

CLIP Surgery论文阅读-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
CLIP Surgery for Better Explainability with Enhancement in Open-Vocabulary TasksCVPR2023
M
=
norm
(
resize
(
reshape
(
F
i
ˉ
∥
F
i
‾
∥
2
⋅
(
F
t
∥
F
t
‾
∥
2
)
⊤
)
)
)
M=\operatorname{norm}\left(\operatorname{resize}\left(\operatorname{reshape}\left(\frac{\boldsymbol{F}_{\bar{i}}}{\left\|\boldsymbol{F}_{\underline{i}}\right\|_{2}} \cdot\left(\frac{\boldsymbol{F}_{t}}{\left\|\boldsymbol{F}_{\underline{t}}\right\|_{2}}\right)^{\top}\right)\right)\right)
M=norm
resize
reshape
Fi
2Fiˉ⋅(
Ft
2Ft)⊤
重点是CLIP的图可视化上面是CLIP Surgery可视化Similarity map的公式
贡献

1.发现CLIP可视化结果相似度图和人的感知是反的集中在背景flatten transformer做q可视化集中在前景
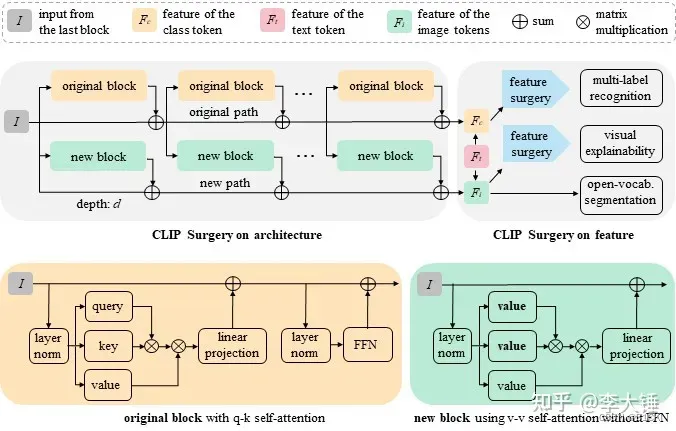
认为是QK self-attention导致最相似的token并不是本身或者相同语义区域而是一些背景的噪声。而用vv attention就不会出现错误的关联。出现这种情况的原因主要是训练的pooling不合适,提出了CLIP Architecture Surgery如模型图所示
x ^ i + 1 = { None i < d f attn ( x i , { ϕ v } ) + x i i = d , f attn n v ( x i , { ϕ v } ) + x ^ i i > d , ∀ T & A x i + 1 = { f F F N ( x i ′ ) + x i ′ , s.t. x i ′ = f a t t n q k ( x i , { ϕ q , ϕ k , ϕ v } ) + x i , ∀ T & A f res ( x i ) + x i , ∀ R e s \begin{array}{l} \hat{x}_{i+1}=\left\{\begin{array}{ll} \text { None } & i<d \\ f_{\text {attn }}\left(x_{i},\left\{\phi_{v}\right\}\right)+x_{i} & i=d, \\ f_{\text {attn } n_{v}}\left(x_{i},\left\{\phi_{v}\right\}\right)+\hat{x}_{i} & i>d \end{array}, \forall T \& A\right. \\ x_{i+1}=\left\{\begin{array}{ll} f_{F F N}\left(x_{i}^{\prime}\right)+x_{i}^{\prime}, \text { s.t. } & \\ x_{i}^{\prime}=f_{a t t n_{q k}}\left(x_{i},\left\{\phi_{q}, \phi_{k}, \phi_{v}\right\}\right)+x_{i} & , \forall T \& A \\ f_{\text {res }}\left(x_{i}\right)+x_{i} & , \forall R e s \end{array}\right. \\ \end{array} x^i+1=⎩ ⎨ ⎧ None fattn (xi,{ϕv})+xifattn nv(xi,{ϕv})+x^ii<di=d,i>d,∀T&Axi+1=⎩ ⎨ ⎧fFFN(xi′)+xi′, s.t. xi′=fattnqk(xi,{ϕq,ϕk,ϕv})+xifres (xi)+xi,∀T&A,∀Res
2.发现CLIP可视化有非常多的噪声响应
算取一个冗余特征多类的情况显著的类会影响其他的类带偏了。所以我们用类之间的分数作为权重对每个特征做类别的加权来抑制显著类的影响。然后在类别维度Nttext token的数量求均值作为冗余特征并对每个特征减去冗余特征然后求和得到余弦相似度。对于单个类来说如交互式分割和多模态可视化则用空文本特征作为冗余特征知乎上看到这句话才明白看的一脸懵逼。category dimension 是(Nt)
具体如下
- 先算出multiplied features[NiNtC] F m = F ^ i ∥ F ^ i ∥ 2 ⊙ F ^ t ∥ F ^ t ∥ 2 F_m=\frac{\hat{F}_i}{\|\hat{F}_i\|_2}\odot\frac{\hat{F}_t}{\|\hat{F}_t\|_2} Fm=∥F^i∥2F^i⊙∥F^t∥2F^t
沿C方向做逐元素乘法
- 再算similarity score[1Nt] s = s o f t m a x ( F c ∥ F c ∥ 2 ⋅ ( F t ∥ F t ∥ 2 ) ⊤ ⋅ τ ) s=softmax(\frac{F_c}{\|F_c\|_2}\cdot(\frac{F_t}{\|F_t\|_2})^\top\cdot\tau) s=softmax(∥Fc∥2Fc⋅(∥Ft∥2Ft)⊤⋅τ)
[CLS]乘token[NtC]算相似度
- 再算category weight[1Nt] w = s m e a n ( s ) w=\frac s{mean(s)} w=mean(s)s
- 再算冗余特征common and redundant features[Ni1C] F r = m e a n ( F m ⊙ e x p a n d ( w ) ) F_r=mean(F_m\odot expand(w))\mathrm{~} Fr=mean(Fm⊙expand(w))
沿C方向做空文本相似度最大的
- 最后算common and redundant features[NiNt] S = s u m ( F m − e x p a n d ( F r ) ) S=sum(F_m-expand(F_r))~ S=sum(Fm−expand(Fr)) 去掉冗余特征
模型
不参与训练只在推理
实验
错误的self-attention也能解释为什么有人删掉CLIP中ResNet的最后一个self-attention可以做可视化。但是ViT每层都是self-attention所以现有的方法在ViT上表现很差(全是self-attention删最后一层没用)
开放多标签分类
除此之外我们的算法做open-vocabulary的多标签分类也有效果可以作为一种后处理任意插到算法里面来提高mAP。原理是抑制冗余特征后会让误报少一些。注意单类没有效果因为冗余特征是一个common bias不改变单张图别之间的位次而是影响跨图之间的排位来减少误报

多模态可解释性
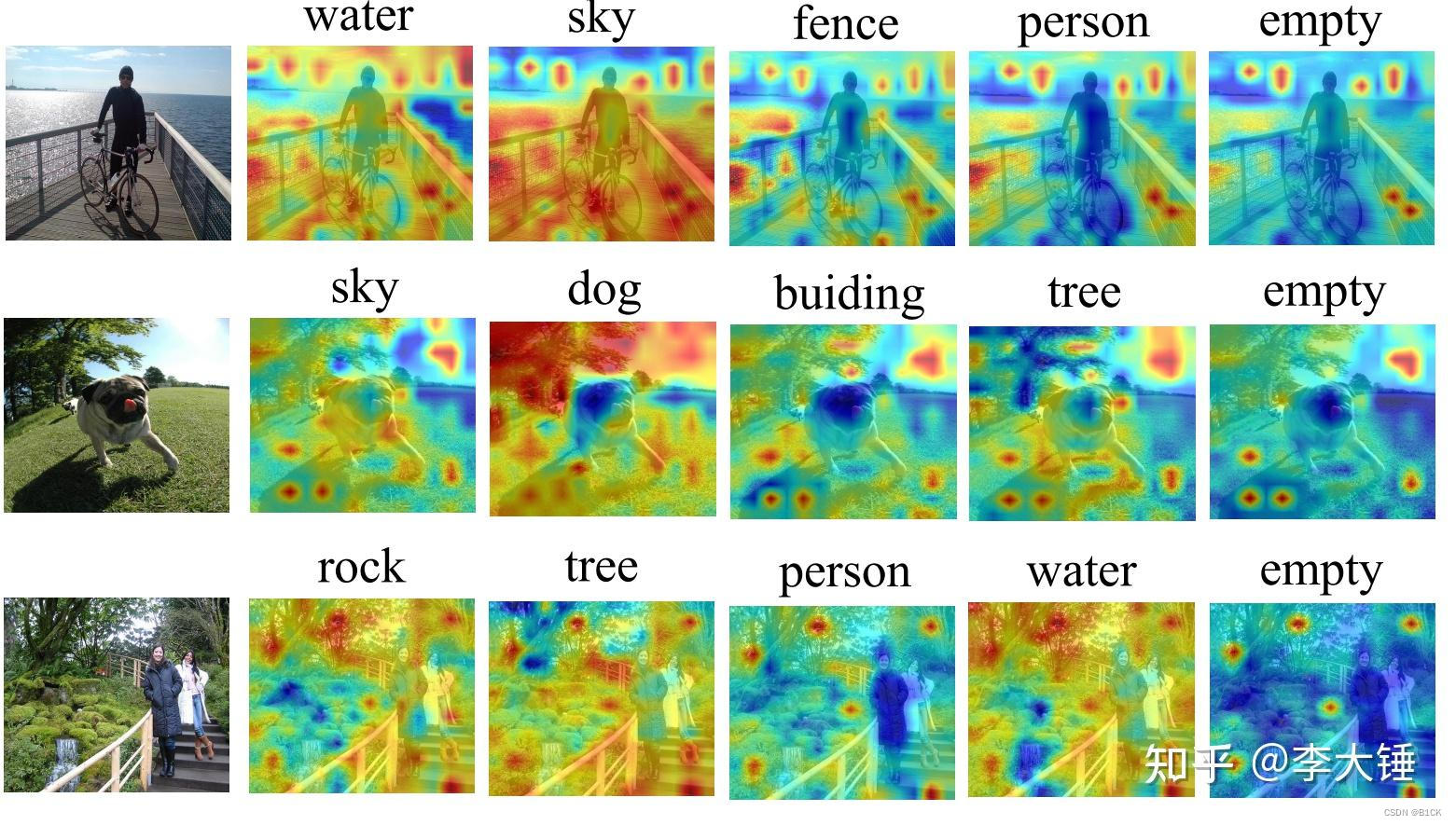
做了多模态的可解释性解释CLIP训练过程中文本和图片是怎么匹配的也发现了一些有趣的现象。比如CLIP训练数据一般关注部分物体如第一张图片只关注了自行车。而且CLIP对文本也有一定的感知如最后一张。对于文本的解释一些不重要的词如 ‘in’ ‘the’ ‘.’ 也经常也有高响应而且结束符[end]是最高频的。这说明clip会把全局特征编码到固定的token中。

ref
https://www.zhihu.com/question/595372017
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |