

C++前缀树 字典树 TrieTree的学习与模拟实现
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
前言
哥们在去年12月的一次实习面试的时候远在旧金山的一家美企CTO面试我岗位在西安只招一个C++实习生然后和以往面试不同的是他偏向问算法多一些:这几道题;
像我这种不爱刷算法的人来说每题他都给了点提示才解答出来最终给了我下面这个图让我实现一下:
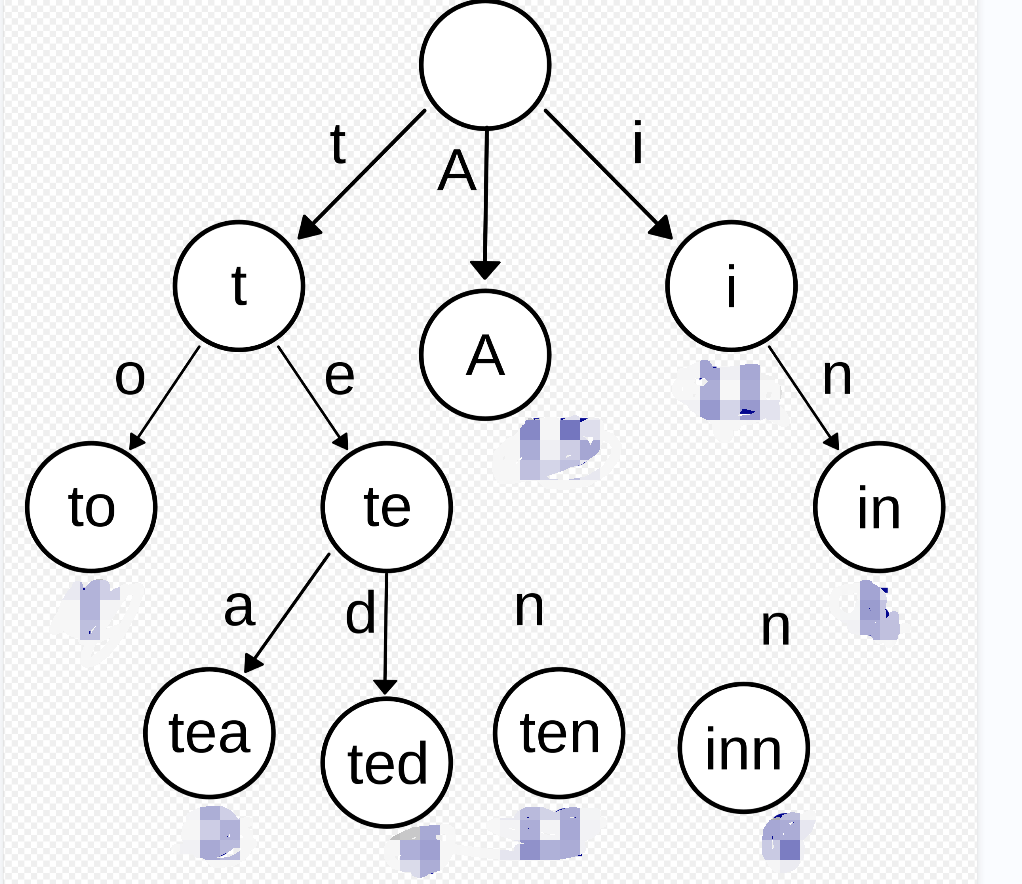
其实就是经典的前缀树我这个笨比由于之前没怎么见过也没写过写了半天没写出来最后让我下去写我大概查了下大致框架不就是个数组存多条链表的头嘛其实也就是链表封装了一下。10分钟写了个大概交了之后的二面只能去线下那会疫情我就放弃了现在想想有点后悔毕竟是外企955呢;
前缀树介绍
- 在计算机科学中trie又称前缀树或字典树是一种有序树用于保存关联数组其中的键通常是字符串。常用与拼写检查自动补全等; 是一种查找结构
- 他的存储逻辑类似于哈希表但是它相对于哈希表来说限制更多通用性较差但是它的功能更加强大可定制性也更强。
leetcode指路实现Trie(前缀树)
如图可以查看trie树的基本结构
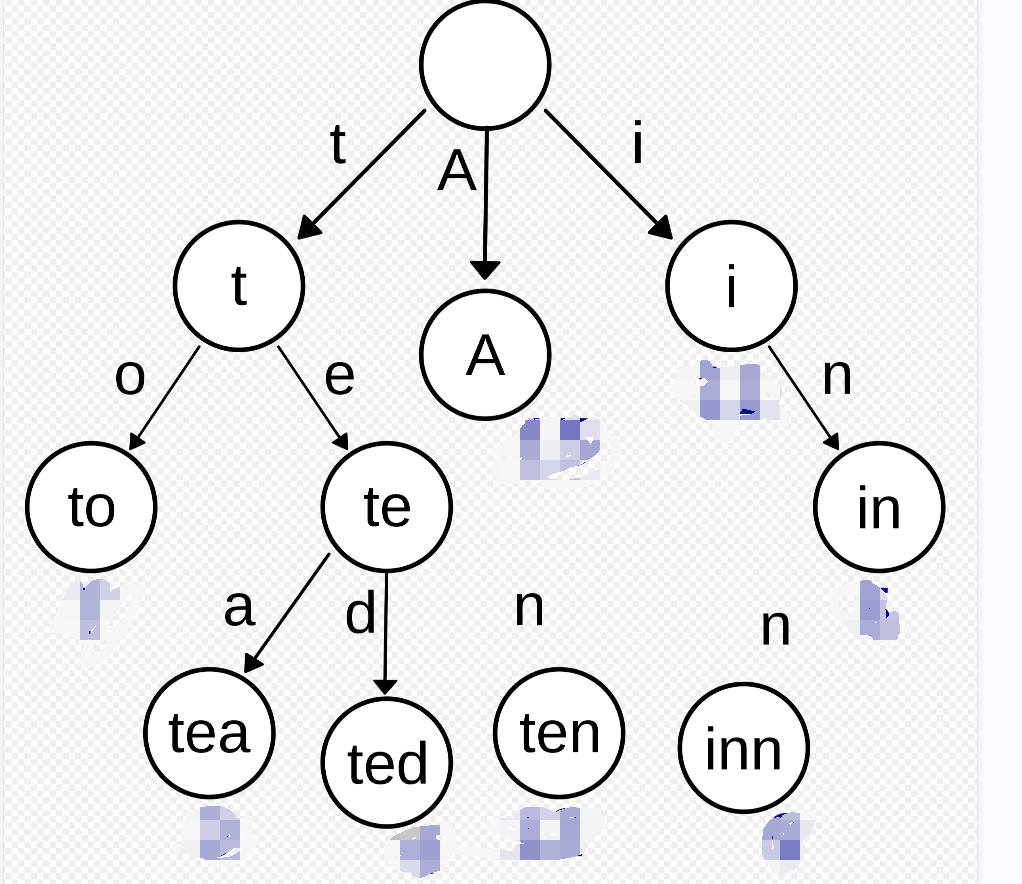
与二叉查找树不同键不是直接保存在节点中而是由节点在树中的位置决定。(这个是前缀树的精髓也是难理解的地方他不用存储某个节点的实际字符他的对应下标映射出了需要存储的字符)
一个节点的所有子孙都有相同的前缀也就是这个节点对应的字符串而根节点对应空字符串。
一般情况下不是所有的节点都有对应的值他们只是前缀只有叶子节点和部分内部节点所对应的键才有相关的值。
C++实现
核心思想
其实这个前缀树的实现没有想象中的复杂觉得难的应该跟我当时一样是第一次看到
仔细想想
单链表:通过Node中封装的Node* next来找下一个连着的节点;
二叉树:通过Node中封装的Node* left 和 Node* right来找左右孩子节点;
前缀树
因为维护了26个可能的Node*节点所以跟上面一个道理只是不能枚举出来了用了一个Node*arr[26]来维护恰巧把这个数组的下标设计成了某个字符的种类就可以达到利用逻辑下标存储一个实际字符的作用了
前缀树插入示意图
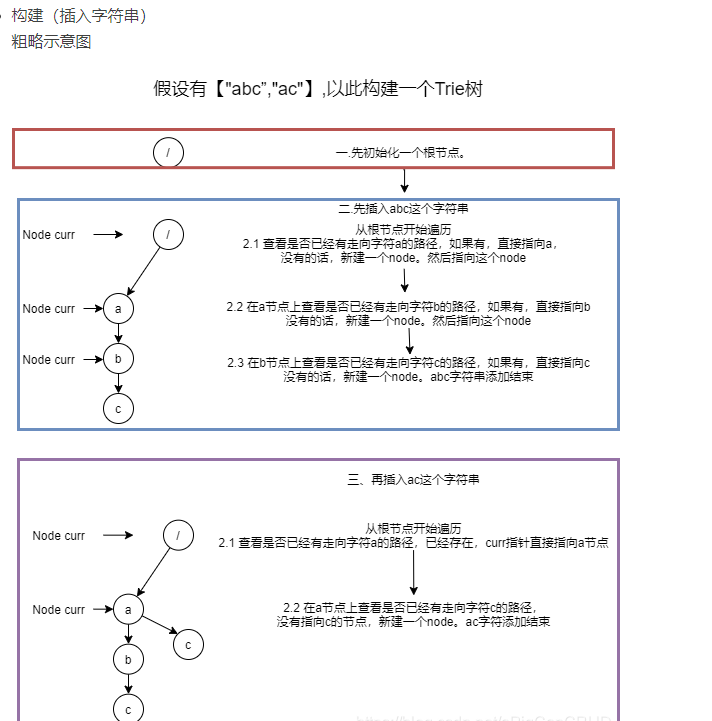
上图中每经过一个节点将该节点的pass值加一将末尾节点的end值加一。通过这种操作记录所有经过的数据记录
前缀树的插入是灵魂所在搞懂了之后结构就明白了不管是查找还是删除无非就是类似对链表的相关操作;
前缀树的大致框架
假设只存小写字符:
#include <iostream>
#include <vector>
#include <string>
using namespace std;
//26 个小写英文字母
#define NUM 26
class Trie{
private:
Trie* arr[NUM];//多叉树(最大26个分支因为26个小写字母嘛)
int end; //代表word完整单词的个数0就是无此单词只是一个前缀;insert一个单词的时候这个单词的end首次出现就置为1;之后重复插入就end++;
int pass; //代表以此前缀为公共前缀的节点个数,每次insert的时候会调整;
public:
Trie() {
memset(arr,0,sizeof(arr));//每个新节点的映射数组内容置nullptr
end = 0;
ncount = 0; //初始化时以该映射信息字符为前缀的个数为1(这个字符本身算的1)
}
//插入单词
void Insert(string &x)
{
}
//查找 完全匹配字符串x 的数量
int Find(string &x)
{
}
//查找 前缀为字符串x 的数量
int FindContain(string& x)
{
}
//删除某个单词(前缀)
bool Erase(string &x)
{
}
~Trie()
{
//因为new了26个连续的tire*空间不要某个节点不要把它对应给下层准备的26个空间也delete掉 防止内存泄漏
for (int i = 0; i < NUMBER; i++)
{
if (nexts[i]){
delete nexts[i];
}
}
}
};
- 二叉树父节点之下包含两个节点分别为左右子节点分别开辟空间进行数据存储。
- 前缀树的结构也是类似的它的每个节点包含两个部分: 值部分和指针部分。
- 它的存储方式为在一棵树上从根到子节点分别存储所有目标数据的每一个下标位置上的数据
- 值部分主要又包含两个数据: 路过该节点的数量为
pass以该节点为结尾的数量为end。- 指针部分主要包含它的所有子节点比如26个小写字母记为
arr
下面的实现给出了四个接口:
Insert插入字符串给前缀树添加一组数据
其中
Insert方法需要注意插入新单词的过程中路径所有前缀的个数pass+1
Find查找已存入的完整匹配的字符串个数FindContain查找已存入的前缀匹配的字符串个数Erase从前缀树中擦除一个完整字符串
Erase方法需要注意的是
- 需Find先检查字符串是否存在
pass == 1时代表其下没有任何可能存在的字符子串所以直接将这个节点delete删除即可- pass不为1且存在这个字符串我们把end有效字符串个数-1就行
- 移除节点时需要提前写好析构函数将其节点开辟的26个Node*内存全部释放以免出现内存泄漏;
前缀树插入字符串
另外下面的功能代码不过多解释代码注释自行理解核心要点就是用数组下表映射的方式确定前往哪一条链表之后的寻找和插入等操作都有点像链表的操作搞个cur指针向后遍历等;
//插入单词
void Insert(const string &x)
{
int size = x.size();
Node* cur = root;
cur->pass++;//不管insert啥我们root空节点的pass相当于必须+1最终这个root->pass可以代表一共insert了几次=-=
for (int i = 0; i<size; i++) {
char index = x[i] - 'a';
//该字符在当前分支下的映射为空没有那就new
if (cur->arr[index] == nullptr) {
cur->arr[index] = new Node;
}
cur->arr[index]->pass++; //不管 cur->arr[index] 是new的还是本来就有insert要路过他了他的pass+1,
cur = cur->arr[index];//同时cur下指过去进行下一个字符的insert
}
cur->end++;//insert最终将完整字符串个数end+1
}
前缀树查找完整的字符串
//查找 完全匹配字符串 x 的数量 -->end
int Find(const string &x)
{
int size = x.size();
Node* cur = root;
for (int i = 0; i < size; i++) {
char index = x[i] - 'a';
//搜索到某个字符断了没有这个完整的字符串x 返回0
if (cur->arr[index] == nullptr) return 0;
//没断继续向下一个字符搜索;
cur = cur->arr[index];
}
return cur -> end;//返回完整字符串x的有效个数end
}
前缀树查找前缀匹配的字符串
//查找 前缀为字符串 x 的数量 -->pass
int FindContain(const string& x)
{
//与Find一模一样的逻辑只是最后的return 变了这体现了Node*封装 int end 和int pass的好处了吧
int size = x.size();
Node* cur = root;
for (int i = 0; i < size; i++) {
char index = x[i] - 'a';
if (cur->arr[index] == nullptr) return 0;
cur = cur->arr[index];
}
return cur -> pass;
}
前缀树删除完整字符串
//删掉某个完整单词-以及这个单词后面可能存在的所有路径;end>1 出现了很多次时只需要end--一下
bool Delete(const string &x)
{
if (Find(x) == 0) return false;//压根没这个单词删除失败;
//有这个单词我们需要找到他的prev前一个delete掉他,prev的arr[x]=nullptr!
Node* cur = root;
Node* prev = root;
int size = x.size();
for (int i = 0; i < size; i++) {
char index = x[i]-'a';
//if (cur->arr[index] == nullptr) return false;这句不需要都过了Find 肯定x每个字符都存在于字典树中
cur->pass--;//别忘了路过的路径都得-1;
prev = cur;
cur = cur->arr[index];
}
if (cur->end==1) {//代表x所在字符串的个数只有1直接递归delete删掉它 和 他后面的子串
delete cur;//这个delete调析构我们析构已经写好了防止内存泄漏;
prev->arr[x[size - 1]-'a'] = nullptr; // prev的arr[x最后一个字符-'a'] = nullptr!
}
else cur->end--;//end>1 :end--代表这个节点的有效字符串个数-1end==1 end-- == 0这个节点的字符有效个数为0了但是他因为pass>1,暂时保存 后面的不删;
//end>1,那就end有效个数-1就行了;
return true;
}
总结
- 这个字典树的树结构可以根据需求来进行多样式的处理比如我为了实现设计的功能每个节点都保存了pass和end俩int方便功能记录和函数内的使用;
- 字典树本质上是牺牲空间换查找同前缀的字符串提升时间效率的一种措施但是我们这种每个节点都开26个数组的方式是非常浪费空间的比如只有一个有效字符下标其他25个nullptr都浪费了而且在大量相同的前缀下就是单链表浪费更严重。
- 这时候我们可以把Node*arr[26]数组换成map<char,Node*>这样搞(每层某一个char只会出现一次所以char做key没问题)需要配对啥就insert给红黑树中添加啥,大大节省空间;
所以说这个树没有啥固定玩法可塑性太强了…这可能也是不刷题的我不常见的愿因
完整代码
#include <iostream>
#include <vector>
#include <string>
using namespace std;
//26 个小写英文字母
#define NUM 26
//前缀树节点
class Node {
public:
Node* arr[NUM];//多叉树(最大26个分支因为26个小写字母嘛)
int end; //代表
int pass; //代表以此前缀为公共前缀的节点个数,每次insert的时候会调整
Node()
{
end = 0;
pass = 0;
memset(arr, 0, sizeof(arr));
}
~Node()
{
//这里有点递归的意思除了删除当前节点更重要的是如果当前节点的子节点还有非空。递归delete掉
for (int i = 0; i < NUM; i++)
{
if (arr[i]!=nullptr) delete arr[i];
}
}
};
//前缀树主体
class Trie{
public:
Node* root = nullptr;
public:
Trie() {
root = new Node;
}
//插入单词
void Insert(const string &x)
{
int size = x.size();
Node* cur = root;
cur->pass++;//不管insert啥我们root空节点的pass相当于必须+1最终这个root->pass可以代表一共insert了几次=-=
for (int i = 0; i<size; i++) {
char index = x[i] - 'a';
//该字符在当前分支下的映射为空没有那就new
if (cur->arr[index] == nullptr) {
cur->arr[index] = new Node;
}
cur->arr[index]->pass++; //不管 cur->arr[index] 是new的还是本来就有insert要路过他了他的pass+1,
cur = cur->arr[index];//同时cur下指过去进行下一个字符的insert
}
cur->end++;//insert最终将完整字符串个数end+1
}
//查找 完全匹配字符串 x 的数量 -->end
int Find(const string &x)
{
int size = x.size();
Node* cur = root;
for (int i = 0; i < size; i++) {
char index = x[i] - 'a';
//搜索到某个字符断了没有这个完整的字符串x 返回0
if (cur->arr[index] == nullptr) return 0;
//没断继续向下一个字符搜索;
cur = cur->arr[index];
}
return cur -> end;//返回完整字符串x的有效个数end
}
//查找 前缀为字符串 x 的数量 -->pass
int FindContain(const string& x)
{
//与Find一模一样的逻辑只是最后的return 变了这体现了Node*封装 int end 和int pass的好处了吧
int size = x.size();
Node* cur = root;
for (int i = 0; i < size; i++) {
char index = x[i] - 'a';
if (cur->arr[index] == nullptr) return 0;
cur = cur->arr[index];
}
return cur -> pass;
}
//删掉某个完整单词-以及这个单词后面可能存在的所有路径;end>1 出现了很多次时只需要end--一下
bool Delete(const string &x)
{
if (Find(x) == 0) return false;//压根没这个单词删除失败;
//有这个单词我们需要找到他的prev前一个delete掉他,prev的arr[x]=nullptr!
Node* cur = root;
Node* prev = root;
int size = x.size();
for (int i = 0; i < size; i++) {
char index = x[i]-'a';
//if (cur->arr[index] == nullptr) return false;这句不需要都过了Find 肯定x每个字符都存在于字典树中
cur->pass--;//别忘了路过的路径都得-1;
prev = cur;
cur = cur->arr[index];
}
if (cur->end==1) {//代表x所在字符串的个数只有1直接递归delete删掉它 和 他后面的子串
delete cur;//这个delete调析构我们析构已经写好了防止内存泄漏;
prev->arr[x[size - 1]-'a'] = nullptr; // prev的arr[x最后一个字符-'a'] = nullptr!
}
else cur->end--;//end>1 :end--代表这个节点的有效字符串个数-1end==1 end-- == 0这个节点的字符有效个数为0了但是他因为pass>1,暂时保存 后面的不删;
//end>1,那就end有效个数-1就行了;
return true;
}
};