

11.7加减计数器,可置位~,数字钟分秒,串转并,串累加转并,24位串并128,流水乘法器,一些乘法器-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
信号发生器

方波就是一段时间内都输出相同的信号

锯齿波就是递增
![]()
三角波就是先增后减

加减计数器
当mode为1则加Mode为0则减只要为0就输出zero

这样会出问题因为要求是十进制但是这里并没有考虑到9之后怎么办所以就会使number输出超过9应该额外要添加十进制的边缘判断即mode为1要加的时候也要判断一下是不是要继续加而不是直接加

简易秒表
输出端口second为1~60到60时minute+1分到60时停止计数
秒的确定
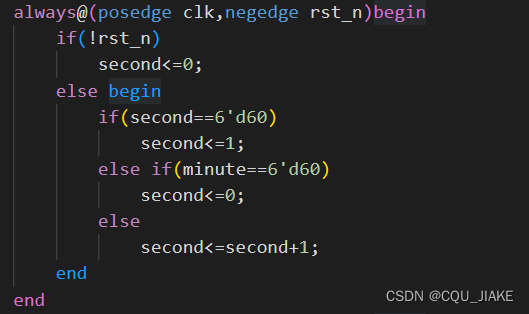
分的确定
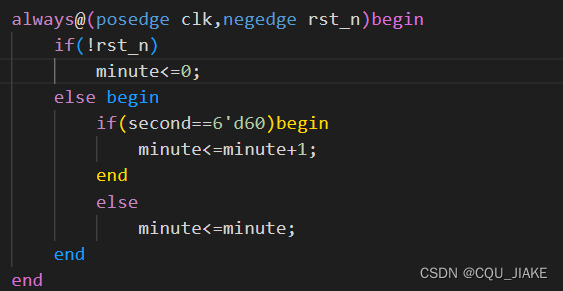
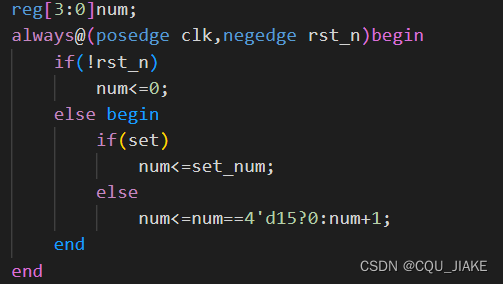
可置位计数器
就是有置位信号时把当前数字置为要置的数字
然后要确定是十六进制
额外逻辑
串转并
输入端输入单位信号累积到6个后输出一个六位的信号

reg [5:0] data_reg;
reg [2:0] data_cnt;
always @(posedge clk or negedge rst_n ) begin
if(!rst_n)
ready_a <= 'd0;
else
ready_a <= 1'd1;
end
always @(posedge clk or negedge rst_n ) begin
if(!rst_n)
data_cnt <= 'd0;
else if(valid_a && ready_a)
data_cnt <= (data_cnt == 3'd5) ? 'd0 : (data_cnt + 1'd1);
end
always @(posedge clk or negedge rst_n ) begin
if(!rst_n)
data_reg <= 'd0;
else if(valid_a && ready_a)
data_reg <= {data_a, data_reg[5:1]};
end
always @(posedge clk or negedge rst_n ) begin
if(!rst_n)begin
valid_b <= 'd0;
data_b <= 'd0;
end
else if(data_cnt == 3'd5)begin
valid_b <= 1'd1;
data_b <= {data_a, data_reg[5:1]};
end
else
valid_b <= 'd0;
end
数据累加输出
当接受到4个输入数据后输出一个这四个数据的累加结果

`timescale 1ns/1ns
module valid_ready(
input clk ,
input rst_n ,
input [7:0] data_in ,
input valid_a ,
input ready_b ,
output ready_a ,
output reg valid_b ,
output reg [9:0] data_out
);
reg [1:0] data_cnt;
assign ready_a = !valid_b | ready_b;
always @(posedge clk or negedge rst_n ) begin
if(!rst_n)
data_cnt <= 'd0;
else if(valid_a && ready_a)
data_cnt <= (data_cnt == 2'd3) ? 'd0 : (data_cnt + 1'd1);
end
always @(posedge clk or negedge rst_n ) begin
if(!rst_n)
valid_b <= 'd0;
else if(data_cnt == 2'd3 && valid_a && ready_a)
valid_b <= 1'd1;
else if(valid_b && ready_b)
valid_b <= 1'd0;
end
always @(posedge clk or negedge rst_n ) begin
if(!rst_n)
data_out <= 'd0;
else if(ready_b && valid_a && ready_a && (data_cnt == 2'd0))
data_out <= data_in;
else if(valid_a && ready_a)
data_out <= data_out + data_in;
end
endmodule非阻塞赋值就是把次态给现态就是说右侧的是次态但是现在还不用是下个状态的情况那么条件判断里就是导致其进入下个状态的条件
非整数倍数据位宽转换24to128
数据位宽转换24位转128位先到的数据为高位
也是串转并的一种只不过最后的时候是只要一部分
思路都是先判断输入的有效性有效时就对数据暂存器做出改变对于输出时如果可以输出了即让输出就输出没有使能就不输出依然暂存。
24和128的最小公倍数为384所以每到384的时候就是对齐了一次即完成一次周期
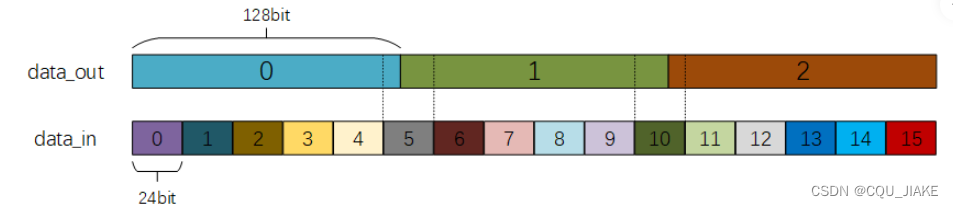
所以每当cnt到51015时就需要输出一次并拉高valid_out一个周期

简单的输入信号计数器表示已经输入了几个24位的信号
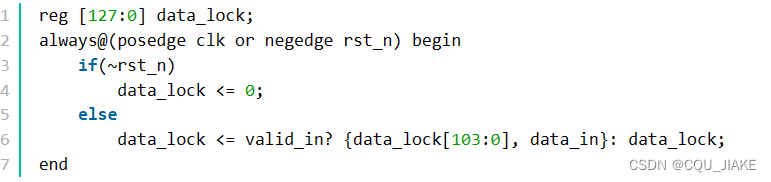
数据暂存器每当输入有效时将数据从低位移入注意是低位而且是要在输入有效时操作
输出使能
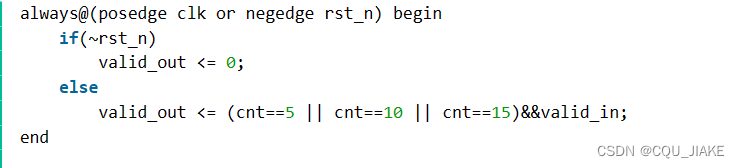
需要注意的是非阻塞是使的关系即这个clk里收到了信号但是并不在这个周期里即时发生改变而是在下个clk里再发生改变也就使得逻辑上同步的输入输出不是在同一个周期上发生而是先有输入才有下个周期对应的输出每个周期输出的都是上个周期的结果。当下输入的数据在下个周期出结果
但在赋值时由于是非阻塞所以也是在给次态赋值所以这个周期里干的事都不是这个周期里的而是去确定下个周期的这个周期里的事都在上个周期里确定了也就是说此时的条件都是下个周期的而不是当下的。
所以写的时候就不要想的是串行。而是想写的是一个一个模块根据不同的输入给出不同的输出
就是注意![]()
先到的数据在高位满的时候先从高位出去即FIFO。只是截取高位的时候是从暂存器的低位开始截取的也就是说还是先进的最高位先出去然后输出的时候是先尝试输出再寄存因为寄存的时候不管截不截取它就是全部存进去。但是输出的时候要判断并截取一部分新的
valid_in是判断当前的输出是不是有效如果无效即使输入了要发生一些改变时也不会
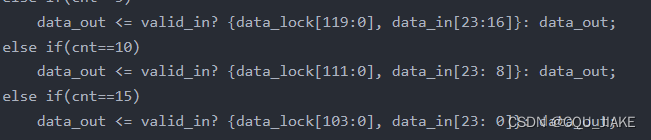
之前担心的是如果能输出的时候先在暂存器里输入了一遍结果又在输入里输入了一遍
但实际上这就是为什么要用非阻塞而不是阻塞。即各个模块都是并行的都是并行的即在这个时钟刻里用的都是上个时间里的数值而且不会发生改变。用非阻塞可以不用考虑这样的先后问题如果是阻塞就必须先尝试输出才能暂存
用阻塞也会出问题出时序问题马丹
`timescale 1ns/1ns
module width_24to128(
input clk ,
input rst_n ,
input valid_in ,
input [23:0] data_in ,
output reg valid_out ,
output reg [127:0] data_out
);
reg [3:0] cnt;
reg [127:0] data_lock;
always@(posedge clk or negedge rst_n) begin
if(~rst_n)
cnt <= 0;
else
cnt <= ~valid_in? cnt:cnt+1;
end
always@(posedge clk or negedge rst_n) begin
if(~rst_n)
valid_out <= 0;
else
valid_out <= (cnt==5 || cnt==10 || cnt==15)&&valid_in;
end
always@(posedge clk or negedge rst_n) begin
if(~rst_n)
data_lock <= 0;
else
data_lock <= valid_in? {data_lock[103:0], data_in}: data_lock;
end
always@(posedge clk or negedge rst_n) begin
if(~rst_n)
data_out <= 0;
else if(cnt==5)
data_out <= valid_in? {data_lock[119:0], data_in[23:16]}: data_out;
else if(cnt==10)
data_out <= valid_in? {data_lock[111:0], data_in[23: 8]}: data_out;
else if(cnt==15)
data_out <= valid_in? {data_lock[103:0], data_in[23: 0]}: data_out;
else
data_out <= data_out;
end
endmodule
流水线乘法器

流水线
就是采用乘法竖式的思想将乘法转化加法最高位为n则就有n个加法数
用循环简化代码

`timescale 1ns/1ns
module multi_pipe#(
parameter size = 4
)(
input clk ,
input rst_n ,
input [size-1:0] mul_a ,
input [size-1:0] mul_b ,
output reg [size*2-1:0] mul_out
);
wire [2*size-1 : 0] a,b;
reg [2*size-1 : 0]temp0,temp1,temp2,temp3;
assign a=mul_a;
assign b=mul_b;
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
temp0<=0;
temp1<=0;
temp2<=0;
temp3<=0;
end
else
begin
temp0 <= b[0] ? a : 0;
temp1<= b[1] ? a<<1 : 0;
temp2<= b[2] ? a<<2 : 0;
temp3<= b[3] ? a<<3 : 0;
end
end
always @ (posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
mul_out=0;
end
else
begin
mul_out=temp0+temp1+temp2+temp3;
end
end
endmodule
`timescale 1ns/1ns
module multi_pipe#(
parameter size = 4
)(
input clk ,
input rst_n ,
input [size-1:0] mul_a ,
input [size-1:0] mul_b ,
output reg [size*2-1:0] mul_out
);
//parameter
parameter N = size * 2;
//defination
wire [N - 1 : 0] temp [0 : 3];
reg [N - 1 : 0] adder_0;
reg [N - 1 : 0] adder_1;
//output
genvar i;
generate
for(i = 0; i < 4; i = i + 1)begin : loop
assign temp[i] = mul_b[i] ? mul_a << i : 'd0;
end
endgenerate
always@(posedge clk or negedge rst_n)begin
if(!rst_n) adder_0 <= 'd0;
else adder_0 <= temp[0] + temp[1];
end
always@(posedge clk or negedge rst_n)begin
if(!rst_n) adder_1 <= 'd0;
else adder_1 <= temp[2] + temp[3];
end
always@(posedge clk or negedge rst_n)begin
if(!rst_n) mul_out <= 'd0;
else mul_out <= adder_0 + adder_1;
end
endmodule

就是说一个数位数是否为1决定另一个数是否为拓位后的数还是0
状态图实现任意位乘法
2个32位整数相乘实际上是进行了32次加法操作

流程图中x因为需要左移所以32位长度的x应该用一个64位寄存器来存储这样才能保证x左移后不会发生高位丧失。
取绝对值操作
首先是获取符号位然后根据符号位去决定对应的操作
如果是正数就直接赋值不然就先取反再+1

输入为mult_begin,拉高后乘法再开始直到运算结束或者人为拉低
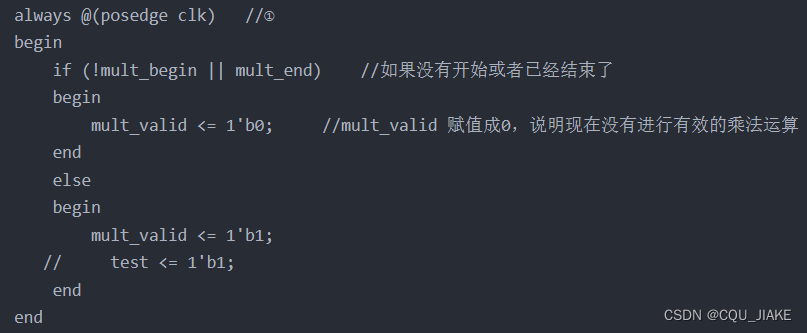
需要注意的是右移y那么每次都是去掉y的最低位然后需要在最高位补0即整体往右移动一位这个块就是实现每次都右移一位y

这个是左移x不会丢位因为最多移32次最多就是到最高位

然后这个是判断加数如果此时y的最低位是1那么就加不然就不加为0

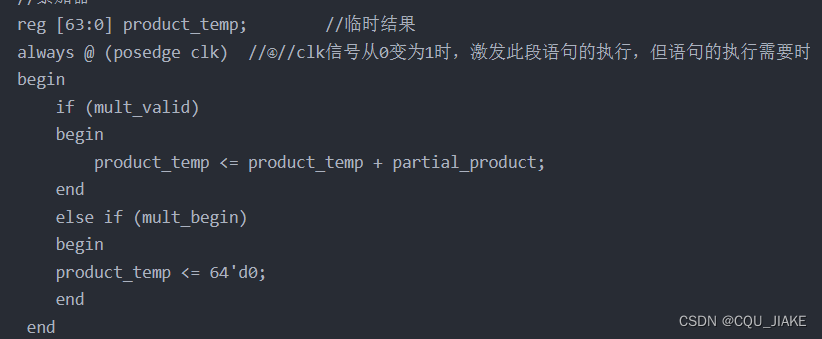
符号位确定

循环实现
相同的思路第二种就是用for循环简化了代码


采用移位寄存器同样可以实现上面那个是每次都计算都是从头开始移位i次采用移位寄存器后就是不断复用上一次的结果只移位一次就可以而不是每次都移位i次
用i,i就代表移位的次数可以简便的读取到第i位以及左移i位的结果
流水线是每次都加两个新的

仿真文件
`timescale 1ns / 1ps
module tb;
// Inputs
reg clk;
reg mult_begin;
reg [31:0] mult_op1;
reg [31:0] mult_op2;
// Outputs
wire [63:0] product;
wire mult_end;
// Instantiate the Unit Under Test (UUT)
multiply uut (
.clk(clk),
.mult_begin(mult_begin),
.mult_op1(mult_op1),
.mult_op2(mult_op2),
.product(product),
.mult_end(mult_end)
);
initial begin
// Initialize Inputs
clk = 0;
mult_begin = 0;
mult_op1 = 0;
mult_op2 = 0;
// Wait 100 ns for global reset to finish
#100;
mult_begin = 1;
mult_op1 = 32'H00001111;
mult_op2 = 32'H00001111;
#400;
mult_begin = 0;
#500;
mult_begin = 1;
mult_op1 = 32'H00001111;
mult_op2 = 32'H00002222;
#400;
mult_begin = 0;
#500;
mult_begin = 1;
mult_op1 = 32'H00000002;
mult_op2 = 32'HFFFFFFFF;
#400;
mult_begin = 0;
#500;
mult_begin = 1;
mult_op1 = 32'H00000002;
mult_op2 = 32'H80000000;
#400;
mult_begin = 0;
// Add stimulus here
end
always #5 clk = ~clk;
endmodule
一些细节
这是两者的位数关系
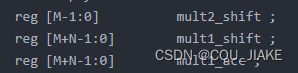
非流水线设计就是每次乘法运算只输出一个结果