

【前端设计】监控顺序返回型总线超时的计时器模块设计
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
前言
总线超时检查机制是系统中必要的模块设计,用于在总线无法返回response时能够及时上报中断。从理论上分析,如果总线发生了诸如挂死或者物理损坏等超时行为,无论计时器上报timeout的时间偏大还是偏小,都是一定可以上报中断的。不过呢在一些敏感的系统中,及时发现问题还是很有必要的,因此这篇文章来聊一下如何设计一个相对平衡的超时计数器。
适用场景为支持outstanding的顺序返回response的总线。
严格计时
如果以最严格的超时检查机制,那么理应对每一个发送出去的req都要进行rsp返回计时:
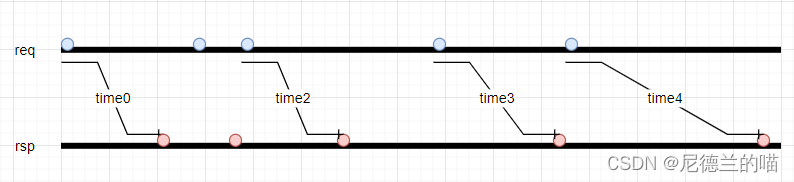
中断超时的条件也就是:
(time0 > timeout) || (time1 > timeout) || (time2 > timeout) || (time3 > timeout) || ...
任何一个计时器超时了都会上报超时中断,显然这样是最及时最准确的方式。但是这样做的缺点也非常的明显,需要为每一个req组织一个计时器,大概有outstanding * timer_width的寄存器资源消耗以及额外的逻辑开销。
简单计时
如果采用简单的超时检查机制呢,那么我们就只需要知道总线是否还“活着”,因此可以把计时器设置为看门狗的方式:当有rsp未返回时,计数器始终累加,每次有一个rsp返回,则把计数器清零:
timer = rsp ? 0 : outstanding