

自定义的卷积神经网络模型CNN,对图片进行分类并使用图片进行测试模型-适合入门,从模型到训练再到测试,开源项目-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
自定义的卷积神经网络模型CNN对图片进行分类并使用图片进行测试模型-适合入门从模型到训练再到测试开源项目
开源项目完整代码及基础教程
https://mbd.pub/o/bread/ZZWclp5x
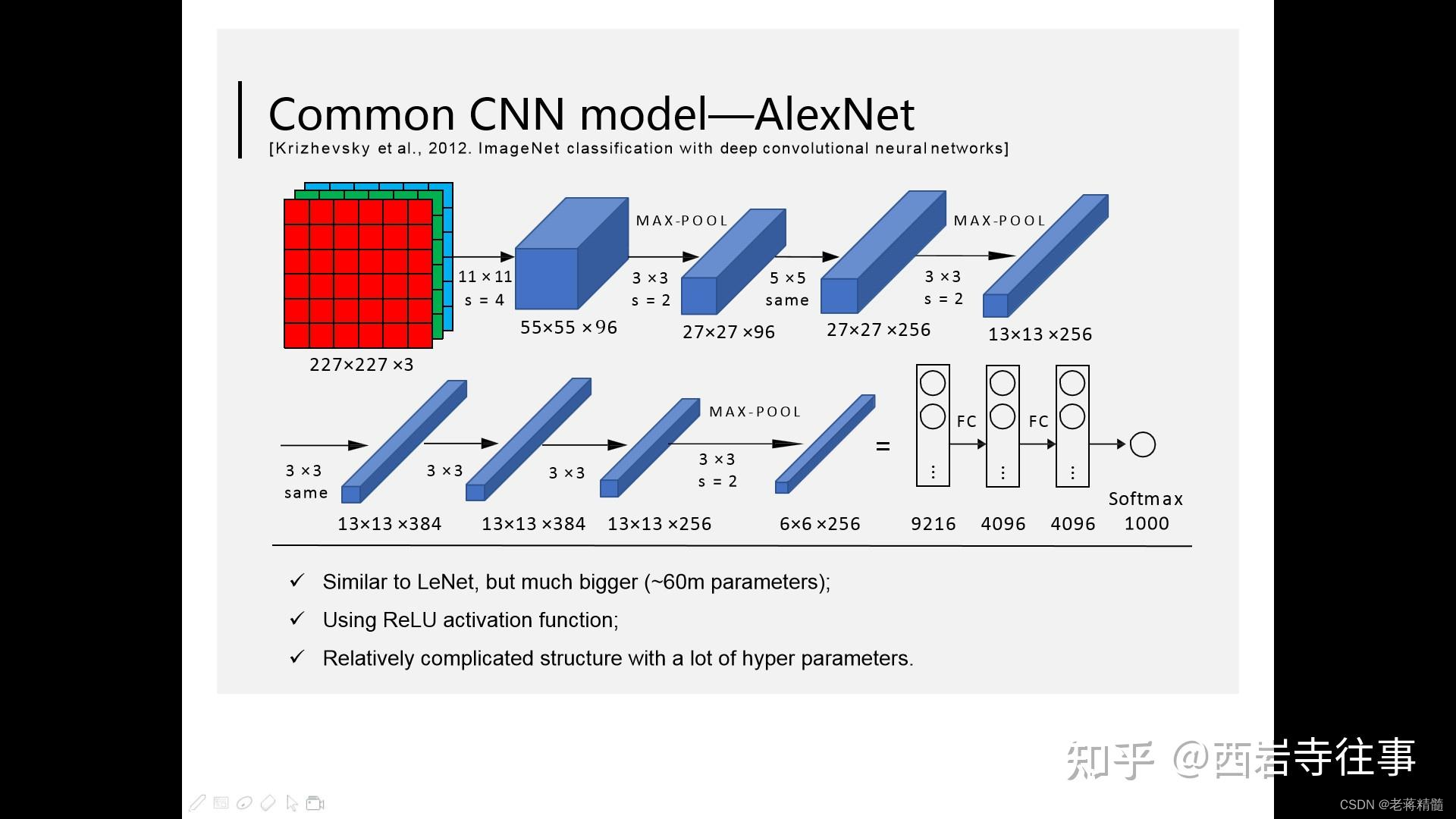
CNN模型
1.导入必要的库和模块
torchPyTorch深度学习框架。
torchvisionPyTorch的计算机视觉库用于处理图像数据。
transforms包含数据预处理的模块。
nnPyTorch的神经网络模块。
FPyTorch的函数模块包括各种激活函数等。
optim优化算法模块。
2.数据预处理
transforms.Compose将一系列数据预处理步骤组合在一起。
transforms.ToTensor()将图像数据转换为张量。
transforms.Normalize对图像数据进行归一化处理以均值0.5和标准差0.5。
定义批处理大小
batch_size每个训练批次包含的图像数量。
加载训练集
trainset使用CIFAR-10数据集设置训练标志为True。
torch.utils.data.DataLoader创建用于加载训练数据的数据加载器指定批处理大小和其他参数。
加载测试集
testset使用CIFAR-10数据集设置训练标志为False。
torch.utils.data.DataLoader创建用于加载测试数据的数据加载器指定批处理大小和其他参数。
定义CNN模型
My_CNN自定义的卷积神经网络模型包括卷积层、池化层和全连接层。
创建CNN模型、损失函数和优化器
model创建My_CNN模型的实例。
nn.CrossEntropyLoss()定义用于多分类问题的交叉熵损失函数。
optim.SGD使用随机梯度下降优化器指定学习率和动量。
训练模型
epochs指定训练轮数。
循环中的嵌套循环迭代训练数据批次进行前向传播、反向传播和参数优化。
保存模型
model_path指定模型保存的路径。
torch.save保存训练后的模型。
在测试集上评估模型性能
计算模型在测试集上的准确率。
计算每个类别的准确率。
具体代码来说
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
解释
transforms.Compose这是一个用于组合多个数据预处理步骤的函数。它允许你按顺序应用多个转换以便将原始数据转换为最终的形式。
transforms.ToTensor()这是一个数据预处理步骤将图像数据转换为张量tensor的格式。在深度学习中张量是常用的数据表示方式因此需要将图像数据从常见的图像格式如JPEG或PNG转换为张量。
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))这是另一个数据预处理步骤用于对图像进行归一化处理。归一化的目的是将图像的像素值缩放到一个特定的范围以便神经网络更容易学习。在这里均值和标准差都被设置为0.5这将使图像像素值在-1到1之间。
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=0)
解释
batch_size = 4定义了每个训练和测试批次中包含的图像数量。在深度学习中通常将数据分成小批次进行训练以便更有效地使用计算资源。
trainset 和 testset 的定义这两行代码加载了CIFAR-10数据集的训练集和测试集并进行了如下操作
torchvision.datasets.CIFAR10使用CIFAR-10数据集它包括一组包含10个不同类别的图像数据适用于图像分类任务。
root=‘./data’指定数据集的存储目录可以根据需要更改。
train=True 和 train=False这两个参数分别用于加载训练集和测试集。
download=True如果数据集尚未下载会自动下载。
transform=transform指定了前面定义的数据预处理管道将在加载数据时应用。
trainloader 和 testloader 的定义这两行代码创建了数据加载器将数据集划分为批次以进行训练和测试。
torch.utils.data.DataLoader这是PyTorch提供的用于加载数据的工具可以自动处理数据的分批和洗牌等任务。
batch_size=batch_size指定了每个批次的大小即每次加载多少图像数据。
shuffle=True 和 shuffle=Falseshuffle参数指定是否在每个epoch训练轮次之前对数据进行洗牌以增加数据的随机性。通常在训练时进行洗牌而在测试时不进行洗牌。
num_workers=0这个参数指定用于数据加载的线程数。在此代码中设置为0表示不使用多线程加载数据。如果有多个CPU核心可用可以将其设置为大于0的值以加速数据加载。
class My_CNN(nn.Module):
def __init__(self):
super().__init__()
省略部分代码
def forward(self, x):
省略部分代码
return x
model = My_CNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
解释
这部分代码定义了一个卷积神经网络CNN模型并创建了用于训练该模型的损失函数和优化器。让我们逐步解释每一部分
class My_CNN(nn.Module):这是一个自定义的CNN模型类的定义。这个类继承自nn.Module这是PyTorch中构建神经网络模型的基本方式。
def init(self):这是构造函数用于初始化CNN模型的各个层。
super().init()调用父类nn.Module的构造函数以确保正确初始化模型。
self.conv1 和 self.conv2这是两个卷积层的定义分别具有不同数量的输入和输出通道以及卷积核的大小。
self.pool这是最大池化层的定义用于减小特征图的空间尺寸。
self.fc1、self.fc2 和 self.fc3这是三个全连接层也称为线性层用于将卷积层的输出转换为最终的分类结果。
def forward(self, x):这是前向传播函数定义了模型的前向传播过程。
在前向传播中输入x经过卷积层、激活函数F.relu、池化层以及全连接层最终输出分类结果。
torch.flatten(x, 1)这一步将卷积层的输出扁平化以便将其输入到全连接层。
返回值是模型的输出表示对输入数据的分类预测。
model = My_CNN()创建了My_CNN类的一个实例即CNN模型。
criterion = nn.CrossEntropyLoss()定义了损失函数这里使用的是交叉熵损失函数。它用于衡量模型的预测与实际标签之间的差距是一个用于监督学习任务的常见损失函数。
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)定义了优化器这里使用的是随机梯度下降SGD。优化器负责更新模型的参数以减小损失函数的值。学习率lr和动量momentum是优化算法的超参数影响了参数更新的速度和方向。
epochs=5
for epoch in range(epochs): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('Finished Training')
name_path = './cnn_model_model.pth'
torch.save(model,name_path)
解释
epochs=5定义了训练的轮次epochs也就是模型将遍历整个训练数据集的次数。
for epoch in range(epochs):这是一个循环遍历每个训练轮次。
running_loss = 0.0用于追踪每个训练轮次的累积损失。
for i, data in enumerate(trainloader, 0):这个嵌套循环遍历训练数据集的小批次。
i 表示当前批次的索引。
data 包含了当前批次的输入数据和标签。
optimizer.zero_grad()在每个批次开始时将优化器的梯度清零以便准备计算新的梯度。
outputs = model(inputs)进行前向传播将输入数据传递给模型得到模型的输出。
loss = criterion(outputs, labels)计算损失衡量模型的预测与实际标签之间的差距。使用了前面定义的交叉熵损失函数。
loss.backward()进行反向传播计算模型参数相对于损失的梯度。
optimizer.step()根据计算得到的梯度更新模型的参数以减小损失函数的值。
running_loss += loss.item()累积当前批次的损失值用于后续打印统计信息。
if i % 2000 == 1999:每经过2000个小批次打印一次统计信息。这是为了跟踪训练进度查看损失是否在逐渐减小。
print(f’[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')打印当前训练轮次和批次的损失值。
running_loss = 0.0重置累积损失值以便下一个统计周期。
print(‘Finished Training’)当所有轮次的训练完成后打印 “Finished Training” 以指示训练结束。
name_path = ‘./cnn_model_model.pth’指定模型的保存路径。
torch.save(model, name_path)将训练好的模型保存到指定路径。这样可以在之后的任务中加载和使用该模型而不需要重新训练。
这段代码执行了模型的训练过程循环遍历多个轮次每轮次内遍历训练数据的小批次。在每个小批次中进行前向传播、计算损失、反向传播以及参数更新。训练的目标是通过调整模型参数减小损失函数的值从而提高模型的性能。同时每隔一定数量的小批次打印训练统计信息以监视训练进度。最后训练完成后模型被保存到文件以备将来使用。
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
prepare to count predictions for each class
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
again no gradients needed
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model(images)
_, predictions = torch.max(outputs, 1)
# collect the correct predictions for each class
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
print accuracy for each class
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')
解释
classes = (‘plane’, ‘car’, ‘bird’, ‘cat’,‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’)这是数据集中的类别标签它们代表CIFAR-10数据集中的10个不同类别分别是飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车。
correct_pred 和 total_pred这两个字典用于跟踪每个类别的正确预测数量和总预测数量初始化为零。
with torch.no_grad():这个语句块指示在此之后的计算不需要梯度信息。这是因为在测试阶段我们不需要计算梯度只是进行前向传播和计算准确度。
for data in testloader:遍历测试数据集的小批次。
images, labels = data将小批次数据分成图像和对应的标签。
outputs = model(images)使用训练好的模型对图像进行预测得到模型的输出。
_, predictions = torch.max(outputs, 1)通过 torch.max 函数找到每个样本预测的类别即具有最高预测分数的类别。
for label, prediction in zip(labels, predictions):通过 zip 函数将实际标签和预测标签一一对应起来以便比较它们。
if label == prediction:比较实际标签和预测标签如果它们相等表示模型做出了正确的预测。
correct_pred[classes[label]] += 1对应类别的正确预测数量加一。
total_pred[classes[label]] += 1对应类别的总预测数量加一。
for classname, correct_count in correct_pred.items():遍历每个类别和其正确预测数量。
accuracy = 100 * float(correct_count) / total_pred[classname]计算每个类别的准确度即正确预测数量除以总预测数量以百分比表示。
print(f’Accuracy for class: {classname:5s} is {accuracy:.1f} %')打印每个类别的准确度格式化输出。
总结这段代码的目标是计算并打印出每个类别的分类准确度以便评估模型在不同类别上的性能。这是在测试阶段对模型性能进行评估的一种方式。
测试模型的代码
import torch
from PIL import Image
from torch import nn
import torch
import torchvision
import torch.nn.functional as F
device = torch.device('cuda')
image_path=“plane.png”
image =Image.open(image_path)
print(image)
image=image.convert('RGB')
transform=torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
image=transform(image)
print(image.shape)
class My_CNN(nn.Module):
def __init__(self):
super().__init__()
省略部分代码 return x
#加载模型
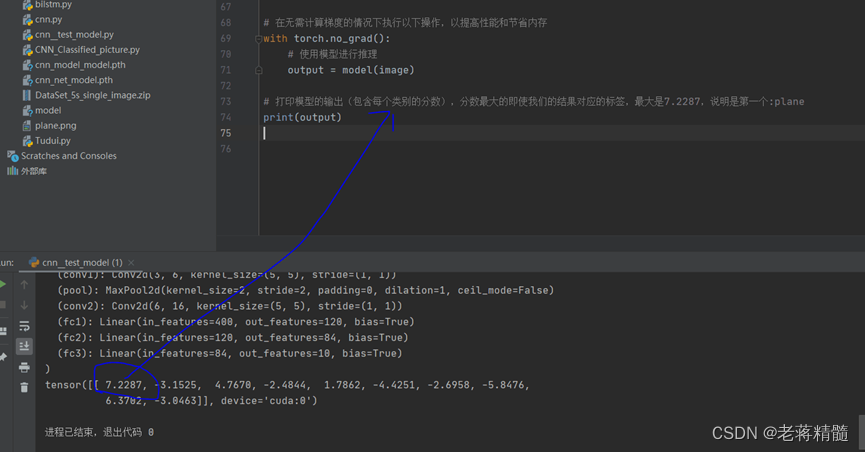
model = torch.load(“cnn_net_model.pth”,map_location=torch.device(‘cuda’))#加载完成网络模型,映射
print(model)#维数不够
image = torch.reshape(image,(1,3,32,32))#这一个很重要要满足四个通道
image=image.to(device)#做cuda变换不然报错
model.eval()
with torch.no_grad():#节约内存性能
output=model(image)
#识别类别数字最大的就是我们的结果
print(output)
解释
导入必要的库和模块
torchPyTorch库用于构建和运行深度学习模型。
PILPython Imaging Library用于处理图像。
nnPyTorch的神经网络模块。
FPyTorch的函数模块。
device将模型加载到GPU设备。
image_path待分类的图像文件路径。
Image.open(image_path)使用PIL库打开图像文件。
图像的预处理
image.convert(‘RGB’)将图像转换为RGB模式以确保图像通道数为3。
transform定义了一系列的图像预处理操作包括将图像缩放到32x32像素大小并将其转换为PyTorch的Tensor数据类型。
image = transform(image)应用上述的预处理操作将图像准备好以供模型处理。
定义神经网络模型
My_CNN 类这是一个自定义的卷积神经网络模型包括两个卷积层两个池化层以及三个全连接层。这个模型与之前训练的CNN模型相似用于图像分类任务。
加载预训练模型
model = torch.load(“cnn_net_model.pth”, map_location=torch.device(‘cuda’))加载之前训练并保存的CNN模型。map_location 参数指定了模型的加载位置这里指定为CUDA/GPU。
调整输入图像的维度和数据类型
image = torch.reshape(image, (1, 3, 32, 32))将输入的图像数据调整为适合模型的维度1个样本3个通道32x32像素大小。
image = image.to(device)将图像数据移动到GPU设备以便进行GPU上的推理。
模型推理和分类
model.eval()将模型切换到推理模式这意味着模型不再更新梯度。
with torch.no_grad():在这个块中不会计算或保存梯度信息以提高性能和节省内存。
output = model(image)对输入的图像进行前向传播得到模型的输出。
print(output)打印模型的输出这是一个包含了不同类别的分数的张量。
测试结果
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |