

PySpark数据分析基础:核心数据集RDD原理以及操作一文详解(一)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
2.aggregateByKey(PairRDD Key值聚合操作)
前言
要进行大数据分析是离不开Spark的不然怎么说是大数据呢数据量不达到几个TB也好意思叫大数据哈...之前一直使用的Pandas做一些少量数据的分析处理的发现最近要玩的数据量实在过于巨大了不得不搬上我们的spark用集群去跑了。但是用Scala总感觉很别扭主要是已经好久没写scala代码了连IDEA的环境都没给配搞起来有点麻烦。虽然建议要是写spark数据分析还是使用原生的scala要好点但是使用python的效率确实是高并且可以兼容他的其他环境这是最舒服的。要是用scala的其他包得一个一个找并且使用例子很少远没有python直接调用其他库来得实在。人家apache也不是没想到不是有pysaprk这个东西嘛但是用这玩意感觉我就是在写python版本的scala说不出来的憋屈而且集群的spark还是2.x版本的一些pandas内置库也没有这就需要对pyspark底层有个详细的了解只能说车到山前必有路。好好再重新理解、操作一遍pyspark版本的RDD了。故写此文去希望能够帮助到和我一样worker。
一、RDD概念
RDD是Resilient distributed datasets的简称中文为弹性分布式数据集;是Spark最核心的模块和类。可以简单的把RDD理解成一个提供了许多操作接口的数据集合和一般数据集不同的是其实际数据分布存储于一批机器中内存或磁盘中这里的分区可以简单地和Hadoop HDFS里面的文件来对比理解。
RDD何为弹性分布式数据集
- 弹性之一自动的进行内存和磁盘数据存储的切换
- 弹性之二基于Lineage的高效容错第n个节点出错会从第n-1个节点恢复血统容错
- 弹性之三Task如果失败会自动进行特定次数的重试默认4次
- 弹性之四Stage如果失败会自动进行特定次数的重试可以只运行计算失败的阶段只计算失败的数据分片
- checkpoint和persist
- 数据调度弹性DAG TASK 和资源 管理无关
- 数据分片的高度弹性(人工自由设置分片函数),repartition
定义一个名为“myRDD”的RDD数据集这个数据集被切分成了多个分区可能每个分区实际存储在不同的机器上同时也可能存储在内存或硬盘上HDFS。
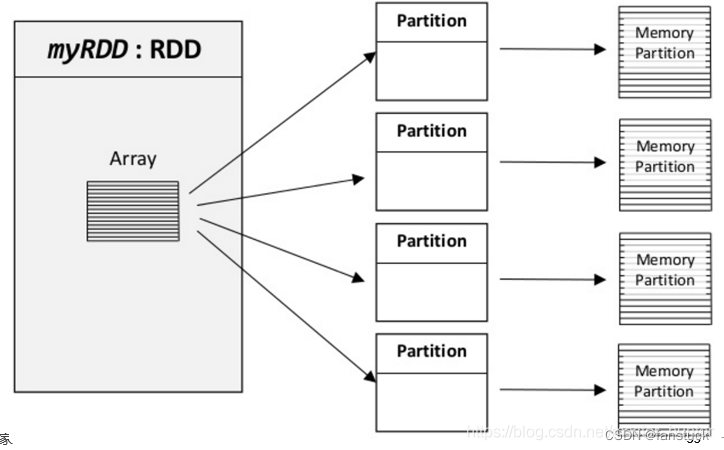
RDD 具有容错机制并且只读不能修改可以执行确定的转换操作创建新的 RDD。具体来讲RDD 具有以下几个属性。
- 只读不能修改只能通过转换操作生成新的 RDD。
- 分布式可以分布在多台机器上进行并行处理。
- 弹性计算过程中内存不够时它会和磁盘进行数据交换。
- 基于内存可以全部或部分缓存在内存中在多次计算间重用。
RDD 实质上是一种更为通用的迭代并行计算框架用户可以显示控制计算的中间结果然后将其自由运用于之后的计算。
在大数据实际应用开发中存在许多迭代算法如机器学习、图算法等和交互式数据挖掘工具。这些应用场景的共同之处是在不同计算阶段之间会重用中间结果即一个阶段的输出结果会作为下一个阶段的输入。
RDD 正是为了满足这种需求而设计的。虽然 MapReduce 具有自动容错、负载平衡和可拓展性的优点但是其最大的缺点是采用非循环式的数据流模型使得在迭代计算时要进行大量的磁盘 I/O 操作。
通过使用 RDD用户不必担心底层数据的分布式特性只需要将具体的应用逻辑表达为一系列转换处理就可以实现管道化从而避免了中间结果的存储大大降低了数据复制、磁盘 I/O 和数据序列化的开销。
RDD 的操作分为转化Transformation操作和行动Action操作。转化操作就是从一个 RDD 产生一个新的 RDD而行动操作就是进行实际的计算。
这里我就不对RD作更深入一步的展开的想要看更多的可以去看我的另一篇文章
这里补充一下RDD与DataFrame之间的区别。
二、RDD与DataFrame之间的区别
DataFrame是一种分布式的数据集并且以列的方式组合的。类似于关系型数据库中的表。可以说是一个具有良好优化技术的关系表。DataFrame背后的思想是允许处理大量结构化数据。提供了一些抽象的操作如select、filter、aggregation、plot。DataFrame包含带schema的行。schema是数据结构的说明。相当于具有schema的RDD。
特性区别
在Apache Spark 里面DF 优于RDD但也包含了RDD的特性。RDD和DataFrame的共同特征是不可性、内存运行、弹性、分布式计算能力。
它允许用户将结构强加到分布式数据集合上。因此提供了更高层次的抽象。我们可以从不同的数据源构建DataFrame。例如结构化数据文件、Hive中的表、外部数据库或现有的RDDs。DataFrame的应用程序编程接口(api)可以在各种语言中使用包括Python、Scala、Java和R。
1、RDD五大特性
1.(必须的)可分区的: 每一个分区对应就是一个Task线程。
2.(必须的)计算函数(对每个分区进行计算操作)。
3.(必须的)存在依赖关系。
4.(可选的)对于key-value数据存在分区计算函数。
5.(可选的)移动数据不如移动计算(将计算程序运行在离数据越近越好)。
2、DataFrame特性
1.支持从KB到PB级的数据量
2.支持多种数据格式和多种存储系统
3.通过Catalyst优化器进行先进的优化生成代码
4.通过Spark无缝集成主流大数据工具与基础设施
5.API支持Python、Java、Scala和R语言
本质区别
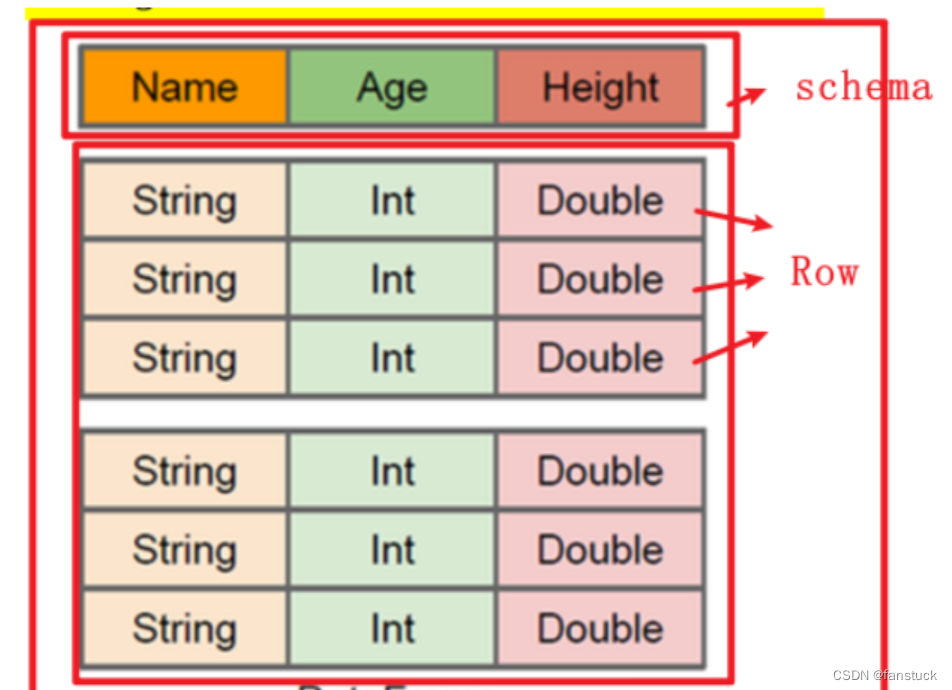
RDD是弹性分布式数据集数据集的概念比较强一点。容器可以装任意类型的可序列化元素支持泛型RDD的缺点是无从知道每个元素的【内部字段】信息。意思是下图不知道Person对象的姓名、年龄等。

DataFrame也是弹性分布式数据集但是本质上是一个分布式数据表因此称为分布式表更准确。DataFrame每个元素不是泛型对象而是Row对象。
DataFrame的缺点是SparkSQL DataFrame API 不支持编译时类型安全因此如果结构未知则不能操作数据同时一旦将域对象转换为Dataframe则域对象不能重构。
DataFrame=RDD-【泛型】+schema+方便的SQL操作+【catalyst】优化
DataFrame本质上是一个【分布式数据表】
三、PySpark中RDD的操作
1.aggregate(分区计算合并操作)
RDD.aggregate(zeroValue: U, seqOp: Callable[[U, T], U], combOp: Callable[[U, U], U]) → Uaggregate() 函数的返回类型不需要和 RDD 中的元素类型一致所以在使用时需要提供所期待的返回类型的初始值然后通过一个函数把 RDD 中的元素累加起来放入累加器。
aggregate(zero)(seqOp,combOp) 函数首先使用 seqOp 操作聚合各分区中的元素然后再使用 combOp 操作把所有分区的聚合结果再次聚合两个操作的初始值都是 zero。
seqOp 的操作是遍历分区中的所有元素 T第一个 T 跟 zero 做操作结果再作为与第二个 T 做操作的 zero直到遍历完整个分区。
combOp 操作是把各分区聚合的结果再聚合。aggregate() 函数会返回一个跟 RDD 不同类型的值。因此需要 seqOp 操作来把分区中的元素 T 合并成一个 U以及 combOp 操作把所有 U 聚合。
这样看起来会有点绕可以通过实际例子去理解我们做一个列表[1,2,3,4]去累加这个列表的结果
import pyspark
sc = pyspark.SparkContext()
seqOp = (lambda x, y: (x[0] + y, x[1] + 1))
combOp = (lambda x, y: (x[0] + y[0], x[1] + y[1]))
sc.parallelize([1, 2, 3, 4]).aggregate((0, 0), seqOp, combOp)这个函数输出的结果为

这个过程要这么理解
定义一个初始值 (0,0)即所期待的返回类型的初始值。代码seqOp = (lambda x, y: (x[0] + y, x[1] + 1))中的x[0]和x[1]就为初始值(0,0)那么这个y就是rdd中的list了。
程序的详细过程大概如下
(0+1,0+1)→(1+2,1+1)→(3+3,2+1)→(6+4,3+1)结果为(10,4)。
实际的 Spark 执行过程是分布式计算可能会把 List 分成多个分区假如是两个p1(1,2) 和 p2(3,4)。
# 注意: 初始值 会参与分区内和分区间的计算;
例如
sc.parallelize([1, 2, 3, 4],1).aggregate((5, 0), seqOp, combOp)(20, 4)
这个计算逻辑为
每个分区内的一次初始值(5) + 分区内的元素(1+2+3+4) + 分区间的一次初始值(5) = 20
可以通过看Spark的源码是一样的过程
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U = withScope {
// Clone the zero value since we will also be serializing it as part of tasks
var jobResult = Utils.clone(zeroValue, sc.env.serializer.newInstance())
val cleanSeqOp = sc.clean(seqOp)
val cleanCombOp = sc.clean(combOp)
val aggregatePartition = (it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)
val mergeResult = (index: Int, taskResult: U) => jobResult = combOp(jobResult, taskResult)
sc.runJob(this, aggregatePartition, mergeResult)
jobResult
}2.aggregateByKey(PairRDD Key值聚合操作)
RDD.aggregateByKey(zeroValue: U,
seqFunc: Callable[[U, V], U],
combFunc: Callable[[U, U], U],
numPartitions: Optional[int] = None,
partitionFunc: Callable[[K], int] = <function portable_hash>)
→ pyspark.rdd.RDD[Tuple[K, U]]对PairRDD中相同的Key值进行聚合操作在聚合过程中同样使用了一个中立的初始值。和aggregate函数类似aggregateByKey返回值的类型不需要和RDD中value的类型一致。因为aggregateByKey是对相同Key中的值进行聚合操作所以aggregateByKey’函数最终返回的类型还是PairRDD对应的结果是Key和聚合后的值而aggregate函数直接返回的是非RDD的结果。
如果需要在聚合操作前根据key进行分组 则使用 aggregateByKey方法;否则使用aggregate方法;
rdd_res = sc.parallelize([1, 2, 3, 4]).map(lambda x: (x, 1)).aggregateByKey((1, 0), seqOp, combOp)
print(rdd_res.collect())[(1, (2, 1)), (2, (2, 1)), (3, (2, 1)), (4, (2, 1))]
aggregateByKey:rdd分区内 所有元素先根据key进行分组,对每组的值 先进行聚合,然后分区间 根据key 再进行聚合;
3.map(逐个元素遍历操作)
RDD.map(f: Callable[[T], U],
preservesPartitioning: bool = False)
→ pyspark.rdd.RDD[U]上文提到了map函数这里就拿出来讲一下就相当于是pandas的apply操作类似
rdd = sc.parallelize(["b", "a", "c"])
sorted(rdd.map(lambda x: (x, 1)).collect())[('a', 1), ('b', 1), ('c', 1)]
比较容易理解对rdd每个元素进行操作可以嵌套函数处理。
rdd = sc.parallelize([1, 2, 3, 4])
sorted(rdd.map(lambda x: x+1).collect())[2, 3, 4, 5]
4.mapPartitions(分个分区操作)
RDD.mapPartitions(f: Callable[[Iterable[T]],
Iterable[U]], preservesPartitioning: bool = False)
→ pyspark.rdd.RDD[U]通过将函数应用于此RDD的每个分区返回一个新的RDD。
rdd = sc.parallelize([1, 2, 3, 4], 2)
def f(iterator): yield sum(iterator)
rdd.mapPartitions(f).collect()[3, 7]
将rdd的分区两个个为[1,2]和[3,4]作用f函数相加分别为[3,7]。用该函数需要注意一下分区数。
5.getNumPartitions(获取分区数)
RDD.getNumPartitions() → int对于分区数可以通过getNumPartitions()方法查看list被分成了几部分
rdd.getNumPartitions()2
6. glom()(分区状况)
RDD.glom() → pyspark.rdd.RDD[List[T]]glom().collect()查看分区状况
rdd.glom().collect()[[1, 2], [3, 4]]
初步就讲这么多函数最主要的我认为还是RDD和DataFrame之间的互相转换互相计算去满足业务逻辑需求。
点关注防走丢如有纰漏之处请留言指教非常感谢
以上就是本期全部内容。我是fanstuck 有问题大家随时留言讨论 我们下期见