

AHP层次分析法与python代码讲解(处理论文、建模)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
眼尖的人会发现目录中③和④是反的。
AHP是啥
层次分析法analytic hierarchy process简称AHP。是建模比赛中比较基础的模型之一其主要解决评价类的问题在毕业论文中也经常能见到可用于绩效评价。如选择哪种方案最好哪位员工表现最好等。
学习本文后你将会对AHP有个大致了解然后你会掌握Python代码计算AHP模型
该方法本质就是把一个决策问题根据评价的标准将其分为多层次结构这些层次按照一定的关联关系构成自上而下的一种阶梯构造再根据最底下的层次到高层次通过两两进行对比得出各个因素的权重权重最大的就是这些方案中最好的方案或因素。
本文借鉴了数学建模清风老师的课件与思路如果大家发现文章中有不正确的地方欢迎指正也可以点击链接查看清风老师视频讲解清风数学建模https://www.bilibili.com/video/BV1DW411s7wi
AHP 的主要计算可分为五个过程
①构建阶梯层次结构②构建判断矩阵③对判断矩阵进行一致性检验④综合算术平均法 、几何平均法、特征值法求权重⑤填充矩阵得出结果
后续会逐一讲到
题目
小明同学想出去旅游。在查阅了网上的攻略后他初步选择了苏杭、北戴河和桂林三地之一作为目标景点。请你确定评价指标、形成评价体系来为小明同学选择最佳的方案。
首要目的对于评价类问题首先需要明确以下三个问题
①我们评价的目标是什么
答为小明同学选择最佳的旅游景点。
②评价的准则或者说指标是什么我们根据什么东西来评价好坏
题目没给相关数据需要我们确定。
一般而言①③这两个问题的答案是显而易见的问题②的答案需要我们根据题目中的背景材料、常识以及网上搜寻到的参考资料进行结合从中筛选出最合适的指标
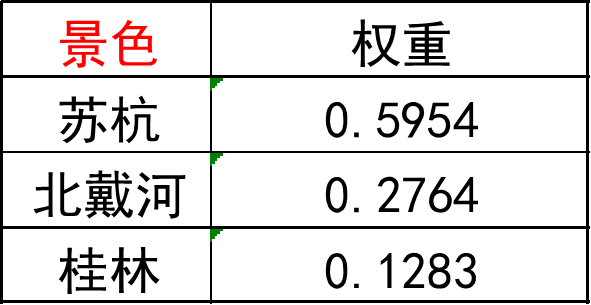
答这里我们选择了景色、花费、居住、饮食、交通。
③我们为了达到这个目标有哪几种可选的方案
答三种分别是去苏杭、去北戴河和去桂林。
①构建阶梯层次结构
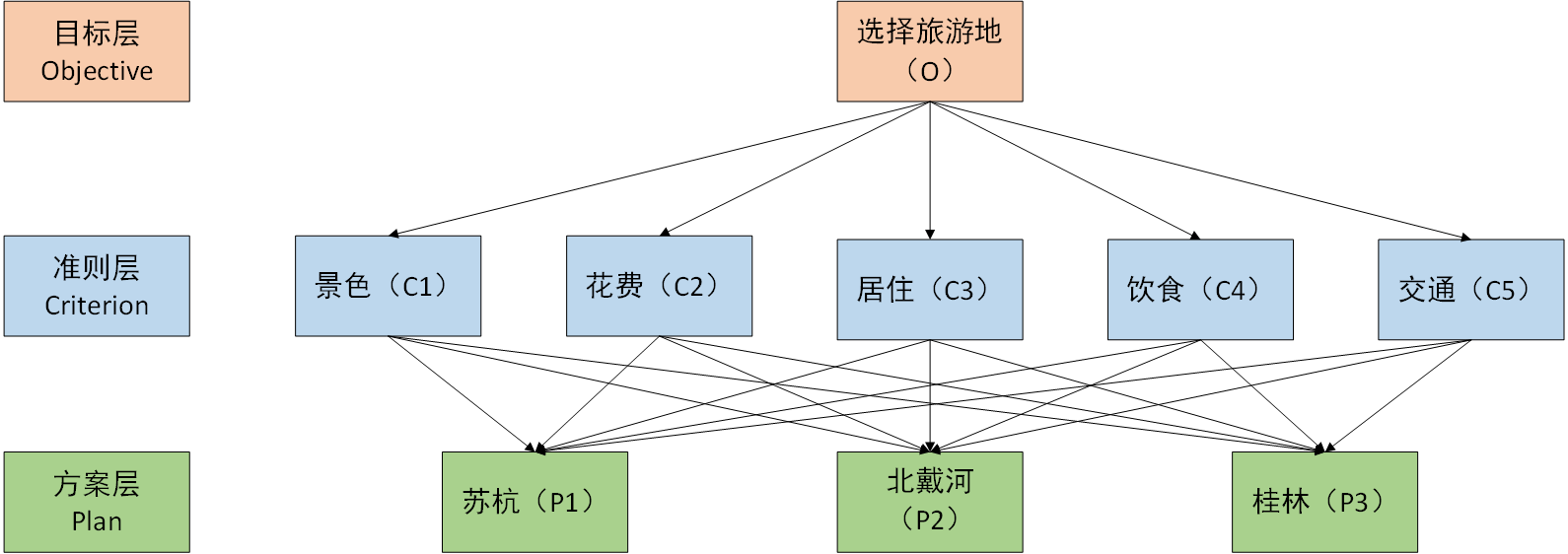
下图为我们最终需要得出的结果图的样子对于其中内容的填写就需要使用到AHP方法了。
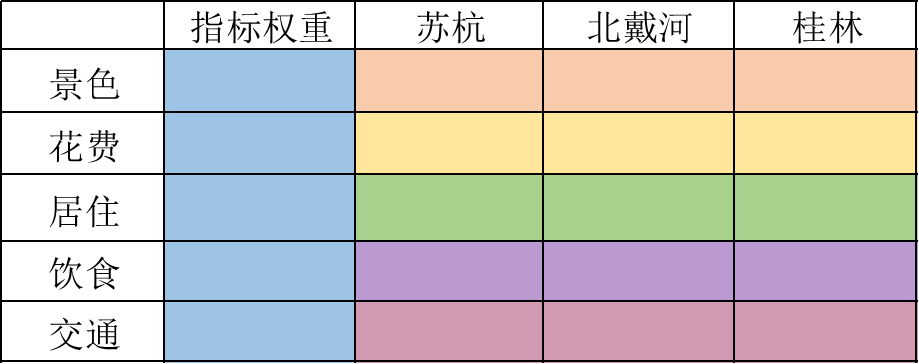
- 其中蓝色一列代表景色、花费、居住、饮食以及交通的权重加和为1有时候加起来不是1是因为四舍五入的原因。实际上就是准则层关于上一层目标层的重要性
- 然后同一颜色每一横行就是三种方案相对于准则层的重要性。
②构建判断矩阵

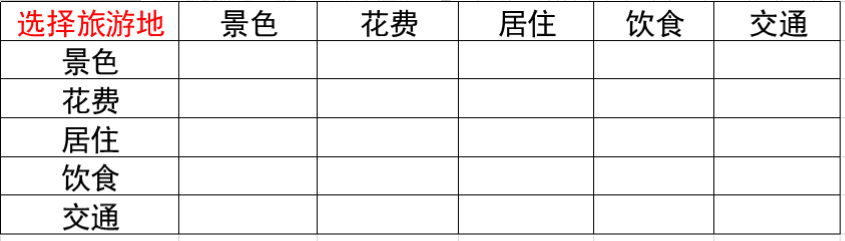
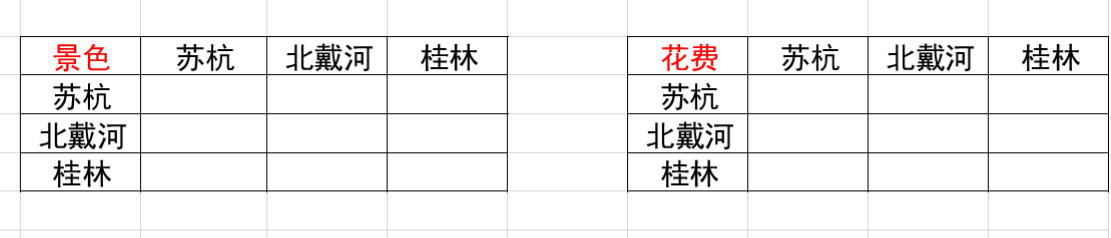
根据以上这个表格我们去寻找专家填写或者根据上述说的根据理论基础来填写得到了下面这个判断矩阵。
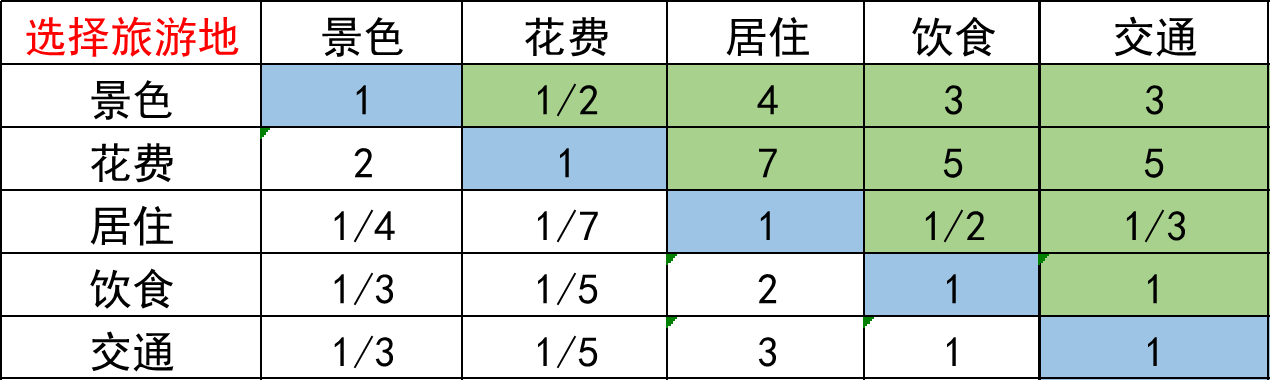


观察一下上面这个判断矩阵有如下特点
①aij 表示的意义是与指标j相比 i的重要程度。注意i是行j是列笔者经常搞混
②主对角线元素为1原因当i= j时两个指标相同因此同等重要记为1
③aj >0 且满足aij = 1/aji也就是 aij × aji = 1 (我们称满足这一条件的矩阵为正互反矩阵)
④综合算术平均法 、几何平均法、特征值法求权重
填充权重矩阵根据矩阵计算得分得出结果。
这里我们先进行填充方案层关于准则层的五组权重向量
计算权重的方法有三种
①算数平均法求权重
②几何平均法求权重
③特征值法求权重
一般情况下第三种特征值法求权重是最常用的但是建议可以综合三种方法来求得一个综合的权重向量。
下面拿下面这个判断矩阵进行说明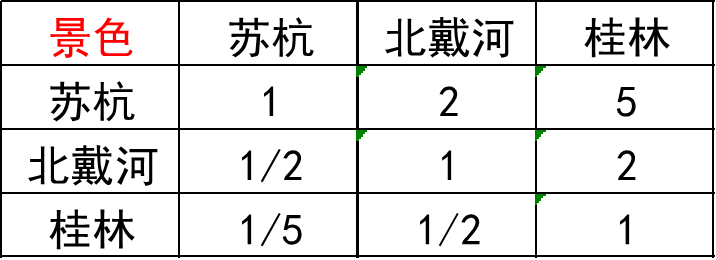
方法1算术平均法求权重
一般步骤
第一步 将判断矩阵按照列归一化每个元素除以其所在列的和如1/(1+0.5+0.2)=0.5882
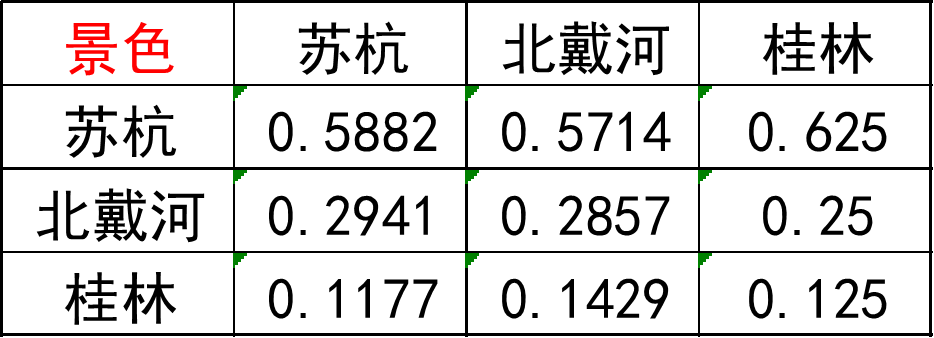
第二步 将归一化的列相加按行求和
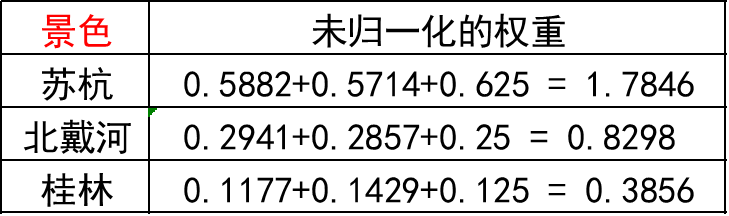
第三步 将相加后得到的向量中的每个元素除以 n 即可得到权重向量

表达式解释

代码实现
import numpy as np
from numpy import linalg
# np.set_printoptions(precision=4)
'''算术平均法权重'''
def arithmetic_mean(a):
n = len(a)
b = sum(a)
print('b:', b)
# 归一化处理
normal_a = a/b
print("算术平均法权重-归一化处理")
print(normal_a)
average_weight = []
for i in range(n):
s = sum(normal_a[i])
print("第{}行求和 ".format(i+1), s)
# 平均权重
average_weight.append(s/n)
# print(average_weight)
print('算术平均法权重:')
print(np.array(average_weight))
return np.array(average_weight)结果如下
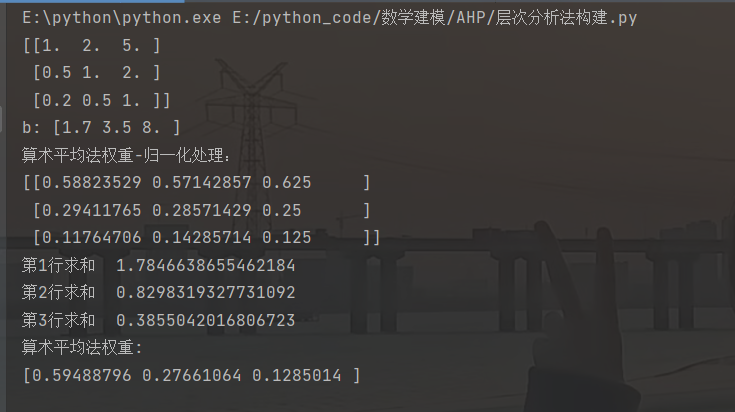
讲解
①如果你想全篇设置四位小数点在开头加上这个
np.set_printoptions(precision=4)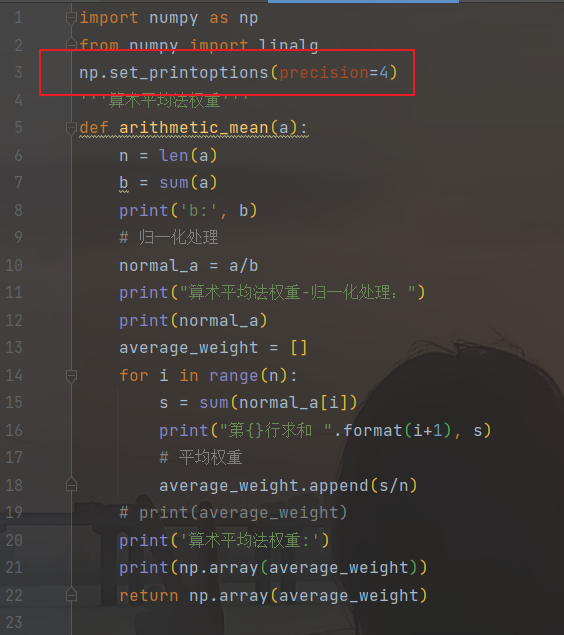
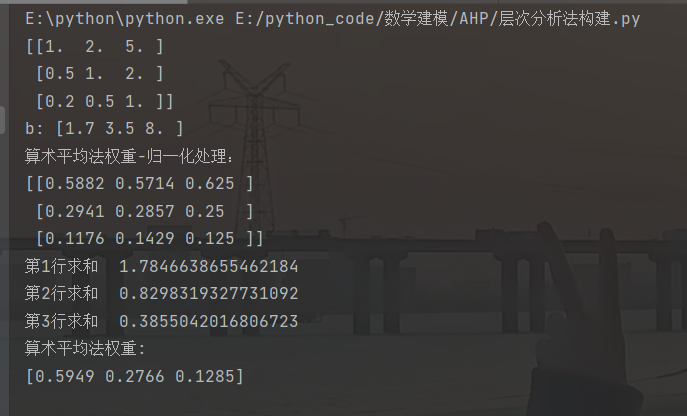
②对二维数组使用sum函数最终形成的是一个包含每列的和的数组。
将数组a除以该数组就得到了归一化的数组。
③代码for循环中进行了上述步骤二和三先对每行求和然后除以n得到了权重。
方法2几何平均法求权重
一般步骤
第一步 将A的元素按照行相乘得到一个新的列向量
第二步 将新的向量的每个分量开n次方
第三步 对该列向量进行归一化即可得到权重向量
表达式解释

代码实现
'''几何平均法求权重'''
def geometric_mean(a):
n = len(a)
# 1表示按照行相乘得到一个新的列向量
b = np.prod(a, 1)
print(b)
c = pow(b, 1/n)
print(c)
# 归一化处理
average_weight = c/sum(c)
print('几何平均法权重:')
print(average_weight)
return average_weight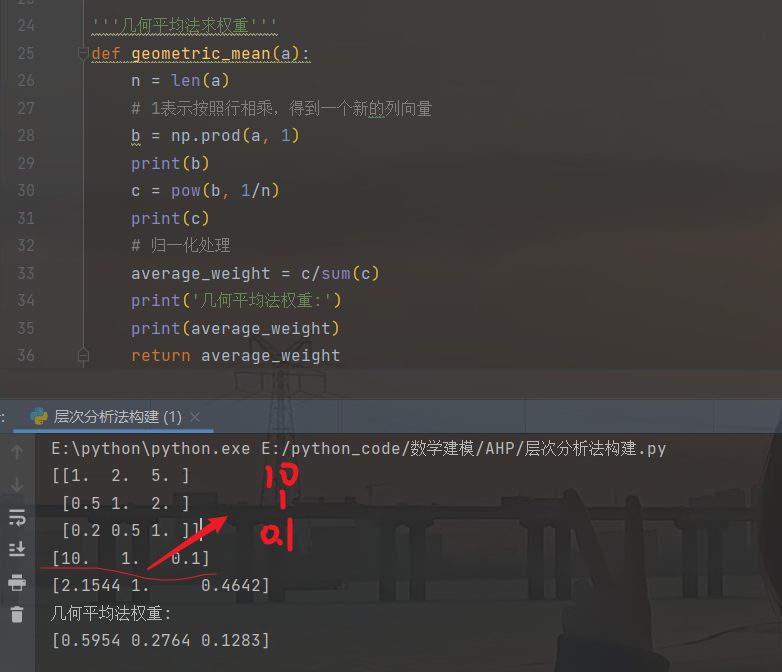
如图这个[10,1,0.1] 是列向量
c为开n次方的数组。
结果一样
方法3特征值法求权重
在了解 这个之前你得大致了解一下什么是特征值特征向量最大特征值上文建议好好看看前半部分
对于一个矩阵A来说我们对这样的向量比较感兴趣在矩阵A的转换下得到的结果向量其方向并没有发生改变只不过结果向量变为某一个向量的的常数倍了
数学上这样表示
其中λ称为A的特征值eigenvalue
而u向量称为A对应于λ的特征向量eigenvector
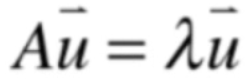
代码实现
'''特征值法求权重'''
def eigenvalue(a):
w, v = np.linalg.eig(a)
for i in range(len(w)):
print('特征值', a[i], '特征向量', v[:, i])
index = np.argmax(w)
w_max = np.real(w[index])
vector = v[:, index]
vector_final = np.transpose(np.real(vector))
print('最大特征值', w_max, '对应特征向量', vector_final)
normalized_weight = vector_final/sum(vector_final)
print('***归一化处理后:', normalized_weight)
return w_max, normalized_weight
np.linalg.eig() 就是用来计算正方形数组的特征值与特征向量的 。
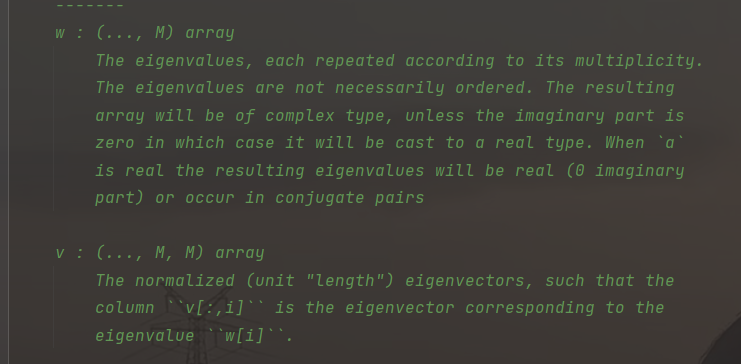
上图是官方文档对于w和v的定义的看不懂没事我将其打印输出后你们就明白了
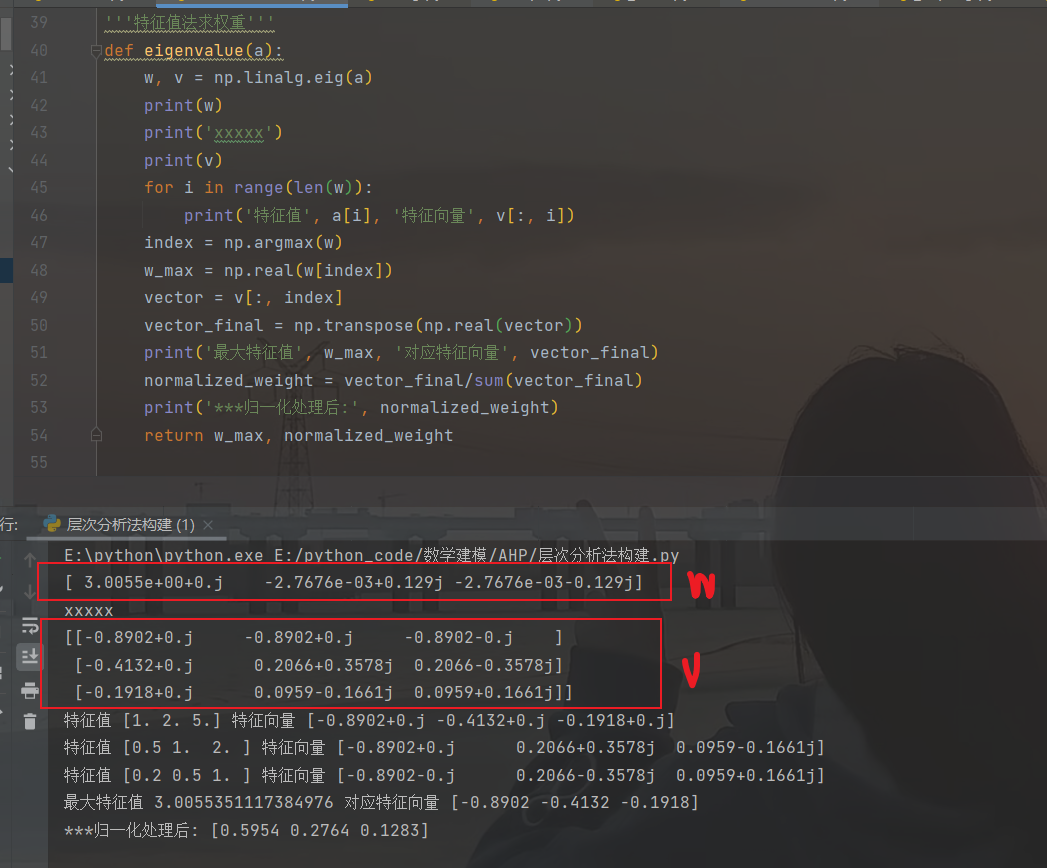
这里的w是每一行的特征值所组成的数组这里的v是归一化后的特征向量。
np.argmax(w)上面代码用于返回最大值的索引
np.real()上面代码用于返回复杂参数的实部
vector = v[:, index]这里涉及到[:,] 的使用
vector = v[:, 0]表示取数组的第0列vector = v[:, 1]表示取数组的第1列vector = v[0:]表示取数组的第0行vector = v[1:]表示取数组的第1行归纳总结可以知道冒号逗号数字的顺序表示取列数字逗号冒号的顺序表示取行
因此最初代码表示按照最大特征值的索引取列。
对最大特征值取小数点四位可以替换成下面的代码
w_max = round(np.real(w[index]),4)最终将最大特征值对应的特征向量归一化就得出了权重。
求综合平均权重
'''综合平均权重'''
def average_Weight(a):
am = arithmetic_mean(a)
gm = geometric_mean(a)
ev = eigenvalue(a)[1]
aw = np.array([am, gm, ev])
print(aw)
final_weight = sum(aw)/3
print(final_weight)
return final_weight将上述三种方法得到的权重经过综合得到了最终的权重
上面代码先获取三种方法的权重放到数组中最终计算平均权重。
③对判断矩阵进行一致性检验
返回上面说的重点
你在求权重前填写的矩阵也叫做判断矩阵。其首先是一个正互反矩阵
aj >0 且满足 aij × aji = 1)
这里很好理解例如由于互相影响i对j是5j对i就是1/5而不是1/4或其他数字。
'''判断正互反矩阵'''
def reciprocal_matrix_judge(a):
print(a)
n = len(a)
b = 0
for j in range(n):
for i in range(n):
if a[:, j][i] * a[j, :][i] == 1:
b += 1
if b == n*n:
print("该矩阵是正互反矩阵\n")
return True
else:
print("该矩阵不是正互反矩阵\n")
return False这里笔者使用自己的理解写的python判断正互反矩阵的代码网上貌似没找到有人写过由于笔者对数组这些不太熟就不是按照定义上判断aij是否等于1/aji而是采用判断aij与aji乘积为1的个数如果刚好为数组元素的个数也是数组行数或者列数的平方因为两两比较所以是个方阵
当然期待有人使用定义或者其他更好的方法进行判断正互反矩阵。
是正互反矩阵还不够还需要进行一致性检验。
考虑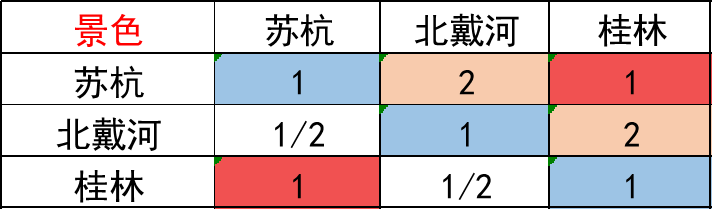
假设我们填写的判断矩阵是这个样子下面括号中的是标度
苏杭2比北戴河1景色好一点
苏杭1和桂林1景色一样好
这里我们就可以得出桂林比北戴河景色好一点可是图上面的内容表达的意思是
北戴河2比桂林1景色好一点
由上可以看出出现了矛盾
从这里就得提出一个概念叫做一致矩阵它在正互反矩阵性质的基础上没有以上的矛盾可以说一致矩阵是正互反矩阵的特例。
将上面的矩阵进行改良得到一致矩阵
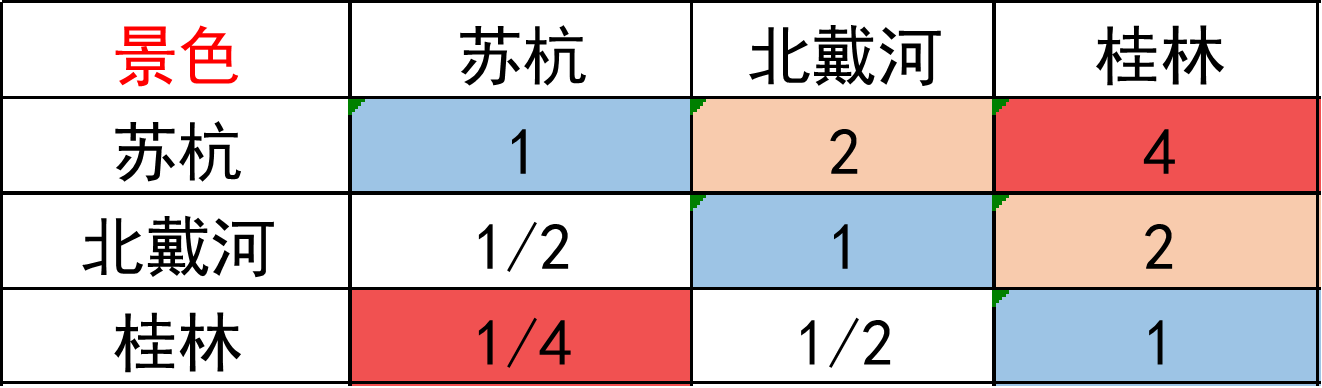
它比正互反矩阵多出两个性质
① aij = i的重要程度 / j的重要程度
ajk = j的重要程度 / k的重要程度
aik = i的重要程度 / k的重要程度 = aij × ajk。
② 矩阵各行各列之间成倍数关系。
我们进行构造矩阵时难免会出现矛盾即不容易构造出一致性矩阵但是我们可以向一致性矩阵靠拢只要这个差距CR不超过一个范围0.1那么这个判断矩阵也是可以使用的。这个判断差距的过程叫做一致性检验。
证明过程如下
一致性检验原理 检验我们构造的判断矩阵和一致矩阵是否有太大的差别。


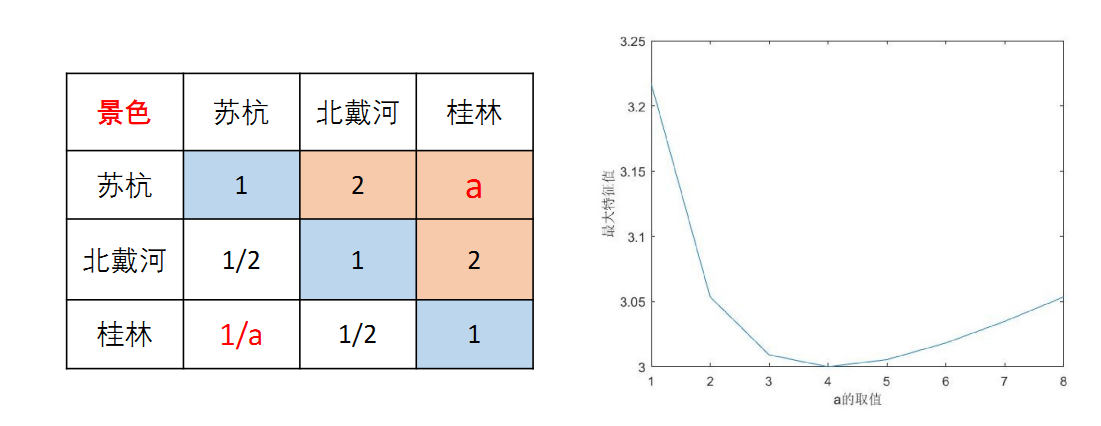
上图为清风老师使用matlab计算a值变化-最大特征值变化图
总而言之判断矩阵越不一致时最大特征值与 n 相差就越大。
接下来我们讲如何计算CICR
一致性指标CI计算
公式如下
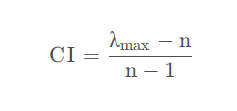
代码如下
'''CI计算'''
def CI_calc(a):
n = len(a)
λ_max = eigenvalue(a)[0]
print(λ_max)
CI = (λ_max-n)/(n-1)
print('CI:', CI)
return CI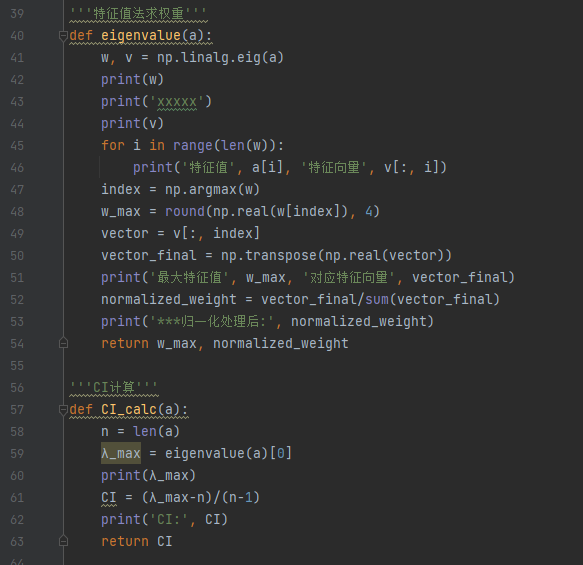
eigenvalue()是上文提到的特征值法求权重由于我们需要 λ_max最大特征值其是eigenvalue()中第一个返回的w_max。然后使用CI的计算公式计算即可
结果如下
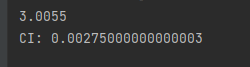
根据n查找对应的平均随机一致性指标 RI

一致性比例CR计算
公式如下
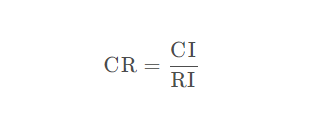
代码如下
'''CR计算'''
def CR_calc(a):
RI = np.array([0, 0, 0.52, 0.89, 1.12, 1.26, 1.36, 1.41,
1.46, 1.49, 1.52, 1.54, 1.56, 1.58, 1.59])
n = len(a)
CI = CI_calc(a)
CR = CI/RI[n-1]
print('CR:', CR)
if CR < 0.1:
print("一致性检验通过\n")
return True
else:
print("一致性检验失败请修改")
return False首先将RI以数组的形式输入其中然后构建公式求RI的值判断其是否小于0.1.
结果如下
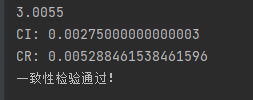
发现一致性检验通过。这样就说明构建的判断矩阵是可行的。
主函数
if __name__ == '__main__':
a = np.array([[1, 2, 5],
[1 / 2, 1, 2],
[1 / 5, 1 / 2, 1]])
rmj = reciprocal_matrix_judge(a)
if rmj:
if CR_calc(a):
average_Weight(a)结果如下有些内容不需要的可以把print()打印给注释掉
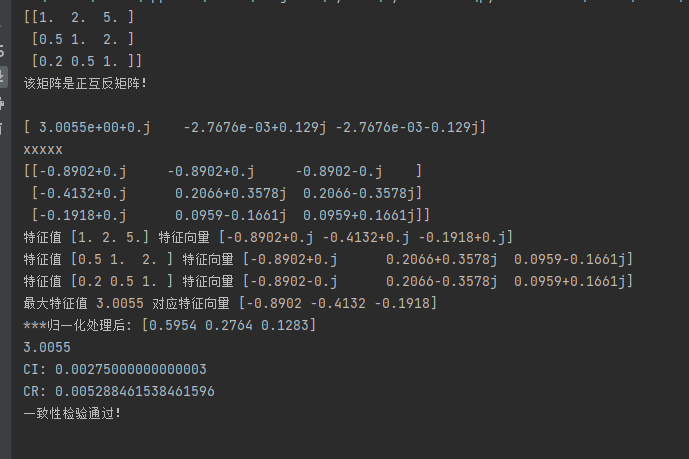
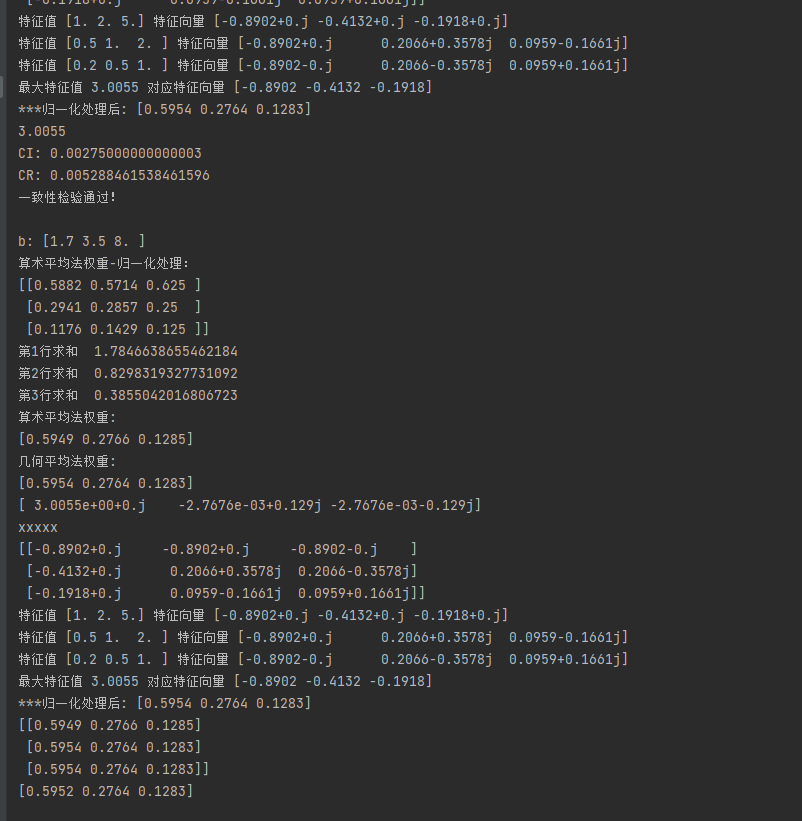
最后一张图的最后一行就是综合权重。
对代码的小小的展望
这里笔者使用的print()函数较多运行CI_calc()和CR_calc() 函数时候都会调用eigenvalue()函数就会重复打印其中的特征值和对应的特征向量这里可以优化。
填充结果
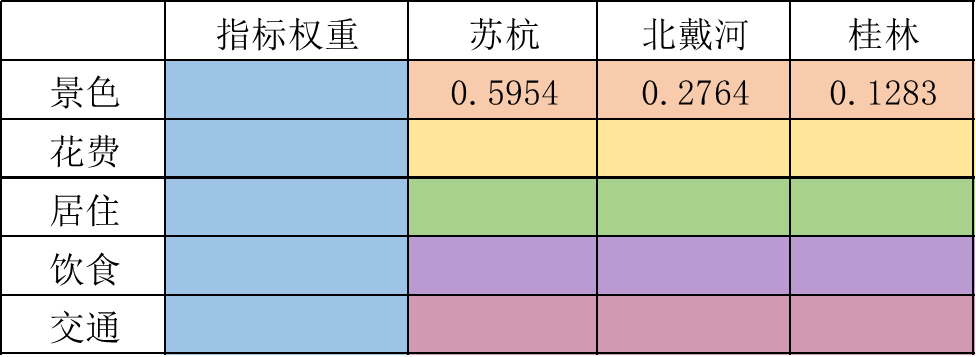
清风老师是使用特征值法求的权重得出最终的权重矩阵这里我就直接使用清风老师的内容了不再去单独做综合三种方法得到的权重的excel
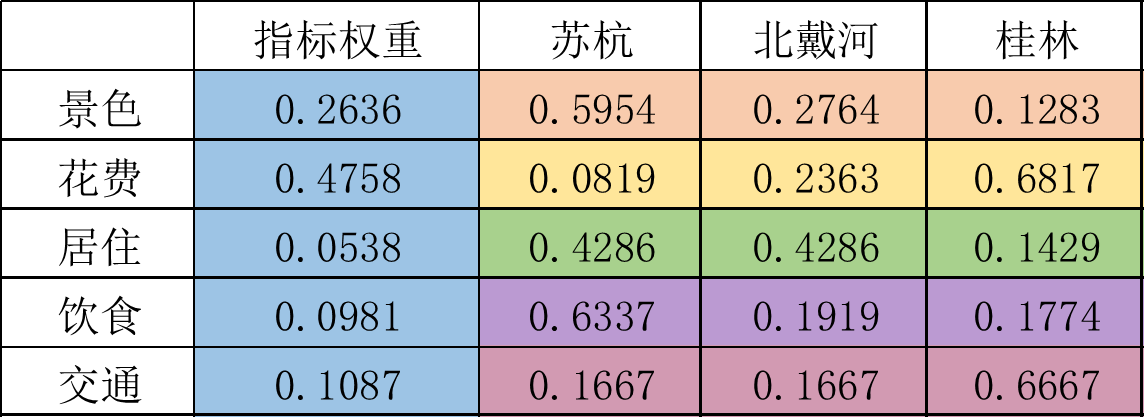
⑤填充矩阵得出结果
计算得分得出最终结果
苏杭得分指标权重×苏杭与其他两种方案中的权重即前两列相乘
0.5954×0.2636+0.0819×0.4758+0.4286×0.0538+0.6337×0.0981+0.1667×0.1087=0.299
同理北戴河得分为0.245桂林得分为0.455。
因此最终选择桂林
AHP扩展知识
1、评价的决策层不能太多太多的话n会很大判断矩阵和一致矩阵差异可能会很大。因为平均随机一致性指标 RI 的表格中 n 最多是15因此应该根据实际情况选择是否应用此方法。
2、如果决策层中指标的数据是已知的那么层次分析法不容易将这些已知数据应用在其中。如拿上面的例题举例如果已知景色 、花费、居住、饮食以及交通在三个旅游景点的一些数据那么如何将这些数据转化为构造判断矩阵的依据只能为其提供一定的文字说明而不容易将数据应用到其中。
3、在实际建模中判断矩阵的数值都是人为填的具有一定的主观性存在这时应该搜寻相应的数据让人信服不能空口无凭。
个人拙见
①关于AHP层次分析法就讲到这里希望大家能多看几遍可能后续建模或者论文中会涉及到就我个人认为虽然是专家填的判断矩阵也使用客观的一致性检验该模型应该算是主观的一类评价类模型。
②AHP层次分析法涉及到线性代数的一些内容而其他的评价类模型如DEA数据包络方法其还涉及到运筹学相关知识对偶问题。
以上内容有不懂的可以通过文末联系我。