

支持向量机、偏最小二乘回归分析、现代优化算法、预测方法
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
一.支持向量机
1.案例消费情况

clc, clear
a0=load('fenlei.txt'); %把表中x1...x8的所有数据保存在纯文本文件fenlei.txt中
a=a0'; b0=a(:,[1:27]); dd0=a(:,[28:end]); %提取已分类和待分类的数据
[b,ps]=mapstd(b0); %已分类数据的标准化
dd=mapstd('apply',dd0,ps); %待分类数据的标准化
group=[ones(20,1); 2*ones(7,1)]; %已知样本点的类别标号
s=fitcsvm(b',group) %训练支持向量机分类器
sv_index=find(s.IsSupportVector) %返回支持向量的标号
beta=s.Alpha %返回分类函数的权系数
bb=s.Bias %返回分类函数的常数项
check=predict(s,b') %验证已知样本点
err_rate=1-sum(group==check)/length(group) %计算已知样本点的错判率
solution=predict(s,dd') %对待判样本点进行分类
beta =
0.3076
0.0336
0.7048
0.4734
0.4052
1.0000
0.0227
0.0916
solution =
1
2
2
2.案例乳腺癌
%原始数据cancerdata.txt可在网上下载数据中的B替换成1M替换成-1X替换成2删除了分割符*,替换后的数据命名成cancerdata2.txt
clc,clear
a=load('cancerdata2.txt');
a(:,1)=[]; %删除第一列病例号
gind=find(a(:,1)==1); %读出良性肿瘤的序号
bind=find(a(:,1)==-1); %读出恶性肿瘤的序号
training=a([1:500],[2:end]); %提出已知样本点的数据
training=training';
[train,ps]=mapstd(training); %已分类数据标准化
group(gind)=1; group(bind)=-1; %已知样本点的类别标号
group=group'; %转换成列向量
xa0=a([501:569],[2:end]); %提出待分类数据
xa=xa0'; xa=mapstd('apply',xa,ps); %待分类数据标准化
s=fitcsvm(train',group,'Standardize',true,'KernelFunction','rbf','KernelScale','auto')
%使用序列最小化方法训练支持向量机的分类器如果使用二次规划的方法训练支持向量机则无法求解
sv_index=find(s.IsSupportVector) %返回支持向量的标号
beta=s.Alpha' %返回分类函数的权系数
b=s.Bias %返回分类函数的常数项
check=predict(s,train'); %验证已知样本点
err_rate=1-sum(group==check)/length(group) %计算错判率
solution=predict(s,xa'); %进行待判样本点分类
solution=solution'
sg=find(solution==1) %求待判样本点中的良性编号
sb=find(solution==-1) %求待判样本点中的恶性编号
良性sg =
列 1 至 20
1 3 7 8 9 11 12 14 15 16 19 20 21 23 24 25 26 27 28 29
列 21 至 40
30 31 32 33 35 38 39 40 41 43 44 45 46 47 48 49 50 51 52 53
列 41 至 50
54 55 56 57 58 59 60 61 62 69
恶性sb =
2 4 5 6 10 13 17 18 22 34 36 37 42 63 64 65 66 67 68二.偏最小二乘回归分析
案例体能训练
clc,clear
ab0=load('pz.txt'); %原始数据存放在纯文本文件pz.txt中
mu=mean(ab0), sig=std(ab0) %求均值和标准差
rr=corrcoef(ab0) %求相关系数矩阵
ab=zscore(ab0); %数据标准化
a=ab(:,[1:3]);b=ab(:,[4:end]); %提出标准化后的自变量和因变量数据
[XL,YL,XS,YS,BETA,PCTVAR,MSE,stats] =plsregress(a,b)
contr=cumsum(PCTVAR,2) %求累积贡献率
xw=a\XS %求自变量提出成分系数每列对应一个成分这里xw等于stats.W
yw=b\YS %求因变量提出成分的系数
ncomp=input('请根据PCTVAR的值确定提出成分对的个数ncomp=');
[XL2,YL2,XS2,YS2,BETA2,PCTVAR2,MSE2,stats2] =plsregress(a,b,ncomp)
n=size(a,2); m=size(b,2);%n是自变量的个数,m是因变量的个数
beta3(1,:)=mu(n+1:end)-mu(1:n)./sig(1:n)*BETA2([2:end],:).*sig(n+1:end); %原始数据回归方程的常数项
beta3([2:n+1],:)=(1./sig(1:n))'*sig(n+1:end).*BETA2([2:end],:) %计算原始变量x1,...,xn的系数每一列是一个回归方程
bar(BETA2','k') %画直方图
yhat=repmat(beta3(1,:),[size(a,1),1])+ab0(:,[1:n])*beta3([2:end],:) %求y1,..,ym的预测值
ymax=max([yhat;ab0(:,[n+1:end])]); %求预测值和观测值的最大值
%下面画y1,y2,y3的预测图并画直线y=x
figure, subplot(2,2,1)
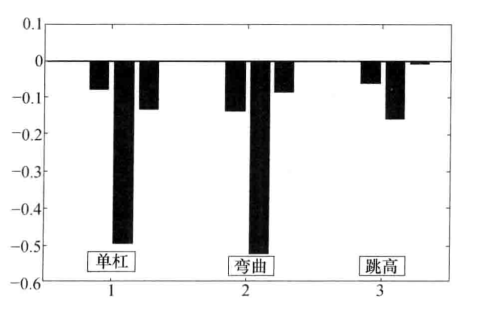
plot(yhat(:,1),ab0(:,n+1),'*',[0:ymax(1)],[0:ymax(1)],'Color','k')
legend('单杠成绩预测图','Location','northwest'), xlabel('预测数据'), ylabel('观测数据')
subplot(2,2,2)
plot(yhat(:,2),ab0(:,n+2),'O',[0:ymax(2)],[0:ymax(2)],'Color','k')
legend('弯曲成绩预测图','Location','northwest'), xlabel('预测数据'), ylabel('观测数据')
subplot(2,2,3)
plot(yhat(:,3),ab0(:,end),'H',[0:ymax(3)],[0:ymax(3)],'Color','k')
legend('跳高成绩预测图','Location','northwest'), xlabel('预测数据'), ylabel('观测数据')

三.现代优化算法
案例飞行路线TSP
1.模拟退火算法
马尔科夫过程
clc, clear
sj0=load('sj.txt'); %加载100个目标的数据数据按照表格中的位置保存在纯文本文件sj.txt中
x=sj0(:,[1:2:8]);x=x(:);
y=sj0(:,[2:2:8]);y=y(:);
sj=[x y]; d1=[70,40];
sj=[d1;sj;d1]; sj=sj*pi/180; %角度化成弧度
d=zeros(102); %距离矩阵d初始化
for i=1:101
for j=i+1:102
d(i,j)=6370*acos(cos(sj(i,1)-sj(j,1))*cos(sj(i,2))*cos(sj(j,2))+sin(sj(i,2))*sin(sj(j,2)));
end
end
d=d+d';
path=[];long=inf; %巡航路径及长度初始化
rand('state',sum(clock)); %初始化随机数发生器
for j=1:1000 %求较好的初始解
path0=[1 1+randperm(100),102]; temp=0;
for i=1:101
temp=temp+d(path0(i),path0(i+1));
end
if temp<long
path=path0; long=temp;
end
end
e=0.1^30;L=20000;at=0.999;T=1;
for k=1:L %退火过程
c=2+floor(100*rand(1,2)); %产生新解
c=sort(c); c1=c(1);c2=c(2);
%计算代价函数值的增量
df=d(path(c1-1),path(c2))+d(path(c1),path(c2+1))-d(path(c1-1),path(c1))-d(path(c2),path(c2+1));
if df<0 %接受准则
path=[path(1:c1-1),path(c2:-1:c1),path(c2+1:102)]; long=long+df;
elseif exp(-df/T)>rand
path=[path(1:c1-1),path(c2:-1:c1),path(c2+1:102)]; long=long+df;
end
T=T*at;
if T<e
break;
end
end
path, long % 输出巡航路径及路径长度
xx=sj(path,1);yy=sj(path,2);
plot(xx,yy,'-*') %画出巡航路径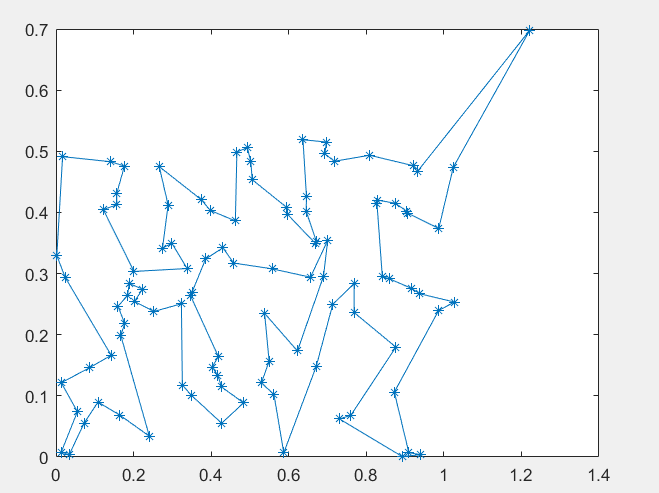
2.遗传算法
clc,clear
sj0=load('sj.txt'); %加载100个目标的数据
x=sj0(:,1:2:8); x=x(:);
y=sj0(:,2:2:8); y=y(:);
sj=[x y]; d1=[70,40];
sj=[d1;sj;d1]; sj=sj*pi/180; %单位化成弧度
d=zeros(102); %距离矩阵d的初始值
for i=1:101
for j=i+1:102
d(i,j)=6370*acos(cos(sj(i,1)-sj(j,1))*cos(sj(i,2))*cos(sj(j,2))+sin(sj(i,2))*sin(sj(j,2)));
end
end
d=d+d'; w=50; g=100; %w为种群的个数g为进化的代数
rand('state',sum(clock)); %初始化随机数发生器
for k=1:w %通过改良圈算法选取初始种群
c=randperm(100); %产生1...100的一个全排列
c1=[1,c+1,102]; %生成初始解
for t=1:102 %该层循环是修改圈
flag=0; %修改圈退出标志
for m=1:100
for n=m+2:101
if d(c1(m),c1(n))+d(c1(m+1),c1(n+1))<d(c1(m),c1(m+1))+d(c1(n),c1(n+1))
c1(m+1:n)=c1(n:-1:m+1); flag=1; %修改圈
end
end
end
if flag==0
J(k,c1)=1:102; break %记录下较好的解并退出当前层循环
end
end
end
J(:,1)=0; J=J/102; %把整数序列转换成[0,1]区间上的实数即转换成染色体编码
for k=1:g %该层循环进行遗传算法的操作
A=J; %交配产生子代A的初始染色体
c=randperm(w); %产生下面交叉操作的染色体对
for i=1:2:w
F=2+floor(100*rand(1)); %产生交叉操作的地址
temp=A(c(i),[F:102]); %中间变量的保存值
A(c(i),[F:102])=A(c(i+1),[F:102]); %交叉操作
A(c(i+1),F:102)=temp;
end
by=[]; %为了防止下面产生空地址这里先初始化
while ~length(by)
by=find(rand(1,w)<0.1); %产生变异操作的地址
end
B=A(by,:); %产生变异操作的初始染色体
for j=1:length(by)
bw=sort(2+floor(100*rand(1,3))); %产生变异操作的3个地址
B(j,:)=B(j,[1:bw(1)-1,bw(2)+1:bw(3),bw(1):bw(2),bw(3)+1:102]); %交换位置
end
G=[J;A;B]; %父代和子代种群合在一起
[SG,ind1]=sort(G,2); %把染色体翻译成1...,102的序列ind1
num=size(G,1); long=zeros(1,num); %路径长度的初始值
for j=1:num
for i=1:101
long(j)=long(j)+d(ind1(j,i),ind1(j,i+1)); %计算每条路径长度
end
end
[slong,ind2]=sort(long); %对路径长度按照从小到大排序
J=G(ind2(1:w),:); %精选前w个较短的路径对应的染色体
end
path=ind1(ind2(1),:), flong=slong(1) %解的路径及路径长度
xx=sj(path,1);yy=sj(path,2);
plot(xx,yy,'-o') %画出路径
flong =
3.9822e+04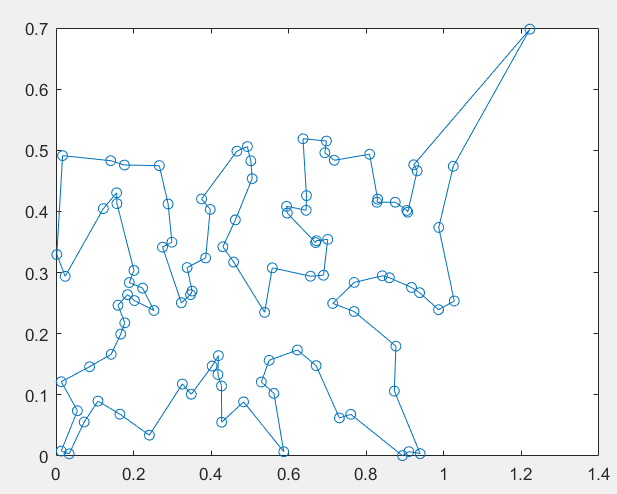
3.改进的遗传算法
tic %计时开始
clc,clear
sj0=load('sj.txt'); %加载100个目标的数据
x=sj0(:,1:2:8); x=x(:);
y=sj0(:,2:2:8); y=y(:);
sj=[x y]; d1=[70,40];
sj=[d1;sj;d1]; sj=sj*pi/180; %单位化成弧度
d=zeros(102); %距离矩阵d的初始值
for i=1:101
for j=i+1:102
d(i,j)=6370*acos(cos(sj(i,1)-sj(j,1))*cos(sj(i,2))*cos(sj(j,2))+sin(sj(i,2))*sin(sj(j,2)));
end
end
d=d+d'; w=50; g=100; %w为种群的个数g为进化的代数
rand('state',sum(clock)); %初始化随机数发生器
for k=1:w %通过改良圈算法选取初始种群
c=randperm(100); %产生1...100的一个全排列
c1=[1,c+1,102]; %生成初始解
for t=1:102 %该层循环是修改圈
flag=0; %修改圈退出标志
for m=1:100
for n=m+2:101
if d(c1(m),c1(n))+d(c1(m+1),c1(n+1))<d(c1(m),c1(m+1))+d(c1(n),c1(n+1))
c1(m+1:n)=c1(n:-1:m+1); flag=1; %修改圈
end
end
end
if flag==0
J(k,c1)=1:102; break %记录下较好的解并退出当前层循环
end
end
end
J(:,1)=0; J=J/102; %把整数序列转换成[0,1]区间上的实数即转换成染色体编码
for k=1:g %该层循环进行遗传算法的操作
A=J; %交配产生子代A的初始染色体
for i=1:2:w
ch1(1)=rand; %混沌序列的初始值
for j=2:50
ch1(j)=4*ch1(j-1)*(1-ch1(j-1)); %产生混沌序列
end
ch1=2+floor(100*ch1); %产生交叉操作的地址
temp=A(i,ch1); %中间变量的保存值
A(i,ch1)=A(i+1,ch1); %交叉操作
A(i+1,ch1)=temp;
end
by=[]; %为了防止下面产生空地址这里先初始化
while ~length(by)
by=find(rand(1,w)<0.1); %产生变异操作的地址
end
num1=length(by); B=J(by,:); %产生变异操作的初始染色体
ch2=rand; %产生混沌序列的初始值
for t=2:2*num1
ch2(t)=4*ch2(t-1)*(1-ch2(t-1)); %产生混沌序列
end
for j=1:num1
bw=sort(2+floor(100*rand(1,2))); %产生变异操作的2个地址
B(j,bw)=ch2([j,j+1]); %bw处的两个基因发生了变异
end
G=[J;A;B]; %父代和子代种群合在一起
[SG,ind1]=sort(G,2); %把染色体翻译成1...,102的序列ind1
num2=size(G,1); long=zeros(1,num2); %路径长度的初始值
for j=1:num2
for i=1:101
long(j)=long(j)+d(ind1(j,i),ind1(j,i+1)); %计算每条路径长度
end
end
[slong,ind2]=sort(long); %对路径长度按照从小到大排序
J=G(ind2(1:w),:); %精选前w个较短的路径对应的染色体
end
path=ind1(ind2(1),:), flong=slong(1) %解的路径及路径长度
toc %计时结束
xx=sj(path,1);yy=sj(path,2);
plot(xx,yy,'-o') %画出路径
flong =
4.0453e+04
四.预测方法
1.微分方程模型


dxy=@(t,x)[-0.0544*x(2)+54000*(t>=0 & t<1)+6000*(t>=2 & t<3)+13000*(t>=5 & t<6)
-0.0106*x(1)]; %用匿名函数定义方程右端项这里用逻辑语句定义分段函数
[t,xy]=ode45(dxy,[0:36],[0,21500])
subplot(211), plot(t,xy(:,1),'r*',t,xy(:,2),'gD')
xlabel('时间t'), ylabel('人数'), legend('美军','日军')
subplot(212), plot(xy(:,1),xy(:,2)) %画微分方程组的轨线
xlabel('美军人数x'), ylabel('日军人数y') 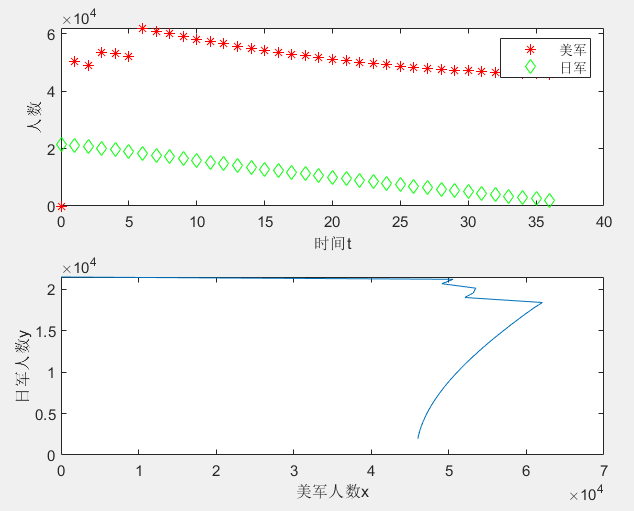
2.灰色预测模型(GM)
数据少、精度高
只适合中短期指数增长的预测
【1】GM(1,1)
一阶微分方程一个变量
较强的指数规律、单调的变化过程
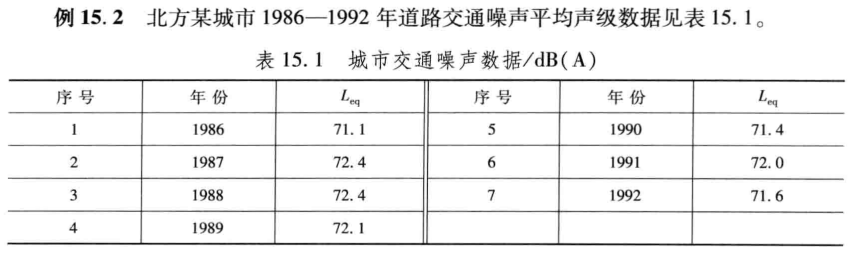
clc,clear
x0=[71.1 72.4 72.4 72.1 71.4 72.0 71.6]'; %注意这里为列向量
n=length(x0);
lamda=x0(1:n-1)./x0(2:n) %计算级比
range=minmax(lamda') %计算级比的范围
x1=cumsum(x0) %累加运算
B=[-0.5*(x1(1:n-1)+x1(2:n)),ones(n-1,1)];
Y=x0(2:n);
u=B\Y %拟合参数u(1)=a,u(2)=b
syms x(t)
x=dsolve(diff(x)+u(1)*x==u(2),x(0)==x0(1)); %求微分方程的符号解
xt=vpa(x,6) %以小数格式显示微分方程的解
yuce1=subs(x,t,[0:n-1]); %求已知数据的预测值
yuce1=double(yuce1); %符号数转换成数值类型否则无法作差分运算
yuce=[x0(1),diff(yuce1)] %差分运算还原数据
epsilon=x0'-yuce %计算残差
delta=abs(epsilon./x0') %计算相对误差
rho=1-(1-0.5*u(1))/(1+0.5*u(1))*lamda' %计算级比偏差值u(1)=a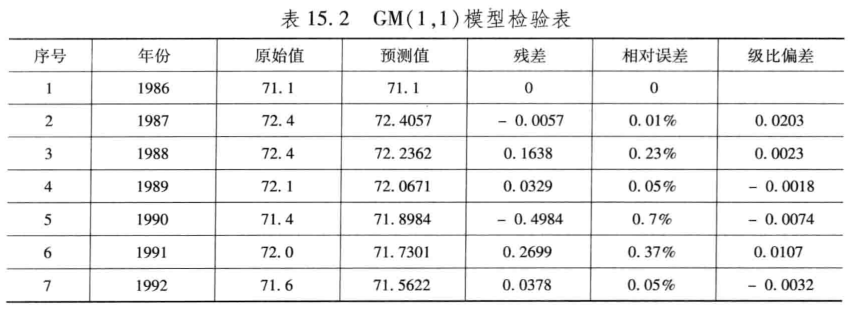
【2】GM(2,1)

clc,clear
x0=[41,49,61,78,96,104]; %原始序列
n=length(x0);
x1=cumsum(x0) %计算1次累加序列
a_x0=diff(x0)' %计算1次累减序列
z=0.5*(x1(2:end)+x1(1:end-1))'; %计算均值生成序列
B=[-x0(2:end)',-z,ones(n-1,1)];
u=B\a_x0 %最小二乘法拟合参数
syms x(t)
x=dsolve(diff(x,2)+u(1)*diff(x)+u(2)*x==u(3),x(0)==x1(1),x(5)==x1(6)); %求符号解
xt=vpa(x,6) %显示小数形式的符号解
yuce=subs(x,t,0:n-1); %求已知数据点1次累加序列的预测值
yuce=double(yuce) %符号数转换成数值类型否则无法作差分运算
x0_hat=[yuce(1),diff(yuce)]; %求已知数据点的预测值
x0_hat=round(x0_hat) %四舍五入取整数
epsilon=x0-x0_hat %求残差
delta=abs(epsilon./x0) %求相对误差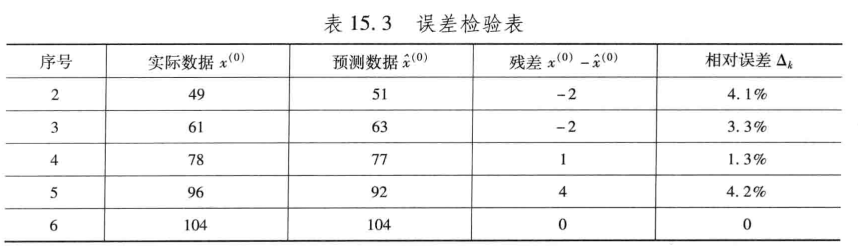
【3】DGM(2,1)

clc,clear
x0=[2.874,3.278,3.39,3.679,3.77,3.8]; %原始数据序列
n=length(x0);
a_x0=diff(x0)'; %求1次累减序列即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0 %最小二乘法拟合参数
syms x(t)
d2x=diff(x,2); dx=diff(x); %定义一阶导数是为了下面赋初值
x=dsolve(d2x+u(1)*dx==u(2),x(0)==x0(1),dx(0)==x0(1)); %求二阶微分方程符号解
xt=vpa(x,6) %显示小数形式的符号解
yuce=subs(x,'t',0:n-1); %求已知数据点1次累加序列的预测值
yuce=double(yuce) %符号数转换成数值类型否则无法作差分运算
x0_hat=[yuce(1),diff(yuce)] %求已知数据点的预测值
epsilon=x0-x0_hat %求残差
delta=abs(epsilon./x0) %求相对误差
【4】Verhulst
S型过程如人口预测、生物生长、繁殖预测、产品经济寿命预测

clc,clear
x0=[4.93 2.33 3.87 4.35 6.63 7.15 5.37 6.39 7.81 8.35];
x1=cumsum(x0); %求1次累加序列
n=length(x0);
z=0.5*(x1(2:n)+x1(1:n-1)); %求x1的均值生成序列
B=[-z',z'.^2];
Y=x0(2:end)';
u=B\Y %估计参数a,b的值
syms x(t)
x=dsolve(diff(x)+u(1)*x==u(2)*x^2,x(0)==x0(1)); %求符号解
xt=vpa(x,6) %显示小数形式的符号解
yuce=subs(x,'t',[0:n-1]); %求已知数据点1次累加序列的预测值
yuce=double(yuce) %符号数转换成数值类型否则无法作差分运算
x0_hat=[yuce(1),diff(yuce)] %求已知数据点的预测值
epsilon=x0-x0_hat %求残差
delta=abs(epsilon./x0) %求相对误差
xlswrite('book4.xls',[x0',x0_hat',epsilon',delta'])


3.马尔科夫链
系统未来的情况只与现在有关而与过去无直接关系
【1】一步转移矩阵

clc,clear
format rat %数据格式是有理分数
fid=fopen('msdata.txt','r');
a=textscan(fid,'%s');b=strjoin(a{:},'');
for i=0:1
for j=0:1
s=[int2str(i),int2str(j)]; %构造子字符串‘ij’
f(i+1,j+1)=length(strfind(b,s)); %计算子串tijr的个数
end
end
fs=sum(f,2); %求f矩阵的行和
p=f./fs %求状态转移频率
p =
4/13 9/13
9/35 26/35 
【2】极限转移矩阵



format rat %有理分数的数据格式
p=[0.8 0.1 0.1;0.5 0.1 0.4;0.5 0.3 0.2];
a=[p'-eye(3);ones(1,3)]; %构造方程组ax=b的系数矩阵
b=[zeros(3,1);1]; %构造方程组ax=b的常数项列
p_limit=a\b %求方程组的解
format %恢复到短小数的显示格式clc,clear, format rat
p=[0.8 0.1 0.1;0.5 0.1 0.4;0.5 0.3 0.2];
[v,d]=eigs(p',1) %求最大特征值及对应的特征向量
p=v/sum(v) %把最大特征值对应的特征向量化成概率向量
format %恢复到短小数的显示格式
p_limit =
5/7
11/84
13/84 4.时间序列
clc, clear
a=[15.2 15.9 18.7 22.4 26.9 28.3 30.5
33.8 40.4 50.7 58 66.7 81.2 83.4];
a=a'; a=a(:); a=a'; %把原始数据按照时间顺序展开成一个行向量
Rt=tiedrank(a) %求原始时间序列的秩
n=length(a); t=1:n;
Qs=1-6/(n*(n^2-1))*sum((t-Rt).^2) %计算Qs的值
T=Qs*sqrt(n-2)/sqrt(1-Qs^2) %计算T统计量的值
t_0=tinv(0.975,n-2) %计算上alpha/2分位数
b=diff(a) %求原始时间序列的一阶差分
m=ar(b,2,'ls') %利用最小二乘法估计模型的参数
bhat=predict(m,b') %求原始数据的预测值,第二个参数必须为列向量
bhat(end+1)=forecast(m,b',1) %计算1个预测值第二个参数必须为列向量
ahat=[a(1), a+bhat'] %求原始数据的预测值并计算t=15的预测值
delta=abs((ahat(1:end-1)-a)./a) %计算原始数据预测的相对误差
xlswrite('yu.xls',ahat), xlswrite('yu.xls',delta,'Sheet1','A3')
%数据写到Excel文件中方便word中做表格贴入数据
m =
Discrete-time AR model: A(z)y(t) = e(t)
A(z) = 1 - 0.2785 z^-1 - 0.6932 z^-2
ahat =
列 1 至 12
15.2000 15.9000 18.7000 19.9651 25.3715 30.7182 31.8093 32.0832 36.2442 44.5258 58.1439 67.1731
列 13 至 15
74.1835 91.2694 94.0640
5.插值拟合



clc,clear
syms x y
syms z positive %由于导弹在空中定义符号变量z为正
format long g %长小数的数据显示格式
a=load('daodan.txt'); %把原始的全部数据保存到纯文本文件daodan.txt中
d=a(:,[2:end]); %提取3个测距仪到观测点的距离a的第一列为时间
n=size(a,1); sol=[]; %sol为保存观测点坐标的矩阵这里初始化
for i=1:n
eq1=x^2+y^2+z^2-d(i,1)^2; %定义非线性方程组的符号方程的左端项
eq2=x^2+(y-4500)^2+z^2-d(i,2)^2;
eq3=(x+2000)^2+(y-1500)^2+z^2-d(i,3)^2;
[xx,yy,zz]=solve(eq1,eq2,eq3); %求x,y,z的符号解。
sol=[sol;double([xx,yy,zz])]; %数据类型转换符号数据无法进行插值运算
end
sol %显示求得的10个点的坐标
pp1=csape(a(:,1),sol(:,1)) %求x(t)的插值函数
xishu1=pp1.coefs(end,:) %显示x(t)最后一个区间的三次样条函数的系数
pp2=csape(a(:,1),sol(:,2)) %求y(t)的插值函数
xishu2=pp2.coefs(end,:) %显示y(t)最后一个区间的三次样条函数的系数
pp3=csape(a(:,1),sol(:,3)) %求z(t)的插值函数
xishu3=pp3.coefs(end,:) %显示z(t)最后一个区间的三次样条函数的系数
6.神经网络
BP(Back Propagation)神经网络
RBF(Radial Basis Function)神经网络


clc, clear
a=load('jingliu.txt'); %把表中第2列到第6列的数据保存到纯文本文件jingliu.txt
a=a'; %注意神经网络的数据格式不要把矩阵搞转置了。
P=a([1:4],[1:end-1]); [PN,PS1]=mapminmax(P); %自变量数据规格化到[-1,1]
T=a(5,[1:end-1]); [TN,PS2]=mapminmax(T); %因变量数据规格化到[-1,1]
net1=newrb(PN,TN) %训练RBF网络
x=a([1:4],end); xn=mapminmax('apply',x,PS1); %预测样本点自变量规格化
yn1=sim(net1,xn); y1=mapminmax('reverse',yn1,PS2) %求预测值并把数据还原
delta1=abs(a(5,20)-y1)/a(5,20) %计算RBF网络预测的相对误差
net2=feedforwardnet(4); %初始化BP网络隐含层的神经元取为4个多次试验
net2 = train(net2,PN,TN); %训练BP网络
yn2= net2(xn); y2=mapminmax('reverse',yn2,PS2) %求预测值并把数据还原
y1 =
26.769326187095
y2 =
19.3755918085407