

微服务01SpringCloud
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

微服务技术栈导学
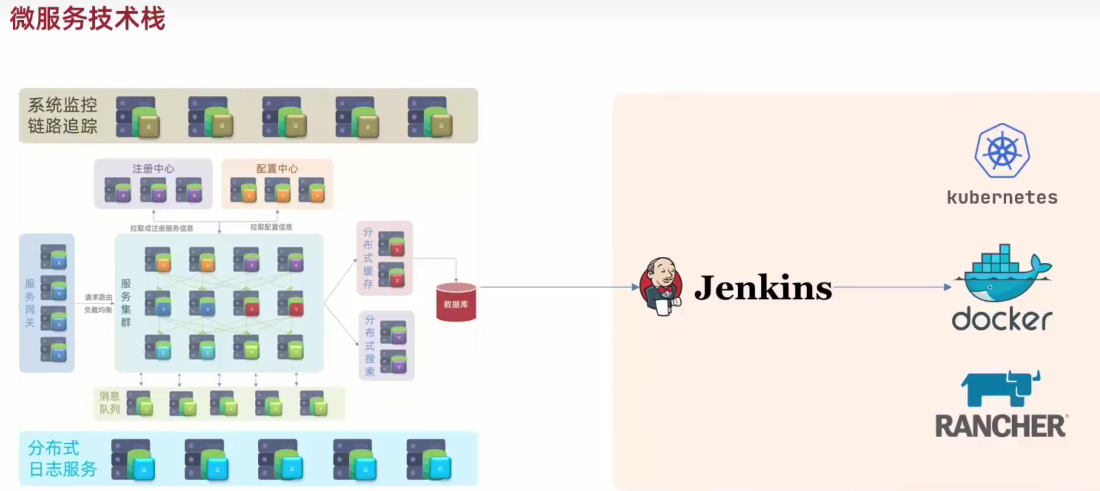
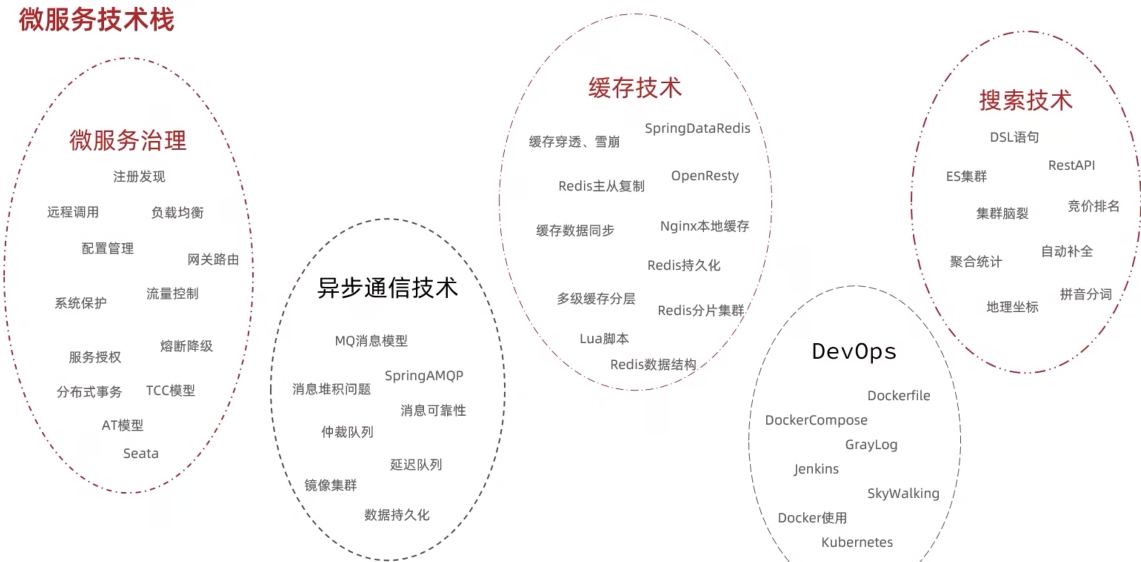


SpringCloud01
1.认识微服务
随着互联网行业的发展对服务的要求也越来越高服务架构也从单体架构逐渐演变为现在流行的微服务架构。这些架构之间有怎样的差别呢?
1.0.学习目标
了解微服务架构的优缺点
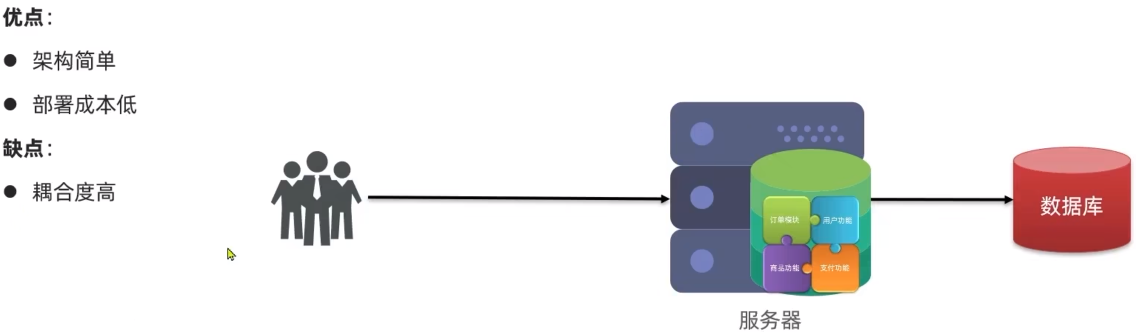
1.1.单体架构
单体架构将业务的所有功能集中在一个项目中开发打成一个包部署。
1.2.分布式架构
分布式架构根据业务功能对系统做拆分每个业务功能模块作为独立项目开发称为一个服务。
分布式架构的优缺点
优点
降低服务耦合
有利于服务升级和拓展
缺点
服务调用关系错综复杂
分布式架构虽然降低了服务耦合但是服务拆分时也有很多问题需要思考
服务拆分的粒度如何界定?
服务之间如何调用?
服务的调用关系如何管理?
人们需要制定一套行之有效的标准来约束分布式架构。
1.3.微服务
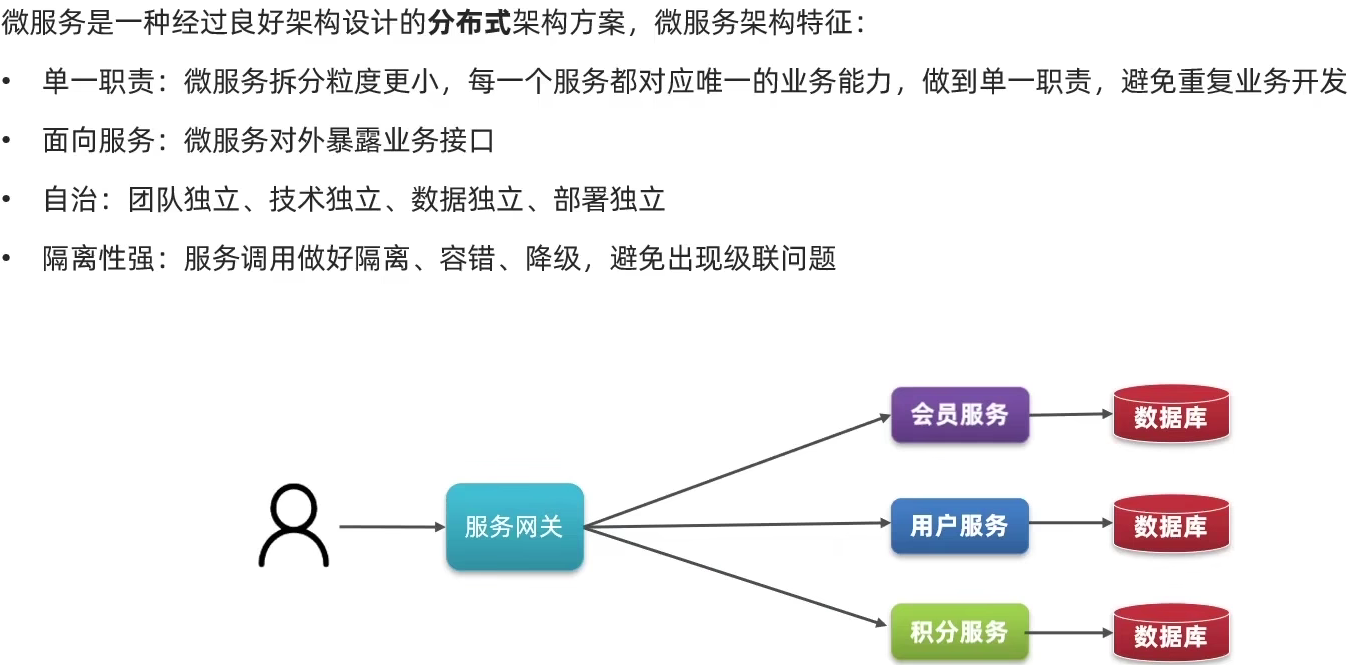
微服务的上述特性其实是在给分布式架构制定一个标准进一步降低服务之间的耦合度提供服务的独立性和灵活性。做到高内聚低耦合。
因此可以认为微服务是一种经过良好架构设计的分布式架构方案 。
但方案该怎么落地?选用什么样的技术栈?全球的互联网公司都在积极尝试自己的微服务落地方案。
其中在Java领域最引人注目的就是SpringCloud提供的方案了。
微服务技术对比


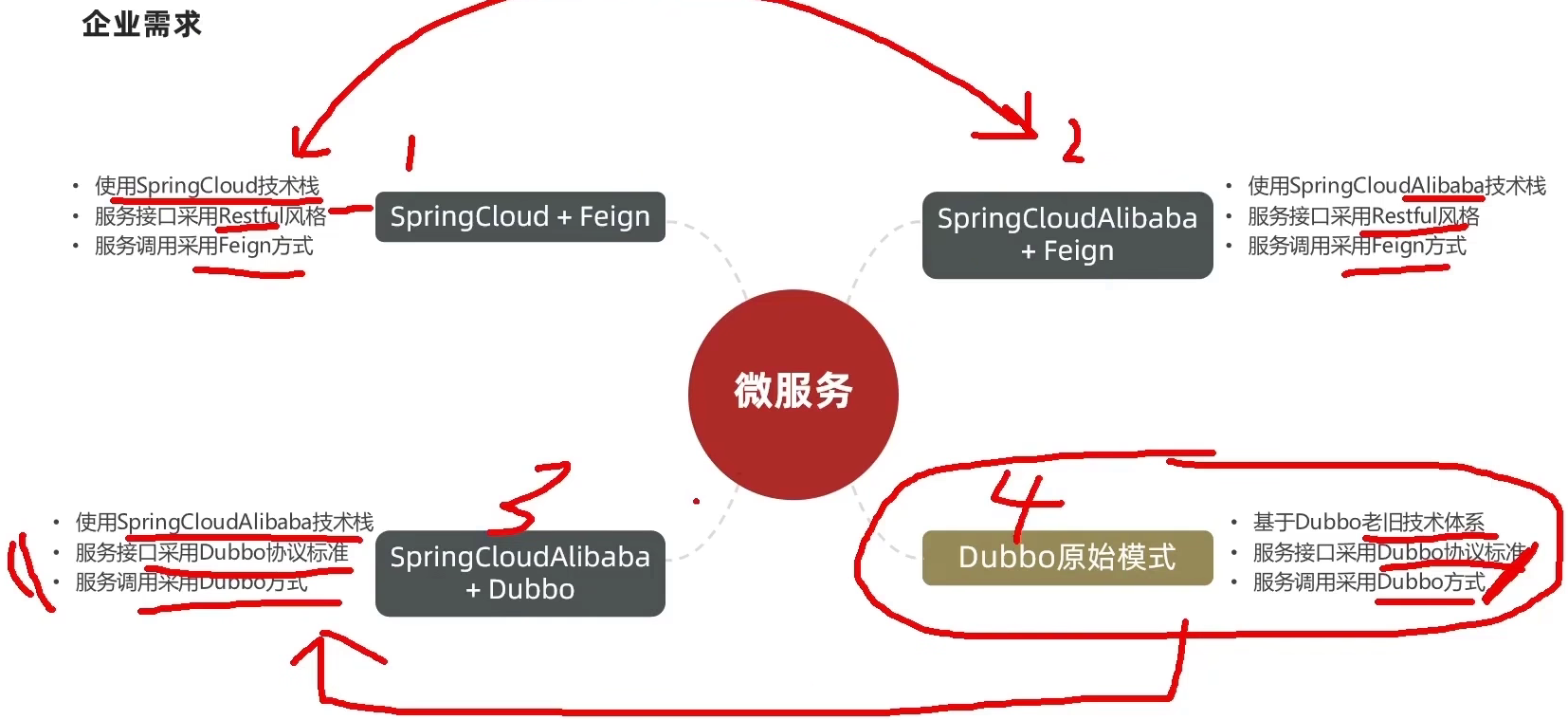
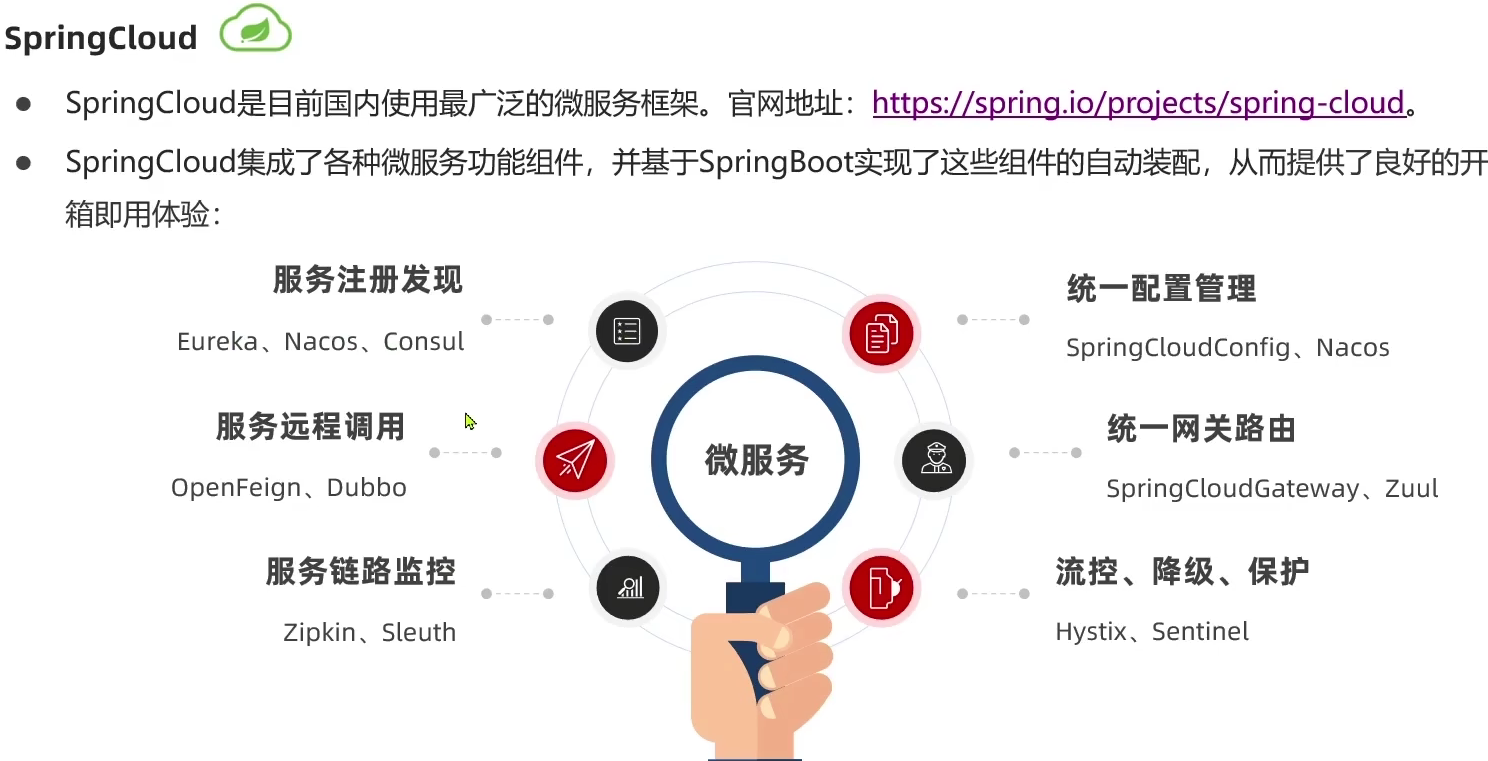
1.4.SpringCloud
官网地址https://spring.io/projects/spring-cloud。
SpringCloud底层是依赖于SpringBoot的并且有版本的兼容关系如下
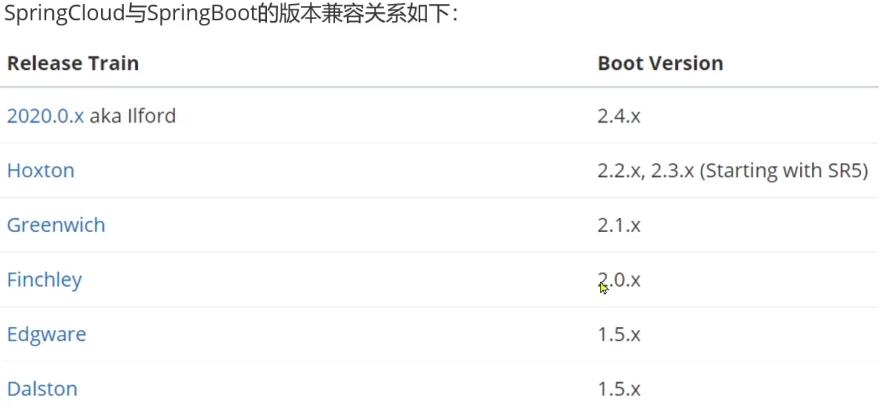
我们课堂学习的版本是 Hoxton.SR10因此对应的SpringBoot版本是2.3.x版本。
1.5.总结

SpringCloud是微服务架构的一站式解决方案集成了各种优秀微服务功能组件
2.服务拆分和远程调用
任何分布式架构都离不开服务的拆分微服务也是一样。
2.1.服务拆分原则
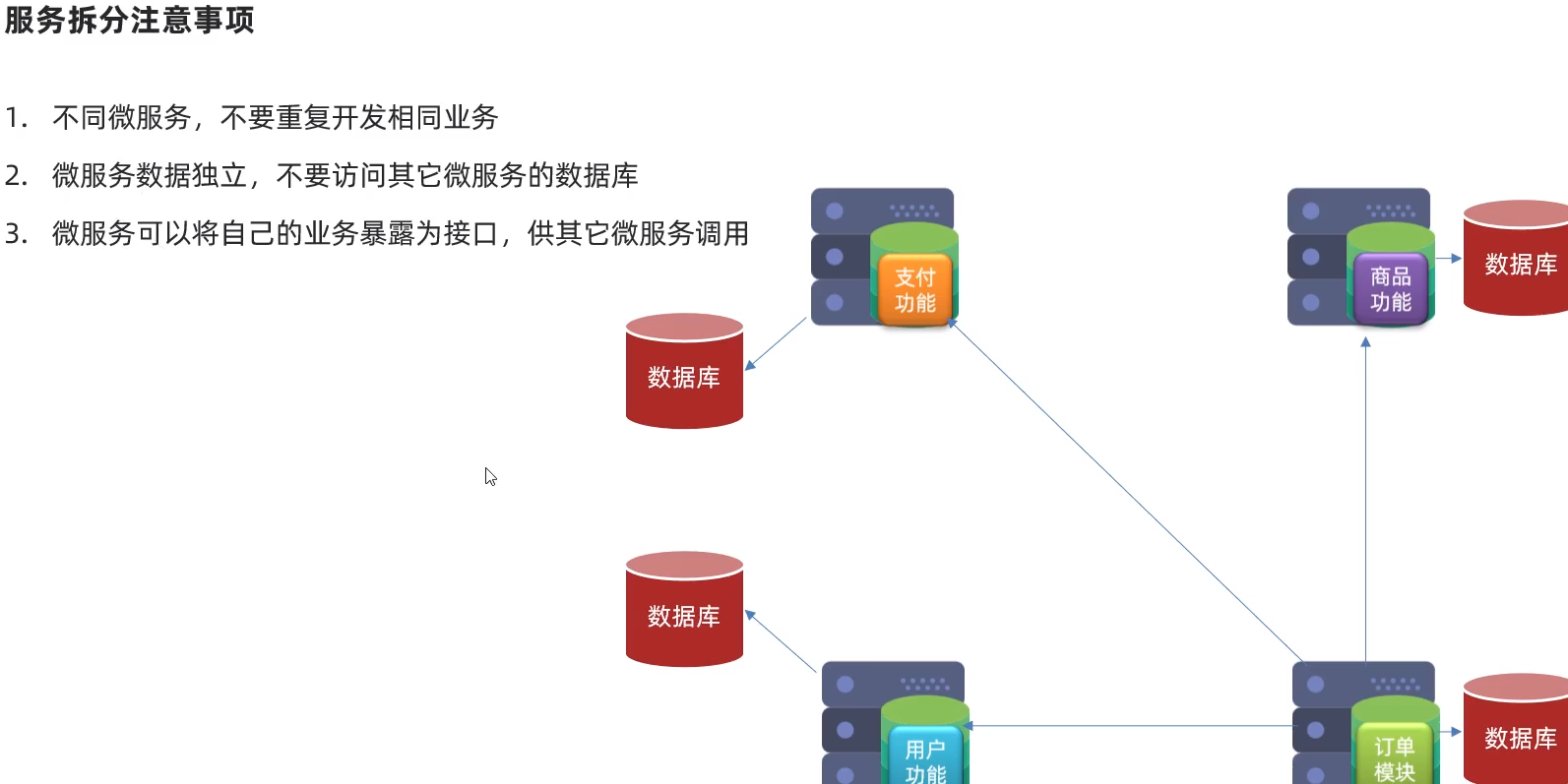
2.2.服务拆分示例
以课前资料中的微服务cloud-demo为例其结构如下

cloud-demo父工程管理依赖
order-service订单微服务负责订单相关业务
user-service用户微服务负责用户相关业务
要求
订单微服务和用户微服务都必须有各自的数据库相互独立
订单服务和用户服务都对外暴露Restful的接口
订单服务如果需要查询用户信息只能调用用户服务的Restful接口不能查询用户数据库
2.3.1.案例需求
修改order-service中的根据id查询订单业务要求在查询订单的同时根据订单中包含的userId查询出用户信息一起返回。
因此我们需要在order-service中 向user-service发起一个http的请求调用http://localhost:8081/user/{userId}这个接口。
大概的步骤是这样的
注册一个RestTemplate的实例到Spring容器
修改order-service服务中的OrderService类中的queryOrderById方法根据Order对象中的userId查询User
将查询的User填充到Order对象一起返回
2.3.2.注册RestTemplate
首先我们在order-service服务中的OrderApplication启动类中注册RestTemplate实例
package cn.itcast.order;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@MapperScan("cn.itcast.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}2.3.3.实现远程调用
修改order-service服务中的cn.itcast.order.service包下的OrderService类中的queryOrderById方法
2.4.提供者与消费者
在服务调用关系中会有两个不同的角色
服务提供者一次业务中被其它微服务调用的服务。提供接口给其它微服务
服务消费者一次业务中调用其它微服务的服务。调用其它微服务提供的接口
但是服务提供者与服务消费者的角色并不是绝对的而是相对于业务而言。
如果服务A调用了服务B而服务B又调用了服务C服务B的角色是什么?
对于A调用B的业务而言A是服务消费者B是服务提供者
对于B调用C的业务而言B是服务消费者C是服务提供者
因此服务B既可以是服务提供者也可以是服务消费者。
3.Eureka注册中心
假如我们的服务提供者user-service部署了多个实例如图
大家思考几个问题
order-service在发起远程调用的时候该如何得知user-service实例的ip地址和端口?
有多个user-service实例地址order-service调用时该如何选择?
order-service如何得知某个user-service实例是否依然健康是不是已经宕机?
3.1.Eureka的结构和作用
这些问题都需要利用SpringCloud中的注册中心来解决其中最广为人知的注册中心就是Eureka其结构如下
回答之前的各个问题。
问题1order-service如何得知user-service实例地址?
获取地址信息的流程如下
user-service服务实例启动后将自己的信息注册到eureka-serverEureka服务端。这个叫服务注册
eureka-server保存服务名称到服务实例地址列表的映射关系
order-service根据服务名称拉取实例地址列表。这个叫服务发现或服务拉取
问题2order-service如何从多个user-service实例中选择具体的实例?
order-service从实例列表中利用负载均衡算法选中一个实例地址
向该实例地址发起远程调用
问题3order-service如何得知某个user-service实例是否依然健康是不是已经宕机?
user-service会每隔一段时间默认30秒向eureka-server发起请求报告自己状态称为心跳
当超过一定时间没有发送心跳时eureka-server会认为微服务实例故障将该实例从服务列表中剔除
order-service拉取服务时就能将故障实例排除了
注意一个微服务既可以是服务提供者又可以是服务消费者因此eureka将服务注册、服务发现等功能统一封装到了eureka-client端
因此接下来我们动手实践的步骤包括
3.2.搭建eureka-server
首先大家注册中心服务端eureka-server这必须是一个独立的微服务
3.2.1.创建eureka-server服务
在cloud-demo父工程下创建一个子模块
填写模块信息
然后填写服务信息
3.2.2.引入eureka依赖
引入SpringCloud为eureka提供的starter依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>3.2.3.编写启动类
给eureka-server服务编写一个启动类一定要添加一个@EnableEurekaServer注解开启eureka的注册中心功能
package cn.itcast.eureka;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}3.2.4.编写配置文件
编写一个application.yml文件内容如下
server:
port: 10086
spring:
application:
name: eureka-server
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka3.2.5.启动服务
启动微服务然后在浏览器访问http://127.0.0.1:10086
看到下面结果应该是成功了
3.3.服务注册
下面我们将user-service注册到eureka-server中去。
1引入依赖
在user-service的pom文件中引入下面的eureka-client依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>2配置文件
在user-service中修改application.yml文件添加服务名称、eureka地址
spring:
application:
name: userservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka3启动多个user-service实例
为了演示一个服务有多个实例的场景我们添加一个SpringBoot的启动配置再启动一个user-service。
首先复制原来的user-service启动配置
然后在弹出的窗口中填写信息
现在SpringBoot窗口会出现两个user-service启动配置
不过第一个是8081端口第二个是8082端口。
启动两个user-service实例
查看eureka-server管理页面
3.4.服务发现
下面我们将order-service的逻辑修改向eureka-server拉取user-service的信息实现服务发现。
1引入依赖
之前说过服务发现、服务注册统一都封装在eureka-client依赖因此这一步与服务注册时一致。
在order-service的pom文件中引入下面的eureka-client依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>2配置文件
服务发现也需要知道eureka地址因此第二步与服务注册一致都是配置eureka信息
在order-service中修改application.yml文件添加服务名称、eureka地址
spring:
application:
name: orderservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka3服务拉取和负载均衡
最后我们要去eureka-server中拉取user-service服务的实例列表并且实现负载均衡。
不过这些动作不用我们去做只需要添加一些注解即可。
在order-service的OrderApplication中给RestTemplate这个Bean添加一个@LoadBalanced注解
修改order-service服务中的cn.itcast.order.service包下的OrderService类中的queryOrderById方法。修改访问的url路径用服务名代替ip、端口
spring会自动帮助我们从eureka-server端根据userservice这个服务名称获取实例列表而后完成负载均衡。
4.Ribbon负载均衡
上一节中我们添加了@LoadBalanced注解即可实现负载均衡功能这是什么原理呢?
4.1.负载均衡原理
SpringCloud底层其实是利用了一个名为Ribbon的组件来实现负载均衡功能的。
那么我们发出的请求明明是http://userservice/user/1怎么变成了http://localhost:8081的呢?
4.2.源码跟踪
为什么我们只输入了service名称就可以访问了呢?之前还要获取ip和端口。
显然有人帮我们根据service名称获取到了服务实例的ip和端口。它就是LoadBalancerInterceptor这个类会在对RestTemplate的请求进行拦截然后从Eureka根据服务id获取服务列表随后利用负载均衡算法得到真实的服务地址信息替换服务id。
我们进行源码跟踪
1LoadBalancerIntercepor
可以看到这里的intercept方法拦截了用户的HttpRequest请求然后做了几件事
request.getURI()获取请求uri本例中就是 http://user-service/user/8
originalUri.getHost()获取uri路径的主机名其实就是服务iduser-service
this.loadBalancer.execute()处理服务id和用户请求。
这里的this.loadBalancer是LoadBalancerClient类型我们继续跟入。
2LoadBalancerClient
继续跟入execute方法
代码是这样的
getLoadBalancer(serviceId)根据服务id获取ILoadBalancer而ILoadBalancer会拿着服务id去eureka中获取服务列表并保存起来。
getServer(loadBalancer)利用内置的负载均衡算法从服务列表中选择一个。本例中可以看到获取了8082端口的服务
放行后再次访问并跟踪发现获取的是8081
果然实现了负载均衡。
3负载均衡策略IRule
在刚才的代码中可以看到获取服务使通过一个getServer方法来做负载均衡:
我们继续跟入
继续跟踪源码chooseServer方法发现这么一段代码
我们看看这个rule是谁
这里的rule默认值是一个RoundRobinRule看类的介绍
这不就是轮询的意思嘛。
到这里整个负载均衡的流程我们就清楚了。
4总结
SpringCloudRibbon的底层采用了一个拦截器拦截了RestTemplate发出的请求对地址做了修改。用一幅图来总结一下
基本流程如下
拦截我们的RestTemplate请求http://userservice/user/1
RibbonLoadBalancerClient会从请求url中获取服务名称也就是user-service
DynamicServerListLoadBalancer根据user-service到eureka拉取服务列表
eureka返回列表localhost:8081、localhost:8082
IRule利用内置负载均衡规则从列表中选择一个例如localhost:8081
RibbonLoadBalancerClient修改请求地址用localhost:8081替代userservice得到http://localhost:8081/user/1发起真实请求
4.3.负载均衡策略
4.3.1.负载均衡策略
负载均衡的规则都定义在IRule接口中而IRule有很多不同的实现类
不同规则的含义如下
内置负载均衡规则类 | 规则描述 |
RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
AvailabilityFilteringRule | 对以下两种服务器进行忽略 1在默认情况下这台服务器如果3次连接失败这台服务器就会被设置为“短路”状态。短路状态将持续30秒如果再次连接失败短路的持续时间就会几何级地增加。 2并发数过高的服务器。如果一个服务器的并发连接数过高配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限可以由客户端的 . .ActiveConnectionsLimit属性进行配置。 |
WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长这个服务器的权重就越小。这个规则会随机选择服务器这个权重值会影响服务器的选择。 |
ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
BestAvailableRule | 忽略那些短路的服务器并选择并发数较低的服务器。 |
RandomRule | 随机选择一个可用的服务器。 |
RetryRule | 重试机制的选择逻辑 |
默认的实现就是ZoneAvoidanceRule是一种轮询方案
4.3.2.自定义负载均衡策略
通过定义IRule实现可以修改负载均衡规则有两种方式
代码方式在order-service中的OrderApplication类中定义一个新的IRule
@Bean
public IRule randomRule(){
return new RandomRule();
}配置文件方式在order-service的application.yml文件中添加新的配置也可以修改规则
userservice: # 给某个微服务配置负载均衡规则这里是userservice服务
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则 注意一般用默认的负载均衡规则不做修改。
4.4.饥饿加载
Ribbon默认是采用懒加载即第一次访问时才会去创建LoadBalanceClient请求时间会很长。
而饥饿加载则会在项目启动时创建降低第一次访问的耗时通过下面配置开启饥饿加载
ribbon:
eager-load:
enabled: true
clients: userservice5.Nacos注册中心
国内公司一般都推崇阿里巴巴的技术比如注册中心SpringCloudAlibaba也推出了一个名为Nacos的注册中心。
5.1.认识和安装Nacos
Nacos是阿里巴巴的产品现在是SpringCloud中的一个组件。相比Eureka功能更加丰富在国内受欢迎程度较高。
安装方式可以参考课前资料《Nacos安装指南.md》
5.2.服务注册到nacos
Nacos是SpringCloudAlibaba的组件而SpringCloudAlibaba也遵循SpringCloud中定义的服务注册、服务发现规范。因此使用Nacos和使用Eureka对于微服务来说并没有太大区别。
主要差异在于
依赖不同
服务地址不同
1引入依赖
在cloud-demo父工程的pom文件中的<dependencyManagement>中引入SpringCloudAlibaba的依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>然后在user-service和order-service中的pom文件中引入nacos-discovery依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>注意不要忘了注释掉eureka的依赖。
2配置nacos地址
在user-service和order-service的application.yml中添加nacos地址
spring:
cloud:
nacos:
server-addr: localhost:8848注意不要忘了注释掉eureka的地址
3重启
重启微服务后登录nacos管理页面可以看到微服务信息
5.3.服务分级存储模型
一个服务可以有多个实例例如我们的user-service可以有:
127.0.0.1:8081
127.0.0.1:8082
127.0.0.1:8083
假如这些实例分布于全国各地的不同机房例如
127.0.0.1:8081在上海机房
127.0.0.1:8082在上海机房
127.0.0.1:8083在杭州机房
Nacos就将同一机房内的实例 划分为一个集群。
也就是说user-service是服务一个服务可以包含多个集群如杭州、上海每个集群下可以有多个实例形成分级模型如图
微服务互相访问时应该尽可能访问同集群实例因为本地访问速度更快。当本集群内不可用时才访问其它集群。例如
杭州机房内的order-service应该优先访问同机房的user-service。
5.3.1.给user-service配置集群
修改user-service的application.yml文件添加集群配置
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称重启两个user-service实例后我们可以在nacos控制台看到下面结果
我们再次复制一个user-service启动配置添加属性
-Dserver.port=8083 -Dspring.cloud.nacos.discovery.cluster-name=SH配置如图所示
启动UserApplication3后再次查看nacos控制台
5.3.2.同集群优先的负载均衡
默认的ZoneAvoidanceRule并不能实现根据同集群优先来实现负载均衡。
因此Nacos中提供了一个NacosRule的实现可以优先从同集群中挑选实例。
1给order-service配置集群信息
修改order-service的application.yml文件添加集群配置
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称2修改负载均衡规则
修改order-service的application.yml文件修改负载均衡规则
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则 5.4.权重配置
实际部署中会出现这样的场景
服务器设备性能有差异部分实例所在机器性能较好另一些较差我们希望性能好的机器承担更多的用户请求。
但默认情况下NacosRule是同集群内随机挑选不会考虑机器的性能问题。
因此Nacos提供了权重配置来控制访问频率权重越大则访问频率越高。
在nacos控制台找到user-service的实例列表点击编辑即可修改权重
在弹出的编辑窗口修改权重
注意如果权重修改为0则该实例永远不会被访问
5.5.环境隔离
Nacos提供了namespace来实现环境隔离功能。
nacos中可以有多个namespace
namespace下可以有group、service等
不同namespace之间相互隔离例如不同namespace的服务互相不可见
5.5.1.创建namespace
默认情况下所有service、data、group都在同一个namespace名为public
我们可以点击页面新增按钮添加一个namespace
然后填写表单
就能在页面看到一个新的namespace
5.5.2.给微服务配置namespace
给微服务配置namespace只能通过修改配置来实现。
例如修改order-service的application.yml文件
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ
namespace: 492a7d5d-237b-46a1-a99a-fa8e98e4b0f9 # 命名空间填ID重启order-service后访问控制台可以看到下面的结果
此时访问order-service因为namespace不同会导致找不到userservice控制台会报错
5.6.Nacos与Eureka的区别
Nacos的服务实例分为两种l类型
临时实例如果实例宕机超过一定时间会从服务列表剔除默认的类型。
非临时实例如果实例宕机不会从服务列表剔除也可以叫永久实例。
配置一个服务实例为永久实例
spring:
cloud:
nacos:
discovery:
ephemeral: false # 设置为非临时实例Nacos和Eureka整体结构类似服务注册、服务拉取、心跳等待但是也存在一些差异
Nacos与eureka的共同点
都支持服务注册和服务拉取
都支持服务提供者心跳方式做健康检测
Nacos与Eureka的区别
Nacos支持服务端主动检测提供者状态临时实例采用心跳模式非临时实例采用主动检测模式
临时实例心跳不正常会被剔除非临时实例则不会被剔除
Nacos支持服务列表变更的消息推送模式服务列表更新更及时
Nacos集群默认采用AP方式当集群中存在非临时实例时采用CP模式;Eureka采用AP方式