

Lyndon Word 与 Lydon 分解
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
\(\newcommand\m\mathbf\) \(\newcommand\t\texttt\)
\(\text{By DaiRuiChen007}\)
约定:
- 对于两个字符串 \(S,T\),用 \(ST\) 表示将 \(T\) 接在 \(S\) 后面得到的字符串(即 \(S+T\))
- 对于两个字符串 \(S,T\),若 \(S\) 的字典序严格小于 \(T\) 的字典序则即 \(S<T\),若在满足 \(S<T\) 的前提下满足 \(S\) 不是 \(T\) 的前缀,我们记 \(S\ll T\),同理能够得到 \(S>T\) 和 \(S\gg T\) 的定义
一、Lydon Word
I. Lyndon Word 的定义
假如某个字符串 \(S\) 满足 \(|root(S)|=|S|\),且 \(S\) 严格小于 \(S\) 的所有循环同构串,那么称 \(S\) 是一个 Lyndon Word,简记为 LW,并假设所有 LW 构成的集合为 \(\m{LW}\)
II. Lyndon Word 的性质
Lyndon Word 与 Border
断言:对于所有 \(w\in\m{LW}\),均满足:\(w\) 没有 Border,证明如下:
证:
采用反证法,设某个 LW \(w\) 中有 Border \(u\)
不妨设 \(w=ux=yu\),那么由于 LW 的性质,\(xu>w,uy>w\)
又因 \(w=yu\),所以 \(xu>yu\),所以 \(x>y\),同理根据 \(uy>ux\) 有 \(y>x\)
显然导出矛盾,故原命题成立
Lyndon Word 与后缀
Lyndon Word 有等价定义:\(w\in\m{LW}\) 当且仅当 \(w\) 小于其所有真后缀,证明如下:
证:
假设 \(v\) 为 \(w\) 的任意真后缀,且 \(w=uv\)
证明 \(w<v\implies w<vu\)
由于 \(|w|>|v|\),因此 \(w\ll v\),此时 \(w\ll vu\),故原命题得证
证明 \(w<vu\implies w<v\)
考虑 \(w'=w[1\cdots |v|]\),显然 \(w'\le w\),若 \(w'=w\) 那么 \(v\) 是 \(w\) 的一个 Border,与上一个性质矛盾,因此我们知道 \(w'<v\),又因为 \(|w'|=|v|\) 且 \(w'\ne v\),所以 \(w'\ll v\) 所以 \(w<v\)
综上所述,我们证明了 \(w<v\iff w<vu\),那么我们就证明了原命题等价于 LW 的定义,因此“\(w\) 小于其所有真后缀”也是 LW 一个等价的定义
Lyndon Word 的标准分解
Lyndon Word 的复合
假设 \(u,v\in\m{LW}\),那么 \(uv\in\m{LW}\iff u<v\),证明如下:
证:
证明 \(uv\in\m{LW}\implies u<v\)
根据 LW 的等价定义,\(uv\ll v\),又因为 \(u<uv\),因此 \(u<v\) 得证
证明 \(u<v\implies uv\in\m{LW}\)
考虑 \(uv\) 的任意一个真后缀 \(s\)
\(|s|>|v|\) 时
假设 \(s=u'v\),注意到 \(u'\) 是 \(u\) 的真后缀,那么我们知道 \(u'\gg u\),所以我们知道 \(u'\gg uv\) 则 \(s\gg uv\)
\(|s|<|v|\) 时
此时 \(s\) 为 \(v\) 的真后缀,那么 \(s\gg v\),且 \(v>u\),故 \(s\gg u\) 所以 \(s>uv\)
\(|s|=|v|\) 时
显然有 \(s=v\),即证 \(v>uv\)
若 \(u\ll v\)
此时显然有 \(uv\ll v\)
若 \(u\) 为 \(v\) 的前缀
记 \(v=uv'\),即证 \(uv'>uv\),事实上我们只需要比较 \(v'\) 和 \(v\) 的大小即可,注意到 \(v'\) 为 \(v\) 的一个真后缀且 \(v\) 为 LW,那么 \(v'>v\) 成立,所以 \(v>uv\) 成立
综上所述,\(u<v\implies uv\in\m{LW}\)
所以我们证明了 \(\forall u,v\in \m{LW}\),\(uv\in\m{LW}\iff u<v\)
Lyndon Word 的分解
假设 \(w\in\m{LW}\) 且 \(|w|\ge 2\),设 \(v\) 为 \(w\) 的最小真后缀,记 \(w=uv\),则 \(u,v\) 满足 \(u<v\) 且 \(u,v\in\m{LW}\),证明如下:
证:
证明 \(v\in\m{LW}\)
事实上,考虑 \(v\) 的每个真后缀 \(v'\),由于 \(v'\) 也是 \(w\) 的一个真后缀,那么 \(v< v'\) 同样成立,因此 \(v\in\m{LW}\)
证明 \(u<v\)
若 \(|u|\ge |v|\)
那么 \(w<v\) 等价于 \(u<v\),此时命题成立
若 \(|u|<|v|\)
此时由于 \(w<v\) 那么 \(u\le v[1\cdots |u|]\)
若 \(u< v[1\cdots|u|]\)
由于 \(|u|=|v|\) 且 \(u\ne v\),那么 \(u\ll v[1\cdots |u|]\) 则 \(u<v\)
若 \(u=v[1\cdots |u|]\)
此时 \(u\) 是 \(v\) 前缀同样有 \(u<v\) 成立
证明 \(u\in \m{LW}\)
考虑反证法,存在一个 \(u\) 的真后缀 \(u'<u\),那么考虑 \(w\) 的真后缀 \(u'v\)
若 \(u'\ll u\)
那么一定有 \(u'v<uv=w\) 与 \(w\) 是 LW 矛盾
若 \(u'\) 为 \(u\) 前缀
此时设 \(u=u't\),由于 \(w\) 是 LW,那么应该满足 \(u'v>uv\),那么 \(u'v>u'tv\) 即 \(v>tv\),此时出现了一个比 \(v\) 更小的 \(w\) 的真后缀,这与假设矛盾
综上,\(u\) 必须是 LW
综上所述,此时有 \(u<v\) 且 \(u,v\in\m{LW}\)
此时我们可以证明 \(v\) 是 \(w\) 最大的一个 LW 真后缀,证明如下:
证:
假设存在另一个 \(w\) 的 LW 真后缀 \(v'\) 满足 \(|v'|>v\),那么 \(v\) 是 \(v'\) 的真后缀,由于 \(v'\in\m{LW}\),那么 \(v>v'\) 这与 \(v\) 是 \(w\) 的最小真后缀矛盾
而此时我们记 \(w=uv\) 为 \(w\) 的标准分解
基于标准分解的 Lyndon Word 定义形式
\(w\in\m{LW}\) 等价于 \(|w|=1\) 或 \(|w|\ge 2\) 且存在 \(u,v\in\m{LW}\) 满足 \(u<v\) 且 \(w=uv\)
证明如下:
证:
当 \(|w|=1\) 时原命题显然成立,因此只讨论 \(|w|\ge 2\) 的情况,简记该判定条件为“\(\exists u,v\)”
证明 \(\exists u,v\implies w\in\m{LW}\)
根据“Lyndon Word 的复合”一节中的结论,我们知道这个结论是城里的
证明 \(w\in\m{LW}\implies \exists u,v\)
设 \(v\) 为 \(w\) 的最小真后缀,且 \(u\) 满足 \(w=uv\),根据“Lyndon Word的分解”一节中的结论,我们知道此时的 \(uv\) 就满足条件
综上所述,我们知道 \(|w|=1\text{ or }\exists u,v\) 也是一个 LW 的判定方式
III. Lyndon Word 的经典问题
Lyndon Word 的后继问题
假设字符集为 \(\{1,2,\cdots,\sigma\}\),且字符串长度 \(\le n\),给定满足条件的 LW \(S\),求字典序大于 \(S\) 的最小合法 LW \(S'\)
给出一个构造方法,先将 \(S\) 不断循环拼接得到一个长度为 \(n\) 的字符串 \(S^\star\)(最后一个周期可以不是整周期),找到 \(S^\star\) 最后一个不是 \(\sigma\) 的字符 \(S^\star_k\),并让 \(S^\star_k\gets S^\star_k+1\),然后删掉子串 \(S^\star[k+1\cdots n]\) 就得到了 \(S\) 的后继 \(S'\),证明如下:
证:
证明 \(S'\in\m{LW}\)
注意到 \(S^\star[1\cdots k]\) 一定是一个近似 LW,而让 \(S^\star_k\gets S^\star_k+1\),我们就得到了一个 LW,具体的证明请参看后文“Duval 算法求 Lyndon 分解”一章中的“引理”部分和“算法流程”部分的第二种情况,会给出一个严谨的证明
证明不存在 \(T\in\m{LW}\) 满足 \(S<T<S'\)
根据定义,比较 \(T,S'\),假设 \(i\) 表示满足 \(T_i<S'_i\) 的最小 \(i\),显然 \(T[1\cdots |S|]=S\) 所以 \(i\ge |S|\)
假设 \(k\times|S|<i\le (k+1)\times |S|\),且 \(i-k\times|S|=r\in[1,|S|]\)
若 \(i<|S'|\)
考虑 \(T\) 的真后缀 \(T[k\times |S|+1\cdots |T|]\)
根据假设,\(S’[k\times|S|+1\cdots i-1]=T[k\times |S|+1\cdots i-1]\)
由于 \(S'\) 的构造定理,\(S'[k\times |S|+1\cdots i-1]=S[1\cdots r-1]=T[1\cdots r-1]\)
因此,我们如果要比较 \(T\) 与 \(T[k\times |S|+1\cdots |T|]\) 的大小关系,只需比较 \(T_i\) 与 \(T_{r}\) 的大小
注意到 \(T_i<S'_i=S_r<T_r\),因此 \(T[k\times |S|+1\cdots |T|]<T\)
与 \(T\in\m{LW}\) 矛盾,故这种情况不存在
若 \(i=|S'|\)
根据对 \(S'\) 的定义,我们知道 \(k\times |S|<|S'|\le (k+1)\times |S|\),所以 \(|T|\le (k+1)\times S\)
根据定义,此时必然有 \(T_i=S'_i-1=S_{r}\),同样考虑 \(T\) 的真后缀 \(T[k\times |S|+1\cdots |T|]\)
注意到 \(T[i+1\cdots |T|]\le \sigma^{|T|-i}\) 且 \(T[r+1\cdots |S|]=S[r+1\cdots |S|]=\sigma^{|S|-r}\),因此 \(T[i+1\cdots |T|]\le S[r+1\cdots |S|]\)
又因为 \(T[k\times |S|+1\cdots |T|]>T\),这就要求 \(T[k\times|S|+1\cdots i]\gg T[1\cdots r]\),又因为事实上 \(T[k\times |S|+1\cdots i]=T[1\cdots r]\),这就导出了矛盾
综上,我们证明了 \(S'\) 是 \(S\) 在 \(\m{LW}\) 中的后继
Lyndon Word 的计数问题
设字符串长度恰好为 \(n\),字符集大小为 \(m\),统计所有这样的字符串中 LW 的数量
首先考虑 \(S\in\m{LW}\) 的判定条件:
- \(|root(S)|=|S|\)
- \(S\) 小于 \(S\) 的所有循环同构串
先考虑第二个问题,假如我们不保证 \(|root(S)|=|S|\),那么我们可以考虑对“\(S\) 小于等于 \(S\) 的所有循环同构串”的 \(S\) 进行计数,然后再在这些串中统计 \(|root(S)|=|S|\) 的即可
为了解决第一个问题,我们可以这样想:把每个 \(S\) 都到环上,即变成圆排列的形式,那么一个圆排列中的满足条件的 \(S\) 有且仅有一个,所以我们只需要求长度为 \(n\),值域为 \(m\) 的有旋转无翻转圆排列计数即可,记这个问题的答案为 \(S_n\)
接下来考虑第二个问题:在 \(S_n\) 个圆排列中,只有那些最小整周期为 \(n\) 的才能转化成一个 LW,因此我们记:在 \(S_n\) 个圆排列中,最小整周期恰好为 \(n\) 的圆排列的个数为 \(T_n\)
容易证明 \(T_n\) 就是我们要求的答案
首先考虑如何根据 \(T_n\) 推导出 \(S_n\),显然对于一个最小整周期为 \(d\) 且 \(d\mid n\) 的长度为 \(d\) 的圆排列 \(T\),我们构造 \(S=\underbrace{TT\cdots T}_{n/d\text{ times}}=T^{n/d}\),显然这样的 \(S\) 与 \(T\) 之间存在双射,即我们可以证明对于 \(T\) 进行旋转后得到 \(T'\),则 \(S'=(T')^{n/d}\) 与 \(S\) 是循环同构的
因此我们知道对于所有长度为 \(n\),最小整周期为 \(d\) 的圆排列,其总数恰好为 \(T_d\),因此我们得到如下的公式:
注意到这个式子实际上等价于 \(S=T*1\),其中 \(S(n)=S_n,T(n)=T_n,1(n)=1\),\(*\) 为狄利克雷卷积符号
那么根据莫比乌斯反演,我们能够得到 \(T=S*\mu\),即:
因此问题转化为求 \(S_d\) 的值,而求 \(S\) 事实上是一个经典的项链计数问题,在《具体数学》第四章有如下的解法:
解:
对于 \(S_n\) 个本质不同圆排列,我们任意写出其对应的一个字符串,对于每个字符串,再写出其 \(n\) 个循环同构串,构成一个可重集 \(\m A\),显然 \(|\m A|=n\times S_n\),对 \(|\m A|\) 进行 Double-Couting,考虑每个字符串 \(S=S_1S_2S_3\cdots S_{n}\) 出现的次数,根据循环同构的定义得到:
\[|\m A|=\sum_S\sum_{i=1}^{n}[S_1S_2\cdots S_{n}=S_iS_{i+1}\cdots S_{n}S_1\cdots S_{i-1}] \]交换求和号,转化为统计贡献的形式:
\[|\m A|=\sum_{i=1}^{n}\sum_S[S_1S_2\cdots S_{n}=S_iS_{i+1}\cdots S_{n}S_1\cdots S_{i-1}] \]注意到对于给定的 \(i\),满足条件的 \(S\) 当且仅当 \(S\) 有一个大小为 \(i\) 的约数的整周期,事实上,根据整周期的性质,这等价于 \(S\) 有整周期 \(\gcd(n,i)\)
根据整周期的性质,有整周期 \(\gcd(n,i)\) 的 \(S\) 的数量等价于长度为 \(\gcd(n,i)\) 的任意字符串的数量,即 \(m^{\gcd(n,i)}\) 种
所以可以优化掉第二个求和号,再根据 \(\gcd(n,i)\) 的性质对于不同的 \(d=\gcd(n,i)\) 统计对应 \(i\) 的数量,不难得到如下变形过程:
\[|\m A|=\sum_{i=1}^{n} m^{\gcd(n,i)}=\sum_{d\mid n}\varphi\left(\dfrac nd\right)\times m^d \]运用 \(|\m A|=n\times S_n\) 的事实得到 \(S_n=\dfrac 1n\sum_{d|n}\varphi\left(\tfrac nd\right)\times m^d\)
所以我们得到了 \(S_n\) 的一个简洁表达,据此计算 \(T_n\) 即可,不过事实上,\(T_n\) 也有更加优美的形式,具体分析如下:
解:
记 \(id(n)=n\),根据狄利克雷卷积和莫比乌斯反演的基本推论有 \(id=\varphi*1\implies \varphi=id*\mu\)
注意到 \(S=T*1\),且 \(nS=n(T*1)\),我们记一个新的函数 \(T'(n)=nT_n\),注意这里的两个 \(n\) 都是自变量而非常数,考虑构造函数 \(id*T'\),根据狄利克雷卷积定义进行展开:
\[\begin{aligned} id*T'(n) &=\sum_{d\mid n}id\left(\dfrac nd\right)\times T'(d)\\ &=\sum_{d\mid n}\dfrac nd\times(d\times T_n)\\ &=n\sum_{d\mid n} T_n\\ &=n\times(T*1(n)) \end{aligned} \]因此 \(id*T'=n(T*1)\),故 \(n\times S_n=id*T'\)
此时结合 \(nS=\varphi* m^n(n)\) 运用莫比乌斯反演得到:\(id*T'=nS=\varphi *m^n(n)=id*\mu*m^n(n)\)
因此 \(T'=\mu*m^n(n)\)
综上所述,我们得到 \(T_n=\dfrac 1n\sum_{d\mid n}\mu\left(\dfrac nd\right)\times m^d\)
IV. 习题演练
[CSES2209] - Counting Necklaces
项链计数模板,求 \(S_n\) 的值即可,可以用线性筛预处理 \(\varphi(n)\) 的值
时间复杂度 \(\Theta(n+\sqrt n\log n)\)
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int MAXN=1e6+1,MOD=1e9+7;
int n,m,phi[MAXN];
bool mark[MAXN];
vector <int> primes;
inline int ksm(int a,int b,int m=MOD) {
int ret=1;
while(b) {
if(b&1) ret=a*ret%MOD;
a=a*a%MOD;
b=b>>1;
}
return ret;
}
inline int calc(int d) {
return ksm(m,d)*phi[n/d]%MOD;
}
signed main() {
int ans=0;
scanf("%lld%lld",&n,&m);
phi[1]=1;
for(int i=2;i<=n;++i) {
if(!mark[i]) phi[i]=i-1,primes.push_back(i);
for(int p:primes) {
if(p*i>n) break;
mark[p*i]=true,phi[p*i]=(i%p==0)?(phi[i]*p):(phi[i]*(p-1));
if(i%p==0) break;
}
}
for(int i=1;i*i<=n;++i) {
if(n%i!=0) continue;
ans=(ans+calc(i))%MOD;
if(i*i!=n) ans=(ans+calc(n/i))%MOD;
}
printf("%lld\n",ans*ksm(n,MOD-2)%MOD);
return 0;
}
[CSES2210] - Counting Grids
类似上一个问题,记答案为 \(S_n\),对于一个染色的 \(n\times n\) 网格,将其旋转四次后做 Double-Counting,考虑每个网格在旋转多少度后重复出现了多少次
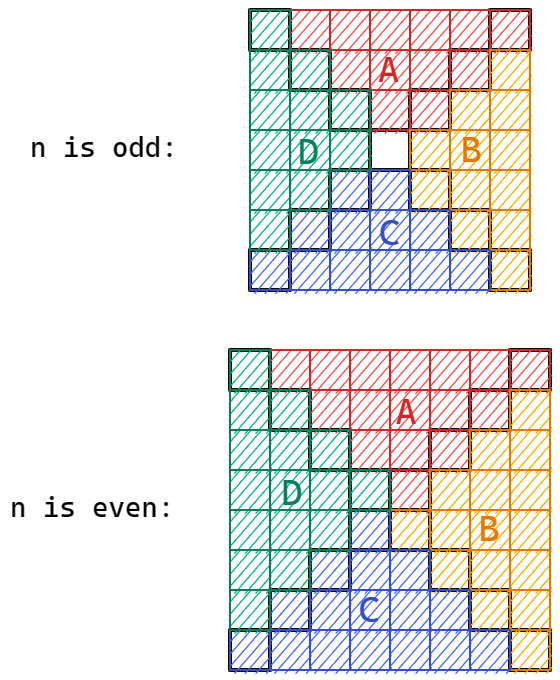
如上图,根据旋转网格的性质我们可以把一个网格划分成 \(4\) 块,分别是 \(A,B,C,D\),不难发现每次旋转后只会交换 \(A,B,C,D\) 的相对顺序,并不会改变 \(A,B,C,D\) 的块内心态,记每块的大小为 \(m\),对 \(n\) 的奇偶性分别讨论:
-
\(n\) 为奇数时
此时 \(m=\dfrac{n^2-1}4\)
-
某个网格在旋转 \(0^\circ\) 时出现过
任何的网格都符合这样的要求,这样的网格共有 \(2^{n\times n}\) 个
-
某个网格在旋转 \(180^\circ\) 时出现过
这要求 \(A=B,C=D\),而中间的那个位置可以随便取色,这样的网格共有 \(2\times 2^m\times 2^m=2^{2\times m+1}\)
-
某个网格在旋转 \(90^\circ\) 或 \(270^\circ\) 时出现过
这要求 \(A=B=C=D\),而中间那个位置依然可以随便取色,这样的网格共有 \(2\times 2^m=2^{m+1}\) 个
综上,我们得到 \(4\times S_n=2^{n\times n}+2^{m+1}+2^{2\times m+1}+2^{m+1}\),当 \(n>1\) 时,\(S_n=2^{n\times n-2}+2^{2\times m-1}+2^m\),当 \(n=1\) 时 \(S_n=2\)
-
-
\(n\) 为偶数时
此时 \(m=\dfrac{n^2}4\)
-
某个网格在旋转 \(0^\circ\) 时出现过
任何的网格都符合这样的要求,这样的网格共有 \(2^{n\times n}\) 个
-
某个网格在旋转 \(180^\circ\) 时出现过
这要求 \(A=B,C=D\),这样的网格共有 \(2^m\times 2^m=2^{2\times m}\)
-
某个网格在旋转 \(90^\circ\) 或 \(270^\circ\) 时出现过
这要求 \(A=B=C=D\),而中间那个位置依然可以随便取色,这样的网格共有 \(2^m\) 个
综上,我们得到 \(4\times S_n=2^{n\times n}+2^{m}+2^{2\times m}+2^m\),则 \(S_n=2^{n\times n-2}+2^{2\times m-2}+2^{m-1}\)
-
综上所述,我们得到 \(S_n\) 的表达式:
快速幂计算即可
时间复杂度 \(\Theta(\log n)\)
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int MOD=1e9+7;
inline int ksm(int a,int b,int m=MOD) {
int ret=1;
while(b) {
if(b&1) ret=a*ret%MOD;
a=a*a%MOD;
b=b>>1;
}
return ret;
}
signed main() {
int n;
scanf("%lld",&n);
int m=(n%2==1)?((n*n-1)/4):(n*n/4);
if(n==1) puts("2");
else if(n%2==1) printf("%lld\n",(ksm(2,n*n-2)+ksm(2,2*m-1)+ksm(2,m))%MOD);
else printf("%lld\n",(ksm(2,n*n-2)+ksm(2,2*m-2)+ksm(2,m-1))%MOD);
return 0;
}
[BZOJ1361] - [WC2004]孪生项链
根据“Lyndon Word”的经典问题一节中介绍的公式计算即可,注意第一问要写高精度
时间复杂度 \(\Theta(k\sqrt k+n)\),其中 \(\Theta(k\sqrt k)\) 的 \(\Theta(\sqrt k)\) 是枚举因子数量 \(\Theta(k)\) 是高精度复杂度
#include<bits/stdc++.h>
using namespace std;
const int MAXN=1001;
struct BigInt {
vector <int> dig;
BigInt() { dig.clear(); }
BigInt(vector <int> _dig) { dig=_dig; }
BigInt(int x) {
while(x) dig.push_back(x%10),x/=10;
}
inline int& operator [](int x) { return dig[x]; }
inline int length() { return (int)dig.size(); }
inline void update() {
while(!dig.empty()&&dig.back()==0) dig.pop_back();
}
inline friend BigInt operator +(BigInt &A,BigInt &B) {
BigInt C(vector<int>(max(A.length(),B.length())+1,0));
for(int i=0;i<A.length();++i) C[i]+=A[i];
for(int i=0;i<B.length();++i) C[i]+=B[i];
for(int i=0;i<C.length()-1;++i) C[i+1]+=C[i]/10,C[i]%=10;
C.update();
return C;
}
inline friend BigInt operator -(BigInt &A,BigInt &B) {
BigInt C(vector<int>(max(A.length(),B.length())+1,0));
for(int i=0;i<A.length();++i) C[i]+=A[i];
for(int i=0;i<B.length();++i) C[i]-=B[i];
for(int i=0;i<C.length()-1;++i) while(C[i]<0) --C[i+1],C[i]+=10;
C.update();
return C;
}
inline friend BigInt operator /(BigInt &A,const int &d) {
BigInt B(vector<int>(A.length(),0));
for(int i=A.length()-1,r=0;i>=0;--i) r=r*10+A[i],B[i]=r/d,r%=d;
B.update();
return B;
}
inline void print() {
for(int i=(int)dig.size()-1;i>=0;--i) printf("%d",dig[i]);
puts("");
}
} pw[MAXN];
int mu[MAXN];
bool mark[MAXN];
vector <int> primes;
signed main() {
int n,m,k;
string S;
cin>>n>>m>>k>>S;
//task 1
pw[0]=BigInt(1);
for(int i=1;i<=k;++i) mu[i]=1,pw[i]=pw[i-1]+pw[i-1];
for(int i=2;i<=k;++i) {
if(!mark[i]) mu[i]=-1,primes.push_back(i);
for(int p:primes) {
if(p*i>k) break;
mark[p*i]=true,mu[p*i]=(i%p==0)?0:(-mu[i]);
if(i%p==0) break;
}
}
BigInt ans(0);
for(int i=1;i*i<=k;++i) {
if(k%i!=0) continue;
if(mu[i]==1) ans=ans+pw[k/i];
if(i*i!=k&&mu[k/i]==1) ans=ans+pw[i];
}
for(int i=1;i*i<=k;++i) {
if(k%i!=0) continue;
if(mu[i]==-1) ans=ans-pw[k/i];
if(i*i!=k&&mu[k/i]==-1) ans=ans-pw[i];
}
ans=ans/k;
ans.print();
//task 2
string T;
while((int)T.length()<n) T=T+S;
T.resize(n);
while(!T.empty()&&T.back()=='1') T.pop_back();
assert(!T.empty());
T[(int)T.length()-1]='1';
cout<<T<<"\n";
return 0;
}
[CodeForcesGym - 100162G] - Lyndon Words
从 \(\texttt{a}\) 开始每次暴力找后缀就行,注意实现常数,比如不要用 STL string 类,最好自己手写一个字符数组维护一下尾指针就行
#include<bits/stdc++.h>
using namespace std;
const int MAXN=31;
char ch[MAXN];
signed main() {
int n,m,l,r,T=0;
while(scanf("%d%d%d%d",&n,&m,&l,&r)!=EOF) {
char sigma=m-1+'a';
printf("Case %d:\n",++T);
int tail=0; ch[++tail]='a';
for(int id=1;id<=r;++id) {
if(l<=id) {
for(int i=1;i<=tail;++i) putchar(ch[i]);
putchar('\n');
}
int cyc=tail;
while(tail<n) {
++tail;
ch[tail]=ch[tail-cyc];
}
while(ch[tail]==sigma) --tail;
++ch[tail];
}
}
}
二、Lyndon 分解
I. Lyndon 分解定理
Lyndon 分解的定义
首先定义对于任意字符串 \(S\) 的一个 Lyndon 分解:
Lyndon 分解指的是一个字符串序列 \(w=\{w_1,w_2,w_3,\cdots,w_k\}\),满足 \(S=w_1w_2w_3\cdots w_k\),其中 \(w_i\in\m{LW}\),且 \(w_1\ge w_2\ge w_3\ge\cdots\ge w_k\)
Lyndon 分解定理
Lyndon 分解定理告诉我们,对于任意字符串 \(S\),其 Lyndon 分解存在且唯一
Lyndon 分解的存在性
首先我们把 \(S\) 写成 \(S=S_1S_2S_3\cdots S_{|S|}\),此时我们就把 \(S\) 写成了 \(|S|\) 个 LW 的形式
此时对于任意两个相邻的 LW \(w_i,w_{i+1}\),若 \(w_i<w_{i+1}\) 我们就把 \(w_i,w_i+1\) 合并成 \(w_iw_{i+1}\) 不断重复这个过程直到这样的 \(w_i,w_{i+1}\) 不存在为止,可以证明这个过程一定会停止,那么我们就得到了一个 Lyndon 分解
Lyndon 分解的唯一性
假设 \(S\) 存在两个不同的 Lyndon 分解 \(w_1\sim w_k\) 与 \(w'_1\sim w'_{k'}\)
如下图,假设 \(w_i\) 与 \(w'_i\) 是这两个分解第一个不同的地方,且 \(|w_i|>|w'_i|\),我们设 \(|w'_iw'_{i+1}\cdots w'_{i+j}|\ge w_i\),且 \(|w'_iw'_{i+1}\cdots w'_{i+j-1}|< w_i\),显然 \(j\ge 1\),\(T\) 为 \(w_i\) 与 \(w'_{i+j}\) 的交
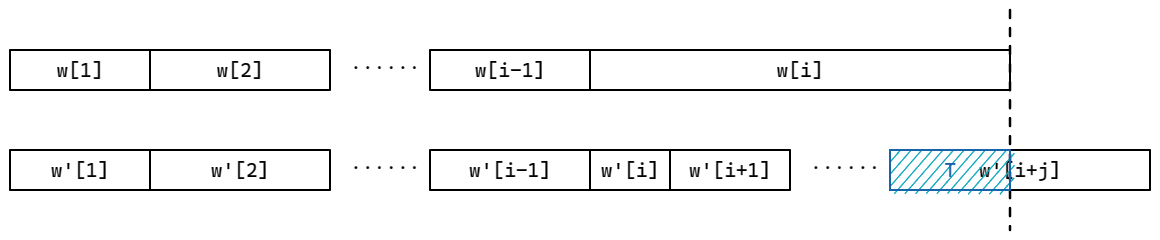
根据 \(w'\) 是一个 Lyndon 分解的假设,我们得到 \(T\le w'_{i+j}\le w'_{i+j-1}\le\cdots\le w'_i\le w_i\),又因为 \(T\) 是 \(w_i\) 的一个真后缀,那么 \(T\le w_i\) 与 \(w_i\) 是 LW 的要求矛盾,因此这样的 Lyndon 分解必须是唯一的
II. Lyndon 分解的性质
定义 \(w=\{w_1,w_2\cdots ,w_k\}\) 为 \(S\) 的 Lyndon 分解,我们有如下的性质:
Lyndon 分解与最小后缀
\(w_k\) 为 \(S\) 的最小后缀,证明如下:
证:
对于长度小于 \(|w_k|\) 的后缀,根据 \(w_k\) 是 LW 的事实即可得到所有长度小于 \(|w_k|\) 的后缀字典序一定大于 \(w_k\)
而对于任意长度大于 \(|w_k|\) 的后缀 \(S'\),我们设 \(S'=w'_iw_{i+1}w_{i+2}\cdots w_k\),其中 \(w'_i\) 是 \(w_i\) 的一个后缀,那么根据 Lyndon 分解的定义,\(w_k\le w_{k-1}\le\cdots \le w_i\),且由于 \(w'_i\) 是 LW \(w_i\) 的一个后缀,我们知道 \(w'_i\le w_i\),因此 \(w_k\le w'_i\) 又因 \(|S'|>|w_k|\),所以 \(S'>w_k\)
综上,\(w_k\) 为 \(S\) 的最小后缀
Lyndon 分解与最长 LW 后缀
\(w_k\) 为 \(S\) 最大的 LW 后缀,证明如下:
证:
对于任意长度大于 \(|w_k|\) 的后缀 \(S'\),我们设 \(S'=w'_iw_{i+1}w_{i+2}\cdots w_k\),其中 \(w'_i\) 是 \(w_i\) 的一个后缀,同上面的分析,\(S'>w_k\),那么 \(S'\) 必然不可能是 LW
Lyndon 分解与最长 LW 前缀
\(w_1\) 为 \(S\) 最大的 LW 前缀,证明如下:
证:
对于任意长度大于 \(|w_1|\) 的前缀 \(S'\),我们设 \(S'=w_1w_2\cdots w'_i\),其中 \(w'_i\) 为 \(w_i\) 的一个前缀,类似上面的过程,我们得到 \(w'_i\le w_i\le w_{i-1}\le\cdots \le w_1\),且 \(|w'_i|<|S'|\),因此 \(w'_i<S'\),那么 \(S'\) 必然不可能是 LW
III. Duval 算法求 Lyndon 分解
介绍
Duval 算法是一种支持在 \(\Theta(|S|)\) 时间内求出 \(S\) 的 Lyndon 分解的算法
引理
我们定义字符串 \(w'\) 为“近似LW”当且仅当存在 \(w\in\m{LW}\) 使得 \(w'\) 为 \(w\) 的一个前缀
那么我们有如下的引理:若 \(w’\) 为一个近似 LW,其中 \(\t c\) 为 \(w'\) 的最后一个字符,如果把 \(\t c\) 修改成一个更大的字符 \(\t d\) ,那么新的 \(w'\) 为一个 LW
证:
不妨设 \(w'u\) 为一个 LW,那么考虑 \(w'\) 的一个真后缀 \(v\),记 \(w=v'v\),那么根据 \(w'u\) 为 LW,我们知道 \(vu>w'u\),且 \(|v|<|w'|\),考虑 \(v\) 和 \(w'[1\cdots |v|]\) 的大小关系,显然 \(v\ge w'[1\cdots |v|]\)
那么此时考虑增大 \(w'\) 的末尾,那么 \(v\) 的末尾会增大且 \(w'[1\cdots |v|]\) 的末尾不会增大,因此 \(v> w'[1\cdots|v|]\),由于 \(v\ne w'[1\cdots |v|]\),所以 \(v\gg w'[1\cdots |v|]\) 所以 \(v>w'\),故修改后的 \(w'\) 是一个 LW
维护内容
如下图,在 Duval 算法的过程中,我们将整个字符串 \(S\) 分成了三个部分,并且维护了一些变量:

- \(S_1\):已经扫描并处理完成的串
- \(w_1\sim w_g\):一些满足 \(w_1\ge w_2\ge \cdots\ge w_g\) 且 \(S_1=w_1w_2\cdots w_g\) 的一些 LW
- \(i\):\(S_1\) 的尾指针,满足 \(S_1=S[1\cdots i-1]\),\(S_2\) 的头指针
- \(S_2\):已经扫描但尚未处理完成的串
- \(t_1\sim t_h\):一些满足 \(t_1=t_2=\cdots =t_h\) 的 LW,且 \(w_g>t_h\)
- \(t'\):\(S_2\) 拆分后剩下的一个近似 LW 串,满足 \(t'\) 是 \(t_h\) 的某个前缀
- \(j\):维护 \(t'\) 与 \(t_h\) 的匹配长度
- \(k\):\(S_2\) 的尾指针,满足 \(S_2=S[i\cdots k-1]\),\(t'\) 的尾指针,满足 \(|t_h|=k-j\),\(S_3\) 的头指针
- \(S_3\):未扫描的串
算法流程
考虑每次将 \(k\) 右移一位,并且讨论 \(S_j\) 和 \(S_k\) 的大小关系
- \(S_j=S_k\),\(t'\) 与 \(t_h\) 继续匹配即可 \(j\gets j+1,k\gets k+1\)
- \(S_j<S_k\),此时根据引理可以知道新的 \(t'\) 会变成一个 LW 满足 \(t'>t_h\),那么根据“Lyndon Word 的复合”一节中的结论,\(t_ht'\) 也是一个 LW,那么由于 \(t_ht'>t_h=t_{h-1}\) 继续重复不断使用该结论即可证明 \(t_1t_2\cdots t_ht'\) 为 LW,因此设整个 \(t_1t_2\cdots t_ht'\) 为新的 \(t_1\),即 \(j\gets i,k\gets k+1\)
- \(S_j>S_k\),失配了,此时把 \(t_1\sim t_h\) 变成 \(w_{g+1}\sim w_{g+h}\),后面新生成的 Lyndon 串也不会超过 \(w_{g+h}=t_h\),并且此时重新匹配 \(k\),记 \(S_t\) 为 \(t'\) 的第一个字符,即 \(i\gets t,j\gets t,k\gets i+1\)
复杂度分析
注意到只有 \(k\) 会回退,而 \(i\) 每次都是增加的且每次回退 \(k\) 事实上也不减小 \(i+k\) 的值,均摊分析可以证明 Duval 算法的复杂度是 \(\Theta(|S|)\) 的
代码实现
根据上面的流程,我们能够写出如下伪代码(记 \(n=|S|\)):
i=1
while i<=n:
j=i,k=i+1
while k<=n and S[j]<=S[k]:
if S[j]=S[k]:
j=j+1,k+k+1
else:
j=i,k=k+1
while i<=j:
print(S[i...(i+k-j+1)])
i=i+k-j
IV. Lyndon 分解与最小表示
最小表示定义为一个字符串 \(S\) 的所有循环同构串(含自身)中字典序最小的一个
我们有如下的结论:对 \(S^2\) 进行 Lyndon 分解,设 \(w_i\) 对应子串 \(S^2[l_i\cdots r_i]\),那么找到满足 \(l_i\le |S|< r_i\) 的 \(i\) 则 \(S^2[l_i\cdots l_i+n-1]\) 即为 \(S\) 的最小表示,证明如下:
证:
对于任意循环同构串 \(S^2[l\cdots r]\ne S^2[l_i\cdots l_i+n-1]\),由于 \(|S^2[l\cdots r]|=r-l+1=S\),那么 \(r\le |S|\le r_i\) 总是成立,假设 \(S^2[l\cdots r]=w'_jw_{j+1}\cdots\),其中 \(w'_j\) 为 \(w_j\) 的一个后缀,且我们知道 \(i\le j\),那么我们有 \(w'_j>w_j>w_{j+1}>\cdots >w_i\),这就证明了 \(S^2[l\cdots r]<S[l_i\cdots l_i+n-1]\)
V. 习题演练
[洛谷6114] - 【模板】Lyndon 分解
模板题,直接用 Duval 算法求 Lyndon 分解即可
时间复杂度 \(\Theta(|s|)\)
#include<bits/stdc++.h>
using namespace std;
const int MAXN=5e6+5;
char s[MAXN];
signed main() {
scanf("%s",s+1);
int n=strlen(s+1),ans=0;
for(int i=1;i<=n;) {
int j=i,k=i+1;
while(k<=n&&s[j]<=s[k]) j=(s[j]==s[k])?(j+1):i,++k;
while(i<=j) ans^=(i+k-j-1),i+=k-j;
}
printf("%d\n",ans);
return 0;
}
[洛谷1368] - 【模板】最小表示法
模板题,根据我们上面的分析,先用 Duval 算法求出 \(\{a_i\}^2\) 的 Lyndon 分解,然后找到满足条件的 \(w_i\) 即可
时间复杂度 \(\Theta(n)\)
#include<bits/stdc++.h>
using namespace std;
struct node {
int l,r;
node() { l=r=0; }
node(int _l,int _r) { l=_l,r=_r; }
};
const int MAXN=1e6+1;
int S[MAXN];
signed main() {
vector <node> w;
int n;
scanf("%d",&n);
for(int i=1;i<=n;++i) scanf("%d",&S[i]),S[i+n]=S[i];
int m=n<<1;
for(int i=1;i<=m;) {
int j=i,k=i+1;
while(k<=m&&S[j]<=S[k]) j=(S[j]==S[k])?(j+1):i,++k;
while(i<=j) w.push_back(node(i,i+(k-j)-1)),i+=k-j;
}
for(auto x:w) {
if(x.l<=n&&n<x.r) {
for(int i=x.l;i<x.l+n;++i) printf("%d ",S[i]);
puts(""); break;
}
}
return 0;
}