

【深入浅出Seata原理及实战】「入门基础专题」探索Seata服务的AT模式下的分布式开发实战指南(2)
阿里云国际版折扣https://www.yundadi.com |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
承接上文
上一篇文章说到了Seata 为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。那么接下来我们将要针对于AT模式下进行分布式事务开发的原理进行介绍以及实战。
Seata AT模式
在AT、TCC、SAGA 和 XA 这四种事务模式中使用最多,最方便的就是 AT 模式。与其他事务模式相比,AT 模式可以应对大多数的业务场景,且基本可以做到无业务入侵,开发人员能够有更多的精力关注于业务逻辑开发。
使用AT模式的前提
任何应用想要使用Seata的 AT 模式对分布式事务进行控制,必须满足以下 2 个前提:
- 必须使用支持本地 ACID 事务特性的关系型数据库,例如 MySQL、Oracle 等;
- 应用程序必须是使用 JDBC 对数据库进行访问的 JAVA 应用。
Seata安装使用
下载地址
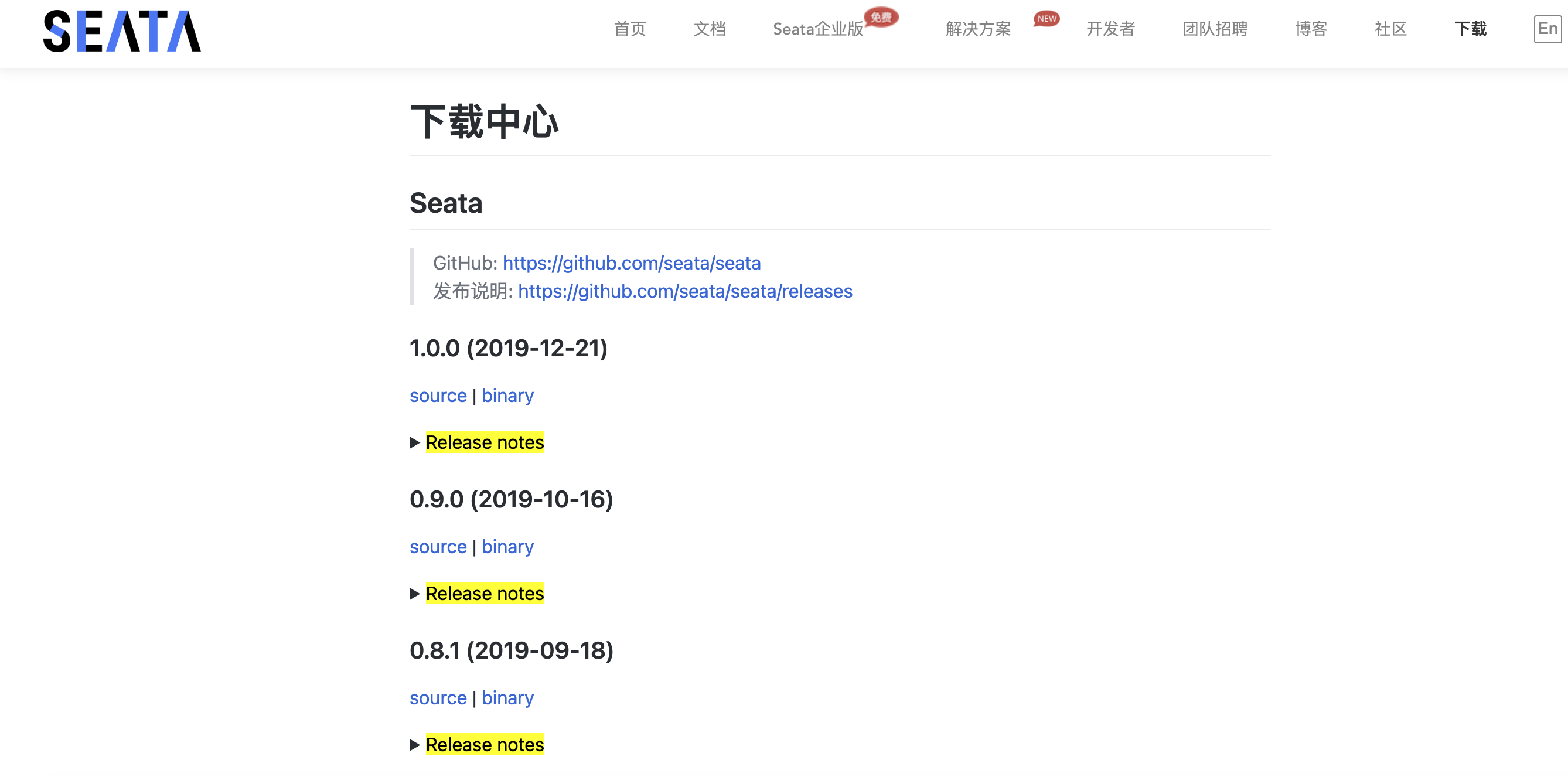
Seata服务进行下载的地址:https://seata.io/zh-cn/blog/download.html,访问之后可以看到下面的资源中,可以直接进行下载,如下图所示。
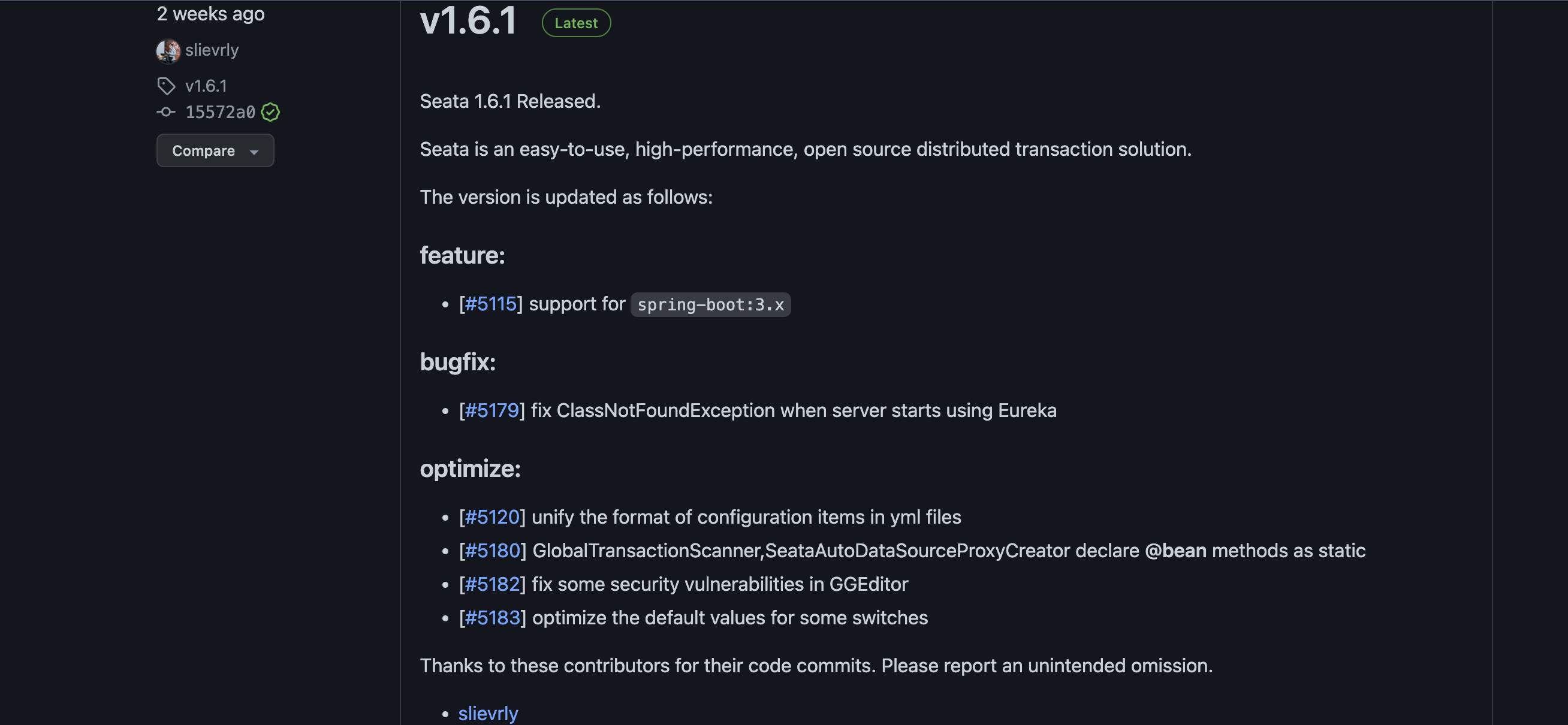
但是由于官方维护的稍微缓慢,所以并不是最新的版本,如果你想要下载较新的版本,可以去官方的Git仓库中进行下载对应的版本文件包。地址为:https://github.com/seata/seata/releases,可以看到下面的最新版本已经到了1.6.1了
我们选择下载对应的可执行包即可。
创建UNDO_LOG表
SEATA AT模式需要针对业务中涉及的各个数据库表,分别创建一个UNDO_LOG(回滚日志)表。不同数据库在创建 UNDO_LOG 表时会略有不同,以 MySQL 为例,其 UNDO_LOG 表的创表语句如下:
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
启动服务
下载服务器软件包后,将其解压缩。主要通过脚本进行启动Seata服务
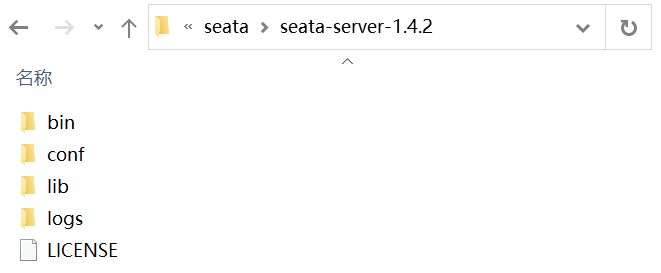
Seata Server 目录中包含以下子目录:
- bin:用于存放Seata Server可执行命令。
- conf:用于存放Seata Server的配置文件。
- lib:用于存放Seata Server依赖的各种 Jar 包。
- logs:用于存放Seata Server的日志。
Seata Server的执行脚本
- seata-server.sh:主要是为Linux和Mac系统准备的启动脚本。执行
sh seata-server.sh启动服务。 - seata-server.bat:主要是为Windows系统准备的启动脚本。执行
cmd seata-server.bat启动服务。
其中参数的选择范围如下所示
--host, -h(简略指令)该地址向注册中心公开,其他服务可以通过该ip访问seata-server,默认: 0.0.0.0
--port, -p(简略指令) 监听的端口,默认值为8091
--storeMode, -m(简略指令)日志存储模式 : file(文件)、db(数据库),默认为:file
--help 帮助指令
例如执行shell脚本
sh seata-server.sh -p 8091 -h 127.0.0.1 -m file
AT 模式的工作机制
Seata的AT模式工作时大致可以分为以两个阶段,下面我们就结合一个实例来对 AT 模式的工作机制进行介绍。
整体机制
两阶段提交协议的演变:
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 二阶段:提交异步化,非常快速地完成。回滚通过一阶段的回滚日志进行反向补偿。
AT模式一阶段
Seata AT模式一阶段的工作流程如下图所示
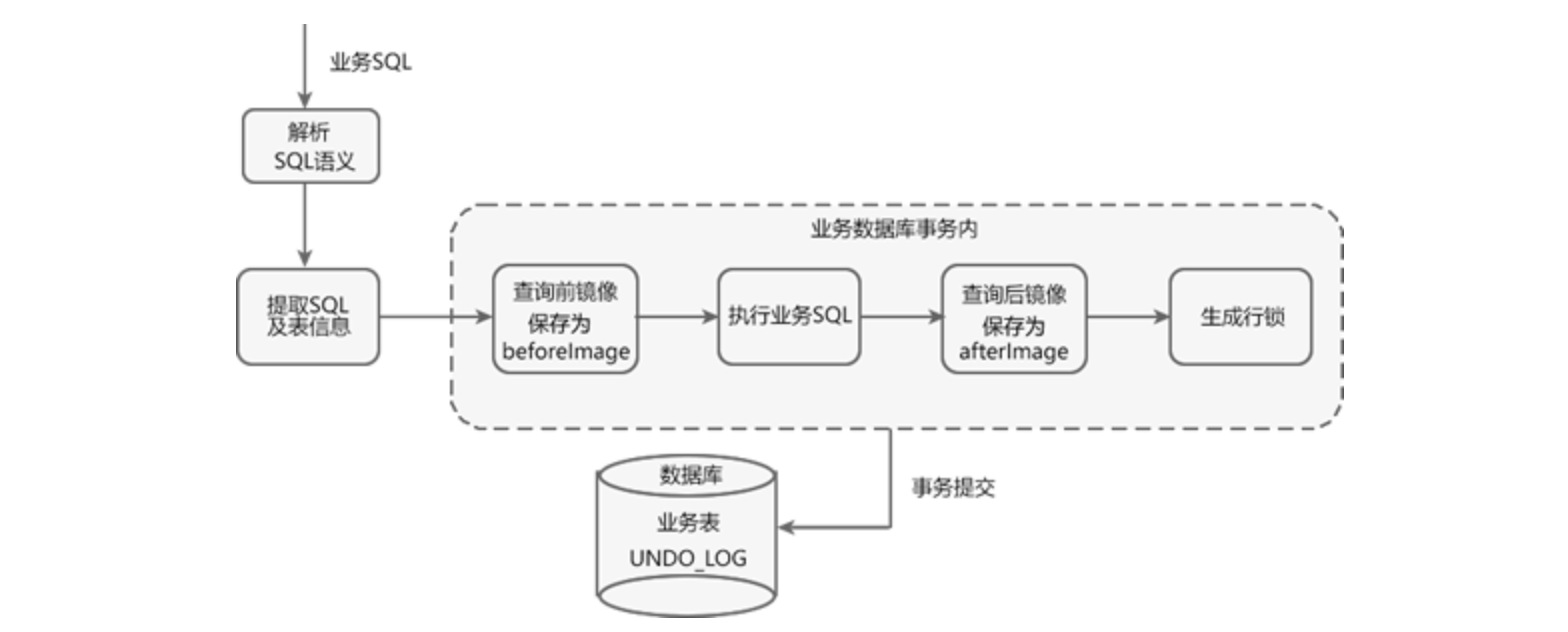
业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
第一子阶段-获取SQL的基本信息
Seata拦截并解析业务SQL,得到SQL 的操作类型(INSERT/UPDATE/DELETE)、表名(tableXXX)、判断条件(where condition = value)等相关信息。
第二子阶段-查询并备份【执行之前】的数据快照
根据得到的业务SQL信息,生成“前镜像查询语句”。
select * from tableXX where condition=value;
执行“前镜像查询语句”,得到即将执行操作的数据,并将其保存为“前镜像数据(beforeImage)”。
第三子阶段-执行业务操作的SQL语句
执行业务SQL,例如(update tableXX set parameter = 'value' where condition = value;),将这条记录的进行修改。
第四子阶段-查询业务操作之后的数据,并且保存下来
查询后镜像:根据“前镜像数据”的主键(id : X),生成“后镜像查询语句”。
select * from tableXX where condition=value;
执行“后镜像查询语句”,得到执行业务操作后的数据,并将其保存为“后镜像数据(afterImage)”。
第五子阶段-插入保存回滚日志记录到undo_log表中
将前后镜像数据和业务SQL的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中,示例回滚日志如下。
{
"branchId": 641789253,
"undoItems": [{
"afterImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "GTS"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"beforeImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "TXC"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"sqlType": "UPDATE"
}],
"xid": "xid:xxx"
}
提交前需要获取申请本地锁
- 提交前,向TC注册分支:申请TableXXX表中,id主键等于N的记录的全局锁 。需要确保先拿到全局锁 。
- 拿不到全局锁 ,不能提交本地事务。
- 拿到全局锁,会被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
示例说明:
两个全局事务tx1和tx2,分别对a表的m字段进行更新操作,m的初始值1000。
-
tx1先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的全局锁 ,本地提交释放本地锁。
-
tx2后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的全局锁 ,tx1 全局提交前,该记录的全局锁被 tx1 持有,tx2需要重试等待 全局锁 。

-
tx1二阶段全局提交,释放全局锁 。tx2 拿到全局锁提交本地事务
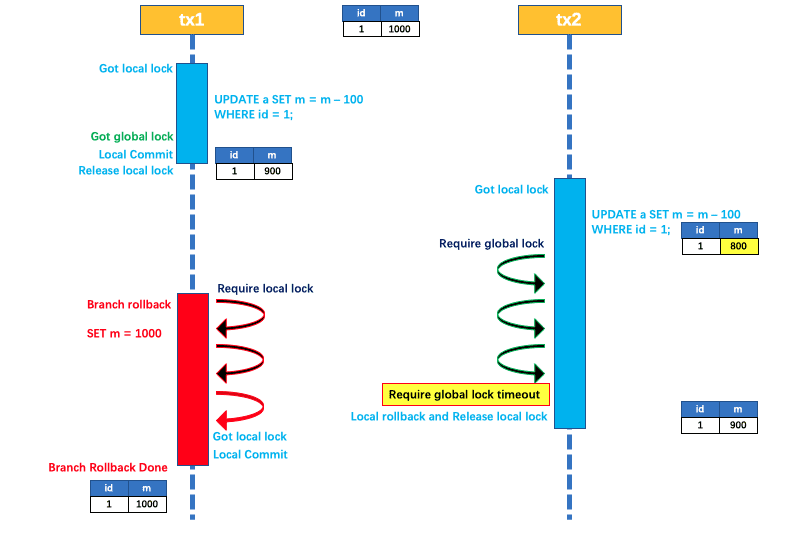
-
如果tx1的二阶段全局回滚,则tx1需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。
此时,如果tx2仍在等待该数据的全局锁,同时持有本地锁,则tx1的分支回滚会失败。分支的回滚会一直重试,直到tx2的全局锁等锁超时,放弃全局锁并回滚本地事务释放本地锁,tx1 的分支回滚最终成功。因为整个过程全局锁在tx1结束前一直是被tx1持有的,所以不会发生脏写的问题。
数据库隔离级别
在数据库本地事务隔离级别,读已提交(Read Committed)或以上的基础上,Seata(AT 模式)的默认全局隔离级别是读未提交(Read Uncommitted) 。
如果应用在特定场景下,必需要求全局的读已提交 ,目前Seata的方式是通过 SELECT FOR UPDATE 语句的代理。

SELECT FOR UPDATE 语句的执行会申请全局锁 ,如果全局锁被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被 block 住的,直到全局锁拿到,即读取的相关数据是已提交的,才返回。
出于总体性能上的考虑,Seata目前的方案并没有对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句。
本地事务提交
业务数据的更新和前面步骤中生成的UNDO LOG一并提交,将本地事务提交的结果上报给TC。
AT模式二阶段-回滚操作
-
收到TC的分支回滚请求,开启一个本地事务。
-
通过XID和Branch ID查找到相应的UNDO LOG 记录。
-
数据校验:拿 UNDO LOG 中的后镜与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改。这种情况,需要根据配置策略来做处理,详细的说明在另外的文档中介绍。
-
根据 UNDO LOG 中的前镜像和业务SQL的相关信息生成并执行回滚的语句:
update TableXXX set parameter = 'XXX' where condition = value;
- 提交本地事务,并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC。
AT模式二阶段-提交操作
-
收到TC的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给 TC。
-
异步任务阶段的分支提交请求将异步和批量地删除相应 UNDO LOG 记录。
本文来自博客园,作者:洛神灬殇,转载请注明原文链接:https://www.cnblogs.com/liboware/p/17050674.html,任何足够先进的科技,都与魔法无异。
阿里云国际版折扣https://www.yundadi.com |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |