

人工智能内容生成元年—AI绘画原理解析_ai绘画原理
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

一、背景
2022年AIGCAI生成内容焕发出了勃勃生机大有元年之势技术与应用迭代都扎堆呈现。在各种新闻媒体处可以看到诸多关于学术前沿研究以及相应落地的商用案例。可谓出现了现象级的学术-商业共振。以往学术研究内容离商用一般较远因为学术研究相应实验数据通常为闭集即固定数据场景而商业应用则为开集即非固定数据场景能见到各式各样、甚至乱七八糟的数据。所以将学术研究内容转化为商业应用的时候就需要以工匠精神去做产品化设计与迭代主要目的就是不断提升其可用性以达到商业化标准避免出现不符预期、甚至乱七八糟的结果。
但AIGC领域似乎大大缩短了这一转化进程尤其以近期短时间内爆火的AI绘画、AI作画类应用为代表。这无疑是人工智能发展至今的巨大胜利时刻这能建立极强、极快的螺旋式发展迭代循环商业应用上的不足点能迅速反馈至学术研究侧学术研究侧的优化改进也能迅速体现到商业应用侧拉满学术研究能获得的成就感。接下来的篇幅将介绍现有AI绘画、AI作画背后的相应基本原理、应用、以及论文参考文献。更多技术与应用的有趣想法欢迎评论区留言。
二、原理
技术脉络归纳
在AI内容生成制作爆火的2022元年在其基础框架技术部分技术演进的脉络可以看作是不断寻找更可靠的特征域建模方式亦可看作是不断寻找更合适的借鸡生蛋方式的过程。原始图像域的特征维度是很高的直接来建模会有维度灾难的问题。需要不断找到可行的中间域来做对齐
1.CLIP可以看作是图像域与文本域特征对齐的大一统技术框架文本域的原始特征空间跟原始图像域的特征空间比是相对更小的。所以在同等维度特征的表达下文本相比图像是能更加容易被刻画好的所以当align文本域特征到图像域特征时图像域特征表达将无疑得到了更佳的富有语义的监督信号。这样获得更好的效果也就很自然了。
2.diffusion可以看作是将原始图像域建模转变为噪声域建模的方法。噪声域有两个极大的好处首先它的特征空间比原始图像域要小的多非常容易建模。其次即使噪声域建模效果没能接近完美它所呈现出来的差异也是噪声域的差异而这个噪声差异在图像内容域上对人眼来说往往注意不到。所以从基本原理上来说diffusion生成的图像细节无疑是会远远优于gan的。
基础技术部分
基础技术框架上大致可以分成如下几个标志性的阶段
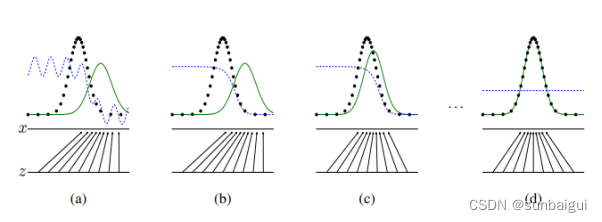
aGAN阶段
原理摘记生成与对抗网络图像特征域对齐示意图如论文[1]中图所示
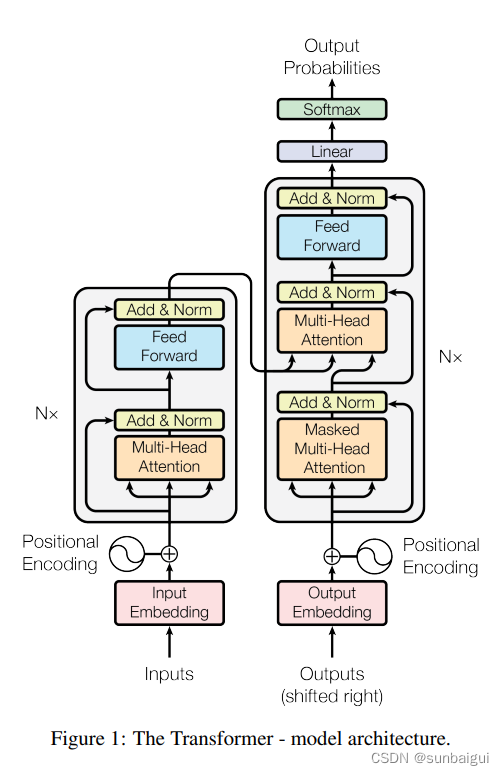
bTransformer阶段
网络由self-Attenion和Feed Forward Neural Network组成强力的文本、图像(ViT系列)编码网络框架。示意图如论文[3]中图所示
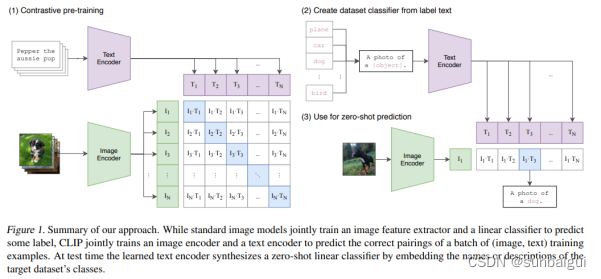
cCLIP阶段
图像文本域特征对齐。基于文本、视觉transformer encode统一框架训练阶段4亿文本图像配对数据训练至少100卡月V100。示意图如论文[4]中图所示
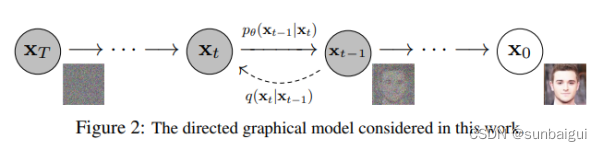
dDiffusion阶段
原始图像特征域对齐转变为图像噪声域对齐。基于参数化马尔科夫链框架实现。示意图如论文[5]中图所示
演化技术部分
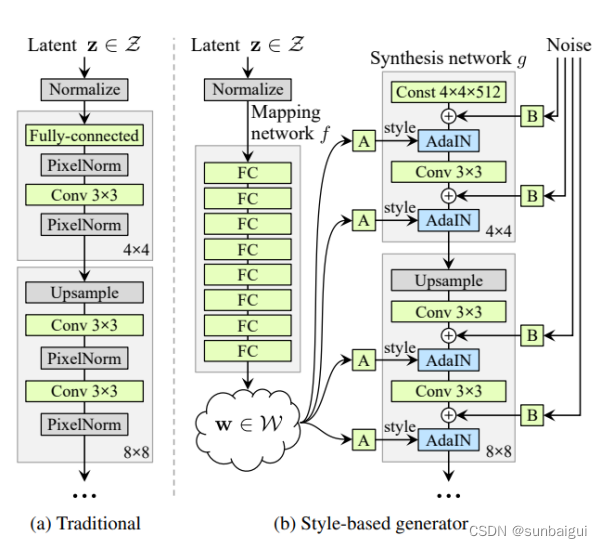
aStyleGan
基于adain思想额外学习高斯分布到风格空间w的映射然后风格空间的变量作用于合成网络中。示意图如论文[2]中图所示
bDALL-E 1
网络可理解为VQVAE + Transformer。示意图如论文[6]中图所示

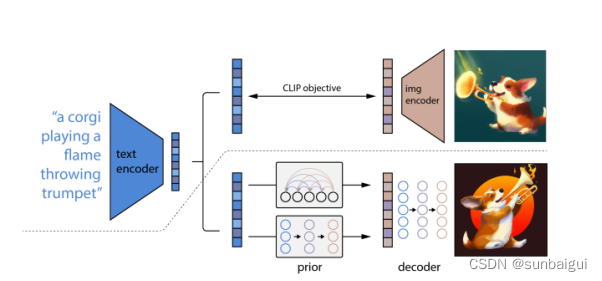
c DALL-E 2
网络可理解为CLIP + Diffusion。示意图如论文[7]中图所示
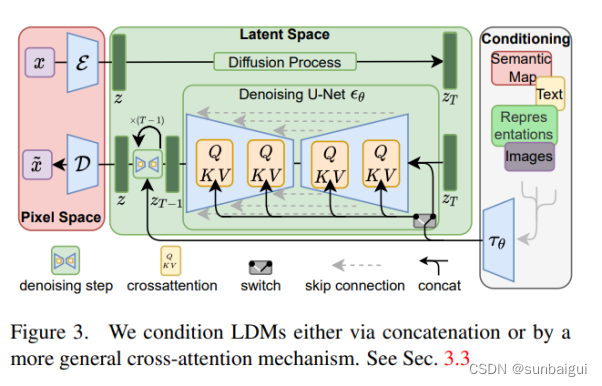
dStable Diffusion
网络可理解为VAE + CLIP + Diffusion + Unet引入LDM等加速手段显著降低计算复杂度。示意图如论文[8]中图所示
三、应用
目前可以看到诸如文生图、图生图、图像编辑、图像修复、图像拓展等应用功能都已实现国内的AI绘画特效类应用也结合国风、动漫等风格有了非常广泛的应用这里面既有大厂也有创业公司等玩家的加入。于此同时对创意行业设计者来说AI绘画也正演变为最佳助手大幅提高创意行业的生产效率。相应应用介绍如下
1.) Disco DiffusionCLIP + Diffusion。https://github.com/alembics/disco-diffusion。
2.) Stable Diffusionhttps://github.com/Stability-AI/stablediffusion。
3.) Stable Diffusion 2显著提升图像质量采用LAION-5B 58.5亿个图像文本对增加NSFW做了内容过滤。https://huggingface.co/stabilityai/stable-diffusion-2 。
4.) Imagic : gan DALL-E 2基于扩散模型的真实图像编辑方法用文字就能实现真实照片的 PS比如让一个人竖起大拇指、让两只鹦鹉亲吻。示意图如论文[9]中图所示

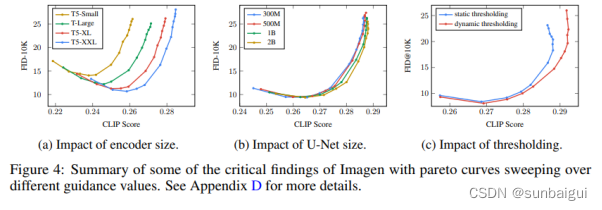
5.) Imagen更强力的语言模型能获得更逼真的画作效果。相较于视觉部分模型来讲语言模型size越大带来的画作逼真性越大。示意图如论文[10]中图所示
6.) DreamBooth: 对输入图像中的主体能进行相应输入文本语义下的内容生成。示意图如论文[11]中图所示

7.) Midjourney https://midjourney.gitbook.io/docs。在美国科罗拉多州举办的艺术博览会《太空歌剧院》的画作获得数字艺术类别冠军。
四、文献
[1]Ganhttps://arxiv.org/abs/1406.2661
[2]StyleGanhttps://arxiv.org/abs/1812.04948
[3]Transformer: https://arxiv.org/abs/1706.03762
[4]CLIPhttps://arxiv.org/abs/2103.00020
[5]Diffusionhttps://arxiv.org/abs/2006.11239
[6]DALL-E 1https://arxiv.org/abs/2102.12092
[7]DALL-E 2https://arxiv.org/abs/2204.06125
[8]Stable Diffusion: https://arxiv.org/abs/2112.10752
[9]Imagichttps://arxiv.org/abs/2210.09276
[10]Imagenhttps://arxiv.org/abs/2205.11487
[11]DreamBoothhttps://arxiv.org/abs/2208.12242