

高并发多级缓存架构解决方案 && OpenResty、canal搭建及使用流程
阿里云国际版折扣https://www.yundadi.com |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
高并发多级缓存架构解决方案
1、缓存的常规使用方式
我们使用redis作为项目中的缓存中间件一般的流程是这样的接收请求并到Redis中查询如果Redis缓存未命中则到数据库中查询再把查询到的值存入Redis中为下次缓存命中做准备
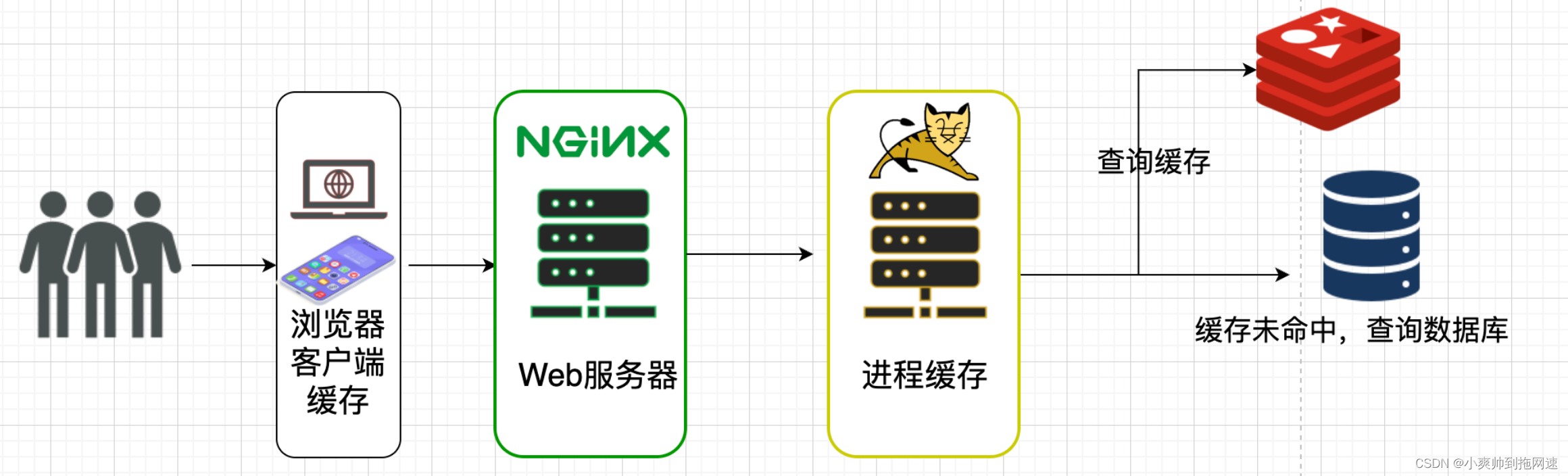
2、请求流程拆分
此时从客户端发出请求到服务器端响应的流程是这样的
客户端发起异步请求到web服务器nginxnginx可以提前保存好静态数据(图片、视频等)减轻后端服务器的压力nginx反向代理到tomcat服务器再去查询redis若缓存命中则直接返回缓存未命中则查询数据库进行缓存重建后返回结果
问题
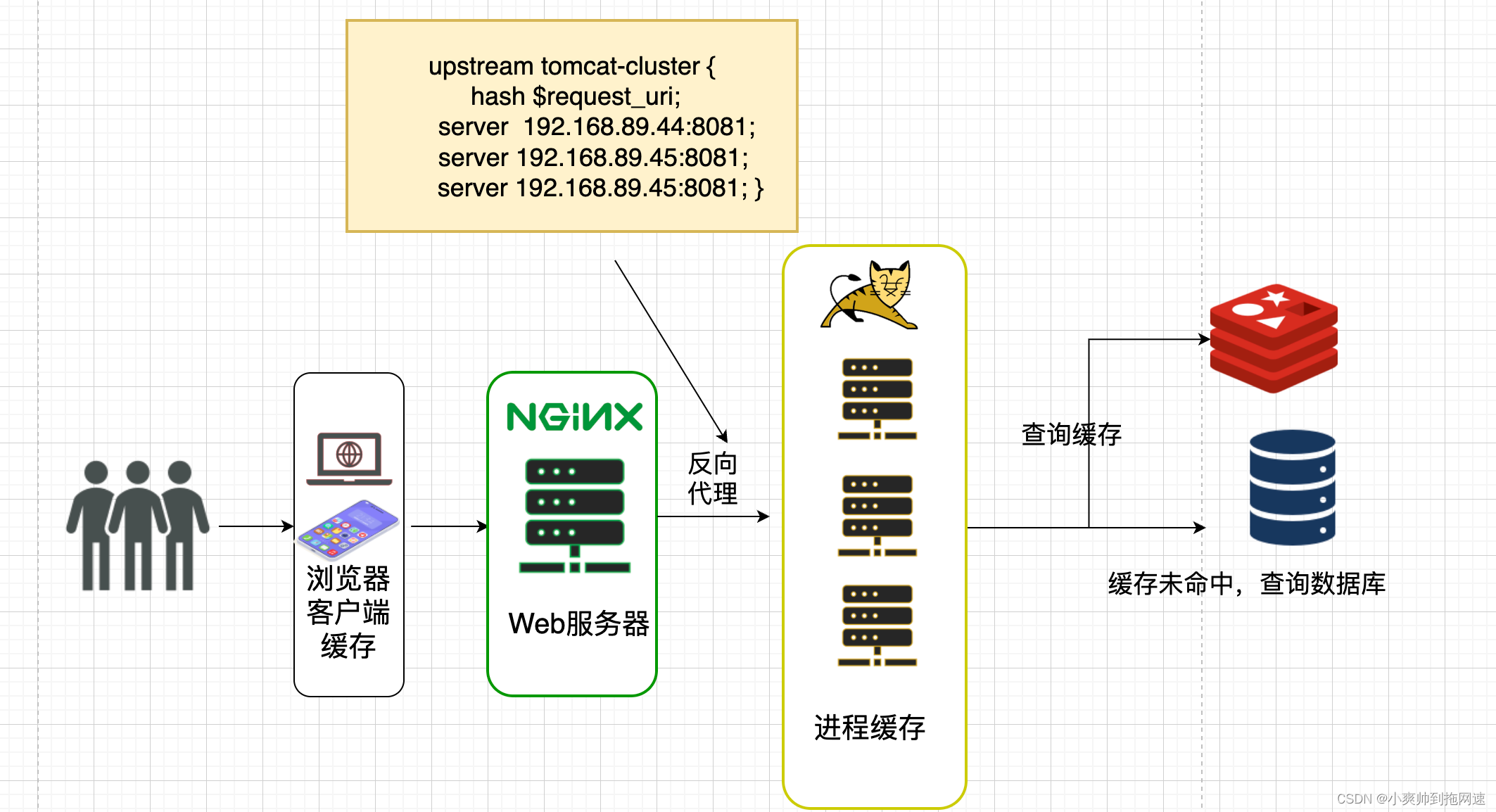
依据这个流程我们不难发现Tomcat将会是整个项目的性能瓶颈Tomcat默认的http实现是采用阻塞式的Socket通信每个请求都要创建一个线程处理Tomcat默认配置的最大请求是150也就是说单个tomcat服务器同时支持150个并发但是具体承载多少并发需要看硬件的配置CPU核数越高分配给JVM内存越多性能也就越高但同时也加重GC的负担此时单个tomcat服务器节点已不能满足我们的需求就需要搭建Tomcat集群以此通过横向拓展的方式提高我们整个项目的并发量
1、搭建tomcat集群
我们通过投钱搭建服务器增加3台tomcat服务器数量以此提高并发量为150*3如果当前每秒QPS是1w并且假设平均的服务器处理时间 (RT)是0.5秒那么在这里1s内意味着有2000个线程同时在执行 并且你的技术老大跟你说该业务不得出现熔断、限流的措施必须保证响客户端请求这个时候就应该意识到tomcat是重量级服务器它的算力上限瓶颈是无论如何都避免不了的
请求到达tomcat即使做了tomcat集群整个后端服务的并发量也不达到我们的预期
既然无法从tomcat这里入手那么我就从nginx入手可以把查询缓存的操作交由nginx去执行正常Nginx Linux 服务器可以达到 500,000 – 600,000 次/秒 的请求处理性能如果Nginx服务器经过优化的话则可以稳定地达到 904,000 次/秒 的处理性能大大提高Nginx的并发访问量可以使用OpenResty 来替代原本的nginx
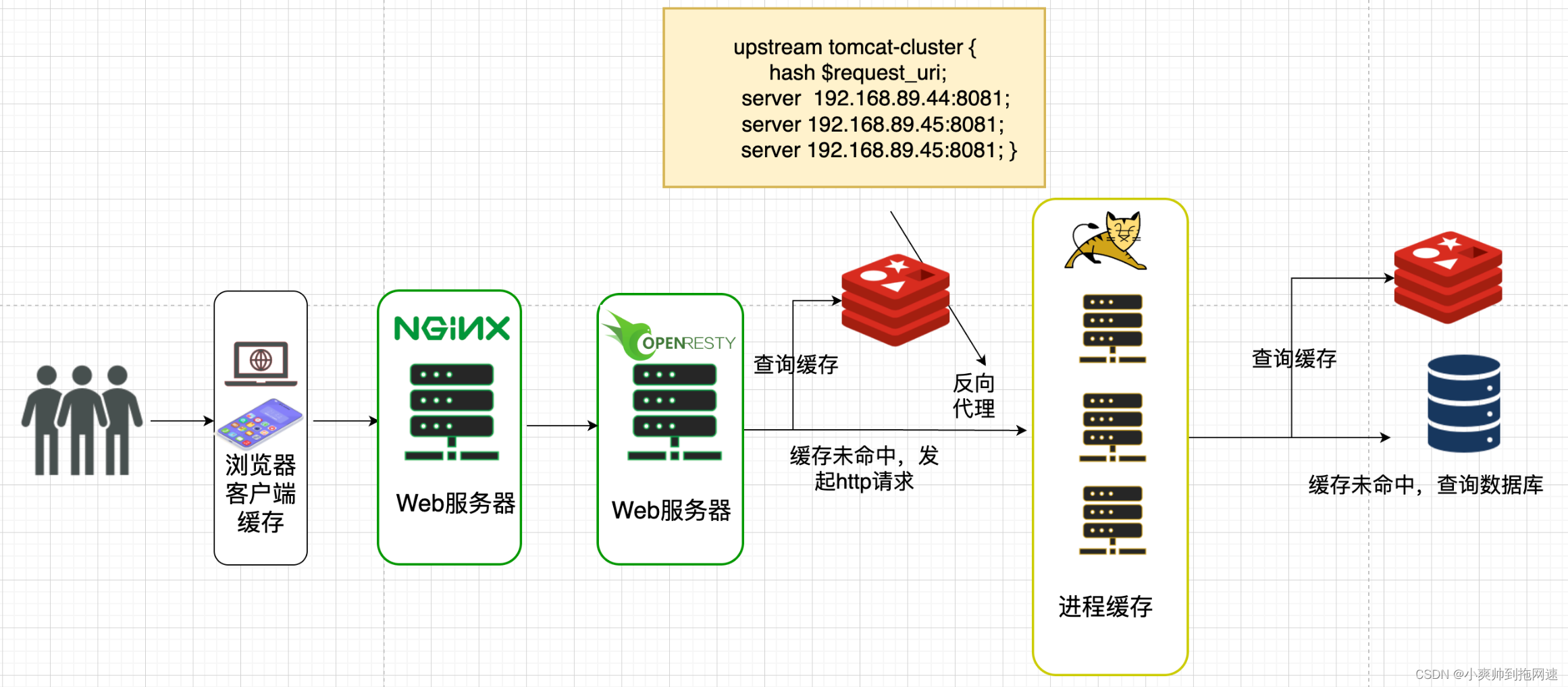
2、搭建OpenResty
那么什么是OpenResty呢为什么说使用OpenResty
OpenResty是一个基于Nginx的高性能Web平台用于方便搭建能够处理超高并发、拓展性极高的动态Web应用、Web服务和动态网关。
- 具备Nginx的完整功能
- 基于Lua语言进行拓展继承大量精良的Lua库、第三方模块
- 允许使用Lua自定义业务逻辑、自定义库
OpenResty的目录结构
显然可以发现openResty包含了完整的Nginx并且使用的方式都和原来一样并且支持通过lua脚本连接到redis服务器查询缓存同时OpenResty还支持本地缓存模块

nginx的配置文件
我们可以先看一下nginx的配置文件主要做了以下几件事情
1、导入加载lua脚本的路径
2、导入加载c模块的路径
3、拦截客户端的异步请求执行lua脚本返回值类型为json
/usr/local/openresty/nginx/conf/nginx.conf
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
# 添加共享字典 本地缓存
# 启动缓存关键字 缓存名 缓存大小
lua_shared_dict item_cache 150m;
server {
listen 8081;
server_name localhost;
location ~ /api/item/(\d+) {
default_type application/json;
content_by_lua_file lua/item.lua;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
lua脚本的执行流程
OpenResty通过lua脚本查询Redis缓存并且将查询到的缓存保存在OpenResty本地
先通过查询OpenResty本地缓存若查询不到则查询Redis若缓存依旧未命中则通过发送http请求到tomcat集群但是http请求只携带请求路径和参数并不包括ip和端口号我们可以通过OpenResty中的nginx模块去捕获请求的路径然后通过反向代理到tomcat服务器
read_http 封装了http请求函数
read_redis封装了调用redis请求函数
ngx.shared.item_cache 是OpenResty提供的本地缓存模块
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson库
local cjson = require('cjson')
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache
-- 封装查询函数
function read_data(key,expire,path,params)
-- 查询本地缓存
local val = item_cache:get(key)
if not val then
ngx.log(ngx.ERR,"本地缓存查询失败,尝试查询redis, key:",key)
-- 查询redis
val = read_redis('127.0.0.1',6379,key)
-- 判断查询结果
if not val then
-- redis 查询失败
ngx.log(ngx.ERR,"redis查询失败,尝试查询http key:",key)
-- 查询http
val = read_http(path,params)
end
end
-- 查询成功,把数据写入本地缓存
item_cache:set(key,val,expire)
-- 返回成功
return val
end
-- 获取路径参数
local id = ngx.var[1]
-- 查询商品信息
local itemJSON = read_data("item:id:"..id,1800,"/item/" .. id, nil)
-- 查询商品库存
local stockJSON = read_data("item:stock:id:"..id,60,"/item/stock/" .. id, nil)
-- 转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 返回结果,商品反序列化
ngx.say(cjson.encode(item))
http请求反向代理到tomcat服务器
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
##c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
# 添加共享字典 本地缓存
# 启动缓存关键字 缓存名 缓存大小
lua_shared_dict item_cache 150m;
upstream tomcat-cluster {
# 通过hash策略计算出每个请求路径固定访问的tomcat节点为jvm进程缓存做准备
hash $request_uri;
server 192.168.89.44:8081;
server 192.168.89.45:8082;
server 192.168.89.46:8083;
}
server {
listen 8081;
server_name localhost;
# 捕获lua脚本中的http请求路径为item通过反向代理到tomcat集群
location /item {
proxy_pass http://tomcat-cluster;
}
location ~ /api/item/(\d+) {
default_type application/json;
content_by_lua_file lua/item.lua;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
3、OpenResty、Redis的单点故障问题
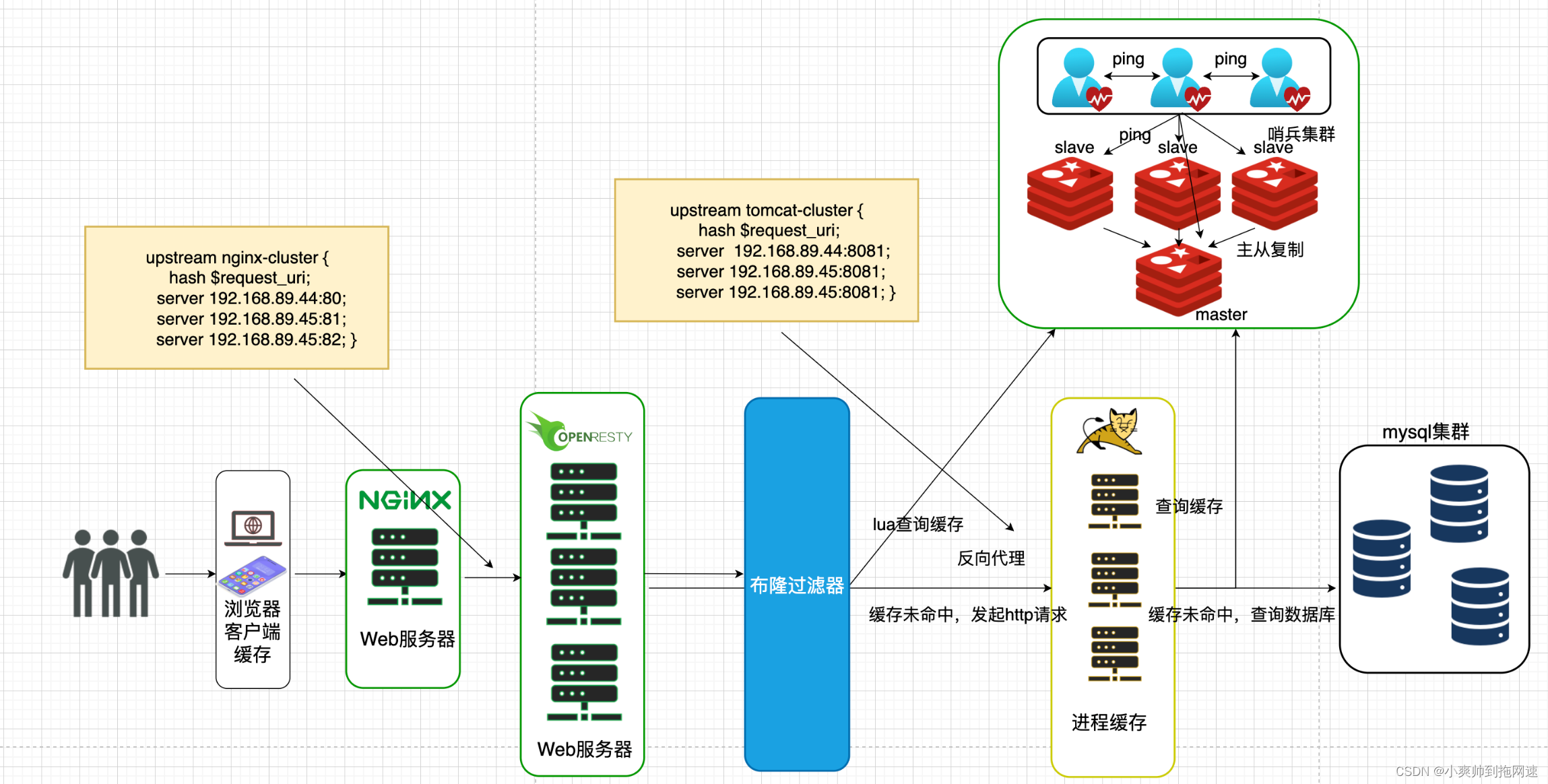
任何分布式系统都难免出现单点故障为保证服务的高可用我们通过搭建集群以数据冗余、服务冗余的方式防止由于网络波动、服务器挂机阻塞导致整个系统发生故障所以OpenResty需要搭建集群而Redis根据业务的需要如果是读多写少的场景并且是高并发读可以搭建主从集群实现读写分离并且通过哨兵集群实现故障自动转移如果业务有海量的数据并且存在高并发写的场景需要搭建分片集群实现多主多从
目前整个业务流程如下

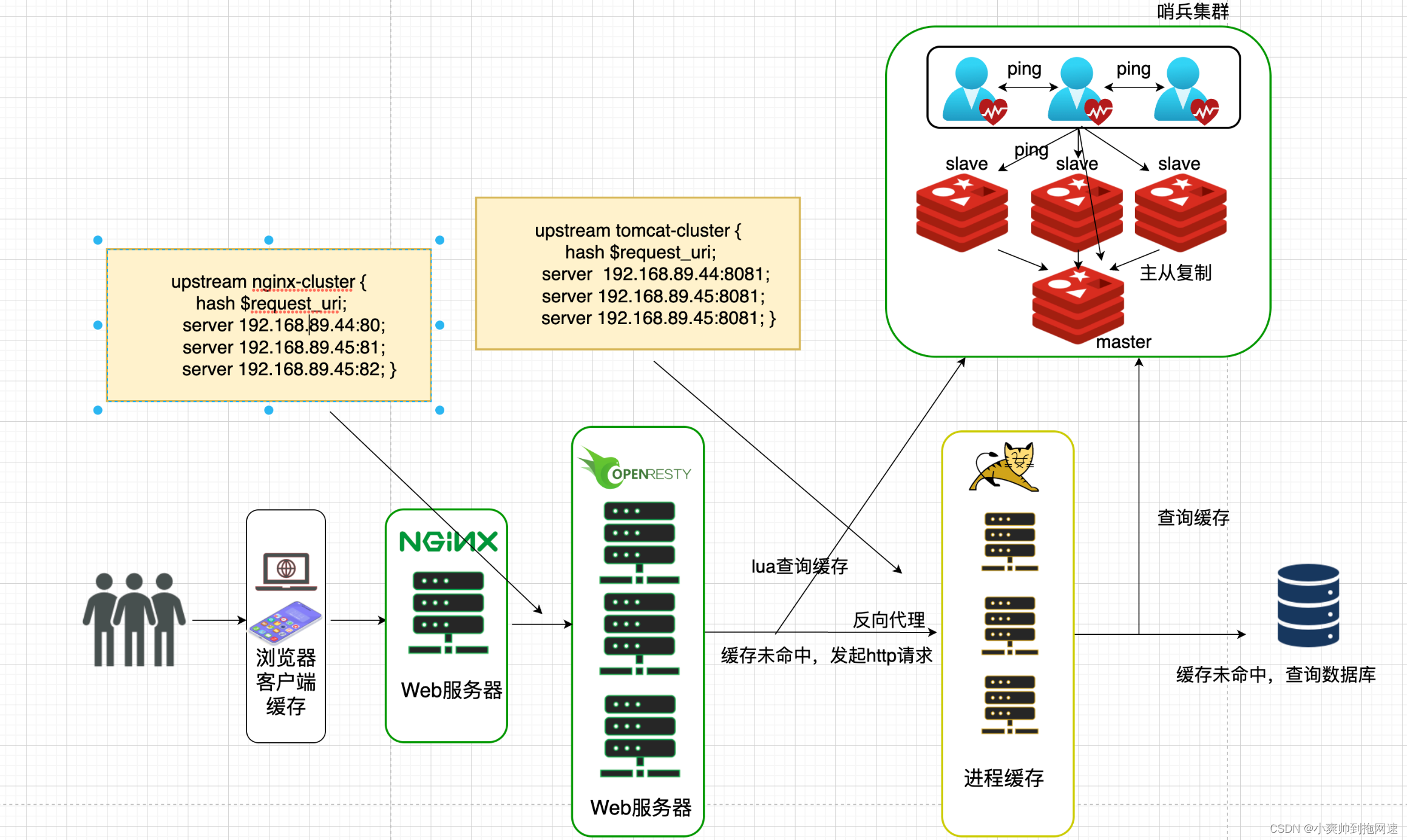
4、防止缓存穿透
使用分布式缓存后伴随着提高服务的响应速度之外也带了许多隐患如缓存击穿、缓存穿透、缓存雪崩等问题其中缓存穿透我们可以通过策略来避免
缓存穿透redis缓存中不存在数据库也查询不到在高并发下大量请求都会落到数据库中使数据库存在服务响应缓慢甚至宕机的风险
解决缓存穿透的方法也有很多比如前端设置些id基础校验、或者增加id复杂度避免被恶意猜测通过后端编码实现的方式就有缓存空对象和布隆过滤器了
缓存空对象这里不再阐述我们重点介绍布隆过滤在业务流程中如何引入
布隆过滤器依靠redis中bitmap特殊的数据结构可以把bitmap理解为一个巨大的二进制数组通过0跟1代表数据是否存在可以提前把某个热点数据的id通过一定的hash算法存储到对应的bitmap中客户端请求的id也通过同样的hash算法后去bitmap中查找若为1则数据一定存在再去redis或数据库中查找
布隆过滤器的原理
第一步插入集合当一个元素被加入集合时通过K个散列函数将这个元素映射成一个位数组中的K个点把它们置为1。
第二步检索集合我们只要看看这些点是不是都是1就大约知道集合中有没有它了如果这些点有任何一个0则被检元素一定不在如果都是1则被检元素很可能在。
(注意Bloom Filter跟单哈希函数Bit-Map不同之处在于Bloom Filter使用了k个哈希函数每个字符串跟k个bit对应。从而降低了冲突的概率
布隆过滤器作为一个判断集合中是否存在元素的算法。
第一个设计一个足够好的hash算法足够散列足够平均使哈希冲突的概率尽可能小。
第二个一个哈希算法终究是不够的使用多个哈希算法使哈希冲突的概率尽可能小。
两个点都是一个目的降低哈希冲突。
布隆过滤器的核心不存储数据的本身。
布隆过滤器算法优点因为不存储数据本身所以数据空间小检索快带来了优点
数据空间小不用存储数据本身。
布隆过滤器算法本身缺点因为不存储数据本身所以误差和难以删除带来了缺点
1元素可以添加到集合中但不能被删除。
2匹配结果只能是“绝对不在集合中”并不能保证匹配成功的值已经在集合中。
3当集合快满时即接近预估最大容量时误报的概率会变大。
4数据占用空间放大。一般来说对于1%的误报概率每个元素少于10比特与集合中的元素的大小或数量无关。 查询过程变慢hash函数增多导致每次匹配过程需要查找多个位hash个数来确认是否存在。
小结对于BloomFilter的优点来说缺点都可以忽略。毕竟只需要kN的存储空间就能存储N个元素。空间效率十分优秀。
更详细的布隆过滤器原理请转到 https://blog.csdn.net/qq_36963950/article/details/108532523
布隆过滤器优缺点
优点优点很明显二进制组成的数组占用内存极少并且插入和查询速度都足够快。
缺点随着数据的增加误判率会增加还有无法判断数据一定存在另外还有一个重要缺点无法删除数据。
java中通过redisson实现布隆过滤器
Redisson客户端搭建
package com.heima.item.config;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Author: 小爽帅到拖网速
*/
@Configuration
public class RedisConfig {
@Bean
public RedissonClient redissonClient(){
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.79.129:6379");
RedissonClient redissonClient = Redisson.create(config);
return redissonClient;
}
}
布隆过滤器配置类实现
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Author: 小爽帅到拖网速
*/
@Configuration
public class RedissBloomFilerConfig {
@Autowired
private RedissonClient redissonClient;
@Bean
public RBloomFilter<String> bloomFilter(){
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("bloomtest");
// 初始化布隆过滤器
bloomFilter.tryInit((long)1E8,0.003);
return bloomFilter;
}
}
使用过程
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
/**
* @Author: 小爽帅到拖网速
*/
@RestController
public class TestBloomFilterController {
@Autowired
RedissonClient redissonClient;
@Autowired
RBloomFilter bloomFilter;
@GetMapping("/add/{name}")
public String addData(@PathVariable String name){
return bloomFilter.add(name)?"ok":"false";
}
@GetMapping("/list/{name}")
public boolean listData(@PathVariable String name){
return bloomFilter.contains(name);
}
}
启动项目访问 http://localhost:8081/add/xiaoshuang 请求响应ok后查看redis保存结果
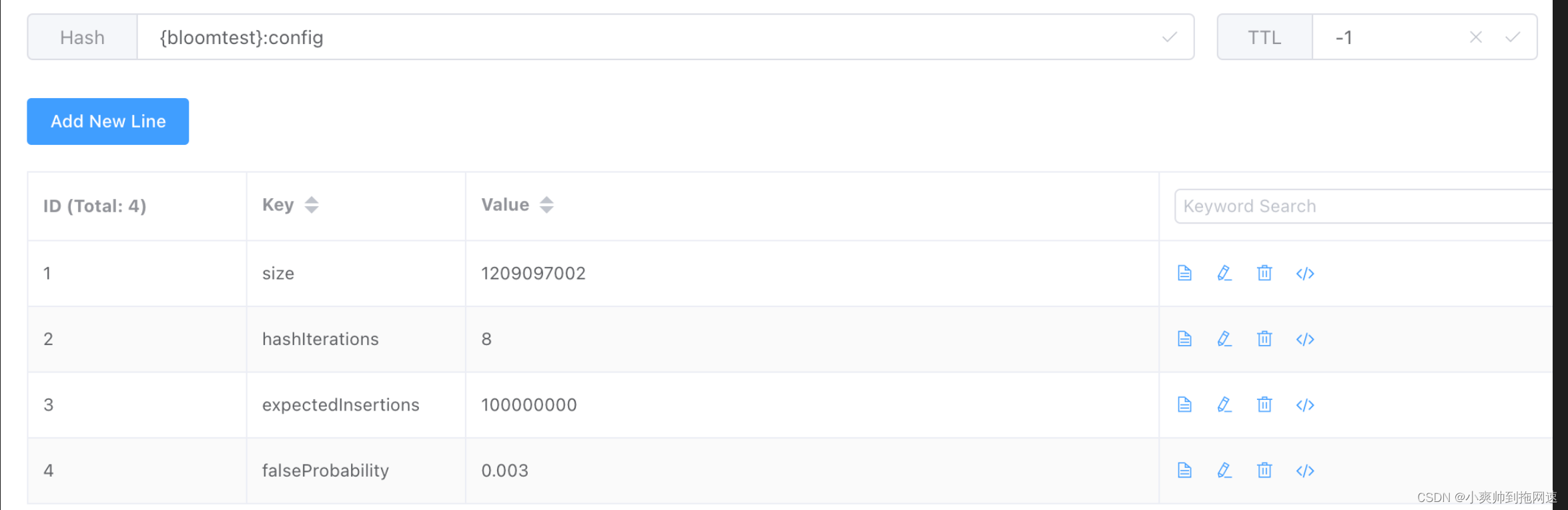
参数说明
expectedInsertions 预插入数
falseProbaility 误判率
hashIterations 哈希迭代次数
OpenResty通过lua脚本实现Redisd的布隆过滤器
这里记录一下OpenResty中通过lua脚本调用Redis模块代码仓库
https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
Configuration你可以找到三个配置变量**“ SIZE”“ PRECISION”和“ NAME”**。
SIZE表示位阵列的大小。精密度意味着布隆过滤器的缺失公差。NAME表示redis键的前缀。
修改它们以使其最适合你的程序。
用法
- bf_checkredis_clientdata返回0/10找不到1找到
- bf_addredis_clientdata返回“确定”
redis_client请新建一个redis对象并使用lua-resty-redis将其连接。数据存储在bloom过滤器中的数据。
多级缓存架构中加入布隆过滤器
1、将布隆过滤器引入我们的业务流程可以在java中利用Redisson实现布隆过滤器在请求通过负载均衡到tomcat后查询redis缓存命中前先去查询布隆过滤器中是否命中若命中则继续去redis查询缓存或者数据库查询缓存后进行缓存重建布隆过滤器判断该数据存在则redis、数据库一定会查询到数据这样避免了高并发请求同样的key获取不到数据从而导致大量请求都落到数据库避免缓存穿透
2、如果想绕开tomcat可以在OpenResty 通过lua脚本实现布隆过滤器判断缓存是否存在若存在则接着执行lua脚本去redis中获取数据之后再根据需要判断是否发起http请求到tomcat集群是否重建OpenResty的本地缓存实现
5、数据同步的问题
我们在OpenResty中通过lua脚本查询Redis中的缓存利用nginx、redis高并发的读写能力来提高客户端请求的响应速度但是同时为了保证数据的一致性问题必须采取一定的策略去更新缓存或者是重建缓存常见缓存数据同步的方式有以下三种
设置有效期
为缓存设置有效期如果缓存的内容是商品信息、地理位置信息等不会轻易改动的数据可以通过设置缓存有效期时间当到达缓存时间后再去进行缓存重建并且根据缓存数据指定缓存有效期的长短
优势简单
缺点存在数据短期不一致的问题
场景缓存数据修改频率低
同步双写
修改数据库的同时修改缓存
优势时效性强缓存与数据库保持强一致性
缺点代码入侵性强耦合性高
场景对数据一致性、时效性要求比较高的缓存数据
异步通知
修改数据库时同时发送事件通知相关服务监听到后修改缓存数据主要实现的方式有mq、canal
优点代码入侵性、耦合度低并且可以实现同时通知多个缓存服务
缺点时效性差通过异步实现可能存在短期数据不一致的状态
场景时效性要求不高并且可以满足实现同时同步多个服务的需求如果修改数据库后可以同时更新redis缓存、es数据
canal实现异步通知
1、canal业务流程
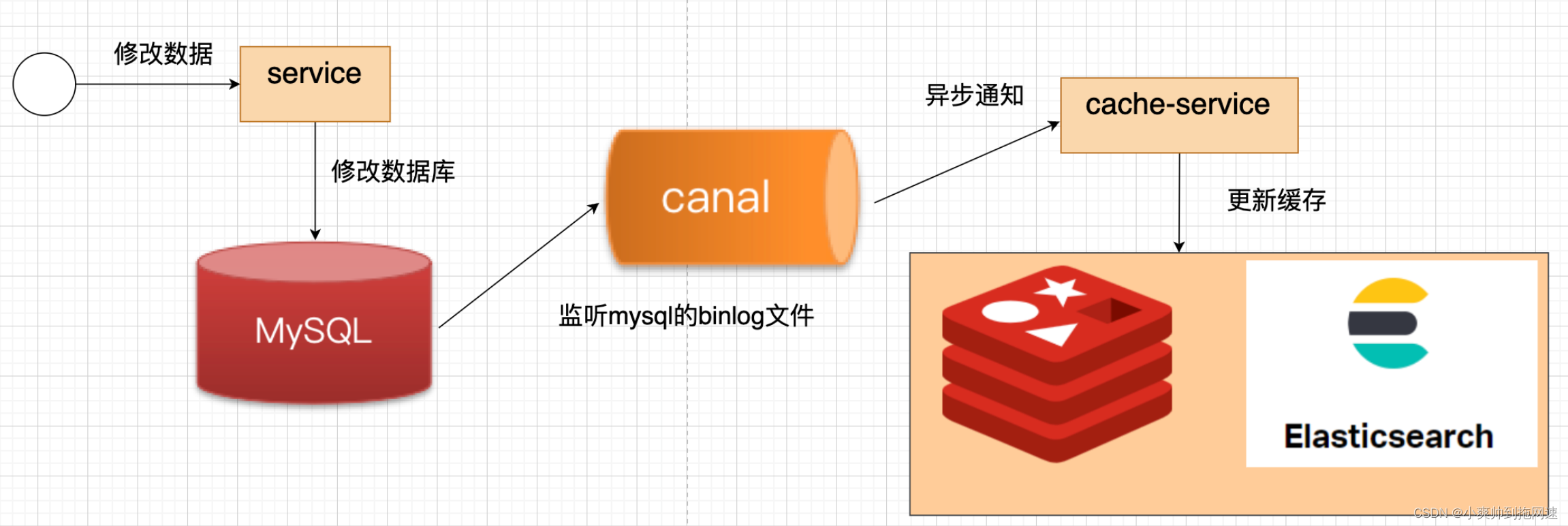
1、修改完数据后本次线程执行的业务直接就结束了不会有任何代码入侵
2、canal中间件监听到mysql数据库的binlog文件的变化立刻通知cache-service缓存服务去更新缓存redis、elasticsearch
2、docker搭建canal中间件
搭建前需要开启mysql的主从复制
修改mysql的my.cnf文件
vi /tmp/mysql/conf/my.cnf
# 添加一下内容
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=数据库名
在mysql数据库中创建canal账号
-- 创建账号
CREATE USER canal IDENTIFIED BY 'canal';
-- 授予权限
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- 刷新权限
FLUSH PRIVILEGES;
-- 修改密码
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal';
创建账号成功后数据库重启
docker启动canal
docker run -p 11111:11111 --name canal \
-e canal.destinations=test \
-e canal.instance.master.address=ip:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=db_name\\..* \
--network heima \
-d canal/canal-server:v1.1.5
环境参数说明
# canal连接mysql服务器ip、端口号
canal.instance.master.address= mysql服务器的ip地址:3306
# mysql中创建的账号
canal.instance.dbUsername=canal
# 登录密码
canal.instance.dbPassword=canal
# 监听某数据库下的所有表db_name为数据库名
canal.instance.filter.regex=db_name\\..* \
3、查看canal运行状态
查看canal运行日志 docker logs -f canal
docker exec -it canal bash
tail -f canal-server/logs/canal/canal.log
tail -f canal-server/logs/db_name/table_name.log
4、springboot配置canal服务
1、导入canal依赖
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.1-RELEASE</version>
</dependency>
2、配置文件
canal:
destination: test # 启动时设定的环境变量参数canal.destinations
server: ip:11111
3、修改实体类
@TableName(“table_name”) 映射表名
@Id 标记主键
@Column 数据库表名与类中属性名映射相同则不用标注自动进行驼峰转换
@Transient 代表该属性在数据库表中不存在
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.Transient;
import javax.persistence.Column;
import java.util.Date;
@TableName("tb_item")
public class Item {
@TableId(type = IdType.AUTO)
@Id
private Long id;//商品id
@Column(name = "name")
private String name;//商品名称
@Transient
private Integer stock;//商品库存
}
4、编写监听器
通过实现EntryHandler<T>接口编写监听器监听Canal消息。注意两点
- 实现类通过
@CanalTable("tb_item")指定监听的表信息 - EntryHandler的泛型是与表对应的实体类
- 重写了EntryHandler的三个方法分别是增删改
@CanalTable("tb_item")
@Component
public class ItemHandler implements EntryHandler<Pojo> {
@Override
public void insert(Pojo pojo) {
// 写数据到redis
// 写数据到elasticsearch
// .....
}
@Override
public void update(Pojo before, Pojo after) {
// 更新redis数据
// 更新elasticsearch
// .....
}
@Override
public void delete(Pojo item) {
// 删除数据到redis
// 删除elasticsearch
// .....
}
}
3、多级缓存架构总结
整个请求的处理流程如下
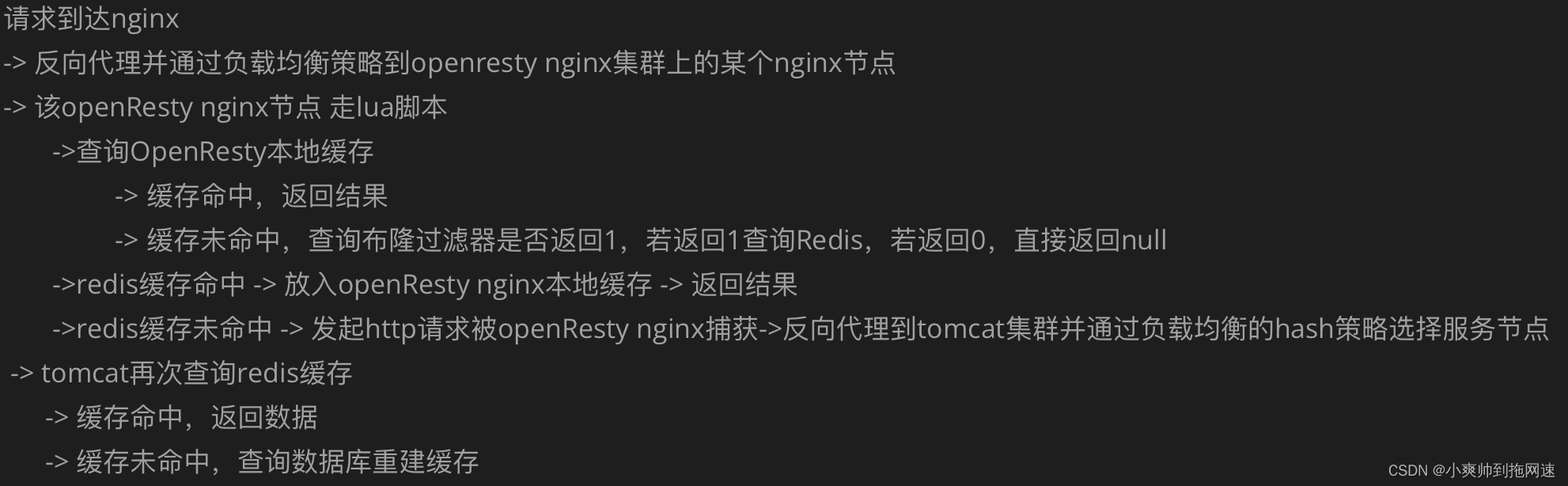
这是最终高并发多级缓存架构解决方案的架构图
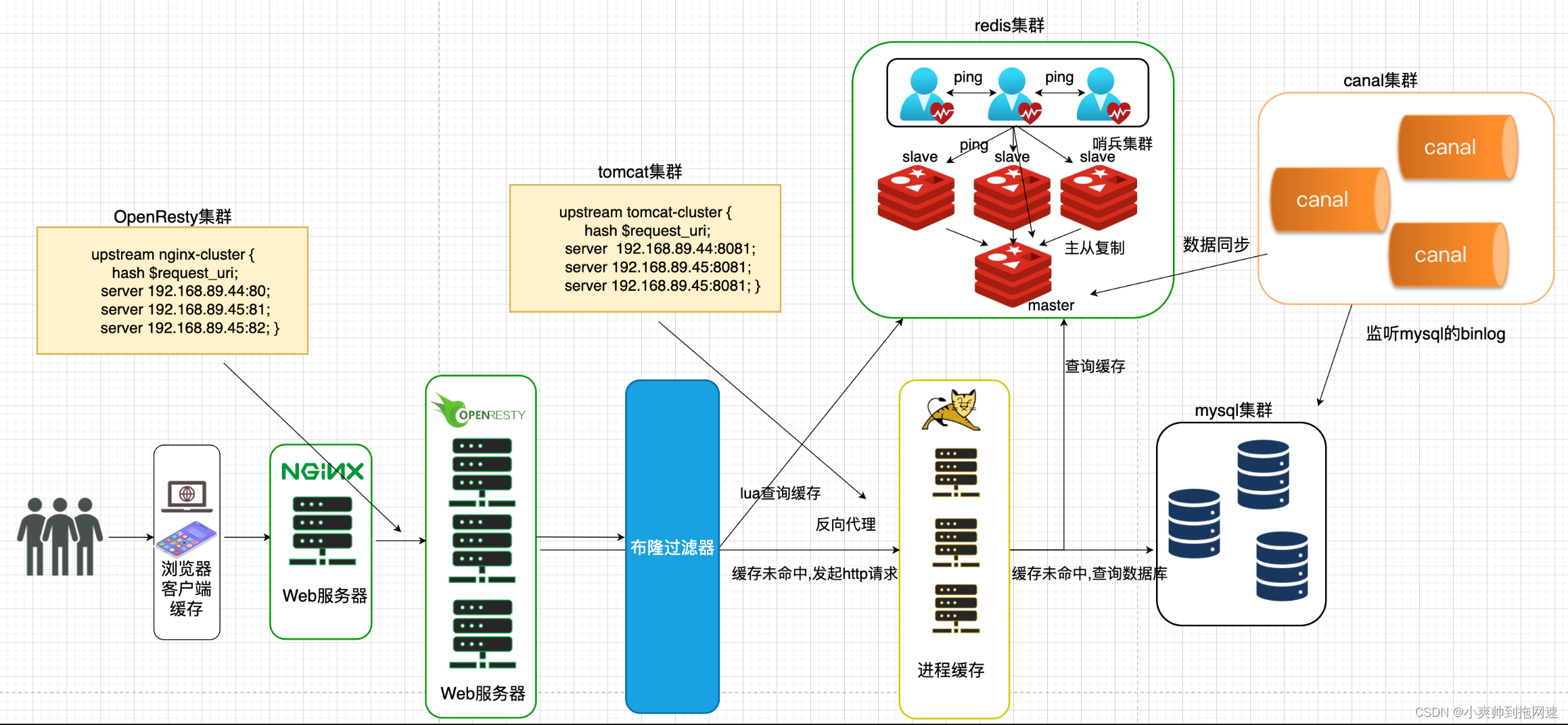
梳理后的架构流程图
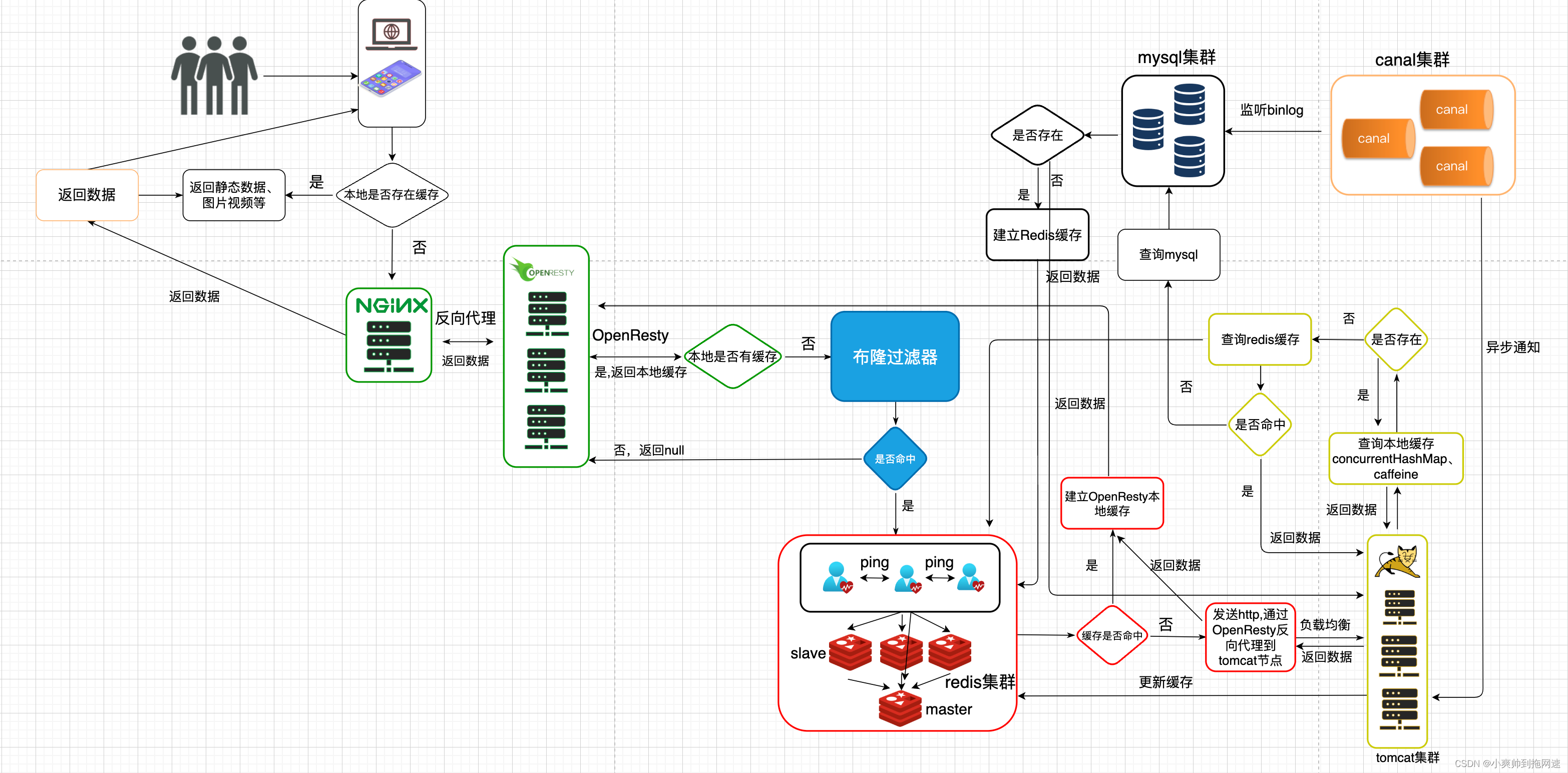
我们并没有在架构中引入mq在数据同步模块中除了使用canal实现数据异步更新还可以通过mq去实现或者在一些需要流量削峰场景中使用mq在引入mq之后还需要对mq的消息可靠性进行保证比如生产者消息确认、消息持久化消费者消息确认以及消息消费失败重试机制并且为了保证mq的高可用性同样需要搭建mq集群。
以上便是高并发多级缓存架构解决方案如有误解请在评论区指出谢谢