

机器学习中的数据预处理方法与步骤
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
数据预处理是准备原始数据并使其适用于机器学习模型的过程。这是创建机器学习模型的第一步也是至关重要的一步。
在创建机器学习项目时我们并不总是遇到干净且格式化的数据。并且在对数据进行任何操作时必须对其进行清理并以格式化的方式放置。所以为此我们使用数据预处理任务。
为什么我们需要数据预处理
真实世界的数据通常包含噪声、缺失值并且可能采用无法直接用于机器学习模型的不可用格式。数据预处理是清理数据并使其适用于机器学习模型的必要任务这也提高了机器学习模型的准确性和效率。
它涉及以下步骤
- 获取数据集
- 导入相关库
- 导入数据集
- 查找缺失的数据
- 编码分类数据
- 将数据集拆分为训练集和测试集
- 特征缩放
一、获取数据集
要创建机器学习模型我们需要的第一件事是数据集因为机器学习模型完全适用于数据。以适当格式收集的特定问题的数据称为数据集。
数据集可能有不同的格式用于不同的目的例如如果我们想为商业目的创建关于肝病患者的机器学习模型那么数据集将是肝病患者所需的数据集。数据集我们通常将其放入 CSV文件中。但是有时我们可能还需要使用 HTML 或 xlsx 文件。
什么是 CSV 文件CSV 代表“逗号分隔值”文件它是一种文件格式允许我们保存表格数据例如电子表格。它对于庞大的数据集很有用并且可以在程序中使用这些数据集。
二、导入常见库
为了使用 Python 进行数据预处理我们需要导入一些预定义的 Python 库。这些库用于执行一些特定的工作。我们将使用三个特定的库进行数据预处理它们是
- numpy
- matplotlib
- pandas
三、导入数据集
3.1 读取数据
一般使用pandas来读取文件
data_set = pd .read_csv('Dataset.csv')
data_set是存储数据集的变量的名称在函数内部我们传递了数据集的名称。一旦我们执行了上面这行代码它将成功地在我们的代码中导入数据集。
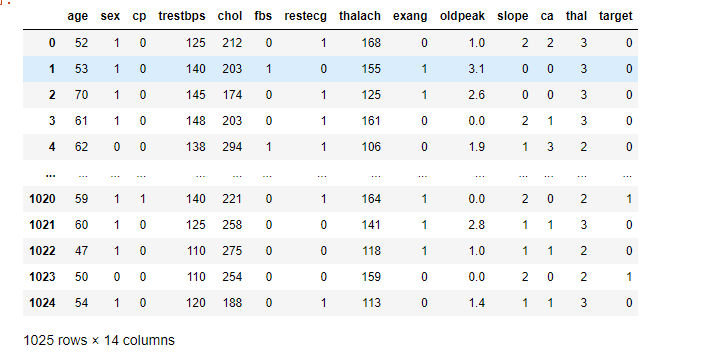
这里以心脏病数据集为例
import pandas as pd
data=pd.read_csv('heart.csv')
data
读取如下
3.2提取因变量和自变量
在机器学习中区分特征矩阵自变量和因变量与数据集很重要。在我们的数据集中有三个自变量age,sex…其中target是因变量。
提取自变量
x= data.iloc[:,:-1].values
x
如下

为了提取自变量我们将使用Pandas 库的iloc[ ]方法。它用于从数据集中提取所需的行和列。在上面的代码中第一个冒号(😃 用于获取所有行第二个冒号(😃 用于获取所有列。这里我们使用了:-1因为我们不想取最后一列因为它包含因变量。因此通过这样做我们将获得特征矩阵。
提取因变量
为了提取因变量我们将再次使用 Pandas .iloc[] 方法:
y = data .iloc[:,-1].values
y
在这里我们只取了最后一列的所有行。它将给出因变量数组。输出为
array([0, 0, 0, ..., 0, 1, 0], dtype=int64)
3.3 处理缺失数据
数据预处理的下一步是处理数据集中缺失的数据。如果我们的数据集包含一些缺失的数据那么它可能会给我们的机器学习模型带来巨大的问题。因此有必要处理数据集中存在的缺失值。
处理缺失数据的方法 处理缺失数据主要有两种方式分别是
- 通过删除特定的行第一种方法通常用于处理空值。这样我们只需删除包含空值的特定行或列。但这种方式效率不高删除数据可能会导致信息丢失无法给出准确的输出。
- 通过计算平均值通过这种方式我们将计算包含任何缺失值的列或行的平均值并将其放在缺失值的位置。这种策略对于具有数字数据的特征很有用例如年龄、薪水、年份等。在这里我们将使用这种方法。
依然是处理心脏病数据集如下
from sklearn.impute import SimpleImputer
import numpy as np
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputerimputer= imputer.fit(x[:, 1:12])
x[:, 1:12]= imputer.transform(x[:, 1:12])
x
输出为
array([[52., 1., 0., ..., 2., 2., 3.],
[53., 1., 0., ..., 0., 0., 3.],
[70., 1., 0., ..., 0., 0., 3.],
...,
[47., 1., 0., ..., 1., 1., 2.],
[50., 0., 0., ..., 2., 0., 2.],
[54., 1., 0., ..., 1., 1., 3.]])
3.4 编码分类数据
为了便于介绍这个编码分类这里我随意构造了一个数据集
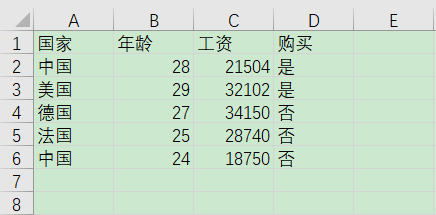
读取
import pandas as pd
data=pd.read_csv('ceshi.csv',encoding='gbk')
x= data.iloc[:,:-1].values
y = data .iloc[:,-1].values
x
如下
array([['中国', 28, 21504],
['美国', 29, 32102],
['德国', 27, 34150],
['法国', 25, 28740],
['中国', 24, 18750]], dtype=object)
查看目标y
array(['是', '是', '否', '否', '否'], dtype=object)
这里没有缺失值就不用处理了但是为了演示这个过程我还是假装有缺失值来处理下
from sklearn.impute import SimpleImputer
import numpy as np
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputerimputer= imputer.fit(x[:, 1:2])
x[:, 1:2]= imputer.transform(x[:, 1:2])
x
输出为
array([['中国', 28.0, 21504],
['美国', 29.0, 32102],
['德国', 27.0, 34150],
['法国', 25.0, 28740],
['中国', 24.0, 18750]], dtype=object)
可以看到处理与未处理之间是没有变化的因为这个方法是用均值处理填充缺失值。
现在开始讲编码分类分类数据是具有某些类别的数据例如在我们的数据集中有两个分类变量国家和购买
由于机器学习模型完全适用于数学和数字但如果我们的数据集有一个分类变量字符那么在构建模型时可能会产生麻烦。因此有必要将这些分类变量编码为数字。这就是为啥需要编码。
对于国家变量
首先我们将国家变量转换为分类数据。为此我们将使用preprocessing库中LabelEncoder()类
from sklearn.preprocessing import LabelEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
x
输出为
array([[0, 28.0, 21504],
[3, 29.0, 32102],
[1, 27.0, 34150],
[2, 25.0, 28740],
[0, 24.0, 18750]], dtype=object)
可以看到国家这里被编码成了0123三个数字表示三种。如果这些国家有重复数字就会重复。第一个国家与第五个国家都是中国编码后数字都是0。
对于购买变量
同样的到底对其进行编码
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
y
输出为
array([1, 1, 0, 0, 0])
可以看到”是“被编码为1”否“被编码为0。因为购买的变量只有两个类别是或否所以自动编码为 0 和 1。
四、将数据集拆分为训练集和测试集
在机器学习数据预处理中我们将数据集分为训练集和测试集。这是数据预处理的关键步骤之一因为通过这样做我们可以提高机器学习模型的性能。
假设如果我们通过一个数据集对我们的机器学习模型进行了训练并且我们通过一个完全不同的数据集对其进行了测试。然后这会给我们的模型理解模型之间的相关性带来困难。
如果我们训练我们的模型非常好并且它的训练精度也非常高但是我们给它提供了一个新的数据集那么它会降低性能。因此我们总是尝试制作一个在训练集和测试数据集上表现良好的机器学习模型。在这里我们可以将这些数据集定义为训练集和测试集。
训练集用于训练机器学习模型的数据集子集我们已经知道输出。
测试集用于测试机器学习模型的数据集子集并通过使用测试集模型预测输出。
为了拆分数据集我们将使用以下代码行将数据集以82进行拆分
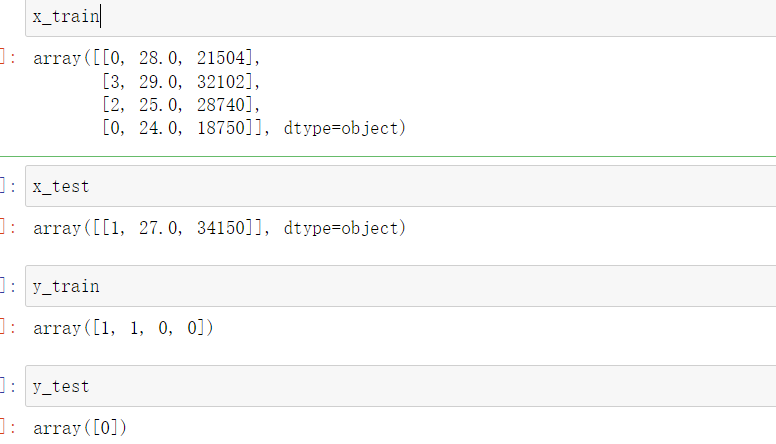
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
解释
- 在上面的代码中第一行用于导入将数据集的数组拆分为随机训练和测试子集。
- x_train训练数据的特征
- x_test测试数据的特征
- y_train训练数据的因变量
- y_test测试数据的自变量
在train_test_split() 函数中我们传递了四个参数其中前两个用于数据数组test_size用于指定测试集的大小。test_size 可能是 0.5、0.3 或0 .2它表示训练集和测试集的划分比率。一般采用0.3或者0.2。
可以挨个查看一下
五、特征缩放
特征缩放是机器学习中数据预处理的最后一步。它是一种将数据集的自变量标准化在特定范围内的技术。在特征缩放中我们将变量放在相同的范围和相同的比例中这样任何变量都不会支配另一个变量。
正如我们所看到的年龄和工资列的值不在同一个范围内。机器学习模型是基于欧几里德距离的如果我们不对变量进行缩放那么它会在我们的机器学习模型中引起一些问题。
欧几里得距离为
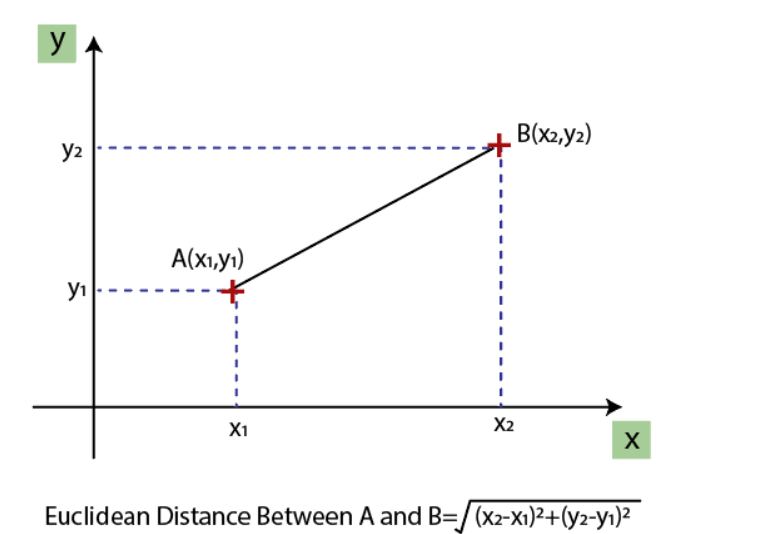
如果我们从年龄和薪水计算任何两个值那么薪水值将支配年龄值并且会产生不正确的结果。所以为了消除这个问题我们需要为机器学习执行特征缩放。
在机器学习中执行特征缩放有两种方法
- 标准化
- 正常化
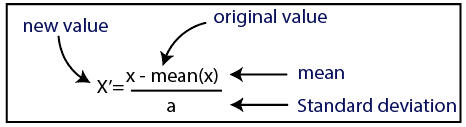
标准化方法x为原始值mean为平均值a为标准差x’为标准化后的值
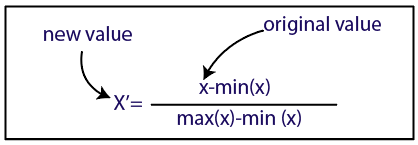
正常化方法x为原始值min为最小值max为最大值,x’为正常化后的值
在这里我们将对数据集使用标准化方法对于特征缩放我们将sklearn.preprocessing库的StandardScaler类导入为
from sklearn.preprocessing import StandardScaler
现在我们将为自变量或特征创建StandardScaler类的对象。然后我们将拟合和转换训练数据集。
from sklearn.preprocessing import StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_train
查看输出
array([[-0.96225045, 0.72760688, -0.70185794],
[ 1.34715063, 1.21267813, 1.2711634 ],
[ 0.57735027, -0.72760688, 0.6452625 ],
[-0.96225045, -1.21267813, -1.21456796]])
对于测试数据集我们将直接应用transform()函数而不是fit_transform()因为它已经在训练集中完成了。
x_test = st_x .transform(x_test)
x_test
输出为
array([[-0.19245009, 0.24253563, 1.65243796]])
通过执行上述代码行我们将得到 x_train 和 x_test 的缩放值。正如我们在上面的输出中看到的所有变量都在值 -1 到 1 之间缩放不过还是会有几个值在缩放后远离这个范围这是正常的。
注意
在这里我们没有对因变量进行缩放因为只有两个值 0 和 1。但是如果这些变量的取值范围更大那么我们还需要对这些变量进行缩放。
注意以上数据是我编的不具有实际性你应该是从这个里面学习对应方法。说白了对于非字符变量需要编码编码成数字本来就是数字就不用编码了。
如果你python基础不够好可以参考我的基础专栏其中有教程也有练习题。如果你觉得我专栏的题太少了你需要更多的刷题推荐一个免费刷题网站牛客网