

Linux 实现原理 — NUMA 多核架构中的多线程调度开销与性能优化-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
前言
NOTE本文中所指 “线程” 均为可执行调度单元 Kernel Thread。
NUMA 体系结构
NUMANon-Uniform Memory Access非一致性存储器访问的设计理念是将 CPU 和 Main Memory 进行分区自治Local NUMA node又可以跨区合作Remote NUMA node以这样的方式来缓解单一内存总线存在的瓶颈。

这里写图片描述
不同的 NUMA node 都拥有几乎相等的资源在 Local NUMA node 内部会通过自己的存储总线访问 Local Memory而 Remote NUMA node 则可以通过主板上的共享总线来访问其他 Node 上的 Remote Memory。
显然的CPU 访问 Local Memory 和 Remote Memory 所需要的耗时是不一样的所以 NUMA 才得名为 “非一致性存储器访问"。同时因为 NUMA 并非真正意义上的存储隔离所以 NUMA 同样只会保存一份操作系统和数据库系统的副本。也就是说默认情况下耗时的远程访问是很可能存在的。
这种做法使得 NUMA 具有一定的伸缩性更加适合应用在服务器端。但也由于 NUMA 没有实现彻底的主存隔离所以 NUMA 的扩展性也是有限的最多可支持几百个 CPU/Core。这是为了追求更高的并发性能所作出的妥协。

这里写图片描述
基本对象概念
- Node节点一个 Node 可以包含若干个 Socket通常是一个。
- Socket插槽一颗物理处理器 SoC 的封装。
- Core核心一个 Socket 封装的若干个物理处理器核心Physical processor。
- Hyper-Thread超线程每个 Core 可以被虚拟为若干个通常为 2 个逻辑处理器Virtual processors。逻辑处理器会共享大多数物理处理器资源e.g. 内存缓存、功能单元。
- Processor逻辑处理器操作系统层面的 CPU 逻辑处理器对象。
- Siblings操作系统层面的 Physical processor 和下属 Virtual processors 之间的从属关系。
下图所示为一个 NUMA Topology表示该服务器具有 2 个 Node每个 Node 含有一个 Socket每个 Socket 含有 6 个 Core每个 Core 又被超线程为 2 个 Thread所以服务器总共的 Processor = 2 x 1 x 6 x 2 = 24 颗其中 Siblings[0] = [cpu0, cpu1]。

这里写图片描述
查看 Host 的 NUMA Topology
#!/usr/bin/env python
# SPDX-License-Identifier: BSD-3-Clause
# Copyright(c) 2010-2014 Intel Corporation
# Copyright(c) 2017 Cavium, Inc. All rights reserved.
from __future__ import print_function
import sys
try:
xrange # Python 2
except NameError:
xrange = range # Python 3
sockets = []
cores = []
core_map = {}
base_path = "/sys/devices/system/cpu"
fd = open("{}/kernel_max".format(base_path))
max_cpus = int(fd.read())
fd.close()
for cpu in xrange(max_cpus + 1):
try:
fd = open("{}/cpu{}/topology/core_id".format(base_path, cpu))
except IOError:
continue
except:
break
core = int(fd.read())
fd.close()
fd = open("{}/cpu{}/topology/physical_package_id".format(base_path, cpu))
socket = int(fd.read())
fd.close()
if core not in cores:
cores.append(core)
if socket not in sockets:
sockets.append(socket)
key = (socket, core)
if key not in core_map:
core_map[key] = []
core_map[key].append(cpu)
print(format("=" * (47 + len(base_path))))
print("Core and Socket Information (as reported by '{}')".format(base_path))
print("{}\n".format("=" * (47 + len(base_path))))
print("cores = ", cores)
print("sockets = ", sockets)
print("")
max_processor_len = len(str(len(cores) * len(sockets) * 2 - 1))
max_thread_count = len(list(core_map.values())[0])
max_core_map_len = (max_processor_len * max_thread_count) \
+ len(", ") * (max_thread_count - 1) \
+ len('[]') + len('Socket ')
max_core_id_len = len(str(max(cores)))
output = " ".ljust(max_core_id_len + len('Core '))
for s in sockets:
output += " Socket %s" % str(s).ljust(max_core_map_len - len('Socket '))
print(output)
output = " ".ljust(max_core_id_len + len('Core '))
for s in sockets:
output += " --------".ljust(max_core_map_len)
output += " "
print(output)
for c in cores:
output = "Core %s" % str(c).ljust(max_core_id_len)
for s in sockets:
if (s,c) in core_map:
output += " " + str(core_map[(s, c)]).ljust(max_core_map_len)
else:
output += " " * (max_core_map_len + 1)
print(output)
OUTPUT
$ python cpu_topo.py
======================================================================
Core and Socket Information (as reported by '/sys/devices/system/cpu')
======================================================================
cores = [0, 1, 2, 3, 4, 5]
sockets = [0, 1]
Socket 0 Socket 1
-------- --------
Core 0 [0] [6]
Core 1 [1] [7]
Core 2 [2] [8]
Core 3 [3] [9]
Core 4 [4] [10]
Core 5 [5] [11]
上述输出的意义
- 有两个 Socket物理 CPU
- 每个 Socket 有 6 个 Core物理核)总计 12 个
Output
$ python cpu_topo.py
======================================================================
Core and Socket Information (as reported by '/sys/devices/system/cpu')
======================================================================
cores = [0, 1, 2, 3, 4, 5]
sockets = [0, 1]
Socket 0 Socket 1
-------- --------
Core 0 [0, 12] [6, 18]
Core 1 [1, 13] [7, 19]
Core 2 [2, 14] [8, 20]
Core 3 [3, 15] [9, 21]
Core 4 [4, 16] [10, 22]
Core 5 [5, 17] [11, 23]
- 有两个 Socket物理 CPU。
- 每个 Socket 有 6 个 Core物理核)总计 12 个。
- 每个 Core 有两个 Virtual Processor总计 24 个。
NUMA 架构中的多线程性能开销
1、跨 Node 的 Memory 访问开销
NUMA非一致性存储器访问的意思是 Kernel Thread 访问 Local Memory 和 Remote Memory 所需要的耗时是不一样的。
NUMA 的 CPU 分配策略有下 2 种
- cpu-node-bind约束 Kernel Thread 运行在指定的若干个 NUMA Node 上。
- phys-cpu-bind约束 Kernel Thread 运行在指定的若干个 CPU Core 上。
NUMA 的 Memory 分配策略有下列 4 种
- local-alloc约束 Kernel Thread 只能访问 Local Node Memory。
- preferred宽松地为 Kernel Thread 指定一个优先 Node如果优先 Node 上没有足够的 Memory 资源则允许运行在访问 Remote Node Memory。
- mem-bind规定 Kernel Thread 只能请求指定的若干个 Node 上的 Memory但并不严格规定只能访问 Local NUMA Memory。
- inter-leave规定 Kernel Thread 可以使用 RR 算法轮转地从指定的若干个 Node 上请求访问 Memory。
2、跨 Core 的多线程 Cache 同步开销
NUMA Domain Scheduler 是 Kernel 针对 NUMA 体系架构实现的 Kernel Thread 调度器目的是为了让 NUMA 中的每个 Core 都尽量均衡的忙碌。
根据 NUMA Topology 的特性呈一颗树状结构。NUMA Domain Scheduling从叶节点向上根节点遍历直到所有的 NUMA Domain 中的负载都是均衡的。当然用户可以对不同的 Domain 设置相应的调度策略。

这里写图片描述
但这种针对所有 Cores 的均衡优化是有代价的比如将同一个 User Process 对应若干个 Kernel Thread 均衡到不同的 Cores 上执行会使得 Core Cache 失效造成性能下降。
- Cache 可见性并发安全问题分别在 Core1 和 Core2 上运行的 Kernel Thread 都会在各自的 L1/L2 Cache 中缓存数据但这些数据对彼此是不可见的即如果在 Core1 不将 Cache 中的数据写回到 Main Memory 的前提下Core2 永远看不见 Core1 对某个变量数值的修改。继而会导致多线程共享数据不一致的情况。
- Cache 一致性并发性能问题如果多个 Kernel Thread 运行在多个 Cores 上同时这些 Threads 之间存在共享数据而这些数据有存储在 Cache 中那么就存在 Cache 一致性数据同步的必要。例如分别在 Core1 和 Core2 上运行的 Kernel Thread 希望保证共享数据是一致的那么就需要强制性的将 Core1 Cache 中对变量数值的修改写回到 Main Memory然后 Core1 通知 Core2 数值更新了再让 Core2 从 Main Memory 获取到最新的数值并加载到 Core2 Cache 中。为了维护 Cache 数据的一致性所产生的流量会为主存数据总线带来压力继而影响到 CPU 的性能。
- Cache 失效性并发性能问题如果出于均衡的考虑调度器会主动出发线程切换例如将在 Core1 上运行的 Kernel Thread 动态的调度到另一个空闲的 Core2 上运行那么在 Core1 Cache 上的数据就需要先写回到 Memory然后再进行调度。如果此时 Core1 和 Core2 分属于不同的 NUMA Node那么就会出现更加耗时的 Remote Memory 访问。
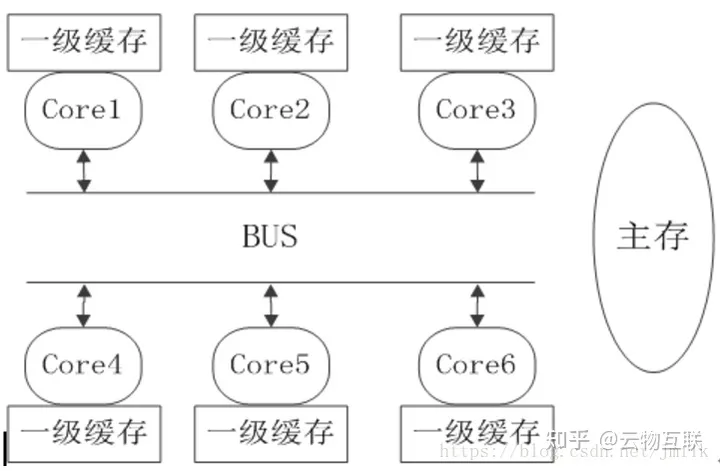
在这里插入图片描述
如下图所示在不同的 Domain 中存在着不同的 Cache 成本。虽然 NUMA Domain Scheduling 自身也具有软亲和特性但其到底是侧重于 NUMA Cores 的均衡调度而不是保证应用程序的执行性能。
可见NUMA Domain Scheduler 的均衡调度机制和高并发性能是相悖的。

这里写图片描述
3、多线程上下文切换开销
在 Core 执行任务期间需要将线程的执行现场信息存储在 Core 的 Register 和 Cache 中这些数据集称为 Context上下文有下列 3 种类型
- User Level ContextPC 程序计数器、寄存器、线程栈等。
- Register Context通用寄存器、PC 程序寄存器、处理器状态寄存器、栈指针等。
- Kernel Level Context进程描述符task_struct、PC 程序计数器、寄存器、虚拟地址空间等。
多线程的 Context Switch上下文切换也可以分为 2 个层面
- User Level Thread 层面由高级编程语言线程库实现的 Multiple User Threads在单一个 Core 上进行时间分片轮训被动切换或协作式自动切换。由于 User Thread 的 User Level Context 非常轻量且共享同一个 User Process 的虚拟地址空间所以 User Level 层面的 Context Switch 开销小速度快。
- Kernel Level Thread 层面Multiple Kernel Threads 由 Kernel 中的 NUMA Domain Scheduler 在多个 Cores 上进行调度和切换。由于 Kernel Thread 的 Context 更大Kernel Thread 执行现场包括task_struct 结构体、寄存器、程序计数器、线程栈等且涉及跨 Cores 之间的数据同步和主存访问所以 Kernel Level 层面的 Context Switch 开销大速度慢。
进行线程切换的过程中首先会将一个线程的 Context 存储在相应的用户或内核堆栈中然后把下一个要运行的线程的 Context 加载到 Core 的 Register 和 Cache 中。
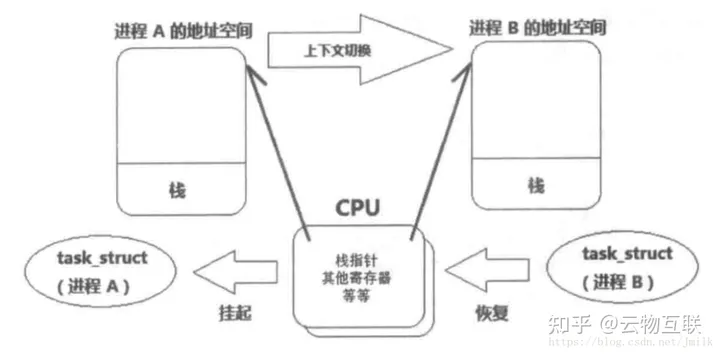
这里写图片描述
可见多线程的 Context Switch 势必会导致处理器性能的下降。并且 User Level 和 Kernel Level 切换很可能是同时出现的这些都是应用多线程模式所需要付出的代价。
使用 vmstat 指令查看当前系统的上下文切换情况
$ vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 1 0 4505784 313592 7224876 0 0 0 23 1 2 2 1 94 3 0
- rCPU 运行队列的长度和正在运行的线程数。
- b正在阻塞的进程数。
- swpd虚拟内存已使用的大小如果大于 0表示机器的物理内存不足了。如果不是程序内存泄露的原因那么就应该升级内存或者把耗内存的任务迁移到其他机器上了。
- si每秒从磁盘读入虚拟内存的大小如果大于 0表示物理内存不足或存在内存泄露应该杀掉或迁移耗内存大的进程。
- so每秒虚拟内存写入磁盘的大小如果大于 0同上。
- bi块设备每秒接收的块数量这里的块设备是指系统上所有的磁盘和其他块设备默认块大小是 1024Byte。
- bo块设备每秒发送的块数量例如读取文件时bo 就会大于 0。bi 和 bo 一般都要接近 0不然就是 I/O 过于频繁需要调整。
- in每秒 CPU 中断的次数包括时间中断。
- cs每秒上下文切换的次数这个值要越小越好太大了要考虑减少线程或者进程的数目。上下文切换次数过多表示 CPU 的大部分时间都浪费在上下文切换了而不是在执行任务。
- stCPU 在虚拟化环境上在其他租户上的开销。
4、CPU 运行模式切换开销
CPU 运行模式切换同样会对执行性能造成影响不过相对于上下文切换会更低一些因为模式切换最主要的任务只是切换线程寄存器的上下文。
Linux 系统中的以下操作会触发 CPU 运行模式切换
- 系统调用 / 软中断当应用程序需要访问 Kernel 资源时需要通过 SCI 进入内核模式执行相应的内核代码完成所需操作后再返回到用户模式。
- 中断处理当外设发生中断事件时会向 CPU 发出中断信号此时 Kernel 需要立即响应中断进入内核模式执行相应的中断处理程序处理完后再返回用户模式。
- 异常处理当 Kernel 出现运行时错误或其他异常情况如页错误、除零错误、非法操作等操作系统需要进入内核模式执行相应的异常处理程序进行错误恢复或提示然后再返回用户模式。
- Kernel Thread 切换当 User Process 下属的 Kernel Thread 进行切换时首先需要切换相应的 Kernel Level Context 并执行最后再返回用户模式下执行 User Process 的代码。
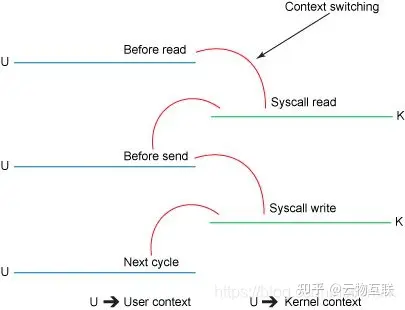
在这里插入图片描述
5、中断处理的开销
硬件中断HW Interrupt是一种外设e.g. 网卡、磁盘控制器、鼠键、串行适配卡等和 CPU 交互通信的机制让 CPU 能够及时掌握外设发生的事件并视乎于中断的类型来决定是否放下当前任务尽快处理紧急的外设事件e.g. 以太网数据帧到达键盘输入)。
硬件中断的本质是一个 IRQ中断请求信号电信号。Kernel 为每个外设分配了一个 IRQ Number以此来区分发出中断的设备类型。IRQ Number 又会映射到 Kernel ISR中断服务路由列表中的一个中断处理程序通常又外设驱动提供。
硬件中断是 Kernel 调度优先级最高的任务类型之一进行抢占式调度所以硬件中断通常都伴随着任务切换将当前任务切换到中断处理程序的上下文。
一次中断处理首先需要将 CPU 的状态寄存器数据保存到虚拟内存空间中的堆栈然后运行中断服务程序最后再将状态寄存器数据从堆栈中夹在到 CPU。整个过程需要至少 300 个 CPU 时钟周期。并且在多核处理器计算平台中每个 Core 都有可能执行硬件中断处理程序所以还存在着跨 Core 处理要面对的 Cache 一致性流量的问题。
可见大量的中断处理尤其是硬件中断处理会非常消耗 CPU 资源。
6、TLB 缓存失效的开销
因为 TLB地址映射表高速缓存的空间非常有限在使用 4K 小页的操作系统中出现 Kernel Thread 频繁切换时会导致 TLB 缓存的虚拟地址空间映射条目频繁变更产生大量的缓存缺失。
7、内存拷贝的开销
在网络报文处理场景中NIC Driver 运行在内核态当 Driver 收到的报文后首先会拷贝到 TCP/IP Stack 处理然后再拷贝到用户空间的应用程序缓冲区。这些拷贝处理的时间会占报文处理总时长的 57.1%。
NUMA 架构中的性能优化使用多核编程代替多线程
为了解决上述问题在 NUMA 架构中进一步提升多核处理器平台的性能应该广泛采用 “多核编程代替多线程编程” 的思想通过将 Kernel Threrad 与 NUMA Node 或 Core 建立亲和性以此来避免多线程调度带来的开销。
NUMA 亲和性避免 CPU 跨 NUMA 访问内存
在 Linux Shell 上可以使用 numastat 指令来查看 NUMA Node 的内存分配统计数据可以使用 numactl 指令可以将 User Process 绑定到指定的 NUMA Node还可以绑定到指定的 NUMA Core 上。
CPU 亲和性避免跨 CPU Cores 的 Kernel Thread 切换
CPU 亲和性CPU Affinity是 Kernel 的一种 Kernel Thread 调度属性Scheduling Property指定 Kernel Thread 要在特定的 CPU 上尽量长时间地运行而不被调度到其他的 CPU 上。在 NUMA 架构中设置 Kernel Thread 的 CPU 亲和性能够有效提高 Thread 的 CPU Cache 命中率减少 Remote NUMA Memory 访问的损耗以获得更高的性能。
- 软 CPU 亲和性是 Linux Scheduler 的默认调度策略调度器会积极的让 Kernel Thread 在同一个 CPU 上运行。
- 硬 CPU 亲和性是 Linux Kernel 提供的可编程 CPU 亲和性用户程序可以显式地指定 User Process 对应的 Kernel Thread 在哪个或哪些 CPU 上运行。
硬 CPU 亲和性通过扩展 task_struct进程描述符结构体来实现引入 cpus_allowed 字段来表示 CPU 亲和位掩码BitMask。cpus_allowed 由 n 位组成对应系统中的 n 个 Processor。最低位表示第一个 Processor最高位表示最后一个 Processor通过对掩码位置 1 来指定 Processors 亲和当有多个掩码位被置 1 时表示运行进程在多个 Processor 间迁移缺省为全部位置 1。进程的 CPU 亲和特性会传递给子线程。
在 Linux Shell 上可以使用 taskset 指令来设定 User Process 的 CPU 亲和性但不能保证 NUMA 亲和性的内存分配。
IRQ中断请求亲和性
Linux Kernel 提供了 irqbalance 程序来进行中断负载优化在大部分场景中irqbalance 提供的中断分配优化都是可以起到积极作用的irqbalance 会自动收集系统数据来分析出使用模式并依据系统负载状况将工作状态调整为以下 2 种模式
- Performance modeirqbalance 会将中断尽可能均匀地分发给各个 CPU 的 Core以充分提升性能。
- Power-save modeirqbalance 会将中断处理集中到第一个 CPU保证其它空闲 CPU 的睡眠时间降低能耗。
当然硬件中断处理也具有亲和性属性用于指定运行 IRP 对应的 ISR 的 CPU。在 Linux Shell 上可以修改指定 IRQ Number 的 smp_affinity。注意手动指定 IRQ 亲和性首先需要关闭 irqbalance 守护进程。
使用大页内存
- END -