

Hadoop3教程(十一):MapReduce的详细工作流程-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
94MR工作流程
本小节将展示一下整个MapReduce的全工作流程。
Map阶段
首先是Map阶段
-
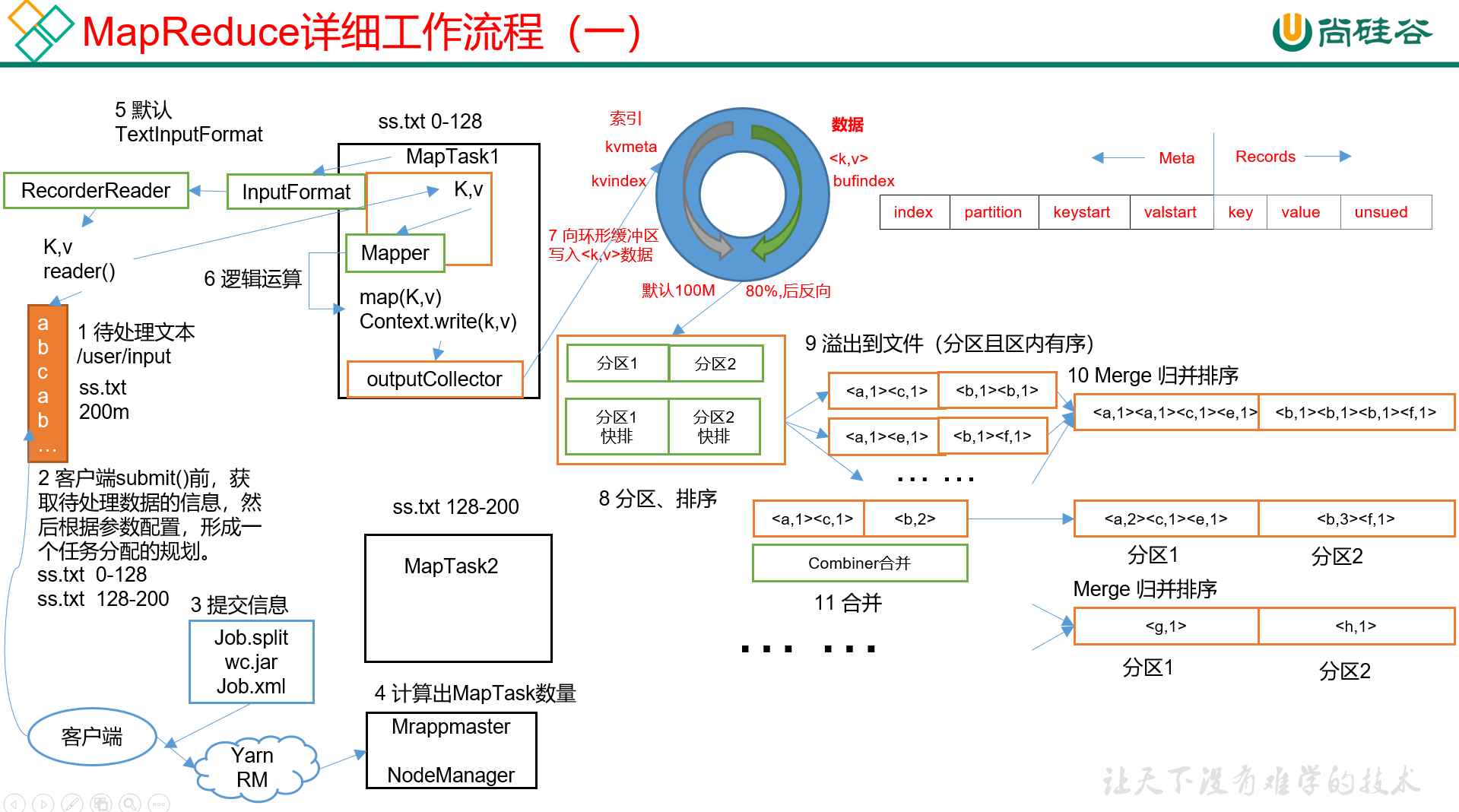
首先我们有一个待处理文本文件的集合
-
客户端开始切片规划
-
客户端提交各种信息如切片规划文件、代码文件及其他配置数据到yarn
-
yarn接收信息计算所需的MapTask数量按照切片数
-
MapTask启动读取输入文件默认使用的是TextInputFormat。输出KV对以TextInputFormat为例K是偏移量行在整个文件的字节数V是这一行的内容
-
TextInputFormat读取完毕后将得到的KV对都输入Mapper()做自定义业务逻辑处理核心处理部分
-
Mapper()处理完的数据放入outputCollector也被叫做环形缓冲区环形缓冲区是位于内存中的其实就是个缓冲数组里面每行数据是分左右两部分右边一部分是KV数据位存放的是输入进来的K值和V值左边一部分是对应的索引数据存放的信息有本行KV对的索引、本行KV对的分区、keystart以及valuestart这里的keystart和valuestart都是指数据在内存中的存储位置(keystart~valuestart)表示本行key值的存储起止位置而(valuestart~下一行数据的keystart)表示本行value值的存储起止位置其他行以此类推。
环形缓冲区默认大小是100M它有个有趣的机制用来协调写 + 磁盘持久化。当写满到80%的时候环形缓冲区会开始进行反向逆写操作。
什么是反向逆写呢
可以结合数组做简单理解就是假设数组有100个位置即索引位0~99当写到80%位置即从索引0开始到索引79写完了之后就开始反向逆写从索引99开始往前写依次是98/97这样子。
为什么要这么设置
很简单当写满到80%的时候系统会开启一个线程将这80%的数据持久化到磁盘但持久化的同时一般希望不会影响正常的写于是留了20%的空位置供正常的写操作。因此是持久化 + 写并行运行。
想象一下如果规定只有写满到100%之后才能持久化到磁盘或者说溢出到磁盘那么在它持久化的过程中整个写流程就必须暂停直到持久化完成后环形缓冲区清空后才能继续写这个时间消耗未免太长效率太低。这么看的话它这个80%后开始逆写的设置还挺棒的。
这里有个潜在的问题就是如果系统写的很快在没有持久化完那80%之前那20%的空位置就写满了这时候会发生什么情况
这时候写流程就不得不暂停直到持久化完成之后再恢复写。
-
注意上一步中持久化或者说溢写数据之前会先将数据分区不同分区的数据在Reduce阶段将会被送进不同的ReduceTask。然后分区内做排序一般使用快排。
那排序是针对什么来排呢
不是数据的KV而是数据的那几个索引。
-
将数据溢出至文件。注意单次溢写的数据虽然是写在一个文件里但是是分区且分区内有序的。
-
在数据溢出数次后我们就有了好几个文件接下来我们将这些文件merge做归并排序相当于是合并成一个文件然后将结果存储在磁盘。
-
做预聚合。比如说如果有两个
<a, 1>那可以直接合并成<a, 2>。当然这一步并不是必要的可以结合实际场景具体看是否需要。
到这里一个MapTask的工作就正式结束了其他的MapTask就是重复以上过程。
Reduce阶段
Reduce阶段
-
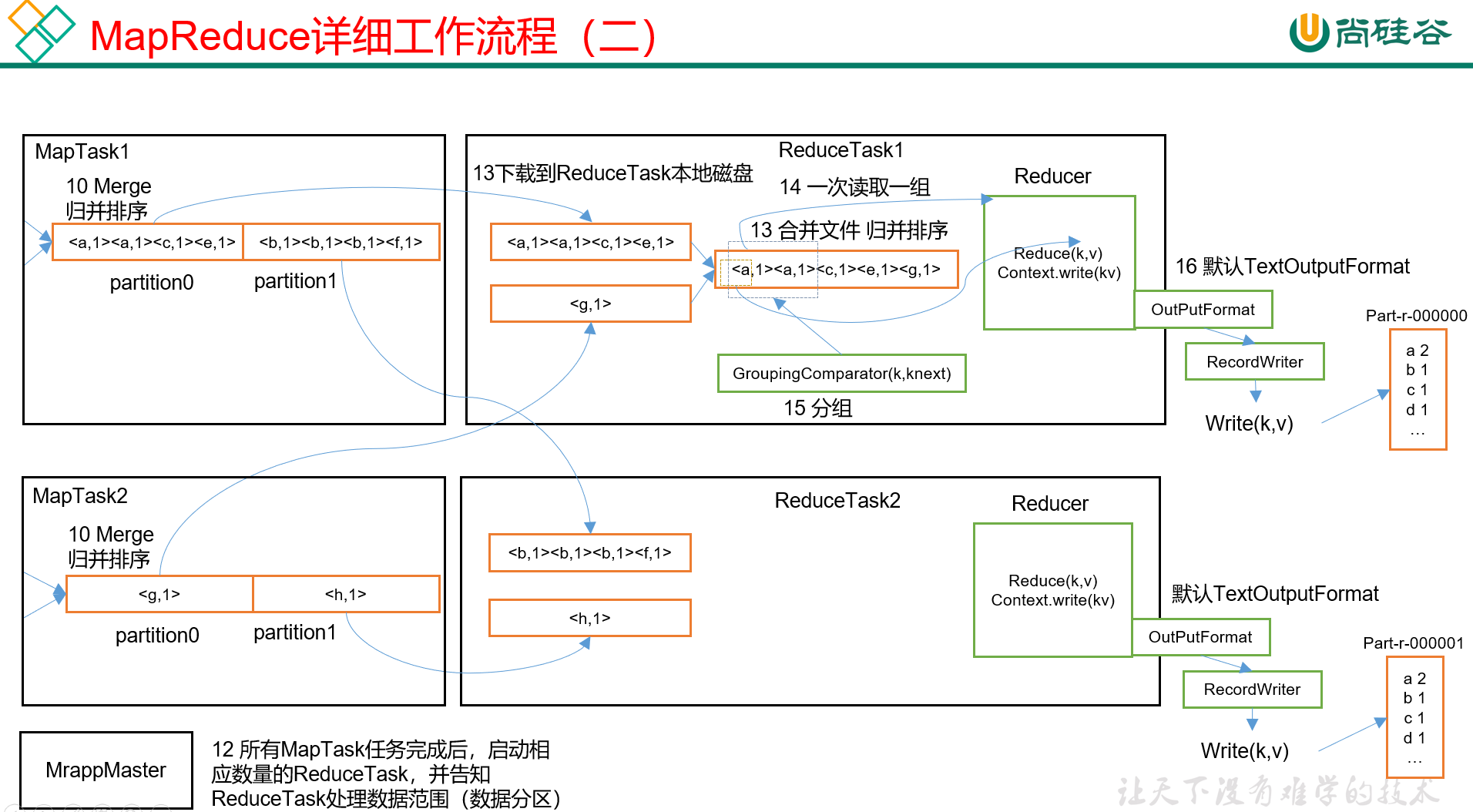
一般情况下等所有MapTask任务都完成后就会启动响应数据的ReduceTask并告知每个ReduceTask它需要处理的数据范围。
这里说的是一般情况下实际上我们也可以设置等到一部分MapTask完成之后就先启动几个ReduceTask做处理相当于Map阶段和Reduce阶段同时进行。这个比较适合MapTask很多的情况比如说有100个MapTask等到100个都执行完才进入Reduce阶段未免太慢了所以可以这样并行走。
-
ReduceTask 主动 从MapTask的结果数据中去拉取需要的数据然后做合并文件 + 归并排序。
举个例子ReduceTask_1可能会从MapTask_1拉取指定分区数据也会从MapTask_2中拉取该分区的数据这样的话就会有多个文件而且虽然每个文件内部是有序的MapTask处理过但是不同文件之间可能是无序的因此合并文件 + 归并排序是很有必要的。
-
对上一步产生的结果一次读取一组送进Reducer()去做业务逻辑处理。这里的一组是KEY值相同作为一组因为上一步中已经排序过了所以KEY值相同的会被放在一起直接取这一组就可以了。
-
分组暂且不表
-
Reducer()处理完了之后由OutputFormat往外输出默认是TextOutputFormat即输出成文本文件。
这就是整个MR处理的流程。
参考文献
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |