

一百八十三、大数据离线数仓完整流程——步骤二、在Hive的ODS层建外部表并加载HDFS中的数据
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
一、目的
经过6个月的奋斗项目的离线数仓部分终于可以上线了因此整理一下离线数仓的整个流程既是大家提供一个案例经验也是对自己近半年的工作进行一个总结。
二、数仓实施步骤
二步骤二、在Hive的ODS层建外部表加载HDFS中的数据
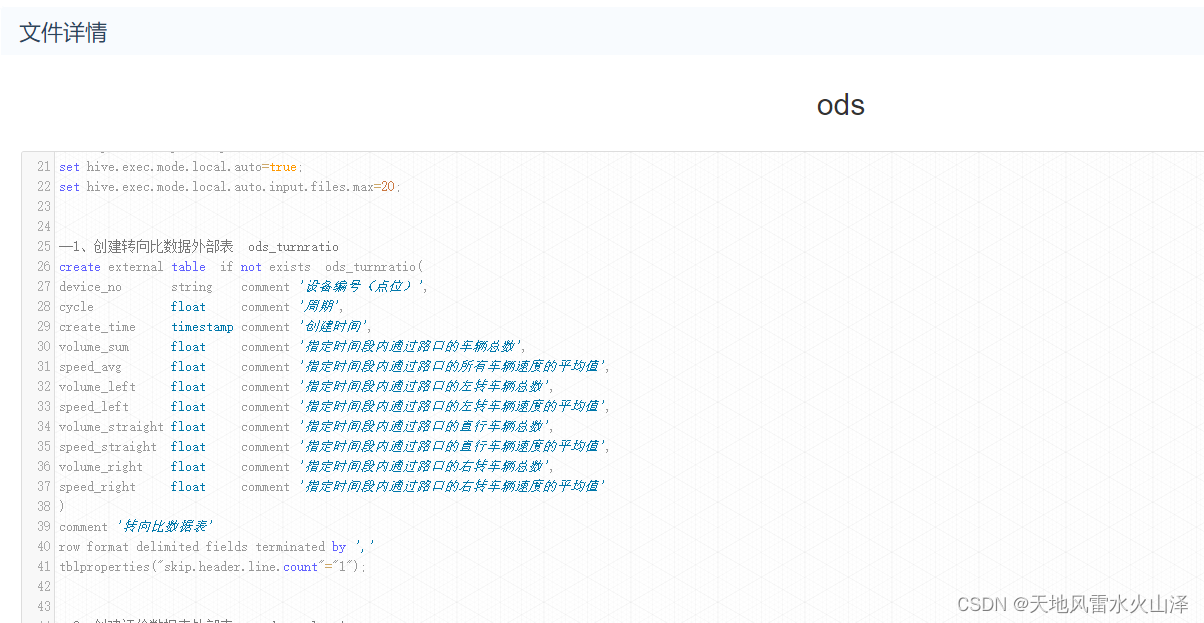
1、Hive的ODS层建库建表语句
--如果不存在则创建hurys_dc_ods数据库
create database if not exists hurys_dc_ods;
--使用hurys_dc_ods数据库
use hurys_dc_ods;
--1、创建转向比数据外部表 ods_turnratio
create external table if not exists ods_turnratio(
device_no string comment '设备编号点位',
cycle float comment '周期',
create_time timestamp comment '创建时间',
volume_sum float comment '指定时间段内通过路口的车辆总数',
speed_avg float comment '指定时间段内通过路口的所有车辆速度的平均值',
volume_left float comment '指定时间段内通过路口的左转车辆总数',
speed_left float comment '指定时间段内通过路口的左转车辆速度的平均值',
volume_straight float comment '指定时间段内通过路口的直行车辆总数',
speed_straight float comment '指定时间段内通过路口的直行车辆速度的平均值',
volume_right float comment '指定时间段内通过路口的右转车辆总数',
speed_right float comment '指定时间段内通过路口的右转车辆速度的平均值'
)
comment '转向比数据表'
row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1");
注意由于HDFS每种数据每天写入的是一个文件所以ODS层表不是分区表不需要静态分区
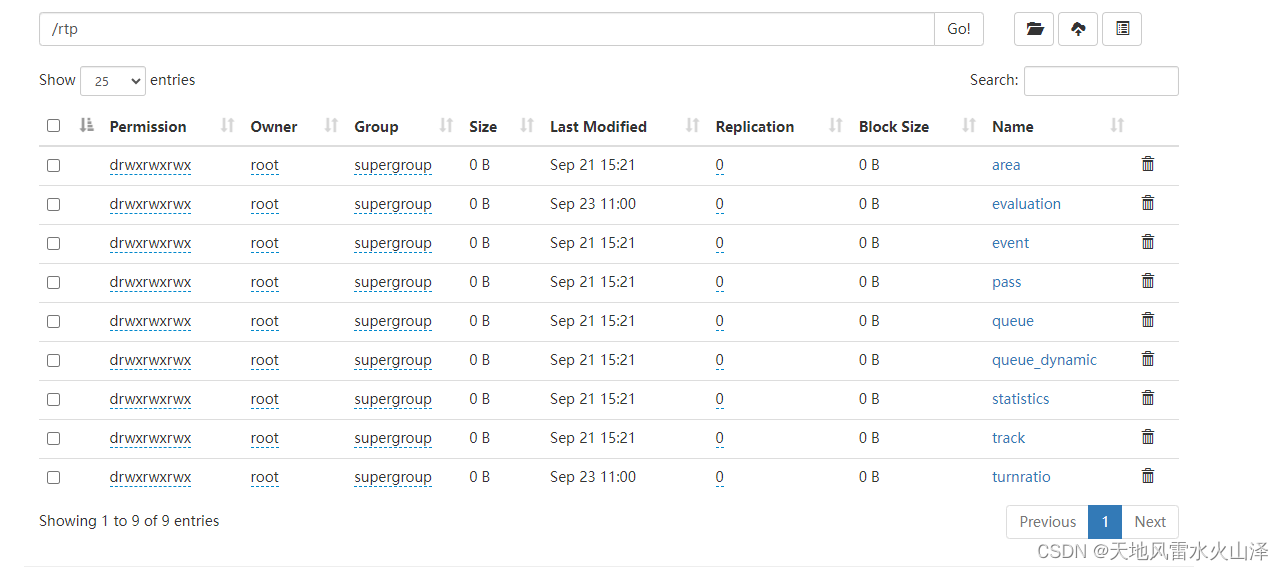
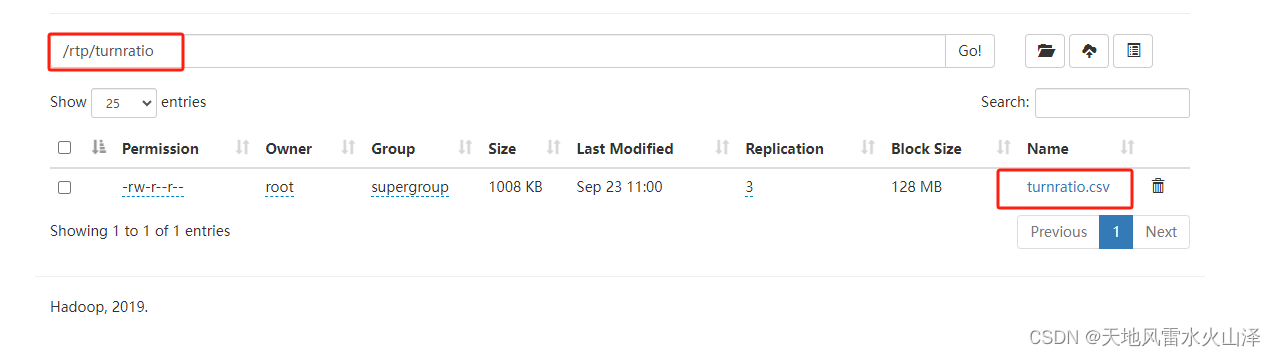
2、海豚执行ODS层建表语句工作流
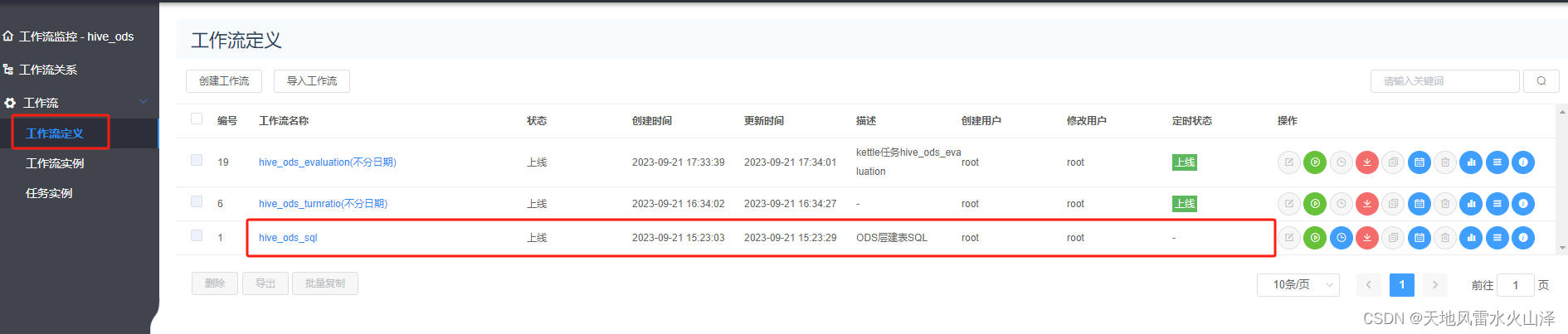
对于刚部署的服务器由于Hive没有建库建表、而且手动建表效率低因此通过海豚调度器直接执行建库建表的.sql文件
1海豚的资源中心加建库建表的SQL文件

2海豚配置ODS层建表语句的工作流不需要定时一次就行

3、海豚配置ODS层表每日加载HDFS数据的工作流
1海豚ODS层工作流配置需要定时每日一次


#! /bin/bash
source /etc/profile
rm -rf /home/hdfs_rtp_data/turnratio/turnratio.csv
hdfs dfs -get /rtp/turnratio/turnratio.csv /home/hdfs_rtp_data/turnratio/
hive -e "
use hurys_dc_ods;
set hive.vectorized.execution.enabled=false;
set hive.auto.convert.join=false;
set mapreduce.map.memory.mb=10150;
set mapreduce.map.java.opts=-Xmx6144m;
set mapreduce.reduce.memory.mb=10150;
set mapreduce.reduce.java.opts=-Xmx8120m;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.dynamic.partition=true;
set hive.exec.parallel=true;
set hive.support.concurrency=false;
set mapreduce.map.memory.mb=4128;
set hive.vectorized.execution.enabled=false;
load data local inpath '/home/hdfs_rtp_data/turnratio/turnratio.csv'
overwrite into table ods_turnratio
"
2工作流定时任务设置

3注意点
3.3.1 由于HDFS每种数据每天写入的是一个文件而且kettle任务在不停执行、不断写入因此需要先get到Linux本地才能得到一个有数据的文件。
hdfs dfs -get /rtp/turnratio/turnratio.csv /home/hdfs_rtp_data/turnratio/
3.3.2 需要先删除Linux本地的数据文件再从HDFS每日get文件
rm -rf /home/hdfs_rtp_data/turnratio/turnratio.csv
hdfs dfs -get /rtp/turnratio/turnratio.csv /home/hdfs_rtp_data/turnratio/
3.3.3 需要注意服务器各文件夹的磁盘使用情况把HDFS文件下载到磁盘大的文件夹下
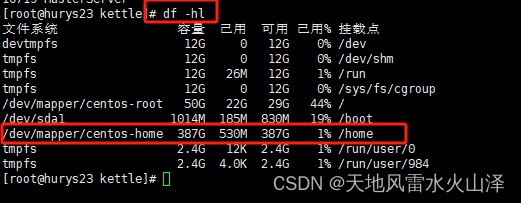
hdfs dfs -get /rtp/turnratio/turnratio.csv /home/hdfs_rtp_data/turnratio/
3.3.4 从Linux本地加载数据到ODS层外部表由于每次都是全部数据所以直接overwrite写入
load data local inpath '/home/hdfs_rtp_data/turnratio/turnratio.csv'
overwrite into table ods_turnratio
剩余数仓部分待续