

Redis数据类型简介
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
常见的数据类型有Strings、Lists、Sets、Hashes、Sorted Sets
文章涉及的Redis底层数据结构介绍可参考Redis底层数据结构简介_零点冰.的博客-CSDN博客
1、字符串(Strings)
1.1、底层实现
字符串底层为Redis特有的SDS结构SDS结构有int、embstr、raw三种编码用于存储不同类型/长度的字符串。
SDS最大存储512M的数据。
- int保存的是整数值对象(8字节的长整型)作为字符串保存
- raw会调用两次内存分配函数分别创建redisObject结构和sdshdr结构内存不一定连续释放时需要释放两次
- embstr编码只会调用一次内存分配函数来分配一个连续的内存空间包含redisObject和sdshdr两个结构释放时只需要释放一次
- int编码和embstr编码如果做追加字符串等操作满足条件下会被转换为raw编码
- embstr编码的对象是只读的一旦修改会先转码到raw
3.2版本前embstr保存的是<=39字节的对象raw保存的是大于39字节的对象。
3.2版本后embstr保存的是<=44字节的对象raw保存的是大于44字节的对象。
1.2、基本命令
- setset key value设置key的值value如果key已经存在则覆盖原值。
- setnxsetnx key value如果key不存在则设置key的值value如果key存在不做任何操作。
- getget key获取指定的key的值。
- mgetget key [key ...]返回一个或多个key的值。
- incrincr key将指定key的值原子性递增1。
- incrbyincrby key decrement将指定key的值原子性递增decrement。
- decrbydecr key decrement将指定key的值原子性递减decrement。
1.3、应用场景
- 缓存热点数据。
- 常规计数(incr)文章阅读量、微博粉丝数、微博点赞数等。
- 限流(incr)以访问者的IP和业务信息作为key访问一次增加一次计数超过次数则返回false。
- 分布式唯一id根据incrby的原子性操作号段模式获取分布式全局唯一ID段。
- 分布式锁set key value nx ex获取分布式锁。
2、列表(Lists)
- 插入顺序排序的字符串列表。可以在列表的头部左边或尾部右边添加元素。
- 列表可以包含超过 40 亿 个元素 ( 2^32 - 1 )。
2.1、底层实现
- Redis3.2版本前
底层为压缩列表(ziplist) 或 双向链表(linkedlist)。
现有如下两个条件
- 列表对象保存的所有字符串元素的长度都小于64字节。
- 列表对象保存的元素数量小于512个。
如果两个条件都满足则列表会使用ziplist编码存储数据否则使用linkedlist编码存储数据。
- Redis3.2版本后
底层为快表(quicklist)快表结合了压缩列表和双向链表。
2.2、基本命令
- lpushlpush key item [item...]将一个或多个元素插入列表左端。
- lpoplpop key移除列表左端元素并且将被移除的元素返回给用户。
- llenllen key获取列表长度(元素个数)。
- ltrimltrim key start end移除给定范围start~end以外的元素只保留列表start~end范围内的元素。
- lindexlindex key index获取列表置顶下标(index)的元素。
- lsetlset key index value为列表指定索引位置设置新值。
- lrangelrange key start end获取列表中索引位置start~end范围内的元素。
- blpop移出并获取列表的第一个元素如果列表没有元素就阻塞。
- brpop移出应获取列表的最后一个元素如果列表没有元素就阻塞。
2.3、应用场景
- 列表微博的关注列表、粉丝列表、评论列表等。
- 队列先进先出rpush和blpop
- 栈先进后出rpush和brpop
3、集合(Sets)
- 常用于存储一个元素不重复的无序集合。
- 一个set最大可以存储2^32 - 1 (4,294,967,295)个元素。
3.1、底层实现
底层结构为整数集合(intset)或字典(hashtable)
现有如下两个条件
- 所有元素都是整数值。
- 元素个数小于等于512个。
- 如果两个条件都满足则集合会使用intset存储数据否则使用hashtable存储数据。
3.2、基本命令
- saddsadd key member1,member2 ...向集合key中新增元素。
- smemberssmembers key, 获取集合全部数据。
- sremsrem key member1,member2 ...删除集合key中的元素。
- sismembersismember key member, 判断集合key中是否包含某个元素。
- scardscard key返回集合中元素的数量。
- sintersinter key1 key2求两个集合的交集。
- sunionsunion key1 key2求两个集合的并集。
- sdiffsdiff key1 key2求两个集合的差集。
3.3、应用场景
主要是一些去重场景
- 知乎点赞数同一个用户只记录一次点赞多次点击只算一次。
- 微博关注对同一个用户只能关注一次。
- 抽奖只能中奖一次。
4、哈希(Hashes)
- 常用于存储对象(如果用字符串存储对象会多一个序列化/反序列化的步骤不方便)。
- 存储多个无序键值对最大可存储2^32 - 1 (4,294,967,295)个键值对。
- 可以把hash结构类比Java中的HashMap辅助理解。
4.1、底层实现
底层数据结构为压缩列表(ziplist)或字典(hashtable)。
现有如下两个条件
- 所有键值对的键和值的字符串长度都小于64字节。
- 键值对数量小于512个。
- 如果两个条件都满足则会使用ziplist编码否则使用hashtable编码。
- 如果是ziplist存储键值对那么key-value键值对是以紧密相连的方式放入压缩链表的先把key放入表尾再放入value键值对总是向表尾添加。

4.2、基本命令
- hsethset key field value在字段(field)不存在时设置哈希表(key)指定字段(field)的值(value)。
- hgethget key field获取存储在哈希表(key)中指定字段(field)的值。
- hmgethmget key field1,[field2]获取哈希表中指定多个字段的值。
- hincrbyhincrby key field increment为哈希表(key)中的指定整数字段(field)加上增量值increment。
4.3、应用场景
存储结构化数据例如购物车信息包括商品名、价格、数量等多个键值对数据。

5、有序集合(Sorted Sets)(ZSet)
- 常用于需要进行排序的元素不重复的列表数据。
- 与Set相比结构上增加了一个权重参数score用于集合中的元素排序。
5.1、底层实现
底层数据结构为压缩列表(ziplist)和跳表(skiplist)。
现有如下两个条件
- 所有元素长度小于64字节。
- 元素个数小于128个。
- 如果两个条件都满足则会使用ziplist编码否则使用skiplist编码。
5.1.1、ziplist编码
两个紧密相连的压缩列表节点第一个保存元素的成员第二个保存元素的分值而且分值小的靠近表头大的靠近表尾。

5.1.2、skiplist编码
zset使用skiplist编码时同时包含一个字典和一个跳跃表。
typedef struct zset {
zskiplist *zsl;
dict *dict;
} zset;跳跃表按分值从小到大保存了所有集合元素 每个跳表节点都保存一个集合元素并按分值从小到大排列节点的object属性保存了元素的成员score属性保存分值。通过这个跳跃表 程序可以对有序集合进行范围型操作。
而字典创建了一个从成员到分值的映射字典的每个键值对都保存了一个集合元素 字典的键保存了元素的成员 而字典的值则保存了元素的分值。 通过这个字典 程序可以用 O(1) 复杂度查找给定成员的分值。
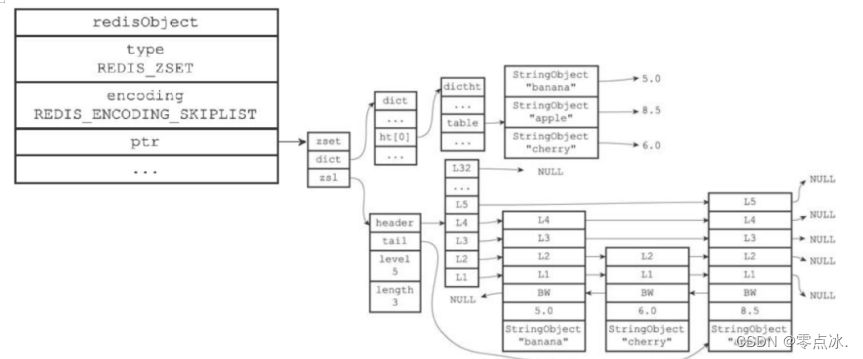
5.1.3、为什么skiplist编码要同时使用跳表和字典
- 从理论上来说跳表和字典两种结构都可以实现zset。
- 跳表优点是有序但是查询分值复杂度为O(logn)字典查询分值复杂度为O(1)但是无序。
假如只使用字典那么可以以O(1)复杂度查找成员分值但是在执行范围性操作(zrank、zrange等命令)时需要对字典保存的元素进行排序。排序过程需要至少O(N\log N)时间复杂度以及额外的O(N)内存空间。
假如只使用跳表那么在执行范围性操作时会很快但是在执行根据成员查找分值这一操作上时间复杂度会从O(1)上升为O(logN).
所以同时使用跳表和字典是为了让有序集合的查找和范围性操作都尽可能快地执行。
5.1.4、zset类型是如何排序的
Zset有序集合和set类似是不包含相同字符串的集合但zset的每个成员都关联着一个分数值(double)该分数值在插入成员的时候制定这个分数值用于把zset中的成员按照最低分到最高分排列。若分数值相同则按照value的字典顺序排序。
5.2、基本命令
- zaddzadd key score1 value1 [score2] [value2]将一个或多个元素及其分值插入到有序集合key中。
- zrangezrange key start end返回有序集合key中下标在start~end范围内的元素。
- zrankzrank key value返回指定值在有序集合key中的排名。
- zremzrem key value删除集合key下的指定元素value。
5.3、应用场景
- 各种排序场景例如热搜排行榜、热门歌曲榜单列表等。
- 延时队列zset 会按 score 进行排序把score设置成想要执行任务的时间戳。
6、Streams
6.1、简介
- Streams是Redis5.0推出的数据类型主要用于实现消息队列。
- Redis本身有一个发布订阅(pub/sub)功能但该功能无法持久化宕机、网络故障情况下容易造成消息丢失。
- Redis Stream提供了消息持久化和主备复制功能可以让任何客户端访问任何时刻的数据并且能记住每一个客户端的访问位置还能保证消息不丢失。
6.2、基本命令
消息队列相关命令
- XADD - 添加消息到末尾
- XTRIM - 对流进行修剪限制长度
- XDEL - 删除消息
- XLEN - 获取流包含的元素数量即消息长度
- XRANGE - 获取消息列表会自动过滤已经删除的消息
- XREVRANGE - 反向获取消息列表ID 从大到小
- XREAD - 以阻塞或非阻塞方式获取消息列表
消费者组相关命令
- XGROUP CREATE - 创建消费者组
- XREADGROUP GROUP - 读取消费者组中的消息
- XACK - 将消息标记为"已处理"
- XGROUP SETID - 为消费者组设置新的最后递送消息ID
- XGROUP DELCONSUMER - 删除消费者
- XGROUP DESTROY - 删除消费者组
7、Geospatial
Redis3.2新增类型地理位置也可以理解成经纬度。redis基于该类型提供了经纬度设置查询范围查询距离查询经纬度Hash等常见操作。
7.1、基本命令
- geoadd存储指定的地理空间位置可以将一个或多个经纬度、位置名称添加到指定key中。
geoadd key longitude latitude member [longitude latitude member]
- geopos从指定key中获取指定名称位置的经纬度。
geopos key member [member]
- geodist返回两个指定位置之间的距离(m-米km-千米ft-英里mi-英尺)。
geodist key member1 member2 [m|km|ft|mi]
- geohash返回一个或多个位置对象的 geohash 值。
geohash key member [member]
8、Bitmaps
可以理解成以位为基本单位的数组数组中的元素只能存储0或1数组的下标在bitmaps里被称为偏移量。
单个bitmaps的最大长度是512M(2^32 bit)。
8.1、基本命令
- getbitgetbit key offset获取指定key对应偏移量上的bit值。
- setbitsetbit key offset value设置指定key对应偏移量上的bit值。
- bitopbitop op destkey key [key ...]对指定key按位进行交、并、非、异或操作并将结果保存到destKey中。(opand-交集or-并集not-非xor-异或)
- bitcountbitcount key start end统计指定偏移量范围内的1的个数。
以上内容为个人学习理解如有问题欢迎在评论区指出。
部分内容截取自网络如有侵权联系作者删除。