

DW动手学数据分析Task1:数据加载及探索性数据分析
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
- Datawhale课程链接链接
- 参考教材《Python for Data Analysis》
1 数据载入
1.1 载入数据
- 相对路径 相对于当前文件来说要选择的文件的位置
- 绝对路径针对电脑来说目标文件的位置
# 绝对位置 df=pd.read_csv('C:\Users\YG小白\DW数据分析学习\train.csv')# 报错 # SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes- 原因在windows系统当中读取文件路径可以使用\但是在python字符串中\有转义的含义
- 方法在路径前面加r即保持字符原始值的意思
df=pd.read_csv(r'C:\Users\YG小白\DW数据分析学习\train.csv')使用
os.getcwd()查看当前工作目录记住要提前导入OS
1.2 read_csv和read_table的区别
- read_csv从文件读取分隔好的数据默认分隔符是逗号。即是将每个元素作为一列存储
df1=pd.read_csv('train.csv',nrows = 3) print("pd.read_csv读取数据行列数为",df1.shape) # pd.read_table读取数据行列数为 (3, 12) - read_table从文件读取分隔好的数据默认分隔符是制表符(‘\t’)即以行为单位进行分隔。即是将每行所有的元素作为一个维度存储在一起因此只有一列
df2 = pd.read_table('train.csv',nrows = 3)#只读取3行数据 print("pd.read_table读取数据行列数为",df2.shape) # pd.read_table读取数据行列数为 (3, 1) - 若想用read_table读取出read_csv的效果设置
sep = ','即可pandas.read_table(数据文件名, sep=’\t’, header=’infer’) pandas.read_csv(数据文件名, sep=’,’, header=’infer’
1.3 逐块读取
- 原理将数据分成小块按块读入得到的对象指向了多个分块对象但并没有将实际数据先读入而是在提取数据时才将数据提取进来。可减少内存的存储与计算资源
- chunker(数据块)是什么类型?
chunker = pd.read_csv('train.csv', chunksize=400) #指定 `chunkersize`参数作为每一块的行数 print(type(chunker)) # TextParser for piece in chunker: print(type(piece)) print(len(piece))

有
chunkersize参数可以进行逐块加载本质就是将文本分成若干块每次处理chunkersize行的数据最终返回一个TextParser对象对该对象进行迭代遍历可以完成逐块统计的合并处理。
1.4 修改表头和索引
- 方法1读取时直接处理
df = pd.read_csv('train.csv', names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'], index_col='乘客ID',header=0) - 方法2用
rename函数用字典的形式替换式的修改可随意修改个数data_df.rename(columns={'PassengerId': '乘客ID', 'Survived': '是否幸存', 'Pclass': '乘客等级(1/2/3等舱位)', 'Name': '乘客姓名', 'Sex': '性别', 'Age': '年龄', 'SibSp': '堂兄弟/妹个数', 'Parch': '父母与小孩个数', 'Ticket': '船票信息', 'Fare': '票价', 'Cabin': '客舱', 'Embarked': '登船港口'},index = '乘客ID', inplace = True) - 读取后修改列名
df.columns = ['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口']
2 数据初步观察
2.1 查看数据基本信息
- 查看数据的基本信息
df.info() # 打印摘要 df.describe() # 打印描述性统计信息- info函数给出样本数据的相关信息概览 行数列数列索引列非空值个数列类型内存占用
- describe()函数直接给出样本数据的一些基本的统计量包括均值标准差最大值最小值分位数等。
df.shape # DataFrame行数和列数 df.dtypes # 数据类型 df.values # 数组形式 df.columns # 列标签<Index> df.columns.values # 列标签<ndarray> df.index # 行标签<Index> df.index.values # 行标签<ndarray> - 观察指定位置的数据
df.head(n) # 前n行 df.tail(n) # 后n行 df.options.display.max_columns=n # 最多显示n列 df.options.display.max_rows=n # 最多显示n行 - 判断数据是否为空
df.isnull()
2.2 保存数据
df.to_csv('train_chinese.csv', encoding = 'utf-8')
若不想存索引则增加
index = False;
不同的操作系统保存下来可能会有乱码。大家可以加入encoding=‘GBK’ 或者encoding = ‘uft-8’
3 pandas数据结构和列操作
3.1 Series 和DataFrame
-
pandas 有两个主要的数据结构Series 和 DataFrame
- DataFrame是一种表格型数据含有一组有序的列既有行索引也有列索引
- Series 是一个一维数组对象只有行索引由一组数据及其标签组成
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000} example_1 = pd.Series(sdata) example_1
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'] ,'year': [2000, 2001, 2002, 2001, 2002, 2003] ,'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]} example_2 = pd.DataFrame(data) example_2
3.2 查看 DataFrame数据每列的名称和值
df.columns # 查看列的名称
df['Cabin'] # 方法1查看 "Cabin" 列的所有值
df.Cabin # 方法2查看 "Cabin" 列的所有值
3.3 DataFrame 的列删除和隐藏
# 列删除
# 单列删除
del df['a']
# 多列删除
df.drop(['PassengerId', 'Name', 'Age'], axis = 1, inplace = True)
# 列隐藏
df.drop(['PassengerId', 'Name', 'Age'], axis = 1)
- drop函数
- 默认删除行列需要加
axis = 1 - 如果想要完全删除数据结构使用
inplace=True默认inplace=False
- 默认删除行列需要加
- del和drop区别
del函数是Python的内置函数函数仅对列进行操作一次只能操作一个仅是就地操作drop函数是属于pandas中的内置函数对列和行都进行操作一次可以处理多个项目可以就地操作或返回副本
4 数据筛选
4.1 筛选列数据
#【单一条件筛选】
# 显示年龄在10岁以下的乘客名字
df[df['Age'] < 10]['Name']
# 【多条件筛选】
# 在10岁以上和50岁以下的乘客信息显示出来
midage =df[(df['Age'] > 10) & (df['Age'] < 50)]
4.2 筛选特定数据
- reset_index()函数
- 作用数据清洗时会将带空值的行删除此时DataFrame或Series类型的数据不再是连续的索引可以使用
reset_index()重置索引。 - 用法
df.reset_index(drop=True) - 获得新的index原来的index变成数据列保留下来
- 不想保留原来的index使用参数
drop=True默认False。
- 如果不使用reset_index()函数显示的就不是midage数据中的第100行而是df数据的第100行。
- 作用数据清洗时会将带空值的行删除此时DataFrame或Series类型的数据不再是连续的索引可以使用
- loc和iloc函数
- loc函数基于行标签进行索引
- iloc函数基于行的号进行索引主要是整数也可以用布尔数组。
- 显示midage数据中第100105108行的"Pclass""Name"和"Sex"的数据
# loc函数 midage.loc[[100,105,108],['Pclass','Name','Sex']] # iloc函数 midage.iloc[[100,105,108],[2,3,4]]
5 探索性数据分析
5.1 数据排序
- 创建DataFrame数据
frame = pd.DataFrame(np.arange(8).reshape((2, 4)), index=['2', '1'], columns=['d', 'a', 'b', 'c'])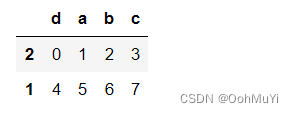
- pd.DataFrame() 创建一个DataFrame对象
- np.arange(8).reshape((2, 4)) : 生成一个二维数组2*4,第一列0123 第二列4567
- index=[‘2’, ‘1’]DataFrame 对象的索引列
- columns=[‘d’, ‘a’, ‘b’, ‘c’] DataFrame 对象的索引行
- 排序
frame.sort_index() # 行索引升序 frame.sort_index(axis = 1) # 列索引升序 frame.sort_index(axis = 1, ascending = False) # 列索引降序 # 任取一列进行升序排序 frame.sort_values(by='c', ascending=True) # 任选两列数据同时降序排序 frame.sort_values(by=['a', 'c'], ascending=False) # sort_values这个函数中by参数指向要排列的列
5.2 DataFrame数据相加
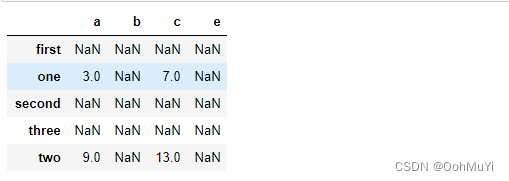
#建立一个例子
frame1_a = pd.DataFrame(np.arange(9.).reshape(3, 3),
columns=['a', 'b', 'c'],
index=['one', 'two', 'three'])
frame1_b = pd.DataFrame(np.arange(12.).reshape(4, 3),
columns=['a', 'e', 'c'],
index=['first', 'one', 'two', 'second'])
# 数据相加
new_frame = frame1_a + frame1_b
# 数据合并
pd.concat([frame1_a, frame1_b], axis = 0)
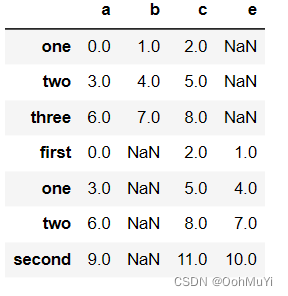
两个DataFrame相加后会返回一个新的DataFrame对应的行和列的值会相加没有对应的会变成空值NaN
5.3 查看数据基本信息
new_frame.describe()
#count : 样本数据大小
#mean : 样本数据的平均值
#std : 样本数据的标准差
#min : 样本数据的最小值
#25% : 样本数据25%的时候的值
#50% : 样本数据50%的时候的值
#75% : 样本数据75%的时候的值
#max : 样本数据的最大值