

【实战项目】Django-Vue007---Redis、Python操作redis之普通连接和连接池、redis操作各种数据、django中使用redis
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
回顾
1、用户登录注册相关5个接口
多方式登录接口
手机号是否存在接口
发送验证码接口
验证码登录接口
验证码注册接口
2、可以写验证码注册+登录接口
如果手机号存在直接登录成功
如果手机号不存在直接创建用户并且成功登录签发token
可以不用序列化类直接写在视图类里面
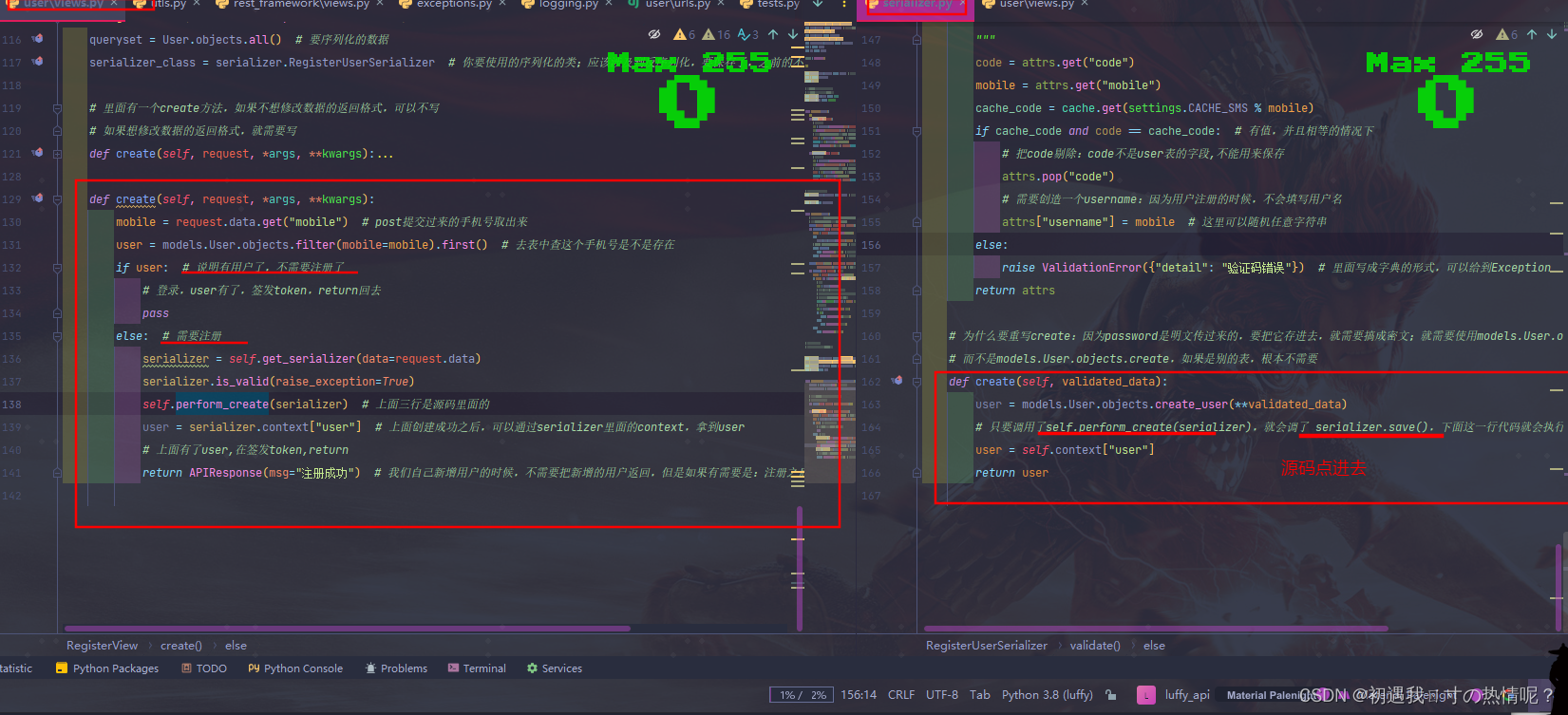
上面就是注册加登录的接口的代码逻辑
3、发送短信二次封装
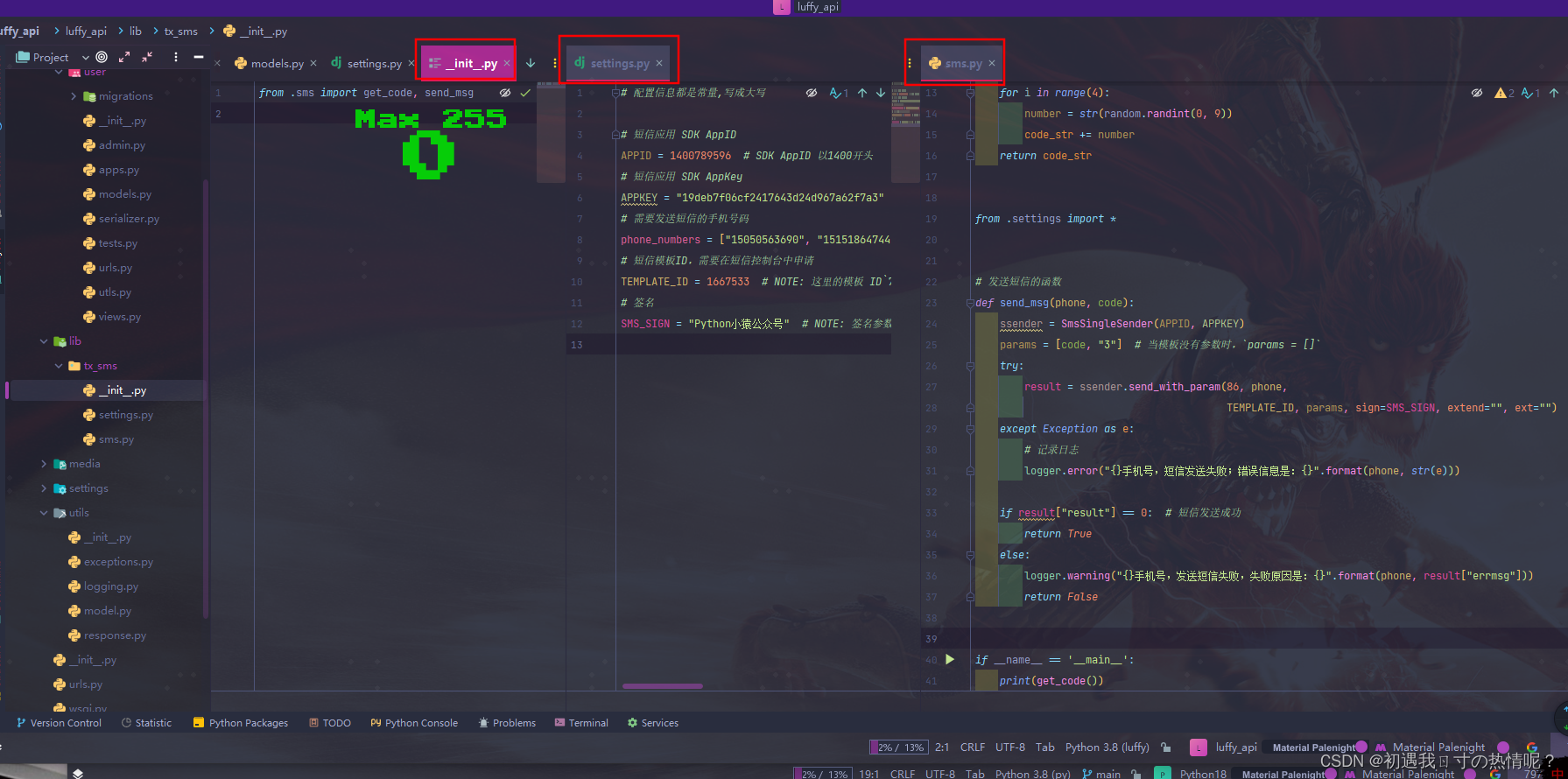
4、发送短信接口
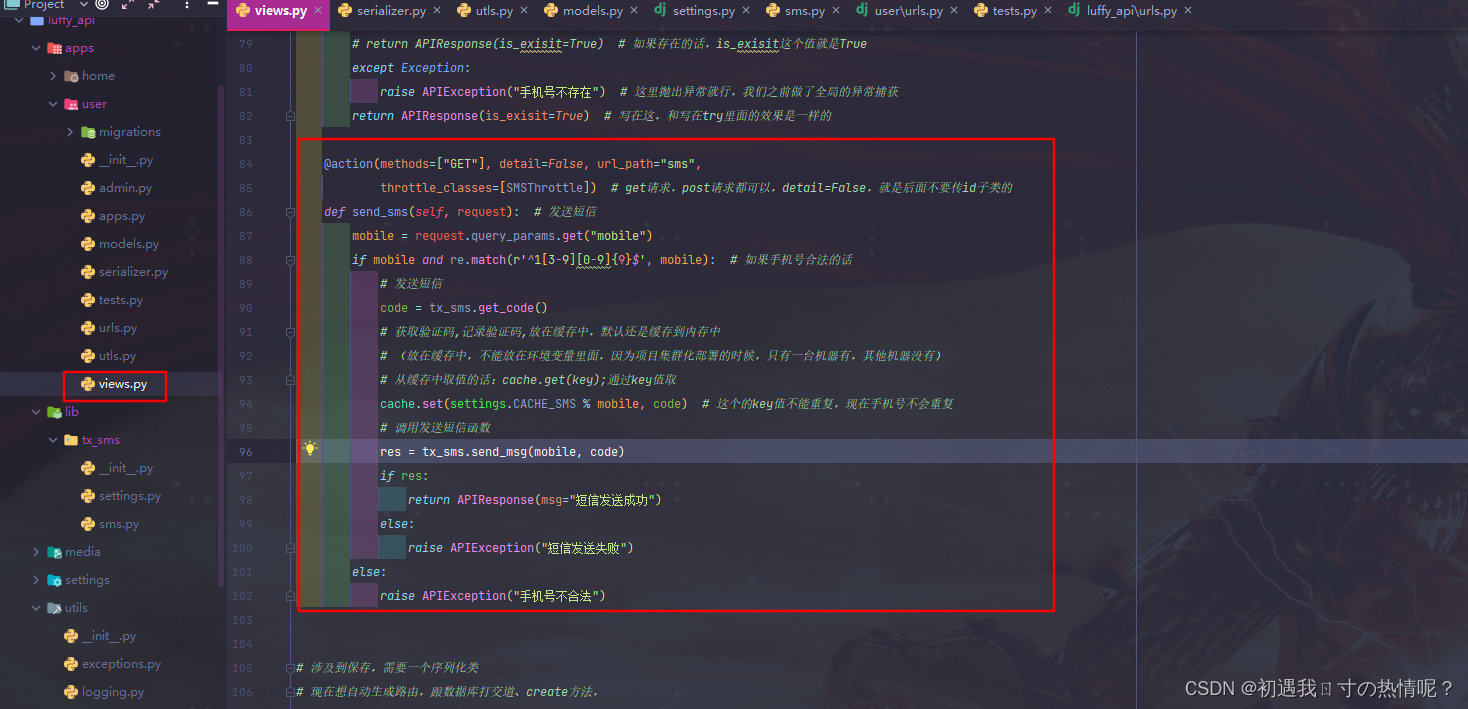
5、验证码登录接口
手机号、验证码 =====> post
视图函数代码
def mobile_login(self, request):
# 逻辑写在序列化类中
ser = serializer.MobileLoginSerializer(data=request.data) # 前端传过来的数据在data中
ser.is_valid(raise_exception=True) # 先走字段自己的规则然后走全局的钩子
# 配置了这个raise_exception=True相当于raise APIException("用户名密码错误")、如果有异常的话。下面的代码就不会走了7
token = ser.context.get("token") # 这个context相当于序列化类和视图函数之间沟通的桥梁
username = ser.context.get("username")
return APIResponse(msg="登录成功", username=username, token=token)
序列化代码
class MobileLoginSerializer(serializers.ModelSerializer): # 以后都用ModelSerializer
# 因为mobile在表中是唯一的因为是反序列化没有保存所以这里要重写mobile字段
mobile = serializers.CharField()
# 需要重写code因为User表里面没有code所以必须重写
code = serializers.CharField()
class Meta:
model = models.User
fields = ['code', 'mobile']
def validate(self, attrs): # 写一个全局规则
# 1、校验code是否正确从缓存中根据手机号获取code比较
# 2、根据手机号拿到当前用户
# 3、根据用户签发token
# 4、把token放在序列化类的对象中
# :param attrs: 校验过后的数据前面的校验规则走完之后的那个字典
# :return:
# 这个里面主要就是校验用户和签发token
user = self._get_user(attrs) # 获取这个用户
token = self._get_token(user) # 获取这个用户的token
# 现在拿到token了现在token在serializers现在要给视图类
# 重点来了把token放在序列化类的对象中不建议self.token = token这样放
# context上下文是一个字典
self.context["token"] = token
self.context["username"] = user.username
return attrs # 把校验过后的数据再返回
def _get_user(self, attrs): # 不是私有__两个横线才是私有但是自己认为尽量只给内部用
# 获取这个用户
# :param attrs: 校验过后的数据前面的校验规则走完之后的那个字典
# :return:
code = attrs.get("code")
mobile = attrs.get("mobile")
# 校验code
# 通过key值取出对应的value当时是这样存进去的cache.set(settings.CACHE_SMS % mobile, code)
cache_code = cache.get(settings.CACHE_SMS % mobile)
if cache_code and code == cache_code: # 有值并且相等的情况下
# 验证码一旦验证过验证码需要失效
cache.set(settings.CACHE_SMS % mobile, "") # 第一种直接将key值设置为空
# cache.set(settings.CACHE_SMS % mobile, code, "-1") # 第二种设置过期时间是-1
user = models.User.objects.filter(mobile=mobile).first()
if user: # 如果有这个用户
return user
else: # 如果用户不存在
raise ValidationError({"detail": "用户名或密码错误"}) # {"detail": "用户名或密码错误"}
else:
ValidationError({"detail": "验证码错误"})
def _get_token(self, user): # 通过user签发token把tokenreturn出去
payload = jwt_payload_handler(user)
token = jwt_encode_handler(payload)
return token
验证码注册接口
手机号、密码、验证码=====> post
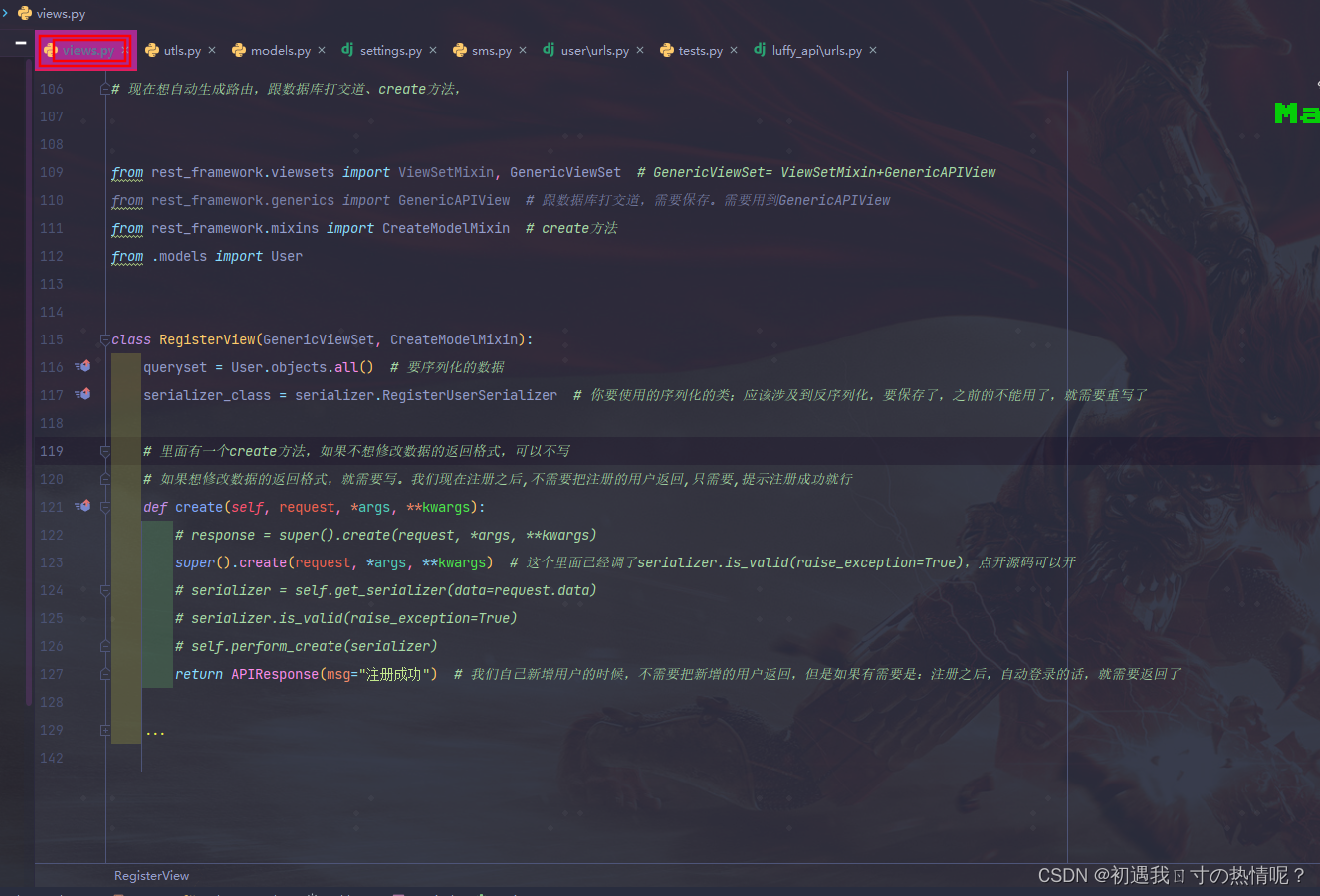
序列化代码
class RegisterUserSerializer(serializers.ModelSerializer):
# code不是user表的字段必须重写
code = serializers.CharField(max_length=4, min_length=4, write_only=True) # 写write_only只做序列化
class Meta:
model = models.User # 跟哪个表有关系
fields = ["mobile", "code", "password"] # 这个是用来做反序列化前端传过来的数据用来做校验
extra_kwargs = {"mobile": {"write_only": True},
"password": {"write_only": True}}
# 我们的意图是做反序列化的但是源码里面调了ser.data,也会做序列化所以说写了write_only
# 校验字段
def validate(self, attrs):
# 1、校验code是否正确
# 2、将code从attrs中剔除表里面没有这个字段不需要存这个字段;因为mobile是必填项不需要校验mobile
# 3、使用手机号作为用户名后期可以改
code = attrs.get("code")
mobile = attrs.get("mobile")
cache_code = cache.get(settings.CACHE_SMS % mobile)
if cache_code and code == cache_code: # 有值并且相等的情况下
# 把code剔除code不是user表的字段,不能用来保存
attrs.pop("code")
# 需要创造一个username因为用户注册的时候不会填写用户名
attrs["username"] = mobile # 这里可以随机任意字符串
else:
raise ValidationError({"detail": "验证码错误"}) # 里面写成字典的形式可以给到Exception
return attrs
# 为什么要重写create因为password是明文传过来的要把它存进去就需要搞成密文就需要使用models.User.objects.create_user来创建用户
# 而不是models.User.objects.create如果是别的表根本不需要
def create(self, validated_data):
user = models.User.objects.create_user(**validated_data)
# 只要调用了self.perform_create(serializer)就会调了 serializer.save()下面这一行代码就会执行
# user = self.context["user"]
return user
前端
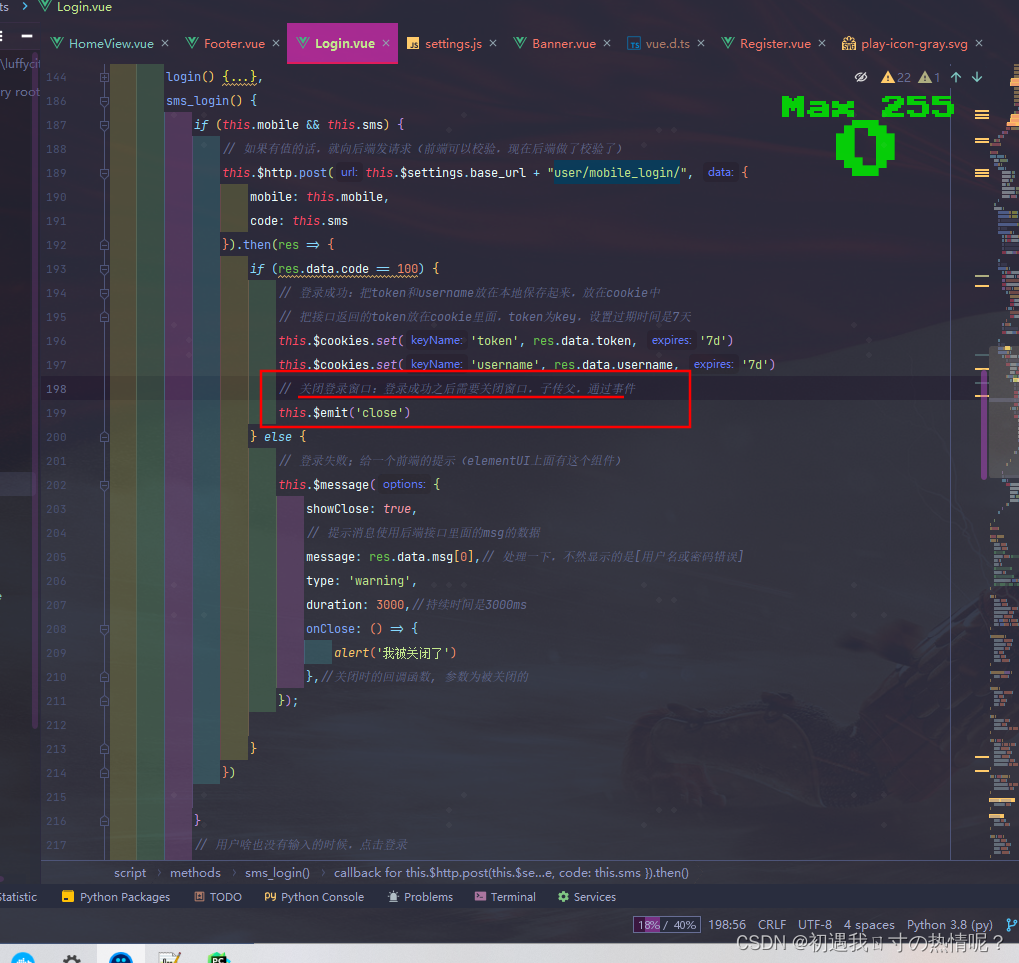
如果加在Local Storage里面效果就是关闭浏览器之后打开还是之前的页面
Redis介绍
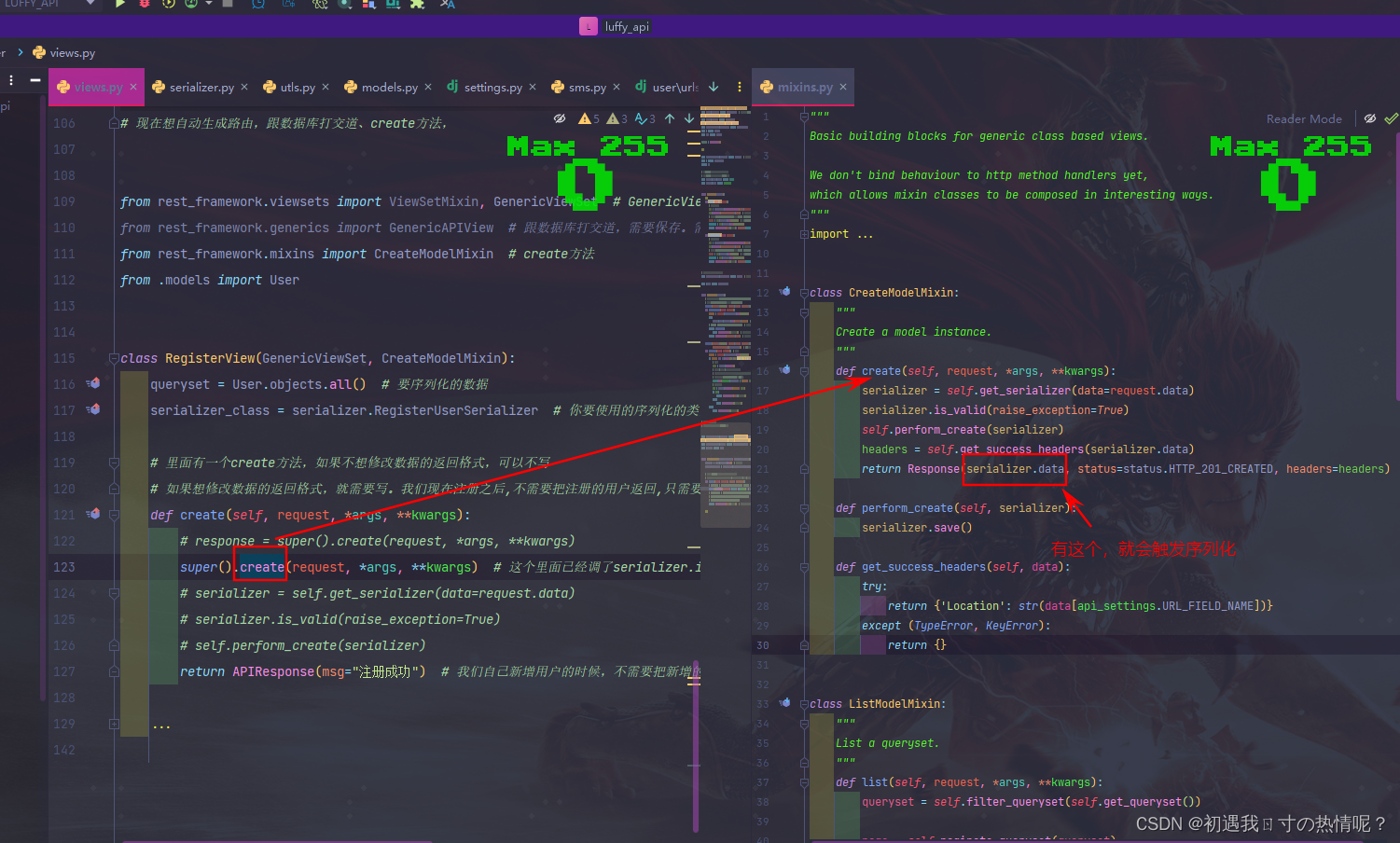
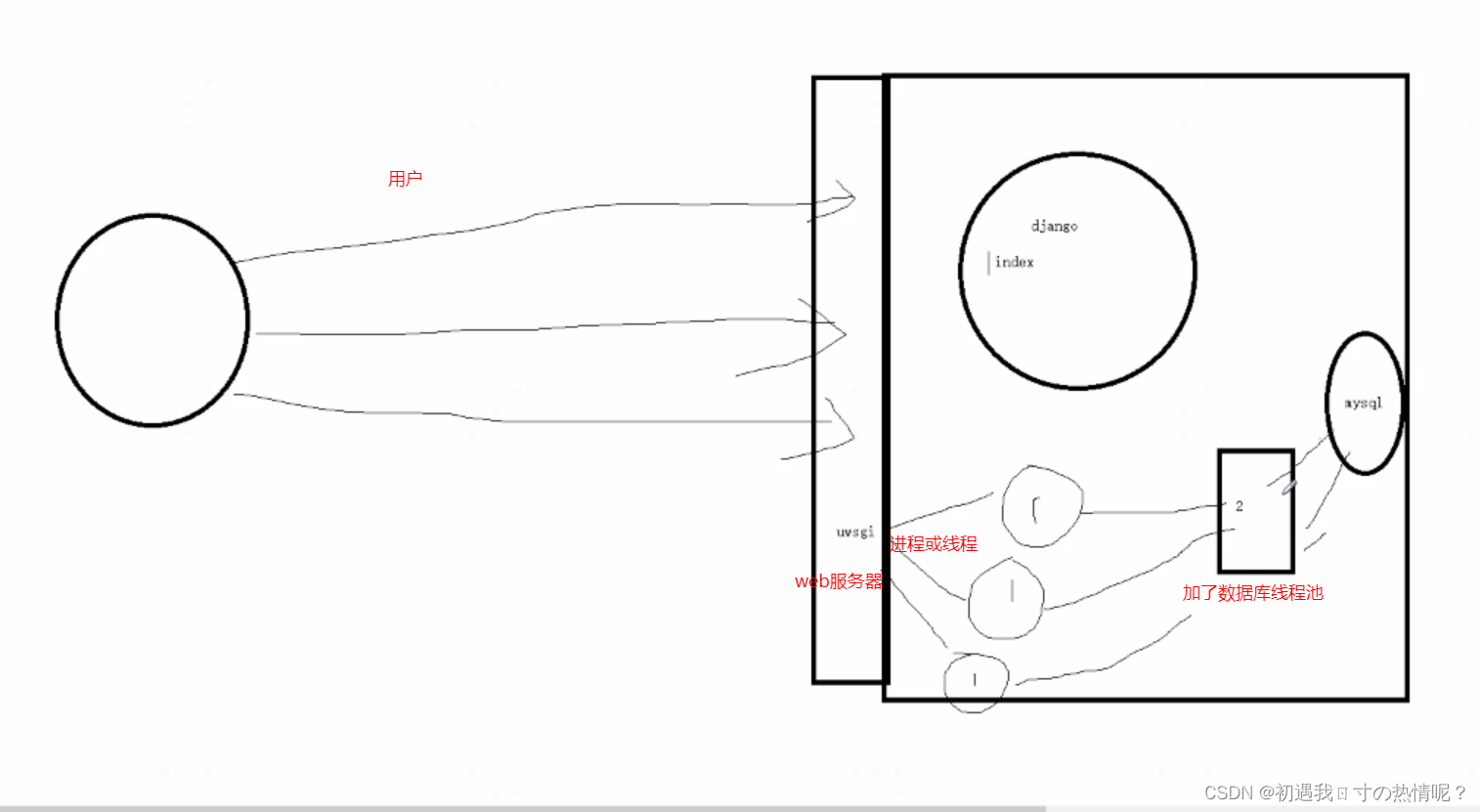
1、非关系型数据库纯内存操作性能很高key-value存储没有表的概念
2、用来做缓存计数器验证码几分钟之后过期geo地理位置信息附近的人发布订阅独立用户统计看日活避免一个人重复登录放在一个集合里面
3、上面的是他的用处用的做多的还是缓存
4、5大数据类型字符串、列表、哈希、集合、有序集合
5、6.x之前是单线程单进程为什么这么快 qps每秒查询率 10W
1、纯内存
2、使用了IO多路复用的模型epollIO多路复用有3个模型select、poll、epoll
3、避免了线程间切换的浪费6.x之后没有这个说法了
6、安装
官方提供了源码c语言写的需要编译安装
编译型语言如果要执行需要在不同平台上编译成不同平台上的可执行文件
在linux上装通过gcc编译编译成可执行文件就可以运行了
在windows上官方不支持会有第三方提供季节方案
监听的端口6379
win上自动做成服务启动关闭服务
使用命令启动服务端
redis-server 配置文件
客户端连接
redis-cli
Python连接
图形化的客户端有很多
推荐redis-desktop-manager
用工具连接到redis
先把服务起来
7、QT:平台
使用c/C++语言在平台上开发----》图形化界面软件(GUI)
pyqt:在qt平台上使用python代码写图形化界面
Tkinter
pymysql和mysql的选择
django 2.7之后
如果还使用pymysql连接mysql源码不兼容需要去改源码
mysqlclient什么都不用配。直接用不需要改源码
Python操作redis之普通连接和连接池
参考https://www.cnblogs.com/liuqingzheng/articles/9833534.html
安装模块
pip install redis
普通连接
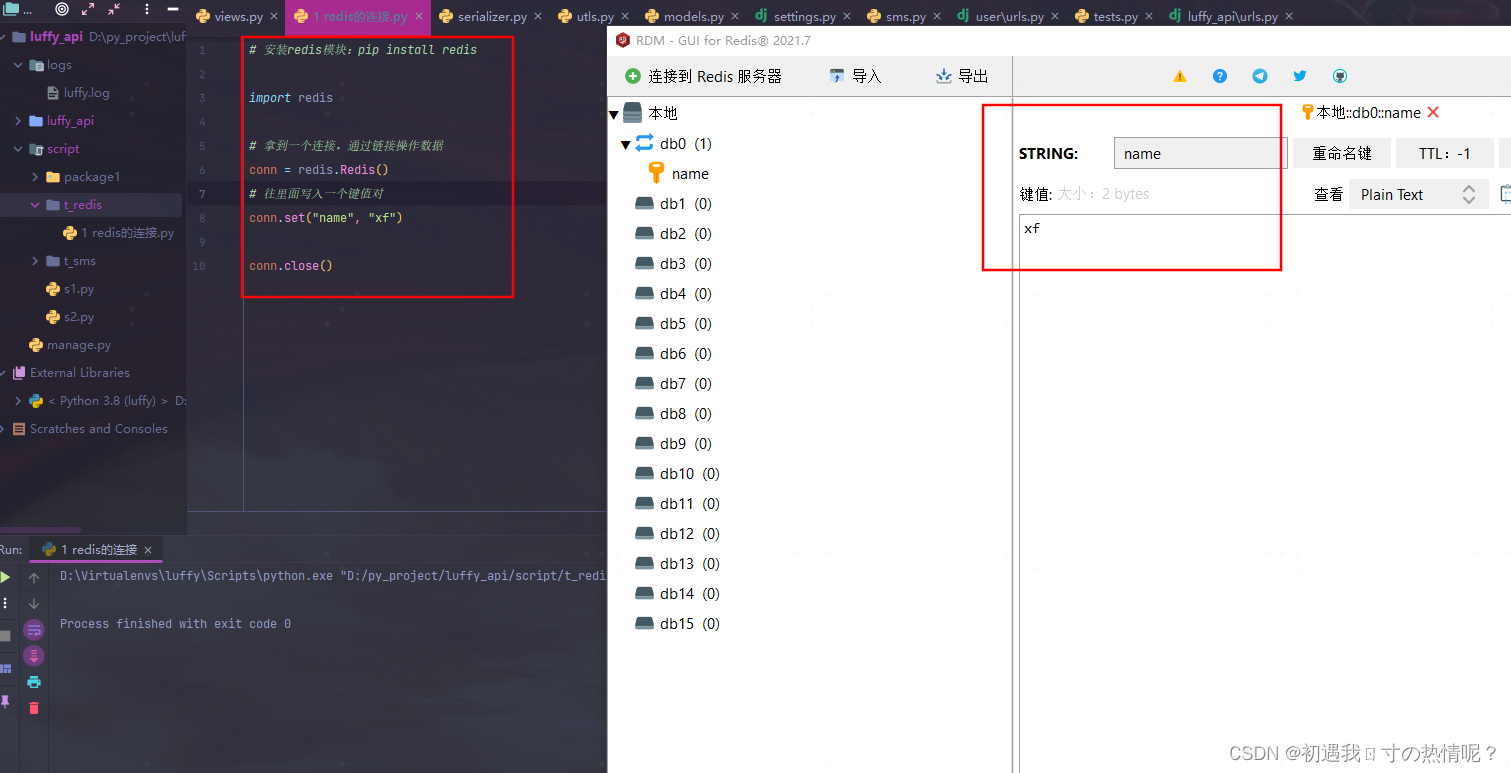
默认有16个库
上面这个是默认情况一般情况下会有一堆参数
这个里面都有默认值默认有16个库默认连的是0
redis连接池
补充django连接mysql是没有连接池的但是第三方会有解决方案提供了连接池的库
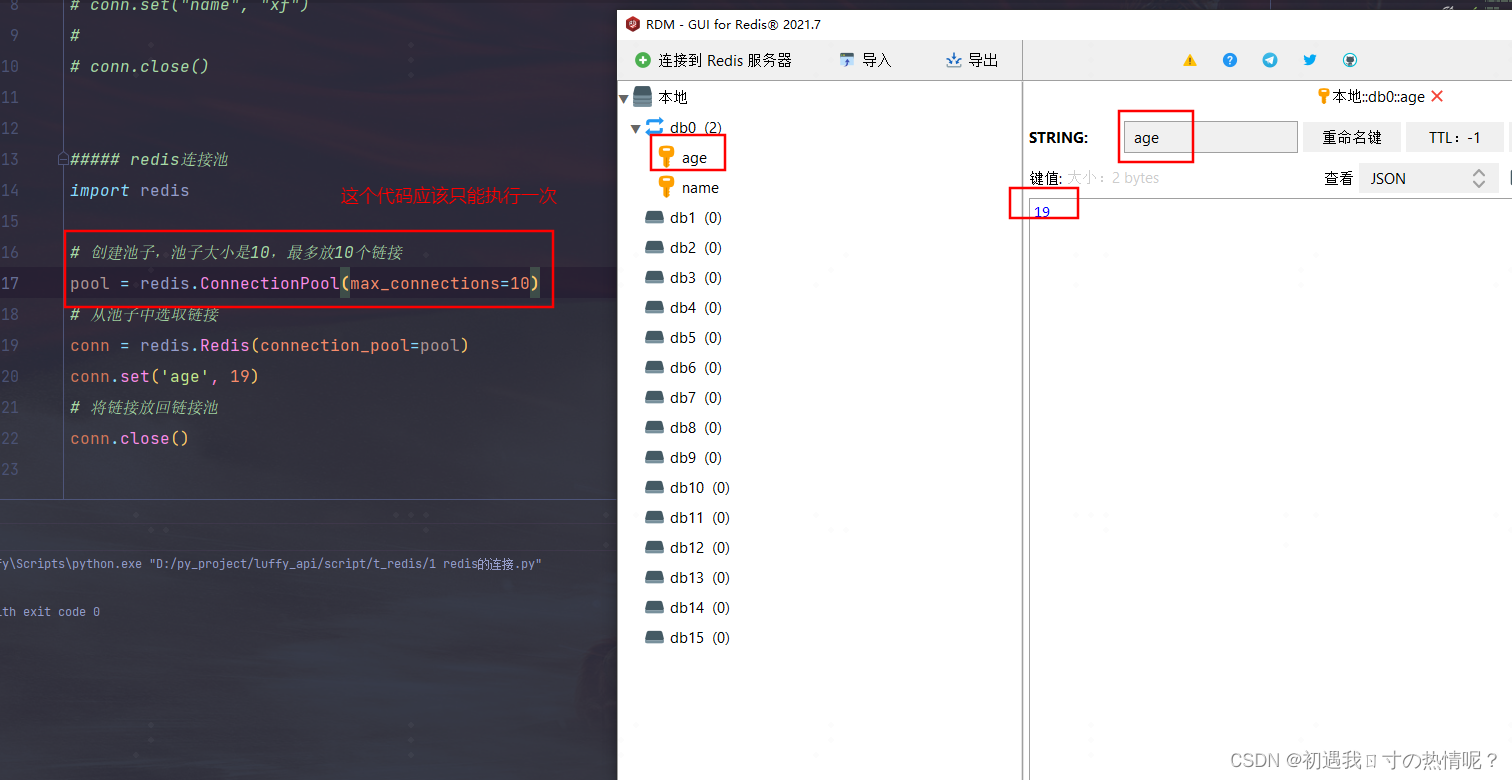
pool = redis.ConnectionPool(max_connections=10)
这个代码只能执行一次就是说只能创建一个池子后面的都从这个池子里面拿链接
所以上面的代码一定不能放在线程里面
所以池需要做成单列整个项目真能有一个
在Python中有5种写单列的情况https://www.liuqingzheng.top/python/%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1%E9%AB%98%E9%98%B6/19-%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1%E9%AB%98%E7%BA%A7%E5%AE%9E%E6%88%98%E4%B9%8B%E5%8D%95%E4%BE%8B%E6%A8%A1%E5%BC%8F/
第一种最简单Python的模块就是天然的单列
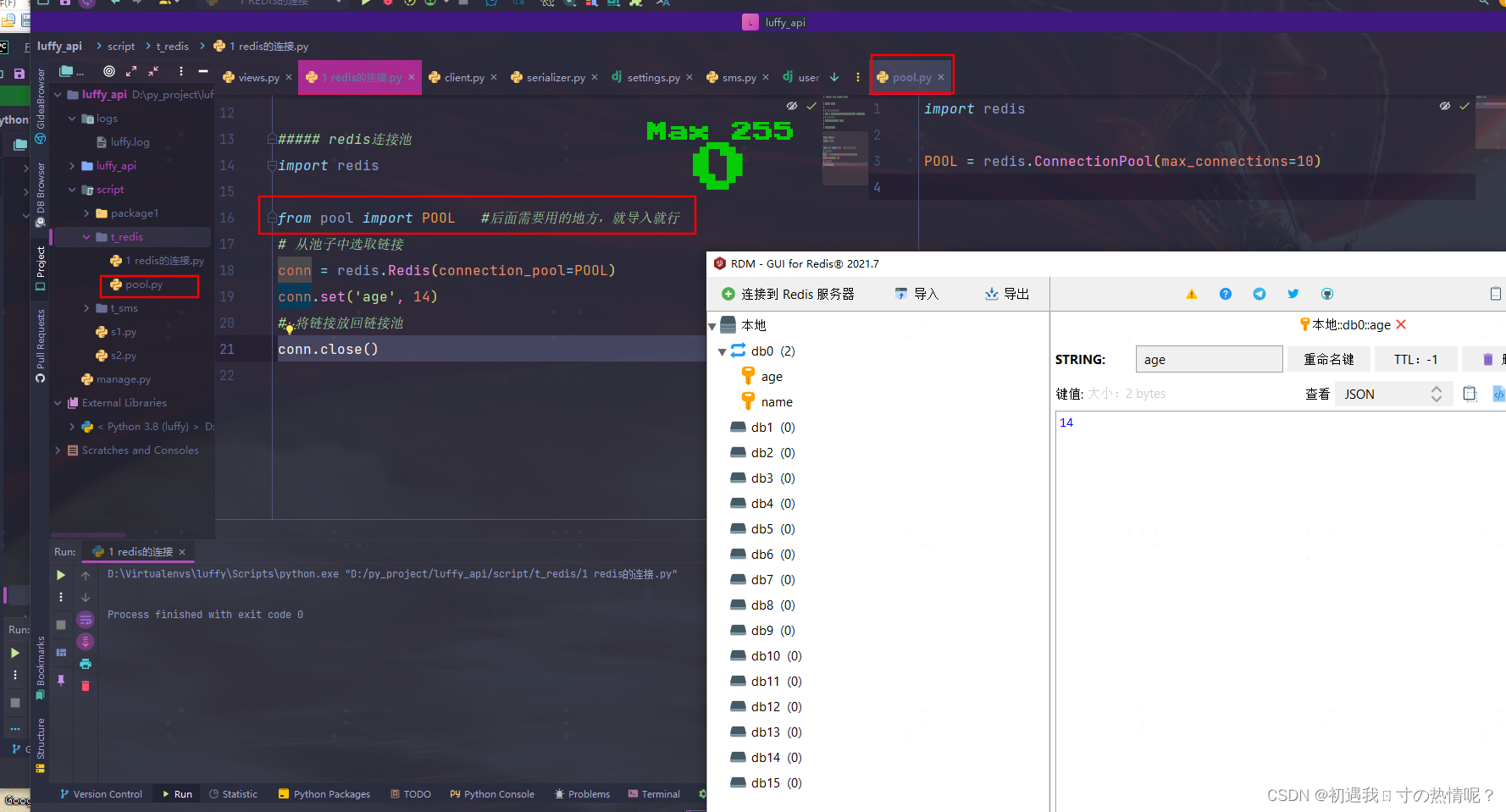
redis操作之字符串操作
说的是对应的value值是字符串
字符串操作不需要全记住
set(name, value, ex=None, px=None, nx=False, xx=False)
setnx(name, value)
setex(name, value, time)
psetex(name, time_ms, value)
mset(*args, **kwargs)
mget({'k1': 'v1', 'k2': 'v2'})
get(name)
mget(keys, *args)
mget('k1', 'k2')
getset(name, value)
getrange(key, start, end)
setrange(name, offset, value)
setbit(name, offset, value)
getbit(name, offset)
bitcount(key, start=None, end=None)
bitop(operation, dest, *keys)
bitop("AND", 'new_name', 'n1', 'n2', 'n3')
strlen(name)
incr(self, name, amount=1)
incrbyfloat(self, name, amount=1.0)
decr(self, name, amount=1)
1、set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值默认不存在则创建存在则修改
参数
ex过期时间秒
px过期时间毫秒
nx如果设置为True则只有name不存在时当前set操作才执行,值存在就修改不了执行没效果
xx如果设置为True则只有name存在时当前set操作才执行值存在才能修改值不存在不会设置新值
ex过期时间秒
import redis
conn = redis.Redis()
# ex=8这个值设置过之后8秒就没有了。适合存验证码子类的
# 不设置的话就是永久的在里面
conn.set("hobby", "篮球", ex=8)
conn.close()
- nx如果设置为True则只有name不存在时当前set操作才执行,值存在就修改不了执行没效果用的不多
xx如果设置为True则只有name存在时当前set操作才执行值存在才能修改值不存在不会设置新值用的不多
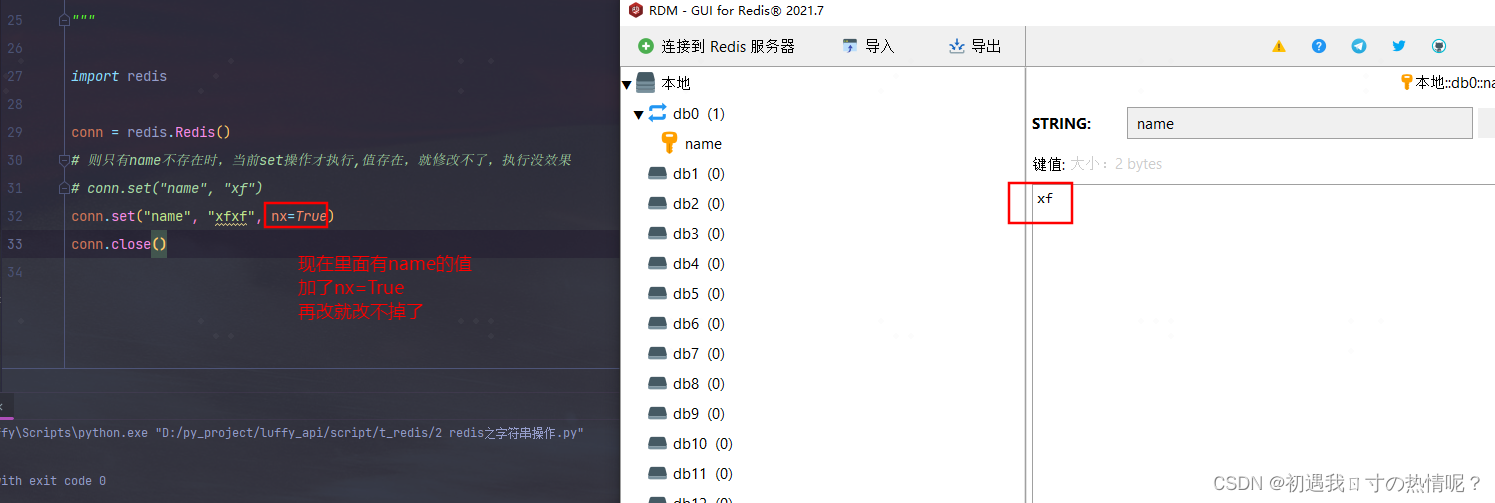
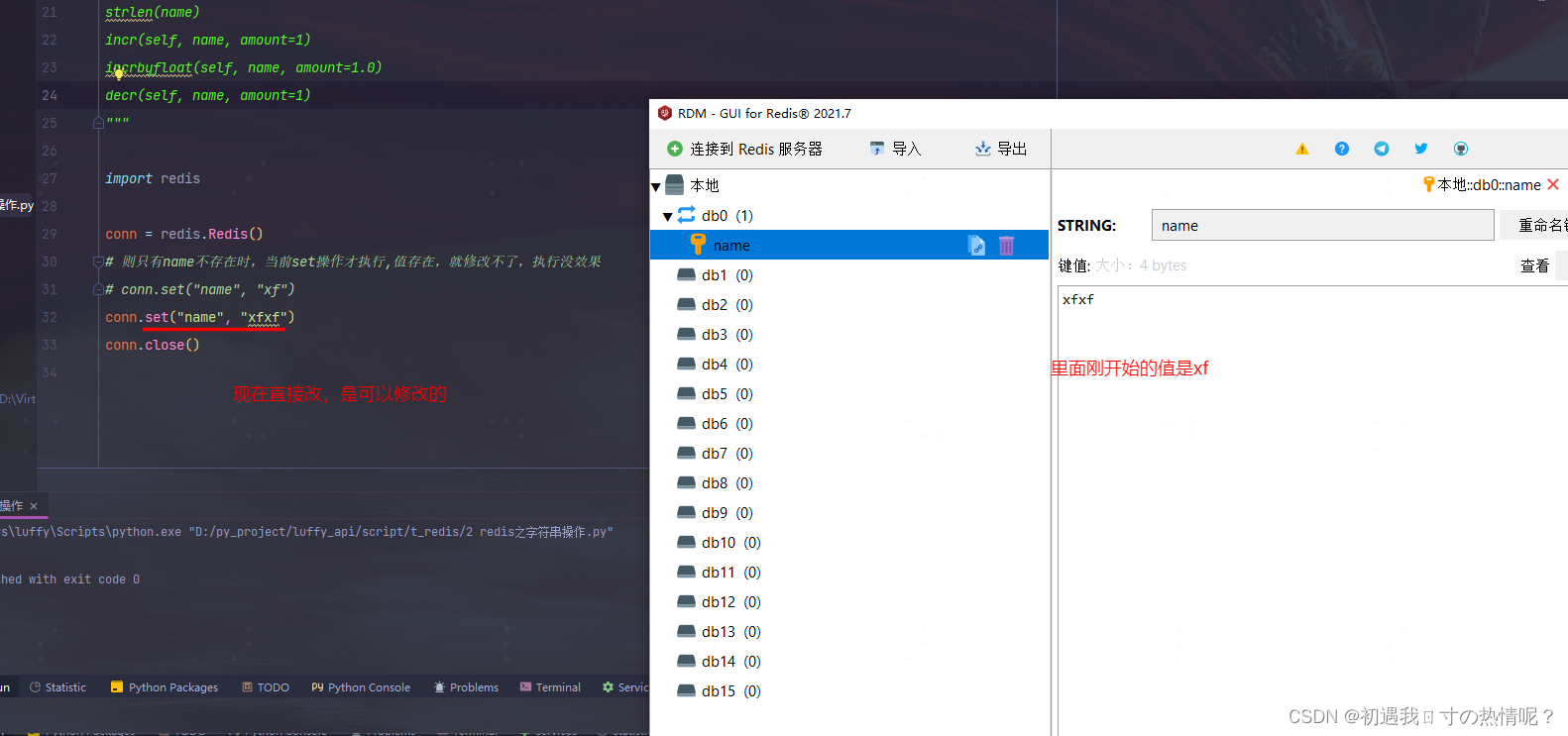
setnx(name, value)
就是 set(name, value, nx=True)的简写
setex(name,timevalue) #过期时间是中间的参数
就是 set(name, value, ex=None)的简写
18
4.psetex(name, time_ms, value)
以毫秒记的过期时间
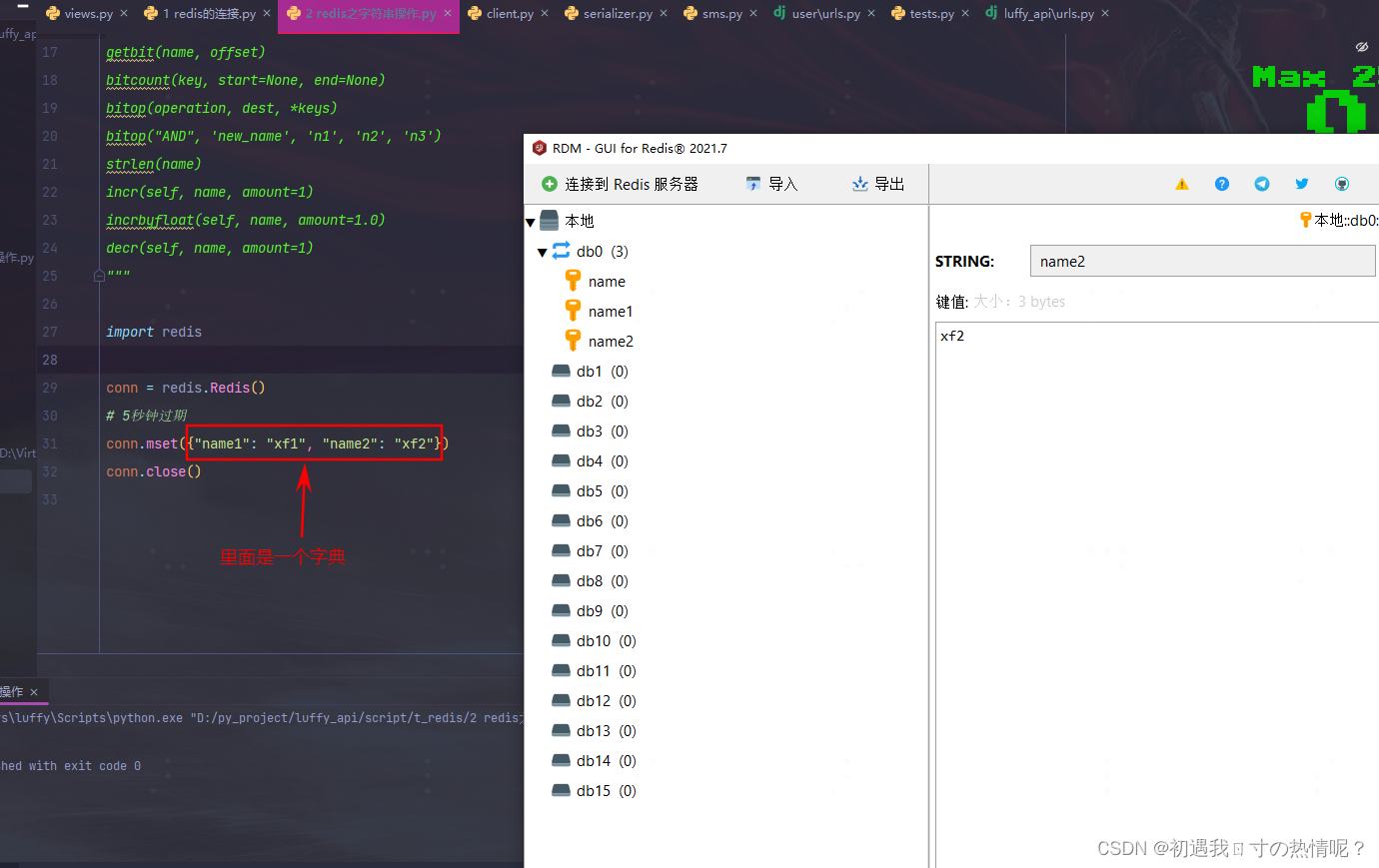
5、 mset(*args, **kwargs)
批量设置值、批量获取值
批量操作快
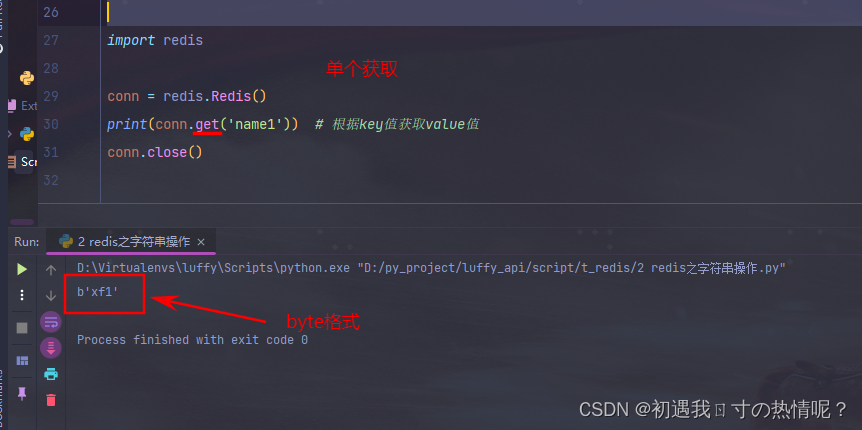
6、get
获取值
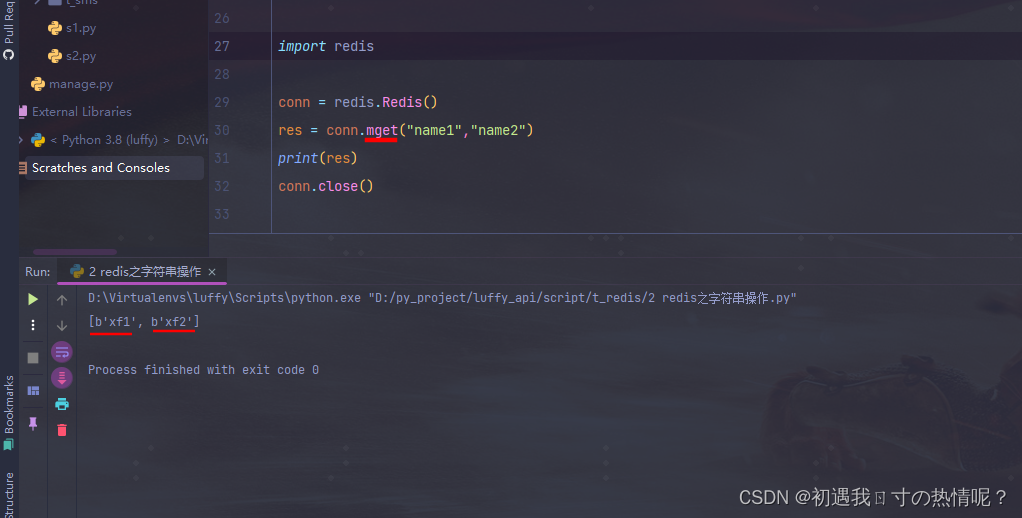
7、mget
批量获取
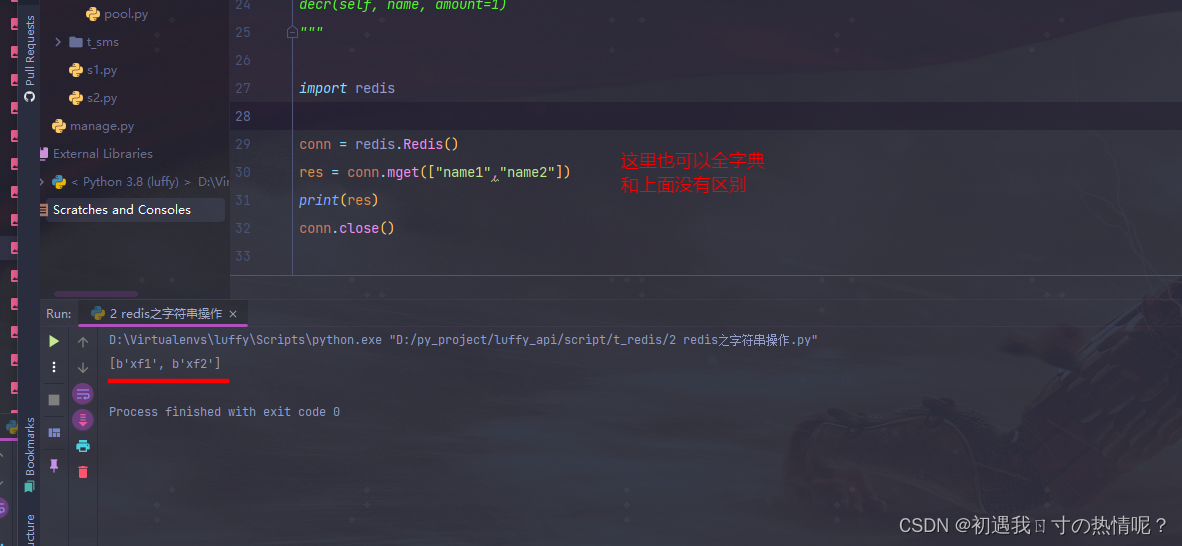
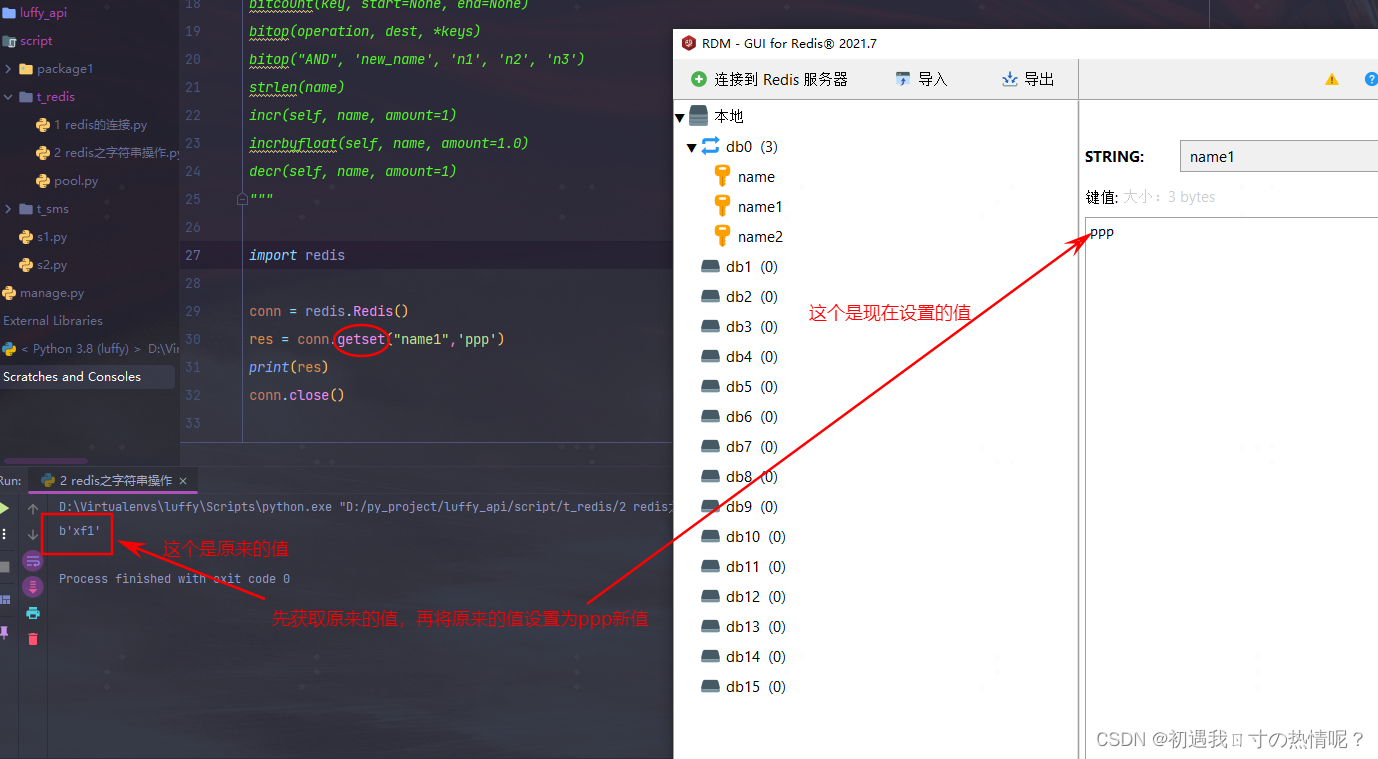
8、getset
设置新值并获取原来的值
9、getrange(key, start, end)
取一个范围
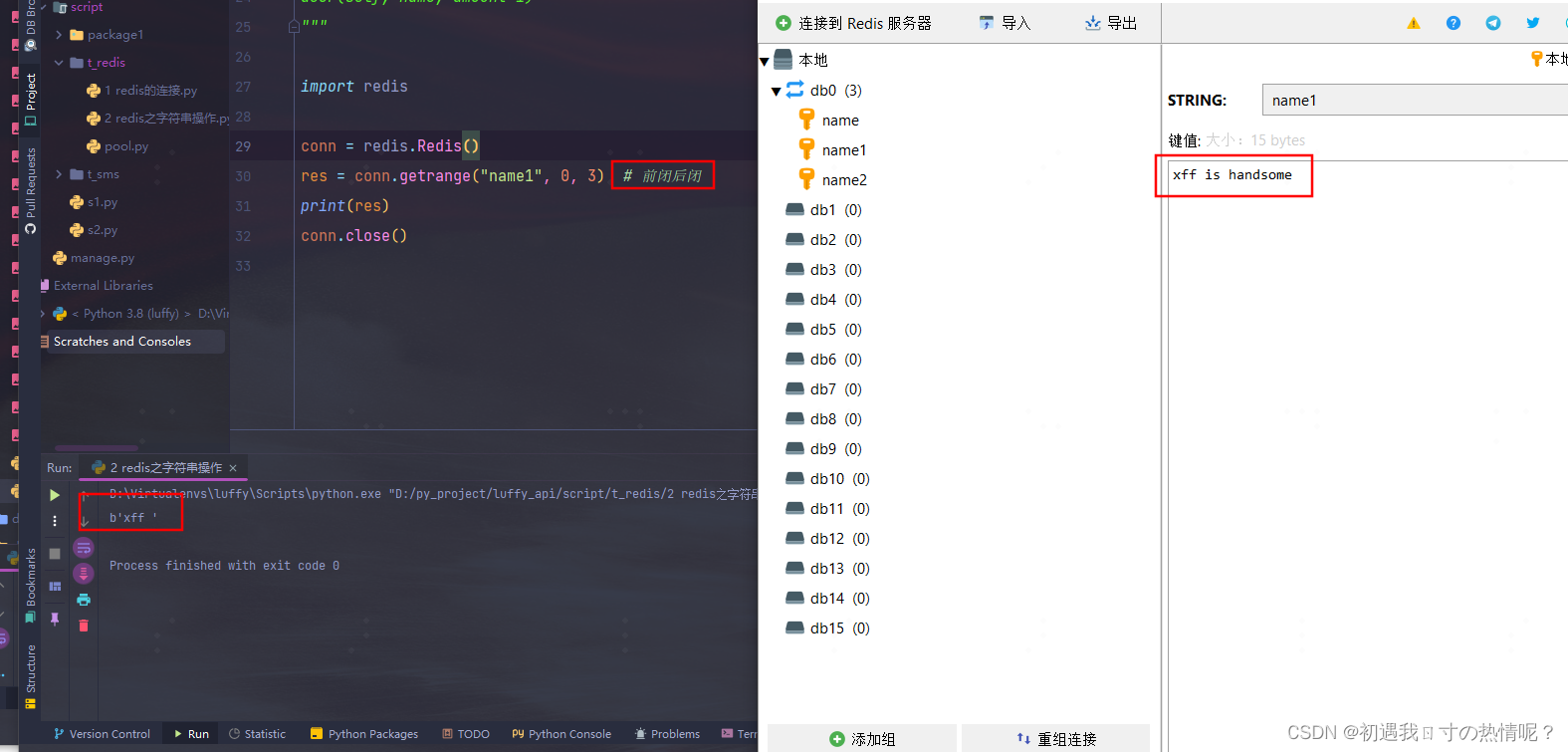
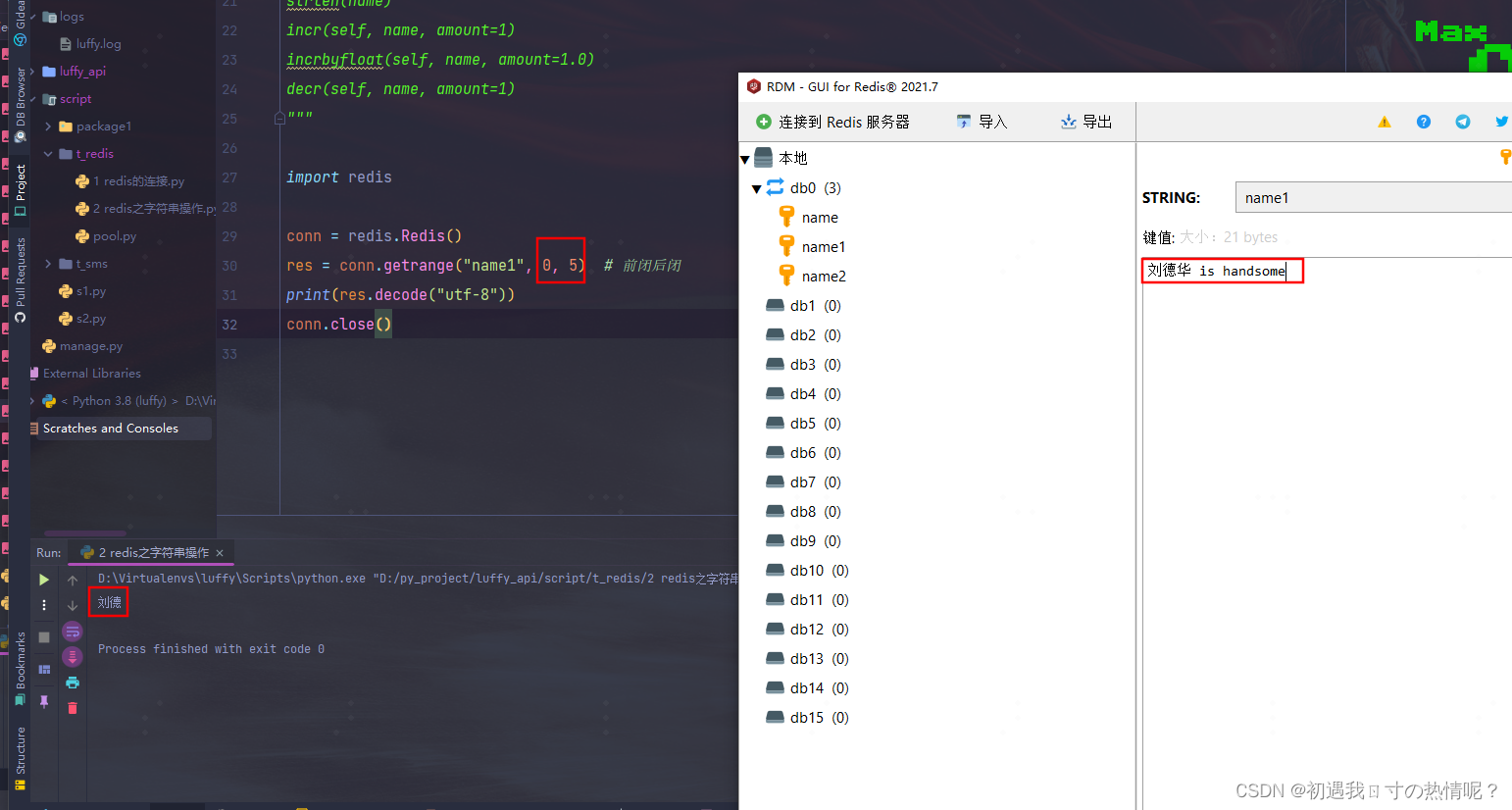
前闭后闭区间以unicode编码存储取的是字节
10、setrange(name, offset, value)
修改字符串内容从指定字符串索引开始向后替换新值太长时则向后添加
参数
offset字符串的索引字节一个汉字三个字节
value要设置的值
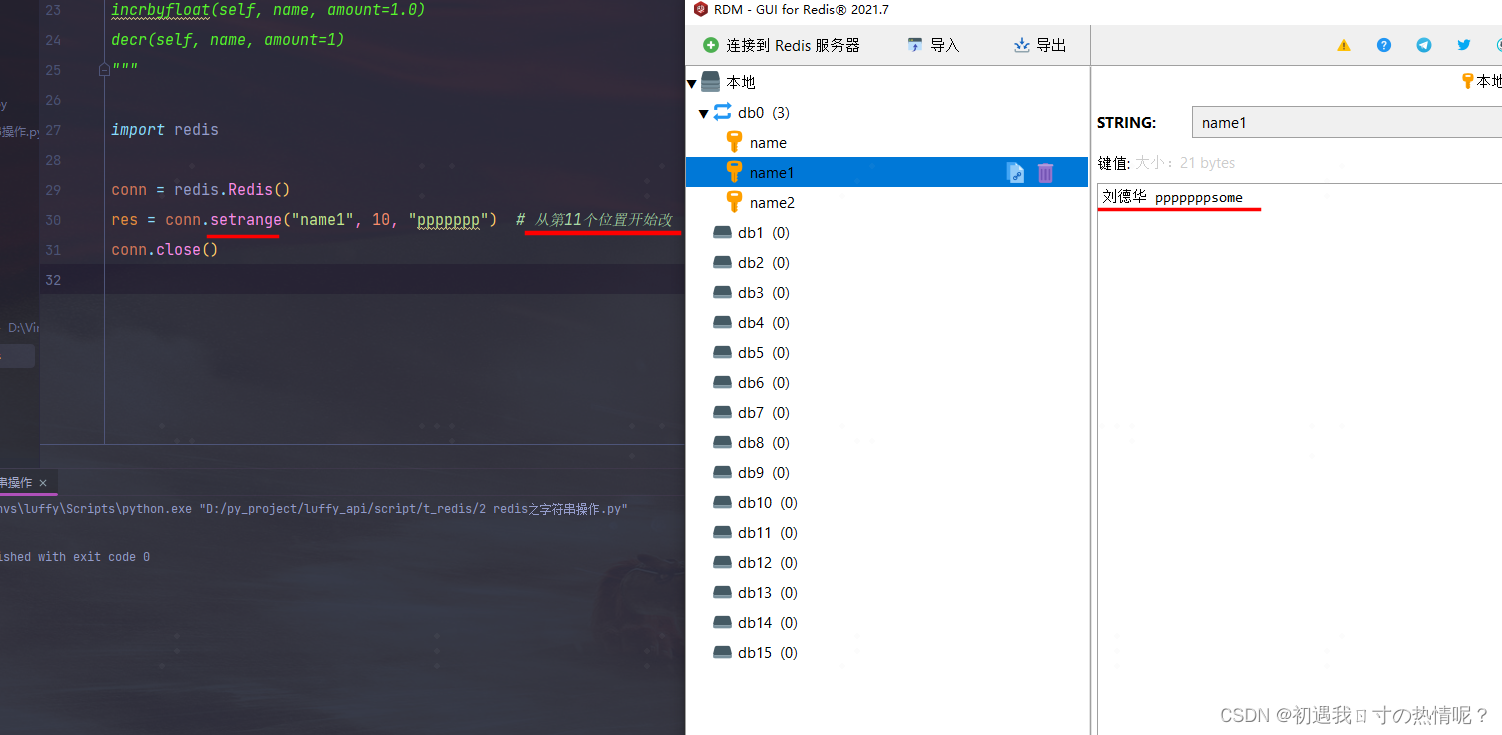
11、strlen(name)
返回name对应值的字节长度一个汉字3个字节
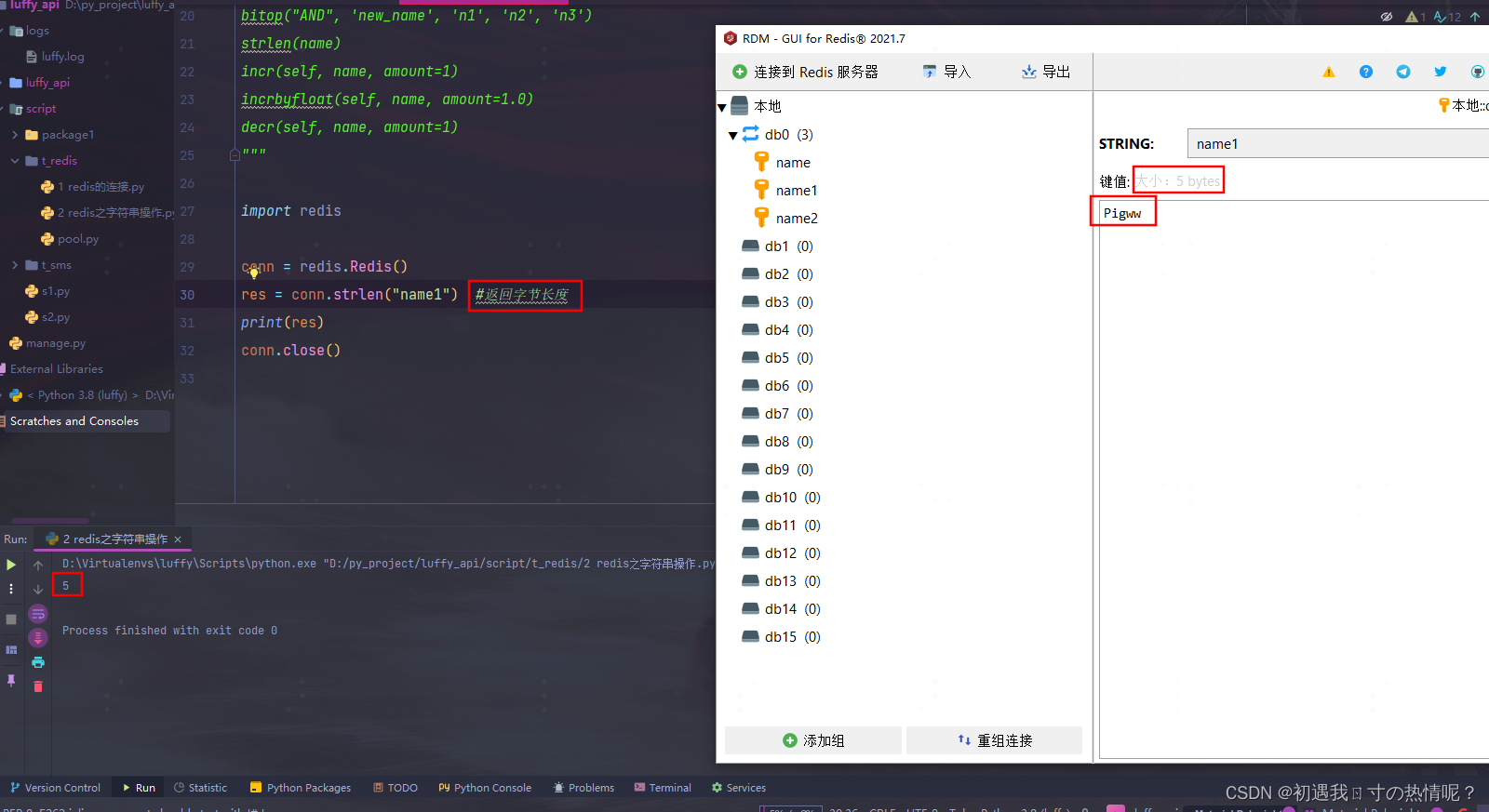
12、incr(self, name, amount=1)
自增执行一次自增一
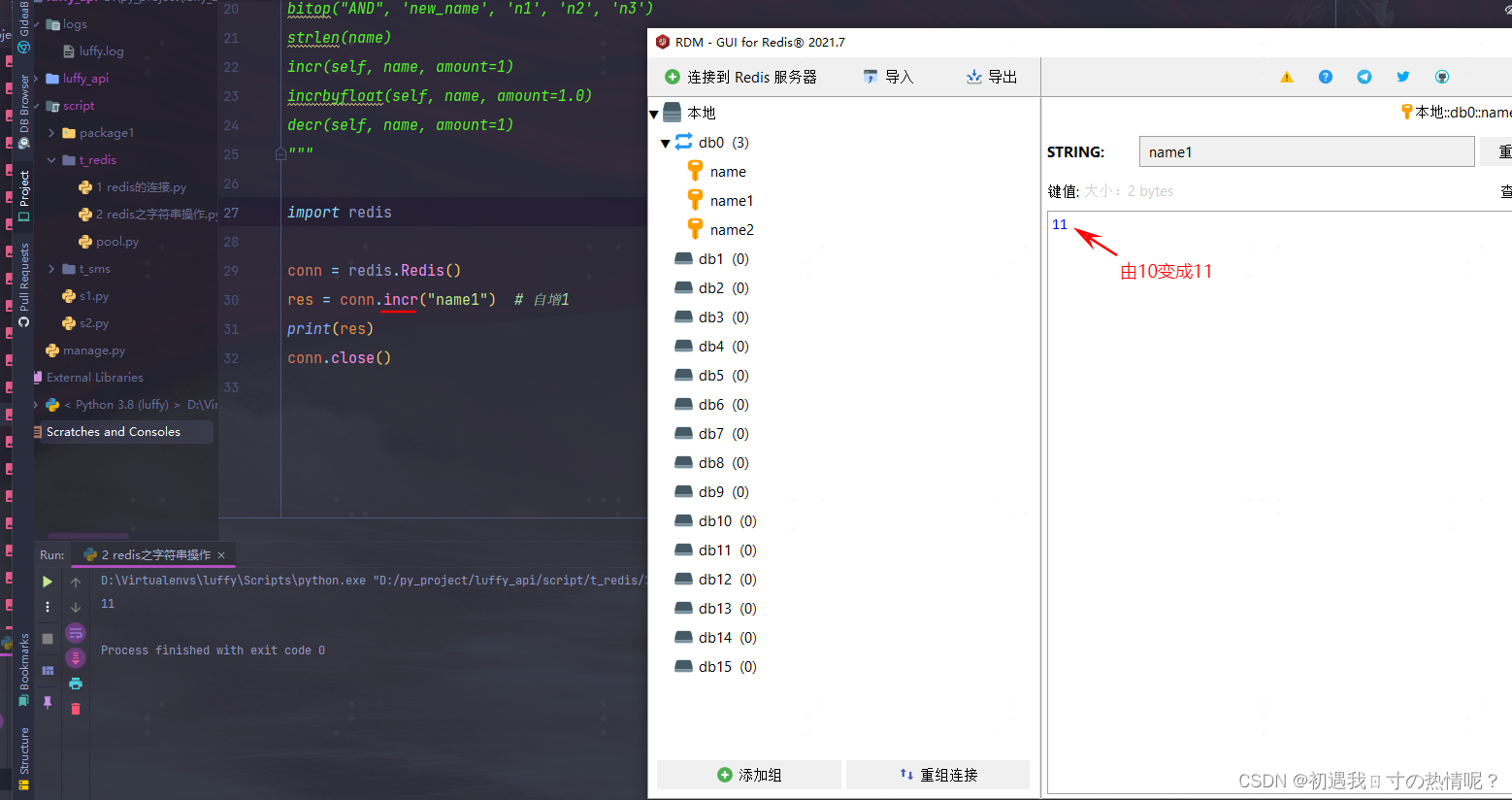
作用可以统计页面访问量
13、decr(self, name, amount=1)
自减
14、incrbyfloat(self, name, amount=1.0)
浮点数自增
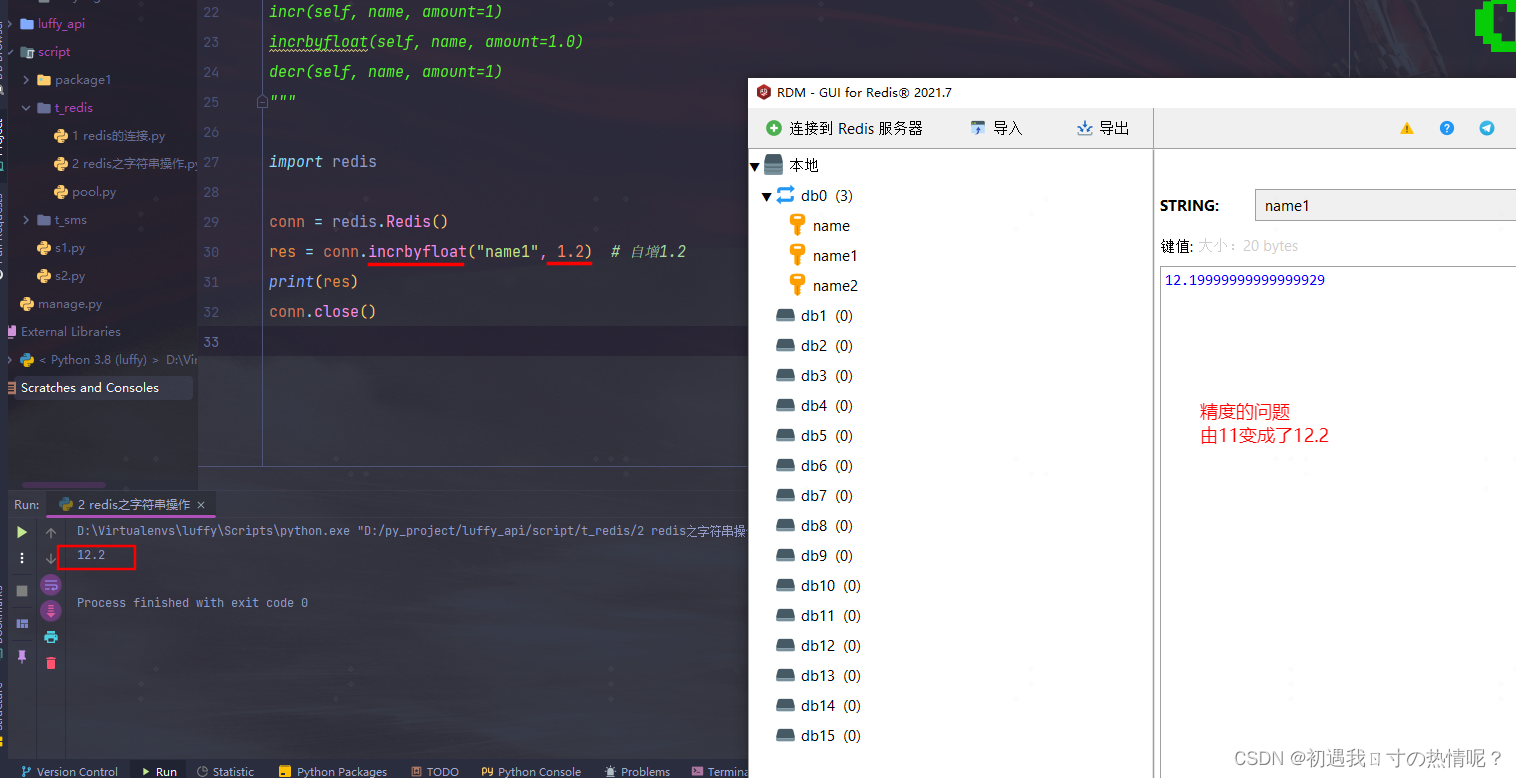
需要记住的
get
set
mget
mset
strlen
incr
Python操作redis操作之hash操作
hset(name, key, value)
hmset(name, mapping)
hget(name,key)
hmget(name, keys, *args)
hgetall(name)
hlen(name)
hkeys(name)
hvals(name)
hexists(name, key)
hdel(name,*keys)
hincrby(name, key, amount=1)
hincrbyfloat(name, key, amount=1.0)
hscan(name, cursor=0, match=None, count=None)
hscan_iter(name, match=None, count=None)
只要是hash类型的开头都是以h开头的
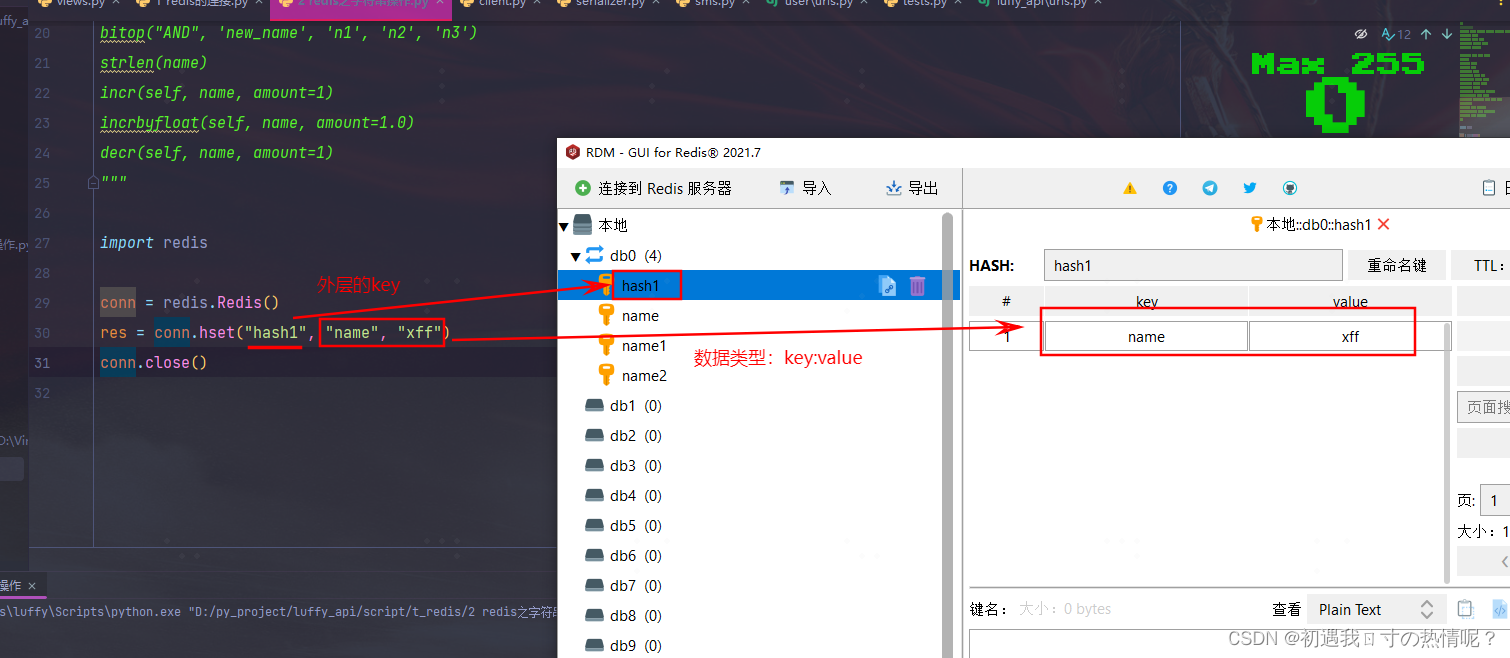
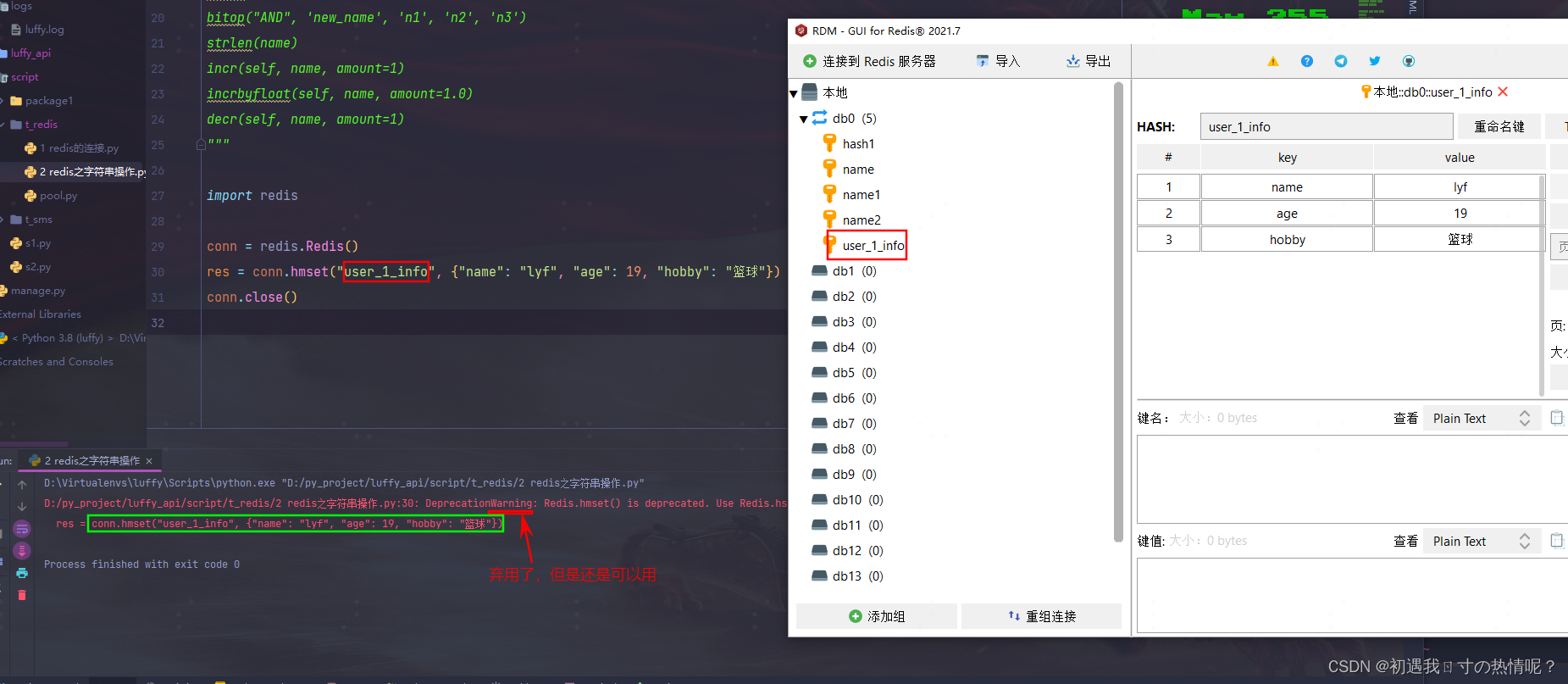
1、hset(name, key, value) 也可以 hmset(name, mapping)就是conn.hset(“user_3_info”, mapping={“name”: “lyf”, “age”: 19, “hobby”: “篮球”})
设置值
import redis
conn = redis.Redis()
res = conn.hset("hash1", "name", "xff")
conn.close()
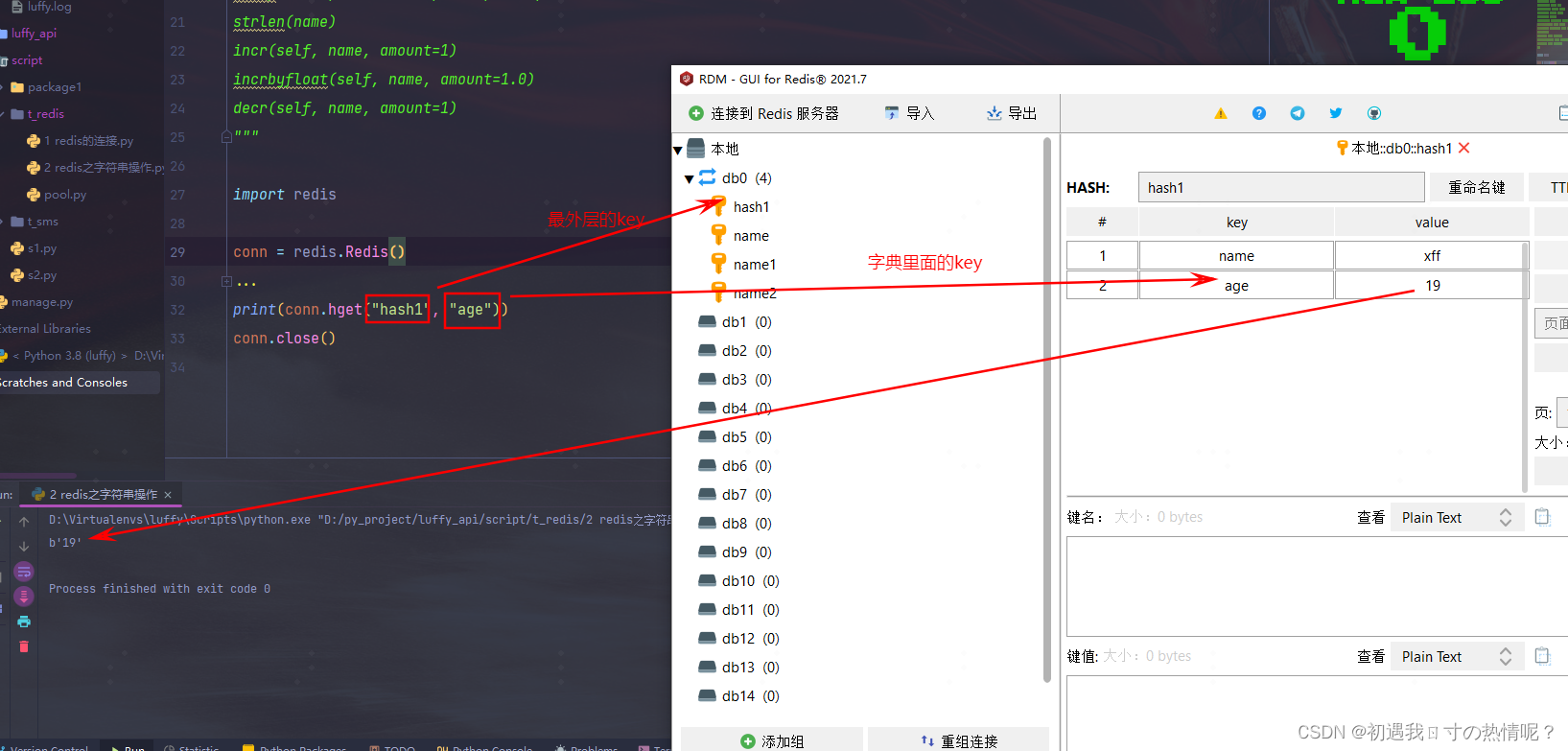
2、hget
获取值
import redis
conn = redis.Redis()
print(conn.hget("hash1", "age"))
conn.close()
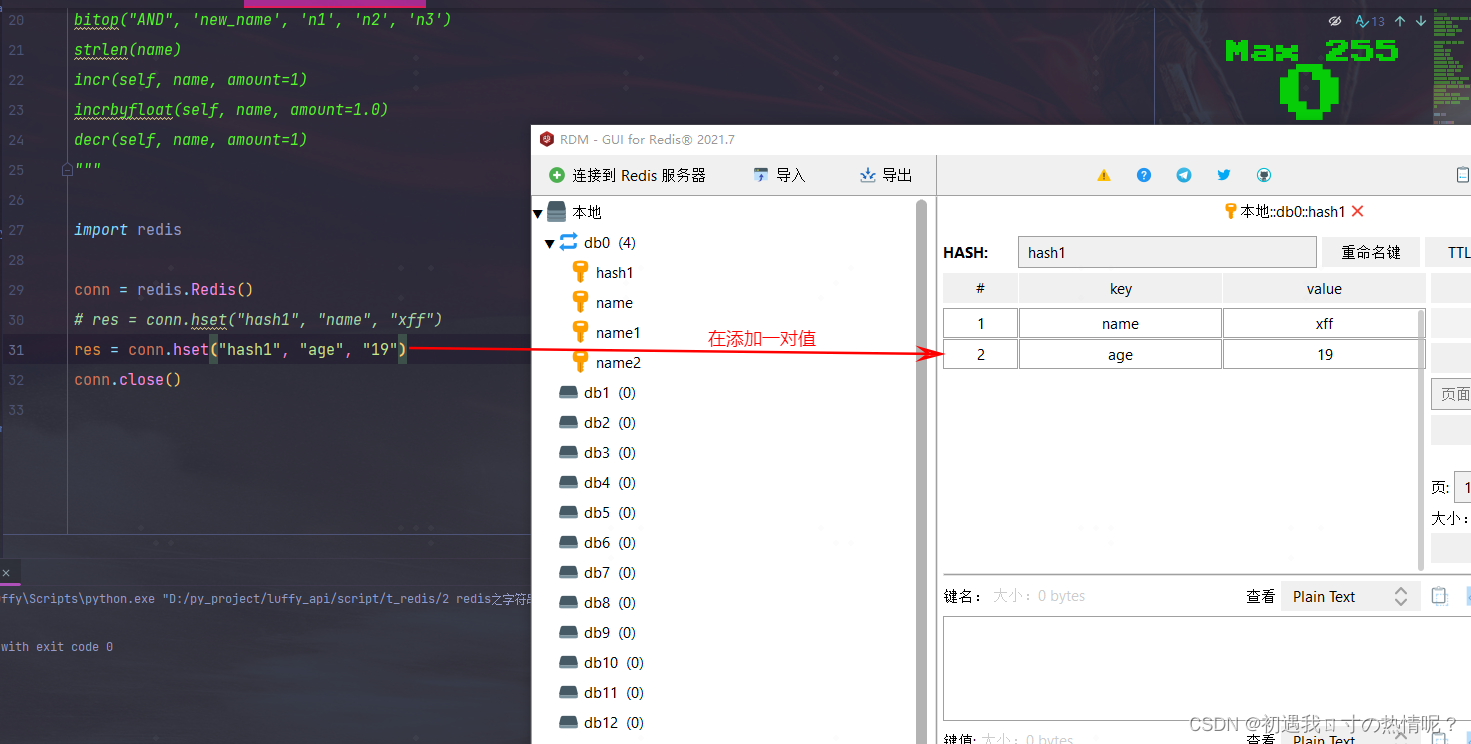
3、hmset(name, mapping)
批量的设置值
import redis
conn = redis.Redis()
res = conn.hmset("user_1_info", {"name": "lyf", "age": 19, "hobby": "篮球"})
conn.close()
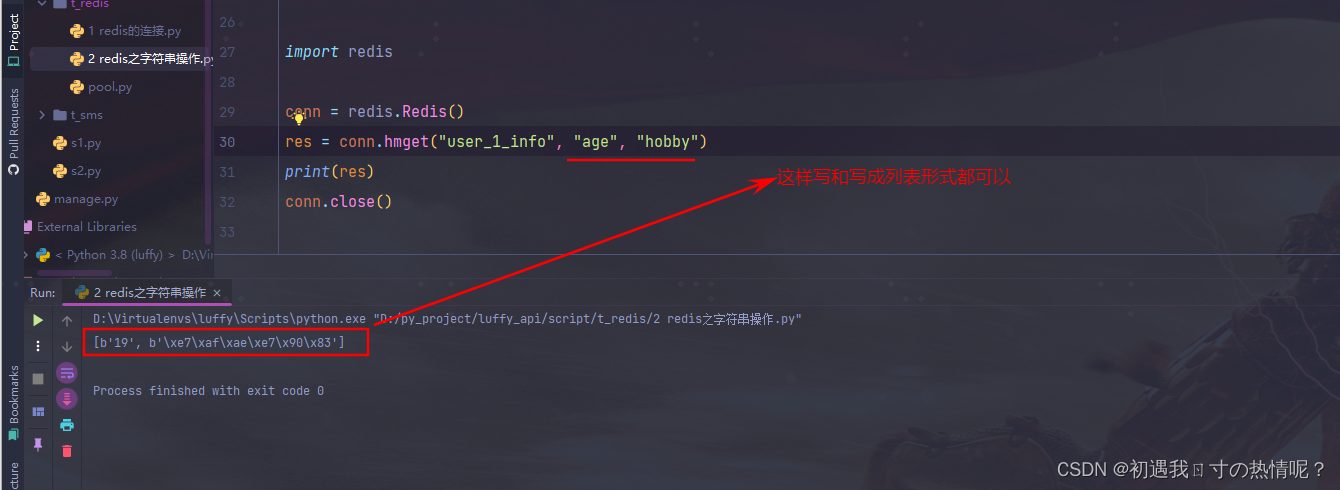
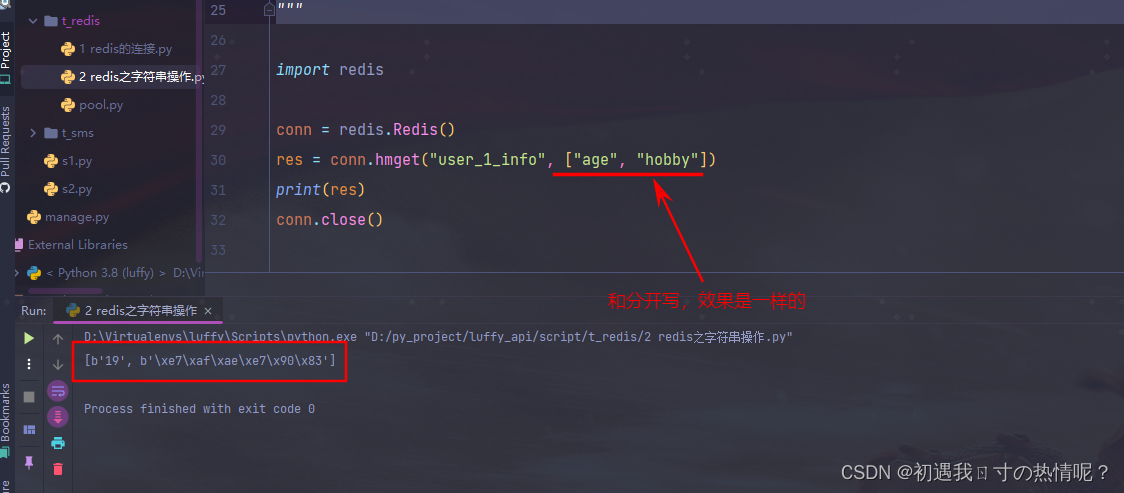
4、hmget(name, keys, *args)
批量的获取值
import redis
conn = redis.Redis()
# res = conn.hmget("user_1_info", "age", "hobby")
res = conn.hmget("user_1_info", ["age", "hobby"])
print(res)
conn.close()
5、hgetall(name)
获取所有慎用生产环境中尽量不要用数据量可能比较多
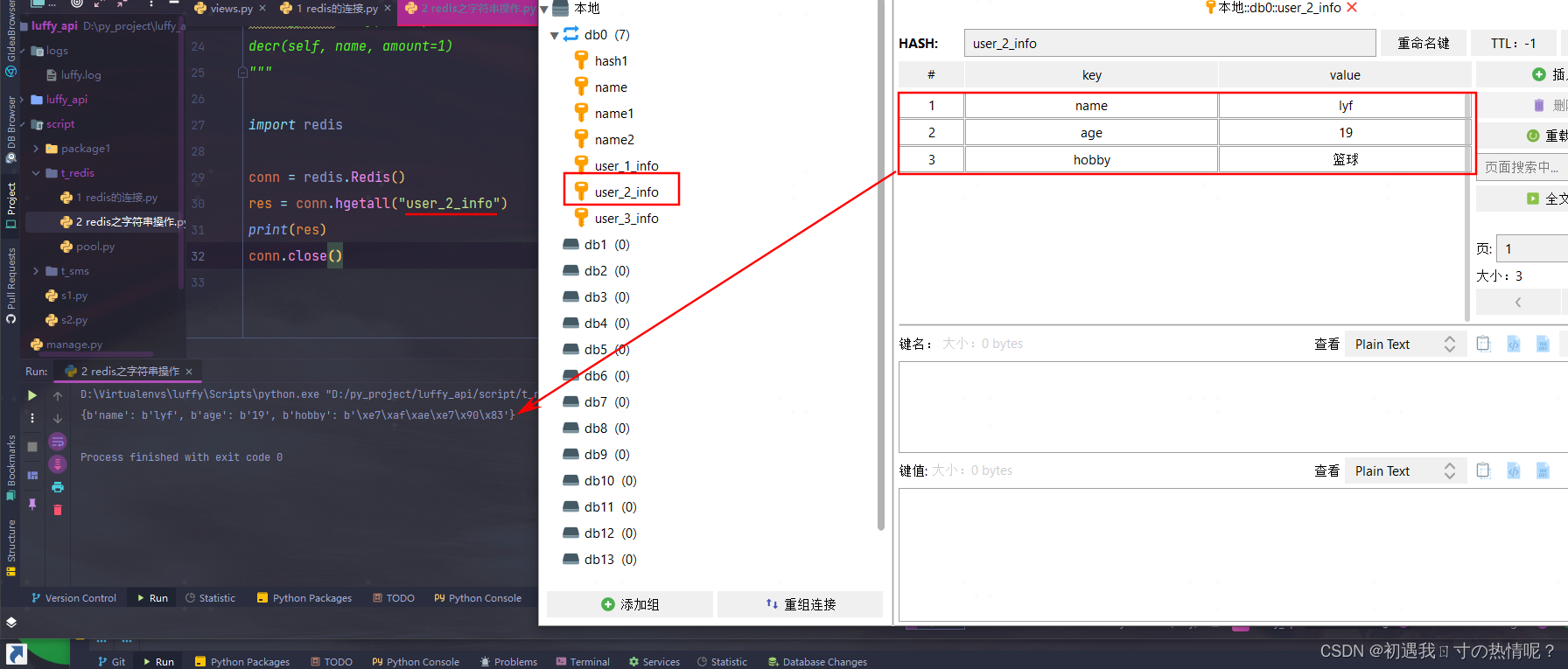
import redis
conn = redis.Redis()
res = conn.hgetall("user_2_info")
print(res)
conn.close()
6、hlen(name)
获取长度获取有多少key值
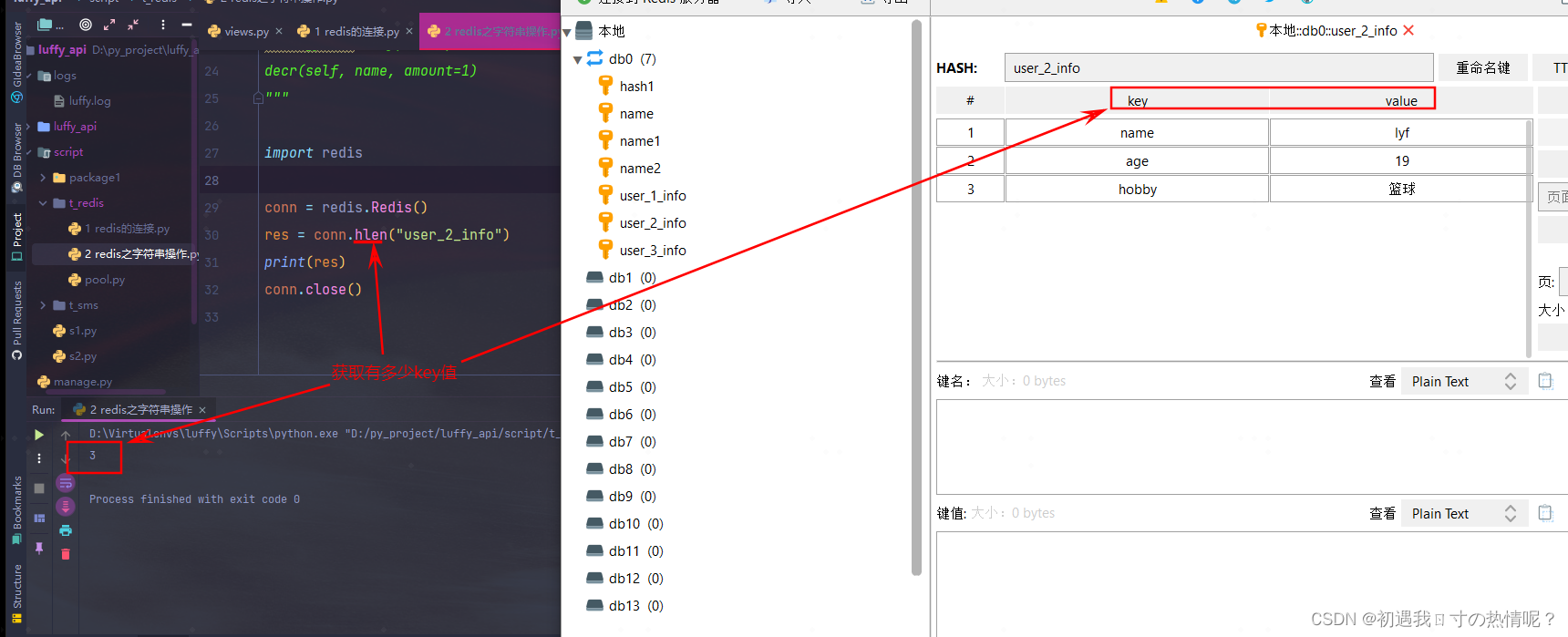
7、hkeys(name)
获取所有的key
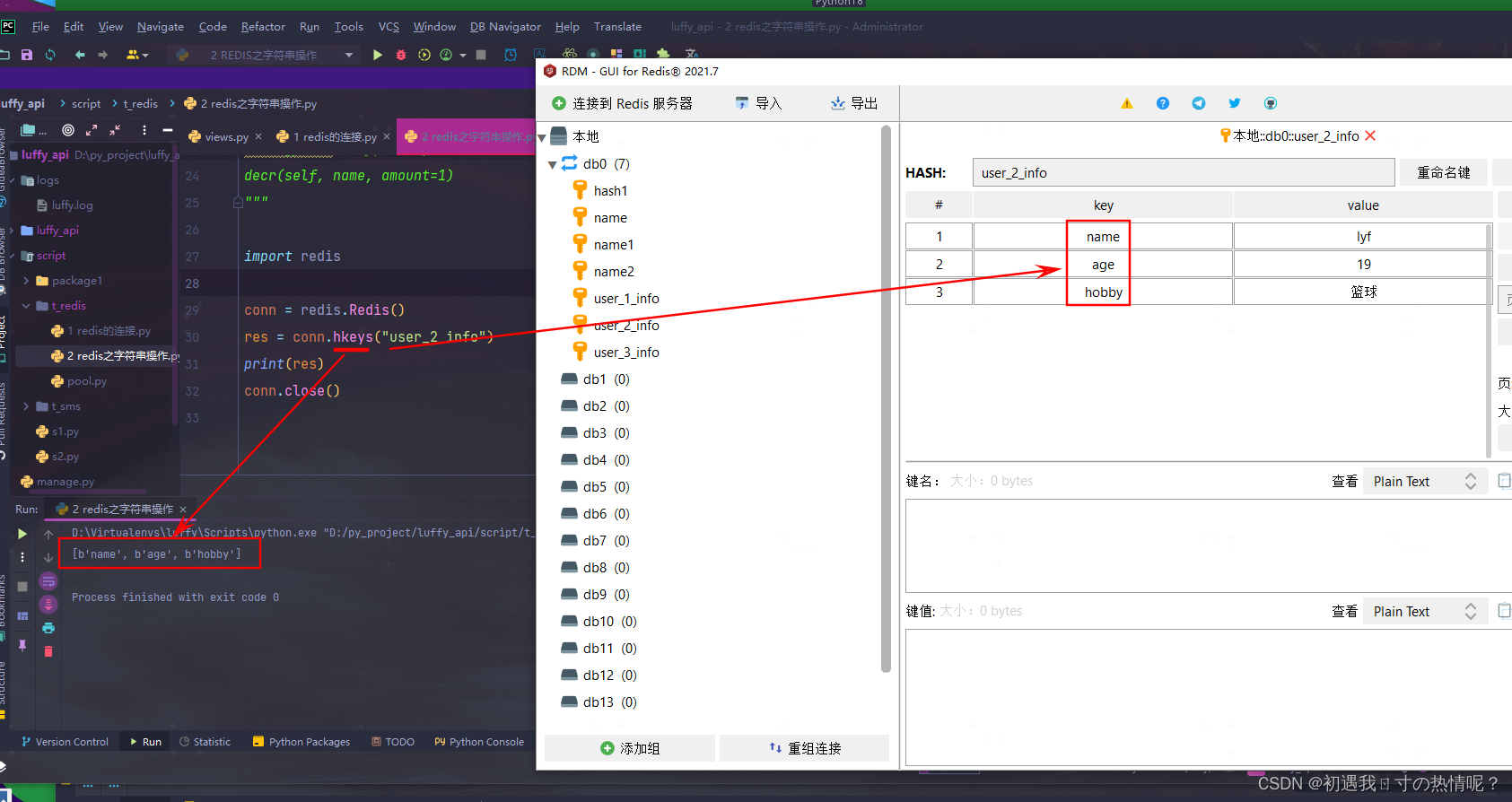
8、hvals(name)
获取所有的value
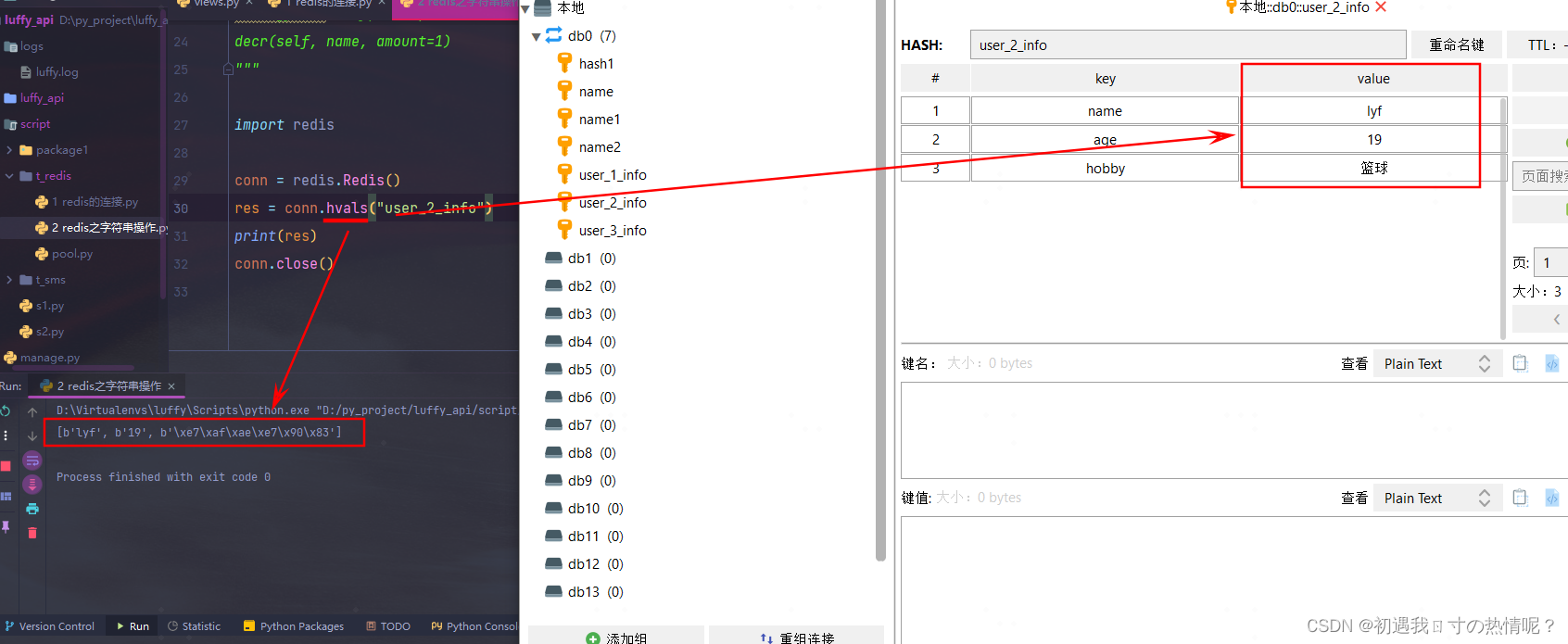
9、hexists(name, key)
判断对应的key是不是在name这个字典里面
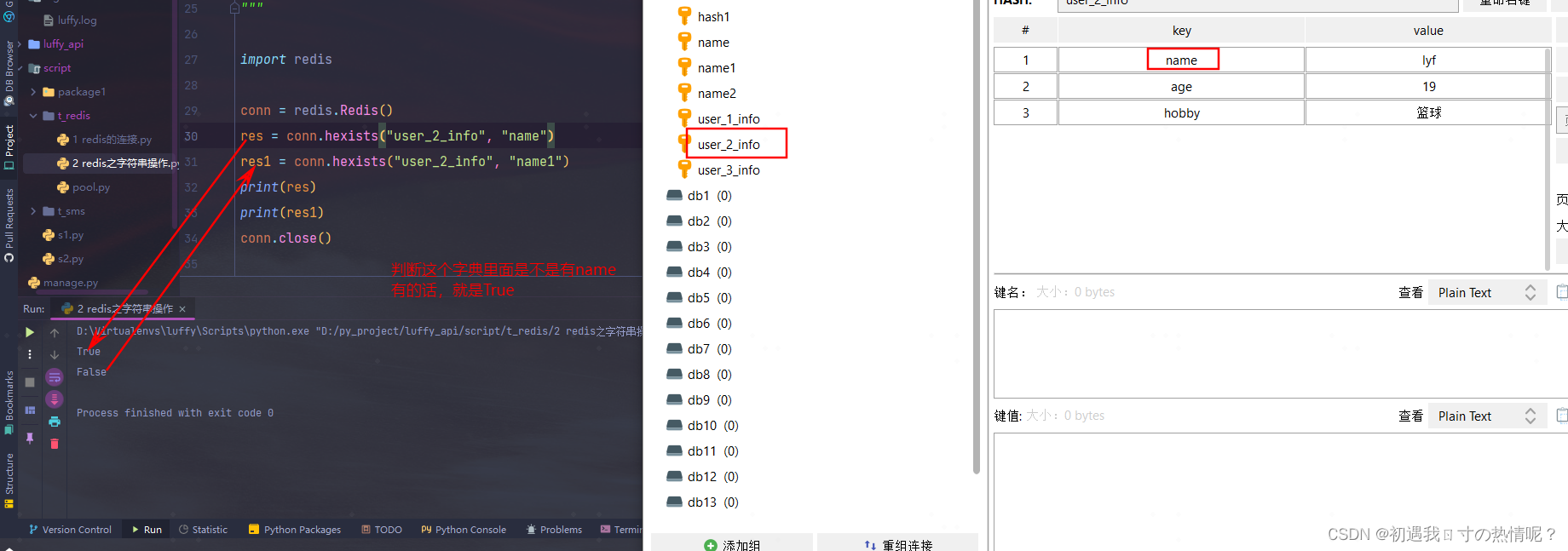
10.hdel(name,*keys)
将name对应的hash中指定key的键值对删除
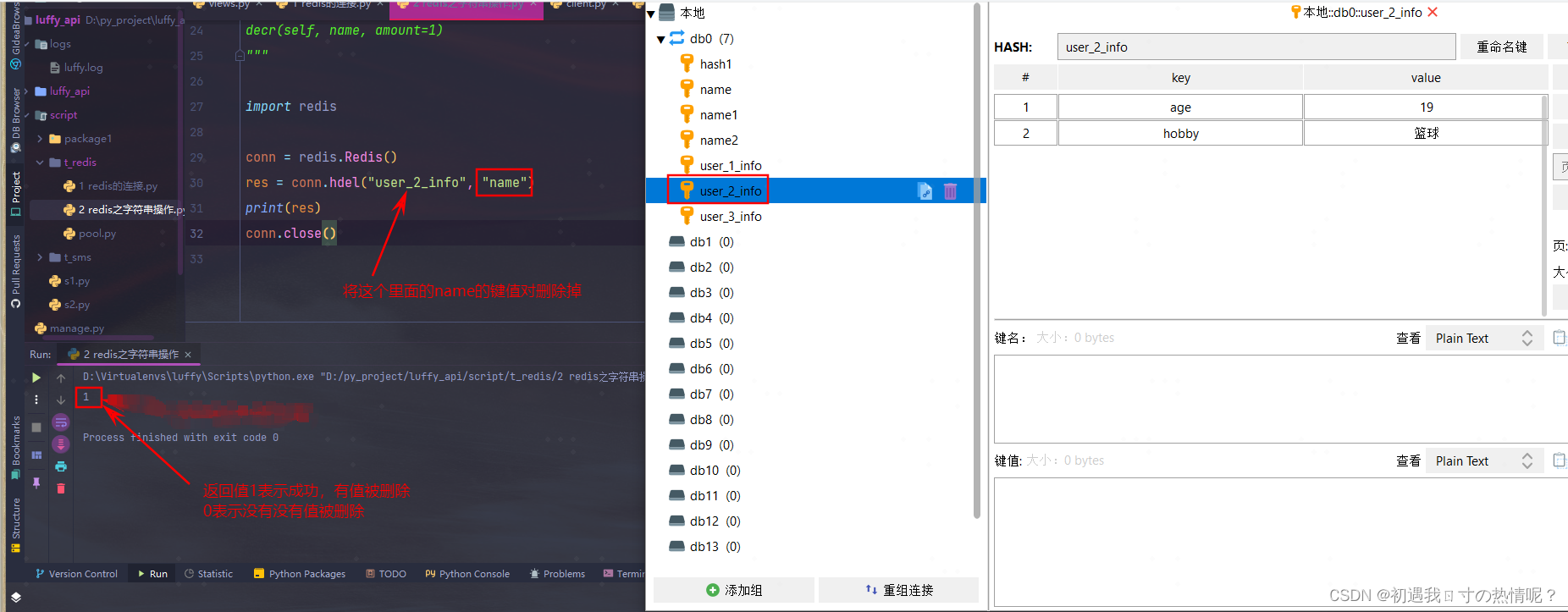
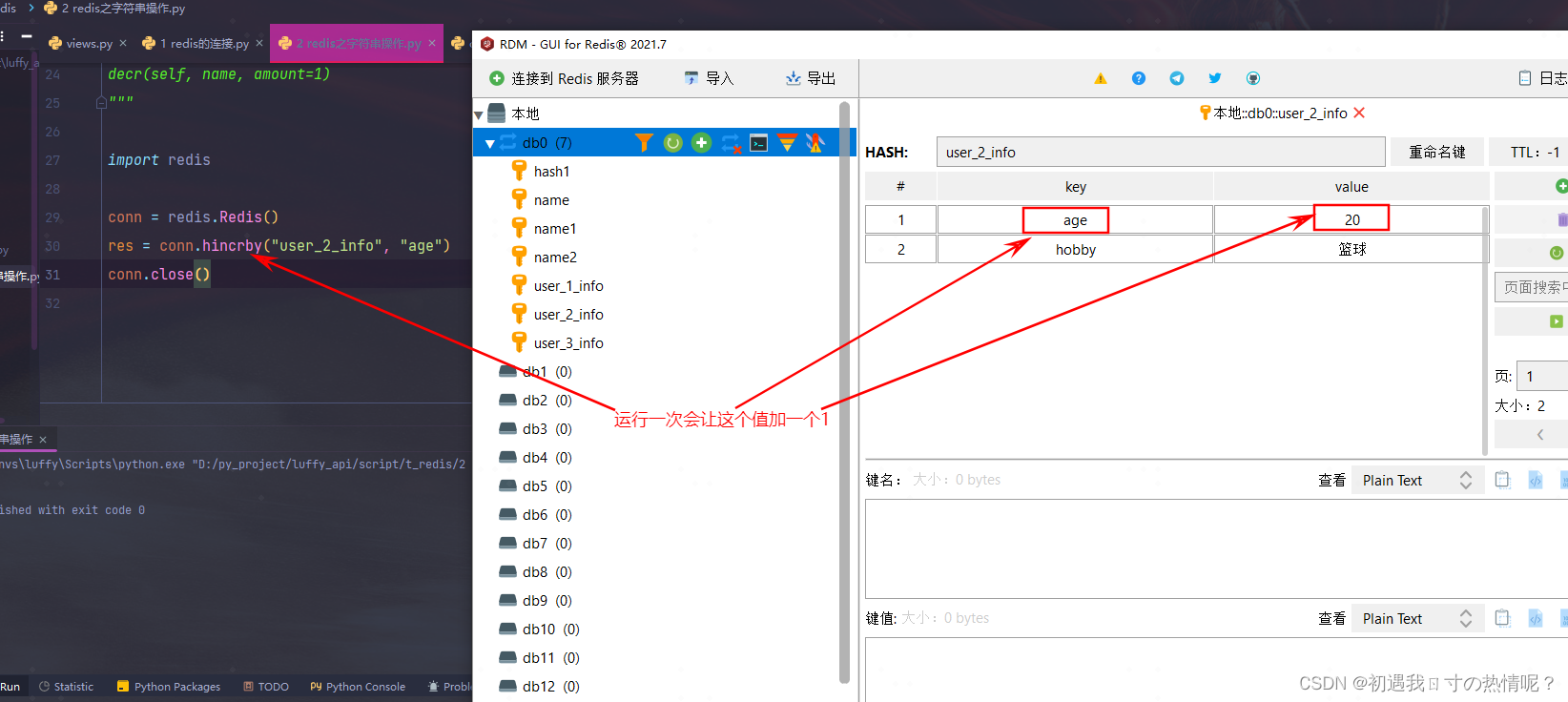
11、hincrby(name, key, amount=1)
自增name对应的hash中的指定key的值不存在则创建key=amount
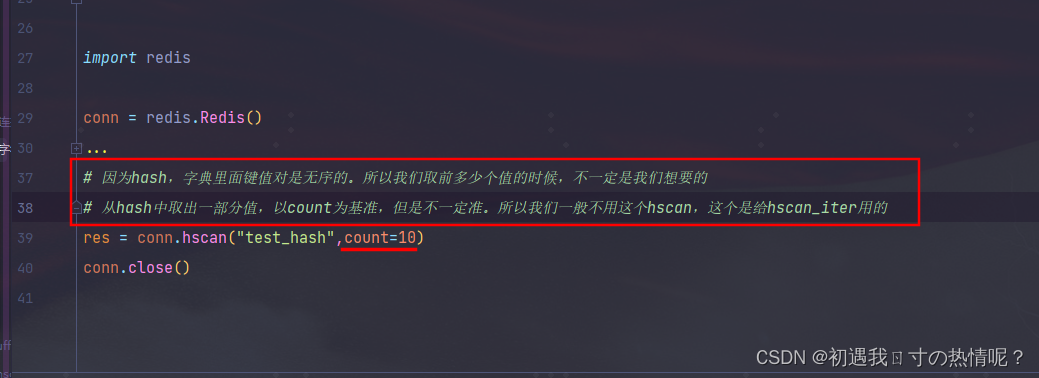
13、hscan
因为hash字典里面键值对是无序的。所以我们取前多少个值的时候不一定是我们想要的
从hash中取出一部分值以count为基准但是不一定准。所以我们一般不用这个hscan这个是给hscan_iter用的
14、hscan_iter(name, match=None, count=None)
分批获取不使用hgetall可以用hscan_iter代替
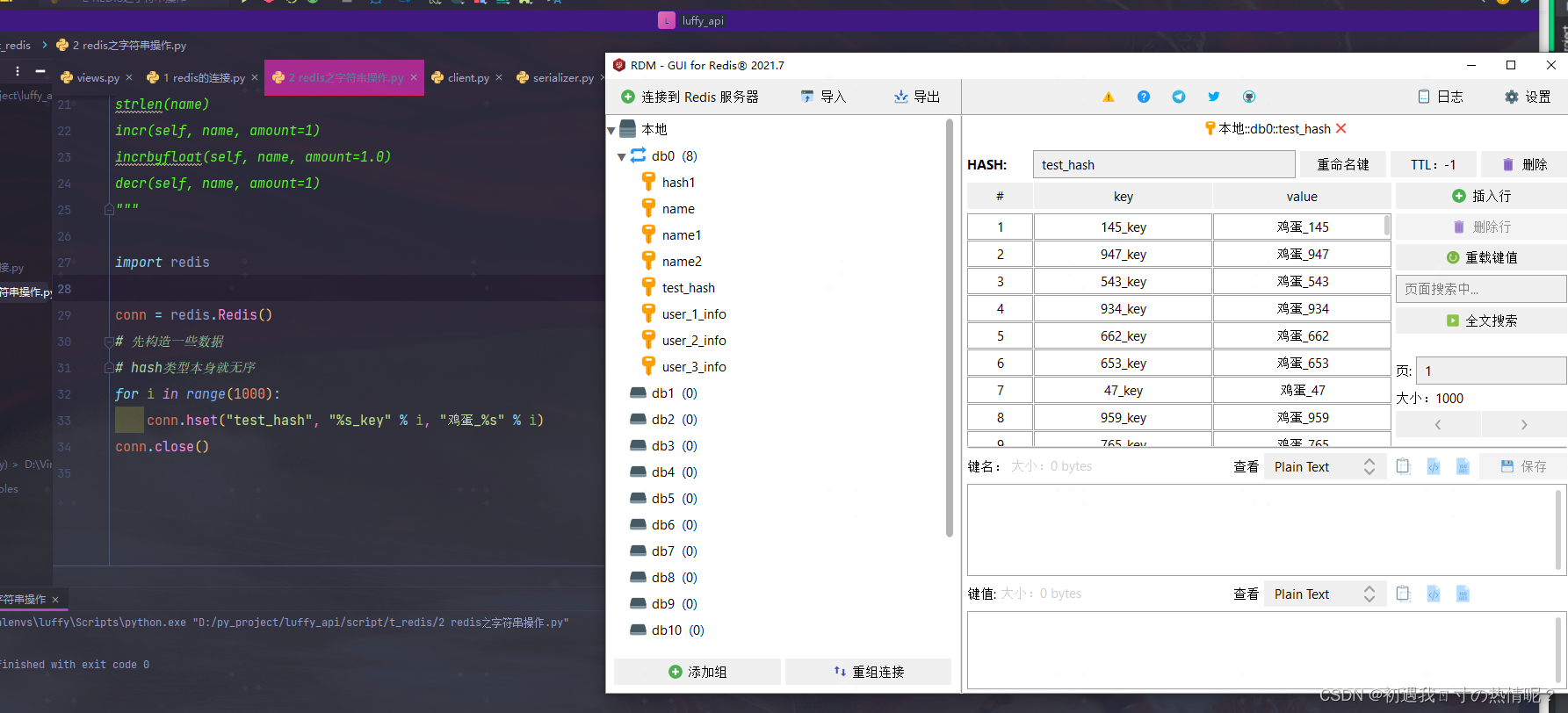
现在想要把数据取出来
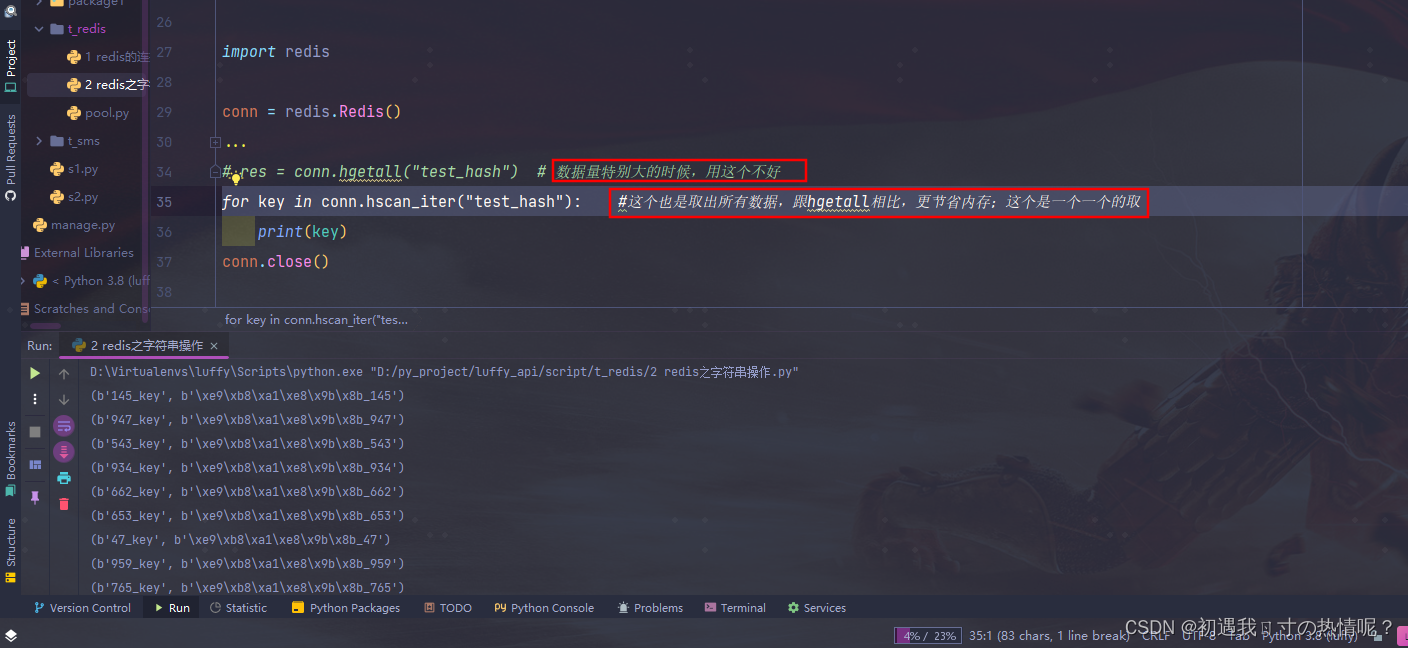
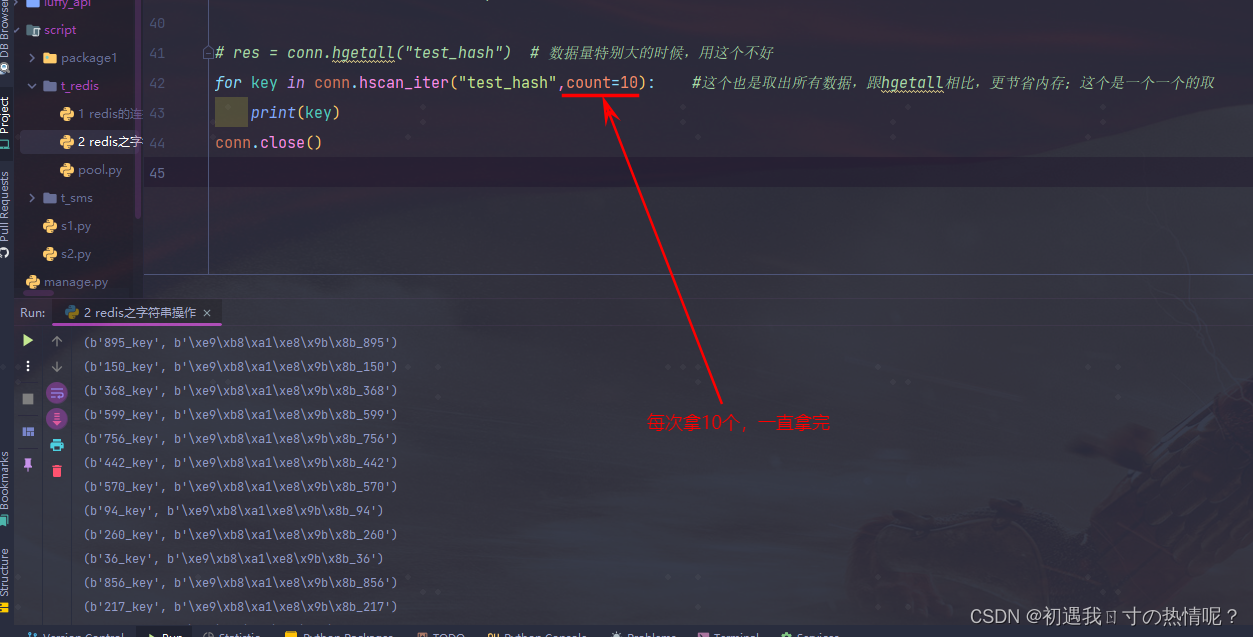
这个就是生成器的概念一次拿指定个数一直到拿完为止
记住
hset
hget
hmset
hmget
hlen
hexists
hincrby
hscan_iter分批获取数据
Python操作redis操作之list操作
lpush(name,values)
lpushx(name,value)
llen(name)
linsert(name, where, refvalue, value))
r.lset(name, index, value)
r.lrem(name, value, num)
lpop(name)
lindex(name, index)
lrange(name, start, end)
ltrim(name, start, end)
rpoplpush(src, dst)
blpop(keys, timeout)
brpoplpush(src, dst, timeout=0)
1、lpush(name,values)
在name对应的list中添加元素每个新的元素都添加到列表的最左边
如果没有name这个key会创建这个key
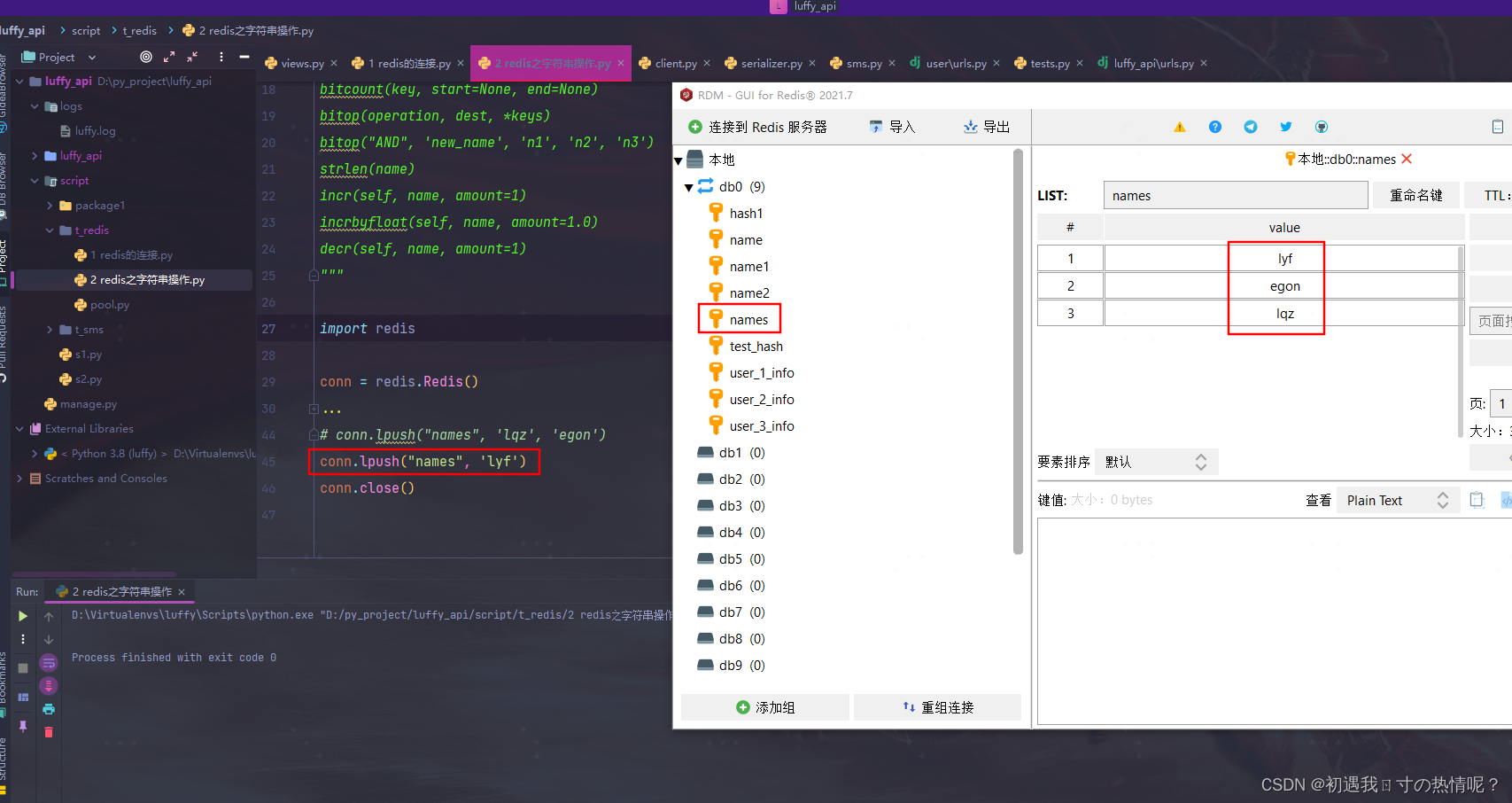
r.lpush('oo', 11,22,33)
保存顺序为: 33,22,11
2、rpush(name, values)
表示从右向左操作将数据从列表的右侧推到列表里面
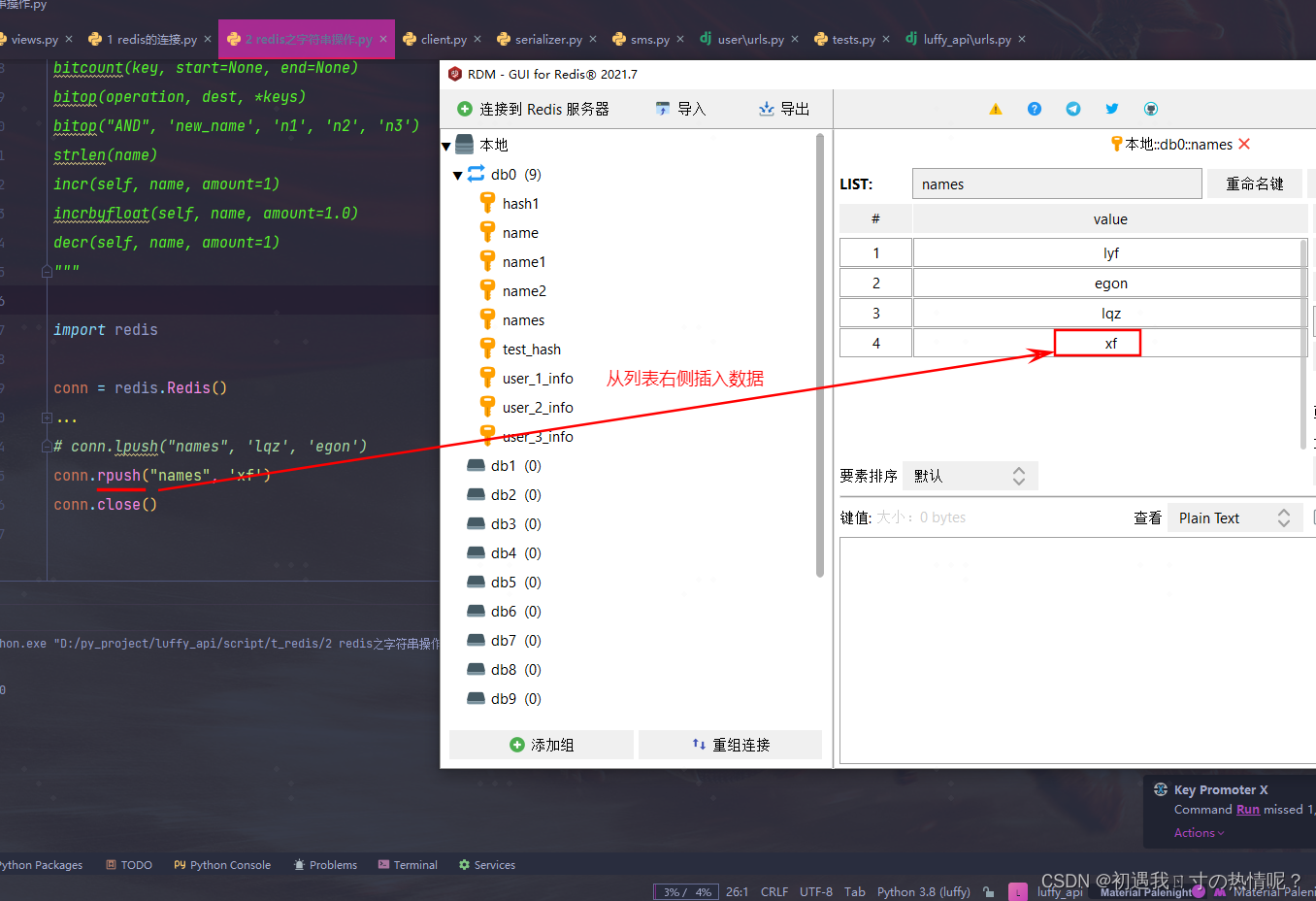
3、lpushx
只有name已经存在时值添加到列表的最左边
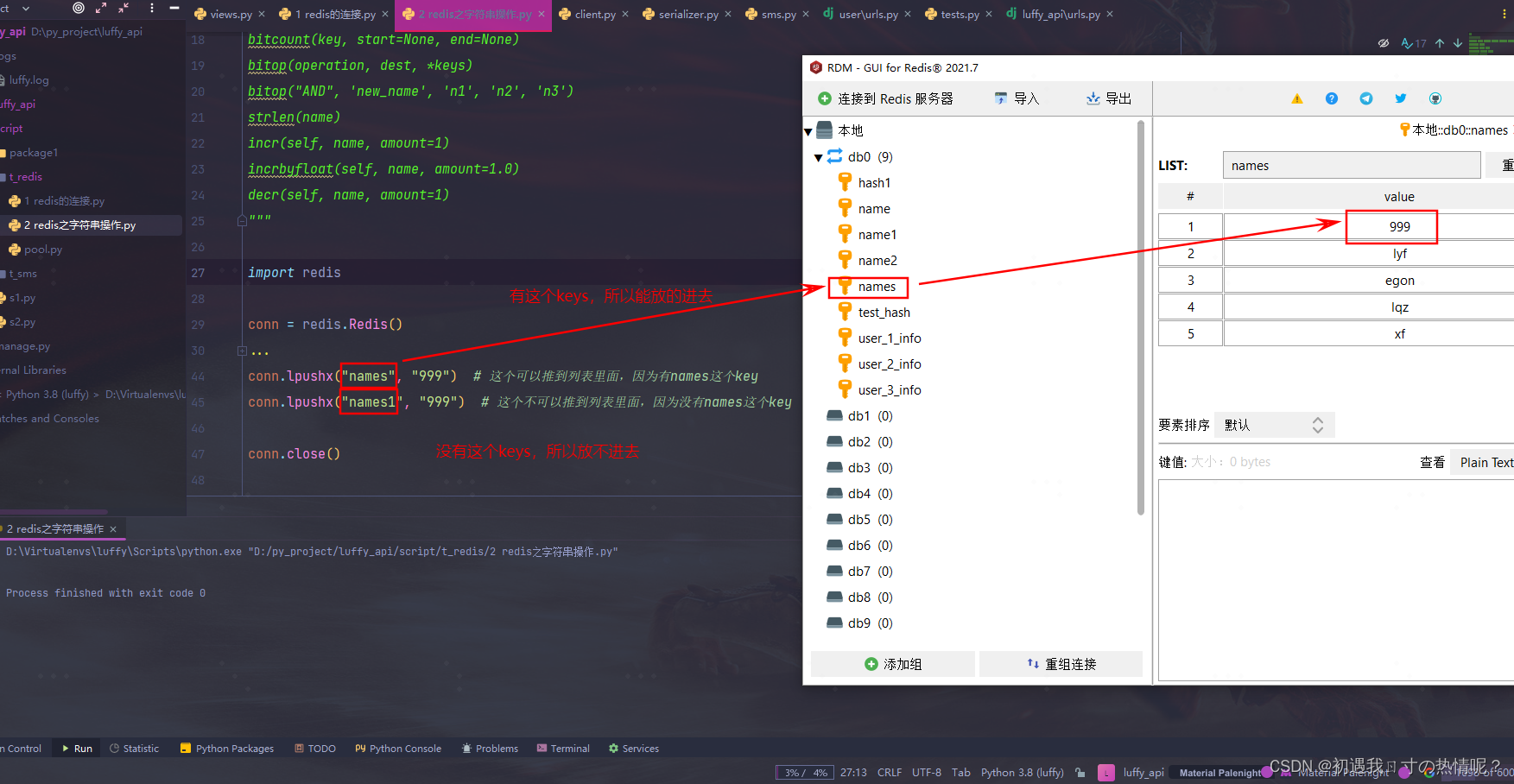
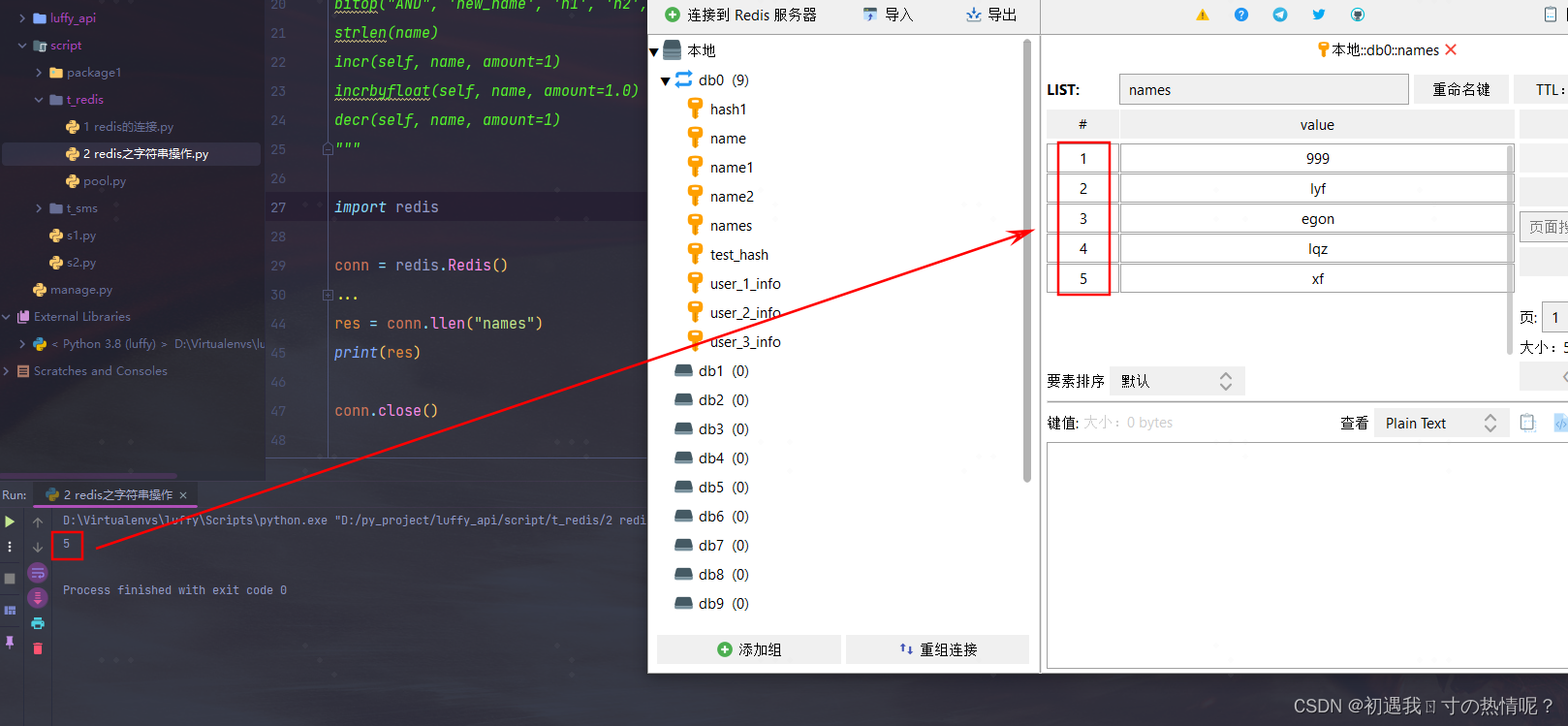
4、llen(name)
name对应的list元素的个数
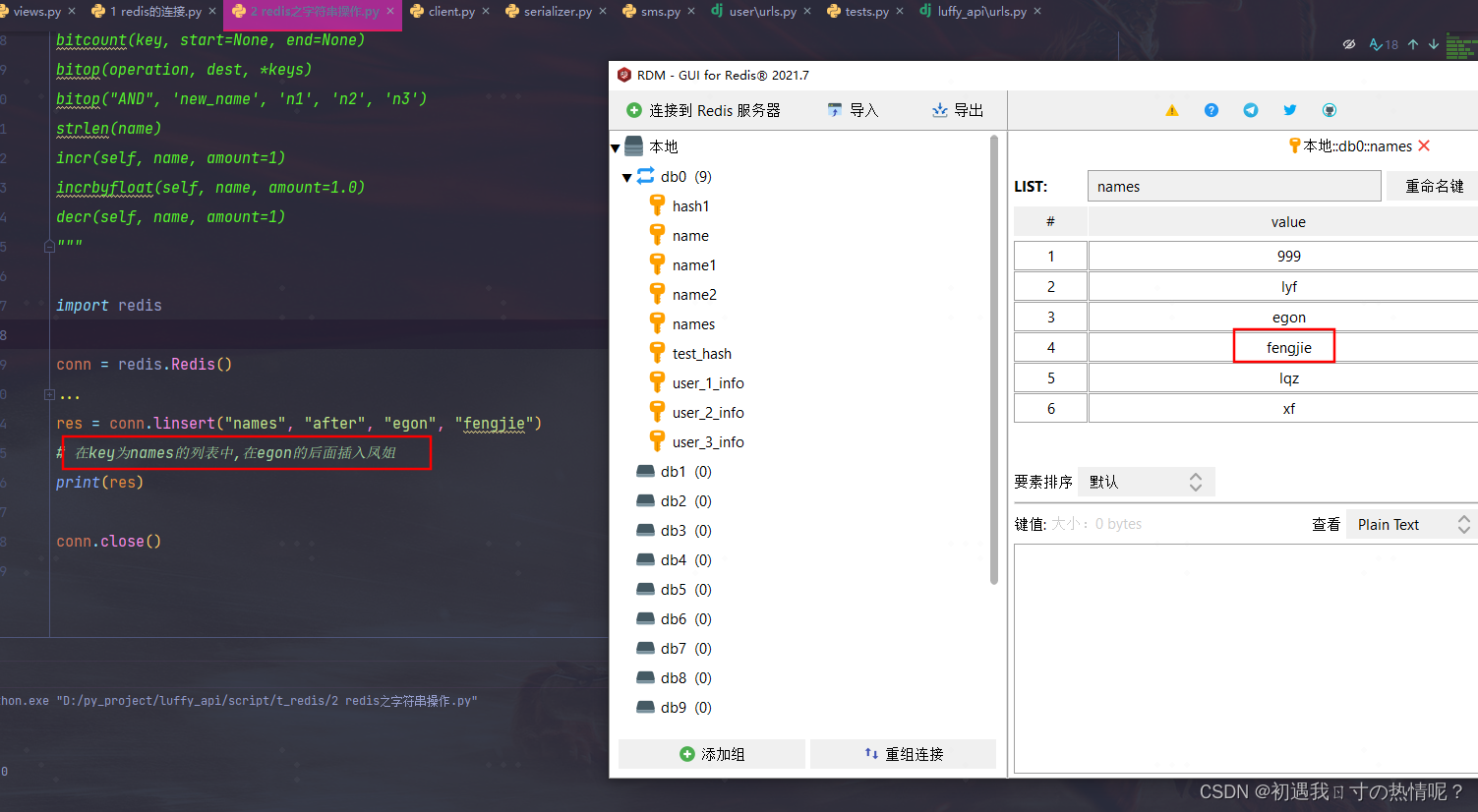
5、linsert(name, where, refvalue, value))
where只能写before 或 after
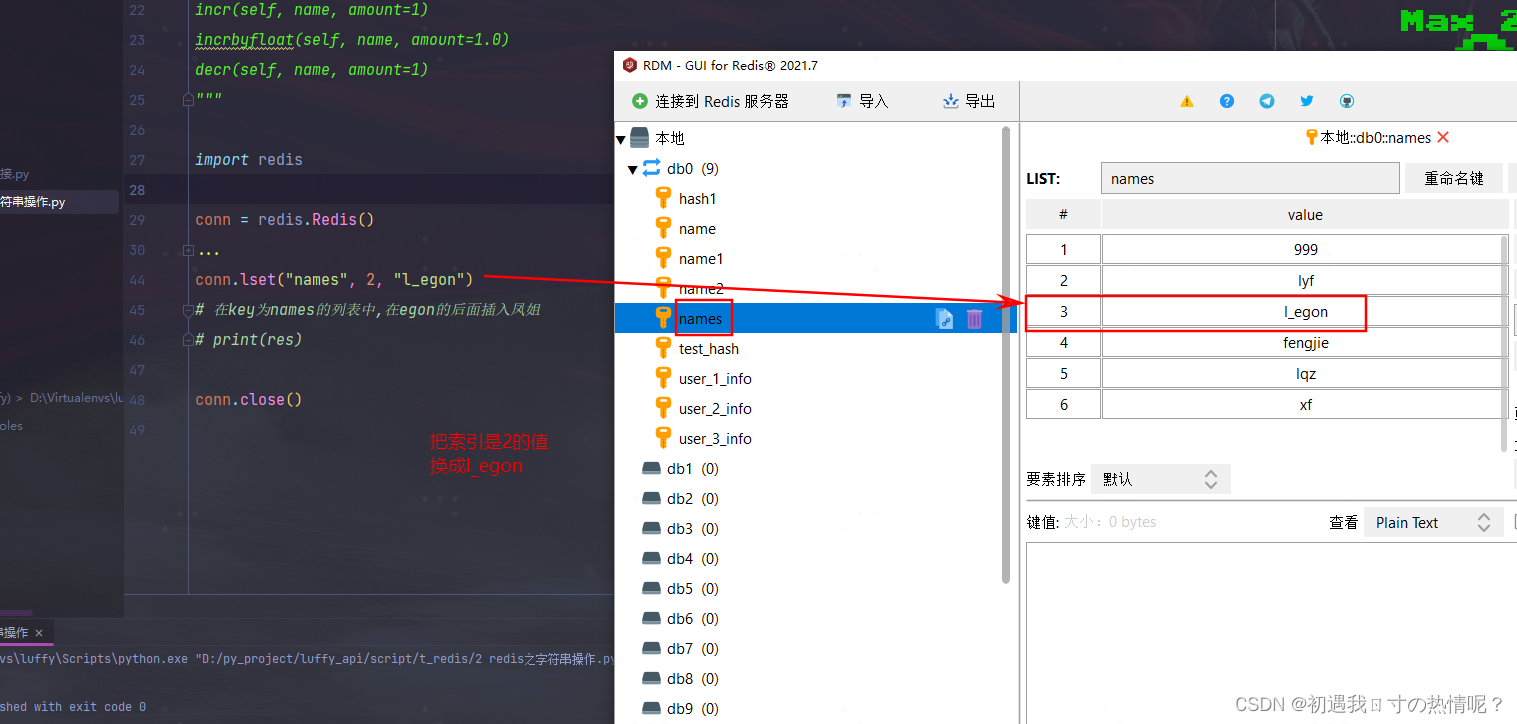
6、r.lset(name, index, value)
给某一个位置重新设置值位置是从0开始的
7、r.lrem(name, num, value)
name对应的list中删除指定的值
import redis
conn = redis.Redis()
conn.lrem("names", 0, "lqz") # 把内部所有的lqz都移除
conn.lrem("names", 1, "lqz") # 从左往右移除第一个lqz
conn.lrem("names", -1, "lqz") # 从右往左移除第一个lqz
conn.close()
8、lpop(name)
在name对应的列表的左侧获取第一个元素并在列表中移除返回值则是第一个元素
rpop(name)
表示从右向左操作
9、lindex(name, index)
获取第几个索引的值
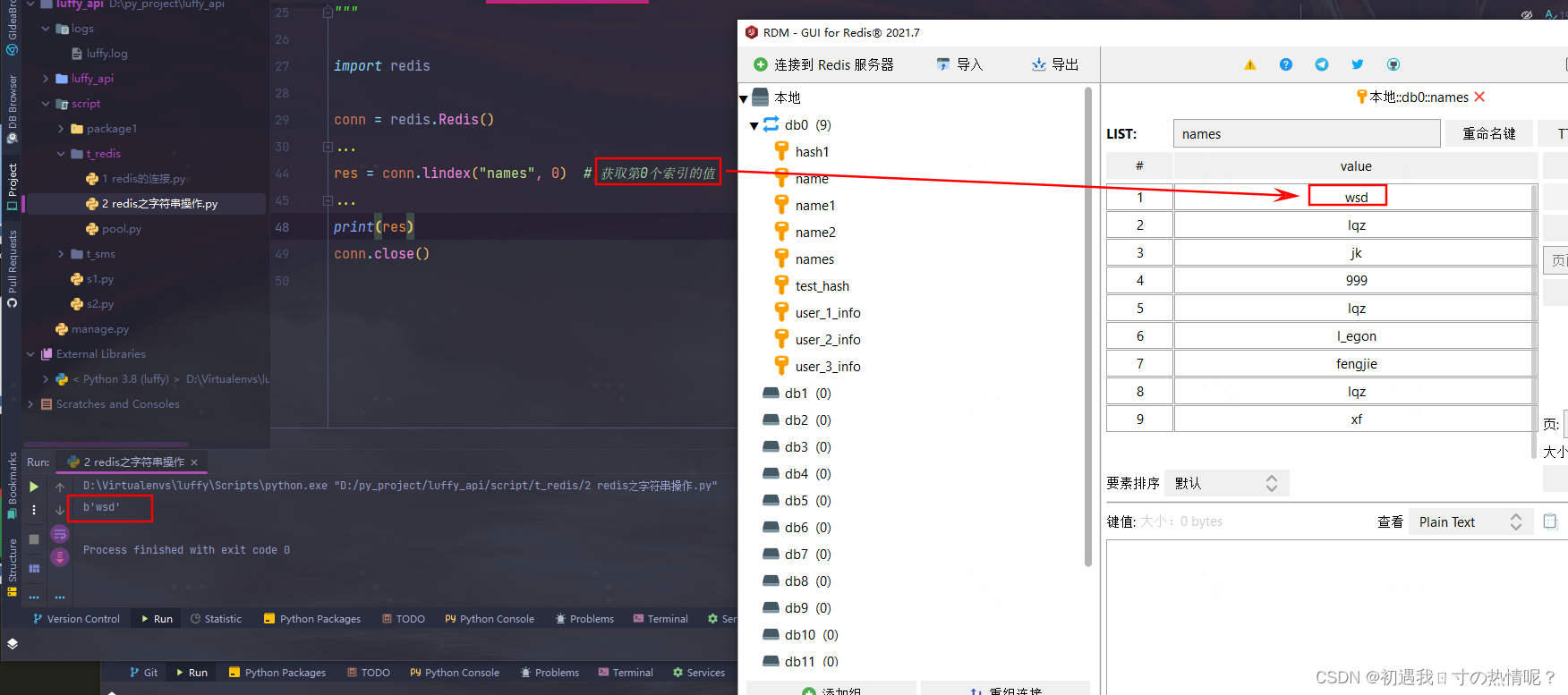
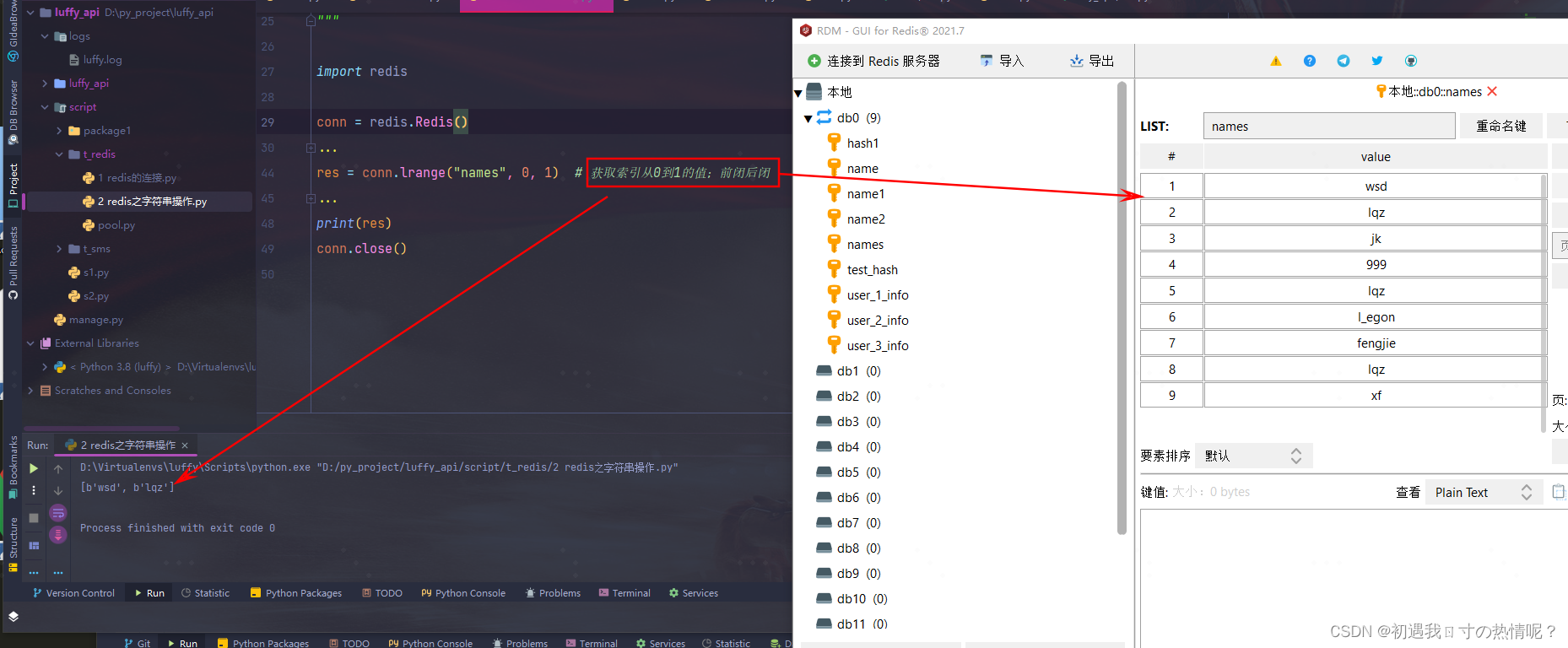
10、lrange(name, start, end)
获取从起止位置到结束位置的值前闭后闭
11、ltrim(name, start, end)
修剪

12、rpoplpush(src, dst)
从一个列表取出最右边的元素同时将其添加至另一个列表的最左边
参数
# src要取数据的列表的name
# dst要添加数据的列表的name
13、blpop(keys, timeout)
将多个列表排列按照从左到右去pop对应列表的元素
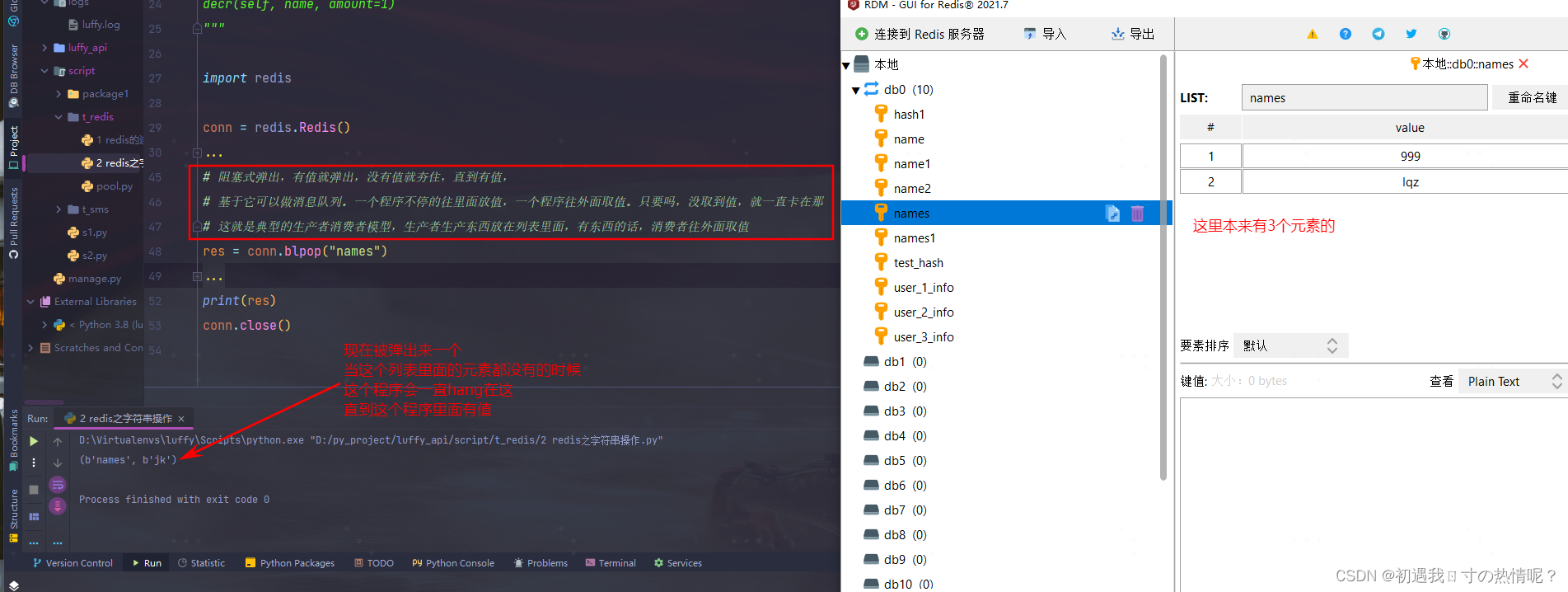
比如爬虫的时候需要爬数据在解析在入库。这个原本是一条线干的事。因为爬的很快解析的时候很慢
可以用这个方式完成分布式可以写一个程序专门负责爬然后放在队列里面另一个程序负责解析入库
redis可以实现简单的消息队列。部署在两台机器上实现IPC进程间通信
一台电脑上的进程间可以使用进程queue但如果两个进程在不同的机器上需要借助消息队列的
如果是简单的消息队列就可以使用redis的list类型
消息队列的作用就是实现扩进程间的通信
blpop(keys, timeout)后面可以设置超时时间可以指定夯住的时间
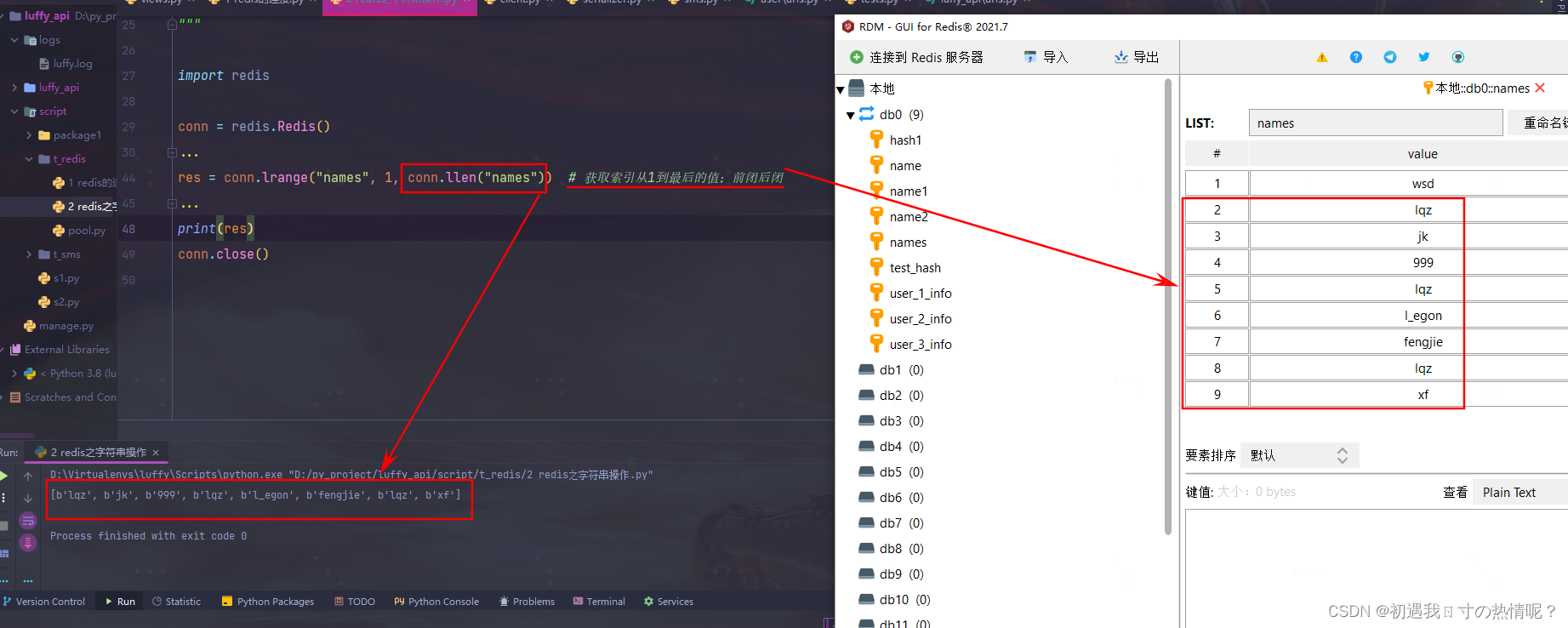
如果想一次性把列表里面的值取出来
res=conn.lrange('names',0,conn.llen('names') #这样是可以的但是如果数据大的话就比较消耗内存
还有一个就是自定义增量迭代面试题Python中生成器在哪个地方用过
import redis
conn=redis.Redis(host='127.0.0.1',port=6379)
# conn.lpush('test',*[1,2,3,4,45,5,6,7,7,8,43,5,6,768,89,9,65,4,23,54,6757,8,68])
# conn.flushall()
def scan_list(name,count=2):
index=0
while True:
data_list=conn.lrange(name,index,count+index-1)
if not data_list:
return
index+=count
for item in data_list:
yield item
print(conn.lrange('test',0,100))
for item in scan_list('test',5):
print('---')
print(item)
记住
lpush
llen
lrem
lindex
lpop
lrange
通用操作
跟类型没有关系
delete(*names)
根据key值删除redis中的任意数据类型
import redis
conn = redis.Redis()
# 删除redis中任意数据类型
conn.delete("names")
conn.close()
exists(name)
检测redis的name是否存在
import redis
conn = redis.Redis()
res = conn.exists("names")
print(res) # 1表示存在0表示不存在
conn.close()
keys(pattern=‘*’)
获取所有的key值可以过滤
import redis
conn = redis.Redis()
res = conn.keys() # 所有的key值
res = conn.keys(pattern="n*") # 所有以n开头的key值
res = conn.keys(pattern="nam?") # 所有以nam开头的,后面再接一个字符的key值
print(res)
conn.close()
expire(name ,time)
为某个redis的某个name设置超时时间
之前我们只可以给字符串设置过期时间其实所有的都可以设置过期时间
import redis
conn = redis.Redis()
res = conn.expire("name1", 5) # 将key值是name1的过期时间设置为5秒时间到了之后key和value就没有了
print(res)
conn.close()
rename(src, dst)
对redis的key值重命名为
import redis
conn = redis.Redis()
res = conn.rename("name1", "name2") # 将key值为name1设置为name2
print(res)
conn.close()
move(name, db)
将redis的某个值移动到指定的db下
import redis
conn = redis.Redis()
res = conn.move("hash1", 5) # 将key值为hash1移动到db5里面
print(res)
conn.close()
randomkey()
随机获取一个redis里面的一个key不删除
import redis
conn = redis.Redis()
res = conn.randomkey() # 随机弹出一个key值
print(res)
conn.close()
type(name)
查看key对应的value的类型
import redis
conn = redis.Redis()
res = conn.type("test_hash") # 获取test_hash对应的value的类型
print(res)
conn.close()
redis管道
redis是非关系型数据库不支持事务
但是redis有管道我们可以通过管道来模拟事务要么都成功要么都失败
import redis
conn = redis.Redis()
# 创建一个管道
pipe = conn.pipeline(transaction=True)
# 开启事务
pipe.multi()
# 向管道中放入命令
pipe.decrby('egon_money', 50) # 将egon_money对应的value减去50元
# 向管道中放入命令
pipe.incrby('lqz_money', 50) # 将lqz_money对应的value加上50元
# 上面这两个是一个事务同时执行要么成功、要么失败
pipe.execute() # 执行这一句话的时候上面的两天命令同时执行
django中使用redis
1、通用方案跟django没有关系
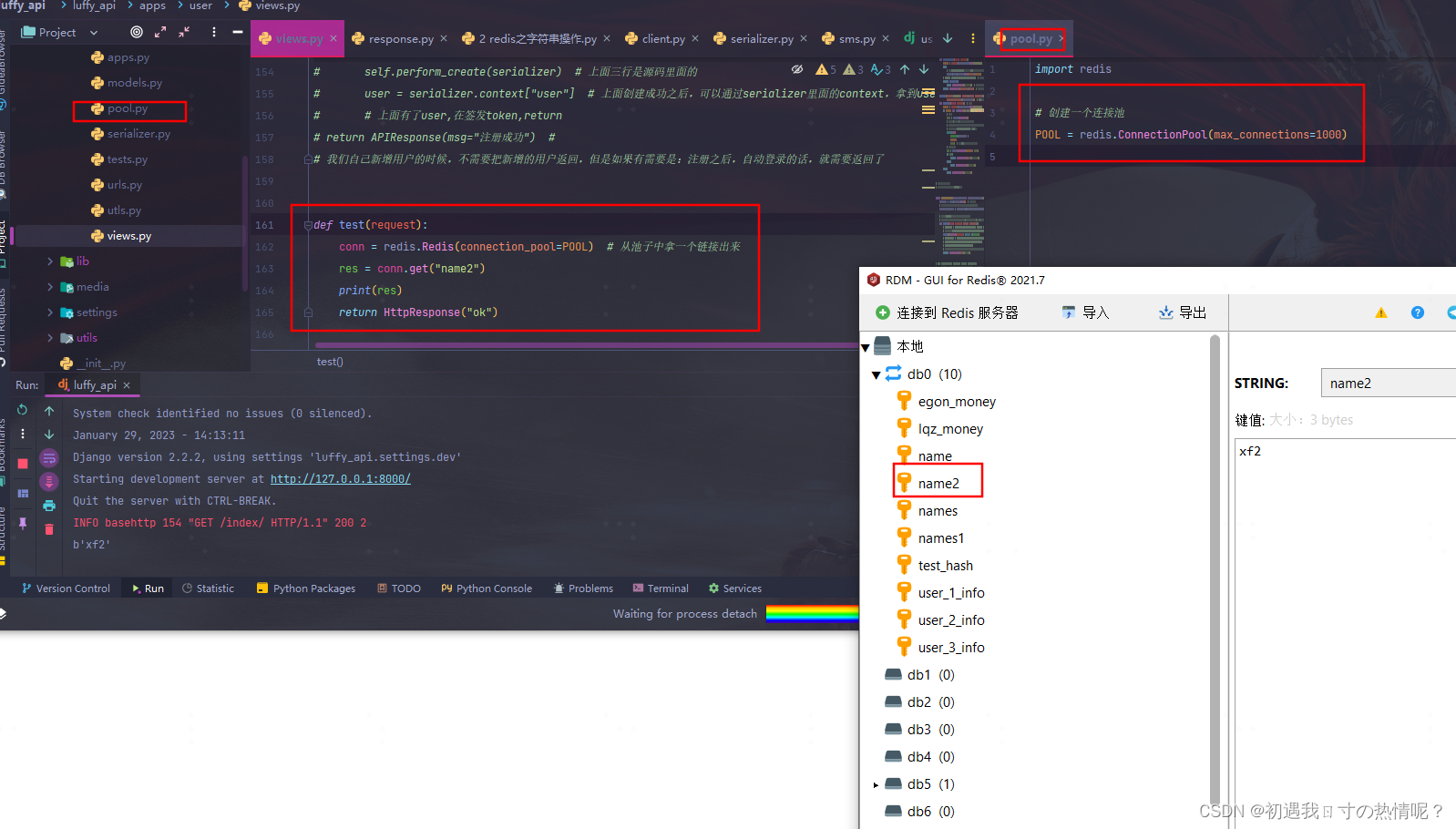
pool.py
import redis
# 创建一个连接池
POOL = redis.ConnectionPool(max_connections=1000)
在用的地方
import redis
from .pool import POOL
def test(request):
conn = redis.Redis(connection_pool=POOL) # 从池子中拿一个链接出来
res = conn.get("name2")
print(res)
return HttpResponse("ok")
2、django方案用第三方方案
1、安装django-redis模块
pip install django-redis
2、setting中配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379", # redis链接地址根据实际情况改
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100} # 连接池大小
# "PASSWORD": "123", #redis有密码的话配置出密码
}
}
}
3、使用
from django_redis import get_redis_connection
def test(request):
conn = get_redis_connection() # 从池子中拿一个链接出来
res = conn.get("name2")
print(res)
return HttpResponse("ok")
一旦使用了第二种后续的django的缓存都缓存到redis中
之前的cache.set("name","xxx")就缓存到redis中了
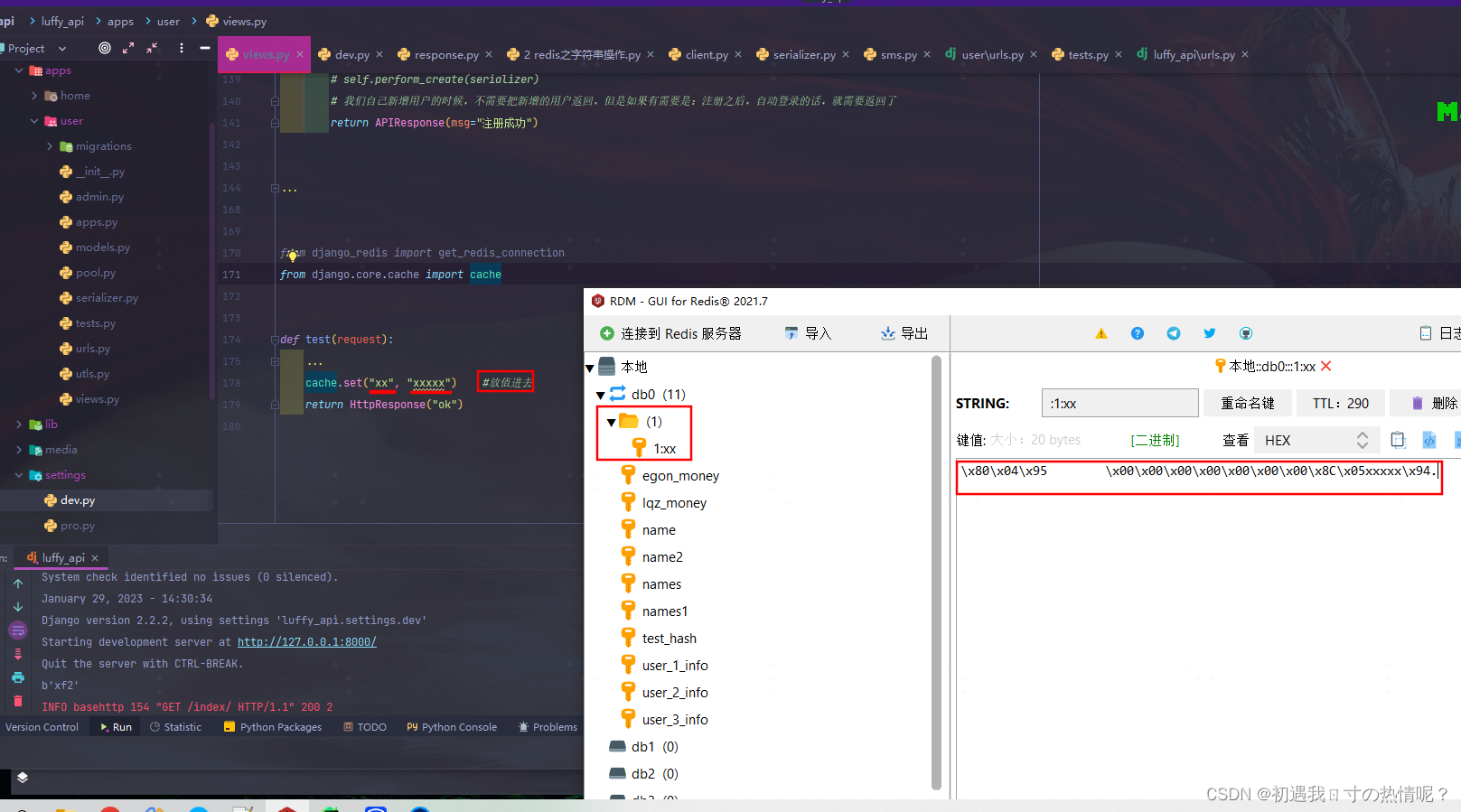
所以我们上面写的验证码的功能代码都不需要改直接就缓存到redis中了
上面图中value的值是“乱码”
因为django的缓存比较高级可以缓存Python中所有的数据类型。包括对象如request对象
django把对象通过pickle序列化成二进制存到redis的字符串中
拿出来之后再用pickle反序列化成对象。所以用cache比conn.set之内的好很多只管存只管取。不需要管什么类型了