

HDFS操作方法和基础编程
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
一完成相关的
HDFS的基本shell命令0.命令基础
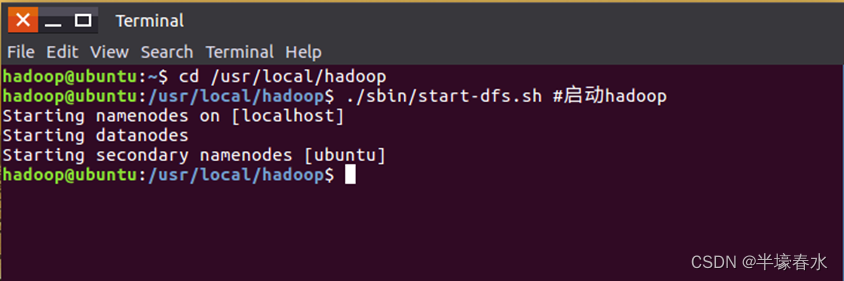
①执行命令启动
Hadoop版本是Hadoop3.1.3。
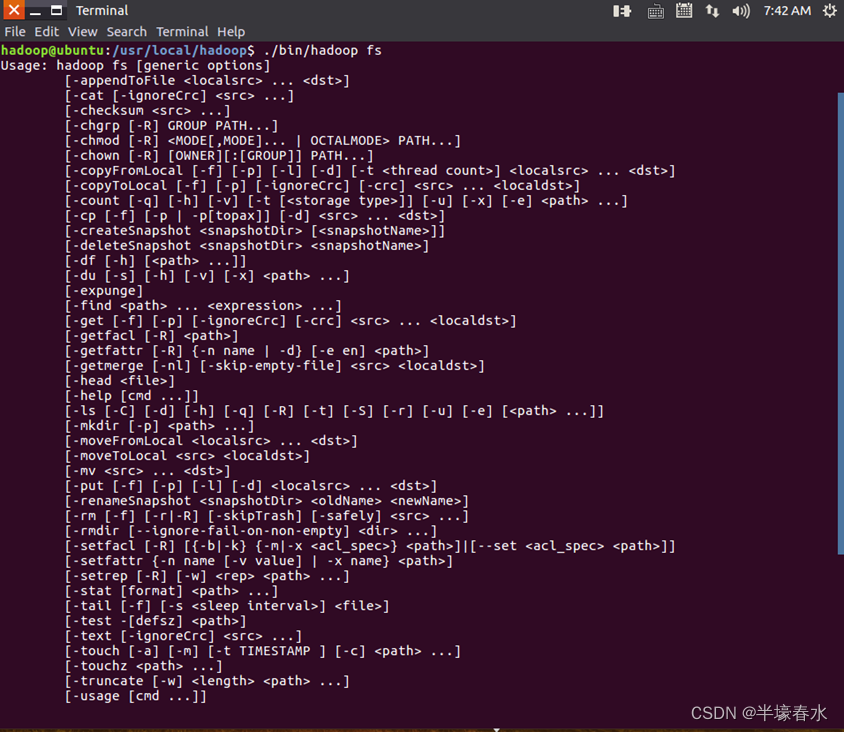
②Hadoop支持很多Shell命令其中fs是HDFS最常用的命令利用fs可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。在终端输入如下命令可以查看fs全部支持的命令。
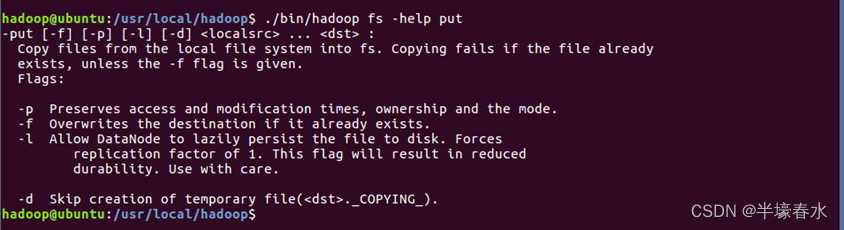
③在终端输入如下命令可以查看具体某个命令的作用。例如查看put命令如何使用可以输入如下命令。
1.目录操作
①
Hadoop系统安装好后第一次使用HDFS时需要首先在HDFS中创建用户目录。hadoop用户需要在HDFS中创建一个用户目录操作如下
该命令表示在HDFS中创建一个“/user/hadoop”目录“–mkdir”是创建目录的操作“-p”表示如果是多级目录则父目录和子目录一起创建这里“/user/hadoop”就是一个多级目录因此必须使用参数“-p”否则会出错。
②“/user/hadoop”目录成为hadoop用户对应的用户目录可以使用如下命令显示HDFS中与当前用户hadoop对应的用户目录下的内容。
在命令中“-ls”表示列出HDFS某个目录下的所有内容“.”表示HDFS中的当前用户目录也就是“/user/hadoop”目录。因此命令"./bin/hdfs dfs -ls.”和命令"./bin/hdfs dfs -ls /user/Hadoop"是等价的。
④列出HDFS上的所有目录。
⑤创建一个input目录但该目录已经存在。
⑥在创建个input目录时采用了相对路径形式实际上⑤的input目录创建成功以后它在HDFS中的完整路径是“/user/hadoop/input”。如果要在HDFS的根目录下创建一个名称为input的目录则需要使用如下命令。
⑦使用rm命令删除一个目录例如使用如下命令删除刚才在HDFS中创建的“/input”目录不是“/user/hadoop/input”目录
上面命令中“-r”参数表示如果删除“/input”目录及其子目录下的所有内容如果要删除的一个目录包含了子目录则必须使用“-r”参数否则会执行失败。2.文件操作
在实际应用中经常需要从本地文件系统向
HDFS中上传文件或者把HDFS中的文件下载到本地文件系统中。
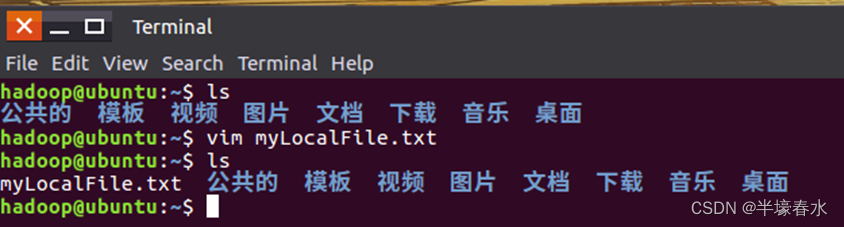
①首先使用vim编辑器在本地Linux文件系统的“/home/hadoop/”目录下创建一个文件myLocalFile.txt里面可以随意输入一些单词比如输入如下三行





Hadoop
Spark
XMU DBLAB

②使用如下命令把本地文件系统的“
/home/hadoop/myLocalFile.txt”上传到HDFS中的当前用户目录的input目录下也就是上传到HDFS的“/user/hadoop/input/”目录下
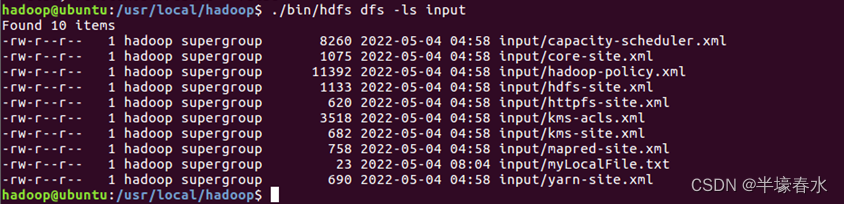
③使用ls命令查看一下文件是否成功上传到HDFS中执行后会显示类似如下的信息。
④使用如下命令查看HDFS中的myLocalFile.txt文件的内容。
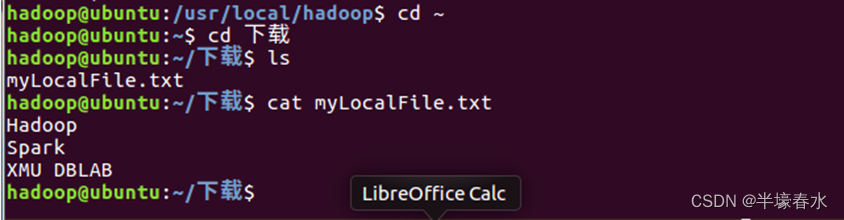
⑤把HDFS中的myLocalFile.txt文件下载到本地文件系统中的“/home/hadoop/下载/”这个目录下。
⑥使用如下命令到本地文件系统查看下载下来的文件myLocalFile.txt。
⑦把文件从HDFS中的一个目录拷贝到HDFS中的另外一个目录。比如要把HDFS的“/user/hadoop/input/myLocalFile.txt”文件拷贝到HDFS的另外一个目录“/input”中注意这个input目录位于HDFS根目录下可以使用如下命令。




二查看
HDFS的网页管理界面。请描述网页界面中的各个参数的名称打开
Linux自带的Firefox浏览器点击此链接HDFS的Web界面即可看到HDFS的web管理界面。WEB界面的访问地址是http://localhost:9870。
1.菜单栏
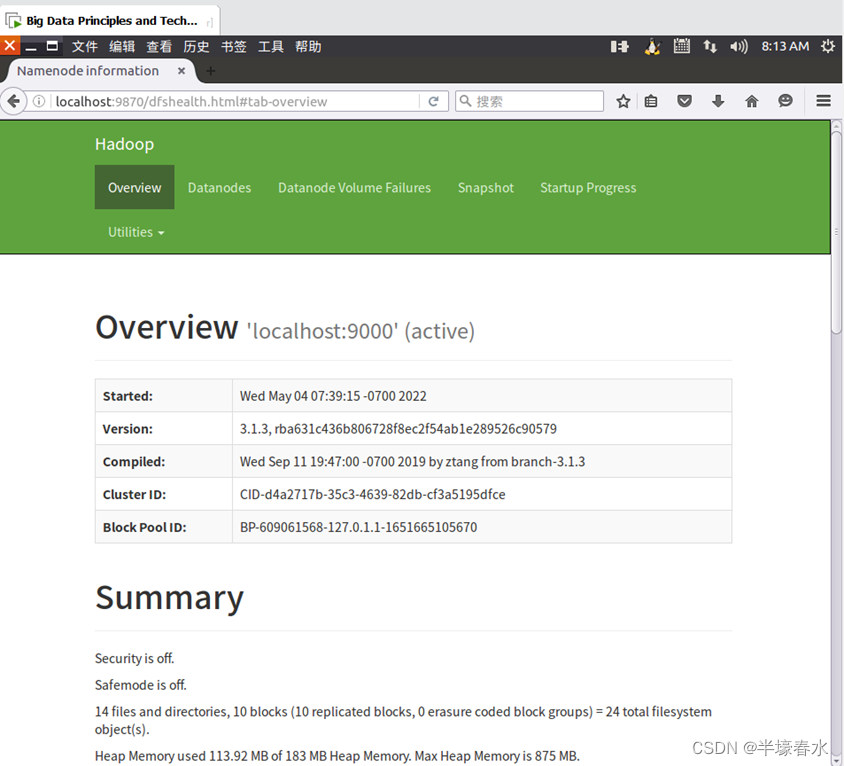

Overview:集群概述
Datanode:数据节点
datanode-volume-failures: 数据节点卷故障
snapshot: 快照
startup-progress: 启动进度
2.Overview
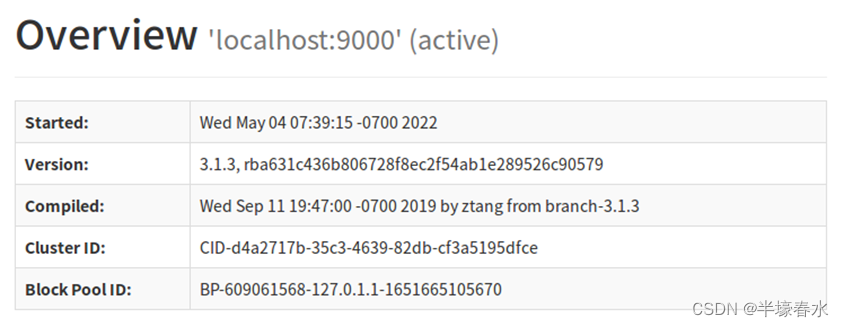
Started启动
Version版本
Compiled已编译
Cluster ID: 群集ID:
Block Pool ID: 块池ID:
3.Summary
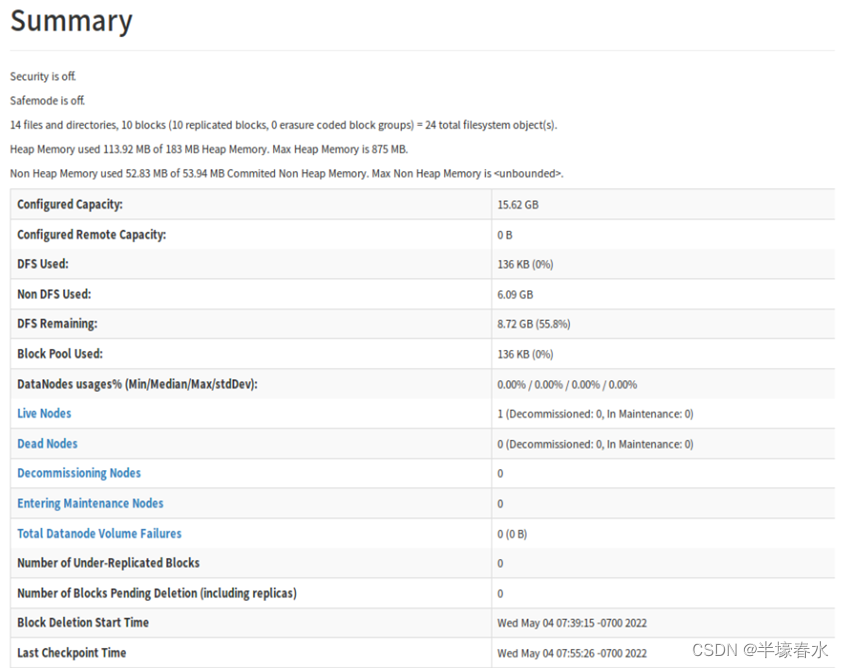
Security is off安全关闭
Safemode is off安全模式已关闭
Configured Capacity:集群配置的总的容量
DFS Used: 已使用的DFS集群总量
Non DFS Used: 已使用的非DFS的量
DFS Remaining: DFS未使用剩余的容量
Block Pool Used: 数据块使用的量
DataNodes usages% (Min/Median/Max/stdDev): 数据节点使用率最小值/中间值/最大值/标准偏差
Live Nodes存活的节点活动节点
Dead Nodes宕机的节点死节点
Decommissioning Nodes已停用节点
Entering Maintenance Nodes进入维护节点
Total Datanode Volume Failures数据节点卷失败的总数
Number of Under-Replicated Blocks复制不足的块数
Number of Blocks Pending Deletion挂起删除的块数
Block Deletion Start Time块删除的开始时间
Last Checkpoint Time上次检查点时间
4.NameNode Journal Status
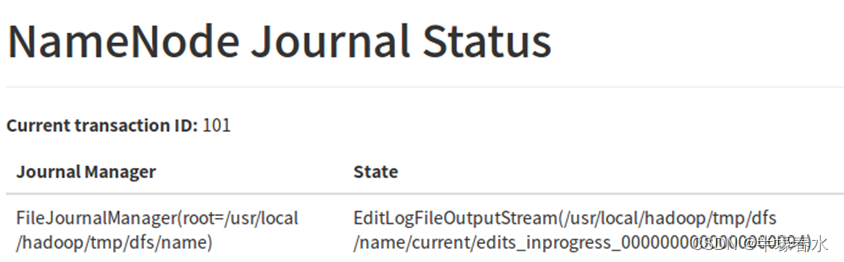
Journal ManagerJournal Node 存储EditLog数据的路径
State Journal Node 存储EditLog数据的文件名
5.NameNode Storage
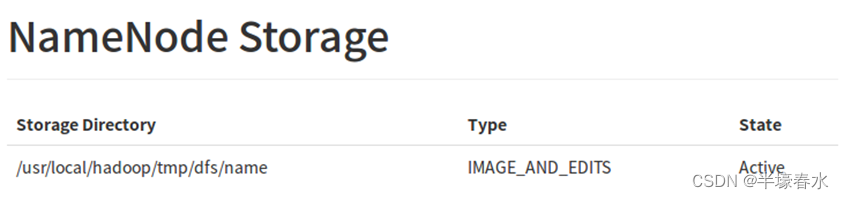
NameNode 存储数据的路径
NameNode存储name的路径
/usr/local/hadoop/tmp/dfs/name
6.DFS Storage Types
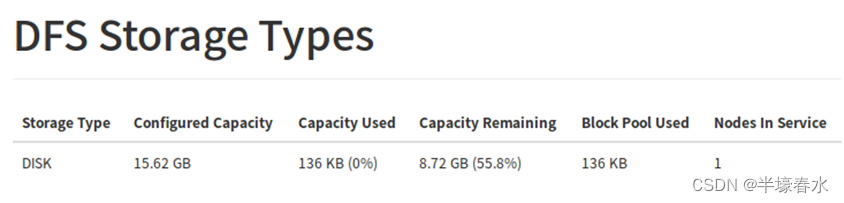
Storage Type 集群存储类型
Configured Capacity 配置容量
Capacity Used 使用的容量
Capacity Remaining 剩余容量
Block Pool Used 使用的块池
Nodes In Service 服务中的节点
7.Datanode
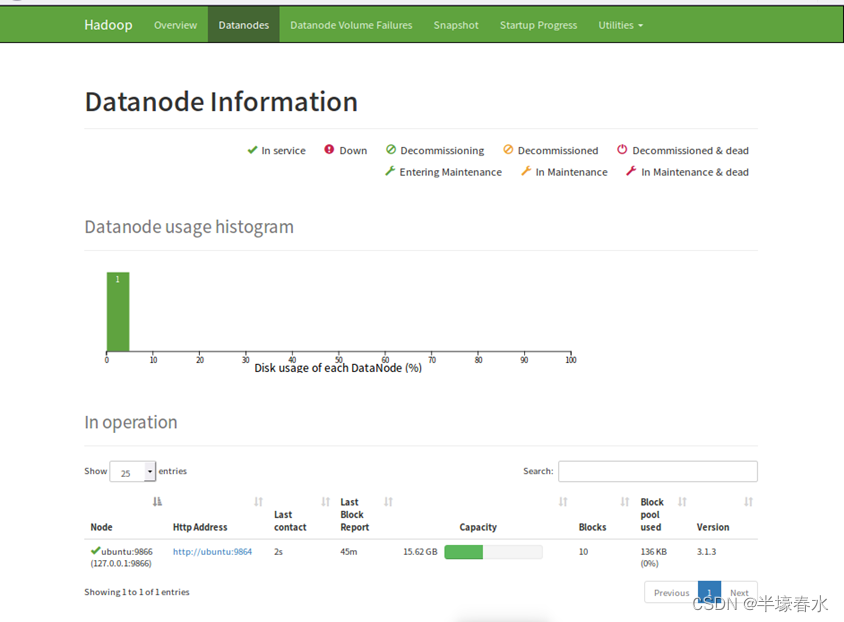
Datanode usage histogram 数据节点使用率柱状图
Disk usage of each DataNode (%) 每个数据节点的磁盘使用率%
In operation 运行中的节点
8.Entering Maintenance和Decommissioning
Entering Maintenance: 进入维护的节点列表
Decommissioning: 退役的节点列表
9.Snapshot Summary
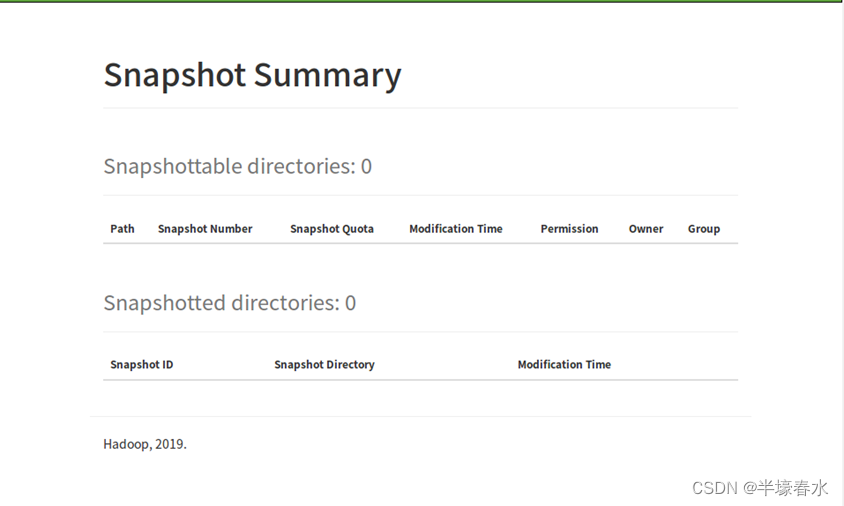
Snapshot Summary快照摘要
Snapshottable directories : 快照目录列表
Snapshotted directories: 已创建的快照目录
10.Startup Progress
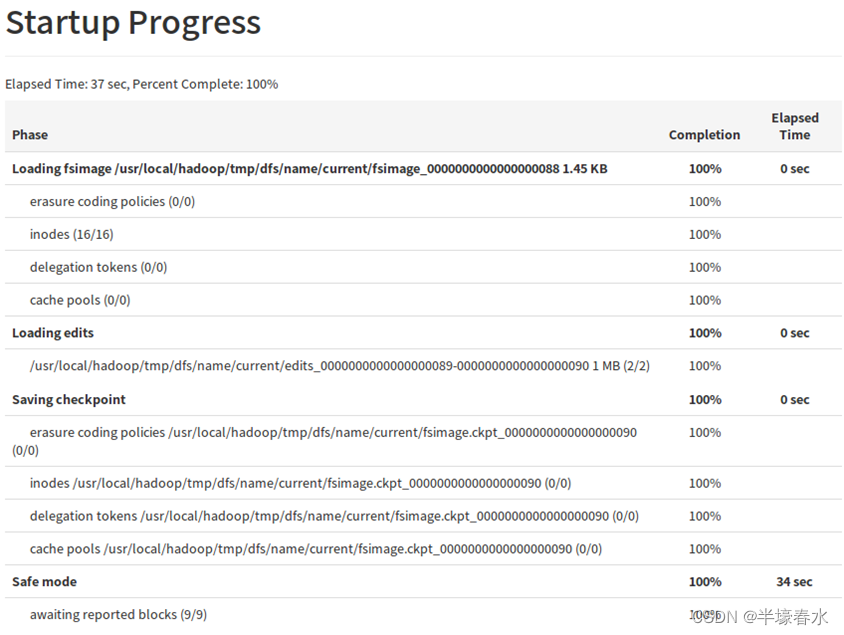
Startup Progress集群启动时加载的fsimage和edits
启动时加载的fsimagefsimage_0000000000000012857
启动时加载的editsedits_0000000000000012858-0000000000000012864
10.Browse the file system
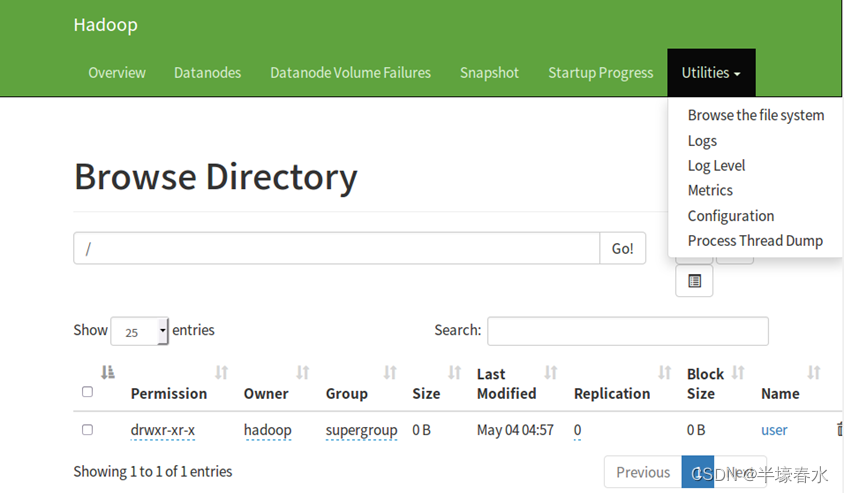
集群DFS存储系统的可视化浏览
11.Directory:/logs/
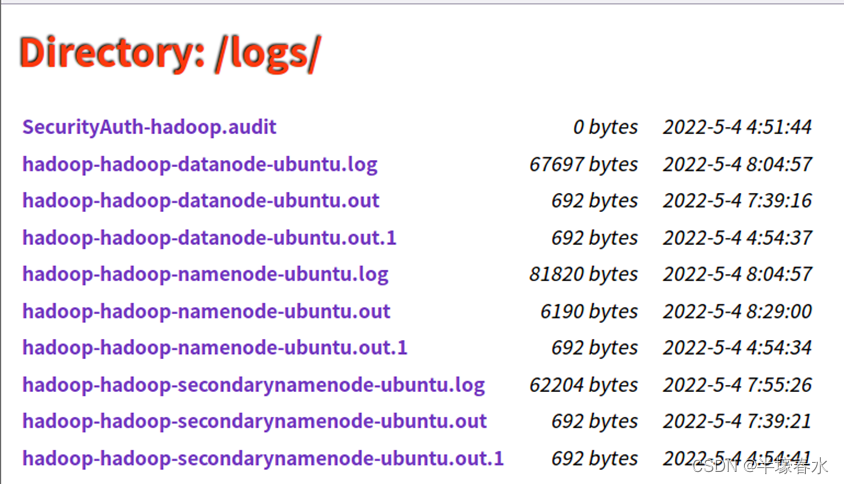
集群组件 NameNode、DataNode、Balance 、Journalnode、Secondarynamenode、Historyserver、Nodemanager、Resourcemanager等组件的日志
三完成
eclipse的安装在eclipse中创建项目配置所需要的jar包编写一个可以和HDFS相交互的Java应用程序1.在
Ubuntu中安装Eclipse
Eclipse是常用的程序开发工具本教程很多程序代码都是使用Eclipse开发调试因此需要在Linux系统中安装Eclipse。是eclipse-4.7.0-linux.gtk.x86_64.tar.gz文件下载后保存在了Linux系统的目录“/home/hadoop/桌面/”下.
①下面执行如下命令对文件进行解压缩
②执行如下命令启动Eclipse就可以看到Eclipse的启动界面。
2使用Eclipse开发调试HDFS Java程序
Hadoop采用Java语言开发的提供了Java API与HDFS进行交互。以上介绍的Shell命令在执行时实际上会被系统转换成Java API调用。
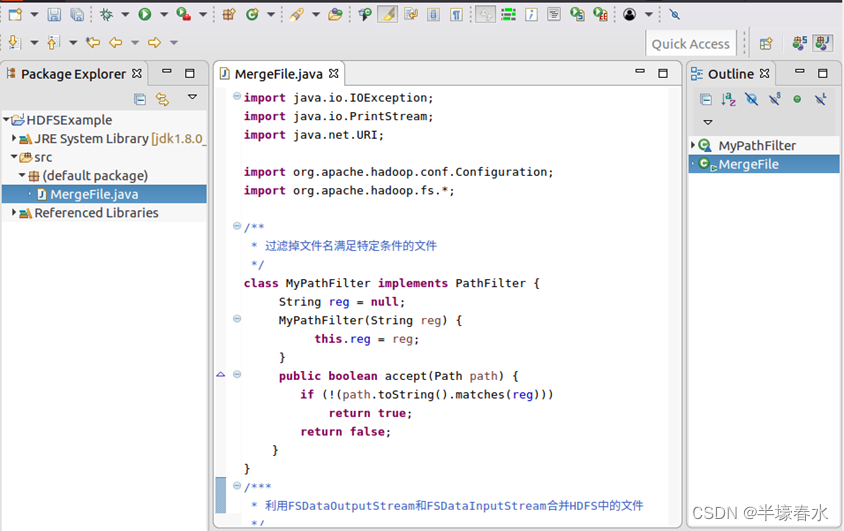
现在要执行的任务是假设在目录“hdfs://localhost:9000/user/hadoop”下面有几个文件分别是file1.txt、file2.txt、file3.txt、file4.abc和file5.abc这里需要从该目录中过滤出所有后缀名不为“.abc”的文件对过滤之后的文件进行读取并将这些文件的内容合并到文件“hdfs://localhost:9000/user/hadoop/merge.txt”中。
1.在Eclipse中创建项目
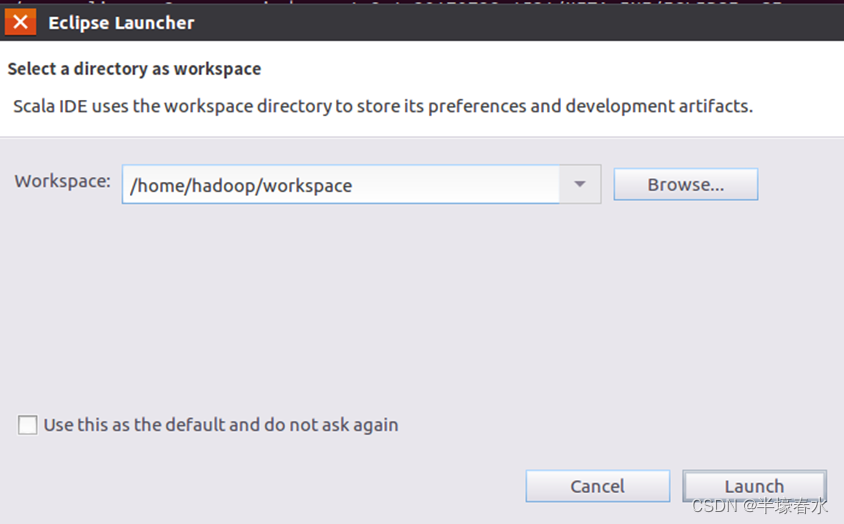
①启动Eclipse。当Eclipse启动以后会弹出如下图所示界面提示设置工作空间workspace。
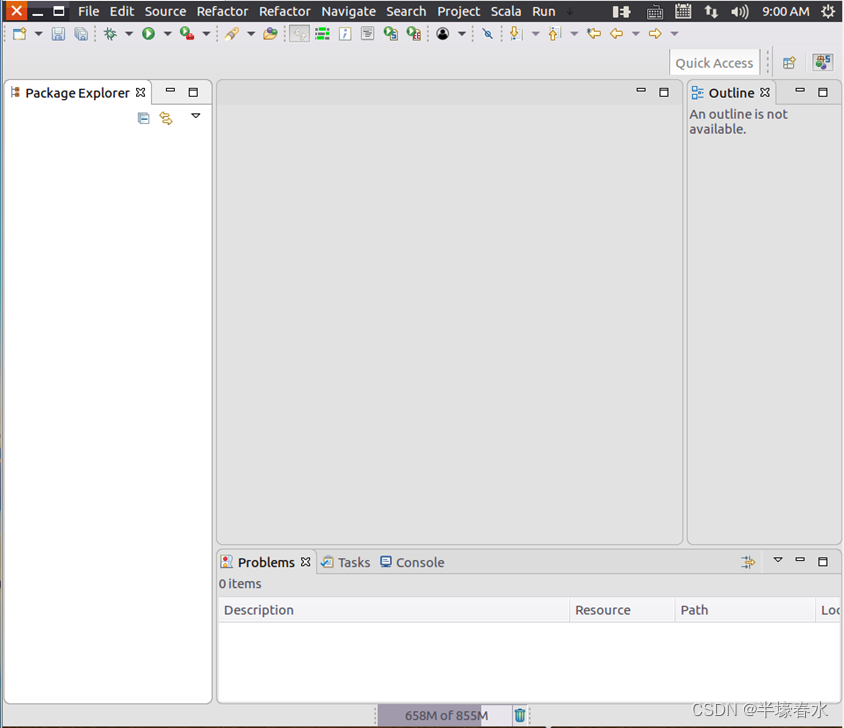
可以直接采用默认的设置“/home/hadoop/workspace”点击“OK”按钮。可以看出由于当前是采用hadoop用户登录了Linux系统因此默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。Eclipse启动以后会呈现如下图所示的界面。
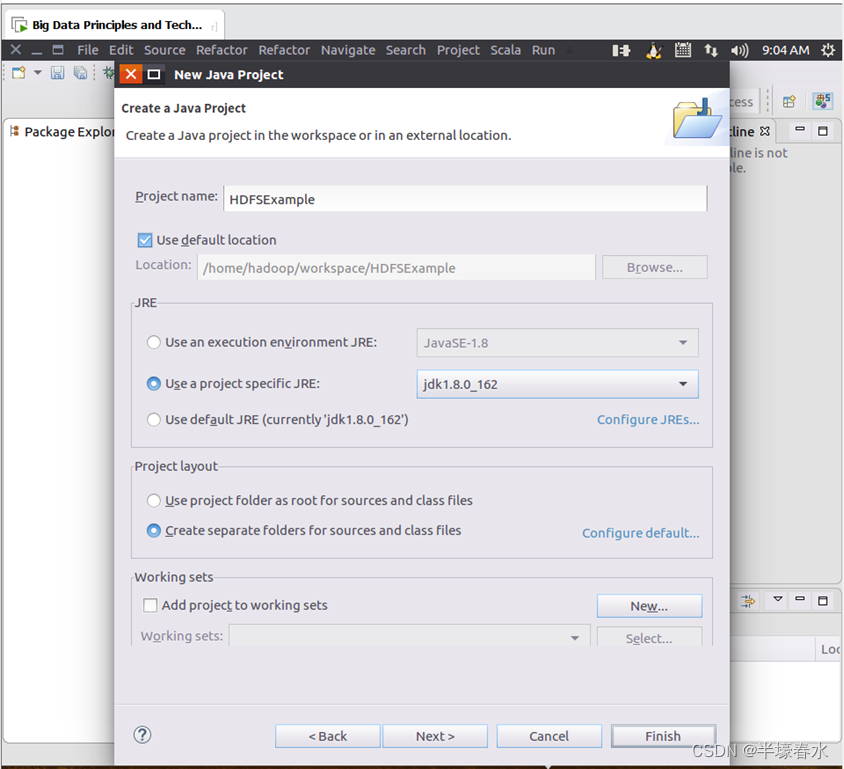
②选择“File–>New–>Java Project”菜单开始创建一个Java工程会弹出如下图所示界面。 在“Project name”后面输入工程名称“HDFSExample”选中“Use default location”让这个Java工程的所有文件都保存到“/home/hadoop/workspace/HDFSExample”目录下。在“JRE”这个选项卡中可以选择当前的Linux系统中已经安装好的JDK比如jdk1.8.0_162。然后点击界面底部的“Next>”按钮进入下一步的设置。
2. 为项目添加需要用到的
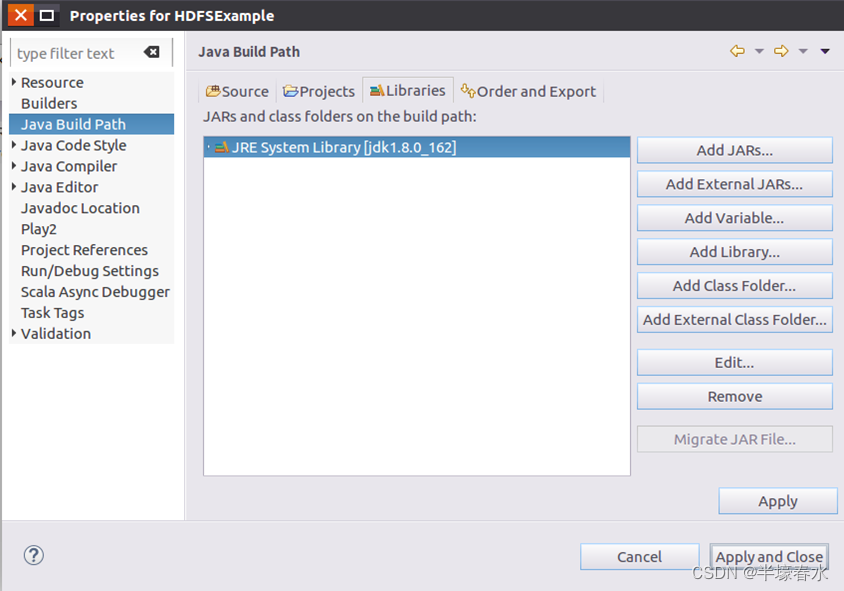
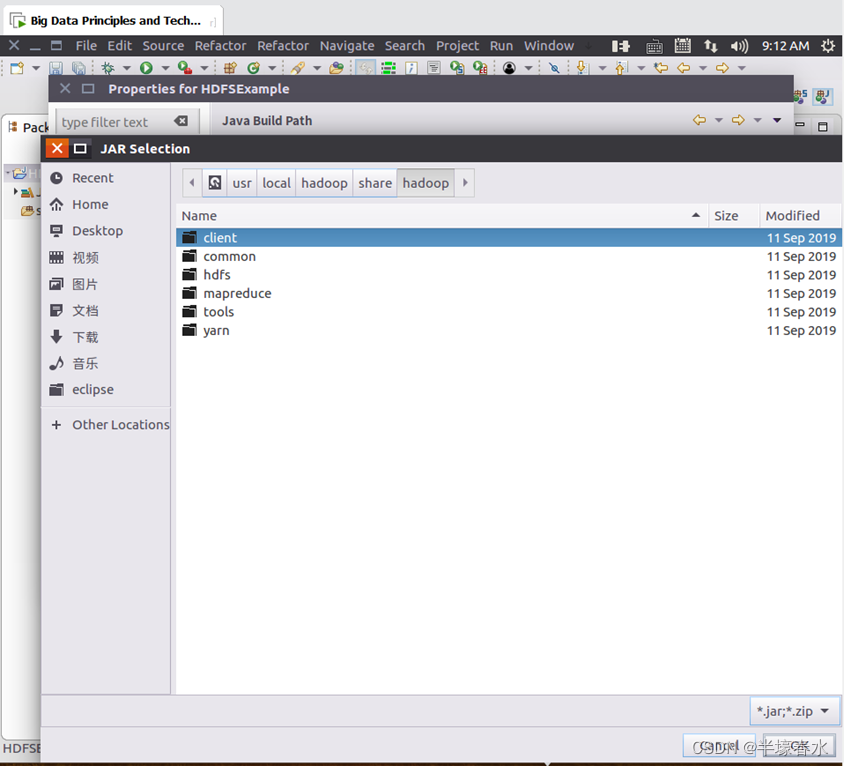
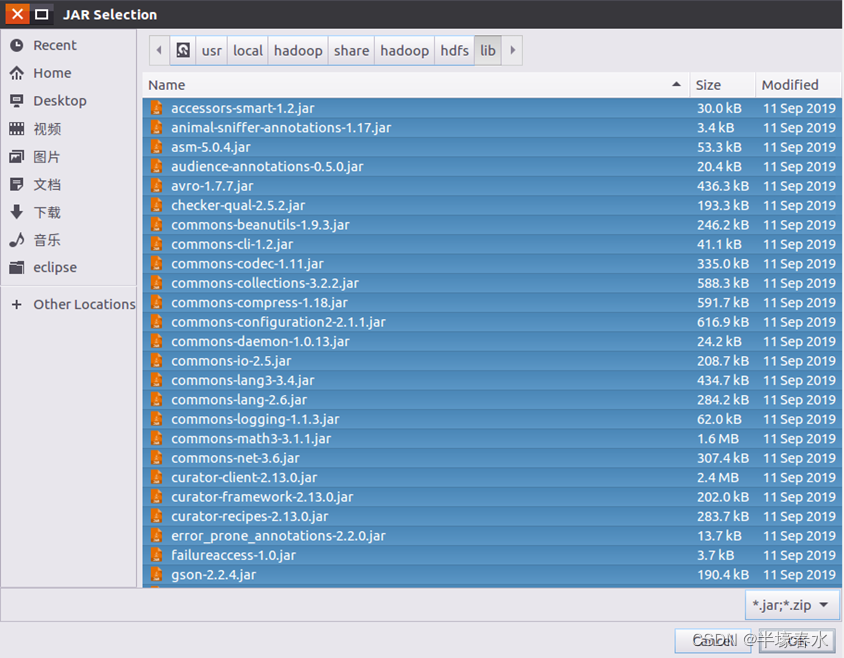
JAR包①进入下一步的设置以后会弹出如下图所示界面。
需要在这个界面中加载该Java工程所需要用到的JAR包这些JAR包中包含了可以访问HDFS的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下对于本教程而言就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡然后点击界面右侧的“Add External JARs…”按钮会弹出如下图所示界面。②需要在这个界面中加载该
Java工程所需要用到的JAR包这些JAR包中包含了可以访问HDFS的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡然后点击界面右侧的“Add External JARs…”按钮会弹出如下图所示界面。
③在该界面中上面的一排目录按钮即“usr”、“local”、“hadoop”、“share”、“hadoop”和“common”当点击某个目录按钮时就会在下面列出该目录的内容。
为了编写一个能够与HDFS交互的Java应用程序一般需要向Java工程中添加以下JAR包
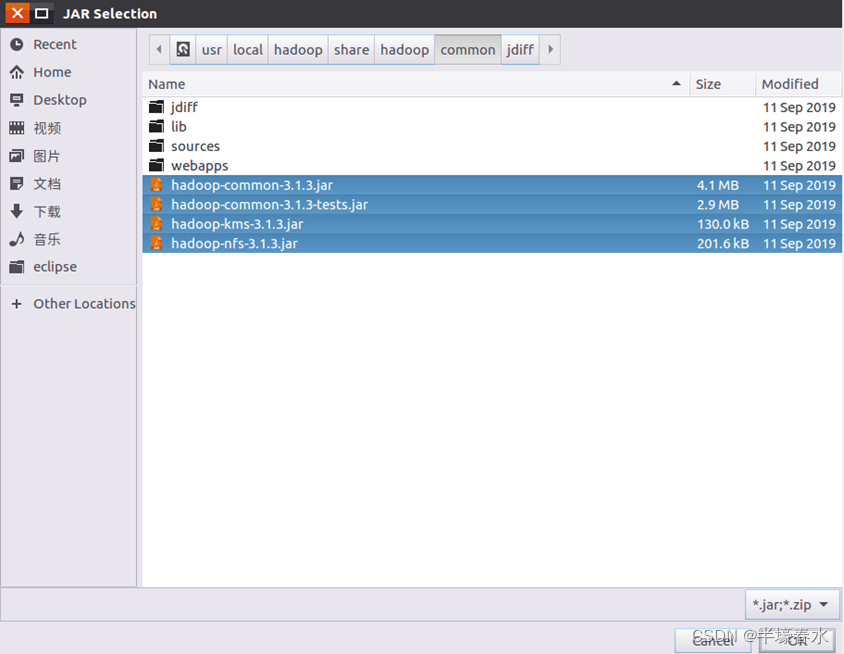
a.“/usr/local/hadoop/share/hadoop/common”目录下的所有JAR包包括hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar和haoop-kms-3.1.3.jar注意不包括目录jdiff、lib、sources和webapps
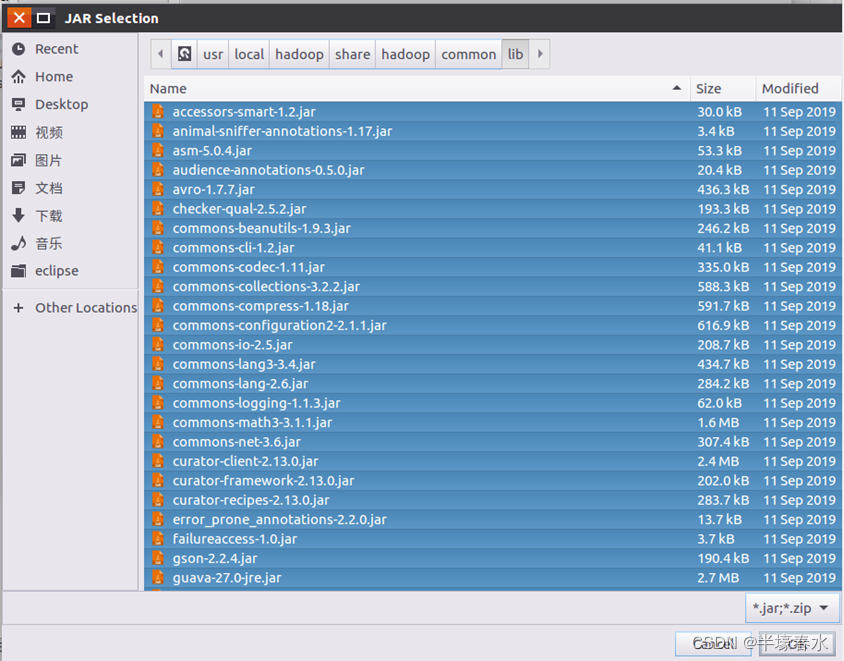
b. “/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包
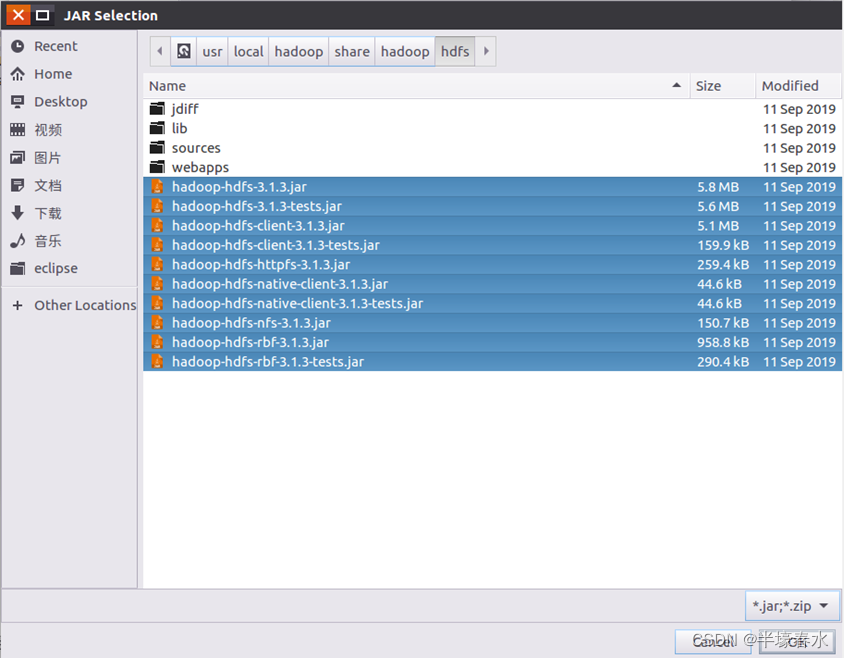
c.“/usr/local/hadoop/share/hadoop/hdfs”目录下的所有JAR包注意不包括目录jdiff、lib、sources和webapps
d.“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
全部添加完毕以后就可以点击界面右下角的“Apply and close”按钮完成Java工程HDFSExample的创建。3. 编写
Java应用程序①编写一个
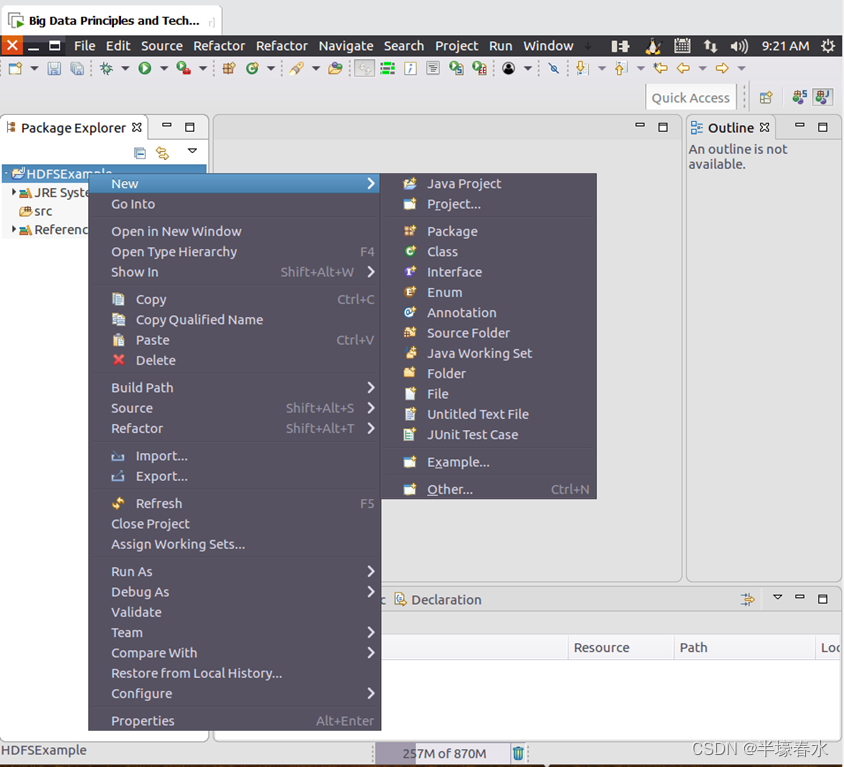
Java应用程序在Eclipse工作界面左侧的“Package Explorer”面板中如下图所示找到刚才创建好的工程名称“HDFSExample”然后在该工程名称上点击鼠标右键在弹出的菜单中选择“New–>Class”菜单。
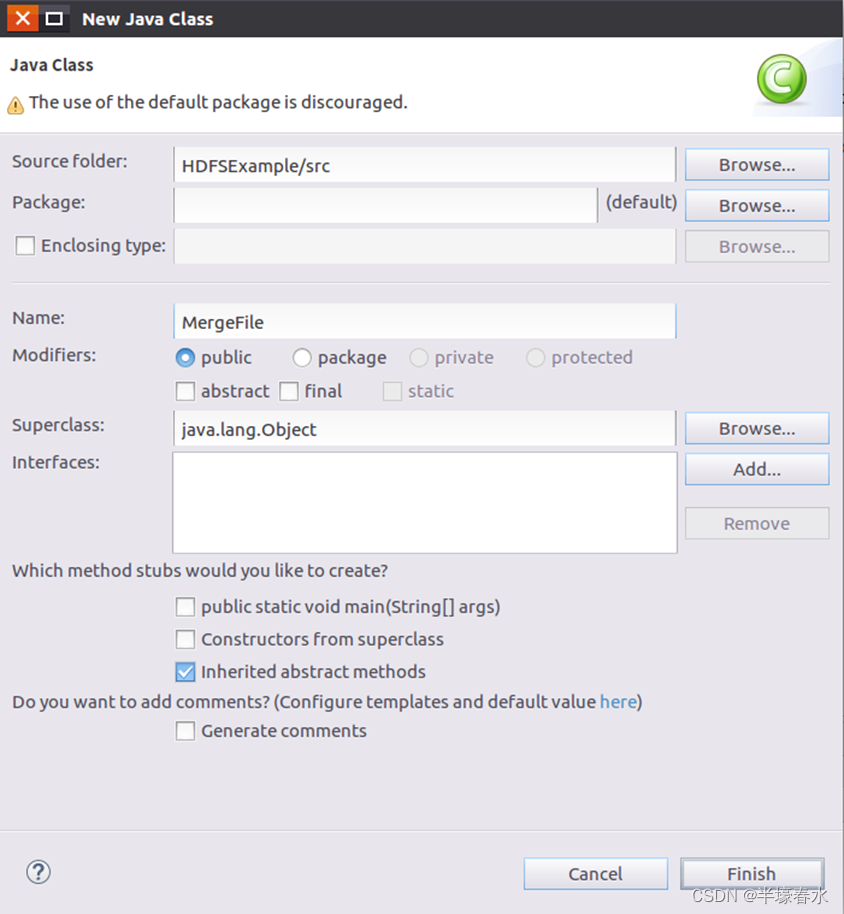
②选择“New–>Class”菜单以后会出现如下图所示界面。在该界面中只需要在“Name”后面输入新建的Java类文件的名称这里采用名称“MergeFile”其他都可以采用默认设置。
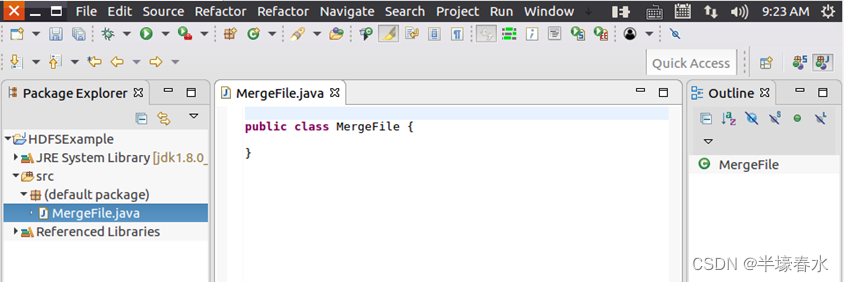
③然后点击界面右下角“Finish”按钮出现如下图所示界面。可以看出Eclipse自动创建了一个名为“MergeFile.java”的源代码文件。
④随后在该文件中输入代码。
4. 编译运行程序
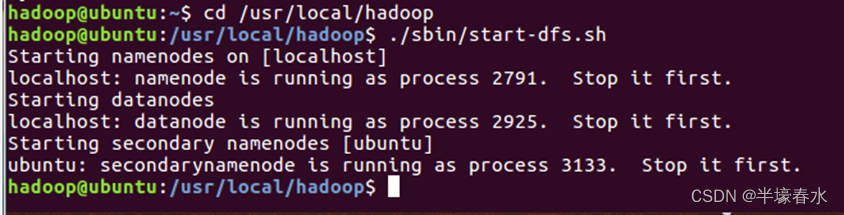
①在开始编译运行程序之前请一定确保
Hadoop已经启动运行如果还没有启动需要打开一个Linux终端输入以下命令启动Hadoop
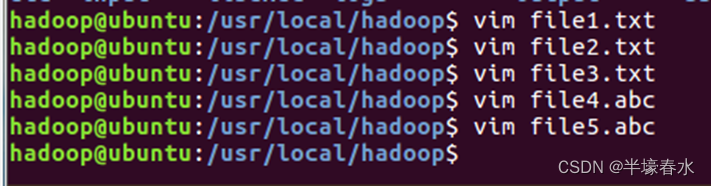
②然后要确保HDFS的“/user/hadoop”目录下已经存在file1.txt、file2.txt、file3.txt、file4.abc和file5.abc每个文件里面有内容。这里假设文件内容如下
file1.txt的内容是this is file1.txt
file2.txt的内容是this is file2.txt
file3.txt的内容是this is file3.txt
file4.abc的内容是this is file4.abc
file5.abc的内容是this is file5.abc
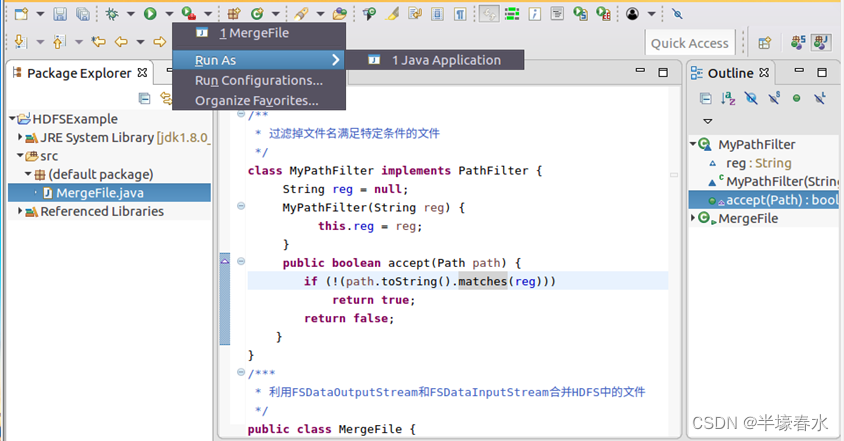
③现在就可以编译运行上面编写的代码。可以直接点击Eclipse工作界面上部的运行程序的快捷按钮当把鼠标移动到该按钮上时在弹出的菜单中选择“Run As”继续在弹出来的菜单中选择“Java Application”如下图所示。
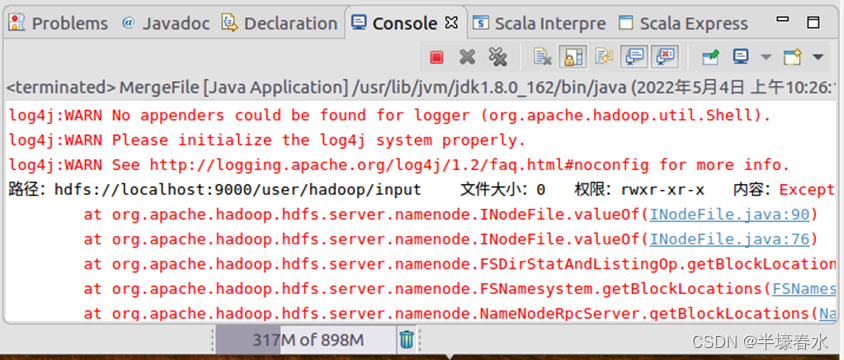
④在该界面中点击界面右下角的“OK”按钮开始运行程序。程序运行结束后会在底部的“Console”面板中显示运行结果信息如下图所示。同时“Console”面板中还会显示一些类似“log4j:WARN…”的警告信息可以不用理会。
⑤如果程序运行成功这时可以到HDFS中查看生成的merge.txt文件比如可以在Linux终端中执行如下命令。
四生成
jar包部署相关的应用程序①首先在
Hadoop安装目录下新建一个名称为myapp的目录用来存放我们自己编写的Hadoop应用程序可以在Linux的终端中执行如下命令。
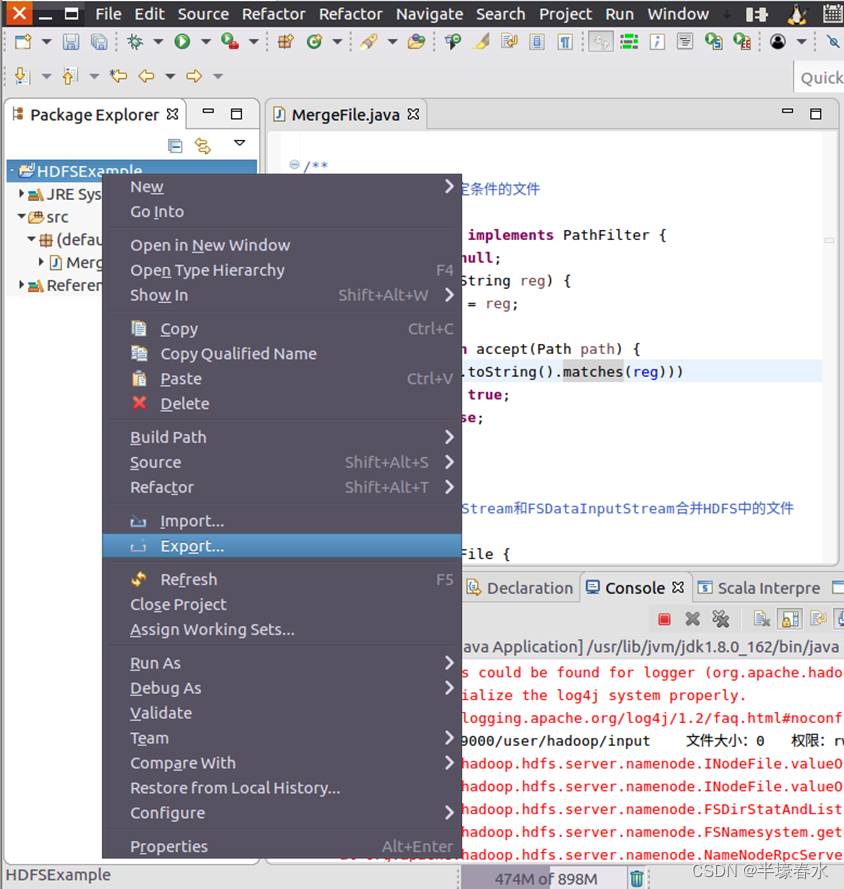
②然后请在Eclipse工作界面左侧的“Package Explorer”面板中在工程名称“HDFSExample”上点击鼠标右键在弹出的菜单中选择“Export”如下图所示。
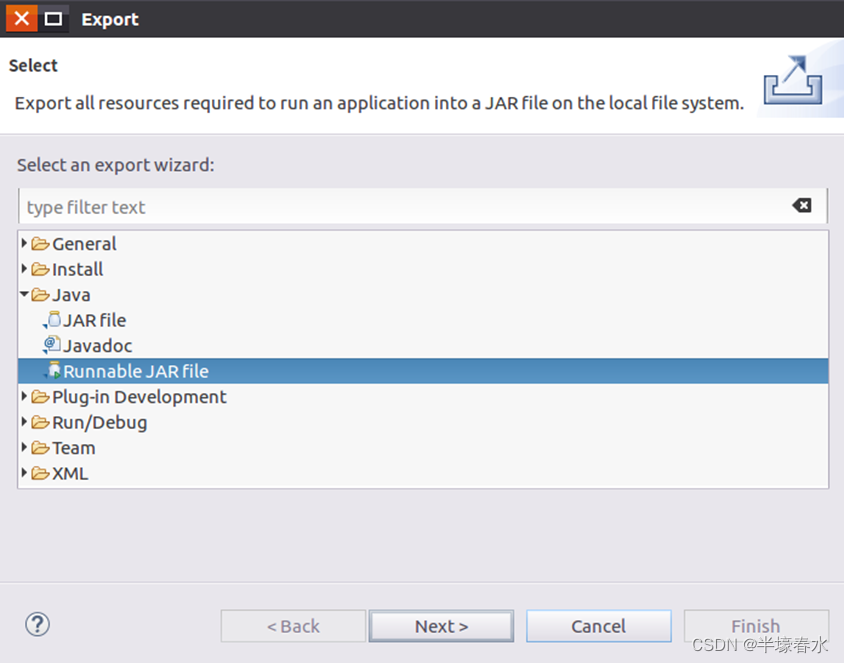
③然后会弹出如下图所示界面。在该界面中选择“Runnable JAR file”。
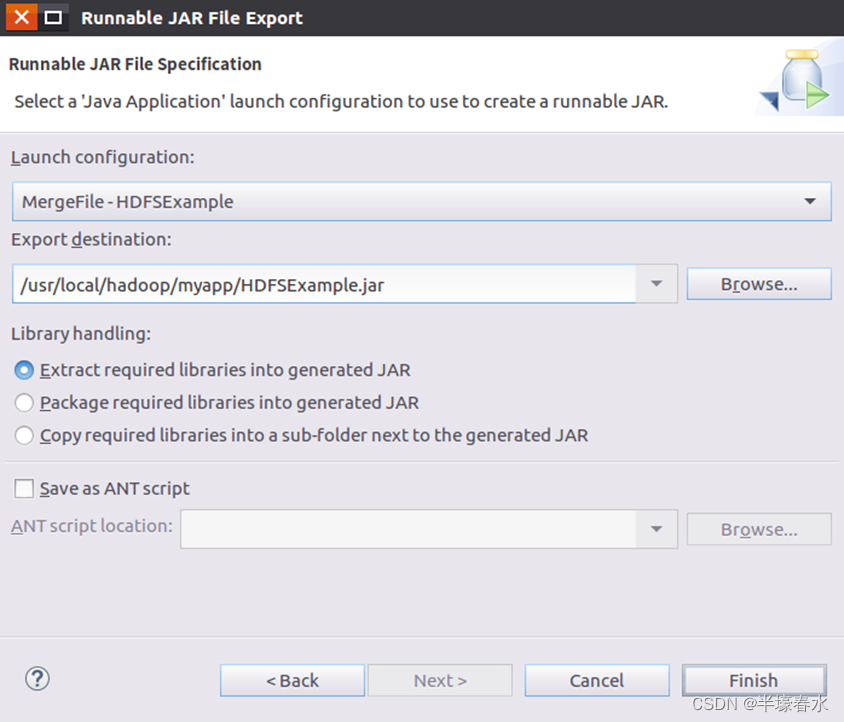
④然后点击“Next>”按钮弹出如下图所示界面。在该界面中“Launch configuration”用于设置生成的JAR包被部署启动时运行的主类需要在下拉列表中选择刚才配置的类“MergeFile-HDFSExample”。在“Export destination”中需要设置JAR包要输出保存到哪个目录比如这里设置为“/usr/local/hadoop/myapp/HDFSExample.jar”。在“Library handling”下面选择“Extract required libraries into generated JAR”。
⑤然后点击“Finish”按钮会出现如下图所示界面。可以忽略该界面的信息直接点击界面右下角的“OK”按钮启动打包过程。
⑥打包过程结束后会出现一个警告信息界面如下图所示。可以忽略该界面的信息直接点击界面右下角的“OK”按钮。
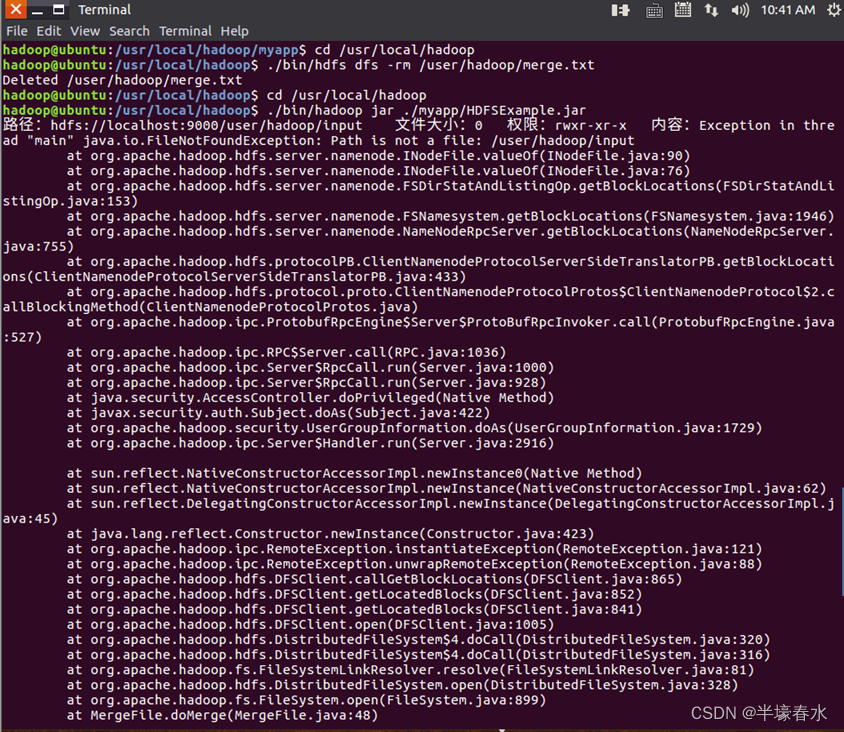
⑦至此已经顺利把HDFSExample工程打包生成了HDFSExample.jar。可以到Linux系统中查看一下生成的HDFSExample.jar文件可以在Linux的终端中执行如下命令。可以看到“/usr/local/hadoop/myapp”目录下已经存在一个HDFSExample.jar文件。
⑧由于之前已经运行过一次程序已经生成了merge.txt因此需要首先执行如下命令删除该文件。
⑨现在就可以在Linux系统中使用hadoop jar命令运行程序命令如下。
⑩上面程序执行结束以后可以到
HDFS中查看生成的merge.txt文件比如可以在Linux终端中执行如下命令。
五思考题
1.
Hadoop中HDFS包含哪些命令这些命令各自代表什么意思①帮助命令
hdfs dfs -help
②查看命令





# -h 以更友好的方式列出主要针对文件大小显示成相应单位K、M、G等
# -r 递归列出,类似于linux中的tree命令
hdfs dfs -ls [-h] [-r] <path>
查看文件内容
hdfs dfs -cat <hdfsfile>
查看文件末尾的1KB数据hdfs dfs -tail [-f] <hdfsfile>③创建命令
新建目录hdfs dfs -mkdir <path>
创建多级目录hdfs dfs -mkdir -p <path>
新建一个空文件hdfs dfs -touchz <filename>
上传本地文件到hdfs hdfs dfs -put [-f] <local src> ... <hdfs dst>
④删除命令
删除文件或目录
# -r 递归删除目录下的所有文件
# -f为直接删除不予提示
# -skipTrash为彻底放入文件不放入回收站
hdfs dfs -rm [-r] [-f] [-skipTrash] <hdfs path>
⑤获取命令将
hdfs文件下载到本地hdfs dfs -get < hdfs path> < localpath>
将hdfs文件合并起来下载到本地hdfs hdfs -getmerge [-nl] <hdfs path> <localdst>
⑥其他hdfs文件操作命令
拷贝hdfs dfs -cp [-r] < hdfs path > < hdfs path1 >
移动hdfs dfs -mv < hdfs path > < hdfs path1 >
统计目录下的对象数hdfs dfs -count < hdfs path >
统计目录下的对象大小hdfs dfs -du [-s] [-h] < hdfs path >
修改hdfs文件权限
修改所属组[-chgrp [-R] GROUP PATH...]
修改权限模式[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
修改所需组和所有者[-chown [-R] [OWNER][:[GROUP]] PATH...]
⑦
hdfs管理命令
显示帮助hdfs dfsadmin -help
查看文件系统健康状态hdfs dfsadmin -report
安全模式管理
a. 查看安全模式状态hdfs dfsadmin -safemode get
b. 强制进入安全模式hdfs dfsadmin -safemode enter
c. 强制离开安全模式hdfs dfsadmin -safemode leave2.
Hadoop创建的应用程序需要导入哪些安装包这些安装包里面有什么功能需要导入的安装包
①“/usr/local/hadoop/share/hadoop/common”目录下的所有JAR包包括hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar和haoop-kms-3.1.3.jar。
②“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包
③“/usr/local/hadoop/share/hadoop/hdfs”目录下的所有JAR包注意不包括目录jdiff、lib、sources和webapps
④“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。安装包的功能
a.用于发布和使用类库
b.作为应用程序和扩展的构建单元
c.作为组件、applet或者插件程序的部署单位
d.用于打包与组件相关联的辅助资源
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |