保存一份头部避免重复的头部传输减少了传输的大小
- 多路复用允许并发的发送多个HTTP请求每个请求不需要等待其他请求或响应避免了线头阻塞的问题。这样如果某个请求任务耗时严重不会影响到其他连接正常的执行极大提高了传输性能。
- 服务端推送会把客户端需要的css/img伴随index.html一同推送到客户端省去了客户端的重复请求需要使用时直接从缓存中获取。
- **缺点**如果TCP连接中出现了丢包的现象会导致整个TCP连接重传
HTTP/3.0:
- HTTP/1.1、HTTP/2.0的缺点都是因为底层协议TCP导致的所以Google 基于 UDP 协议推出了一个的 QUIC 协议并且使用在了 HTTP/3 上。
- HTTP/3.0有避免包堵塞、快速重启会话的优点
Session、Cookie和Token的主要区别
HTTP协议本身是无状态的。什么是无状态呢即服务器无法判断用户身份。
什么是cookie客户端
cookie是由Web服务器保存在用户浏览器上的小文件key-value格式包含用户相关的信息。客户端向服务器发起请求如果服务器需要记录该用户状态就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie以此来辨认用户身份。
什么是session服务端
session是依赖Cookie实现的。session是服务器端对象
session 是浏览器和服务器会话过程中服务器分配的一块储存空间。服务器默认为浏览器在cookie中设置 sessionid浏览器在向服务器请求过程中传输 cookie 包含 sessionid 服务器根据 sessionid 获取出会话中存储的信息然后确定会话的身份信息。
cookie与session区别
- 存储位置与安全性cookie数据存放在客户端上安全性较差session数据放在服务器上安全性相对更高
- 存储空间单个cookie保存的数据不能超过4K很多浏览器都限制一个站点最多保存20个cookiesession无此限制
- 占用服务器资源session一定时间内保存在服务器上当访问增多占用服务器性能考虑到服务器性能方面应当使用cookie。
什么是Token客户端
Token的引入Token是在客户端频繁向服务端请求数据服务端频繁的去数据库查询用户名和密码并进行对比判断用户名和密码正确与否并作出相应提示在这样的背景下Token便应运而生。
Token的定义Token是服务端生成的一串字符串以作客户端进行请求的一个令牌当第一次登录后服务器生成一个Token便将此Token返回给客户端以后客户端只需带上这个Token前来请求数据即可无需再次带上用户名和密码。
使用Token的目的Token的目的是为了减轻服务器的压力减少频繁的查询数据库使服务器更加健壮。
Token 是在服务端产生的。如果前端使用用户名/密码向服务端请求认证服务端认证成功那么在服务端会返回 Token 给前端。前端可以在每次请求的时候带上 Token 证明自己的合法地位
session与token区别
- session机制存在服务器压力增大CSRF跨站伪造请求攻击扩展性不强等问题
- session存储在服务器端token存储在客户端
- token提供认证和授权功能作为身份认证token安全性比session好
- session这种会话存储方式方式只适用于客户端代码和服务端代码运行在同一台服务器上token适用于项目级的前后端分离前后端代码运行在不同的服务器下
Servlet是线程安全的吗
单例多线程 Servlet不是线程安全的多线程并发的读写会导致数据不同步的问题。
解决的办法是 尽量不要定义name属性而是要把name变量分别定义在doGet()和doPost()方法内。虽然使用synchronized(name){}语句块可以解决问题但是会造成线程的等待不是很科学的办法。 尽量不定义成员变量
注意多线程的并发的读写Servlet类属性会导致数据不同步。但是如果只是并发地读取属性而不写入则不存在数据不同步的问题。因此Servlet里的只读属性最好定义为final类型的。
Servlet接口中有哪些方法及Servlet生命周期探秘
在Java Web程序中Servlet主要负责接收用户请求HttpServletRequest在doGet()doPost()**中做相应的处理并将回应**HttpServletResponse反馈给用户。Servlet可以设置初始化参数供Servlet内部使用。
Servlet接口定义了5个方法其中前三个方法与Servlet生命周期相关
-
void init(ServletConfig config) throws ServletException
-
void service(ServletRequest req, ServletResponse resp) throws ServletException, java.io.IOException
-
void destory()
-
java.lang.String getServletInfo()
-
ServletConfig getServletConfig()
生命周期
Web容器加载Servlet并将其实例化后Servlet生命周期开始容器运行其init()方法进行Servlet的初始化
请求到达时调用Servlet的service()方法service()方法会根据需要调用与请求对应的doGet或doPost等方法
当服务器关闭或项目被卸载时服务器会将Servlet实例销毁此时会调用Servlet的destroy()方法。
init方法和destory方法只会执行一次service方法客户端每次请求Servlet都会执行。Servlet中有时会用到一些需要初始化与销毁的资源因此可以把初始化资源的代码放入init方法中销毁资源的代码放入destroy方法中这样就不需要每次处理客户端的请求都要初始化与销毁资源。
如果客户端禁止 cookie 能实现 session 还能用吗
Cookie 与 Session一般认为是两个独立的东西Session采用的是在服务器端保持状态的方案而Cookie采用的是在客户端保持状态的方案。
但为什么禁用Cookie就不能得到Session呢
因为Session是用Session ID来确定当前对话所对应的服务器Session而Session ID是通过Cookie来传递的禁用Cookie相当于失去了Session ID也就得不到Session了。
假定用户关闭Cookie的情况下使用Session其实现途径有以下几种
- 手动通过URL传值、隐藏表单传递Session ID。
- 用文件、数据库等形式保存Session ID在跨页过程中手动调用。
什么是DNS
DNS是域名解析系统最初由于ip长且难记通过ip访问网站不方便所以出现了域名解析系统将域名转化为对应的ip地址。DNS主要采用了UDP进行通讯主机向本地域名服务器查询一般递归查询本地域名向根域名服务器查询采用迭代查询。
递归查询所谓的递归查询就是如果主机所询问的本地域名服务器不知道被查询的域名的IP地址那么本地域名服务器就以DNS客户的身份向其他根域名服务器继续发出查询请求报文即替该主机继续查询而不是让该主机自己进行下一步的查询。因此递归查询返回的查询结果或者是所要查询的IP地址或者是报错表示无法查询到所需要的IP地址。
迭代查询当根域名服务器收到本地域名服务器收到本地域名服务器发出的迭代查询请求报文时要么给出所要查询的IP地址要么告诉本地域名服务器进行后续的查询而不是替本地域名服务器进行后续的查询。
什么是CDN
CDN工作原理
CDN是内容分发网络尽可能避开互联网上有可能影响数据传出速度和稳定性的瓶颈和环节使传输内容更快、更稳定。CDN只是对某个具体的域名的加速。
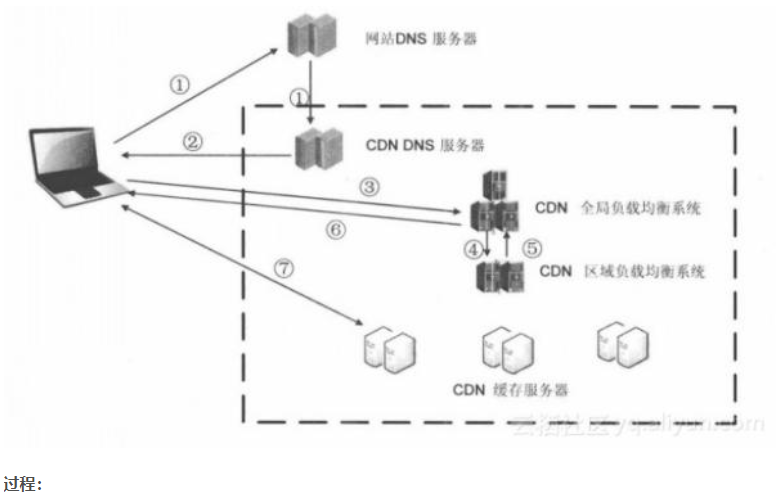
过程
-
用户向浏览器提供要访问的域名
-
浏览器调用域名解析库对域名进行解析由于CDN对域名解析过程进行了调整所以解析函数库得到的是该域名对应的CNAME记录由于现在已经是使用了CDN服务CNAME为CDN服务商域名为了得到实际IP地址浏览器需要再次对获得的CNAME域名进行解析以得到实际的IP地址在此过程中使用的全局负载均衡DNS解析如根据地理位置信息解析对应的IP地址使得用户能就近访问。CDN服务来提供最近的机器
-
此次解析得到CDN缓存服务器的IP地址浏览器在得到实际的IP地址以后向缓存服务器发出访问请求
-
缓存服务器根据浏览器提供的要访问的域名通过Cache内部专用DNS解析得到此域名的实际IP地址再由缓存服务器向此实际IP地址提交访问请求
-
缓存服务器从实际IP地址得得到内容以后一方面在本地进行保存以备以后使用二方面把获取的数据返回给客户端完成数据服务过程
-
客户端得到由缓存服务器返回的数据以后显示出来并完成整个浏览的数据请求过程。
-
当用户点击网站页面上的URL内容经过本地DNS解析会将域名的解析权交给CNAME指向的CDN专用DNS服务器。
-
CDN的DNS服务器将CDN的全局均衡设备IP地址返回给用户
-
用户向CDN的全局负载均衡设备发起请求
-
CDN全局均衡设备根据用户IP地址以及用户请求的内容URL选择一台用户所属区域的区域均衡设备并将请求转发到这台设备。
-
区域负载均衡设备根据用户IP、请求的URL为用户选择一台 合适的缓存服务器提供内容。
-
全局负载均衡设备把服务器的IP返回给用户
-
用户向CDN缓存服务器发起请求
-
缓存服务器响应用户请求将用户所需内容传送到用户终端。
CDN工作原理
①当用户点击网站页面上的内容URL经过本地DNS系统解析DNS系统会最终将域名的解析权交给CNAME指向的CDN专用DNS服务器。
②CDN的DNS服务器将CDN的全局负载均衡设备IP地址返回用户。
③用户向CDN的全局负载均衡设备发起内容URL访问请求。
④CDN全局负载均衡设备根据用户IP地址以及用户请求的内容URL选择一台用户所属区域的区域负载均衡设备告诉用户向这台设备发起请求。
⑤区域负载均衡设备会为用户选择一台合适的缓存服务器提供服务选择的依据包括根据用户IP地址判断哪一台服务器距用户最近根据用户所请求的URL中携带的内容名称判断哪一台服务器上有用户所需内容查询各个服务器当前的负载情况判断哪一台服务器尚有服务能力。基于以上这些条件的综合分析之后区域负载均衡设备会向全局负载均衡设备返回一台缓存服务器的IP地址。
⑥全局负载均衡设备把服务器的IP地址返回给用户。
⑦用户向缓存服务器发起请求缓存服务器响应用户请求将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容而区域均衡设备依然将它分配给了用户那么这台服务器就要向它的上一级缓存服务器请求内容直至追溯到网站的源服务器将内容拉到本地。
DNS服务器根据用户IP地址将域名解析成相应节点的缓存服务器IP地址实现用户就近访问。使用CDN服务的网站只需将其域名解析权交给CDN的GSLB设备将需要分发的内容注入CDN就可以实现网站内容加速。
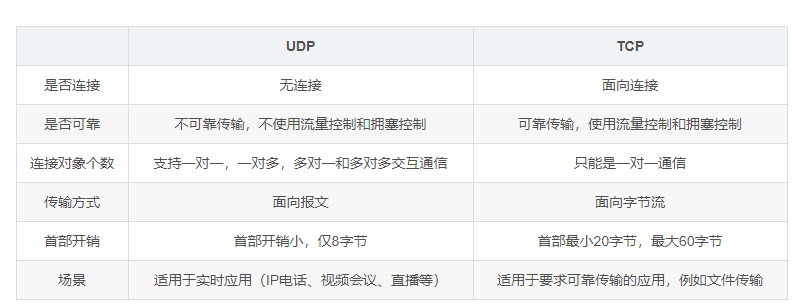
什么是UDP
UDP全称用户数据报协议是运输层协议。具有以下特点
- 无连接发送数据之前不需要建立连接 减少开销和发送数据之前的时延
- 面向报文应用层传过来多少数据原封不动的向下传递 因此需要选择合适的报文长度
- 尽最大努力交付不可靠连接 主机不需要维持复杂的连接状态
- 首部开销较小首部仅有8个字节
- 可以实现一对一、一对多、多对多之间的通讯
- 没有拥塞控制
什么是TCP
TCP全称传输控制协议也是运输层协议。TCP是面向连接的、可靠的字节流服务。具有以下特点
- 面向连接的运输层协议
- 一条TCP连接只有两个端口 只能是点对点
- TCP提供全双工的通信并且接收端和发送端都设有缓存
- 面向字节流的服务 字节流指的是流入到进程或从进程流出的字节序列
- 可靠传输、流量控制、拥塞控制
**可靠传输**已字节为单位的滑动窗口、超时重传
**流量控制**利用滑动窗口实现的流量控制告诉发送方不要太快要让接收方来的及接受
**拥塞控制**采用了四种算法慢开始、拥塞避免、快重传、快恢复
**衍生问题1**流量控制和拥塞控制的区别
- 流量控制是一个端到端的问题是接收端告诉发送端发送数据的速率以便使接收端来的及接受
- 拥塞控制是一个全局性的过程涉及所有主机所有路由器以及与降低网络传输性能有关的所有因素
Tcp传输控制协议与Udp用户数据报协议的区别
TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议是专门为了在不可靠的网络中提供一个可靠的端对端字节流而设计的面向字节流。
UDP用户数据报协议是iso参考模型中一种无连接的传输层协议提供简单不可靠的非连接传输层服务面向报文
区别
1 TCP是面向连接的可靠性高UDP是基于非连接的可靠性低 面向报文的
2 由于TCP是连接的通信需要有三次握手、重新确认等连接过程会有延时实时性差同时过程复杂也使其易于攻击UDP没有建立连接的过程因而实时性较强也稍安全
3 在传输相同大小的数据时TCP首部开销20字节UDP首部开销8字节TCP报头比UDP复杂故实际包含的用户数据较少。TCP在IP协议的基础上添加了序号机制、确认机制、超时重传机制等保证了传输的可靠性不会出现丢包或乱序而UDP有丢包故TCP开销大UDP开销较小
4 每条TCP连接只能时点到点的UDP支持一对一、一对多、多对一、多对多的交互通信
应用场景选择
对实时性要求高和高速传输的场合下使用UDP;在可靠性要求低追求效率的情况下使用UDP;
需要传输大量数据且对可靠性要求高的情况下使用TCP
补充
tcp是socket建立连接的一个服务器socket和和一个客户端socket建立通信udp是广播模式不需要建立连接
TCP与IP的区别
-
TCP又叫传输控制协议Transmission Control Protocal是一种面向连接的、端对端的、可靠的、基于IP的传输层协议。主要特点是3次握手建立连接4次挥手断开连接。
-
IP又叫因特网协议Internet ProtocolIP协议位于网络层IP协议规定了数据传输时的基本单元数据包和格式IP协议还定义了数据包的递交办法和路由选择。
总结整个网络中的传输流程是IP层接收由更低层网络接口层例如以太网设备驱动程序发来的数据包并把该数据包发送到更高层—TCP层相反IP层也把从TCP接收来的数据包传送到更低层。
TCP和IP的关系是IP提供基本的数据传送而高层的TCP对这些数据包做进一步加工如提供端口号等等。
从输入URL到页面加载完成都发生了什么
重要
https://blog.csdn.net/qq_40959677/article/details/94873075?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=1328741.27106.16169191275911073&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
- 判断浏览器缓存是否可用如果可用直接获取缓存
- 进行DNS解析获得对应ip
- 建立TCP连接
- 发送HTTP请求
- 服务端收到请求之后返回响应
- 浏览器渲染构建DOM树
- 断开TCP连接
1、浏览器的地址栏输入URL并按下回车。
2、浏览器查找当前URL是否存在缓存并比较缓存是否过期。
3、DNS解析URL对应的IP。
4、根据IP建立TCP连接三次握手。
5、HTTP发起请求。
6、服务器处理请求浏览器接收HTTP响应。
7、渲染页面构建DOM树。
8、关闭TCP连接四次挥手。
说完整个过程的几个关键点后我们再来展开的说一下。
一、URL
我们常见的RUL是这样的:http://www.baidu.com,这个域名由三部分组成协议名、域名、端口号这里端口是默认所以隐藏。除此之外URL还会包含一些路径、查询和其他片段例如http://www.tuicool.com/search?kw=%E4%。我们最常见的的协议是HTTP协议除此之外还有加密的HTTPS协议、FTP协议、FILe协议等等。URL的中间部分为域名或者是IP之后就是端口号了。通常端口号不常见是因为大部分的都是使用默认端口如HTTP默认端口80HTTPS默认端口443。说到这里可能有的面试官会问你同源策略以及更深层次的跨域的问题我今天就不在这里展开了。
二、缓存
说完URL我们说说浏览器缓存,HTTP缓存有多种规则根据是否需要重新向服务器发起请求来分类我将其分为强制缓存对比缓存。
强制缓存判断HTTP首部字段cache-controlExpires。
Expires是一个绝对时间即服务器时间。浏览器检查当前时间如果还没到失效时间就直接使用缓存文件。但是该方法存在一个问题服务器时间与客户端时间可能不一致。因此该字段已经很少使用。
cache-control中的max-age保存一个相对时间。例如Cache-Control: max-age = 484200表示浏览器收到文件后缓存在484200s内均有效。 如果同时存在cache-control和Expires浏览器总是优先使用cache-control。
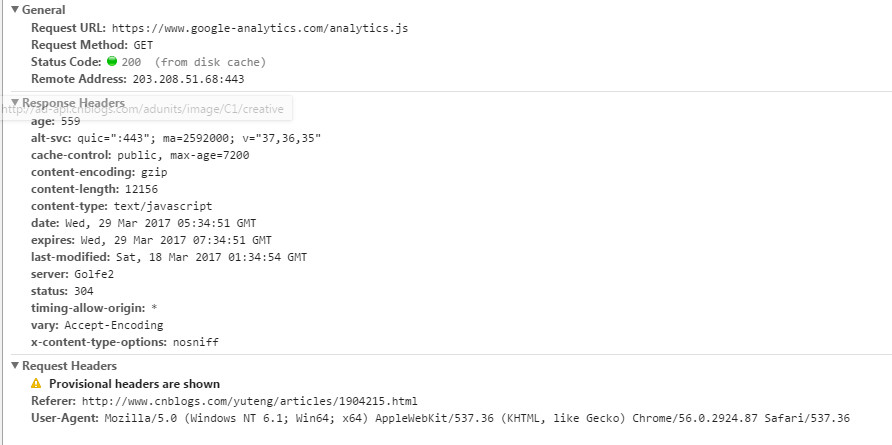
对比缓存通过HTTP的last-modifiedEtag字段进行判断。
last-modified是第一次请求资源时服务器返回的字段表示最后一次更新的时间。下一次浏览器请求资源时就发送if-modified-since字段。服务器用本地Last-modified时间与if-modified-since时间比较如果不一致则认为缓存已过期并返回新资源给浏览器如果时间一致则发送304状态码让浏览器继续使用缓存。
Etag资源的实体标识哈希字符串当资源内容更新时Etag会改变。服务器会判断Etag是否发生变化如果变化则返回新资源否则返回304。
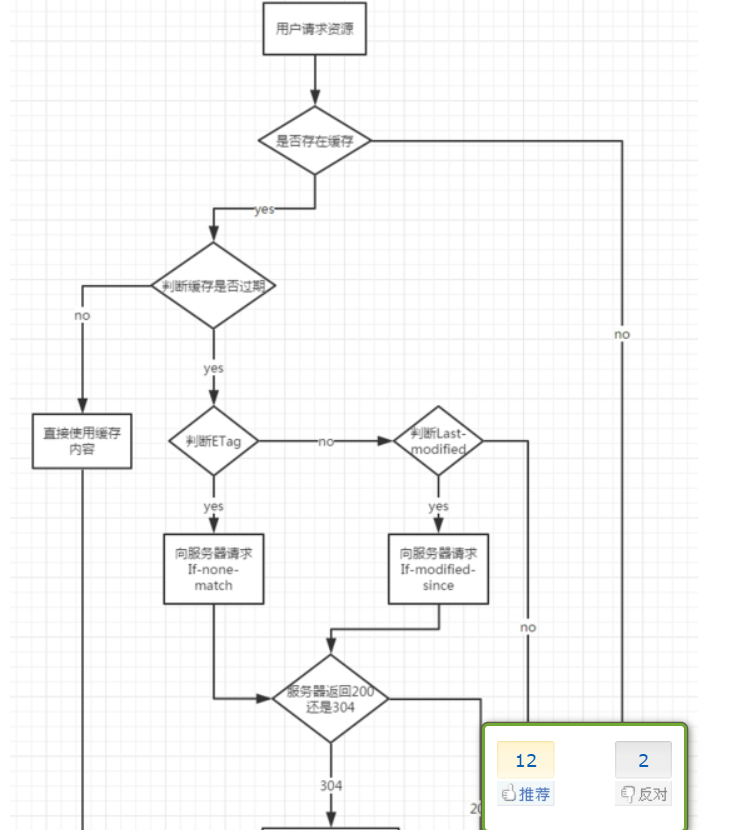
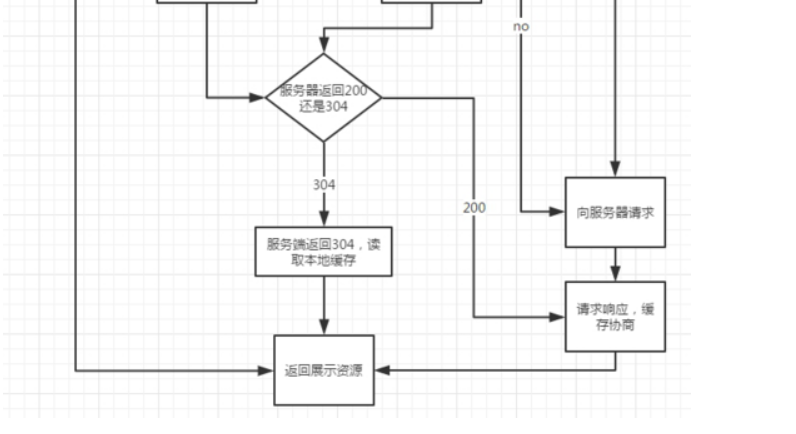
三、DNS域名解析
我们知道在地址栏输入的域名并不是最后资源所在的真实位置域名只是与IP地址的一个映射。网络服务器的IP地址那么多我们不可能去记一串串的数字因此域名就产生了域名解析的过程实际是将域名还原为IP地址的过程。
1. 首先浏览器先检查本地hosts文件是否有这个网址映射关系如果有就调用这个IP地址映射完成域名解析。
2. 如果没找到则会查找本地DNS解析器缓存如果查找到则返回。
3. 如果还是没有找到则会查找本地DNS服务器如果查找到则返回。
4. 最后迭代查询按根域服务器 ->顶级域,.cn->第二层域hb.cn ->子域www.hb.cn的顺序找到IP地址。
完整的HTTP请求包含请求起始行、请求头部、请求主体三部分。
浏览器是怎么渲染页面的
浏览器是边解析边渲染首先浏览器解析HTML文件构建DOM树然后会解析CSS文件构建CSS 规则树最后根据DOM树和CSS规则树构建渲染树等到渲染树构建完成之后浏览器开始布局渲染树并将其绘制到屏幕这个过程要尽量减少回流和重绘。
JS的解析是由浏览器中的JS引擎完成的JS是单线程文档中的JS加载并且解析完成之后才会继续HTML的渲染因为JS可能会改变DOM结构所以要把script标签放到body后面这里也可以使用defer和async。defer表示延迟执行等到HTML解析完毕并且script加载完成才执行async表示异步引入如果加载好了就会立即执行。CSS文件不会影响JS的加载但是会影响JS的解析。
从输入域名到拿到首页的所有细节过程
[https://blog.csdn.net/qq_39380590/article/details/82432364?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160405138619725222455214%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=160405138619725222455214&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_v2~rank_v28-1-82432364.pc_first_rank_v2_rank_v28&utm_term=%E4%B8%BB%E5%9F%9F%E5%90%8D%E6%9C%8D%E5%8A%A1%E5%99%A8%E5%9C%A8%E6%8E%A5%E6%94%B6%E5%88%B0%E5%9F%9F%E5%90%8D%E8%AF%B7%E6%B1%82%E5%90%8E%E9%A6%96%E5%85%88%E6%9F%A5%E8%AF%A2%E7%9A%84%E6%98%AF%E4%BB%80%E4%B9%88&spm=1018.2118.3001.4449]
详细说一下跨域
只有浏览器具有同源策略同源策略是指“协议+域名+端口”相同否则就是跨域即使2个不同的域名指向同一个服务端也是跨域。服务器与服务器之间不存在跨域。
解决跨域的方案有
JSONP:利用<script>表示没有跨域限制的漏洞网页可以获得从其他来源动态产生的JSON数据。JSONP请求一定需要对方的服务器支持才可以。**优缺点**简单兼容性好但是仅支持GET方法具有局限性。CORS:需要后端设置Access-Control-Allow-Origin字段表示哪些域名可以访问资源。CORS默认不会发生cookie,只有Access-Control-Allow-Credentials为true表示服务器允许该请求包含cookie信息。postMessage:允许来自不同源的脚本采用异步方式进行有限的通信可以实现跨文本文档、多窗口、跨域消息传递。websocket:是H5的一个持久化协议实现了客户端与浏览器的全双工通信。- 代理
其中CORS分为简单请求和复杂请求。对于简单请求浏览器直接发出CORS请求就是在头信息中增加一个Origin字段来说明请求来自哪个源如果不在许可范围内则响应头中没有Access-Conctrol-Allow-Origin浏览器会报错。复杂请求会在正式通信之前增加一次HTTP请求options请求方法称之为“预检”请求。浏览器先会询问服务器当前网站所在的域名是否在服务器的许可名单之内只有得到肯定的答复浏览器才会发出正式的请求否则就报错
什么是XSS攻击和CSRF攻击
https://freessl.wosign.com/1336.html
**XSS**跨站脚本攻击是一种代码注入攻击。攻击者通过在目标网站上注入恶意脚本使之在用户的浏览器上运行。
XSS攻击的分类
- 存储型XSS攻击者将恶意代码提交到目标网站的数据库中
- 反射型XSS攻击者构造出特殊的URL其中包含恶意代码用户打开带有恶意代码的 URL 时网站服务端将恶意代码从 URL 中取出拼接在 HTML 中返回给浏览器。
- DOM型XSS:攻击者构造出特殊的 URL其中包含恶意代码。用户浏览器接收到响应后解析执行前端 JavaScript 取出 URL 中的恶意代码并执行。
**预防XSS攻击**改为纯前端渲染把代码和数据分隔开、对输入的内容做长度控制 、避免内联事件
**CSRF**跨站请求伪造攻击者诱导受害者进入第三方网站在第三方网站中向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证绕过后台的用户验证达到冒充用户对被攻击的网站执行某项操作的目的。
**预防CSRF攻击**阻止不明外域的访问同源检测 、提交时要求附加本域才能获取的信息CSRF Token、双重cookie验证
SQL注入是比较常见的网络攻击方式之一它不是利用操作系统的BUG来实现攻击而是针对程序员编写时的疏忽通过SQL语句实现无账号登录甚至篡改数据库。
二SQL注入攻击的总体思路
1寻找到SQL注入的位置
2判断服务器类型和后台数据库类型
3针对不同的服务器和数据库特点进行SQL注入攻击
三SQL注入攻击实例
[ ](javascript:void(0)😉
](javascript:void(0)😉
String sql = "select * from user_table where username=
' "+userName+" ' and password=' "+password+" '";
--当输入了上面的用户名和密码上面的SQL语句变成
SELECT * FROM user_table WHERE username=
'’or 1 = 1 -- and password='’
"""
--分析SQL语句
--条件后面username=”or 1=1 用户名等于 ” 或1=1 那么这个条件一定会成功
--然后后面加两个-这意味着注释它将后面的语句注释让他们不起作用这样语句永远都--能正确执行用户轻易骗过系统获取合法身份。
--这还是比较温柔的如果是执行
SELECT * FROM user_table WHERE
username='' ;DROP DATABASE (DB Name) --' and password=''
--其后果可想而知…
"""
四如何防御SQL注入
注意但凡有SQL注入漏洞的程序都是因为程序要接受来自客户端用户输入的变量或URL传递的参数并且这个变量或参数是组成SQL语句的一部分对于用户输入的内容或传递的参数我们应该要时刻保持警惕这是安全领域里的「外部数据不可信任」的原则纵观Web安全领域的各种攻击方式大多数都是因为开发者违反了这个原则而导致的所以自然能想到的就是从变量的检测、过滤、验证下手确保变量是开发者所预想的。
1、检查变量数据类型和格式
如果你的SQL语句是类似where id={$id}这种形式数据库里所有的id都是数字那么就应该在SQL被执行前检查确保变量id是int类型如果是接受邮箱那就应该检查并严格确保变量一定是邮箱的格式其他的类型比如日期、时间等也是一个道理。总结起来只要是有固定格式的变量在SQL语句执行前应该严格按照固定格式去检查确保变量是我们预想的格式这样很大程度上可以避免SQL注入攻击。
比如我们前面接受username参数例子中我们的产品设计应该是在用户注册的一开始就有一个用户名的规则比如5-20个字符只能由大小写字母、数字以及一些安全的符号组成不包含特殊字符。此时我们应该有一个check_username的函数来进行统一的检查。不过仍然有很多例外情况并不能应用到这一准则比如文章发布系统评论系统等必须要允许用户提交任意字符串的场景这就需要采用过滤等其他方案了。
2、过滤特殊符号
对于无法确定固定格式的变量一定要进行特殊符号过滤或转义处理。
3、绑定变量使用预编译语句
MySQL的mysqli驱动提供了预编译语句的支持不同的程序语言都分别有使用预编译语句的方法
实际上绑定变量使用预编译语句是预防SQL注入的最佳方式使用预编译的SQL语句语义不会发生改变在SQL语句中变量用问号?表示黑客即使本事再大也无法改变SQL语句的结构
1.1预编译语句是什么
通常我们的一条sql在db接收到最终执行完毕返回可以分为下面三个过程
-
- 词法和语义解析
- 优化sql语句制定执行计划
- 执行并返回结果
我们把这种普通语句称作Immediate Statements。
但是很多情况我们的一条sql语句可能会反复执行或者每次执行的时候只有个别的值不同比如query的where子句值不同update的set子句值不同,insert的values值不同。
如果每次都需要经过上面的词法语义解析、语句优化、制定执行计划等则效率就明显不行了。
所谓预编译语句就是将这类语句中的值用占位符替代可以视为将sql语句模板化或者说参数化一般称这类语句叫Prepared Statements或者Parameterized Statements
预编译语句的优势在于归纳为一次编译、多次运行省去了解析优化等过程此外预编译语句能防止sql注入。
当然就优化来说很多时候最优的执行计划不是光靠知道sql语句的模板就能决定了往往就是需要通过具体值来预估出成本代价。
加密相关
https://blog.csdn.net/Jack__iT/article/details/86490908
对称加密和非对称加密区别
https://blog.csdn.net/qq_29689487/article/details/81634057
TCP粘包拆包及解决方法
http请求报文格式和响应报文格式
WebSocket的实现原理
https://www.jianshu.com/p/3444ea70b6cb
https://blog.csdn.net/qq_35623773/article/details/87868682
DDOS分布式拒绝服务攻击
分布式拒绝服务攻击可以使很多的计算机在同一时间遭受到攻击使攻击的目标无法正常使用分布式拒绝服务攻击已经出现了很多次导致很多的大型网站都出现了无法进行操作的情况
分布式拒绝服务攻击方式在进行攻击的时候可以对源IP地址进行伪造这样就使得这种攻击在发生的时候隐蔽性是非常好的同时要对攻击进行检测也是非常困难的因此这种攻击方式也成为了非常难以防范的攻击。
分布式拒绝服务攻击(英文意思是Distributed Denial of Service简称DDoS)是指处于不同位置的多个攻击者同时向一个或数个目标发动攻击或者一个攻击者控制了位于不同位置的多台机器并利用这些机器对受害者同时实施攻击。由于攻击的发出点是分布在不同地方的这类攻击称为分布式拒绝服务攻击其中的攻击者可以有多个。
它利用网络协议和操作系统的一些缺陷采用欺骗和伪装的策略来进行网络攻击使网站服务器充斥大量要求回复的信息消耗网络带宽或系统资源导致网络或系统不胜负荷以至于瘫痪而停止提供正常的网络服务。
它利用网络协议和操作系统的一些缺陷采用欺骗和伪装的策略来进行网络攻击使网站服务器充斥大量要求回复的信息消耗网络带宽或系统资源导致网络或系统不胜负荷以至于瘫痪而停止提供正常的网络服务。
UDP如何实现可靠传输
https://www.jianshu.com/p/6c73a4585eba
UDP不属于连接协议具有资源消耗少处理速度快的优点所以通常音频视频和普通数据在传送时使用UDP较多因为即使丢失少量的包也不会对接受结果产生较大的影响。
传输层无法保证数据的可靠传输只能通过应用层来实现了。实现的方式可以参照tcp可靠性传输的方式只是实现不在传输层实现转移到了应用层。
综合阐述http1.0/1.1/2和https
https://blog.csdn.net/weixin_37719279/article/details/81388358
nat协议
NATNetwork Address Translation网络地址转换是1994年提出的。当在专用网内部的一些主机本来已经分配到了本地IP地址即仅在本专用网内使用的专用地址但现在又想和因特网上的主机通信并不需要加密时可使用NAT方法。
这种方法需要在专用网私网IP连接到因特网公网IP的路由器上安装NAT软件。装有NAT软件的路由器叫做NAT路由器它至少有一个有效的外部全球IP地址公网IP地址。这样所有使用本地地址私网IP地址的主机在和外界通信时都要在NAT路由器上将其本地地址转换成全球IP地址才能和因特网连接。
NAT不仅能解决IP地址不足的问题而且还能够有效地避免来自网络外部的攻击隐藏并保护网络内部的计算机。
1.宽带分享这是 NAT 主机的最大功能。
2.安全防护NAT 之内的 PC 联机到 Internet 上面时他所显示的 IP 是 NAT 主机的公共 IP所以 Client 端的 PC 当然就具有一定程度的安全了外界在进行 portscan端口扫描 的时候就侦测不到源Client 端的 PC 。
NAT的实现方式有三种即静态转换Static Nat、动态转换Dynamic Nat和端口多路复用OverLoad。
静态****转换是指将内部网络的私有IP地址转换为公有IP地址IP地址对是一对一的是一成不变的某个私有IP地址只转换为某个公有IP地址。借助于静态转换可以实现外部网络对内部网络中某些特定设备如服务器的访问。
动态转换是指将内部网络的私有IP地址转换为公用IP地址时IP地址是不确定的是随机的所有**被授权访问上Internet的私有IP地址可随机转换为任何指定的合法IP地址。**也就是说只要指定哪些内部地址可以进行转换以及用哪些合法地址作为外部地址时就可以进行动态转换。动态转换可以使用多个合法外部地址集。当ISP提供的合法IP地址略少于网络内部的计算机数量时。可以采用动态转换的方式。
端口多路复用Port address Translation,PAT==是指改变外出数据包的源端口并进行端口转换即端口地址转换PATPort Address Translation).==采用端口多路复用方式。内部网络的所有主机均可共享一个合法外部IP地址实现对Internet的访问从而可以最大限度地节约IP地址资源。同时又可隐藏网络内部的所有主机有效避免来自internet的攻击。因此目前网络中应用最多的就是端口多路复用方式。
ALGApplication Level Gateway即应用程序级网关技术传统的NAT技术只对IP层和传输层头部进行转换处理但是一些应用层协议在协议数据报文中包含了地址信息。为了使得这些应用也能透明地完成NAT转换NAT使用一种称作ALG的技术它能对这些应用程序在通信时所包含的地址信息也进行相应的NAT转换。
如果协议数据报文中不包含地址信息则很容易利用传统的NAT技术来完成透明的地址转换功能通常我们使用的如下应用就可以直接利用传统的NAT技术HTTP、TELNET、FINGER、NTP、NFS、ARCHIE、RLOGIN、RSH、RCP等
工作原理
借助于NAT私有保留地址的"内部"网络通过路由器发送数据包时私有地址被转换成合法的IP地址一个局域网只需使用少量IP地址甚至是1个即可实现私有地址网络内所有计算机与Internet的通信需求。
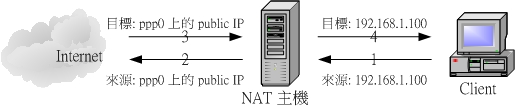 Nat-工作流程1
Nat-工作流程1
NAT将自动修改IP报文的源IP地址和目的IP地址Ip地址校验则在NAT处理过程中自动完成。有些应用程序将源IP地址嵌入到IP报文的数据部分中所以还需要同时对报文的数据部分进行修改以匹配IP头中已经修改过的源IP地址。否则在报文数据部分嵌入IP地址的应用程序就不能正常工作。
Java异常架构与异常关键字
Java异常简介
Java异常是Java提供的一种识别及响应错误的一致性机制。
Java异常机制可以使程序中异常处理代码和正常业务代码分离保证程序代码更加优雅并提高程序健壮性。在有效使用异常的情况下异常能清晰的回答what, where, why这3个问题异常类型回答了“什么”被抛出异常堆栈跟踪回答了“在哪”抛出异常信息回答了“为什么”会抛出。
非检查型异常继承自RuntimeException或Error的是非检查型异常
检查型异常继承Exception的则是检查型异常编译时就可发现需要try-catch或把异常交给上级方法处理总之需要提前处理
运行时异常继承自RuntimeException的是运行时异常
spring声明式事务管理默认对非检查型异常和运行时异常进行事务回滚而对检查型异常则不进行回滚操作。
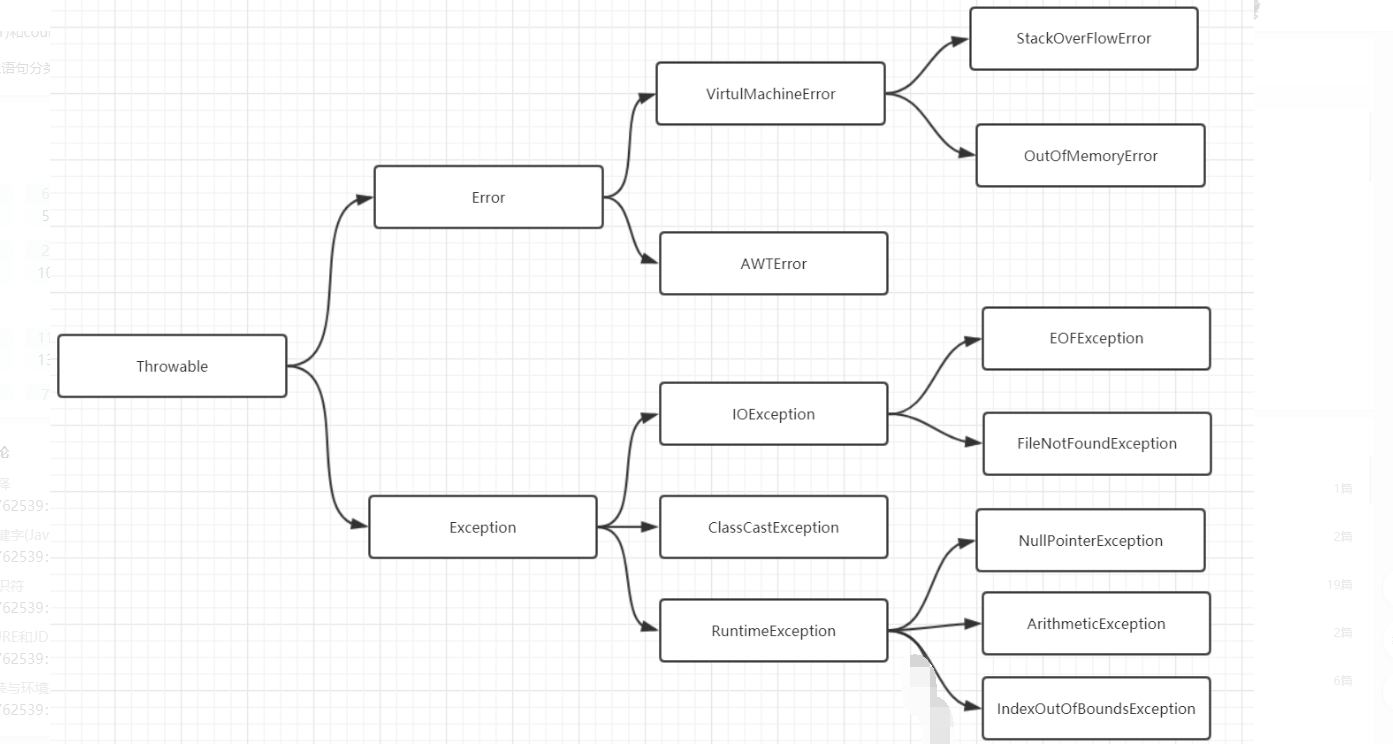
1. Throwable
Throwable 是 Java 语言中所有错误与异常的超类。
Throwable 包含两个子类Error错误和 Exception异常它们通常用于指示发生了异常情况。
Throwable 包含了其线程创建时线程执行堆栈的快照它提供了 printStackTrace() 等接口用于获取堆栈跟踪数据等信息。
2. Error错误
定义Error 类及其子类。程序中无法处理的错误表示运行应用程序中出现了严重的错误。
特点此类错误一般表示代码运行时 JVM 出现问题。通常有 Virtual MachineError虚拟机运行错误、NoClassDefFoundError类定义错误等。比如 OutOfMemoryError内存不足错误StackOverflowError栈溢出错误。此类错误发生时JVM 将终止线程。
这些错误是不受检异常非代码性错误。因此当此类错误发生时应用程序不应该去处理此类错误。按照Java惯例我们是不应该实现任何新的Error子类的
3. Exception异常
程序本身可以捕获并且可以处理的异常。Exception 这种异常又分为两类运行时异常和编译时受查异常。
运行时异常
定义RuntimeException 类及其子类表示 JVM 在运行期间可能出现的异常。
特点Java 编译器不会检查它。也就是说当程序中可能出现这类异常时倘若既"没有通过throws声明抛出它"也"没有用try-catch语句捕获它"还是会编译通过。比如NullPointerException空指针异常、ArrayIndexOutBoundException数组下标越界异常、ClassCastException类型转换异常、ArithmeticExecption算术异常。此类异常属于不受检异常一般是由程序逻辑错误引起的在程序中可以选择捕获处理也可以不处理。虽然 Java 编译器不会检查运行时异常但是我们也可以通过 throws 进行声明抛出也可以通过 try-catch 对它进行捕获处理。如果产生运行时异常则需要通过修改代码来进行避免。例如若会发生除数为零的情况则需要通过代码避免该情况的发生
RuntimeException 异常会由 Java 虚拟机自动抛出并自动捕获就算我们没写异常捕获语句运行时也会抛出错误此类异常的出现绝大数情况是代码本身有问题应该从逻辑上去解决并改进代码。
编译时异常
定义: Exception 中除 RuntimeException 及其子类之外的异常。
特点: Java 编译器会检查它。如果程序中出现此类异常比如 ClassNotFoundException没有找到指定的类异常IOExceptionIO流异常要么通过throws进行声明抛出要么通过try-catch进行捕获处理否则不能通过编译。在程序中通常不会自定义该类异常而是直接使用系统提供的异常类。该异常我们必须手动在代码里添加捕获语句来处理该异常。
4. 受检异常与非受检异常
Java 的所有异常可以分为受检异常checked exception和非受检异常unchecked exception。
受检异常
==编译器要求必须处理的异常。==正确的程序在运行过程中经常容易出现的、符合预期的异常情况。一旦发生此类异常就必须采用某种方式进行处理。除 RuntimeException 及其子类外其他的 Exception 异常都属于受检异常。编译器会检查此类异常也就是说当编译器检查到应用中的某处可能会此类异常时将会提示你处理本异常——要么使用try-catch捕获要么使用方法签名中用 throws 关键字抛出否则编译不通过。
非受检异常
编译器不会进行检查并且不要求必须处理的异常也就说当程序中出现此类异常时即使我们没有try-catch捕获它也没有使用throws抛出该异常编译也会正常通过。该类异常包括运行时异常RuntimeException及其子类和错误Error。
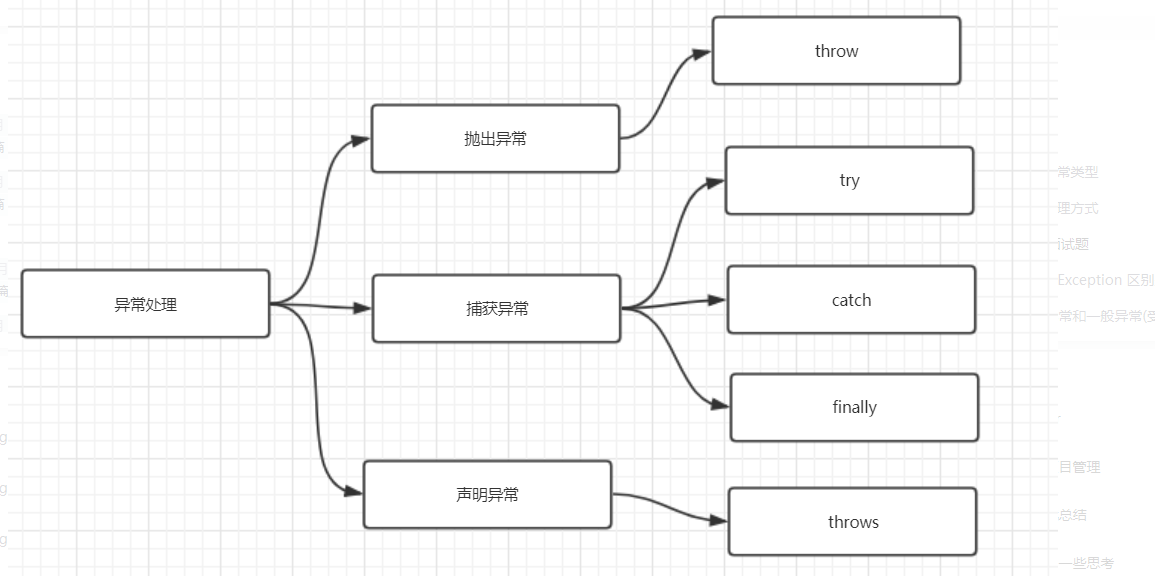
声明异常
通常应该捕获那些知道如何处理的异常将不知道如何处理的异常继续传递下去。传递异常可以在方法签名处使用 throws 关键字声明可能会抛出的异常。
注意
- 非检查异常Error、RuntimeException 或它们的子类不可使用 throws 关键字来声明要抛出的异常。
- 一个方法出现编译时异常就需要 try-catch/ throws 处理否则会导致编译错误。
抛出异常
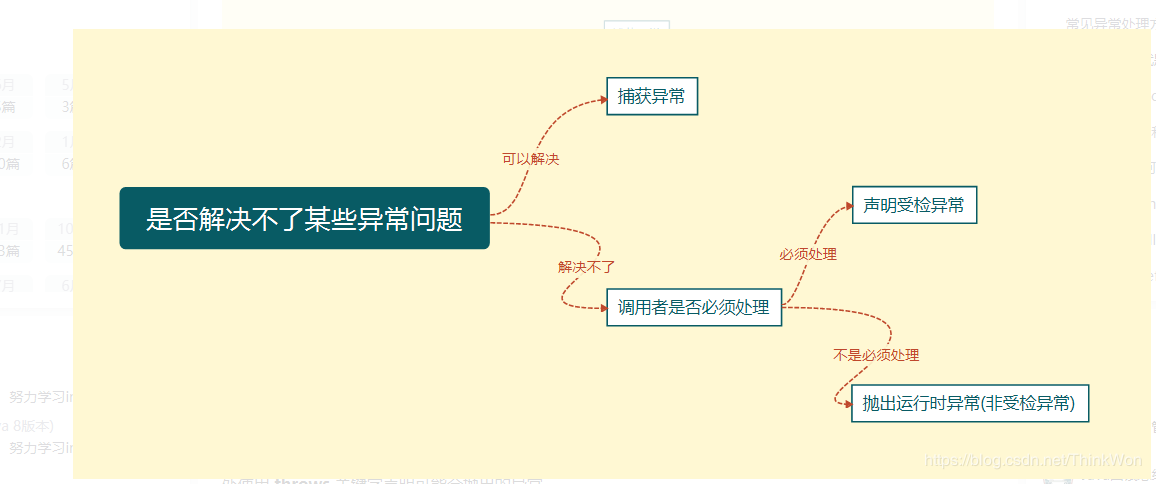
如果你觉得解决不了某些异常问题且不需要调用者处理那么你可以抛出异常。
throw关键字作用是在方法内部抛出一个Throwable类型的异常。任何Java代码都可以通过throw语句抛出异常。
自定义异常
习惯上定义一个异常类应包含两个构造函数
一个无参构造函数和一个带有详细描述信息的构造函数Throwable 的 toString 方法会打印这些详细信息调试时很有用
public class MyException extends Exception {
public MyException(){ }
public MyException(String msg){
super(msg);
}
// ...
}
若 finally 中也包含 return 语句finally 中的 return 会覆盖前面的 return.
Java异常常见面试题
异常和错误的区别
Exception
1.可以是可被控制也有不可控制
2.表示一个由程序员导致的错误
3.应该在应用程序级被处理
Erroregjava虚拟机运行错误Virtual MachineError当 JVM 不再有继续执行操作所需的内存资源时将出现 OutOfMemoryError。
1.总是不可控制的
2.经常用来表示系统错误或者底层资源错误
3.如果可能的话应该在系统级被捕捉
补充可控异常NoSuchFieldExceptionIOException编译时就可发现需要try-catch或把异常交给上级方法处理总之需要提前处理
运行时异常例如除数为0不能被编译器检测到
Error 类型的错误通常为虚拟机相关错误如系统崩溃内存不足堆栈溢出等编译器不会对这类错误进行检测JAVA 应用程序也不应对这类错误进行捕获一旦这类错误发生通常应用程序会被终止仅靠应用程序本身无法恢复
Exception 类的错误是可以在应用程序中进行捕获并处理的通常遇到这种错误应对其进行处理使应用程序可以继续正常运行。
2. 运行时异常和一般异常(受检异常)区别是什么
运行时异常包括 RuntimeException 类及其子类表示 JVM 在运行期间可能出现的异常。 Java 编译器不会检查运行时异常。
受检异常是Exception 中除 RuntimeException 及其子类之外的异常。 Java 编译器会检查受检异常。
RuntimeException异常和受检异常之间的区别是否强制要求调用者必须处理此异常如果强制要求调用者必须进行处理那么就使用受检异常否则就选择非受检异常(RuntimeException)。一般来讲如果没有特殊的要求我们建议使用RuntimeException异常。
JVM 是如何处理异常的
在一个方法中如果发生异常这个方法会创建一个异常对象并转交给 JVM该异常对象包含异常名称异常描述以及异常发生时应用程序的状态。创建异常对象并转交给 JVM 的过程称为抛出异常。可能有一系列的方法调用最终才进入抛出异常的方法这一系列方法调用的有序列表叫做调用栈。
JVM 会顺着调用栈去查找看是否有可以处理异常的代码如果有则调用异常处理代码。当 JVM 发现可以处理异常的代码时会把发生的异常传递给它。如果 JVM 没有找到可以处理该异常的代码块JVM 就会将该异常转交给默认的异常处理器默认处理器为 JVM 的一部分默认异常处理器打印出异常信息并终止应用程序。
throw 和 throws 的区别是什么
Java 中的异常处理除了包括捕获异常和处理异常之外还包括声明异常和拋出异常可以通过 throws 关键字在方法上声明该方法要拋出的异常或者在方法内部通过 throw 拋出异常对象。
throws 关键字和 throw 关键字在使用上的几点区别如下
- throw 关键字用在方法内部只能用于抛出一种异常用来抛出方法或代码块中的异常受查异常和非受查异常都可以被抛出。
- throws 关键字用在方法声明上可以抛出多个异常用来标识该方法可能抛出的异常列表。一个方法用 throws 标识了可能抛出的异常列表调用该方法的方法中必须包含可处理异常的代码否则也要在方法签名中用 throws 关键字声明相应的异常。
NoClassDefFoundError 和 ClassNotFoundException 区别
NoClassDefFoundError 是一个 Error 类型的异常是由 JVM 引起的不应该尝试捕获这个异常。
引起该异常的原因是 JVM 或 ClassLoader 尝试加载某类时在内存中找不到该类的定义该动作发生在运行期间即编译时该类存在但是在运行时却找不到了可能是变异后被删除了等原因导致
ClassNotFoundException 是一个受查异常需要显式地使用 try-catch 对其进行捕获和处理或在方法签名中用 throws 关键字进行声明。当使用 Class.forName, ClassLoader.loadClass 或 ClassLoader.findSystemClass 动态加载类到内存的时候通过传入的类路径参数没有找到该类就会抛出该异常另一种抛出该异常的可能原因是某个类已经由一个类加载器加载至内存中另一个加载器又尝试去加载它。
try-catch-finally 中哪个部分可以省略
答catch 可以省略
原因
更为严格的说法其实是**try只适合处理运行时异常try+catch适合处理运行时异常+普通异常。**也就是说如果你只用try去处理普通异常却不加以catch处理编译是通不过的因为编译器硬性规定普通异常如果选择捕获则必须用catch显示声明以便进一步处理。而运行时异常在编译时没有如此规定所以catch可以省略你加上catch编译器也觉得无可厚非。
理论上编译器看任何代码都不顺眼都觉得可能有潜在的问题所以你即使对所有代码加上try代码在运行期时也只不过是在正常运行的基础上加一层皮。但是你一旦对一段代码加上try就等于显示地承诺编译器对这段代码可能抛出的异常进行捕获而非向上抛出处理。如果是普通异常编译器要求必须用catch捕获以便进一步处理如果运行时异常捕获然后丢弃并且+finally扫尾处理或者加上catch捕获以便进一步处理。
至于加上finally则是在不管有没捕获异常都要进行的“扫尾”处理。
常见的 RuntimeException 有哪些
- ClassCastException(类转换异常)
- IndexOutOfBoundsException(数组越界)
- NullPointerException(空指针)
- ArrayStoreException(数据存储异常操作数组时类型不一致)
- 还有IO操作的BufferOverflowException异常
Java常见异常有哪些
java.lang.IllegalAccessError违法访问错误。当一个应用试图访问、修改某个类的域Field或者调用其方法但是又违反域或方法的可见性声明则抛出该异常。
java.lang.InstantiationError实例化错误。当一个应用试图通过Java的new操作符构造一个抽象类或者接口时抛出该异常.
java.lang.OutOfMemoryError内存不足错误。当可用内存不足以让Java虚拟机分配给一个对象时抛出该错误。
java.lang.StackOverflowError堆栈溢出错误。当一个应用递归调用的层次太深而导致堆栈溢出或者陷入死循环时抛出该错误。
java.lang.ClassCastException类造型异常。假设有类A和BA不是B的父类或子类O是A的实例那么当强制将O构造为类B的实例时抛出该异常。该异常经常被称为强制类型转换异常。
java.lang.ClassNotFoundException找不到类异常。当应用试图根据字符串形式的类名构造类而在遍历CLASSPAH之后找不到对应名称的class文件时抛出该异常。
java.lang.ArithmeticException算术条件异常。譬如整数除零等。
java.lang.ArrayIndexOutOfBoundsException数组索引越界异常。当对数组的索引值为负数或大于等于数组大小时抛出。
java.lang.IndexOutOfBoundsException索引越界异常。当访问某个序列的索引值小于0或大于等于序列大小时抛出该异常。
java.lang.InstantiationException实例化异常。当试图通过newInstance()方法创建某个类的实例而该类是一个抽象类或接口时抛出该异常。
java.lang.NoSuchFieldException属性不存在异常。当访问某个类的不存在的属性时抛出该异常。
java.lang.NoSuchMethodException方法不存在异常。当访问某个类的不存在的方法时抛出该异常。
java.lang.NullPointerException空指针异常。当应用试图在要求使用对象的地方使用了null时抛出该异常。譬如调用null对象的实例方法、访问null对象的属性、计算null对象的长度、使用throw语句抛出null等等。
java.lang.NumberFormatException数字格式异常。当试图将一个String转换为指定的数字类型而该字符串确不满足数字类型要求的格式时抛出该异常。
java.lang.StringIndexOutOfBoundsException字符串索引越界异常。当使用索引值访问某个字符串中的字符而该索引值小于0或大于等于序列大小时抛出该异常。
String、StringBuffer、StringBuilder的区别
原文链接https://blog.csdn.net/jin970505/article/details/79647406
6.String str = new String(“abc”)创建了多少个对象
这个问题在很多书籍上都有说到比如《Java程序员面试宝典》包括很多国内大公司笔试面试题都会遇到大部分网上流传的以及一些面试书籍上都说是2个对象这种说法是片面的。
如果有不懂得地方可以参考这篇帖子
http://rednaxelafx.iteye.com/blog/774673/
首先必须弄清楚创建对象的含义创建是什么时候创建的这段代码在运行期间会创建2个对象么毫无疑问不可能用javap -c反编译即可得到JVM执行的字节码内容
很显然new只调用了一次也就是说只创建了一个对象。
而这道题目让人混淆的地方就是这里这段代码在运行期间确实只创建了一个对象即在堆上创建了”abc”对象。而为什么大家都在说是2个对象呢这里面要澄清一个概念 该段代码执行过程和类的加载过程是有区别的。在类加载的过程中确实在运行时常量池中创建了一个”abc”对象而在代码执行过程中确实只创建了一个String对象。
因此这个问题如果换成 String str = new String(“abc”)涉及到几个String对象合理的解释是2个。
个人觉得在面试的时候如果遇到这个问题可以向面试官询问清楚”是这段代码执行过程中创建了多少个对象还是涉及到多少个对象“再根据具体的来进行回答。
String是不可变长度的StringBuffer和StringBuilder是可变长度的但StringBuffer是线程安全的StringBuilder是线程不安全但执行比StringBuffe快
一、Java String 类——String字符串常量
字符串广泛应用 在Java 编程中在 Java 中字符串属于对****象Java 提供了 String 类来创建和操作字符串。
需要注意的是String的值是不可变的这就导致每次对String的操作都会生成新的String对象这样不仅效率低下而且大量浪费有限的内存空间。我们来看一下这张对String操作时内存变化的图

二、Java StringBuffer 和 StringBuilder 类——StringBuffer字符串变量、StringBuilder字符串变量

当对字符串进行修改的时候需要使用 StringBuffer 和 StringBuilder 类。
和 String 类不同的是StringBuffer 和 StringBuilder 类的对象能够被多次的修改并且==不产生新的未使用对象。==
StringBuffer 类在 Java 5 中被提出它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的不能同步访问。
由于 StringBuilder 相较于 StringBuffer 有速度优势所以多数情况下建议使用 StringBuilder 类。然而在应用程序要求线程安全的情况下则必须使用 StringBuffer 类。
三者的继承结构
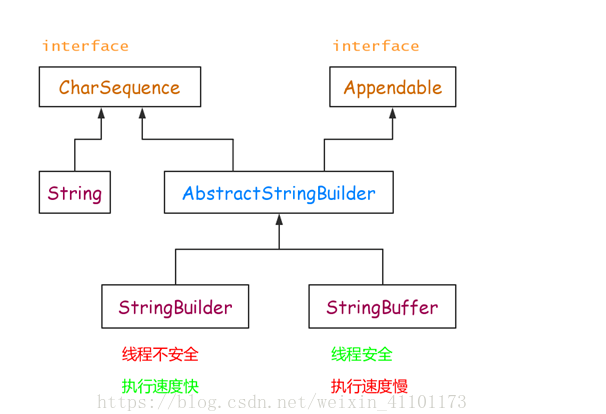
三者的区别

1字符修改上的区别主要见上面分析
2初始化上的区别String可以空赋值后者不行报错
①String
String s = null;
String s = “abc”;
②StringBuffer
StringBuffer s = null; //结果警告Null pointer access: The variable result can only be null at this location
StringBuffer s = new StringBuffer();//StringBuffer对象是一个空的对象
StringBuffer s = new StringBuffer(“abc”);//创建带有内容的StringBuffer对象,对象的内容就是字符串”
如果要操作少量的数据用 String
2多线程操作字符串缓冲区下操作大量数据 StringBuffer
3单线程操作字符串缓冲区下操作大量数据 StringBuilder。
String的equals
第一步
判断两个String地址是否相同相同则返回true
第二步
依次进行三个判断有一个不符合就false
判断要比较的字符串equals的方法参数是否为字符串
比较两个字符串长度不相等返回false
则依次比较两个字符串中的字符若有一个不相等就返回false
String的常用方法
1、int length(); 语法字符串变量名.length(); 返回值为 int 类型。得到一个字符串的字符个数中、英、空格、转义字符皆为字符计入长度
2、char charAt(值); 语法 字符串名.charAt(值); 返回值为 char 类型。从字符串中取出指定位置的字符
3、char toCharArray(); 语法 字符串名.toCharArray(); 返回值为 char 数组类型。将字符串变成一个字符数组
4、int indexOf(“字符”) 语法 字符串名.indexOf(“字符”)字符串名.indexOf(“字符”,值)查找一个指定的字符串是否存在返回的是字符串的位置如果不存在则返回-1 。
5、 in lastIndexOf(“字符”) 得到指定内容最后一次出现的下标
6、toUpperCase() toLowerCase()字符串大小写的转换
7、String[] split(“字符”) 根据给定的正则表达式的匹配来拆分此字符串。形成一个新的String数组。
8、boolean equals(Object anObject) 语法 字符串变量名.wquals(字符串变量名); 返回值为布尔类型。所以这里用 if 演示。比较两个字符串是否相等返回布尔值
9、trim(); 去掉字符串左右空格
10、String substring(int beginIndex,int endIndex) 截取字符串 不包括最后endIndex
11、boolean equalsIgnoreCase(String) 忽略大小写的比较两个字符串的值是否一模一样返回一个布尔值
12、boolean contains(String) 判断一个字符串里面是否包含指定的内容返回一个布尔值
13、boolean startsWith(String) 测试此字符串是否以指定的前缀开始。返回一个布尔值
14、boolean endsWith(String) 测试此字符串是否以指定的后缀结束。返回一个布尔值
15、String replaceAll(String,String) 将某个内容全部替换成指定内容
16、String repalceFirst(String,String) 将第一次出现的某个内容替换成指定的内容
17、**replace(char oldChar,char newChar);**新字符替换旧字符也可以达到去空格的效果一种。
如何反转字符串
①利用 StringBuffer 或 StringBuilder 的 reverse 成员方法:
public static void main(String[] args) {
String s = "abc123";
String reverse =new StringBuilder(s).reverse().toString();
System.out.println(reverse);
}
②利用 String 的 toCharArray 方法先将字符串转化为 char 类型数组然后将各个字符进行重新拼接:
public static void main(String[] args) {
String s = "abc123";
char[] chars = s.toCharArray();
String reverse = "";
for (int i = chars.length - 1; i >= 0; i--) {
reverse += chars[i];
}
System.out.println(reverse);
}
③利用 String 的 CharAt 方法取出字符串中的各个字符:
public static void main(String[] args) {
String s = "abc123";
String reverse = "";
int length = s.length();
for (int i = 0; i < length; i++) {
reverse = s.charAt(i) + reverse;
}
System.out.println(reverse);
}
计算一个字符串中每一个字符出现的次数
分析
1.使用Scanner获取用户输入的字符串
2.创建Map集合key是字符串中的字符value是字符的个数
3.遍历字符串获取每一个字符
4.使用获取到的字符去Map集合判断key是否存在
public class CaiNiao{
public static void main(String[] args){
//1.使用Scanner获取用户输入的字符串
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个字符串");
String str = sc.next();
//2.创建Map集合key是字符串中的字符value是字符的个数
HashMap<Character.Integer> map = new HashMap<>();
//3.遍历字符串获取每一个字符
for(char c : str.toCharArray()){
//4.使用获取到的字符去Map集合判断key是否存在
if(map.containsKey(c)){
//key存在
Integer value = map.get(c);
value++;
map.put(c,value);
}else{
//key不存在
map.put(c,1);
}
}
//5.遍历Map集合输出结果
for(Character key : map.keySet(){
Integer value = map.get(key);
System.out.println(key+"="+value);
}
}
}
实例化对象的方式
1.使用new关键字
2.使用Class类的newInstance方法
3.使用Constructor类的newInstance方法
4.使用clone方法
5.使用反序列化
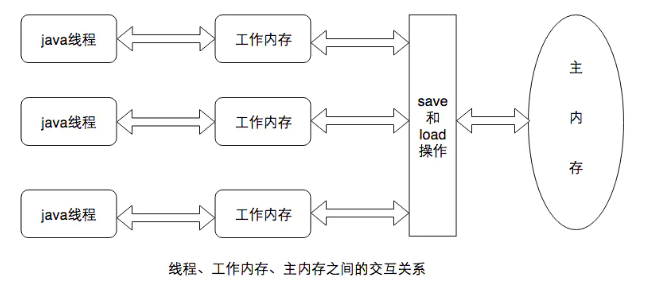
Java的内存模型
虽然java程序所有的运行都是在虚拟机中涉及到的内存等信息都是虚拟机的一部分但实际也是物理机的只不过是虚拟机作为最外层的容器统一做了处理。虚拟机的内存模型以及多线程的场景下与物理机的情况是很相似的可以类比参考。
Java内存模型的主要目标是定义程序中变量的访问规则。即在虚拟机中将变量存储到主内存或者将变量从主内存取出这样的底层细节。需要注意的是这里的变量跟我们写java程序中的变量不是完全等同的。这里的变量是指实例字段静态字段构成数组对象的元素但是不包括局部变量和方法参数(因为这是线程私有的)。这里可以简单的认为主内存是java虚拟机内存区域中的堆局部变量和方法参数是在虚拟机栈中定义的。但是在堆中的变量如果在多线程中都使用就涉及到了堆和不同虚拟机栈中变量的值的一致性问题了。
Java内存模型中涉及到的概念有
- 主内存java虚拟机规定所有的变量(不是程序中的变量)都必须在主内存中产生为了方便理解可以认为是堆区。可以与前面说的物理机的主内存相比只不过物理机的主内存是整个机器的内存而虚拟机的主内存是虚拟机内存中的一部分。
- 工作内存java虚拟机中每个线程都有自己的工作内存该内存是线程私有的为了方便理解可以认为是虚拟机栈。可以与前面说的高速缓存相比。线程的工作内存保存了线程需要的变量在主内存中的副本。虚拟机规定线程对主内存变量的修改必须在线程的工作内存中进行不能直接读写主内存中的变量。不同的线程之间也不能相互访问对方的工作内存。如果线程之间需要传递变量的值必须通过主内存来作为中介进行传递。
*这里需要说明一下主内存、工作内存与java内存区域中的java堆、虚拟机栈、方法区并不是一个层次的内存划分。这两者是基本上是没有关系的上文只是为了便于理解做的类比*
Java常见的IO
什么是内部类内部类的种类内部类的作用
一、什么是内部类
定义 将一个类定义在一个类或者一个方法里面这样的类称着内部类
二、内部类的种类
内部类的种类有4种
1、成员内部类
成员内部类是最普通的一种内部类成员内部类可以访问外部类所有的属性和方法。但是外部类要访问成员内部类的属性和方法必须要先实例化成员内部类。
注意 成员内部类里面不能包含静态的属性和方法
public class OutClass {
public void test1() {
}
private void test2() {
}
private static void test3() {
}
class InnerClass {//成员内部类
private String testStrInner = "";
private void testInner() {
test1();
test2();
test3();//成员内部类可以访问外部类所有的属性和方法。静态方法直接访问。
}
}
}

2、静态内部类
静态内部类就是在成员内部类多加了一个 static 关键字。静态内部类只能访问外部类的静态成员变量和方法包括私有静态
public class OutClass {
private static String s = "";
public void test1() {
}
private void test2() {
}
private static void test3() {
}
static class InnerClass {//静态内部类
private static String testStrInner = "";
private static void testInner() {
test3();
String ss = s;
}
}
}
3、匿名内部类
匿名内部类顾名思义就是没有名字的类。什么时候用到匿名内部类呢在Android中最常见得回调监听事件 就是匿名内部类
一般遇到下面这种情况都会考虑到使用匿名内部类
当一个内部类需要继承或者实现而且只使用一次的时候可以考虑使用匿名内部类。调用的时候直接使用父类的无参构造并重写父类方法。如下代码
//父类 Animal
public class Animal {
public void bellow() {//动物吼叫的类型
System.out.println("动物吼叫");
}
}
如果现在只是需要一个 狗Dog的吼叫类型。一般我们会写一个Dog类继承Animal 然后重写
bellow()方法最后实例化Dog类调用bellow()方法。但是此时我们可以使用内部类因为只用一次没有其他地方调用没必要再去写一个class类。代码如下
class Demo {
public static void main(String[] args) {
Demo demo = new Demo();
demo.getDogBellow(new Animal(){//匿名内部类重写父类方法。当然接口也是一样
@Override
public void bellow() {
System.out.println("狗 汪汪汪。。。。");
}
});
}
public void getDogBellow(Animal animal){
animal.bellow();
}
}
4、局部内部类
局部内部类就是定义在代码块内的一个内部类。比如在方法里面定义一个内部类就是局部内部类。
局部内部类的作用范围仅仅就在它所在的代码块里。局部内部类不能被public protectedprivate以及static修饰但是可以被final修饰。
public class Animal {
public static void bellow() {
String bellowStr = "动物吼叫";
System.out.println(bellowStr);
final class Dog {//局部内部类
String dogBellowStr = bellowStr + "狗 汪汪汪";
public void dogBellow() {
System.out.println(dogBellowStr);
}
}
}
}
三、内部类的作用
- 1、内部类可以很好的实现隐藏。
非内部类是不可以使用 private和 protected修饰的但是内部类却可以从而达到隐藏的作用。同时也可以将一定逻辑关系的类组织在一起增强可读性。 - 2、间接的实现多继承。
每个内部类都能独立地继承自一个(接口的)实现所以无论外部类是否已经继承了某个(接口的)实现对于内部类都没有影响。如果没有内部类提供的可以继承多个具体的或抽象的类的能力一些设计与编程问题就很难解决。所以说内部类间接的实现了多继承。
泛型
https://segmentfault.com/a/1190000014120746
cookie 和 session
4.cookie的简介
会话是由一组请求与响应组成是围绕着一件相关的事情所进行的请求与响应。所以这些请求与响应之间一定是需要有数据传递的即是需要进行会话状态跟踪的。然而HTTP协议是一种无状态协议在不同的请求间是无法进行数据传递的。此时就需要一种可以进行请求间数据传递的会话跟踪技术。而cookie就是一种这样的技术。
Cookie是由服务器生成保存在客户端的一种信息载体。这个载体中存放着用户访问该站点的会话状态信息。只要Cookie没有被清空或都Cookie没有失效那么保存在其中的会话状态就有效。
用户在提交第一次请求后由服务器生成Cookie并将其封装到响应头中以响应头的形式发送给客户端。客户端接收到这个响应后将Cookie保存到客户端。当客户端再次发送同类请求(资源路径相同的请求)后在请求中会携带保存在客户端的Cookie数据发送到服务器由服务器对会话进行跟踪。
5.不同的浏览器其Cookie的保存位置及查看方式是不同的。因此删除了某一浏览器下的Cookie,不会影响到其他浏览器中的Cookie
在火狐
6.Cookie相当于键值对有name和Cookie
7.Cookie存在于浏览器的缓存中
8.设置Cookie的有效期。这个值为一个整型值单位为秒。
该值大于0表示将Cookie存放到客户端的硬盘
该值小于0与不设置效果相同会将Cookie存放到浏览器的缓存
该值等于0表示Cookie一生成马上失效
9.Cookie的禁用
浏览器是可以禁用Cookie的。所谓禁用Cookie是指客户端浏览器不接收服务器发送来的Cookie。不过现在的很多网站若浏览器禁用了Cookie则将无法使用
Session
1.session的定义
Session即会话是web开发中的一种会话状态跟踪技术。但是Cookie 也是一种会话跟踪技术。不同的是Cookie是将会话状态保存在了客户端而session则是将会话状态保存在了服务器端。
2.会话当用户打开浏览器从发出第一次请求开始一直到最终关闭浏览器就表示第一次会话的完成
3.Session并不是JavaWeb开发所特有的而是整个Web开发中所实用的技术。在JavaWeb开发中Session是以javax.servlet.http.HttpSession的接口对象的形式出出现的
4.request.getSession():如果当前请求有Session就返回当前的Session,如果
当前的请求没有Session,就创建一个Session
5.request域在同一请求下可以接受数据传递。如果跨的是两个Servlet ,一个Servlet到另一个Servlet是通过请求转发过来的。在一个Servlet的request域中放入属性值在另一个Servlet中就能读取到。Session是跨请求的只要是在同一次会话里面在一个请求里面放入Session属性,在另一个请求里面也能获取到可以实现跨请求的数据传递。
public void setAttribute(String name,Object value)
该方法用于向Session的域属性空间中存入指定名称指定值的域属性
•public Object getAttribute(String name)
该方法用于从Session的域属性空间中读取指定名称为域属性值
•public void removeAttribute(String name)
该方法用于从Session的域属性空间中删除指定名称的域属性
\6. 通过地址栏访问使用doGet()就是在地址中直接改变Servlet的url
7.对于request的getSession()的用法
一般情况下若要向Session中写入数据则需使用getSession(true),即getSession()方法。意义是有旧的Session就用旧的Session,没有旧的Session就创建一个新的Session
若要从Session中读取数据则需要使用getSession(false),意义是;有旧的Session就使用旧的Session,没有旧的就返回null。因为要读取数据只有旧的Session中才有可能存在你要查找的数据。
8.Session的工作原理面试
在服务器中系统会为每个会话维护一个Session(创建一个Session对象)。不同的会话对应不同的Session.
1Session列表
服务器对当前应用中的Session是以Map的形式进行管理的这个Map称为Session列表。该Map的key为一个32位长度的随机串这个随机串称为JSessionID,value则为Session对象的引用。
当用户第一次提交请求的时候服务端Servlet中执行到request.getSession()方法后会自动生成一个Map.Entry键值对对象key为一个根据某种算法新生成的JSessionID,value为新创建的HttpSession对象。

2服务器生成并发送Cookie
在将Session写入Session列表中系统还会自动将“JSESSIONID”作为name,这个32位长度的随机串作为value,以Cookie的形式存放到响应报头中并随着响应将该Cookie发送到客户端
3客户端接收到这个Cookie后将其存放到浏览器的缓存中。即只要客户端浏览器不关闭浏览器缓存中的Cookie就不会消失。
当用户提交第二次请求时会将缓存中的这个Cookie伴随着请求的头部信息一块发送到服务端。
(4)从Session列表中查找
服务端从请求中读取到客户端发送来的Cookie并根据Cookie的JSsessionid的值从Map中查找响应key所对应的value,即session对象。然后对该Session对象的域属性进行读写操作
总结;当发出第一次请求的时候服务器会生成一个32位的随机串再创建一个Session对象 ,然后往Session列表中中放属性再把32位的随机串包装成一个Cookie发送给客户端浏览器此Cookie的name叫做JSessionID,value就是这个32位长度的随机字符串客户端再把这个Cookie存放到浏览器缓存然后客户端又发出一次请求把 JSessionID放到请求的头部信息中发送给服务器。服务器接受到Cookie以后会拿到JSessionID的值即32位长度的串服务器接收到这个串之后从Session列表中寻找找到key就是找到key所对应的value,即存放域属性的Session
9.Session的失效
web开发中引入的Session超时的概念Session的失效就是指Session的超时。若某个Session在指定的时间范围内一直未被访问那么Session将超时即将失效。
在web.xml中可以通过标签设置Session的超时时间单位为分钟。默认Session的超时时间为30分钟。需要再次强调的是这个时间并不是从Session被创建开始计时的生命周期时长而是从最后一次被访问开始计时在指定的时长内一直未被访问的时长。
若未到超时时限也可以通过代码提前使Session失效。
HttpSession中的方法Invalide()使得Session失效
httpSession.invalidate()使Session失效解绑所有绑定在Session上面的对象
10.浏览器据I化的结束就是Session的失效
11.超链接的URL重写
12.用户登录之后都会把用户登录的信息保存在Session域中。所以要检查用户是否登陆可以判断Session中是否包含有用户登录的信息
13.使用Filter拦截器要在web工程下有一个admin
ClassLoader的重要方法
https://blog.csdn.net/qq1003400592/article/details/80808232
java异常
https://blog.csdn.net/dnxyhwx/article/details/6975087?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.control
Java基础之—反射非常重要
https://blog.csdn.net/sinat_38259539/article/details/71799078
爬虫IP被封的6个解决办法
https://blog.csdn.net/myli_binbin/article/details/99694563
深入 java debug 原理及远程remote调试详解
https://blog.csdn.net/ywlmsm1224811/article/details/98611454?utm_medium=distribute.pc_relevant_bbs_down.none-task–2allfirst_rank_v2rank_v29-1.nonecase&depth_1-utm_source=distribute.pc_relevant_bbs_down.none-task–2allfirst_rank_v2rank_v29-1.nonecase
当我们在 idea 或者 eclipse 中以 debug 模式启动运行类就可以直接调试了这其中的原理令人不解下面就给大家介绍一下
客户端idea 、eclipse 等之所以可以进行调试是由于客户端 和 服务端程序端进行了 socket 通信通信过程如下
1、先建立起了 socket 连接
2、将断点位置创建了断点事件通过 JDI 接口传给了 服务端程序端的 VMVM 调用 suspend 将 VM 挂起
3、VM 挂起之后将客户端需要获取的 VM 信息返回给客户端返回之后 VM resume 恢复其运行状态
4、客户端获取到 VM 返回的信息之后可以通过不同的方式展示给客户
Java编程String 类中 hashCode() 方法详解
https://zhibo.blog.csdn.net/article/details/53770830?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
成员变量和局部变量的区别(理解)
String中的hashCode方法
https://blog.csdn.net/u012501054/article/details/88863045
那为什么这里用31而不是其它数呢?《Effective Java》是这样说的之所以选择31是因为它是个奇素数如果乘数是偶数并且乘法溢出的话信息就会丢失因为与2相乘等价于移位运算。使用素数的好处并不是很明显但是习惯上都使用素数来计算散列结果。31有个很好的特性就是用移位和减法来代替乘法可以得到更好的性能31*i==(i<<5)-i。现在的JVM可以自动完成这种优化。
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
IDEA打包可执行jar
https://cloud.tencent.com/developer/article/1764737
模拟实战排查堆内存溢出java.lang.OutOfMemoryError: Java heap space问题
JAVA注解
> 面试问的不多但是在使用框架开发时会经常使用但东西太多了这里只是简单介绍下概念。
Annotation注解可以看成是java中的一种标记记号用来给java中的类成员方法参数等任何程序元素添加一些额外的说明信息同时不改变程序语义。注解可以分为三类基本注解元注解自定义注解
- 标准注解
- @Deprecated该注解用来说明程序中的某个元素类方法成员变量等已经不再使用如果使用的话的编译器会给出警告。
- @SuppressWarnings(value=“”)用来抑制各种可能出现的警告。
- @Override用来说明子类方法覆盖了父类的方法保护覆盖方法的正确使用
- 元注解元注解也称为元数据注解是对注解进行标注的注解元注解更像是一种对注解的规范说明用来对定义的注解进行行为的限定。例如说明注解的生存周期注解的作用范围等
- @Target(value=“ ”)该注解是用来限制注解的使用范围的即该注解可以用于哪些程序元素。
- @Retention(value=“ ”)用于说明注解的生存周期
- @Documnent用来说明指定被修饰的注解可以被javadoc.exe工具提取进入文档中所有使用了该注解进行标注的类在生成API文档时都在包含该注解的说明。
- @Inherited用来说明使用了该注解的父类其子类会自动继承该注解。
- @Repeatablejava1.8新出的元注解如果需要在给程序元素使用相同类型的注解则需将该注解标注上。
- 自定义注解用@Interface来声明注解。
网络攻击
01SSRF概念 SSRF为服务端请求伪造(Server-Side Request Forgery),指的是攻击者在未能取得服务器所有权限时。
利用服务器漏洞以服务器的身份发送一条构造好的请求给服务器所在内网。SSRF攻击通常针对外部网络无法直接访问的内部系统。
02SSRF的原理
很多web应用都提供了从其他的服务器上获取数据的功能。使用指定的URLweb应用便可以获取图片下载文件读取文件内容等。SSRF的实质是利用存在缺陷的web应用作为代理攻击远程和本地的服务器。一般情况下 SSRF攻击的目标是外网无法访问的内部系统黑客可以利用SSRF漏洞获取内部系统的一些信息正是因为它是由服务端发起的所以它能够请求到与它相连而与外网隔离的内部系统。SSRF形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。
03SSRF的主要攻击方式
攻击者想要访问主机B上的服务但是由于存在***或者主机B是属于内网主机等原因导致攻击者无法直接访问主机B。而服务器A存在SSRF
漏洞这时攻击者可以借助服务器A来发起SSRF攻击通过服务器A向主机B发起请求从而获取主机B的一些信息。
csrf
跨站请求伪造英语Cross-site request forgery也被称为 one-click attack 或者 session riding通常缩写为 CSRF
或者 XSRF 是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。跟跨网站脚本XSS相比
XSS 利用的是用户对指定网站的信任CSRF 利用的是网站对用户网页浏览器的信任。
几种IO模型
https://cloud.tencent.com/developer/article/1684951