

[零基础]用docker搭建Hadoop集群
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
准备下载VMware、VMwareTools或Xftp、Xshell、Ubuntu或者CentOS映像文件、Hadoop和jdk压缩包
3通过build Dockfile生成带ssh功能的centos镜像
5生成带有ssh、hadoop和jdk环境的CentOS镜像
4测试是否成功配置ssh免密登录ssh + hadoop服务器名
2编辑hadoop_env.sh修改下面三个参数按照你自己的改
前言为什么要用docker搭建Hadoop集群
1、磁盘空间的占用
docker搭建的集群占用电脑磁盘空间较小对电脑的硬件要求也不高搭建一个Hadoop集群一主两从只需要17GB左右的磁盘空间而常规的开启多台虚拟机搭建的方法可能搭建一台Hadoop服务器就需要将近20GB的磁盘空间。
2、稳定性
docker搭建的Hadoop集群不容易宕机用常规的方法搭建的话可能会有一台或者多台虚拟机宕机稳定性较差。
准备下载VMware、VMwareTools或Xftp、Xshell、Ubuntu或者CentOS映像文件、Hadoop和jdk压缩包
给大家准备了Ubuntu映像文件、Hadoop和jdk压缩包点击链接下载即可。没有Xftp和Xshell的同学可以用VMwareTools替代只要把压缩包添加到虚拟机主机上即可。
链接Ubuntu、jdk、Hadoop
提取码2v56
一、创建虚拟机
用VMware创建一台新的虚拟机(CentOS或Ubuntu都可以
1点击新建虚拟机

2下一步

3下一步

4选择映像文件
选择自己的映像文件CentOS或者Ubuntu都可以后面第11步开启虚拟机时可能要加载20分钟左右不想等待加载的话可以选择稍后安装操作系统自定义安装可以快一点不过很多东西得自己配置和下载后续使用可能麻烦一点。

5自定义信息

6自定义信息位置最好放在非C盘

7设置处理器内核总数
处理器数量 x 每个处理器的内核数量 = 处理器内核总数依据自己电脑的配置设定在任务管理器的性能页面中可以查看自己电脑的处理器数量我的是8个直接设置最大值防止后续使用虚拟机时卡顿。


8 后面五步都选下一步即可。





9设置磁盘大小
设置磁盘大小为50GB只搭建Hadoop集群的话20GB就足够了但后面还需要搭建其他集群所以设置磁盘大小为50GB可以根据自己的需求设定。将虚拟磁盘拆分成多个文件。

10点击下一步再点击完成


11自动加载默认配置
这个过程可能需要二十分钟左右。如果不想等待加载可以在第4步选择自己的映像文件那里选择稍后安装操作系统不过很多东西得自己配置和下载后续使用可能麻烦一点。成功开启虚拟机页面如下所示

二、安装docker并生成相关的镜像
1安装docker
CentOS在 CentOS | 上安装 Docker 引擎码头工人文档
Ubuntu: 在 Ubuntu | 上安装 Docker 引擎码头工人文档
只要在终端输入sudo docker run hello-world后出现如下图的内容就证明安装docker成功了

2拉取CentOS镜像Ubuntu镜像也行
在终端输入sudo docker pull centos
在终端输入sudo docker images可以看到刚刚拉取的两个镜像

每次执行docker语句都要在前面加sudo比较麻烦直接将hadoop用户加入docker用户组就不用再输入sudo了。
sudo gpasswd -a $USER docker #将当前用户加入到docker用户组中
newgrp docker #重新加载docker用户组
一般安装时会自动创建docker用户组如果docker用户组不存在的话在终端输入
sudo groupadd docker #创建docker用户组
注意此时只有执行上述两条命令行的终端可以不用输入sudo其他终端仍要输入得重启虚拟机后所有终端才不用输入sudo。
3通过build Dockfile生成带ssh功能的centos镜像
先创建Dockfile文件在终端输入
vi Dockerfile
在Dockfile文件中添加以下内容
FROM centos
MAINTAINER hadoop
RUN cd /etc/yum.repos.d/
RUN sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*
RUN sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*
RUN yum makecache
RUN yum update -y
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
RUN yum install -y openssh-clients
RUN echo "root:a123456" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
Dockfile文件的内容解释基于centos镜像生成带有spenssh-server、openssh-clients的镜像用户为root密码为a123456镜像维护者作者为hadoop。为了防止出现Error: Failed to download metadata for repo 'appstream': Cannot prepare internal mirrorlist: No URLs in mirrorlist
错误我更改了yum下载依赖的镜像baseurl。注意如果拉取的镜像是Ubuntu的话得修改下载spenssh-server、openssh-clients的命令行。
你可能需要修改的地方
1、MAINTAINER hadoop
MAINTAINER+空格+作者的信息用于指定镜像作者的信息我的用户名是hadoop改成你自己的
2、root:a123456
设置镜像的密码改成你自己的
建好Dockerfile文件后生成镜像在终端输入
docker build -t="centos7-ssh" .
查看生成的centos7-ssh镜像在终端输入
docker images

4将下载的文件上传虚拟机
没有Xftp和Xshell的同学可以用VMwareTools替代只要把压缩包添加到虚拟机主机上即可。安装VMwareTools后复制本地主机的文件粘贴到虚拟机主机指定目录下。下面演示的是Xftp和Xshell的操作。
1、在主机下载ssh在终端输入
sudo apt-get install -y openssh-server
下载完后查看ssh进程的运行状态在终端输入
ps -e|grep ssh

再查看ssh的运行状态在终端输入
systemctl status sshd

2、 查看ip地址在终端输入
ip a

我的ip地址是192.168.237.131
3、用Xshell和Xftp连接虚拟机主机
Xshell(测试是否能正常连接其实只需要用Xftp传输文件

用户名填hadoop换成你自己的root可能会登不上如果ssh运行状态没问题还连接不上的话可能是防火墙没关。
Xftp

将压缩包上传到/home/hadoop有Dockerfile的目录如果上传失败可能是目录没有传输文件的权限在终端输入chmod 777 /home/hadoop/
4、解压文件把目录和文件名改成你自己的
在终端输入
tar -zxvf /home/hadoop/hadoop-3.1.3.tar.gz -C /home/hadoop
tar -zxvf /home/hadoop/jdk-8u212-linux-x64.tar.gz -C /home/hadoop
5生成带有ssh、hadoop和jdk环境的CentOS镜像
移除原有的Dockerfile文件在终端输入
mv Dockerfile Dockerfile.bak
再重新创建一个Dockerfile文件在终端输入
vi Dockerfile
或者直接在Xftp上用记事本编辑原来的Dockerfile文件更加方便推荐

将下面内容填入Dockerfile文件(记得保存)
FROM centos7-ssh
COPY jdk1.8.0_212 /usr/local/jdk
ENV JAVA_HOME /usr/local/jdk
ENV PATH $JAVA_HOME/bin:$PATH
COPY hadoop-3.1.3 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
构建Dockerfile,在终端输入
docker build -t="hadoop" .
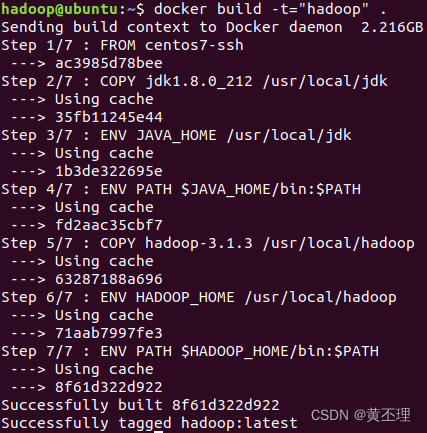
成功生成名字为hadoop的镜像。
三、创建网桥并启动docker容器
因为集群的服务器之间需要通信而且每次虚拟机给集群分配的ip地址都不一样所以需要创建网桥给每台服务器分配固定的ip映射这样就可以通过使用服务器名进行通信了而且ip地址也不会变动。
1创建网桥在终端输入
docker network create hadoop
2查看网桥在终端输入
docker network ls

其他三个网桥是安装docker时自带的hadoop是刚刚创建的。
3启动三个容器并指定网桥
依次在终端执行下面三条命令行
docker run -itd --network hadoop --name hadoop1 -p 50070:50070 -p 8088:8088 hadoop
docker run -itd --network hadoop --name hadoop2 hadoop
docker run -itd --network hadoop --name hadoop3 hadoop
参数解释
-itd在后台运行交互式容器
--network指定网桥
--name指定生成的容器名
-p指定端口映射主机端口号容器端口号第一个是hdfs服务第二个是yarn 服务
末尾的hadoop是运行的镜像名
查看生成的容器在终端输入
docker ps -a
 查看网桥使用情况在终端输入
查看网桥使用情况在终端输入
docker network inspect hadoop

记录每台服务器的ip地址后面要用每个人的可能不一样换成你自己的
172.18.0.2 hadoop1
172.18.0.3 hadoop2
172.18.0.4 hadoop3
四、登录容器配置ip地址映射和ssh免密登录
(1)登录容器Hadoop服务器
开启三个终端在每个终端分别输入
docker exec -it hadoop1 bash
docker exec -it hadoop2 bash
docker exec -it hadoop3 bash
2在每个hadoop服务器中配置ip地址映射
在每台hadoop服务器的终端输入
vi /etc/hosts
然后填入刚刚记录的ip地址

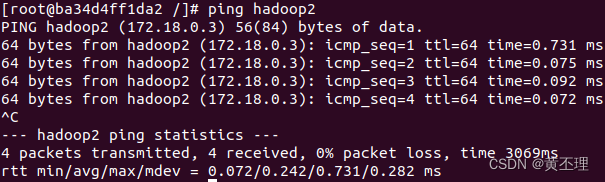
每台Hadoop服务器都配置好后可以互相ping一下ctrl + c停止ping看看是否配置成功。hadoop1 ping hadoop2 如下图所示
(3)在每台hadoop服务器中配置ssh免密登录
在每台hadoop服务器终端输入
ssh-keygen
然后一直回车即可再在每台hadoop服务器终端中输入
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop1
填yes后输入第二3步时设置的密码a123456
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop2
填yes后输入第二3步时设置的密码a123456
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop3
填yes后输入第二3步时设置的密码a123456
4测试是否成功配置ssh免密登录ssh + hadoop服务器名
ssh hadoop1
ssh hadoop2
ssh hadoop3
五、修改Hadoop配置文件
在hadoop1中进入Hadoop配置目录我的是/usr/local/hadoop/etc/hadoop查看目录下的文件不同版本的Hadoop可能文件数量和名字会不同在终端输入
ls

1创建文件夹配置时要用
mkdir /home/hadoop
mkdir /home/hadoop/tmp /home/hadoop/hdfs_name /home/hadoop/hdfs_data
2编辑hadoop_env.sh修改下面三个参数按照你自己的改

3编辑core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
(4)编辑mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
5编辑hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs_name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs_data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9001</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9002</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
Hadoop的Web UI界面访问地址1、namenodehadoop1:9001会自动跳转到9000端口如果直接访问9000端口号可能会访问异常2、secondarynamenodehadoop2:9002
6编辑yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
</configuration>
7编辑workers,把原先的默认值localhost删除
hadoop2
hadoop3
8配置环境变量在终端输入
vi /etc/profile
在文件尾部添加配置
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
保存退出后再输入下面的命令行使配置生效
source /etc/profile
9把文件拷贝到hadoop2和hadoop3上
依次执行以下命令
scp -r $HADOOP_HOME/ hadoop2:/usr/local/
scp -r $HADOOP_HOME/ hadoop3:/usr/local/
scp -r /home/hadoop hadoop2:/
scp -r /home/hadoop hadoop3:/
scp -r /etc/profile hadoop2:/
scp -r /etc/profile hadoop3:/
10给文件赋权
在每台hadoop服务器的终端执行下面两条命令行
chmod -R 777 /usr/local/hadoop
chmod -R 777 /usr/local/jdk
六、启动Hadoop集群
1在hadoop1上执行以下命令
1、格式化hdfs
hdfs namenode -format
2、一键启动Hadoop集群
start-all.sh
2测试Hadoop集群
每台服务器都输入
jps
hadoop1

hadoop2

hadoop3

hadoop1是名称结点hadoop2是第二名称节点和数据节点hadoop3是数据节点。网上很多人把名称节点和第二名称节点配置在同一台服务器上我觉得这样配置是错的这样配置根本发挥不了第二名称节点的作用作为名称节点的检查点定期合并日志和镜像。
3磁盘空间占用
现在hadoop集群已经搭建好了我们看看磁盘空间占用了多少。前面是剩余磁盘空间后面是总磁盘空间可以得出只用了17GB左右。

参考使用docker部署hadoop集群_upupfeng的博客-CSDN博客
感谢浏览如果搭建过程中出现问题欢迎评论一起讨论一起进步