

scrapy爬虫爬取小姐姐图片(不羞涩)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
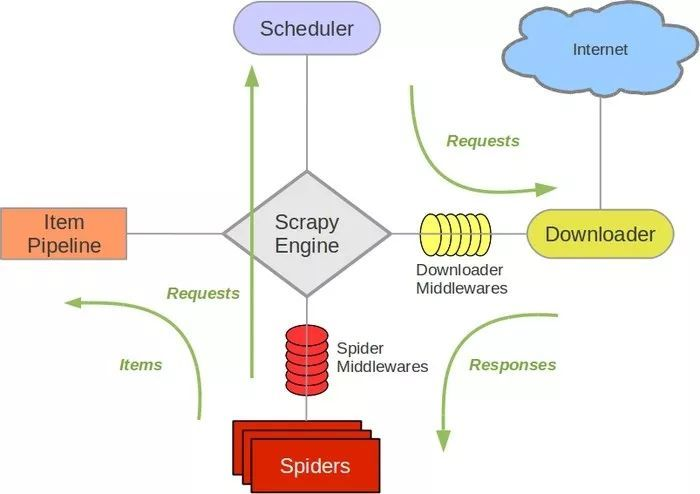
这个爬虫主要学习scrapy的item Pipeline
是时候搬出这张图了:
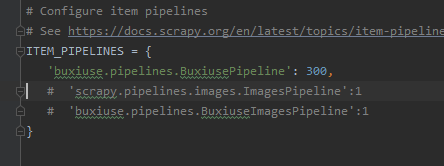
当我们要使用item Pipeline的时候,要现在settings里面取消这几行的注释
我们可以自定义Item Pipeline,只需要实现指定的方法,其中必须要实现的一个方法是: p
process_item(item,spider)
另外还有几个方法我们有时候会用到
open_spider(spider)
close_spider(spider)
from_crawler(cls,crawler)
在不羞涩的主页(https://www.buxiuse.com/)我们使用xpath进行分析可以得到每一张小姐姐图片的url,我们将每一页urls作为一个item对象返回,并且找到下一页的链接,持续爬取
class IndexSpider(scrapy.Spider):
name = 'index'
allowed_domains = ['buxiuse.com']
start_urls = ['https://www.buxiuse.com/?page=1']
base_domain="https://www.buxiuse.com" def parse(self, response):
image_urls=response.xpath('//ul[@class="thumbnails"]/li//img/@src').getall()
next_url=response.xpath('//li[@class="next next_page"]/a/@href').get()
item=BuxiuseItem(image_urls=image_urls)
yield item
if not next_url:
return
else:
yield scrapy.Request(self.base_domain+next_url)
对于yield的item对象,因为只返回了一个urls,所以我们在items进行设置
class BuxiuseItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls=scrapy.Field()
这样在刚才的index文件里面,才可以新建BuxiuseItem对象,
item=BuxiuseItem(image_urls=image_urls)
当然要先在index导入BuxiuseItem这个类
接着在pipeline里面我们处理接收到的Item和下载图片
我们先创建一个image的文件夹储存爬取到的图片,使用os.mkdir(self.path)
这个self.path由我们自己设定,这里学到了一个知识点:os.path.dirname(__file__)可以显示当前文件所在的位置
我们先输出一下
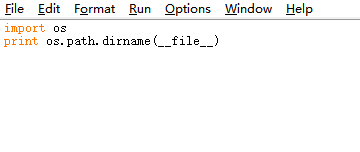
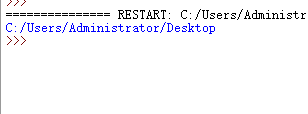
使用os.path.dirname(os.path.dirname(__file__))可以返回到上一级目录位置
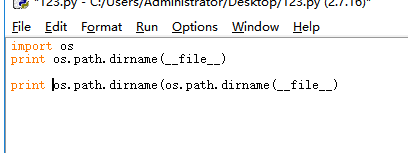
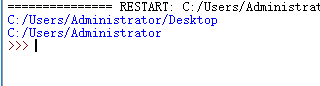
我们使用这个方法控制储存的目录,如果是其他比较远的位置就使用绝对路径吧。
因为我是python2的环境,使用
urllib.urlretrieve(link,os.path.join(self.path,image_name))
将链接上的图片以指定的文件名保存在指定位置上
所以pipeline里面的代码就是
import os
import urllib
from scrapy.pipelines.images import ImagesPipeline
import settings
i=1
class BuxiusePipeline(object):
def __init__(self):
self.path=os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
if not os.path.exists(self.path):
os.mkdir(self.path) def process_item(self, item, spider):
global i
link_list=item['image_urls']
for link in link_list:
print i
image_name=str(i)+".jpg"
urllib.urlretrieve(link,os.path.join(self.path,image_name))
i=i+1
return item
输出i是为了让我能看到脚本还在正常下载,免得被网站ban掉了还不知道。
运行一下看看效果:
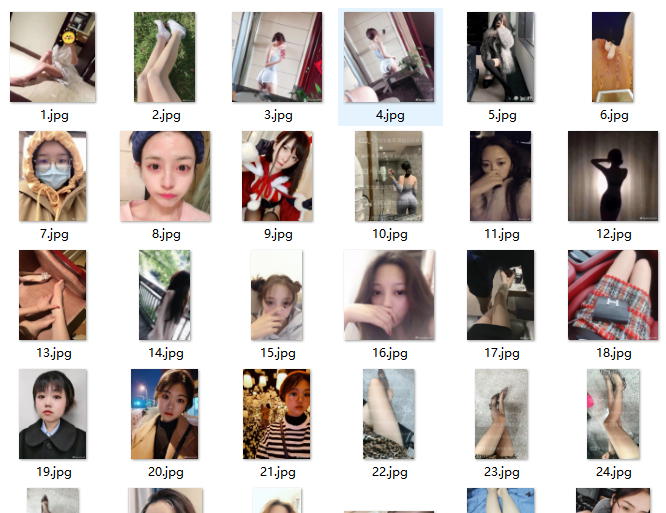
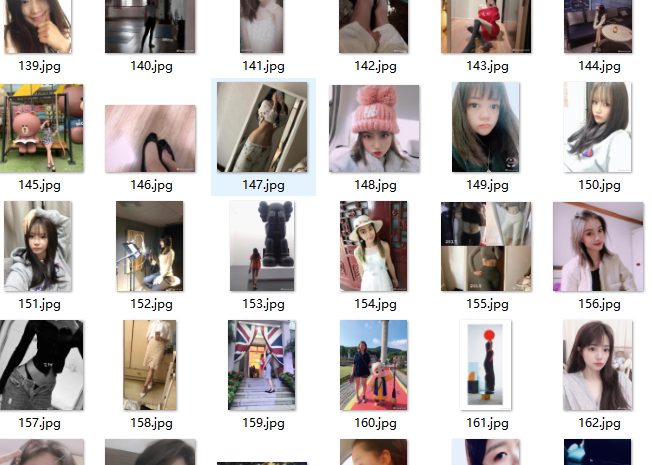
可以看到小姐姐的图片已经被下载下来了,并且按照i的编号整齐排列,完事。
github代码:
https://github.com/Cl0udG0d/scrapy_demo/tree/master/buxiuse
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |