

【大数据开发技术】实验03-Hadoop读取文件
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
Hadoop读取文件
一、实验目标
- 熟练掌握hadoop操作指令及HDFS命令行接口
- 掌握HDFS原理
- 掌握HDFS的API使用方法
- 掌握通过URL类读取HDFS上的文件内容的方法
- 掌握FileSystem读取HDFS上文件内容的方法
二、实验要求
- 给出每个实验操作步骤成功的效果截图。
- 对本次实验工作进行全面的总结。
- 完成实验内容后实验报告文件重命名为学号姓名实验三。
三、实验内容
-
使用FileSystem类读取HDFS上的文件把文件的内容打印到标准输出流中分别在本地和集群上进行测试给出详细实现过程、完整代码和实现效果截图最终效果图参考图1和图2。要求在本地新建一个文件文件名或文件内容体现本人名字文件内容自拟中英文均可使用shell命令上传到HDFS上。
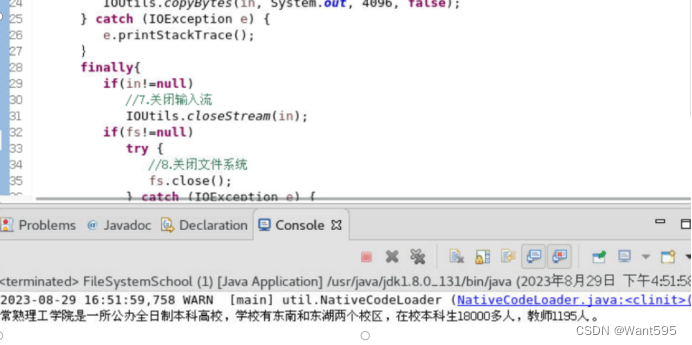
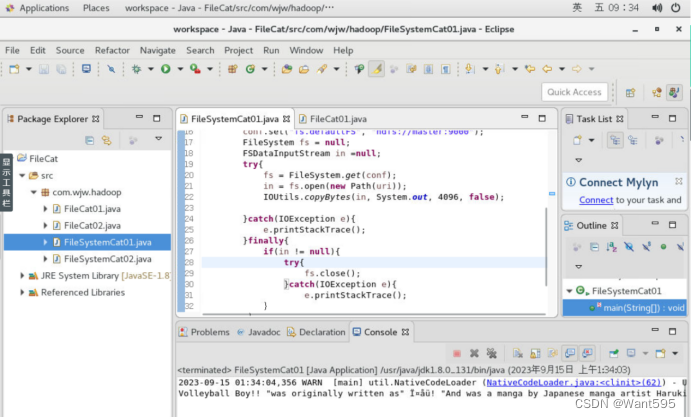
图1 FileSystem读取文件本地测试效果图
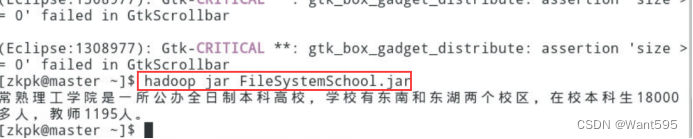
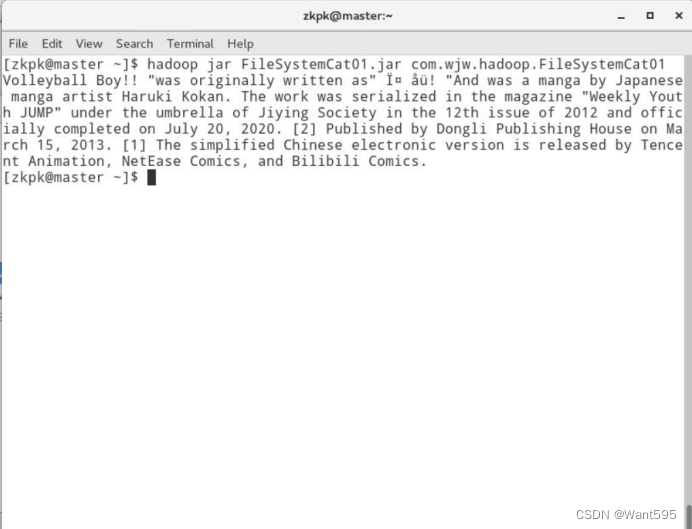
图2 FileSystem读取文件集群测试效果图 -
通过URL类读取HDFS上的文件内容给出主要实现过程、完整代码和实现效果截图最终效果图参考图3和图4。要求在本地新建一个文件文件名或文件内容体现本人名字文件内容自拟中英文均可使用shell命令上传到HDFS上
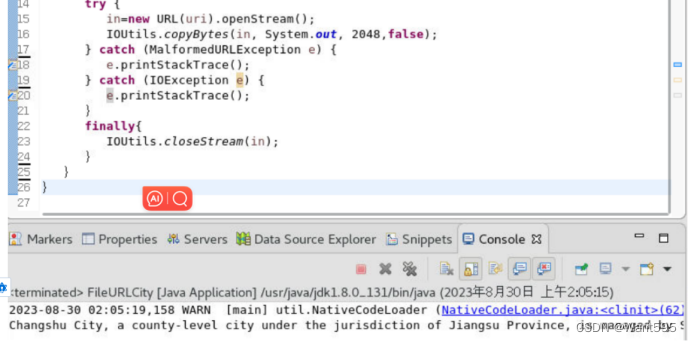
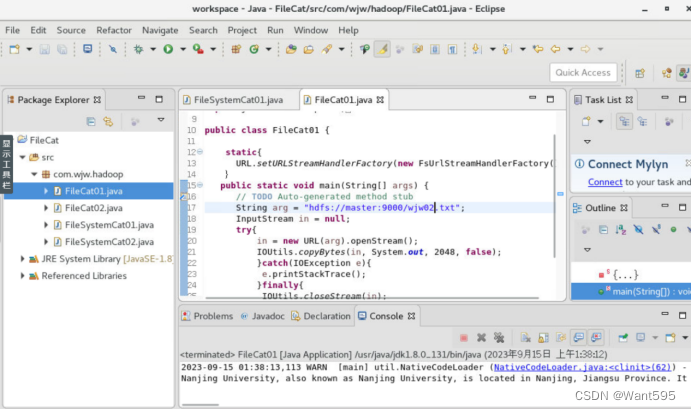
图3 URL读取文件本地测试效果图

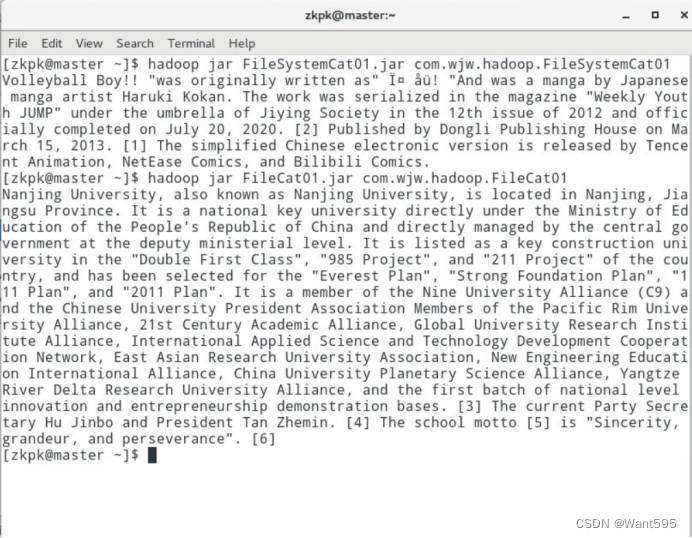
图4 URL读取文件集群测试效果图 -
使用FileSystem类读取HDFS上的多个文件把文件的内容打印到标准输出流中给出主要实现过程、完整代码和实现效果截图。实现效果截图参考图5图5是读取cs.txt和cslg.txt两个文件内容的测试效果截图。要求在本地新建两个其中两个文件名为自己的学号和姓名文件内容分别个人简介和家乡信息文件内容中英文均可使用shell命令上传到HDFS上。

图5 FileSystem方式读取多个文件内容 -
通过URL类读取HDFS上的多个文件的内容给出主要实现过程、完整代码和实现效果截图最终效果图参考图6。使用上一个实验中的两个文本文件也可以重新创建两个文本文件文件命名同上一个实验文件内容自拟。
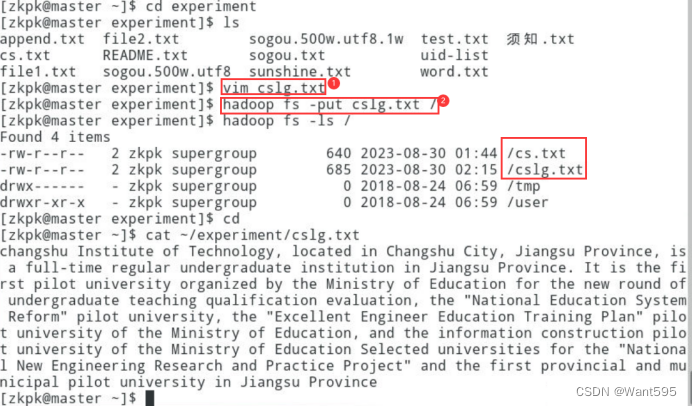
图6 URL方式读取多个文件内容
四、实验步骤
实验1
实验代码
package com.wjw.hadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
String uri = "hdfs://master:9000/wjw01.txt";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:9000");
FileSystem fs = null;
FSDataInputStream in =null;
try{
fs = FileSystem.get(conf);
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
}catch(IOException e){
e.printStackTrace();
}finally{
if(in != null){
try{
fs.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
}
}
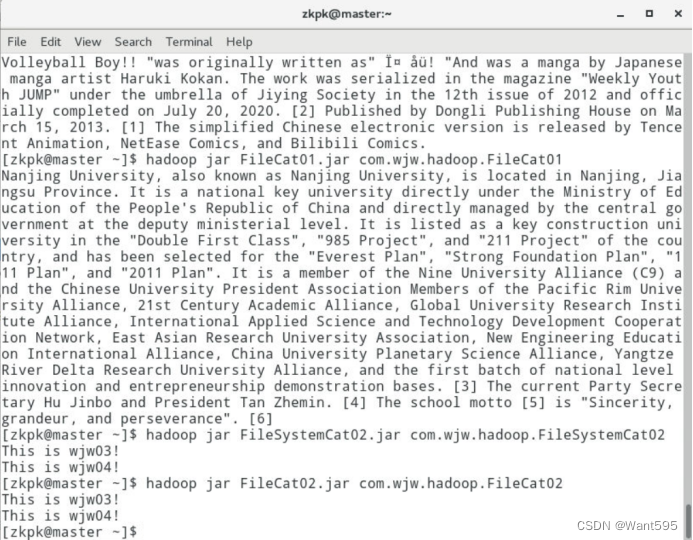
实验截图
实验2
实验代码
package com.wjw.hadoop;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
public class FileCat01 {
static{
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) {
// TODO Auto-generated method stub
String arg = "hdfs://master:9000/wjw02.txt";
InputStream in = null;
try{
in = new URL(arg).openStream();
IOUtils.copyBytes(in, System.out, 2048, false);
}catch(IOException e){
e.printStackTrace();
}finally{
IOUtils.closeStream(in);
}
}
}
实验截图
实验3
实验代码
package com.wjw.hadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat02 {
public static void main(String[] args) {
// TODO Auto-generated method stub
args = new String[2];
args[0] = "hdfs://master:9000/wjw03.txt";
args[1] = "hdfs://master:9000/wjw04.txt";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:9000");
for(int i=0; i < args.length; i++){
FileSystem fs = null;
FSDataInputStream in =null;
try{
fs = FileSystem.get(conf);
in = fs.open(new Path(args[i]));
IOUtils.copyBytes(in, System.out, 4096, false);
}catch(IOException e){
e.printStackTrace();
}finally{
if(in != null){
try{
fs.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
}
}
}
实验截图

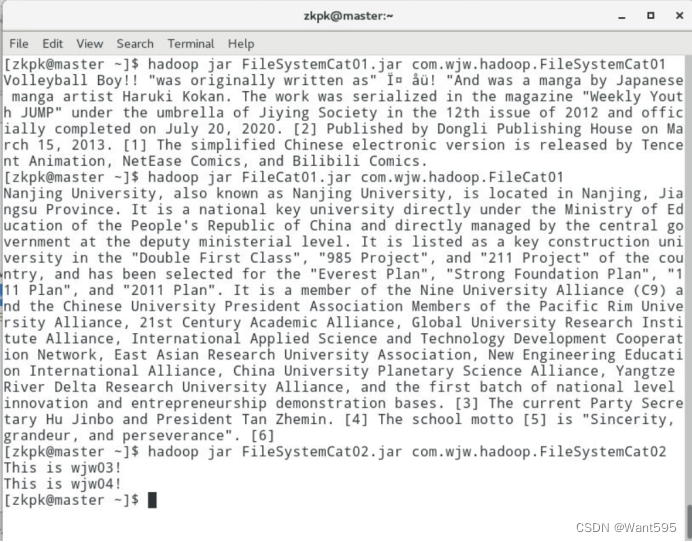
实验4
实验代码
package com.wjw.hadoop;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
public class FileCat02 {
static{
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) {
// TODO Auto-generated method stub
args = new String[2];
args[0] = "hdfs://master:9000/wjw03.txt";
args[1] = "hdfs://master:9000/wjw04.txt";
for(int i=0; i < args.length; i++){
InputStream in = null;
try{
in = new URL(args[i]).openStream();
IOUtils.copyBytes(in, System.out, 2048, false);
}catch(IOException e){
e.printStackTrace();
}finally{
IOUtils.closeStream(in);
}
}
}
}
实验截图
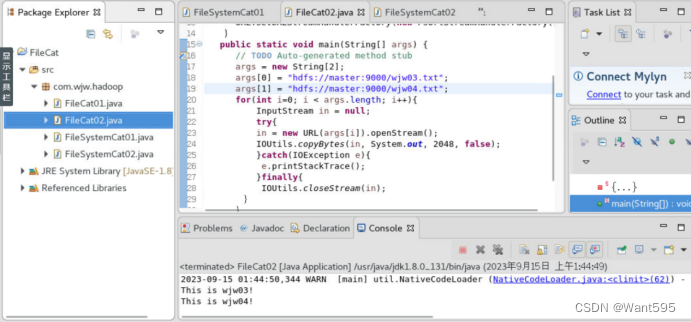
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |