

机器学习算法:线性回归的改进-岭回归-黑马程序员_线性回归 岭回归
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
学习目标
- 知道岭回归api的具体使用
1 API
- sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver="auto", normalize=False)
- 具有l2正则化的线性回归
- alpha:正则化力度,也叫 λ
- λ取值:0~1 1~10
- solver:会根据数据自动选择优化方法
- sag:如果数据集、特征都比较大,选择该随机梯度下降优化
- normalize:数据是否进行标准化
- normalize=False:可以在fit之前调用preprocessing.StandardScaler标准化数据
- Ridge.coef_:回归权重
- Ridge.intercept_:回归偏置
Ridge方法相当于SGDRegressor(penalty='l2', loss="squared_loss"),只不过SGDRegressor实现了一个普通的随机梯度下降学习,推荐使用Ridge(实现了SAG)
- sklearn.linear_model.RidgeCV(_BaseRidgeCV, RegressorMixin)
- 具有l2正则化的线性回归,可以进行交叉验证
- coef_:回归系数
2 观察正则化程度的变化,对结果的影响?
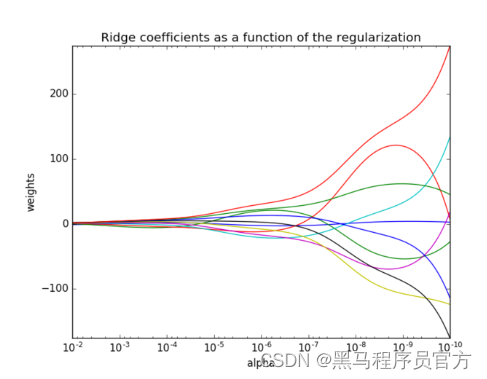
- 正则化力度越大,权重系数会越小
- 正则化力度越小,权重系数会越大
3 波士顿房价预测
4 小结
- sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver="auto", normalize=False)【知道】
- 具有l2正则化的线性回归
- alpha -- 正则化
- 正则化力度越大,权重系数会越小
- 正则化力度越小,权重系数会越大
- normalize
- 默认封装了,对数据进行标准化处理
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |