

hadoop权威指南第四版-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
第一部分 HaDOOP基础知识
1.1 面临的问题
存储越来越大读写跟不上。
并行读多个磁盘。
问题1 磁盘损坏 – 备份数据HDFS
问题2 读取多个磁盘用于分析数据容易出错 --MR 编程模型
1.2 衍生品
1 在线访问的组件是hbase 。一种使用hdfs底层存储的模型。支持单行的读写对数据块读写也是不错的。
2 yarn 资源管理系统。允许其他分布式系统对hadoop集群数据运行。
迭代处理(iterative processing) spark.例如机器学习算法需要很多迭代。mr不支持。sparK 可基于内存计算。
3 流处理 sTORM SPARKSTEMING
4 SEARCH 搜索 solr (Solr它是一种开放源码的、基于Lucene Java 的搜索服务器) 。
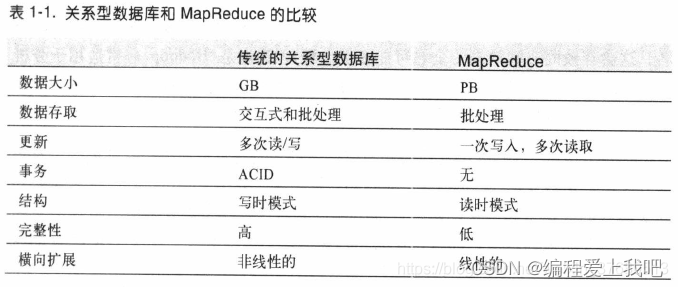
1.3 为什么不能用配有大量硬盘的数据库进行大规模分析为什么需要Hadoop
因为计算机硬盘的发展趋势是寻址时间的提升远远不如传输速率的提升如果访问包含大量地址的数据读取就会消耗很多时间
RDBMS B树是传统的数据库 适合更新一小部分数据。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |