

SPL 实现电力高频时序数据实时存储统计
阿里云国际版折扣https://www.yundadi.com |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
问题背景
发电设备中常常会放置传感器DCS来采集数据以监控设备运转的状况某集团设计的电力监控统计系统需要实时采集传感器的数据后保存然后提供按时段的实时查询统计功能。
系统设计规模将支持20万个传感器以下称为测点采集频率为每秒一个数据即每秒总共会有20万条数据总时间跨度在1年以上。在这个基础上实现任意指定时段的多个测点数据统计包括最大、最小、平均、方差、中位数等。
系统原结构图为
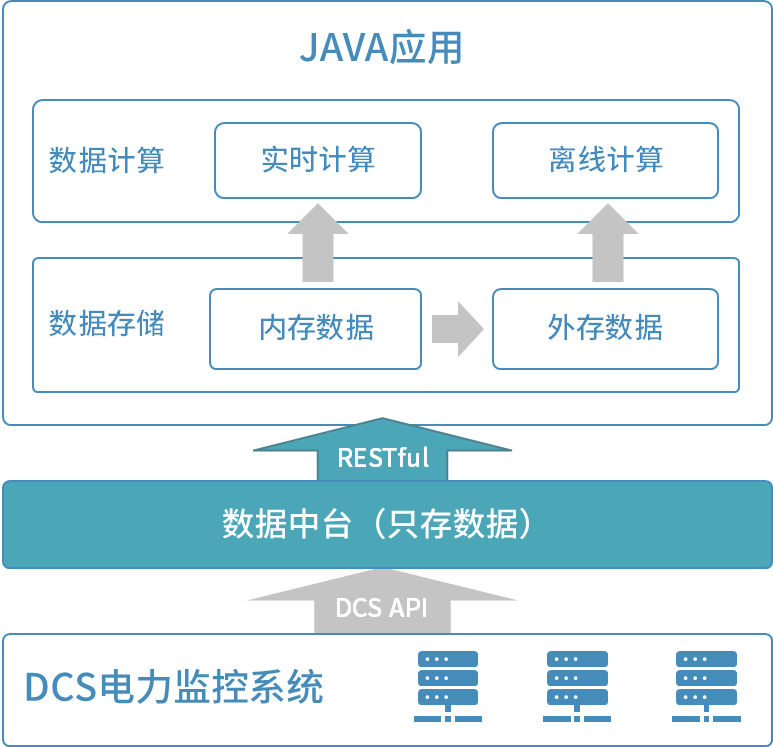
系统中用户期望的统计响应延迟为从20万个测点中任取100个测点统计频率最高可能每隔若干秒调用一次从总时间跨度中统计任意一天的数据预期执行时间在1分钟内另外还会有少许离线任务最长的时间段跨度长达一年。
现有的数据中台中没有计算能力仅存储数据计算时需要通过RESTful接口取出数据再统计。经测试通过RESTful接口从数据中台取数取出100个测点一天的数据量就需要10分钟时间还没有开始计算取数的时间已经远远超出了完成计算的预期时间。
基于现有结构完成上述统计任务性能上无法达到预期要求需要将数据重新存储。
解决办法
第一步梳理数据和计算要求
数据结构如下
| 字段名 | 类型 | 中文名 |
|---|---|---|
| TagFullName | 字符串 | 测点名 |
| Time | 长整型 | 时间戳 |
| Type | 数值 | 数据类型 |
| Qualitie | 数值 | 质量码 |
| Value | 浮点数 | 数值 |
计算要求为在每秒生成20万条记录的时序数据中任意时间段内从20万个测点中任取100个测点的数据分别基于每个测点的数值序列统计最大、最小、方差、中位数等结果。
第二步确定存储和计算方案
20万测点一天的数据仅Value字段就要200000*86400*4字节至少64g内存当总时间跨度为1年时数据量会有数十T单台服务器内存显然装不下。多台服务器集群又会带来很高的管理和采购成本。
简单按时间为序存储的数据可以迅速找到相应时间区间但即使是这样单个测点一天也有86400条记录20万个测点共17.28亿条每次统计都要遍历这个规模的数据也很难满足性能要求。
那么测点号上建立索引是否可行
索引只能快速定位数据但这些数据如果在外存中不是连续存储的硬盘有最小读取单位会导致大量无用数据量读出使得计算变得很慢同样也无法满足性能要求。此外索引占用空间会随着数据量增大而增大并且插入数据的维护开销也更大。
如果数据可以按测点号物理有序存储并在测点号上建立索引相比时序物理有序存储查找时待查找的测点记录变得紧凑了需要读入的块也就少了。100个测点的数据存成文本约300m不到这样即使使用外存也可以满足性能要求。
只有历史冷数据时处理起来比较简单定时将数据按指定字段排序即可。但实际上每秒都会有20万个测点的新数据因为历史数据规模巨大如果每次获取几秒热数据都与历史数据整体按测点号、时间排序即使不算排序仅是重写一遍的时间成本上都无法接受。
这时需要将冷热数据区分对待。不再变化的冷数据可以按测点次序准备好。这里有一点变通因为要将非常早期的数据删除比如一年前的如果所有冷数据都按测点排序时会导致数据维护比较麻烦删除早期数据会导致重写一遍所有数据。因此可以设计为先按时间分段每段时间内的数据按测点、时间有序整体数据还是按时间有序。任务需求是按天计算这里按天分段就比较合适更长跨度的离线计算性能损失也不是很大。每当一天过去时将昨天数据按上述规则排序后存储当天的数据作为热数据处理。但是当天内的数据量还是太大了依然无法全部装入内存还需要再分。
经过一些测试后确认我们发现将数据按热度分为三层可以满足要求。第一层十分钟内的热数据通过接口读入内存第二层每过10分钟将过去10分钟的内存数据按测点、时间有序保存到外存第三层每过一天将过去24小时内的所有每10分钟的数据按测点、时间有序归并。总数据为一年的数据由365段每天数据加144段当天数据和一段内存数据。
分层后的冷热数据属于不同的数据源需要独立计算同源数据的结果后再将结果合并起来算出最终的统计结果。即使计算方差、中位数这种需要全内存统计的情况100个测点一天的数据量也只需要64m内存。
第三步确定技术选型和方案
从上述的存储方案中得知需要将实时数据按时间分段段内按测点号、时间物理有序存储常规数据库显然没办法做到这点。此外拆分数据需要可以支持按自定义时间段灵活地拆分数据存储时要具备高性能索引冷热数据属于不同层不在同一个数据源计算时需要分别计算后再合并。
完成该任务用Java硬编码工作量巨大Spark写起来也很麻烦。开源的集算器SPL语言提供上述所有的算法支持包括高性能文件、物理有序存储、文件索引等机制能够让我们用较少的代码量快速实现这种个性化的计算。
取数不能再用原系统的RESTful接口也不合适直接通过API从DCS获取数据。用户方商定后引入kafka缓冲数据屏蔽DCS层同时还可以将DCS的数据提供给不同的消费者使用。变更后的系统结构图如下

说明
- DCS系统每秒推送20万个测点数据至Kafka MQ。
- Kafka MQ到SPL使用SPL基于Kafka API封装的Kafka函数连接Kafka、消费数据。
- 内存缓冲循环从Kafka消费数据(kafka_poll)每轮循环确保10秒以上的数据量将每轮前10秒的数据补全后按测点、时间序保存成文件并读入内存。
- 分层数据文件按不同时间段将冷热数据文件分层。
- 统计时将冷热数据混合计算。
- 支持每个测点名对应一个CSV文件作为数据源计算。
- 统计接口以HTTP服务方式供外部应用调用并将统计结果通过回调接口返回给外部应用。
第四步实施优化方案
现有的RESTful接口取数太慢了接口变为从kafka消费数据。存储数据时将字符串类型的测点名数字化后保存以获得更小的存储量和更好的运算性能。
在第二步中已经提到数据量较大时无法将数据都放在内存中计算所以考虑采用冷热分层方案将数据分为三层每天的冷数据按测点号、时间有序下文中的所有外存文件存储均采用该序不再重复说明用组表存储因为大表对性能的影响很大存储成组表有利于提升系统整体性能当天的每10分钟的冷数据用集文件存因为集文件创建和使用都更简单用来存储小表会很便捷也不会因为索引块而降低存储效率10分钟内的热数据从kafka直接读到内存因为数据本身是通过kafka接口获取的另外数据可能有一定的延迟不适合每秒取数即写出。
测试后发现10分钟内的热数据从kafka获取后再解析json不但需要消耗大量内存而且解析json也需要花费很长的时间。这样在内存中直接加载热数据是没办法用来统计计算的所以将热数据改为每10秒存成一个集文件。
接下来开始实现统计计算部分。每天组表中的冷数据计算较快但是当天的144个集文件计算很慢。通过计算可以知道每10分钟的数据量约1.2亿条记录这个规模的数据可以用组表来存储另外还可以再加一层每2小时一个组表文件来减少当天总文件数的数量从144个变成了24个。实际上计算时采用的二分查找是对单个文件内有序的测点号使用的减少了文件个数也就是减少了总查找次数。
最终我们把数据分成了4层。第一层延迟10秒的集文件热数据第二层每10分钟的组表冷数据第三层每2小时的组表冷数据第四层每天的组表冷数据。由于每层数据都按测点号、时间有序所以每一层都可以用归并快速生成下一层数据文件。
这时的冷数据计算已经很快了可以满足实际使用但是热数据的计算相比冷数据还是很慢。观察发现热数据的所有集文件都加起来大约3G不算很大内存可以装下。实际测试把文件读到内存中再查找相比直接外存文件查找可以快出好几倍。
已知的统计计算分为最大值、最小值、中位数、方差、平均值等不尽相同但是之前的数据查找是一样的。都用二分法找出对应测点号组的数据再用时间过滤即可得到相应的value值。
实测效果
经过几天时间的SPL编码、测试优化的效果非常明显。优化之后的测试结果如下耗时为毫秒
| 测点数 时间段 | 10 | 50 | 100 |
|---|---|---|---|
| 10分钟 | 467 | 586 | 854 |
| 1小时 | 1739 | 3885 | 4545 |
| 6小时 | 2599 | 7489 | 13138 |
| 1天 | 4923 | 16264 | 30254 |
说明测试环境使用的机械硬盘对并发计算不友好更换为固态硬盘后测试结果还会有较大的提升。
后记
解决性能优化难题最重要的是设计出高性能的计算方案有效降低计算复杂度最终把速度提上去。因此一方面要充分理解计算和数据的特征另一方面也要熟知常见的高性能算法和存储方案才能因地制宜地设计出合理的优化方案。本次工作中用到的基本高性能算法和存储方案都可以从下面这门课程中找到点击这里学习性能优化课程有兴趣的同学可以参考。
传统数据库的功能比较单一只能解决一个环节的问题比如内存数据库解决热数据问题大数据平台解决冷数据。而当前问题需要多种技术组合如果运用多种产品混合实现又会带来架构的复杂性增加系统的风险。而且业界中的大数据库产品的架构也较为死板对存储层基本不提供可编程能力很难基于这些产品实现某些特殊设计的方案。
相比之下集算器则拥有开放的技术架构和强大的编程能力SPL语言可以被深度控制从而实现各种因地制宜设计的方案。